1. Introduction
Atmospheric pollution [
1] is closely related to agricultural production and human health. In recent years, with the expansion of industrial production, the problem of atmospheric pollution has become increasingly serious. Thus, we must pay attention to this problem [
2]. PM2.5 refers to particles in the air with a particle size less than or equal to 2.5 microns, which can float in the outdoor air for a long time. Its content is a key factor in determining the degree of air pollution. A greater content of PM2.5 in the outdoor air indicates increased pollution. PM2.5 particles are also an important element in the formation of haze, as they are finer particles, are richer in harmful substances, and have a longer transmission distance and life span. Therefore, PM2.5 particles are harmful to human health, the quality of the atmospheric environment, and they have a more direct impact on air quality and visibility. A person’s travel and health conditions in haze environments [
3] are greatly affected. Therefore, it is necessary to establish accurate, reliable, and effective models to make predictions of atmospheric pollutant concentrations over a long period of time. The prediction results [
4,
5,
6,
7] can provide guidance for decision-making behavior, in addition to being important for the protection and management of ambient air.
Accurate long-term forecasting of PM2.5 concentration is more important than short-term forecasting, as it allows us more time to deal with the impact of air pollution. At present, the main timeseries forecasting methods are divided into two categories. One is the traditional probabilistic method [
8], which determines the parameters of the model according to theoretical assumptions and prior knowledge of the data. If our actual data and theoretical models do not match, then this method cannot give satisfactory long-term prediction results. There is also the machine learning method [
9]. The biggest difference with the traditional probability method is that the machine learning method does not need to determine the model parameters through theoretical assumptions and prior knowledge of the data. The algorithm is used for learning to obtain the law between the model parameters and the data to make predictions. Therefore, deep learning networks have actually surpassed traditional probabilistic prediction methods in many nonlinear modeling fields.
Traditional methods are mostly used in simple applications of the environment, such as threshold autoregressive (TAR) models [
10] and hidden Markov models (HMM) [
11] since these models are determined on the basis of theoretical assumptions and prior knowledge of the data parameters. Many times we cannot know the previous parameters, resulting in relatively large limitations, which seriously affect the accuracy of prediction.
Machine learning models are generally based on basic algorithms and historical data to build predictive models that can adaptively learn model parameters, obtain laws and relationships between complex data, and conduct simulation training through part of the data to obtain models to predict future development trends. Basic parameter identification algorithms include iterative algorithms [
12], particle-based algorithms [
13], and recursive algorithms [
14].
Machine learning models are divided into shallow networks and deep networks [
15,
