1. Introduction
The issue of spatial data quality has been attracting broad interest for many years, not only of data producers and distributors, but also from users and researchers. The importance of data quality in business and science is well recognized and widely described [
1,
2,
3,
4]. From the perspective of a data provider or distributor, quality assessment is one of the key elements of production that is always analysed in the context of compliance with technical specifications. The ability to create, collect, store, maintain, transmit, process and present information and data to support business processes in a timely and cost-effective manner requires both an understanding of the characteristics of information and data that determine its quality and the ability to measure, manage and report on it. The issue of geospatial data quality has a crucial role in terms of its ability to be used to determine sustainable development goals indicators. In 2015, the United Nations adopted 17 sustainable development goals (SDGs), which represented a universal call to action to end poverty, protect the planet and ensure peace and prosperity for all by 2030 [
5]. To track progress toward sustainable development goals, the UN proposed a set of 231 statistical indicators that range from health outcomes such as infant mortality (Indicator 3.2) to economic indicators such as the percentage of the population living in poverty (Indicator 1.1), environmental indicators such as air quality (Indicator 11.6) and geospatial data. Indicator-based approaches help ground broad and, in many cases, vague sustainable development goals in more concrete and measurable terms, but obtaining the data needed to monitor indicators on a national or global scale is a significant and fundamental challenge.
Data quality problems are quite widely highlighted by the international standards organization ISO (the International Organization for Standardization). ISO has developed several standards dedicated to the assessment and reporting of geospatial data quality, including: ISO 8000-61:2016—data quality and ISO 19157:2013—geographic information—data quality. ISO 8000-61:2016 specifies the processes required for data quality management. Each process is defined by a purpose, outcomes and the activities that are to be applied for the assurance of data quality [
6].
The following are within the scope of this part of ISO 8000: fundamental principles of data quality management, the structure of the data quality management process, definitions of the lower-level processes for data quality management, the relationship between data quality management and data governance and implementation requirements.
The scope of this part of ISO 8000 does not include detailed methods or procedures by which to achieve the outcomes of the defined processes.
ISO 19157:2013 establishes the principles for describing the quality of geographic data. It defines the components for describing data quality, specifies the components and content structure of a register for data quality measures, describes general procedures for evaluating the quality of geographic data and establishes the principles for reporting data quality. ISO 19157:2013 also defines a set of data quality measures for use in evaluating and reporting data quality. It is applicable to data producers who provide quality information to describe and assess how well a data set conforms to its product specification and to data users attempting to determine whether or not specific geographic data are of sufficient quality for their particular application. ISO 19157:2013 does not attempt to define minimum acceptable levels of quality for geographic data.
In ISO normative documents, quality is defined as a comprehensive set of characteristics and features of data sets and services that affect the ability to satisfy current and future user requirements [
7]. The characteristics and features mentioned in the standard with respect to spatial data sets are defined by more than a dozen quantitative and qualitative indicators. The most commonly used ones, which are also valid for INSPIRE Directive (Infrastructure for Spatial Information in Europe) data sets, include completeness (lack and excess of objects), logical consistency (conceptual, topological, domain and format), position accuracy, temporal and thematic accuracy (e.g., correctness of classification or correctness of quality attributes) and lineage [
8]. All the mentioned quality elements are assessed in terms of compliance with the technical specifications of the data, and the results of the assessment are reported in the metadata. Researchers also pay attention to data availability, which is often a key element of quality, and to the distributor that guarantees better quality, e.g., official data are considered more reliable [
3].
As far as data collected voluntarily and free of charge by a very large number of volunteers, referred to as volunteered geographic information (VGI) or crowdsourcing geodata are concerned, the use of the indicators mentioned above becomes problematic. This results from the lack of detailed technical specifications, only giving rules and guidelines for data provision, and the frequent absence of formal verification of all data entered into the database. Volunteers are usually left with a great deal of discretion regarding the accuracy of the data entered and the detail of its descriptive characteristics. Data verification is generally performed by other users, who are potentially more familiar with the area or willing to use community data for specific tasks. The dataset that is the most commonly studied and evaluated for data quality is OpenStreetMap (OSM), which is also a potential source of geospatial data for monitoring SDG indicators [
9,
10].
1.1. Related Works
The usage of OpenStreetMap has rapidly increased since it was first established in 2004. In line with this increased usage, a number of studies have been conducted to analyse the accuracy and quality of OSM data, but many of them focus mainly on the completeness and accuracy of the location of roads or buildings. In the study [
11], the author aimed to analyse the quality of OSM data by comparing it with the Ordnance Survey (OS) data sets in England and selected five areas of London. The geometric accuracy and completeness of road sections were analysed. The analysis shows that OSM information can be quite accurate: on average at a distance of about 6 m from the position recorded by the operating system and with about 80% overlap of highway features between the two data sets. In paper [
12], OSM road data was analysed to characterize the behaviour of OSM participants. The study area, Ankara, the capital of Turkey, was evaluated using several network analysis methods such as completeness, degree centrality, proximity, PageRank and a proposed method to measure contributor activation in a limited area from 2007–2017. The results show that the experience level of contributors determines the type of contribution. In general, more experience means more detailed contributions. The paper [
13] analyses the spatial pattern, evolution, density and diversity of OSM road networks in Iran between 2008 and 2016 and looks to find casual relations between OSM and census statistics. This is due to the fact that OSM completeness reflects the importance of OSM data in human life. The results show that the road network in Iran considerably increased from 2008 to 2016, with road length increasing to 489,400 km in 2016 from 4300 km in 2008. Road density grew while road diversity and evenness declined. Mapping direction extended from big cities to medium or small-sized ones. Western counties located in mountainous regions are still not very active. The top active counties producing OSM data are mostly populated by urban citizens.
This study [
14] aims to provide an analysis of the evolution, completeness and spatial patterns of OSM building data in China from 2012 to 2017 using two quality indicators, OSM building count and OSM building density. The development of OSM numbers from 2012 to 2017 is analysed by province in a regular 1 km
2 grid. The obtained results showed that the number of OSM buildings increased nearly 20 times from 2012 to 2017, and in most cases, economic (gross domestic product) and OSM road length are two factors that can influence the development of OSM building data in China. Most grid cells in urban areas have no building data, but two typical patterns (dispersion and aggregation) of high-density grid cells are among the prefecture-level divisions. In the article [
15], the authors describe the methods of completeness analysis of OSM buildings and their application to various test areas in Germany. The results show that unit-based completeness measurements (e.g., total number or area of buildings) are very sensitive to modelling discrepancies between official data and OSM. The November 2011 analysis in Germany showed a completeness of 25% in the Länder of North Rhine-Westphalia and 15% in Saxony. While further analyses from 2012 confirm that the completeness of the data in Saxony increased to 23%, the pace of new data entry decreased in 2012. In study [
16], the quality of OSM land use and land-cover (LULC) data is investigated for an area in southern Germany for two spatial data quality elements: thematic accuracy and completeness. The results show a substantial agreement between OSM and the authoritative dataset. Nonetheless, for this study region, there were clear variations between the LULC classes. Forest covers a large area and shows both a high OSM completeness (97.6%) and correctness (95.1%). In contrast, farmland also covers a large area, but for this class OSM shows a low completeness value (45.9%) due to unmapped areas. Additionally, the results indicate that a high population density, as present in urbanized areas, seems to denote a higher strength of agreement between OSM and the DLM (digital landscape model).
These studies show that OSM information can be quite accurate, but its value depends on the areas for which it was acquired. The aforementioned studies clearly show that the best spatial data quality results were achieved for urban areas and those of interest to OSM users. Based on the statistical results of the research, the authors have inferred that the experience levels of contributors determine the contribution type and level of object detail.
