Abstract
In the past couple of years, the world has come to realize the importance of renewable sources of energy and the disadvantages of excessive use of fossil fuels. Numerous studies have been conducted to implicate the benefits of artificial intelligence in areas of green energy production. Artificial intelligence (AI) and machine learning algorithms are believed to be the driving forces behind the fourth industrial revolution and possess capabilities for interpreting non-linear relationships that exist in complex problems. Sustainable biofuels are derived from renewable resources such as plants, crops, and waste materials other than food crops. Unlike traditional fossil fuels such as coal and oil, biofuels are considered to be more sustainable and environmentally friendly. The work discusses the transesterification of jatropha oil into biodiesel using KOH and NaOH as alkaline catalysts. This research aims to examine and optimize the nonlinear relationship between transesterification process parameters (molar ratio, temperature, reaction time, and catalyst concentration) and biodiesel properties. The methodology employed in this study utilizes AI and machine learning algorithms to predict biodiesel properties and improve the yield and quality of biodiesel. Deep neural networks, linear regression, polynomial regression, and K-nearest neighbors are the algorithms implemented for prediction purposes. The research comprehensively examines the impact of individual transesterification process parameters on biodiesel properties, including yield, viscosity, and density. Furthermore, this research introduces the use of genetic algorithms for optimizing biodiesel production. The genetic algorithm (GA) generates optimal values for transesterification process parameters based on the desired biodiesel properties, such as yield, viscosity, and density. The results section presents the transesterification process parameters required for obtaining 72%, 85%, and 98% biodiesel yields. By leveraging AI and machine learning, this research aims to enhance the efficiency and sustainability of biodiesel production processes.
1. Introduction
The rise in economic progress for countries across the world has increased their need for energy, the majority of which is sourced from scarce fossil fuels such as coal, natural gas, and petroleum. This, together with increasing environmental concern and strict environmental rules, has prompted a plethora of scientists to investigate renewable feedstock as a source of alternative fuels [1,2]. Among various options, biodiesel is becoming an increasingly popular choice because of its environmental benefits. Biodiesel is a clean-burning alternative fuel that can be synthesized from indigenous resources [3,4]. Basically, it is a methyl ester with long-chain fatty acids generated from vegetable oil and animal fats. When compared to petroleum-based diesel, it has several benefits, such as a reduction of exhaust emissions, viz., less carbon monoxide, sulfur oxides, nitrogen hydride, particulate matter, unburned hydrocarbons during combustion, improved biodegradability, non-toxicity, inherent lubricity, a higher flash point, and domestic origin. Therefore, it is advantageous to utilize biodiesel as an alternative fuel to replace conventional petroleum-based fuels [5]. Biodiesel can be directly used in the existing diesel engine, either in neat or blended form. The alternative fuel must be technically, ecologically, and commercially viable. These conditions make triglycerides and their derivatives viable diesel fuel replacements.
The major problems with triglycerides being used as diesel fuel replacements are high viscosity, poor volatility, and polyunsaturation. These problems, however, can be mitigated by developing vegetable oil derivatives through different processes such as dilution, microemulsion, pyrolysis, and transesterification. Among various methods, transesterification is the most prevalent technique for making biodiesel, where triglycerides react with alcohol in the presence of a catalyst to produce biodiesel and glycerol. The process depends on the free fatty acid (FFA) content of the feedstock. If the FFA content of the oil is less than 1 wt % FFA, an alkali-catalyzed method is used. However, for oil containing a higher level of FFA, a two-step transesterification process is suggested that involves acid esterification followed by alkali transesterification. This present study focuses on the transesterification of Jatropha Curcas with FFA less than 1% using potassium hydroxide (KOH) as a catalyst and the implementation of a DNN model along with multiple machine learning models over process parameters of the transesterification process for predicting multiple characteristics of the biodiesel produced.
Machine learning is a branch of AI that works on the concept of self-learning and enables computers to do so without explicit programming [6,7]. With the assistance of adequate training data, machine learning algorithms can detect patterns, learn from them, and make conclusive predictions [8]. Similar to machine learning algorithms, the application of neural networks for predictions is a subset of AI and is inspired by the workings of the human brain. Neural networks are widely applicable for solving supervised learning and reinforcement learning-related problems. A deep neural network (DNN) is a sophisticated version of an artificial neural network (ANN) comprising multiple densely connected hidden layers between the input and output layers [9,10]. Multiple studies have suggested the superiority of DNN over shallow ANN in modeling complex nonlinear relationships. A DNN comprises several connected nodes, also known as neurons. The neurons receive input signals and trigger computational processes, which subsequently generate outputs that act as inputs for other neurons in the subsequent layers of the neural network.
The richness of the data and learning time are directly proportional to the efficiency of a DNN, with certain caveats that are introduced with different problem areas. The reason for selecting a DNN or machine learning algorithm is to identify complex relationships that exist between different input variables; the relationships may be nonlinear or polynomial in nature. The ability of the model to understand the existing relationships will determine its efficiency in predicting outcomes. Similar to AI and machine learning algorithms, the use of genetic algorithms (GA) has started gaining popularity in terms of its implementation beyond traditional computer science [11]. GA is widely used for solving optimization problems across different areas of medical science, vehicle routing, financial markets, etc. A genetic algorithm is an optimization technique that works on the principle of natural selection and helps find optimal or near-optimal solutions. GA is a type of evolutionary algorithm that is inspired by Darwin’s theory of evolution. It is a randomized approach that works towards finding the best solution by making slow and slight continuous changes in every set of solutions. GA and AI are complementary in nature to one another and, when used in combination, can prove significantly beneficial.
Alternative fuels must be technically, environmentally, and economically viable. These requirements make triglycerides (vegetable oils/animal fats) and their derivatives viable diesel fuel alternatives [12,13,14,15]. Substituting triglycerides is difficult due to their high viscosity, low volatility, and polyunsaturation in the catalytic process during the transesterification of oils [16,17]. The optimization of these parameters is required for any effort that seeks.
The work discusses the use of two regression algorithms, random forest and artificial neural networks, for predicting cetane numbers for biodiesel [18]. The authors collected experimental data from various literary works and created a consolidated dataset. The data set included 12 different FAME profiles from 131 different biodiesel types. The author is aiming at establishing the impact of the FAME composition on the cetane number for biodiesel. The root mean squared error (RMSE) and the coefficient of determination (R2) are used as performance indicators for both regression algorithms. The experimental analysis depicted a better performance for ANN as compared to the random forest algorithm. The RMSE and R2 values for ANN are 0.95 and 2.53, respectively. Higher values of stearic acid and myristic acid beyond 51.95 and 44.95%, respectively, resulted in a positive impact on the cetane number, whereas higher values beyond 68.4% for linolenic acid resulted in a negative impact on the same.
