
Automated Estimation of Construction Equipment Emission Using Inertial Sensors and Machine Learning Models



Abstract
:1. Introduction
2. Literature Review
2.1. On-Road Vehicles
2.2. Off-Road Vehicles
2.3. Training ML Models with Inertial Data
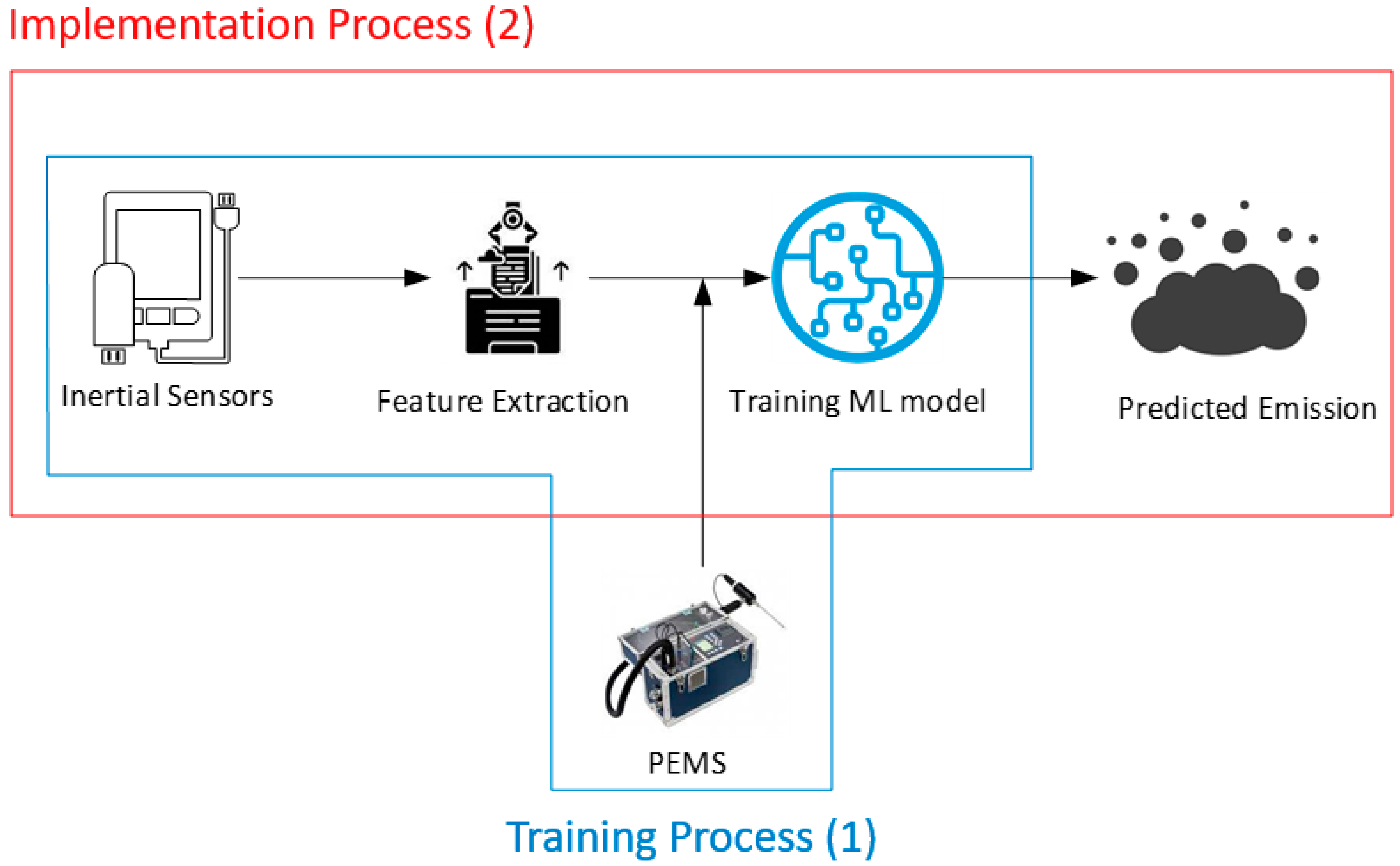
3. Methodology
3.1. Data Collection
3.2. Feature Extraction
3.3. Learning Algorithms and Performance Metrics
3.3.1. Linear Regression (LR)
3.3.2. Neural Network (NN)
3.3.3. Regression Trees (RT)
3.3.4. Random Forest (RF)
3.3.5. Performance Metrics
4. Results
4.1. LR
4.2. NN
4.3. RT
4.4. RF
5. Discussion
5.1. Model Performance and Pollutants Predictability
5.2. Evaluation of the Results in the Context of Previous Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Ghussain, L. Global warming: Review on driving forces and mitigation. Environ. Prog. Sustain. Energy 2019, 38, 13–21. [Google Scholar] [CrossRef] [Green Version]
- Abanda, F.; Tah, J.; Cheung, F. Mathematical modelling of embodied energy, greenhouse gases, waste, time–cost parameters of building projects: A review. Build. Environ. 2013, 59, 23–37. [Google Scholar] [CrossRef]
- Mishra, A.K.; Singh, V.P.; Jain, S.K. Impact of global warming and climate change on social development. J. Comp. Soc. Welf. 2010, 26, 239–260. [Google Scholar] [CrossRef]
- Cline, W.R. The impact of global warming of agriculture: Comment. Am. Econ. Rev. 1996, 86, 1309–1311. [Google Scholar]
- Keatinge, W.; Donaldson, G. The impact of global warming on health and mortality. South. Med. J. 2004, 97, 1093–1100. [Google Scholar] [CrossRef]