1.2. Research Purpose
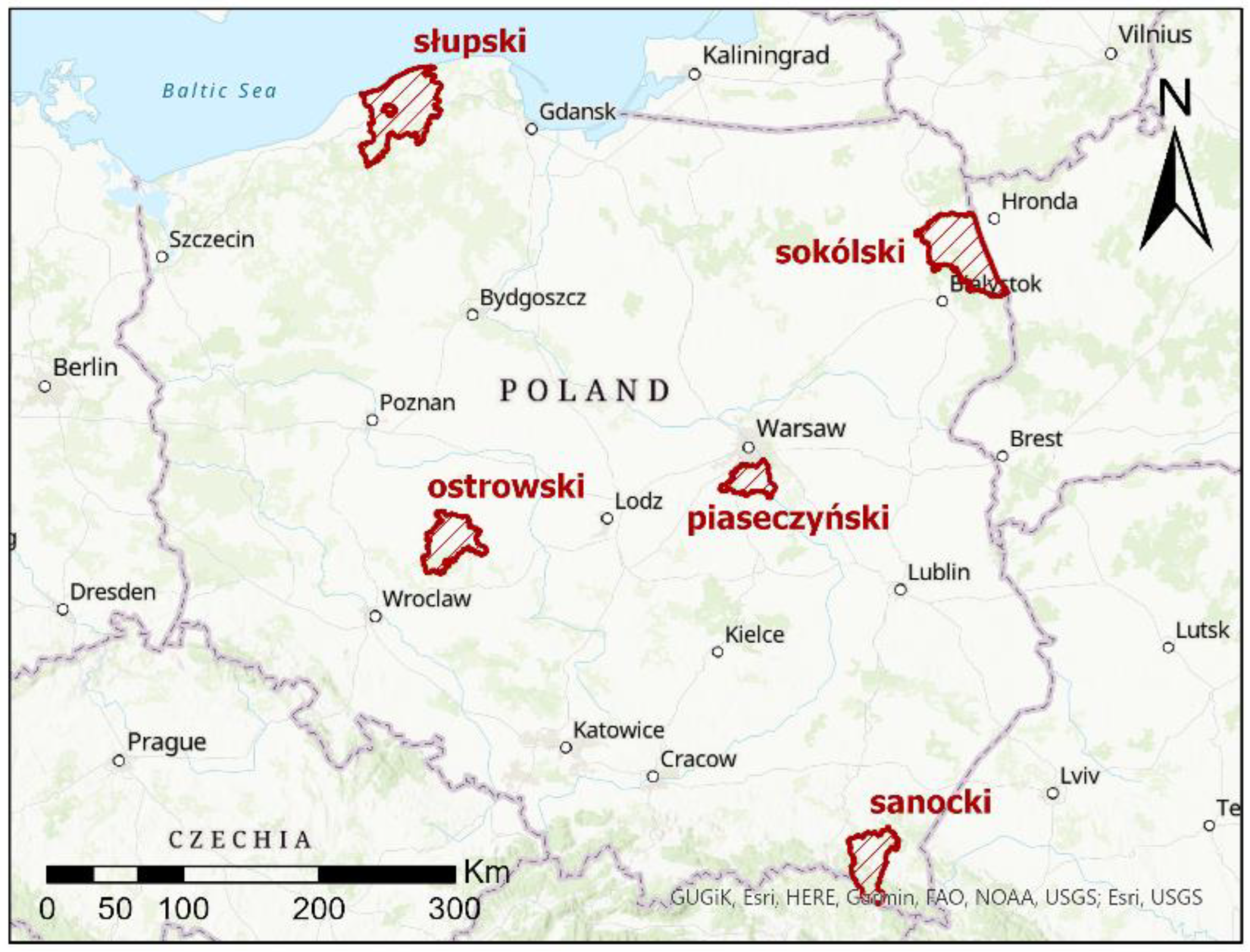
Taking into account the above facts, this paper presents a comprehensive assessment of the quality of OpenStreetMap volunteer data, paying attention to the aspect of imperfect semantic findings and quality assumptions. The research question posed was to determine, first of all, the completeness, location accuracy and attribute compatibility of the main land-cover classes of OSM objects in relation to the national official data collected in the database of topographic objects, which was the reference base in the conducted research. The analyses were performed for five selected counties in Poland, taking into account their diversity in terms of terrain and urbanization level, which allows them to be treated as representative samples. The data to which OSM was referred were official Polish data from BDOT10k (National Database of Topographic Objects). This study complements the previous research results in the field of quantitative and qualitative analysis of OSM data, especially in relation to the Polish territory, taking into account the diversity of land cover and development of the test areas. A novelty in the study is its comprehensive approach to assessing the quality of OSM data for the main classes of land cover in the area of a particular county. Another novelty is the analysis of these elements in relation to the indicators of sustainable development, including economic resources.
4. Results
4.1. Geometric Accuracy of OSM Area Objects
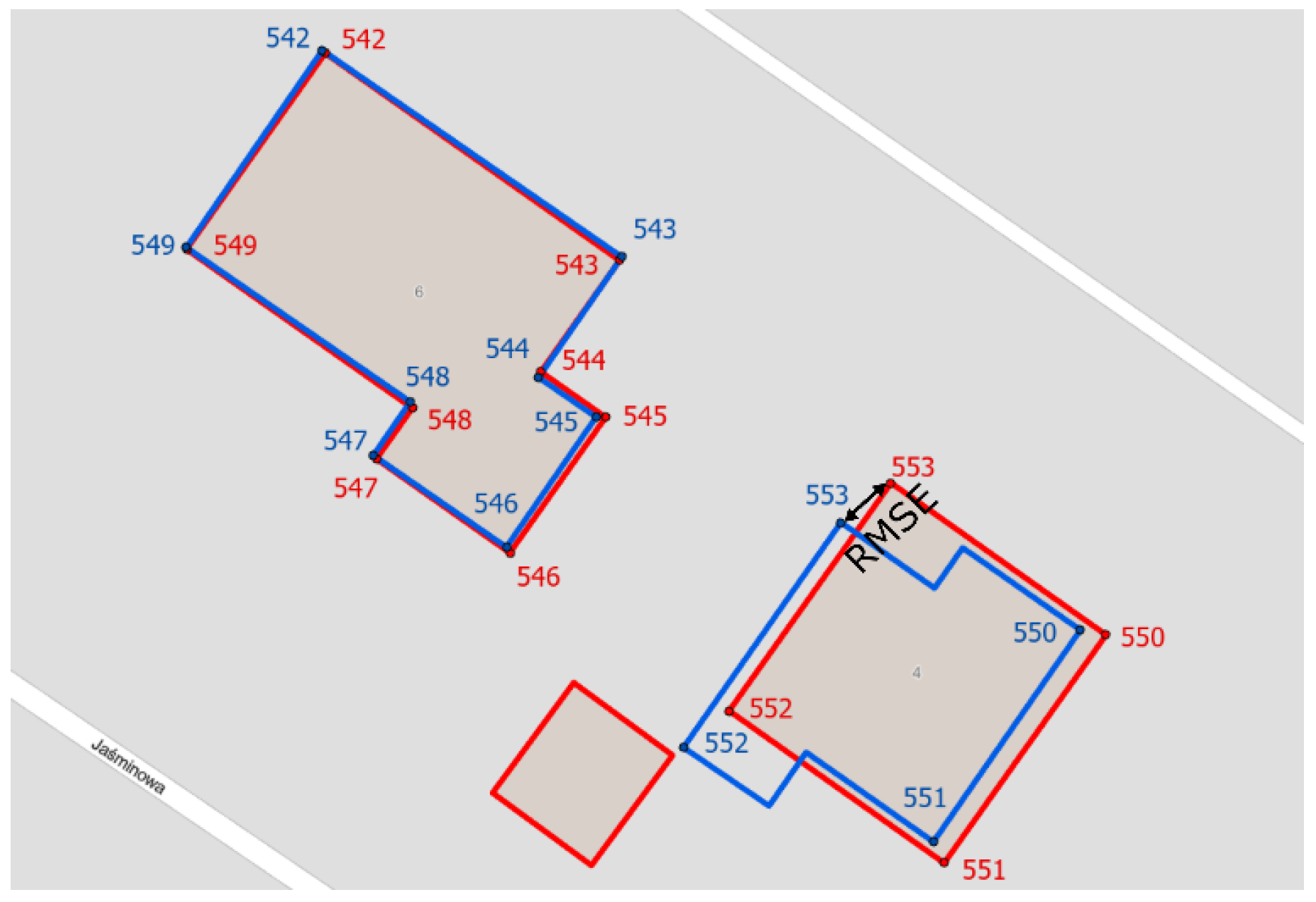
Using the methods described in
Section 3.2.1, the geometric accuracy of area objects was calculated separately for each of the five analysed counties. The obtained results of OSM area object geometric accuracy based on homologous points are presented in
Table 3.
According to the results presented in
Table 3, it is noticeable that the smallest values of RMSE were obtained in all the counties for building type objects. The smallest error was recorded in Sokólski County—1.36 m (295,224 homologous points). On the other hand, the lowest value of RMSE was obtained in the Ostrowski County—2.40 m (467,641 homological points).
Objects of the forest and surface water type obtained much higher values of RMSE in the analysed areas. The lowest values on a quite similar level were obtained for objects of forest type (from 5.35 m for Ostrowski to 5.99 m for Piaseczyński County). On the other hand, the values of RMSE for surface waters were slightly more diversified—from 3.52 m for the Sokólski County to 4.79 m for the Słupski County.