16]. Shallow networks include the short-term prediction method based on the back-propagation (BP) neural network proposed by Ni et al. [
17], the improved grey neural network model [
18], the radial basis function (RBF) neural network [
19], etc. These methods have been used for PM2.5 concentration data, daily average temperature, and other pollutant concentration data.
However, due to the simple structure of the shallow network, it can only achieve short-term prediction performance, and long-term accurate prediction results must be captured using deep neural networks.
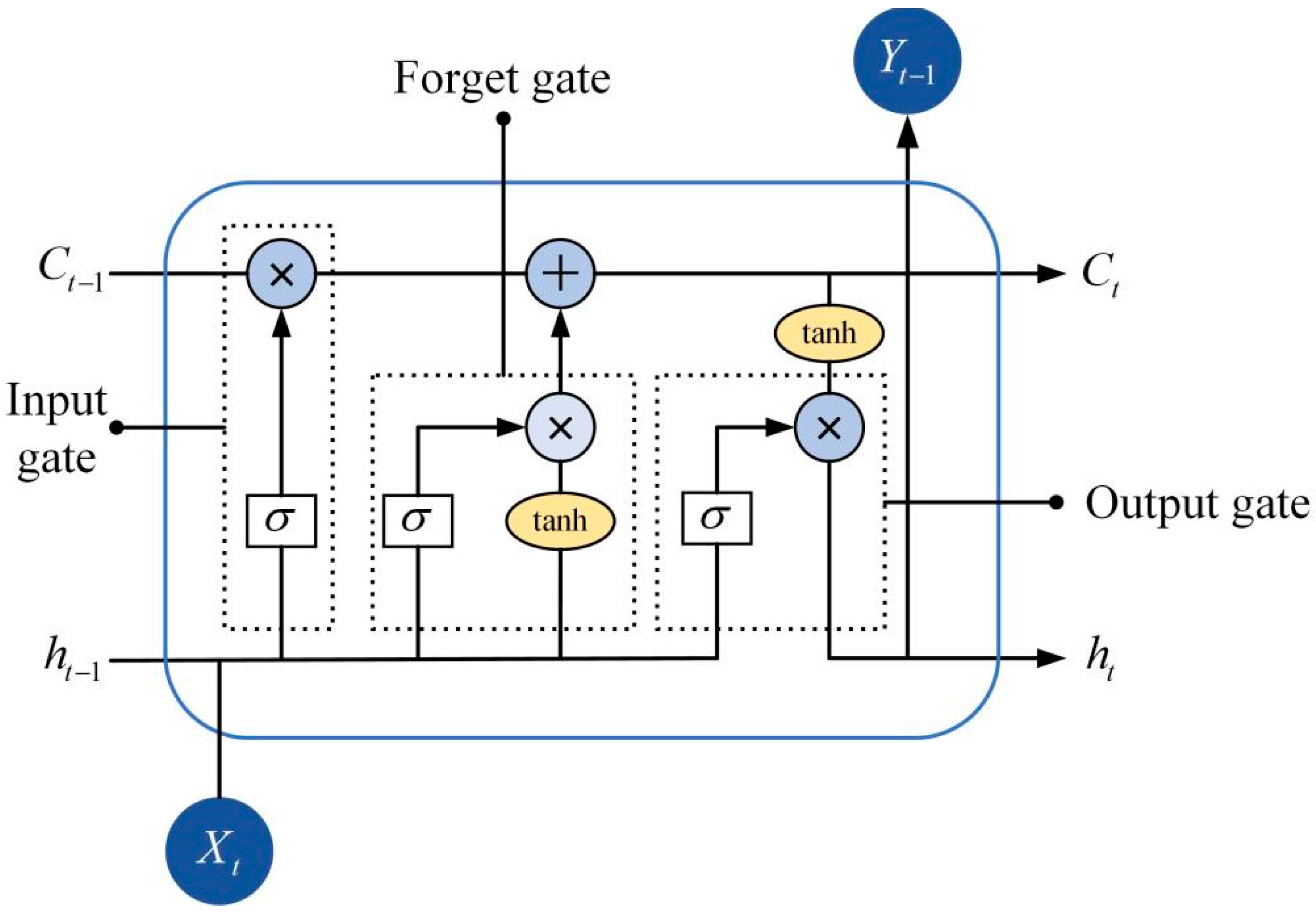
Deep machine learning networks show strong learning ability in complex timeseries. They have good performance in capturing the high nonlinearity of timeseries data. They can highly abstract data analysis through the multi-nonlinear transformation of complex structures. Timeseries problem-solving functions include long short-term memory (LSTM) [
20,
21], differential integrated moving average autoregressive model (ARIMA) [
22,
23], and support vector machine (SVM) [
24,
25].
Although deep machine learning models have the ability to extract accurate information in complex environments, PM2.5 concentration sequences are datasets with strong randomness and nonlinearity, and the accuracy of long-term prediction needs further development. In recent years, the application of deep learning methods in the field of air pollution has also attracted the attention of researchers, combinatorial approaches to data decomposition have been shown to be effective ways to improve forecasting performance, and various hybrid models have been introduced to forecast nonlinear timeseries data.
For example, Huang and Kuo [
26] used a hybrid model based on convolutional neural networks (CNNs) and LSTM to predict PM2.5 concentrations. Rojo used a loess-based seasonal decomposition program [
27,
28] to decompose the seasonal components of the data for the short-term prediction of air pollen, and Zhang and Li set the wavelet basis function through wavelet decomposition [
29,
30] to obtain the predicted decomposition information.
The fully adaptive noise ensemble empirical modal decomposition (CEEMDAN) algorithm [
31,
32] can completely decompose timeseries data into intrinsic mode function (IMF) components with different frequency characteristics [
33] and sort them from high frequency to low frequency, which can greatly reduce the complexity of the original data. We believe that the predictive power of a single model is ultimately limited; therefore, we focused on developing a combined model based on data decomposition.
The focus of this study is to improve the long-term prediction accuracy of PM2.5 based on deep learning networks, combined with the CEEMDAN decomposition algorithm, the complexity of the original PM2.5 data is effectively reduced, and to predict all IMF components separately through four different timeseries machine learning models, the BP model, ARIMA model, LSTM model, and SVM model. Different characteristics were used to adapt to different models, and then the optimal prediction results corresponding to each IMF component were superimposed and summed to restore the optimal solution so as to obtain the combination model based on the above models that was most suitable for Hangzhou PM2.5 data. Our innovation priorities were as follows:
- (1)
The CEEMDAN decomposition algorithm was introduced for the long-term prediction of PM2.5 timeseries data.