- Ring, M.J.; Lindner, D.; Cross, E.F.; Schlesinger, M.E. Causes of the global warming observed since the 19th century. Atmos. Clim. Sci. 2012, 2, 401. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Krigsvoll, G.; Johansen, F.; Liu, Y.; Zhang, X. Carbon emission of global construction sector. Renew. Sustain. Energy Rev. 2018, 81, 1906–1916. [Google Scholar] [CrossRef] [Green Version]
- González, M.J.; Navarro, J.G. Assessment of the decrease of CO2 emissions in the construction field through the selection of materials: Practical case study of three houses of low environmental impact. Build. Environ. 2006, 41, 902–909. [Google Scholar] [CrossRef]
- Teng, Y.; Li, K.; Pan, W.; Ng, T. Reducing building life cycle carbon emissions through prefabrication: Evidence from and gaps in empirical studies. Build. Environ. 2018, 132, 125–136. [Google Scholar] [CrossRef]
- Li, Z.T.; Akhavian, R. Carbon dioxide emission evaluation in construction operations using DES: A case study of carwash construction. In Proceedings of the 2017 Winter Simulation Conference (WSC), Las Vegas, NV, USA, 3–6 December 2017; pp. 2384–2393. [Google Scholar]
- Yan, H.; Shen, Q.; Fan, L.C.; Wang, Y.; Zhang, L. Greenhouse gas emissions in building construction: A case study of One Peking in Hong Kong. Build. Environ. 2010, 45, 949–955. [Google Scholar] [CrossRef] [Green Version]
- US EPA. User’s Guide for the Final NONROAD2005 Model; EPA420; U.S. Environmental Protection Agency: Washington, DC, USA, 2005.