4.2. Geometric Accuracy of OSM Linear Objects
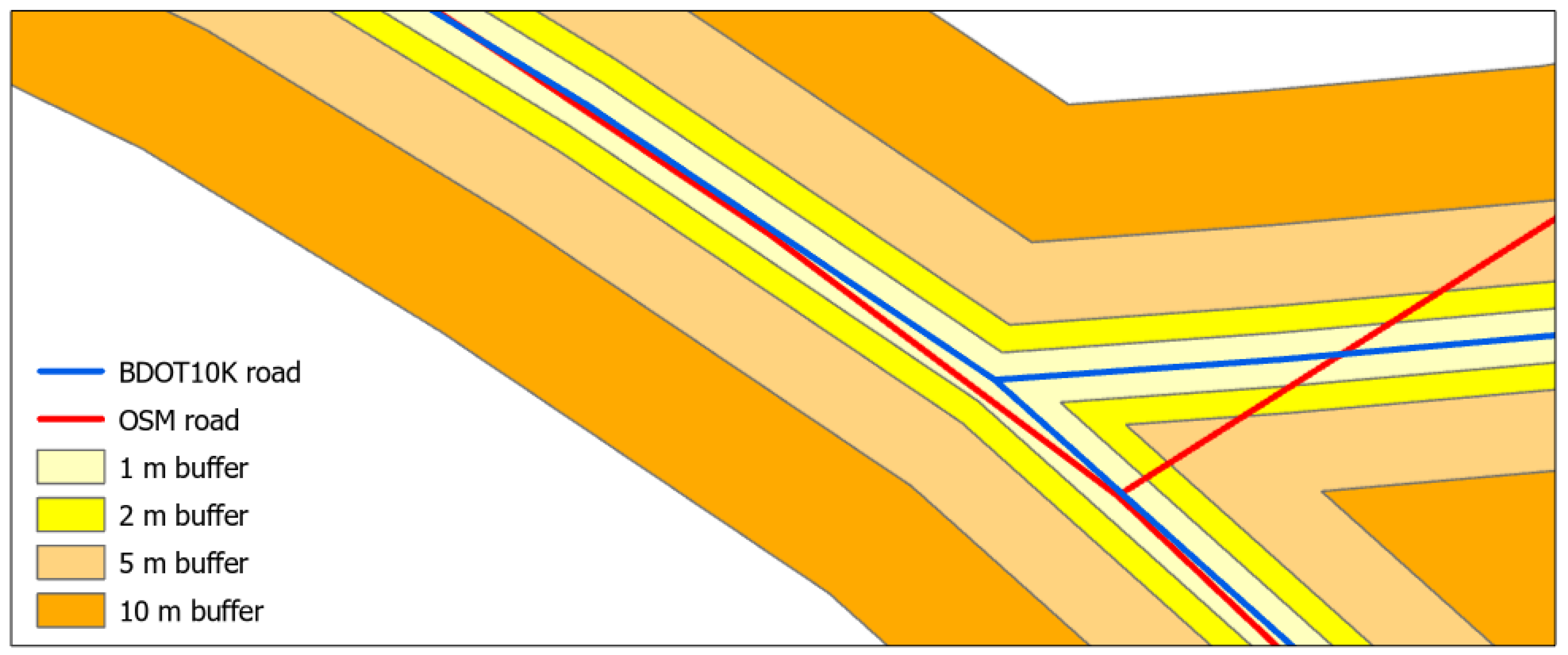
According to
Section 3.2.2, the accuracy of OSM linear objects’ locations was determined by creating buffer zones in relation to BDOT10k objects with widths of 1 m, 2 m, 5 m and 10 m. Then, the percentage of overlap of OSM data in relation to each buffer zone was determined. Linear land-cover objects (roads, railroads and river network) in all analysed counties were included in the analysis. The resulting analysed linear objects by county are shown in
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8.
According to the results presented in
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8, it can be seen that the geometric accuracy of linear objects varies significantly depending on the reference buffer width used. In case of the road network, the highest increase in the share of OSM data in the analysed buffer zones was recorded in Słupski county—from 14.3% for 1 m buffer width to 50% for 10 m buffer width. On the other hand, in the county of Piaseczyński for 1 m width of the buffer there was a significant share of the OSM data—48.5%. With increasing buffer width, the share of OSM data relative to BDOT10k increased up to 127.5% for 10 m buffer width. Increase in share of OSM data above 100% indicates data overabundance, i.e., the OSM database contains more data than BDOT10k. As far as the remaining counties (Sanocki, Sokólski and Ostrowski) are concerned, the share of OSM data in relation to BDOT10k was at a similar level with the increase in reference buffer zones, but in no case did it exceed 70%.
The analysis of the railroad network revealed that the situation is slightly different than in the case of the road network. The highest share of OSM data for the reference buffer width of 1 m was recorded in Sanocki county—62%. As the width of the buffer zones increased, the share of OSM data increased slightly—up to 93.7% for a 10 m wide reference buffer. For the Piaseczyński and Ostrowski Counties, the situation is very similar. The share of OSM data in individual buffer zones increases significantly with the increasing width of the reference buffer—from about 30% for 1 m width to over 113% for 10 m width. In the case of the Sokólski and Słupski Counties, the share of OSM data in relation to the intervals of the reference buffer zones is similar and does not exceed 90% in the case of the 10-m-wide buffer.