The authors propose the creation of an estimation model for the cetane number of biodiesels [19]. The work combines the use of least squares support vector machines, genetic algorithms (GA), particle swarm optimization (PSO), and a hybrid of GA and PSO. The dataset comprised 232 fuel samples that were collected by the authors from different literary works. The coefficient of determination (R2) and mean relative errors (MREs) were used as performance indicators. The statistical analysis indicated LSSVMHGAPSO as the most accurate model for the estimation of cetane numbers.
The work discusses the use of ANN for predicting the physical and chemical properties of biodiesel blends [20]. The authors described the production process of biodiesel as a result of blends of virgin castor oil (VCO) and waste frying oil (WFO). The following are the respective blend compositions: B1 (100% VCO), B2 (100% WFO), B3 (50% VCO), B4 (25% VCO), and B5 (75% VCO). Acidity level, saponification index, and density were considered independent variables of the ANN model. The statistical analysis indicated the influence of WFO on the physical and chemical properties of biodiesel. Depending on the blend composition and the subsequent transesterification process, the ANN model predicted different values for fuel acidity, cetene index, and kinematic viscosity.
The authors discuss the production of biodiesel from cotton oil. Subsequent blends for biodiesel were created by mixing diesel fuel with the produced cotton biodiesel. The work proposes the use of artificial neural networks and a linear regression model for predicting the viscosity and density of the fuel and its blends that were produced [21]. The authors used temperature and blend ratio as the two independent variables for the model. The temperatures ranged from 293 K to 373 K, whereas the blends were created by mixing 20, 30, 40, 50, and 75% of diesel fuel in volumetric ratios. MAPE was used as a performance indicator for both models. The ANN model performed better in comparison to the linear regression model with a 0.02% ANOVA for predicted density.
The authors propose a genetic algorithm-based back propagation neural network model for predicting biodiesel properties concerning its FAME compositions. The model comprises five input parameters or independent variables such as methyl palmitate, methyl stearate, methyl oleate, methyl linoleate, and methyl linolenate [22]. The proposed prediction model aims to identify the nonlinear relationship between FAME compositions and biodiesel properties. The root mean square error (RMSE) and mean absolute percentage error (MAPE) are the performance indicators chosen by the authors. The authors observed that combining a genetic algorithm with a back propagation neural network assists in parameter optimization and improves prediction accuracy. The authors consider cetene number, kinematic viscosity, iodine value, and cold filter plugging point as the four output parameters or dependent variables. The experiment analysis concluded that saturated FAMEs had a positive impact on cetane number, kinematic viscosity, and cold filter plugging point, whereas the iodine value for biodiesel was dependent on unsaturated FAMEs.
The authors propose an ANN-based model for yield prediction of biodiesel blends. The work discusses the production of biodiesel blends from the Jatropha algae oil mixture [23]. Catalyst concentration, reaction time, temperature, and methanol/oil volumetric ratio were used as independent variables for the model. The coefficient of determination (R2) is selected as a performance indicator for the model in terms of predicting blend yield.
The work discusses the use of linear regression algorithms for the prediction of biodiesel properties. The biodiesel samples used in the dataset were produced from 17 different blends [24]. The authors selected viscosity, density, flash point, higher heating value, and oxidative stability as dependent variables. Saponification value, iodine value, and polyunsaturated fatty acids were considered independent variables. Flashpoint and oxidative stability displayed no correlation during the statistical analysis. The authors implemented the ANOVA model after regression analysis to determine the significance of the model and the importance of individual independent variables. The proposed model was successful in predicting biodiesel properties such as viscosity and density with significantly higher accuracy as compared to the flashpoint. An increase in accuracy for the model was observed by the authors when they included polyunsaturated/monounsaturated fatty acid balance (PU/MU) as part of the independent variables.
The work discusses the implementation of a linear regression model and artificial neural networks to predict yield for biodiesel [25]. The authors produce biodiesel using the transesterification process of soybean oil at a constant temperature. Reaction time, catalyst percentage, and molar ratio were selected as independent variables for both models. R2 and RMSE are the selected performance indicators for both models. The ANN model presented better results in terms of accuracy and establishing a correlation in comparison with the linear regression model. The R2 values for linear regression and ANN are 0.41 and 0.98, respectively. The ANN model predicted a minimum of 70.97 and a maximum of 87.56% yield for biodiesel.
The study discusses publication distribution for the applicability of machine learning algorithms for biodiesel production during 2017 and 2022 from the Scopus database [26] mentioned in Appendix A. Table 1 illustrates a comparative study between selected works focusing on the application of machine learning algorithms and neural networks for biodiesel production.

Table 1.
Applications of ML algorithms in biodiesel production.
In the context of the present paper, it is divided into two broad sections: prediction and optimization. In terms of prediction, a DNN model along with multiple machine learning models is created over the process parameters of the transesterification process for predicting multiple characteristics of the biodiesel produced. The aspect of optimization discusses the use of genetic algorithms for predicting optimized transesterification process parameter values with respect to the desired biodiesel characteristics. A detailed explanation of our work is discussed in the subsequent methodology section.
2. Methodology
The transesterification process was carried out in a reactor. The apparatus comprises an oil bath, a reaction flask fitted with a condenser, and a digitally controlled mechanical stirrer. The glass reactor had a capacity of 500 mL, and it had three necks: one for the stirrer, the other for the condenser, and the inlet for the reactants. To determine the temperature of the reaction, a thermometer indicator was utilized. At the very bottom of the batch reactor was a valve that could be used to collect the finished product. To keep the temperature stable, the flask used for the reaction is stored inside an oil bath. Before beginning the reaction, the oil sample (200 mL) was brought up to the desired temperature through preheating. To preserve the catalytic activity and avoid moisture absorption, the potassium hydroxide–methanol solution was freshly prepared. The methanolic solution was then added to the oil that was contained in the reaction flask, and at this point, the measurement of the time began. This laboratory setup was utilized to optimize the primary process conditions in relation to the transesterification of the virgin Jatropha oils.
In order to guarantee the accuracy of the measurements of all the raw materials for the chemical reactions, as well as the temperature measurement and the other safety measures, precautions were taken. The traditional approach to the production of biodiesel, which makes use of a homogenous alkali catalyst such as KOH and produces a high yield of methyl ester, was utilized in this experiment. In the first case, the reaction conditions were optimized for maximum yield while simultaneously keeping the quality of the methyl esters as close to the specification as possible.