- Heidari, B.; Marr, L.C. Real-time emissions from construction equipment compared with model predictions. J. Air Waste Manag. Assoc. 2015, 65, 115–125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frey, H.C.; Zhang, K.; Rouphail, N.M. Fuel use and emissions comparisons for alternative routes, time of day, road grade, and vehicles based on in-use measurements. Environ. Sci. Technol. 2008, 42, 2483–2489. [Google Scholar] [CrossRef] [PubMed]
- O’Driscoll, R.; ApSimon, H.M.; Oxley, T.; Molden, N.; Stettler, M.E.J.; Thiyagarajah, A. A Portable Emissions Measurement System (PEMS) study of NOx and primary NO2 emissions from Euro 6 diesel passenger cars and comparison with COPERT emission factors. Atmos. Environ. 2016, 145, 81–91. [Google Scholar] [CrossRef]
- Ceylan, İ.; Erkaymaz, O.; Gedik, E.; Gürel, A.E. The prediction of photovoltaic module temperature with artificial neural networks. Case Stud. Therm. Eng. 2014, 3, 11–20. [Google Scholar] [CrossRef] [Green Version]
- O’Driscoll, R.; Stettler, M.E.J.; Molden, N.; Oxley, T.; ApSimon, H.M. Real world CO2 and NOx emissions from 149 Euro 5 and 6 diesel, gasoline and hybrid passenger cars. Sci. Total Environ. 2018, 621, 282–290. [Google Scholar] [CrossRef]
- Sentoff, K.M.; Aultman-Hall, L.; Holmén, B.A. Implications of driving style and road grade for accurate vehicle activity data and emissions estimates. Transp. Res. Part D Transp. Environ. 2015, 35, 175–188. [Google Scholar] [CrossRef]
- Ben-Chaim, M.; Shmerling, E.; Kuperman, A. Analytic modeling of vehicle fuel consumption. Energies 2013, 6, 117–127. [Google Scholar] [CrossRef]
- de Lucas, A.; Durán, A.; Carmona, M.; Lapuerta, M. Modeling diesel particulate emissions with neural networks. Fuel 2001, 80, 539–548. [Google Scholar] [CrossRef]
- Alonso, J.M.; Alvarruiz, F.; Desantes, J.M.; Hernández, L.; Hernández, V.; Molto, G. Combining neural networks and genetic algorithms to predict and reduce diesel engine emissions. IEEE Trans. Evol. Comput. 2007, 11, 46–55. [Google Scholar] [CrossRef]
- Kesgin, U. Genetic algorithm and artificial neural network for engine optimisation of efficiency and NOx emission. Fuel 2004, 83, 885–895. [Google Scholar] [CrossRef]
- Obodeh, O.; Ajuwa, C. Evaluation of artificial neural network performance in predicting diesel engine NOx emissions. Eur. J. Sci. Res. 2009, 33, 642–653. [Google Scholar]
- Atkinson, C.M.; Long, T.W.; Hanzevack, E.L. Virtual sensing: A neural network-based intelligent performance and emissions prediction system for on-board diagnostics and engine control. Prog. Technol. 1998, 73, 2–4. [Google Scholar]
- Johri, R.; Filipi, Z. Neuro-fuzzy model tree approach to virtual sensing of transient diesel soot and NOx emissions. Int. J. Engine Res. 2014, 15, 918–927. [Google Scholar] [CrossRef]
- Traver, M.L.; Atkinson, R.J.; Atkinson, C.M. Neural network-based diesel engine emissions prediction using in-cylinder combustion pressure. SAE Trans. 1999, 108, 1166–1180. [Google Scholar]
- Si, M.; Tarnoczi, T.J.; Wiens, B.M.; Du, K. Development of Predictive Emissions Monitoring System Using Open Source Machine Learning Library—Keras: A Case Study on a Cogeneration Unit. IEEE Access 2019, 7, 113463–113475. [Google Scholar] [CrossRef]