As for the river network, the share of OSM data in particular buffer zones is the smallest in comparison with the other analysed objects of the road and railroad network. The smallest share of OSM objects of the river network in the analysed buffers was recorded in the Ostrowski County—from 6% for the 1 m buffer to only 19.8% for the 10 m buffer. For Sanocki County, the share of OSM data in relation to BDOT10k data for the width of reference for a buffer of 1 m is the largest share from all analysed counties—32.5%. With the increase in the buffer width, this share increases to 57.3% for 10 m width of the reference buffer. On the other hand, in the Sokólski County, the share of OSM data in relation to BDOT10k reaches the highest value for the reference buffer of 10 m width—66.7%. In the case of Piaseczyński and Słupski Counties, the obtained values of the accuracy of the OSM data position in relation to the reference buffer zones are similar and amount from about 8% for the buffer zone of 1 m to about 42% for the buffer zone of 10 m width.
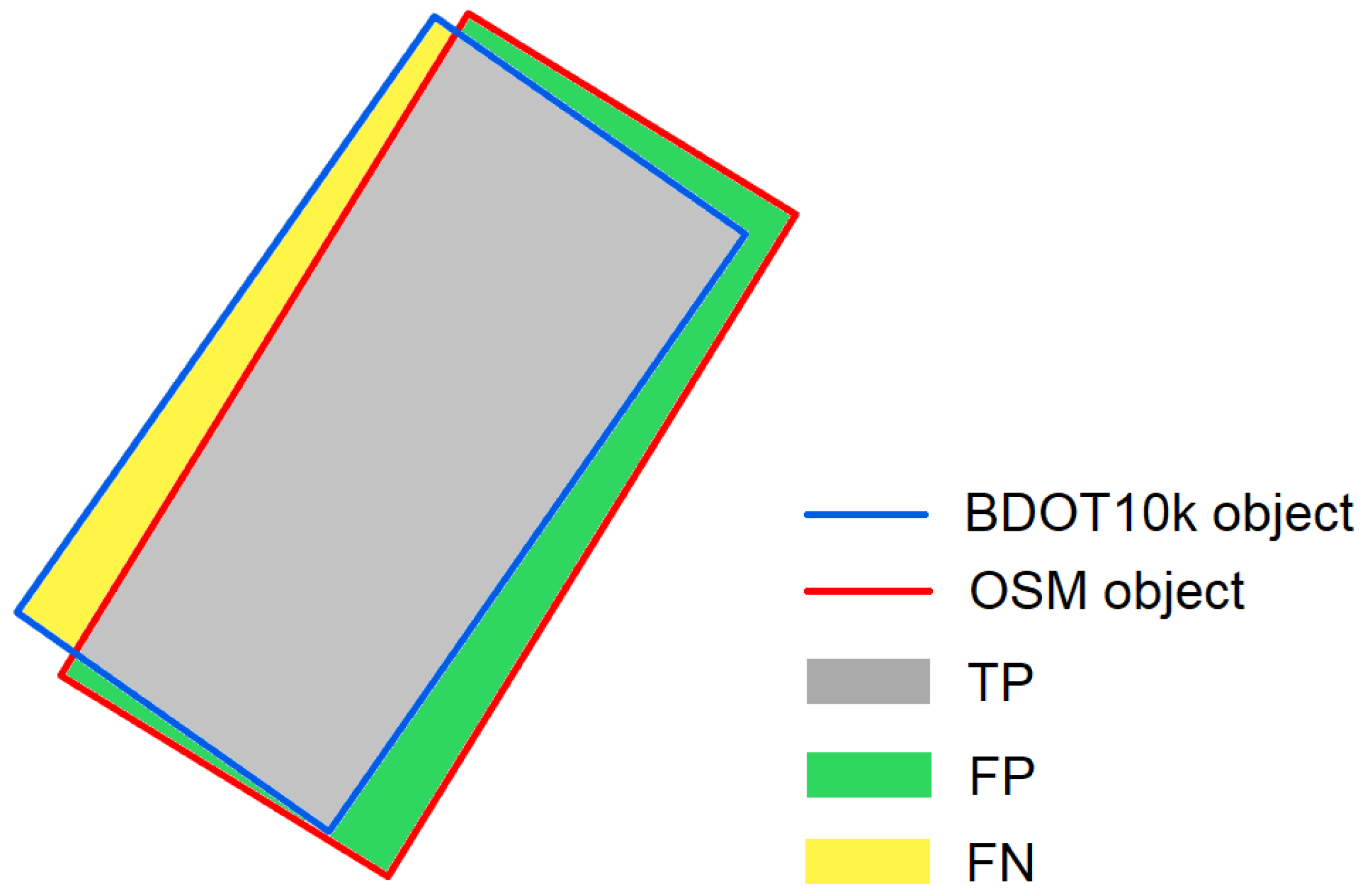
4.3. Completeness of OSM Area Objects
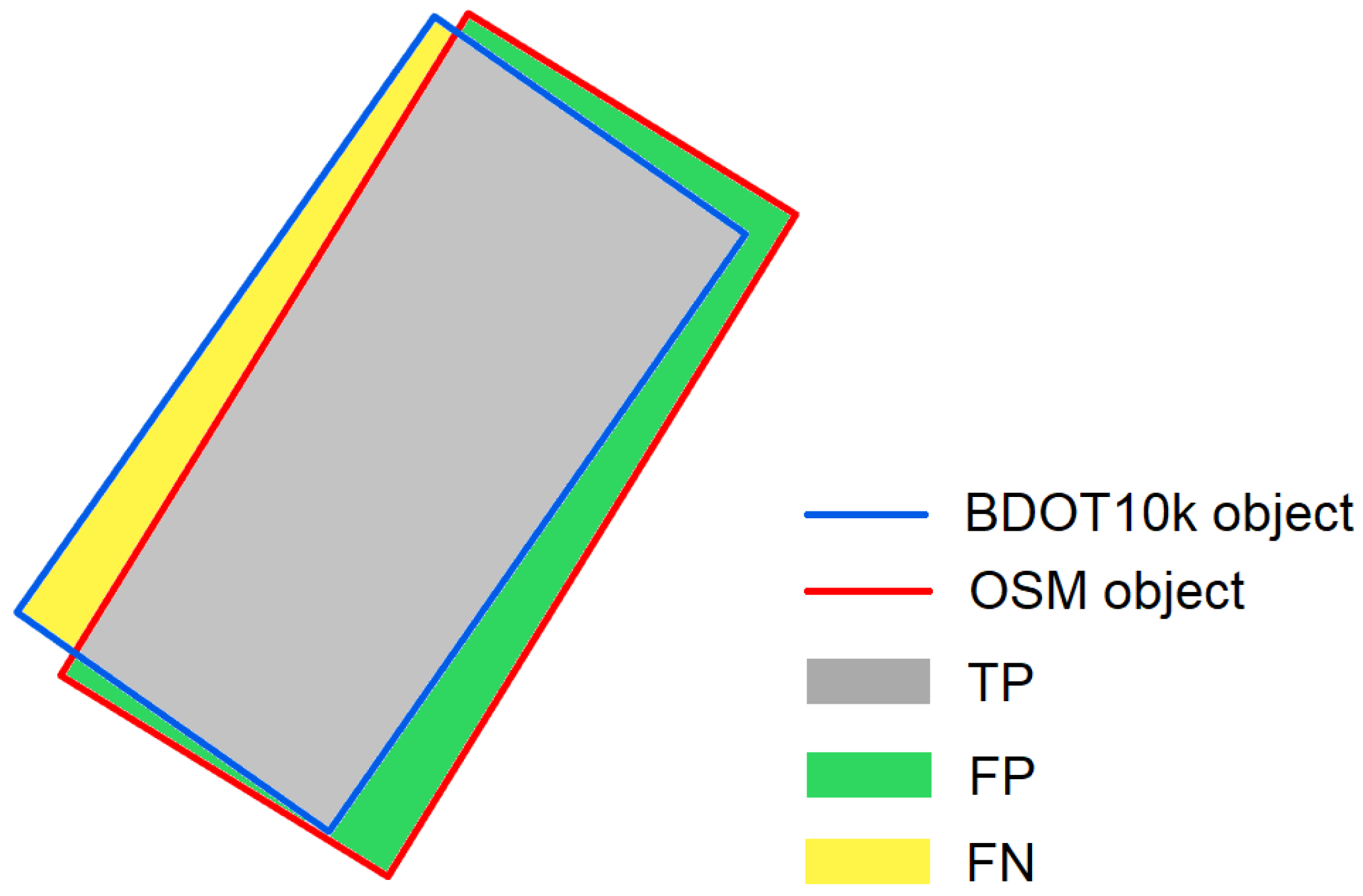
The methods described in
Section 3.2.3 were used to calculate the completeness of OSM area objects in individual cells of the hexagonal grid. The analysed area was divided into basic fields in the form of a hexagonal grid of 1 km
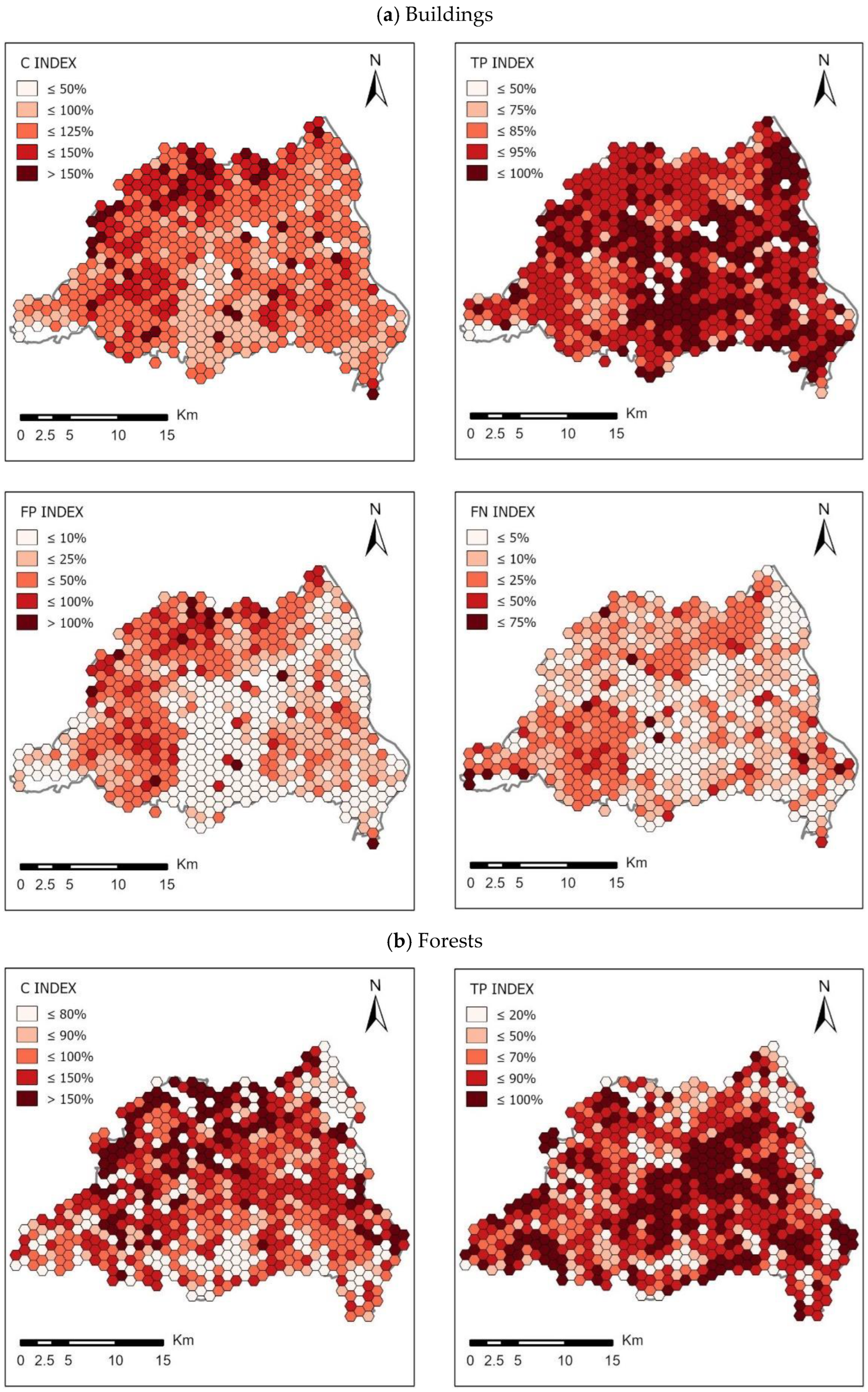
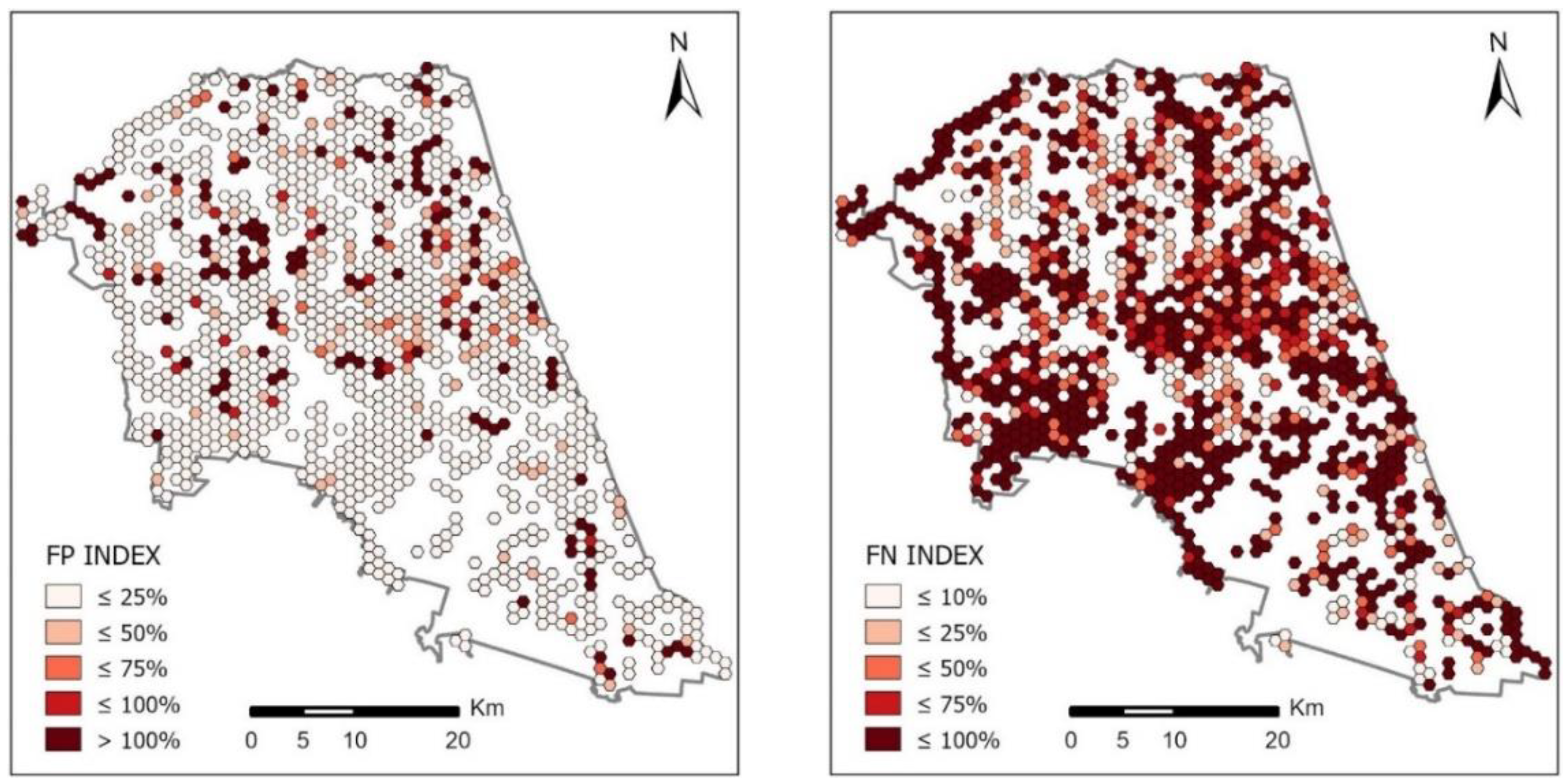
2. Finally, 60 thematic maps were developed visualizing the spatial distribution of C, TP, FP and FN indices in the analysed counties. Due to the large number of maps, the obtained thematic maps are presented for the two analysed counties, which represent the greatest diversity of the results. For Piaseczyński County (
Figure 8) the developed maps are presented in
Figure 9 and for Sokólski County (
Figure 10) the obtained maps are shown in
Figure 11.