The amounts of methanol and metal hydroxide, in addition to the temperature of the reaction and the amount of time it takes, are the most important factors that influence the transesterification reaction. It has been determined that the molecular weight of Jatropha curcus oil, including its primary chemical constituents, is 870.19. Since the oil also consists of some other less significant components. It was estimated that the molecular weight of the oil extracted from Jatropha curcus was approximately 900. For the transesterification reaction to take place, there must be a total of three moles of methanol present for every mole of vegetable oil. Because the molecular weight of methanol is 32, 96 g of methanol was required for the transesterification of one mole (or 900 g) of Jatropha curcus oil, which resulted in a methanol concentration of 10.67 percent.
The process of systematic literature review has resulted in the creation of the following research questions. The research questions have been formulated concerning existing works and futuristic possibilities concerning the production of biodiesel. The authors have attempted to answer the following research questions through their respective findings in the results section:
- RQ1
- What are the key transesterification parameters that determine biodiesel properties?
- RQ2
- What is the relationship between different transesterification parameters?
- RQ3
- What is the impact of individual transesterification parameters on different properties of biodiesel?
- RQ4
- What methods can be adopted to produce biodiesel with the desired physical and chemical properties?
- RQ5
- How can we optimize transesterification parameters to yield the most sustainable and profitable biodiesel?
Table 2 and Table 3 illustrate the training dataset for input and output variables, respectively. NaOH and KOH are the two alkaline catalysts that have been used during the training process.
Table 2.
Training data input variables.
Table 3.
Training data output variables.
3. Experimental Details
Biodiesel is a renewable and biodegradable form of diesel synthesized from renewable sources such as vegetable oils, waste oils, and animal fat oils. The process of biodiesel production involves multiple steps such as feedstock pre-treatment, transesterification reactions, purification of biodiesel, etc. Our current work focuses on the application of machine learning and neural network algorithms for optimizing the transesterification reaction. Figure 1 represents the model workflow. Figure 2 depicts the architecture for the DNN model implemented in our work. In this section, the authors discuss the four algorithms that have been implemented to comprehend the relationships between transesterification process parameters and predict biodiesel properties. The section talks about the role of genetic algorithms in optimizing the process parameters for transesterification. A flowchart has been presented that depicts the workings of the genetic algorithm.
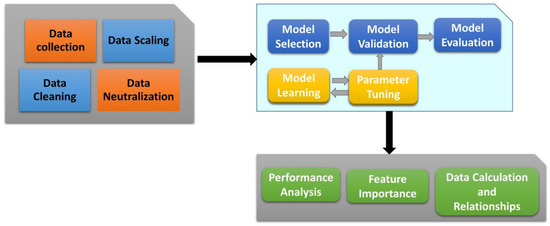
Figure 1.
Model workflow.
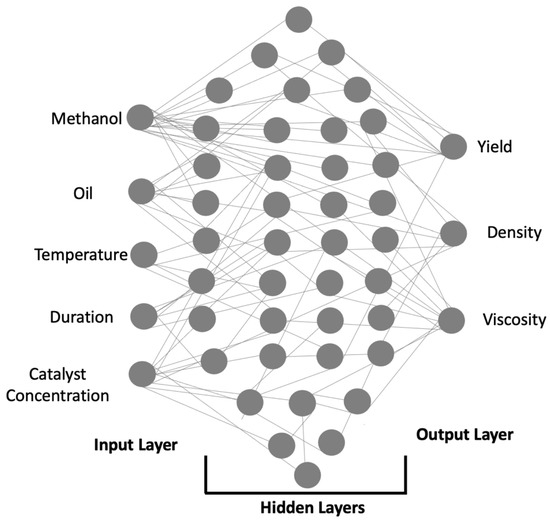
Figure 2.
Deep neural network architecture.
Linear regression is one of the most widely implemented machine learning algorithms for predictive analytics. It falls under the category of supervised learning and performs regression tasks. The purpose of a regression model is to predict the target variable based on certain independent variables. The target variable may also be addressed as the output variable, whereas the independent variables may be addressed as input variables. The LR algorithm assesses the relationship between dependent and independent variables. It estimates the impact of independent variables on the magnitude of the output variable. The linear regression algorithm generates a straight line or a surface that minimizes the distance between predicted and actual output values. A simple linear regression model may comprise one input and one output variable, whereas in the case of multivariate regression, there are multiple independent variables involved. Multi-output linear regression involves predicting multiple output variables from a set of various independent variables. In this work, the multi-output linear regression algorithm has been implemented, which considers transesterification process parameters as input variables and properties of biodiesel as target or output variables. The model establishes a linear correlation between input and output variables. It predicts the behavior of output variables based on the values of multiple independent variables.
The linear regression algorithm works well in the case of a linear relationship between independent and dependent variables. In the case of a non-linear relationship between dependent and independent variables, certain polynomial expressions have been added to the linear regression to convert it into a polynomial regression problem. A polynomial regression model computes an nth-degree polynomial relationship between independent and dependent variables. In the current work, the polynomial regression algorithm has been implemented to ensure the prediction of biodiesel properties. The work computes the model on different polynomial degrees, evaluates the performance and accuracy of the model at each stage, and subsequently selects the best nth-degree option.
The K-Nearest Neighbor (KNN) regression model is non-parametric and intuitive in nature. It approximates the association between independent and dependent variables based on distance functions. KNN-based regression is most suited for problems with lower data dimensionality. The KNN algorithm can be used for both classification and regression problems. The KNN model works on the concept of common intuition (feature similarity) and is adequate for handling nonlinear relationships in the data set without involving any complicated data engineering practices.
The final set of algorithms that have been implemented in this work of ours is the deep neural network (DNN). The DNN architecture comprises an input layer, multiple densely connected hidden layers, and an output layer. Each layer in the neural network is comprised of an activation function that is responsible for introducing nonlinearity in the data set. Hyperparameter tuning is one of the key aspects of implementing a DNN model. The efficiency, accuracy, and learning rate of the model are directly related to its hyperparameters. The proposed work discusses the implementation of a DNN model coupled with a genetic algorithm for its hyperparameter tuning. The deep net model considers transesterification process parameters as input variables, constructs generalizations based on input values, and stores them in the form of weights in the hidden layers. Table 4 describes the various hyperparameters that have been used to construct the deep neural network.
Table 4.
DNN network parameters.