- Roth, M.; Lawrence, P. A cost-effective alternative to continuous emission monitoring systems. Environ. Sci. Eng. Mag. 2010, 5, 6–57. [Google Scholar]
- Si, M.; Du, K. Development of a predictive emissions model using a gradient boosting machine learning method. Environ. Technol. Innov. 2020, 20, 101028. [Google Scholar] [CrossRef]
- Ciarlo, G.; Angelosante, D.; Guerriero, M.; Saldarini, G.; Bonavita, N. Enhanced PEMS Performance and Regulatory Compliance through Machine Learning. Sustain. Environ. 2018, 3, 329. [Google Scholar] [CrossRef]
- Lee, J.; Kwon, S.; Kim, H.; Keel, J.; Yoon, T.; Lee, J. Machine Learning Applied to the NOx Prediction of Diesel Vehicle under Real Driving Cycle. Appl. Sci. 2021, 11, 3758. [Google Scholar] [CrossRef]
- Wen, H.T.; Li, M.A.; Lu, J.H. The regression model of NOx emission in a real driving automobile. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Khurana, S.; Saxena, S.; Jain, S.; Dixit, A. Predictive modeling of engine emissions using machine learning: A review. Mater. Today Proc. 2021, 38, 280–284. [Google Scholar] [CrossRef]
- Fei, X.; Fang, Y.; Ling, Q. Discrimination of Excessive Exhaust Emissions of Vehicles based on Catboost Algorithm. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 4396–4401. [Google Scholar]
- Le Cornec, C.M.A.; Molden, N.; van Reeuwijk, M.; Stettler, M.E.J. Modelling of instantaneous emissions from diesel vehicles with a special focus on NOx: Insights from machine learning techniques. Sci. Total Environ. 2020, 737, 139625. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Wang, Y.; Li, J.; Fu, M.; Shah, A.N.; He, C. A Novel Deep Learning Approach to Predict the Instantaneous NOₓ Emissions From Diesel Engine. IEEE Access 2021, 9, 11002–11013. [Google Scholar] [CrossRef]
- May, D.; Fisher, L.; Tennis, C.; Parrish, T. Simple, portable, on-vehicle testing (SPOT) final report. Contract 2002, 86-C, 1–106. [Google Scholar]
- Gautam, M.; Carder, D.; Clark, N.; Lyons, D.W. Testing for Exhaust Emissions of Diesel Powered Off-Road Engines; Department of Mechanical and Aerospace Engineering: Morgantown, WV, USA, 2002. [Google Scholar]
- Vojtisek-Lom, M. Real-World Exhaust Emissions from Construction Equipment at the World Trade Center No. 7 Site; Clean Air Technologies International Inc.: Buffalo, NY, USA, 2003. [Google Scholar]
- United States Environmental Protection Agency. Quality Assurance Guidance Document-Model Quality Assurance Project Plan for the PM Ambient Air; United States Environmental Protection Agency: Washington, DC, USA, 2001.
- May, D.F. On-Vehicle Emissions Testing System; California Environmental Protection Agency: Sacramento, CA, USA, 2003.
- Abolhasani, S.; Frey, H.C.; Kim, K.; Rasdorf, W.; Lewis, P.; Pang, S.-H. Real-world in-use activity, fuel use, and emissions for nonroad construction vehicles: A case study for excavators. J. Air Waste Manag. Assoc. 2008, 58, 1033–1046. [Google Scholar] [CrossRef] [Green Version]
- Frey, H.C.; Rasdorf, W.; Kim, K.; Pang, S.-H.; Lewis, P. Comparison of real-world emissions of B20 biodiesel versus petroleum diesel for selected nonroad vehicles and engine tiers. Transp. Res. Rec. 2008, 2058, 33–42. [Google Scholar] [CrossRef]