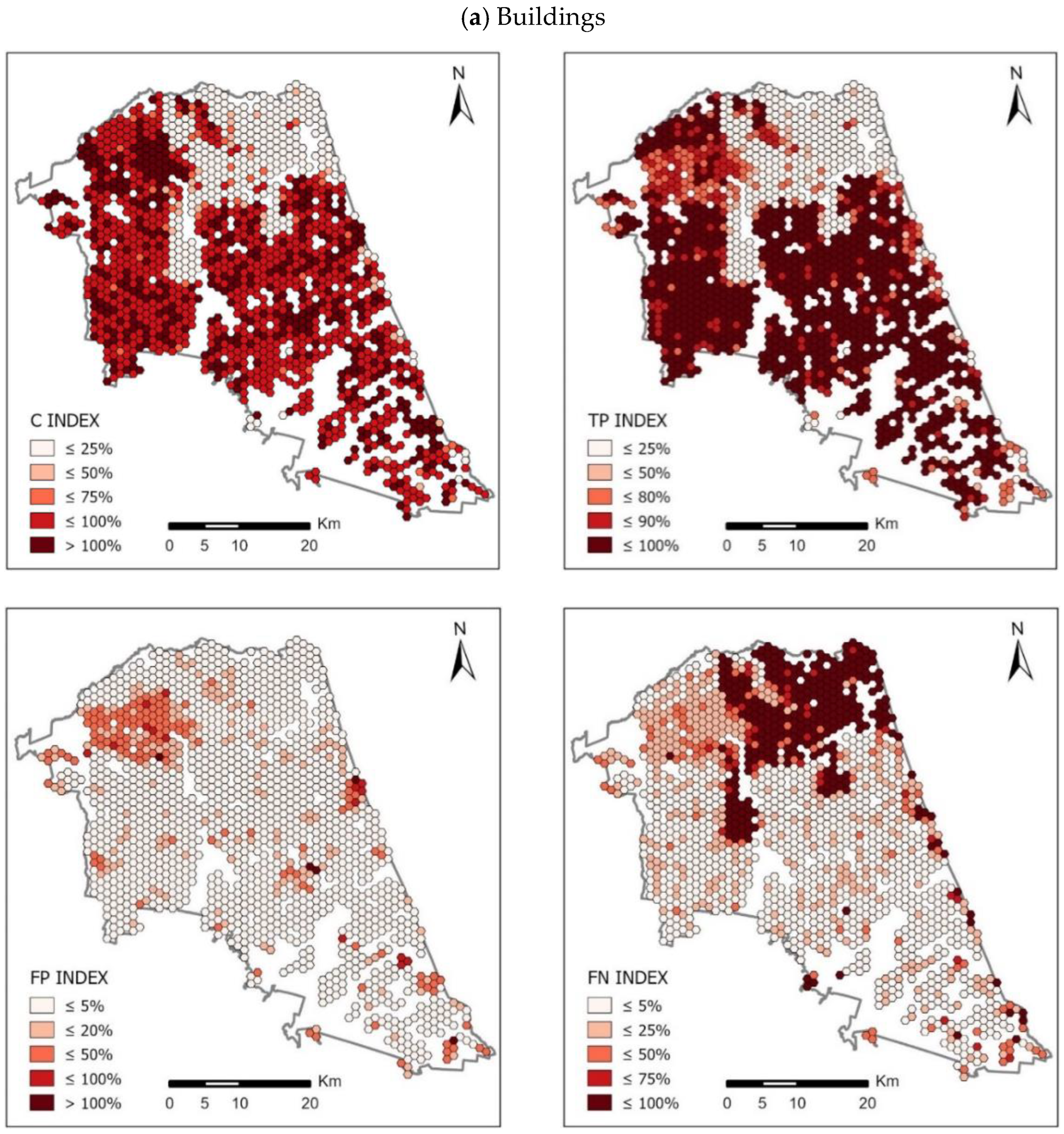
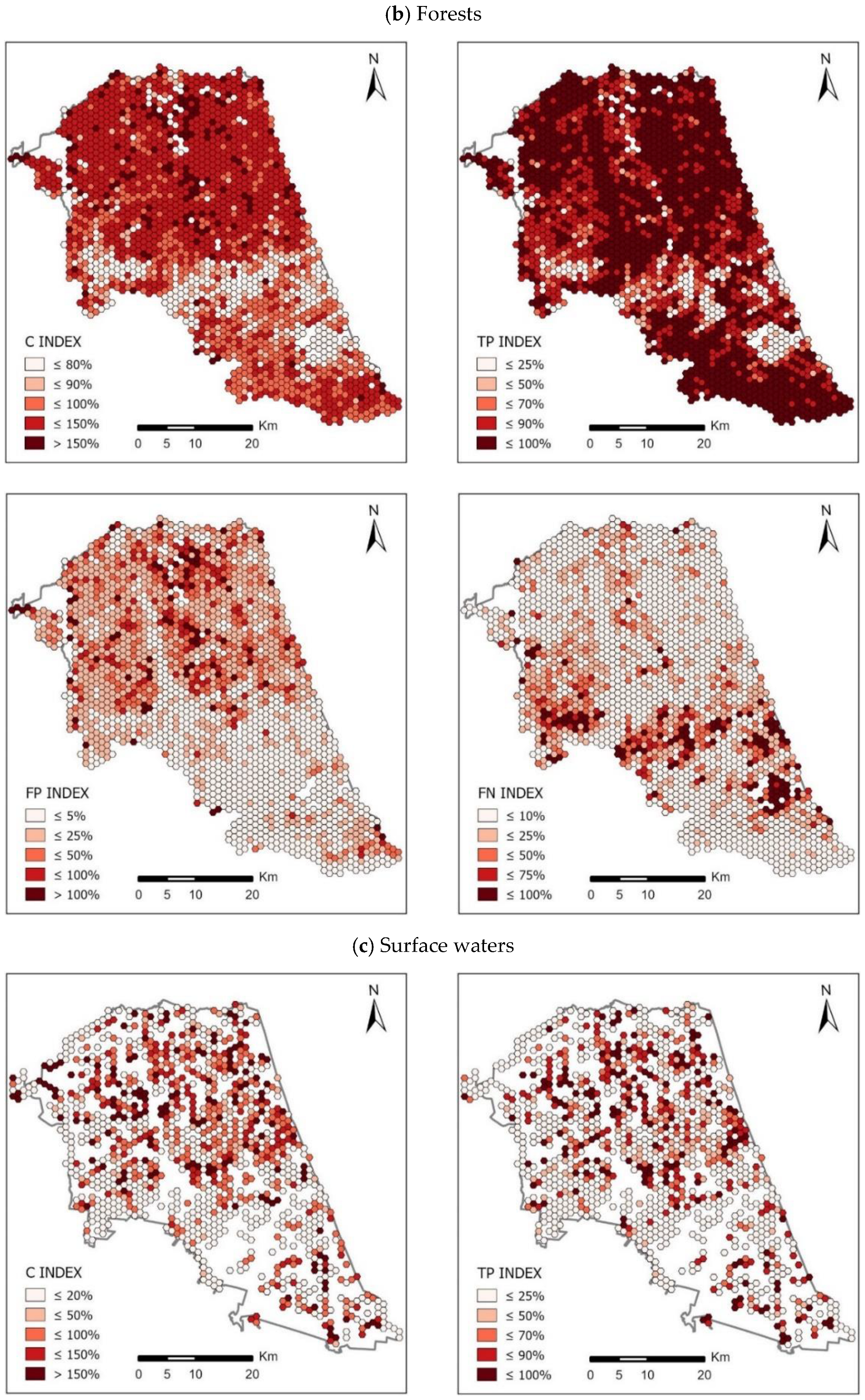
The set of maps presented in
Figure 9 and
Figure 11 shows the spatial distribution of the calculated indices of completeness of OSM area objects in comparison with the BDOT10k reference database in two counties: Piaseczyński and Sokólski. The ranges of values for each of the indicators were determined according to the Natural Breaks algorithm. Jenks Natural Breaks classification (or optimization) is a data classification method designed to optimize the distribution of a set of values into “natural” classes. The range of classes consists of elements with similar characteristics that form a “natural” group in the data set [
37].