Deep neural networks (DNNs) are a type of artificial neural network (ANN) with multiple layers of interconnected nodes, also known as artificial neurons. These networks are called “deep” because they have many layers, typically more than three. DNNs are modeled after the structure and function of the human brain and are used for a wide variety of tasks, such as image and speech recognition, natural language processing, and decision-making. They are trained to recognize patterns and make predictions by adjusting the weights and biases of the artificial neurons in each layer. A DNN typically has an input layer, one or more hidden layers, and an output layer. The input layer receives the raw data, and the output layer produces the final prediction or decision. The hidden layers process the data and extract features that are used to make the final decision. The training process of DNNs is conducted by providing them with a large set of labeled data and adjusting the weights and biases of the artificial neurons in each layer to minimize the error between the predicted output and the true output. The training process of a DNN is carried out by providing it with a large set of labeled data and adjusting the weights and biases of the artificial neurons in each layer to minimize the error between the predicted output and the true output.
The algorithm used to adjust the weights and biases is called backpropagation. During the forward pass, the input data is passed through the network, and the artificial neurons in each layer process the data by applying a set of mathematical operations to it. These operations include matrix multiplications, activation functions, and bias additions. The activation function is a non-linear function that is applied to the output of each neuron to introduce non-linearity into the network, allowing it to learn and represent more complex patterns. During the backward pass, the error is propagated back through the network, and the weights and biases of the neurons are updated to reduce the error. This process is repeated multiple times until the error is minimized. After the training is complete, the DNN can be used to make predictions on new, unseen data by passing it through the trained network. The predictions are made by the output layer, which produces the final decision based on the features extracted by the hidden layers.
A genetic algorithm (GA) is a type of optimization algorithm that is inspired by the process of natural selection. It is used to find an optimal solution to a problem by mimicking the process of evolution. A GA is used to find an optimal solution in a large search space by simulating the process of natural selection. Table 5 describes the operating parameters for the implemented GA. Figure 3 explains the workflow for a GA. The basic components of the GA are a population of candidate solutions, a fitness function, a selection mechanism, and genetic operators such as crossover and mutation. The population of candidate solutions is a set of potential solutions to the problem, represented as a set of chromosomes. Each chromosome is a string of bits or numbers that encodes a possible solution. The fitness function is used to evaluate the quality of each candidate solution by assigning it a fitness value. The selection mechanism is used to select the fittest individuals from the population, which will be used to generate the next generation of solutions.
Table 5.
Genetic algorithm operating parameters.
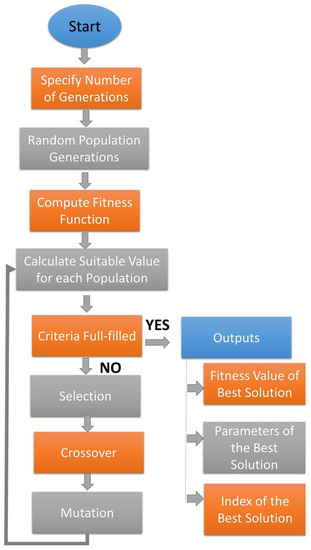
Figure 3.
Working of genetic algorithm.
The genetic operators are used to create new solutions by combining the genetic information of the selected individuals. The process starts with a random population of candidate solutions, and then it repeatedly applies the selection, crossover, and mutation operators to create new generations of solutions. The algorithm stops when a satisfactory solution is found or when a stopping criterion is met, such as a maximum number of iterations. Table 6 and Table 7 represent the results obtained after implementing GA.
Table 6.
Genetic algorithm optimization data KOH.
Table 7.
Genetic algorithm optimization data NaOH.
4. Results and Discussion
In this section, a clear and concise summary of the experimental results has been added, including quantitative evaluations of the performance of the proposed model. These results provide insight into the behavior of different regression models and discuss patterns that have emerged from the experiments. Table 8, Table 9, Table 10, Table 11, Table 12, Table 13, Table 14 and Table 15 represent prediction values for yield, density, and viscosity obtained from the implementation of DNN along with different regression models.
Table 8.
Deep neural network prediction NaOH.
Table 9.
Deep neural network prediction KOH.
Table 10.
Linear regression observed and predicted data KOH.
Table 11.
Linear regression observed and predicted data NaOH.
Table 12.
Poly regression observed and predicted data KOH.
Table 13.
Poly regression observed and predicted data NaOH.
Table 14.
K nearest neighbor observed and predicted data KOH.
Table 15.
K nearest neighbor observed and predicted data NaOH.
PDP (partial dependence plot) graphs are a way to visualize the relationship between a single feature of a dataset and the outcome variable in a machine learning model. The graph shows how the outcome variable changes as the features of interest are varied while keeping all other features constant. PDP graphs are often used to interpret the results of complex models and identify which features have the greatest impact on the outcome. They are also useful for identifying non-linear relationships between features and the outcome variable. Figure 4 and Figure 5 illustrate the PDP graphs between transesterification process parameters and biodiesel properties for NaOH and KOH as catalysts, respectively.
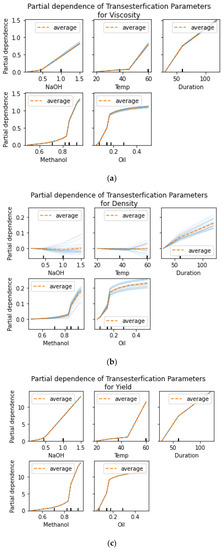
Figure 4.
PDP Graphs NaOH. (a) Viscosity; (b) density; (c) yield.
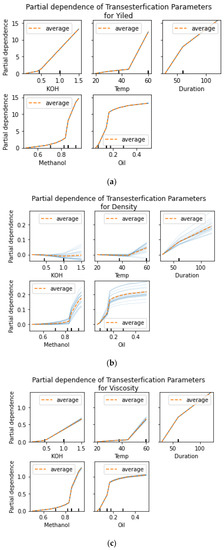
Figure 5.
PDP Graphs KOH: (a) Viscosity; (b) density; (c) yield.
4.1. Influence of Methanol/Oil Ratio
One of the crucial aspects that determines the outcome of the transesterification reaction is the proportion of alcohol to oil that is used. In theory, transesterification requires three moles of alcohol for every mole of oil that is being converted. In actuality, however, the molar ratio ought to be on the higher side to move the reaction forward in accordance with Le Chatelier’s principle, which states that an increase in the concentration of the reactant shifts the equilibrium toward the formation of the product. This is the case to move the reaction forward in accordance with Le Chatelier’s principle. Experiments were run at 60 °C and 400 revolutions per minute with varying proportions of methanol to oil to determine the optimal amount of methanol needed for the reaction (6:1, 12:1, 15:1, 18:1). When using a ratio of 6:1, the yield that could be obtained in two hours was a maximum of 88% weight. There is not much of an increase in the % yield with higher molar ratios, but the process takes less time.