- (2)
After the IMF component was obtained using the CEEMDAN decomposition algorithm, an adaptive model was further established according to the characteristics of the IMF component, so as to improve the accuracy of long-term prediction.
- (3)
This method of further predictive analysis of the IMF components can become a new framework, which can be applied for the prediction of more similar data, thus obtaining accurate long-term prediction results.
3. Results and Analysis
In this study, we first compared the prediction effectiveness of individual models for PM2.5.
The PM2.5 prediction results of the four single models are shown in
Figure 8, and the error results are shown in
Table 1. It can be concluded that the basic trend of the future PM2.5 concentration could be predicted simply by using single models, but there were clearly large errors, especially at the peaks and troughs. The ARIMA model was the best model for predicting PM2.5 in Hangzhou among the four single models, with an RMSE of 10.09, an MAE of 7.51, and an
R2 of 0.46.
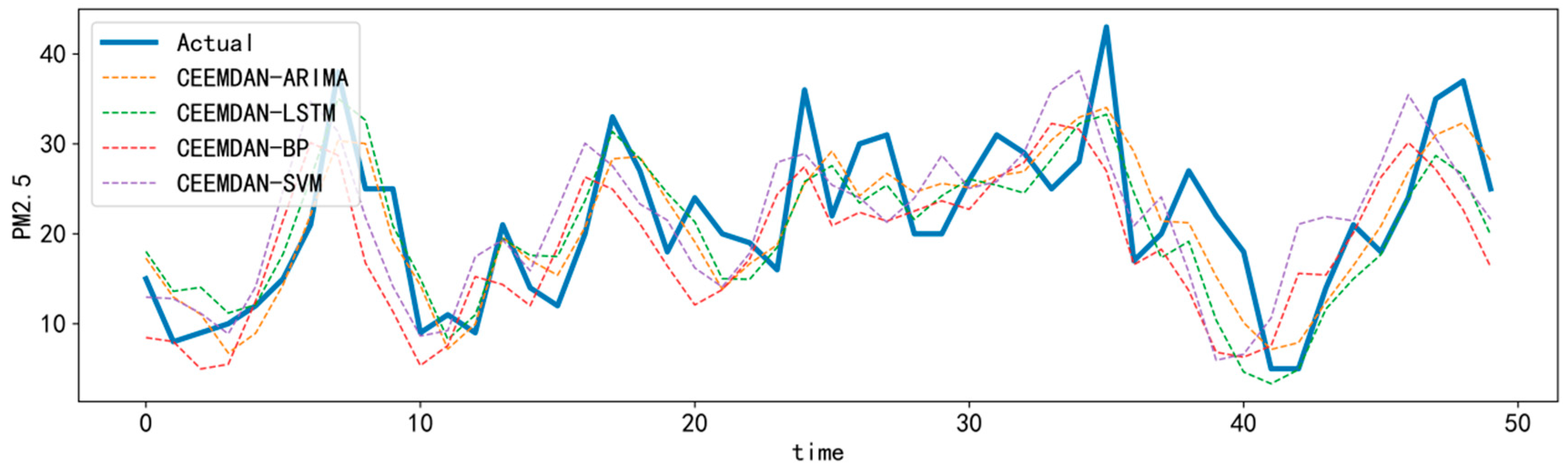
We then optimized the single models using the CEEMDAN algorithm due to its predictive power.
Figure 9 and
Table 2 show the prediction and error comparison results for the CEEMDAN–LSTM, CEEMDAN–ARIMA, CEEMDAN–BP, and CEEMDAN–SVM models.
It can be concluded that the prediction ability of the coupled models processed using the CEEMDAN algorithm was greatly improved, and the trend of PM2.5 concentration in the future could be better predicted. Every error metric in the coupled model was better than that of the single models in
Table 1. The fitting result of the CEEMDAN–SVM model was best, with an RMSE value of 6.27, an MAE value of 4.88, and an
R2 of 0.77. The comparison between the coupled models, combined with the CEEMDAN algorithm, and the simple models without the CEEMDAN algorithm fully reflect the superior performance of the CEEMDAN algorithm in improving the prediction accuracy of PM2.5.
Without the CEEMDAN algorithm, the predictive ability of the ARIMA model was better than that of the SVM model; whereas, with the CEEMDAN algorithm, the prediction ability of the CEEMDAN–SVM model was better than that of the CEEMDAN–ARIMA model. Their RMSE values were the same, but the MAE values of the CEEMDAN–SVM model were better. Therefore, we chose to compare the prediction results of each modal component after decomposition using the CEEMDAN algorithm in detail.