This classification method seeks to minimize the average deviation from the class mean while maximizing the deviation from the means of the other groups. This method reduces the variance within classes and maximizes the variance between classes.
The mean values of OSM area objects’ completeness indices for all counties analysed with respect to the base field of the hexagonal grid are presented below in
Table 9.
The spatial distribution of the completeness index C for buildings in the analysed counties reaches the highest values in urbanized and densely built-up areas. This index in highly urbanized areas in all cases reaches values above 100%. The highest average values of index C were noted in Piaseczyński County—on average, the completeness index C here equals 115%, and in some grid cells it reaches values above 400%. The lowest value of the C indicator for buildings was observed in Słupski County—about 67%. The total area of the TP index for buildings (i.e., buildings present in both BDOT10k and OSM datasets) is approximately 89% of the total area of BDOT10k buildings on average in Piaseczyński County. The highest value of the TP index for buildings was recorded in Sanocki county (92.3%). In the Słupski County, on the other hand, this index averaged 53%—the lowest value in all the analysed counties. In all cases, the highest TP values were achieved in urban areas, where high values of index C (close to 100%) were obtained. As for the FN indicator (i.e., buildings mapped in BDOT10k but not in the OSM data set), the highest value was obtained in Słupski County—on average 47% of the total BDOT10k area, while the lowest value was obtained in Sanocki County: 7% of the total BDOT10k area. On the other hand, the total FP area (i.e., buildings mapped in OSM but not in the BDOT10k data set) was on average 26% of the total BDOT10k area in Piaseczyński County (the highest value) and 5% in Sokólski County (the lowest).
In the case of forests, the highest C index was recorded in Sokólski County (180.6%). An equally high value of this indicator was calculated for Piaseczyński County: 171.2%, whereas the lowest C index was found in Ostrowski county: 78.4%. In all analysed counties the TP index was at a similar level, but the highest value was achieved by Sokólski County (82.8%) and the lowest by Piaseczyński County (69.5%). The FP index reached the highest value for the Piaseczyński County—102.3%. Much lower values were achieved in the three analysed counties: Słupski, Sanocki and Ostrowski (7.4%, 6.4% and 5.6%, respectively). The highest values of FN were obtained for three counties—Piaseczyński (30.4%), Słupski (27.3%) and Ostrowski (27.1%). On the other hand, Sokólski County had the lowest FN: 16.4%.
The completeness index C for surface waters obtained the highest value for the Sokólski County: 154.7%. On the other hand, the lowest value was obtained in Sanocki County (41.7%) and Ostrowski County (35.2%). The TP index obtained the highest value for Piaseczyński County (42.7%), while the lowest for Ostrów Wielkopolski County (34.6%). The value of the FP index varied significantly between the analysed counties—the highest value was achieved by Sokólski County (122.4%), while the lowest by Sanocki County (11.2%) and Ostrowski County (10.6%). The FN index for the analysed counties was at a similar level, but the highest value was calculated for Ostrowski County—75.9%, and the lowest for Piaseczyński County: 57.3%.
4.4. Completeness of OSM Linear Objects
As far as linear objects are concerned, OSM data completeness was assessed by comparing the length of OSM data to the length of corresponding objects in the BDOT10k reference database. The results are presented as a percentage in
Table 10.
According to the results presented in
Table 10, it can be seen that the completeness of OSM linear objects varies considerably by objects type and by the county analysed. As far as roads are concerned, the highest completeness rate was found in Piaseczyński County (155.6%).
The same applies to railroad OSM facilities, for which the highest completeness rate was again found in Piaseczyński County: 123.2%. On the other hand, the lowest index was noted in Słupski County (89.2%). The remaining counties achieved values ranging from 89.5% to 115.9%.
The highest completeness rate for river-type OSM objects was obtained for Sokólski County: 75.7%. On the other hand, the drastically lowest value was obtained for Ostrowski County—only 24.6%. For the remaining counties the obtained index of completeness was quite similar—from 57.2% to 66.8%.
4.5. Semantic and Attribute Accuracy in OSM Database
Tests of attribute accuracy of OSM were performed by analysing the number of objects in OSM database and by checking the degree of information entered by the user concerning particular attributes of a given object. The analysis was performed for linear and area objects in all counties. The attribute to be verified was the NAME key. Additionally, for buildings, the TYPE attribute was also evaluated, denoting information about the type of a given building. All values for buildings other than “yes”, indicating a specific building type and entered values for the amenity key, were included in the analysis (see
Table 11).
According to the results presented in
Table 11, it can be seen that the degree of attribute accuracy of OSM database is very low. The highest degree of compatibility was achieved for rivers in Ostrowski county (58.7%) for the attribute “NAME”. A rate of 0% was recorded for railroads in the Sokólski, Słupski and Ostrowski counties. As for roads, the highest degree of attribute compatibility of OSM database was achieved in Piaseczyński County (39%), and the lowest in Sokólski County (8.7%). For rivers, the relatively highest results were achieved in Ostrowski County, and the lowest ones were recorded in Sanocki County: 17%. For railroads, the highest rate was recorded in Piaseczyński County: 15%. When analysing the attribute compatibility of buildings in OSM, the information degree of two attributes “NAME” and “TYPE” was examined. For the “NAME” attribute, the highest rate was achieved in Słupski County (1.2%), and the lowest rate was achieved in Sokólski County (0.2%). The situation was similar for the “TYPE” attribute: the highest index was recorded for the Słupski county (28%), and the lowest for Sokólski county (2.0%). In the case of rivers, the highest compatibility index was indicated in Ostrowski County (11.7%), and the lowest in Sokólski County (0%). In the case of forests, the attribute compatibility index remained in all counties at a fairly similar level—about 1%, but it reached the lowest in Sokólski County (0%) and Słupski County (1%).
5. Discussion
In the conducted research, the geometric accuracy, completeness and semantic and attribute accuracy of OSM linear and area objects, representing the main land-cover elements, i.e., buildings, forests, surface water, transportation network and water network, were analysed.
5.1. Geometric Accuracy of OSM Area Objects
The analysis of the geometric accuracy of area objects revealed that the highest accuracy of location was achieved by buildings—the average error of RMSE in this group was 1.92 m. The best results were achieved for counties with a high level of urbanization. In case of the Piaseczyński administrative district the achieved accuracy of RMSE of homological points in comparison with other results was not the highest, but it should be emphasized that the number of investigated pairs of homological points in this county was exceptionally big—even three times bigger than in other counties, which might have influenced the obtained results. The lowest results of accuracy of OSM surface objects’ position were achieved for forests: on average the RMSE error was 5.65 m.
5.2. Geometric Accuracy of OSM Linear Objects
Analysing the location of linear objects, it was noted that the highest accuracies were achieved for such objects as roads and railways. As the width of the buffer zone increased from 1 to 10 m, the share of OSM objects in the given buffer also increased significantly. The highest accuracy along with the highest share of objects was recorded in Piaseczyński County, which is characterised by a dense and developed road network, while the lowest accuracy was recorded in Sanocki County, with agricultural and forest structure, where the road network is poorly developed. Quite high accuracy was also noted for railroads: as the buffer zone increased up to 10 m in the analysed counties, the share of railroads oscillated around 100%. The lowest results were obtained for the river network: from 6% for 1 m buffer (Ostrowski County) to maximum 67% for 10 m buffer (Sokólski County).