4.2. Influence of Catalyst Concentration
KOH was used as a catalyst for the transesterification of Jatropha curcus oil with methanol. The reaction was carried out at a temperature of 60 °C, with a rotational speed of 400 revolutions per minute and a ratio of six parts methanol to one part oil. It was determined through observation that a concentration of KOH of 1.0% is necessary for the most efficient transesterification possible. It was observed that although there was not a significant increase in the ester yield when the concentration of KOH was decreased below or increased above 1%, there was an increase in the formation of glycerol. The highest possible ester yield of 97% was achieved by using a KOH concentration of 1.0% by weight.
4.3. Influence of Reaction Temperature
The temperature ranges of 30, 45, and 60 °C were used in this investigation. The reaction was carried out with a constant reaction time of 120 min, a constant methanol-to-oil ratio, and constant KOH concentrations of 6:1 and 1.0%, respectively. The highest ester yield of 97% was achieved at a temperature of 60 degrees Celsius. It is evident from this that the ester yield increases in direct proportion to the degree to which the reaction temperature is raised. The temperature of the reaction should never rise above methanol’s boiling point, which is 65 degrees Celsius. As a result, the temperature of the reaction was maintained at 60 degrees Celsius.
4.4. Influence of Reaction Time
In order to determine the optimal time for the reaction, it was carried out for 30, 60, 90, and 120 min at a temperature of 60 °C with a rotational speed of 400 revolutions per minute and a ratio of 6:1 methanol to oil. According to the findings, it is abundantly clear that the ester yield rises as the reaction time increases. At 90 and 120 min of reaction time, the ester yields were almost identical. It is abundantly clear that a reaction time of 120 min resulted in the highest ester yield possible, which was 89% by weight.
Figure 6 and Figure 7 describe the performance evaluation graphs for the DNN with respect to NaOH and KOH as catalysts. The graphs indicate the comparison between actual values of biodiesel properties and predicted values.
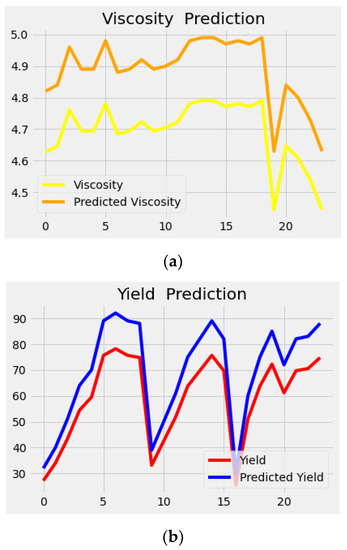
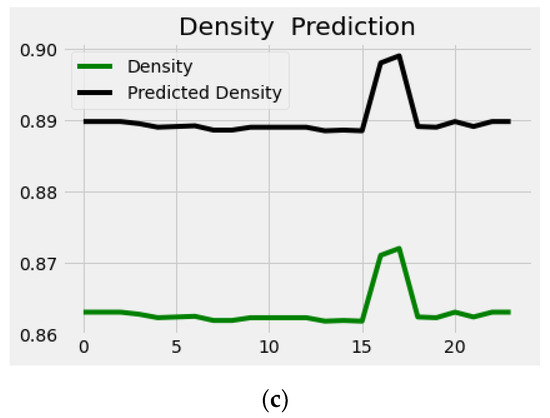
Figure 6.
DNN prediction graphs NaOH: (a) Viscosity; (b) yield; (c) density.
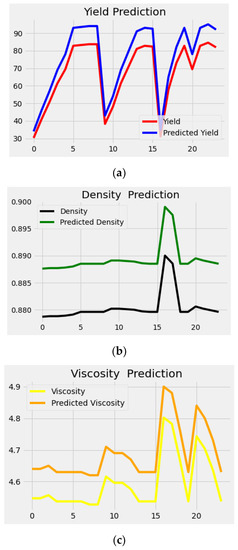
Figure 7.
DNN prediction graphs KOH: (a) Yield; (b) density; (c) viscosity.
Figure 8 and Figure 9 discuss the functioning of polynomial regression in terms of calculating the degree of the polynomial equation that describes the best non-linear relationship between transesterification process parameters and individual biodiesel properties.
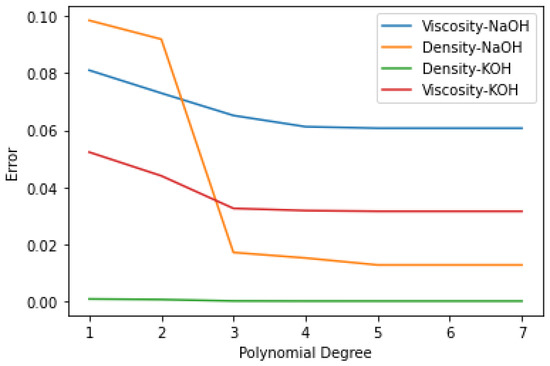
Figure 8.
Polynomial regression NaOH and KOH: Density vs. Viscosity.
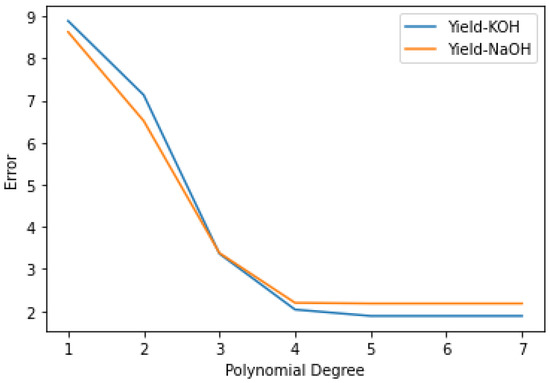
Figure 9.
Polynomial regression NaOH and KOH yield.
Figure 10 and Figure 11 illustrate the correlations that exist between individual transesterification process parameters and biodiesel properties and transesterification process parameters, respectively. The following heatmaps indicate the level of importance of a transesterification process parameter in terms of its impact on biodiesel properties.
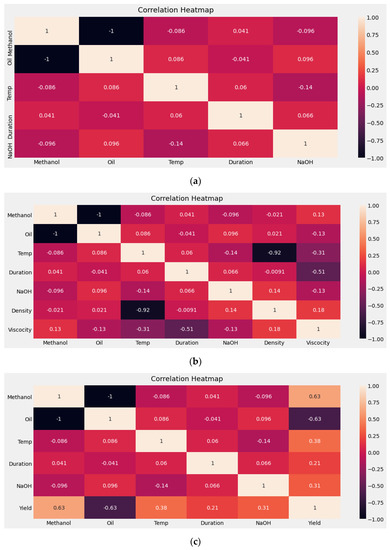
Figure 10.
Heatmap NaOH: (a) Input parameters; (b) input parameters vs. density and viscosity; (c) input parameters vs. yield.