- Frey, H.C.; Kim, K.; Pang, S.-H.; Rasdorf, W.J.; Lewis, P. Characterization of real-world activity, fuel use, and emissions for selected motor graders fueled with petroleum diesel and B20 biodiesel. J. Air Waste Manag. Assoc. 2008, 58, 1274–1287. [Google Scholar] [CrossRef]
- Lewis, P.; Rasdorf, W.; Frey, H.C.; Pang, S.-H.; Kim, K. Requirements and incentives for reducing construction vehicle emissions and comparison of nonroad diesel engine emissions data sources. J. Constr. Eng. Manag. 2009, 135, 341–351. [Google Scholar] [CrossRef]
- Lewis, P.; Frey, H.C.; Rasdorf, W. Development and use of emissions inventories for construction vehicles. Transp. Res. Rec. 2009, 2123, 46–53. [Google Scholar] [CrossRef]
- Frey, H.C.; Bammi, S. Probabilistic nonroad mobile source emission factors. J. Environ. Eng. 2003, 129, 162–168. [Google Scholar] [CrossRef]
- Frey, H.C.; Rasdorf, W.; Lewis, P. Comprehensive field study of fuel use and emissions of nonroad diesel construction equipment. Transp. Res. Rec. 2010, 2158, 69–76. [Google Scholar] [CrossRef]
- Barati, K.; Shen, X. Operational level emissions modelling of on-road construction equipment through field data analysis. Autom. Constr. 2016, 72, 338–346. [Google Scholar] [CrossRef]
- Somboonpisan, J.; Limsawasd, C. Environmental Weight for Bid Evaluation to Promote Sustainability in Highway Construction Projects. J. Constr. Eng. Manag. 2021, 147, 04021013. [Google Scholar] [CrossRef]
- Li, Q.; Stankovic, J.A.; Hanson, M.A.; Barth, A.T.; Lach, J.; Zhou, G. Accurate, fast fall detection using gyroscopes and accelerometer-derived posture information. In Proceedings of the 2009 Sixth International Workshop on Wearable and Implantable Body Sensor Networks, Berkeley, CA, USA, 3–5 June 2009; pp. 138–143. [Google Scholar]
- Van Laerhoven, K.; Cakmakci, O. What shall we teach our pants? In Proceedings of the Digest of Papers—Fourth International Symposium on Wearable Computers, Atlanta, GA, USA, 18–21 October 2000; pp. 77–83. [Google Scholar]
- Kochersberger, G.; McConnell, E.; Kuchibhatla, M.N.; Pieper, C. The reliability, validity, and stability of a measure of physical activity in the elderly. Arch. Phys. Med. Rehabil. 1996, 77, 793–795. [Google Scholar] [CrossRef]
- Alt, E. Medical Interventional Device with Accelerometer for Providing Cardiac Therapeutic Functions. U.S. Patent 5,472,453, 5 December 1995. [Google Scholar]
- Altun, K.; Barshan, B. Human activity recognition using inertial/magnetic sensor units. In Proceedings of the International Workshop on Human Behavior Understanding, Istanbul, Turkey, 22 August 2010; pp. 38–51. [Google Scholar]
- Casale, P.; Pujol, O.; Radeva, P. Human activity recognition from accelerometer data using a wearable device. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Las Palmas de Gran Canaria, Spain, 8–10 June 2011; pp. 289–296. [Google Scholar]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Proceedings of the International Conference on Pervasive Computing, Vienna, Austria, 21–23 April 2004; pp. 1–17. [Google Scholar]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the AAAI, Pittsburgh, PA, USA, 9–13 July 2005; pp. 1541–1546. [Google Scholar]