5.3. Completeness of OSM Area Objects
As far as spatial data completeness analysis is concerned, the results obtained were quite diverse and depended on the type of object and analysed county. For buildings, the highest OSM data completeness values were obtained in urbanized areas of the studied counties (cities and built-up areas). The lowest completeness values were found in the suburbs of the counties and in agricultural areas. For buildings in built-up areas, over-completeness was often recorded, i.e., the number of OSM buildings significantly exceeded the number of BDOT10k buildings. Additionally, the calculated TP index, showing the degree of overlap between OSM and BDOT10k objects, reached the highest values for areas, with the degree of completeness oscillating around 100%. The FP index, which informs about OSM surface objects that do not exist in the BDOT10k data set, also achieved the highest values for highly urbanized areas, which resulted directly from the high over-completeness of OSM data. Finally, the highest values of the FN index were achieved for areas where the degree of data completeness was the lowest. In these cells, the majority were objects that were not present in the OSM database, although they existed in the BDOT10k database.
5.4. Completeness of OSM Linear Objects
The analysis of the degree of completeness of OSM linear objects in relation to the BDOT10k reference database for individual counties revealed that the transport network in most of the studied counties achieved the highest results, including over-completeness (numerically, the OSM base exceeds the BDOT10k base) for counties with a high degree of urbanization and a developed transport network (Piaseczyński and Ostrowski Counties). In the case of the river network, the lowest completeness index (up to 75.7%) was recorded in the Sokólski County.
5.5. Semantic and Attribute Accuracy in the OSM Database
The average attribute accuracy index obtained for OSM linear and surface objects was only 11.7%. The highest accuracy values were obtained for road network, rivers and buildings in developed counties that were also popular among users: Piaseczno, Ostrowski and the coastal county of Słupsk. The lowest indices were obtained for railroads, forests and surface waters. The quantitative results show that the main tag of each type of analysed OSM objects is mostly informed, while the secondary attributes are rarely informed. The obtained results indicate the need to complete information about most of the objects in the OSM database—according to the analyses performed, there is no information about the name and type of most of the OSM facilities. Lack of information value concerning buildings and roads may be a serious obstacle in using the OSM database for many spatial analyses.
5.6. Comparison of OSM and BDOT10k Data with Orthophotomap
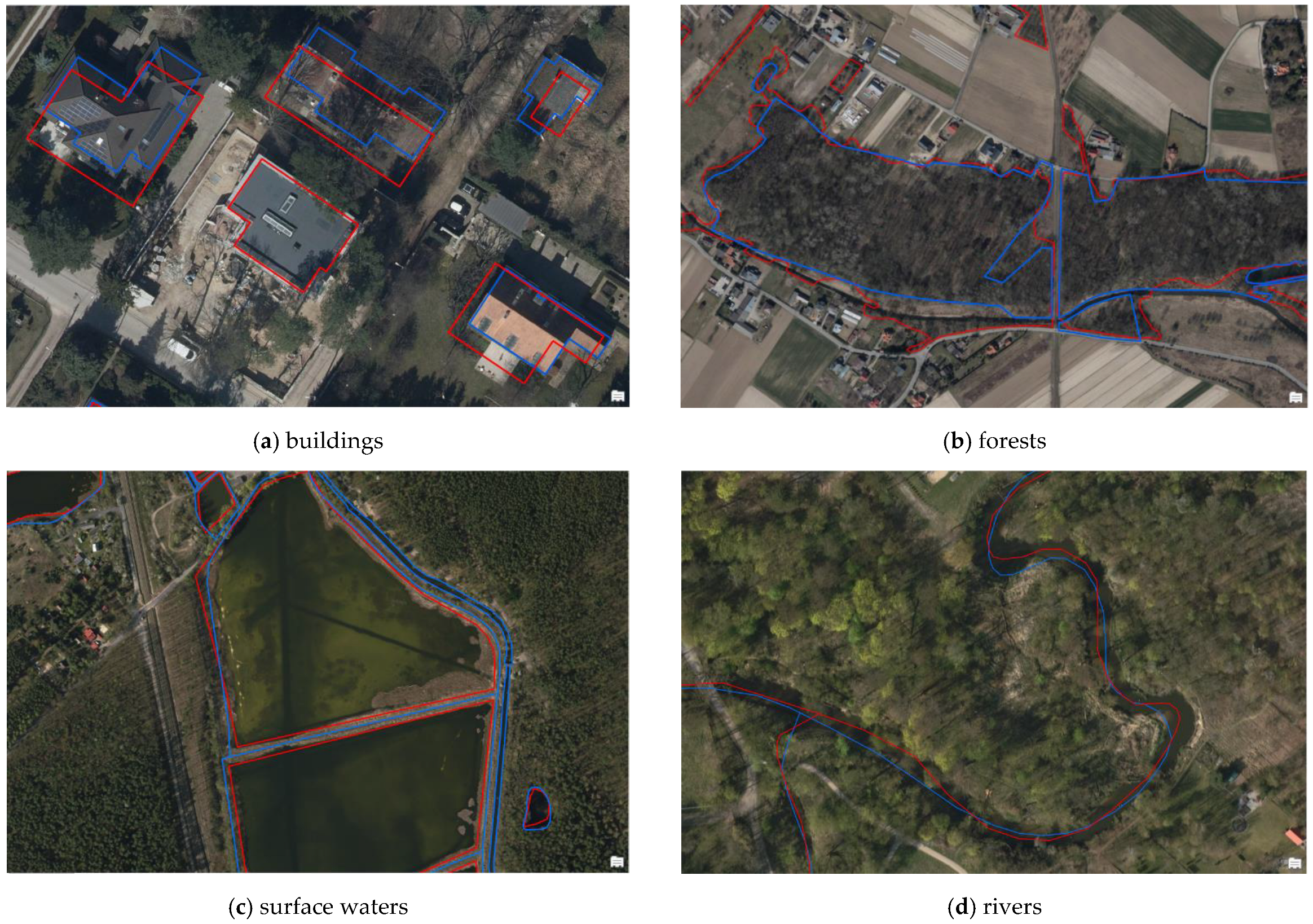
Another element of the OSM data quality assessment was the comparison of objects from the OSM and BDOT10k databases with the actual terrain situation visible on orthophotomap updated to 2020 from Geoportal service. For this purpose, about 20 objects of the analysed geometric types presented on the orthophotomap were selected in random places of each county. These objects were then compared with corresponding objects in the OSM and BDOT10k databases. An example of the objects identified in the OSM and BDOT10k databases on the background of an orthophotomap is presented in
Figure 12 below.
As a result of the analysis, it was found that the greatest differences were noted for buildings (outline shift in relation to the analysed databases) and forests (defining the contour of the forest was subject to the interpretation skills of the OSM and BDOT10k database editors). Additionally, it was found that the large over-completion of OSM database objects is mainly due to the entry of a given building in the OSM database and its absence in the BDOT10k database, which is updated relatively less frequently than the OSM database. Such cases occurred in single cells of the analysed hexagonal network, which led directly to a high completeness rate. In addition, it was observed that the location and outline of OSM buildings is more generalized than BDOT10k objects, which retain considerable detail of the building shape. However, as far as forests and surface waters are concerned, the OSM database retains a higher level of contour detail than the BDOT10k database.
The obtained differences between the quality of OSM data in comparison with the BDOT10k reference database are certainly due to several reasons. One of them is the discrepancies in the source images and their shift in relation to reality. Many companies and institutions provide imagery to help create OpenStreetMap. In Poland, it is possible to use the data available on the official Geoportal service. They are correctly calibrated for the territory of Poland. These images are used when updating BDOT10k. The available aerial photos or satellite imagery from sources other than Geoportal are in a large proportion of cases shifted compared with reality. In this case, the person editing OSM should suggest GPS traces. The BDOT10k database is regularly updated, while the objects in the OSM database are introduced by users on an ongoing basis. Updating and verification of BDOT10k data sets for a selected area (usually a poviat) is a long-term process subject to strict official regulations. For this reason, there are visible differences in the quality of OSM data, which make it over-completed in relation to the BDOT10k and leads to differences in the mutual spatial position (FN and FP Indices). It should also be emphasized that in the BDOT10k database, the classification of objects is strictly defined by legal regulations corresponding to the detail on a scale of 1:10,000 [
31]. There are no such regulations in the assessment of OSM objects, which leads to a fairly large content for users to operate on. An example would be building mapping. In the BDOT10k database, buildings are defined as “construction objects permanently connected with the ground, having foundations separated from the space by means of building partitions (i.e., walls and covers), i.e., enclosed with walls on all sides and covered with a roof, with or without a basement with built-in house connections”. In the case of the OSM base, the building is the outline of a single building created for each complex or “block” that may be associated with one single-family house or more complex buildings. In addition, the outlines can be very simplified outlines, or very closely match the shape of the building. In the case of introducing a building to OSM from satellite imagery, one should try to recognize the geometry of the building next to the ground and not the course of the roof. The OSM mapper community in Poland has a total of over 28,000 members, of which an average of more than 200 members are constantly active on a daily basis (data from December 2021) [
38]. Special activity of people editing OSM is visible in the central part of Poland (Piaseczyński county) and the eastern part (Sokólski and Sanocki counties). The remaining parts of Poland, which include the Ostrowski and Słupski counties, show minimal or no activity in recent months [
39]. Such a heterogeneous structure of the OSM community and its differentiation between counties affects the quality of OSM data and its level of topicality.