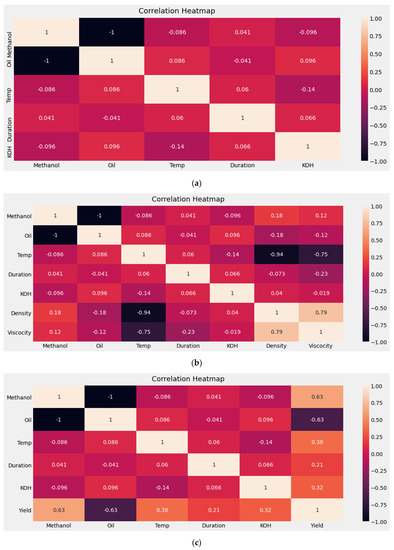
Figure 11.
Heatmap KOH: (a) Input parameters; (b) input parameters versus density and viscosity; (c) input parameters versus yield.
Mean absolute error (MAE), mean square error (MSE), and root mean square error (RMSE) have been used as performance indicators for comparing the performance of different regression models and the DNN. Figure 12, Figure 13, Figure 14, Figure 15, Figure 16 and Figure 17 represent the same for individual biodiesel properties of yield, density, and viscosity.
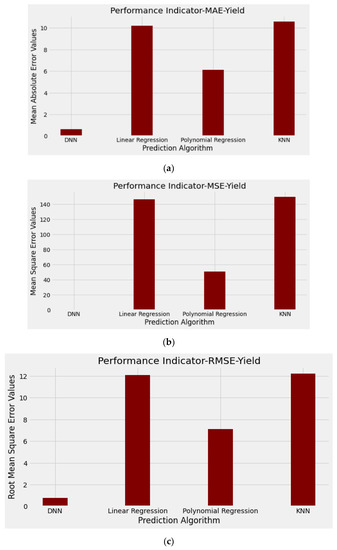
Figure 12.
Performance indicator graph KOH: (a) Mean absolute error values of yield; (b) mean square error values of yield; (c) root mean square error values of yield.
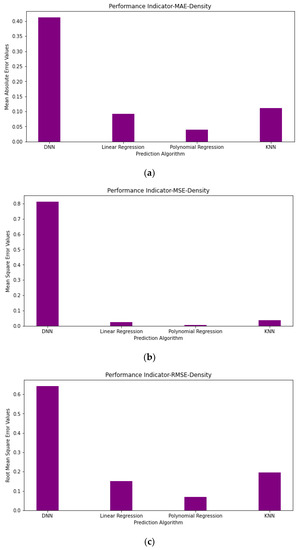
Figure 13.
Performance indicator graph KOH: (a) Mean absolute error values of density; (b) mean square error values of density; (c) root mean square error values of density.

Figure 14.
Performance indicator graph KOH: (a) Mean absolute error values of viscosity; (b) mean square error values of viscosity; (c) root mean square error values of viscosity.

Figure 15.
Performance indicator graph NaOH: (a) Mean absolute error values of yield; (b) mean square error values of yield; (c) root mean square error values of yield.
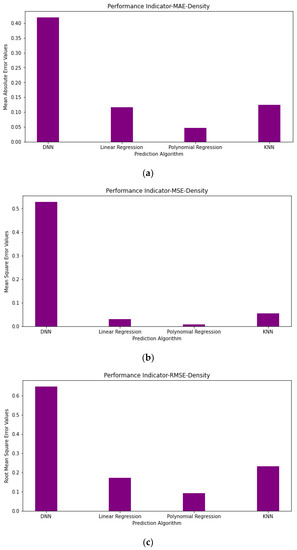
Figure 16.
Performance indicator graph NaOH: (a) Mean absolute error values of density; (b) mean square error values of density; (c) root mean square error values of density.
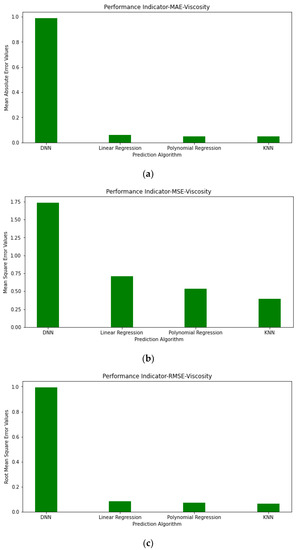
Figure 17.
Performance indicator graph NaOH: (a) Mean absolute error values of viscosity; (b) mean square error values of viscosity; (c) root mean square error values of viscosity.
4.5. Physichemical Characterization of Biodiesel
ASTM D-6584 is the most important biodiesel analysis and standard test technique for monitoring the refining process. This outlines a GC-FID (gas chromatography with flame ionization detection) method for quantifying free and total glycerol in 100% methyl esters (B-100) biodiesel. The G.C. accurately determines the percent mass of free glycerin, mono, di, and triglycerides in methyl esters. Measuring the level of free glycerol and any unreacted mono-, di-, or triglycerides in biodiesel will indicate how efficiently the transesterification reaction is proceeding.
A detailed analysis giving the % composition of various components is given in Table 16.
Table 16.
Concentration levels of the analyte components as seen in the chromatographic display.
GC analysis (Table 16) of the jatropha biodiesel shows that jatropha curcus methyl ester contains mostly C18 + C20 carbon-number fatty acids (stearic and arachidic) and C16 hexadecanoic acid. Other components: monglycerides at 2.48%, di and triglycerides.
4.6. Future Work and Recommendation
The developed model can be used to predict the optimal conditions for biodiesel synthesis from various feedstocks. Moreover, the sustainability of biodiesel production can be evaluated with a number of different tools. These include techno-economic, life cycle assessment, energy, and exergy assessments [33,34].