- Namal, S.; Senanayake, A.; Chong, V.; Chong, J.; Sirisinghe, G.R. Analysis of soccer actions using wireless accelerometers. In Proceedings of the 2006 4th IEEE International Conference on Industrial Informatics, Singapore, 16–18 August 2006; pp. 664–669. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Motoi, K.; Tanaka, S.; Nogawa, M.; Yamakoshi, K.-I. Evaluation of a new sensor system for ambulatory monitoring of human posture and walking speed using accelerometers and gyroscope. In Proceedings of the SICE 2003 Annual Conference, Fukui, Japan, 4–6 August 2003; (IEEE Cat. No. 03TH8734). pp. 1232–1235. [Google Scholar]
- Lukowicz, P.; Ward, J.A.; Junker, H.; Stäger, M.; Tröster, G.; Atrash, A.; Starner, T. Recognizing workshop activity using body worn microphones and accelerometers. In Proceedings of the International Conference on Pervasive Computing, Vienna, Austria, 21–23 April 2004; pp. 18–32. [Google Scholar]
- Sherafat, B.; Ahn, C.R.; Akhavian, R.; Behzadan, A.H.; Golparvar-Fard, M.; Kim, H.; Lee, Y.-C.; Rashidi, A.; Azar, E.R. Automated methods for activity recognition of construction workers and equipment: State-of-the-art review. J. Constr. Eng. Manag. 2020, 146, 03120002. [Google Scholar] [CrossRef]
- Akhavian, R.; Brito, L.; Behzadan, A. Integrated mobile sensor-based activity recognition of construction equipment and human crews. In Proceedings of the 2015 Conference on Autonomous and Robotic Construction of Infrastructure, Ames, IA, USA, 2–3 June 2015; pp. 1–20. [Google Scholar]
- Johnson, D.A.; Trivedi, M.M. Driving style recognition using a smartphone as a sensor platform. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1609–1615. [Google Scholar]
- Akhavian, R.; Behzadan, A.H. Simulation-based evaluation of fuel consumption in heavy construction projects by monitoring equipment idle times. In Proceedings of the 2013 Winter Simulations Conference (WSC), Washington, DC, USA, 8–11 December 2013; pp. 3098–3108. [Google Scholar]
- Akhavian, R.; Behzadan, A.H. Smartphone-based construction workers’ activity recognition and classification. Autom. Constr. 2016, 71, 198–209. [Google Scholar] [CrossRef]
- Akhavian, R.; Behzadan, A.H. Construction equipment activity recognition for simulation input modeling using mobile sensors and machine learning classifiers. Adv. Eng. Inform. 2015, 29, 867–877. [Google Scholar] [CrossRef]
- Slaton, T.; Hernandez, C.; Akhavian, R. Construction activity recognition with convolutional recurrent networks. Autom. Constr. 2020, 113, 103138. [Google Scholar] [CrossRef]
- Noraxon. myoMOTION Software Module. Available online: https://www.noraxon.com/our-products/myomotion/ (accessed on 25 July 2021).
- Instruments—E-Instruments Emissions Tools. Available online: https://www.e-inst.com/?gclid=CjwKCAjwxo6IBhBKEiwAXSYBszYQ7plZKlx1MgJvvrslD2L4V5KTJctU2fnGPdT9KXbD6lTga8OP-RoC3B4QAvD_BwE (accessed on 25 July 2021).
- Inc, A.T. How Do Electrochemical Sensors Work? Available online: https://www.analyticaltechnology.com/analyticaltechnology/gas-water-monitors/blog.aspx?ID=1327&Title=How%20Do%20Electrochemical%20Sensors%20Work (accessed on 20 August 2021).
- CO2meter. How Does an NDIR CO2 Sensor Work? Available online: https://www.co2meter.com/blogs/news/6010192-how-does-an-ndir-co2-sensor-work (accessed on 20 August 2021).