Some people editing the OSM database in Poland independently import objects from selected state registers (e.g., BDOT10k, the Register of Places, Streets and Addresses). According to available data these are mainly address points and outlines of buildings [
40]. The highest rate of imported objects to OSM database concerns mainly the central part of Poland. For the analysed areas address points were imported, which is not included in the OSM data quality analysis. In the case of data on buildings and land-cover elements, such an import was not made in the analysed counties [
40].
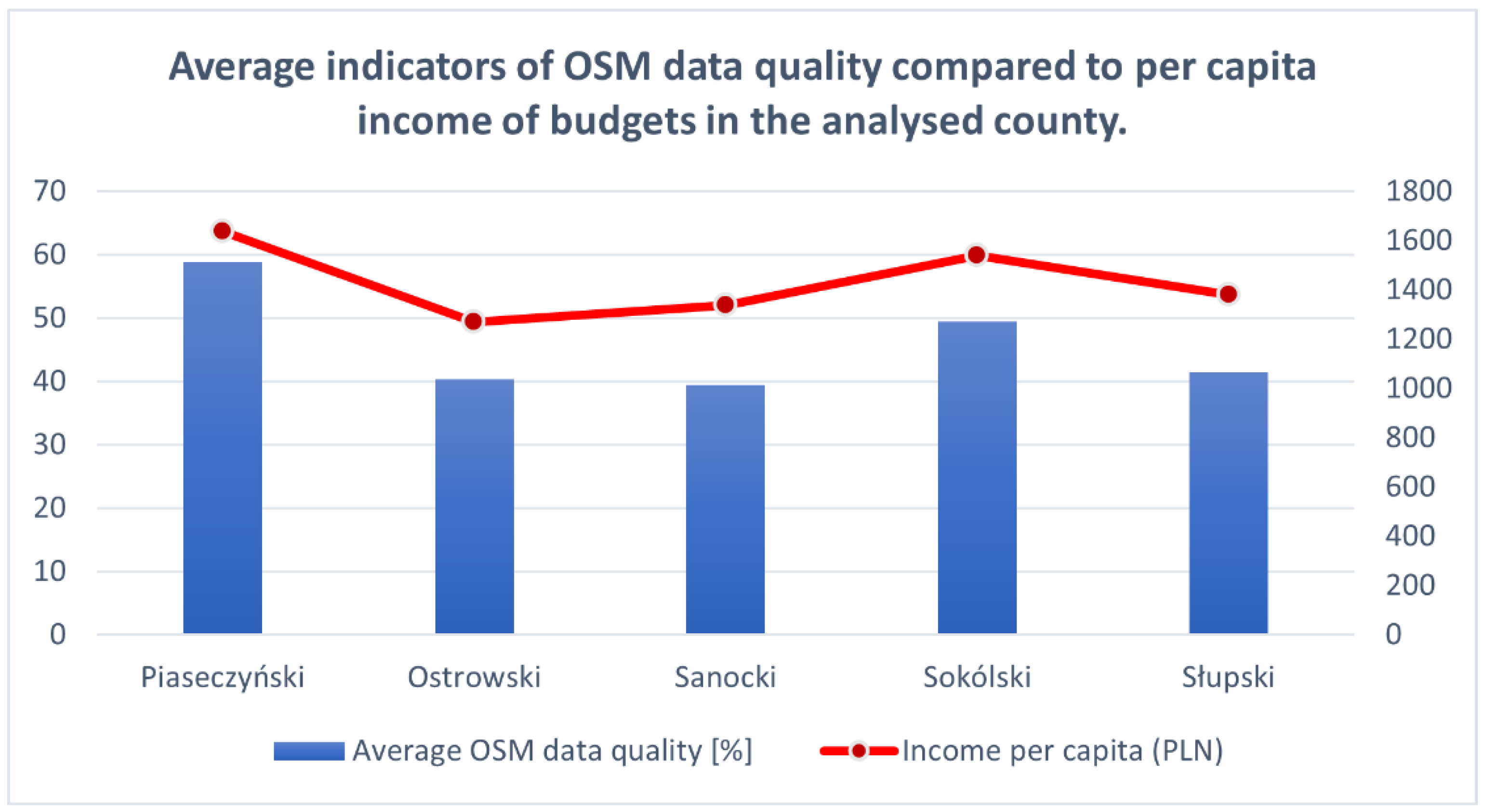
5.7. OSM Data Quality in Relation to Economic Development
From the point of view of economics, one of the main tasks of local government is the equitable distribution of public goods and the creation of conditions for socio-economic development, which promotes the implementation of the objectives of Agenda 2030. Therefore, in the next step, the average indicators of the quality of OSM data in each county were recalculated as the arithmetic mean for the obtained values and compared with the income per capita in the county in 2020 [
29]. The obtained results are presented in
Table 12.
The income of county budgets consists of: (1) own income, (2) subsidies, (3) general subvention and (4) funds for subsidizing tasks. The calculated Pearson correlation coefficient between the average indicator of data quality and income per capita in the county was 0.96. This means that the wealthier the county, the higher the indicator of OSM data quality. A graph of the analysed values is shown in
Figure 13.
Indeed, counties with high per capita income showed the highest quality OSM data. This is probably because there are not only many more OSM objects in relatively developed regions of Poland, but also more users with high incomes and better Internet access.
OpenStreetMap can be a true data source for measuring SDG metrics that require geographic data [
41]. Taking into account the demonstrated data quality, OpenStreetMap objects can be used to measure sustainable development goals, which mainly include goal 11 (make cities and human settlements inclusive, safe, resilient and sustainable) and goal 15 (protect, restore and promote sustainable use of terrestrial ecosystems, sustainably manage forests, combat desertification and halt and reverse land degradation and biodiversity loss). For example, the conducted analyses show a relatively good quality of buildings for all analysed poviats, which is taken into account by the SDG Indicator 11.7.1—the average share of built-up area in cities that is open to public use.
6. Conclusions
The presented results of the analysis of the comprehensive assessment of the quality of OSM data in comparison with the official reference database of spatial data BDOT10k clearly demonstrate that the obtained results largely depend on the geometric type of objects analysed and the characteristics of the test counties, including their economic development.
The obtained results confirm that the best quality indicators of OSM data were achieved for objects of quite easily recognizable and interpretable characteristics and location, i.e., buildings and transport network. On the other hand, the lowest values were achieved for objects for which defining the range and type may be a problem for a non-professional user of spatial databases—mainly forests and water network. In addition, the nature of the studied areas influenced the obtained results. The best results of spatial OSM data quality were obtained for highly urbanized areas with developed infrastructure and high per capita income ratio. The degree of coverage of line and area objects of OSM with BDOT10k amounted to 82% in the Piaseczyński county and 71.3% in the Sokólski county, respectively. The worst was in urban outskirts and low urbanized areas with low-income ratio. The obtained results show that the lowest average value of coverage of linear and surface objects’ OSM in relation to the reference database BDOT10k was obtained in the counties: Słupski 55.4%, Sanocki 55.2% and Ostrowski 51%. This is mainly due to the interest of users in a given area and the frequency of introducing new OSM spatial objects. It is also worth noting that in highly urbanized counties there was often an over-completion of data (the number of OSM data significantly exceeded the number of BDOT10k data). In less urbanized areas that are less “popular” among OSM users, there are gaps in the OSM database and “white spots” resulting from the lack of objects introduced there.
The results received from the OSM data quality analysis indicate that OSM data may provide strong support for other spatial data, including official and state data. Additionally, OSM data are mapped by users and appear in the OSM database on an ongoing basis. In the case of the BDOT10k data, the Head Office of Geodesy and Cartography, by virtue of legal provisions, conducts coordination works aimed at maintaining homogeneity, harmonization and consistency of the BDOT10k data in the entire country through cooperation with public administration bodies and voivodship marshals with respect to developing and maintaining up-to-date data. Updating the BDOT10k is a time-consuming process that involves many additional units and institutions. Due to the voluntary nature of the OSM data and the work of the database users, it should be emphasized that the database requires systematic control and supplementation with new objects and information.
Voluntary geographic information (VGI), or geospatial content generated by non-professionals who use mapping systems available on the Internet, provides opportunities for government agencies at all levels to enrich their geospatial databases. Moreover, in some cases, “eyes on the ground” VGIs have an advantage over more expensive accuracy tests conducted by official agencies because the authors have unique local knowledge. OSM’s crowdsourced geospatial data helps fill micro-level data gaps and provides insight into SDG progress in a more real-time manner than is possible through annual or biennial surveys and periodic censuses. OpenStreetMap is currently the largest geospatial dataset under an open license. As OSM is increasingly used in various applications, it is important to control the quality of OSM data. OSM service provides its own OSM data quality control tools. Often the tools accomplish this by providing a list of errors in the data that mappers can then fix with editing tools. However, it is an internal tool that may validate data incorrectly. Therefore, external data quality control is important. Taking into account the received discrepancies, it would be recommended to introduce a control system in areas with available reference data of higher accuracy. Consider the OSM data quality indices presented in the article, in future studies the authors plan to extend the OSM data quality analysis with point objects for the entire territory of Poland and to compare these results with the data quality in other areas of Europe.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}