5. Conclusions and Prospects
The study investigates various parameters to obtain optimized conditions for the production of Jatropha biodiesel using NaOH and KOH as catalysts. A group of multi-objective regression models coupled with a deep neural network were implemented for the production of biodiesel properties. The statistical analysis enabled us to categorize the most relevant transesterification process parameters in terms of having the maximum impact on biodiesel properties. The empirical analysis depicted a positive correlation between temperature and duration and a negative correlation between methanol content and catalyst concentration. Moreover, the analysis stated that methanol concentration had the maximum positive correlation with the density and viscosity of the biodiesel produced. The PDP graphs depicted an almost linear curve between viscosity and duration, whereas the S-shaped curve between viscosity and amount of oil content. The analysis depicted the nature and extent of the correlation that exists between different transesterification process parameters. Mean square error (MSE), mean absolute error (MAE), and root mean square error (RMSE) were used as performance indicators for different prediction models. The deep neural network model proved to be more accurate in predicting yield and viscosity in comparison with linear regression, polynomial regression, and the KNN model. Whereas, on the contrary, linear regression and polynomial regression proved to be better in terms of accuracy when predicting the density of the biodiesel produced. The same can be confirmed from Table 10, Table 11, Table 12 and Table 13. Following the prediction phase, an evolutionary optimization technique in the form of a genetic algorithm is applied to optimize the transesterification process parameters based on desired biodiesel properties. The work presented in the paper signifies the applicability of AI in producing biodiesel with the desired set of properties and aligns itself with its contemporaries [35,36]. The GA-based optimization algorithm was able to predict trance esterification process parameters for three different sets of values for yield, density, and viscosity of the biodiesel. The deep neural network exhibits favorable performance in simulating the biodiesel production process. The sustainability aspect of biodiesel production, which involves using environmentally friendly feedstocks and minimizing resource usage, is emphasized. The authors look forward to extending the existing work by incorporating data regarding biodiesel blends and simulating the biodiesel production process to produce more sustainable and economically viable forms of biodiesel.
Author Contributions
Conceptualization, A.K. and S.J.; methodology, A.K. and B.Y.L.; software, A.K., S.J., V.B. and D.B.; validation, A.K., B.Y.L., V.B. and D.B.; formal analysis, A.K., B.Y.L., V.B. and D.B.; investigation, A.K., B.Y.L., S.J. and V.B.; resources, A.K. and B.Y.L.; data curation, A.K., S.J., V.B. and D.B.; writing—original draft preparation, A.K., B.Y.L., S.J. and V.B.; writing—review and editing, V.B., D.B., V.P. and A.S.; visualization, S.J., V.B., V.P. and A.S.; supervision, V.B., D.B., S.J. and V.P.; project administration, A.K.; funding acquisition, A.K., V.B., D.B., V.P. and A.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data can be made available on request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| FFA | Free Fatty Acid |
| NaOH | Sodium Hydroxide |
| KOH | Potassium Hydroxide |
| FAME | Fatty Acid Methyl Ester |
| VCO | Virgin Castor Oil |
| WFO | Waste Frying Oil |
| CN | Cetane Number |
| CFPP | Cold Filter Plugging Point |
| GC | Gas Chromatography |
| GC-FID | Gas Chromatography with Flame Ionization Detection |
| AI | Artificial Intelligence |
| DNN | Deep Neural Network |
| GA | Genetic Algorithm |
| ANN | Artificial Neural Network |
| RMSE | Root Mean Squared Error |
| MAPE | Mean absolute percentage error |
| ANOVA | Analysis of variance |
| LR | Linear Regression |
| SVM | Support Vector Machine |
| KNN | k-nearest neighbours |
| PDP | Partial Dependence Plot |
| MSE | Mean Square Error |
| MAE | Mean Absolute Error |
| R2 | Coefficient of determination |
| PSO | Particle swarm optimisation |
Appendix A

Figure A1.
Year specific publication stats.
Figure A1.
Year specific publication stats.


Figure A2.
Feedstock based publication distribution.
Figure A2.
Feedstock based publication distribution.


Figure A3.
Region specific publication distribution.
Figure A3.
Region specific publication distribution.


Figure A4.
Publication trends for biodiesel production.
Figure A4.
Publication trends for biodiesel production.


Figure A5.
Schematic diagram of transesterification lab reactor.
Figure A5.
Schematic diagram of transesterification lab reactor.

References
- Tan, D.; Wu, Y.; Lv, J.; Li, J.; Ou, X.; Meng, Y.; Lan, G.; Chen, Y.; Zhang, Z. Performance optimization of a diesel engine fueled with hydrogen/biodiesel with water addition based on the response surface methodology. Energy 2023, 263, 125869. [Google Scholar] [CrossRef]
- Tan, D.; Meng, Y.; Tian, J.; Zhang, C.; Zhang, Z.; Yang, G.; Cui, S.; Hu, J.; Zhao, Z. Utilization of renewable and sustainable diesel/methanol/n-butanol (DMB) blends for reducing the engine emissions in a diesel engine with different pre-injection strategies. Energy 2023, 269, 126785. [Google Scholar] [CrossRef]
- Wang, J.; Xia, A.; Deng, Z.; Huang, Y.; Zhu, X.; Zhu, X.; Liao, Q. Intensifying biofuel production using a novel bionic flow-induced peristaltic reactor: Biodiesel production as a case study. Biofuel Res. J. 2022, 9, 1721–1735. [Google Scholar] [CrossRef]
- Liu, J.; Tao, B. Fractionation of fatty acid methyl esters via urea inclusion and its application to improve the low-temperature performance of biodiesel. Biofuel Res. J. 2022, 9, 1617–1629. [Google Scholar] [CrossRef]
- Lamba, B.Y.; Joshi, G.; Rawat, D.S.; Jain, S.; Kumar, S. Study of oxidation behavior of Jatropha oil methyl esters and Karanja oil methyl esters blends with EURO-IV high speed diesel. Renew. Energy Focus 2018, 27, 59–66. [Google Scholar] [CrossRef]
- Greener, J.G.; Kandathil, S.M.; Moffat, L.; Jones, D.T. A guide to machine learning for biologists. Nat. Rev. Mol. Cell Biol. 2022, 23, 40–55. [Google Scholar] [CrossRef]