- Maksoud, E.A.A.; Barakat, S.; Elmogy, M. Medical images analysis based on multilabel classification. In Machine Learning in Bio-Signal Analysis and Diagnostic Imaging; Elsevier: Amsterdam, The Netherlands, 2019; pp. 209–245. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Uyanık, G.K.; Güler, N. A study on multiple linear regression analysis. Procedia-Soc. Behav. Sci. 2013, 106, 234–240. [Google Scholar] [CrossRef] [Green Version]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Pekel, E. Estimation of soil moisture using decision tree regression. Theor. Appl. Climatol. 2020, 139, 1111–1119. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Random forests. In The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2009; pp. 587–604. [Google Scholar]
- Kuhn, M. Caret: Classification and regression training. Astrophys. Source Code Libr. 2015, ascl:1505.1003. [Google Scholar]
- Xu, J.; Saleh, M.; Hatzopoulou, M. A machine learning approach capturing the effects of driving behaviour and driver characteristics on trip-level emissions. Atmos. Environ. 2020, 224, 117311. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Up to 16 Sensors |
|---|---|
| Static accuracy | ±0.4˚ |
| Dynamic accuracy | ±1.2˚ |
| Sampling frequency | 100 Hz |
| Data output | Joint angles, acceleration, rotation quaternions |
| Maximum output rate | 400 Hz |
| Orientation angel frequency | 0.25 degree (pitch/roll); 1.25 degrees (heading) |
| Anatomical angel frequency | +/− 1.0 degree (static); +/− 2.0 degrees (dynamic) |
| Angular velocity (Gyroscope) | +/− 7000 degrees/sec; Internal Sampling Rate 1600 Hz |
| Acceleration (Accelerometer) | +/− 200 g; Internal Sampling Rate 1600 Hz |
| Motion sensor dimensions | 1.75″ L × 1.3″ W × 0.48″ H (4.45 cm L × 3.3 cm W × 1.22 cm H) |
| Weight | Less than 0.67 oz (19 g) |
| Parameter | Sensor | Range | Resolution | Accuracy |
|---|---|---|---|---|
| NO | Electrochemical | 0–5000 ppm | 1 ppm | ±5 ppm < 100 ppm ±5% rdg for >100 ppm |
| NO2 | Electrochemical | 0–1000 ppm | 1 ppm | ±5 ppm < 100 ppm ±5% rdg for >100 ppm |
| CO2 | NDIR | 0–50.0% | 0.1% | ±3% rdg < 8% ±5% rdg < 50% |
| O2 | Electrochemical | 0–25% | 0.1% | ±0.2% vol |
| SO2 | Electrochemical | 0–5000 ppm | 1 ppm | ±5 ppm < 100 ppm ±5% rdg for >100 ppm |
| CH4 | NDIR | 0–50,000 ppm | 1 ppm | ±50 ppm < 2500 ppm ±2% >2500 ppm |
| H2S | Electrochemical | 0–500.0 ppm | 0.1 ppm | ±5 ppm <125 ppm ±4% rdg for <500 ppm |
| Tair | Pt100 | −4 to 248 °F −20 to 120 °C | 0.1 °F 0.1 °C | ±1 °F ±1 °C |
| Tgas | Tc K | −4 to 2280 °F −20 to 1250 °C | 0.1 °F 0.1 °C | ±2 °F ±2 °C |
| Emitted Gas | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| CO | 0.06 | 45.12 | 32.12 | 16.40 |
| NO | 0.19 | 84.42 | 71.39 | 20.84 |
| NO2 | 0.33 | 4.92 | 3.65 | 9.85 |
| NOX | 0.18 | 85.35 | 72.26 | 19.44 |
| CO2 | 0.22 | 113.98 | 92.25 | 18.65 |
| Layer Architecture | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| [40 30] | 0.81 | 20.72 | 12.41 | 7.55 |
| [40 30 20] | 0.80 | 20.77 | 12.43 | 7.56 |
| [100 90 80] | 0.82 | 19.85 | 11.79 | 7.22 |
| [200 190 180] | 0.79 | 20.88 | 12.36 | 7.59 |
| Layer Architecture | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| [40 30] | 0.62 | 58.97 | 43.17 | 13.73 |
| [40 30 20] | 0.64 | 56.48 | 39.80 | 12.86 |
| [100 90 80] | 0.65 | 55.92 | 39.47 | 12.74 |
| [200 190 180] | 0.65 | 55.82 | 38.67 | 12.71 |
| Layer Architecture | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| [40 30] | 0.71 | 69.94 | 45.78 | 11.45 |