We used the CEEMDAN algorithm to completely decompose the original PM2.5 concentration data in Hangzhou into nine IMF components and residuals according to their frequency from high to low, and then substituted each IMF component and residual into the LSTM, ARIMA, SVM, and BP neural network models for prediction. The final prediction result was obtained by stacking and summing. The comparison results are shown in
Table 3,
Table 4 and
Table 5. The LSTM network performed best in IMF1 component prediction. The BP neural network performed best in predicting the IMF2 components. The prediction performance of the ARIMA model was excellent for the IMF3–9 components. Since the residual value was minuscule, the value of all models when predicting the residual was infinitely close to 0. It can be concluded that the model corresponding to each data type with the best performance was different, and no model could be used for all components. Therefore, data types with different frequencies should be matched with different prediction models, and the optimal solution for each IMF component prediction was obtained by constructing the CEEMDAN–LSTM–BP–ARIMA model. The prediction results obtained from the experiment are shown in
Figure 10, and the error results are shown in
Table 6. The fitting degree in the figure is high, and the various error indicators are significantly better than all the previous models.
In order to better reflect the applicability of the model, and to prevent the occurrence of chance, we substitute the data from Kunming, Yunnan Province, into the optimal model for validation. The prediction results are shown in
Figure 11, and the error results are shown in
Table 7. We can obviously conclude that the optimal model applicable to Hangzhou PM2.5 prediction is also applicable to Kunming, and the prediction results fit well with the actual values. Therefore, in this experiment, it can be said that the model combining the machine learning time series model with the CEEMDAN algorithm is the ideal model for predicting PM2.5 concentration.
Comparing various methods, Qian [
8] et al. used the traditional probabilistic method for PM2.5 concentration prediction, which was able to provide highly time-resolved particle concentrations, but required high parameters of the individual data itself, and required the combination of meteorological variables, land use terms, and spatial and temporal lag terms. In contrast, the learning ability of simple time series models such as LSTM, ARIMA, SVM, and BP is limited, and there is an upper limit to their ability to handle anomalous data. Zhao [
20] et al. used LSTM models to model the local variation of PM2.5, Chen [
18] et al. used BP neural networks for a 3-h short-term prediction of PM2.5 concentrations, and the experimental results proved that the single machine learning time series model has certain PM2.5 concentration prediction ability, which is mainly superior in the short term or locally, and the long-term results are not satisfactory. The CEEMDAN algorithm has been well applied in the hands of Rongbin [
32] et al. The algorithm has good decomposition integrity by decomposing the original signal with complexity and nonsmoothness into eigenmodal components (IMF), and the decomposition completes with significantly lower data values, so the decomposed training data can better improve the prediction accuracy when applied to a single neural network model.
4. Conclusions
In recent years, air quality problems have had a serious impact on people’s normal life. Environmental problems such as PM2.5 have received more and more attention and PM2.5 is characterized by a strong multilateral and a strong randomness. Thus, accurate long-term PM2.5 concentration prediction remains a formidable challenge for us.
In this study, we proposed a way to combine the CEEMDAN algorithm with the LSTM model, ARIMA model, BP neural network, and SVM model to predict the PM2.5 concentration. The results of various evaluation indicators showed that all models based on the CEEMDAN algorithm improved the prediction accuracy to varying degrees compared with the original simple models. The introduction of the CEEMDAN algorithm can provide new inspiration for a PM2.5 prediction, and the CEEMDAN algorithm can perhaps be combined with additional timeseries machine learning models. In this experiment, the predictive performance of the coupled model was higher than that of the single model.
Secondly, we discovered a new application of the IMF components obtained using the CEEMDAN algorithm. We carried out LSTM, ARIMA, BP neural network, and SVM modeling and prediction for each IMF component of the PM2.5 concentration timeseries data. The optimal prediction results of the components were added and summed. In this paper, the CEEMDAN-LSTM-BP-ARIMA model obtained the ideal results for a PM2.5 concentration prediction in Hangzhou and Kunming. Compared with the other models, the long-term prediction accuracy was significantly improved. Applying a single model is not optimal. We found that the best models differed according to IMF components, whereby a combination of timeseries machine learning models obtained the best prediction accuracy. We believe that this method also has good generalizability and can be used to predict additional characteristics such as wind speed and other pollutant concentrations.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}