- Aghbashlo, M.; Peng, W.; Tabatabaei, M.; Kalogirou, S.A.; Soltanian, S.; Hosseinzadeh-Bandbafha, H.; Mahian, O.; Lam, S.S. Machine learning technology in biodiesel research: A review. Prog. Energy Combust. Sci. 2021, 85, 100904. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. arXiv 2021, arXiv:2107.03342. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Lamba, B.Y.; Joshi, G.; Tiwari, A.K.; Rawat, D.S.; Mallick, S. Effect of antioxidants on physico-chemical properties of EURO-III HSD (high speed diesel) and Jatropha biodiesel blends. Energy 2013, 60, 222–229. [Google Scholar] [CrossRef]
- Sun, K.; Lu, J.; Ma, L.; Han, Y.; Fu, Z.; Ding, J. Optimization of biodiesel synthesis from Jatropha curcas oil using kaolin derived zeolite Na–X as a catalyst. Fuel 2015, 158, 848–854. [Google Scholar] [CrossRef]
- Joshi, G.; Lamba, B.Y.; Rawat, D.S.; Mallick, S.; Murthy, K.S.R. Evaluation of Additive Effects on Oxidation Stability of Jatropha Curcas Biodiesel Blends with Conventional Diesel Sold at Retail Outlets. Ind. Eng. Chem. Res. 2013, 52, 7586–7592. [Google Scholar] [CrossRef]
- Peña, R.; Romero, R.; Martínez, S.L.; Natividad, R.; Ramírez, A. Characterization of KNO3/NaX catalyst for sunflower oil transesterification. Fuel 2013, 110, 63–69. [Google Scholar] [CrossRef]
- Neha, P.; Chintan, B.; Pallavi, D.; Neha, T. Use of Sunflower and Cottonseed Oil to prepare Biodiesel by catalyst assisted Transesterification. Res. J. Chem. Sci. 2013, 3, 42–47. [Google Scholar]
- Lamba, B.Y.; Rawat, M.S.M.; Singh, H. Bio-diesel production from Jatropha curcus & Pongamia pinnata oil sea comparative study. Dew 2009, 18, 7. [Google Scholar]
- Miraboutalebi, S.M.; Kazemi, P.; Bahrami, P. Fatty Acid Methyl Ester (FAME) composition used for estimation of biodiesel cetane number employing random forest and artificial neural networks: A new approach. Fuel 2016, 166, 143–151. [Google Scholar] [CrossRef]
- Bemani, A.; Xiong, Q.; Baghban, A.; Habibzadeh, S.; Mohammadi, A.H.; Doranehgard, M.H. Modeling of cetane number of biodiesel from fatty acid methyl ester (FAME) information using GA-, PSO-, and HGAPSO- LSSVM models. Renew. Energy 2020, 150, 924–934. [Google Scholar] [CrossRef]
- Arce, P.F.; Guimarães, D.H.P.; de Aguirre, L.R. Experimental data and prediction of the physical and chemical properties of biodiesel. Chem. Eng. Commun. 2019, 206, 1273–1285. [Google Scholar] [CrossRef]
- Özgür, C.; Tosun, E. Prediction of density and kinematic viscosity of biodiesel by artificial neural networks. Energy Sources Part A Recover. Util. Environ. Eff. 2017, 39, 985–991. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, F. Prediction of critical properties of biodiesel fuels from FAMEs compositions using intelligent genetic algorithm-based back propagation neural network. Energy Sources Part A Recover. Util. Environ. Eff. 2021, 43, 2063–2076. [Google Scholar] [CrossRef]
- Kumar, S.; Jain, S.; Kumar, H. Prediction of jatropha-algae biodiesel blend oil yield with the application of artificial neural networks technique. Energy Sources Part A Recover. Util. Environ. Eff. 2019, 41, 1285–1295. [Google Scholar] [CrossRef]
- Mairizal, A.Q.; Awad, S.; Priadi, C.R.; Hartono, D.M.; Moersidik, S.S.; Tazerout, M.; Andres, Y. Experimental study on the effects of feedstock on the properties of biodiesel using multiple linear regressions. Renew. Energy 2020, 145, 375–381. [Google Scholar] [CrossRef]
- Kumar, S. Comparison of linear regression and artificial neural network technique for prediction of a soybean bio-diesel yield. Energy Sources Part A Recover. Util. Environ. Eff. 2020, 42, 1425–1435. [Google Scholar] [CrossRef]
- Scopus Preview—Scopus—Welcome to Scopus. (n.d.). Available online: https://www.scopus.com/ (accessed on 10 January 2023).
- Rocabruno-Valdés, C.; Ramírez-Verduzco, L.; Hernández, J. Artificial neural network models to predict density, dynamic viscosity, and cetane number of biodiesel. Fuel 2015, 147, 9–17. [Google Scholar] [CrossRef]
- Moradi, G.; Dehghani, S.; Khosravian, F.; Arjmandzadeh, A. The optimized operational conditions for biodiesel production from soybean oil and application of artificial neural networks for estimation of the biodiesel yield. Renew. Energy 2013, 50, 915–920. [Google Scholar] [CrossRef]
- Banerjee, A.; Varshney, D.; Kumar, S.; Chaudhary, P.; Gupta, V.K. Biodiesel production from castor oil: ANN modeling and kinetic parameter estimation. Int. J. Ind. Chem. 2017, 8, 253–262. [Google Scholar] [CrossRef]
- Ighose, B.O.; Adeleke, I.A.; Damos, M.; Junaid, H.A.; Okpalaeke, K.E.; Betiku, E. Optimization of biodiesel production from Thevetia peruviana seed oil by adaptive neuro-fuzzy inference system coupled with genetic algorithm and response surface methodology. Energy Convers. Manag. 2017, 132, 231–240. [Google Scholar] [CrossRef]
- Corral Bobadilla, M.; Fernández Martínez, R.; Lostado Lorza, R.; Somovilla Gómez, F.; Vergara González, E.P. Optimizing Biodiesel Production from Waste Cooking Oil Using Genetic Algorithm-Based Support Vector Machines. Energies 2018, 11, 2995. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Prayogo, D.; Ju, Y.-H.; Wu, Y.-W.; Sutanto, S. Optimizing Mixture Properties of Biodiesel Production Using Genetic Algorithm-Based Evolutionary Support Vector Machine. Int. J. Green Energy 2016, 13, 1599–1607. [Google Scholar] [CrossRef]
- Aghbashlo, M.; Hosseinzadeh-Bandbafha, H.; Shahbeik, H.; Tabatabaei, M. The role of sustainability assessment tools in realizing bioenergy and bioproduct systems. Biofuel Res. J. 2022, 35, 1697–1706. [Google Scholar] [CrossRef]
- Hosseinzadeh-Bandbafha, H.; Nizami, A.-S.; Kalogirou, S.A.; Gupta, V.K.; Park, Y.-K.; Fallahi, A.; Sulaiman, A.; Ranjbari, M.; Rahnama, H.; Aghbashlo, M.; et al. Environmental life cycle assessment of biodiesel production from waste cooking oil: A systematic review. Renew. Sustain. Energy Rev. 2022, 161, 112411. [Google Scholar] [CrossRef]
- Ahmad, J.; Awais, M.; Rashid, U.; Ngamcharussrivichai, C.; Naqvi, S.R.; Ali, I. A systematic and critical review on effective utilization of artificial intelligence for bio-diesel production techniques. Fuel 2023, 338, 127379. [Google Scholar] [CrossRef]
- Pahwa, M.S.; Dadhich, M.; Saini, J.S.; Saini, D.K. Use of Artificial Intelligence (AI) in the Optimization of Production of Biodiesel Energy. In Artificial Intelligence for Renewable Energy Systems; Scrivener Publishing LLC.: Salem, MA, USA, 2022; pp. 229–238. [Google Scholar] [CrossRef]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).