| [40 30 20] | 0.71 | 69.94 | 45.78 | 11.45 |
| [100 90 80] | 0.78 | 60.51 | 37.32 | 9.90 |
| [200 190 180] | 0.77 | 60.61 | 36.46 | 9.92 |
| Emitted Gas | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| CO | 0.82 | 19.85 | 11.79 | 7.22 |
| NO | 0.66 | 54.71 | 38.02 | 13.51 |
| NO2 | 0.78 | 2.85 | 1.65 | 5.70 |
| NOx | 0.65 | 55.82 | 38.67 | 12.71 |
| CO2 | 0.78 | 60.51 | 37.32 | 9.90 |
| [MinLeafSize MinParentSize] | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| [1 5] | 0.77 | 44.46 | 19.63 | 10.12 |
| [1 10] | 0.78 | 43.98 | 20.42 | 10.02 |
| [2 5] | 0.76 | 45.82 | 20.92 | 10.43 |
| [2 10] | 0.77 | 45.08 | 21.16 | 10.26 |
| [3 5] | 0.76 | 45.22 | 21.30 | 10.30 |
| [3 10] | 0.77 | 44.87 | 21.47 | 10.22 |
| [MinLeafSize MinParentSize] | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|
| [1 5] | 0.86 | 47.52 | 18.00 | 7.77 |
| [1 10] | 0.86 | 47.28 | 18.53 | 7.73 |
| [2 5] | 0.87 | 46.97 | 18.17 | 7.67 |
| [2 10] | 0.86 | 47.45 | 19.05 | 7.76 |
| [3 5] | 0.86 | 48.02 | 19.46 | 7.86 |
| [3 10 | 0.86 | 47.79 | 19.77 | 7.82 |
| Gas | [MinLeafSize MinParentSize] | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|---|
| CO | [2 10] | 0.85 | 117.69 | 6.78 | 6.43 |
| NO | [1 10] | 0.79 | 42.39 | 19.66 | 10.47 |
| NO2 | [1 10] | 0.87 | 2.15 | 0.74 | 4.31 |
| NOx | [1 10] | 0.78 | 43.98 | 20.42 | 10.02 |
| CO2 | [2 5] | 0.87 | 46.97 | 18.17 | 7.67 |
| Gas | Number of Trees | R2 | RMSE | MAE | NRMSE |
|---|---|---|---|---|---|
| CO | 100 | 0.94 | 11.70 | 5.48 | 4.25 |
| NO | 100 | 0.91 | 28.35 | 16.77 | 7.00 |
| NO2 | 100 | 0.95 | 1.30 | 0.64 | 2.60 |
| NOx | 100 | 0.91 | 28.19 | 16.74 | 6.42 |
| CO2 | 100 | 0.94 | 31.63 | 15.98 | 5.17 |
| Gas | R2—Test Performance | R2—Train Performance | |
|---|---|---|---|
| LR | CO | 0.06 | 0.08 |
| NO | 0.19 | 0.25 | |
| NO2 | 0.33 | 0.33 | |
| NOX | 0.18 | 0.21 | |
| CO2 | 0.22 | 0.22 | |
| NN | CO | 0.82 | 0.81 |
| NO | 0.66 | 0.71 | |
| NO2 | 0.78 | 0.78 | |
| NOx | 0.65 | 0.68 | |
| CO2 | 0.78 | 0.78 | |
| RT | CO | 0.85 | 0.99 |
| NO | 0.79 | 0.98 | |
| NO2 | 0.87 | 0.99 | |
| NOx | 0.78 | 0.99 | |
| CO2 | 0.87 | 0.99 | |
| RF | CO | 0.94 | 0.94 |
| NO | 0.91 | 0.94 | |
| NO2 | 0.95 | 0.95 | |
| NOx | 0.91 | 0.94 | |
| CO2 | 0.94 | 0.94 |
| R2 | NN | RT | RF | LR |
|---|---|---|---|---|
| CO | 0.82 | 0.85 | 0.94 | 0.06 |
| NOX | 0.65 | 0.77 | 0.91 | 0.18 |
| CO2 | 0.78 | 0.87 | 0.94 | 0.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahnavaz, F.; Akhavian, R. Automated Estimation of Construction Equipment Emission Using Inertial Sensors and Machine Learning Models. Sustainability 2022, 14, 2750. https://doi.org/10.3390/su14052750
Shahnavaz F, Akhavian R. Automated Estimation of Construction Equipment Emission Using Inertial Sensors and Machine Learning Models. Sustainability. 2022; 14(5):2750. https://doi.org/10.3390/su14052750
Chicago/Turabian StyleShahnavaz, Farid, and Reza Akhavian. 2022. "Automated Estimation of Construction Equipment Emission Using Inertial Sensors and Machine Learning Models" Sustainability 14, no. 5: 2750. https://doi.org/10.3390/su14052750
APA StyleShahnavaz, F., & Akhavian, R. (2022). Automated Estimation of Construction Equipment Emission Using Inertial Sensors and Machine Learning Models. Sustainability, 14(5), 2750. https://doi.org/10.3390/su14052750