1. Introduction
To achieve sustainable growth, companies must pay attention to the issue of financial risks. Early forecasting of financial risks refers to selecting suitable financial indicators and issuing early warning signals. With the development of information and computer technology, listed companies have accumulated a wealth of historical financial data. Since the deterioration of a company’s financial risk is a gradual process, the practical importance of selecting important indicators from this high dimensional data and making accurate predictions about financial conditions in advance is significant.
A common approach to the financial risk forecast problem is to use a dichotomous approach, with Special Treatment (ST) classification as the primary criterion. Altman [
1] was the first to use a multivariate linear discriminant approach to predict a company’s financial position based on multiple financial indicators, while Ohlson [
2] proposed a conditional probability-based logistic model for analyzing the financial early warning problem. These models have since been explored and extended by many researchers in different countries [
3,
4]. Zhao and Lin [
5] utilized a logistic model to identify the influencing factors of default risk in small and medium-sized enterprises. However, the logistic regression model is less restrictive than multivariate discriminant analysis, but multicollinearity among variables can reduce model stability. Li et al. [
6] showed that incorporating corporate efficiency information using the Data Envelopment Analysis (DEA) method as a variable can increase the accuracy of the financial risk forecasting model. García et al. [
7] explored the performance of four linear classification models, including Fisher linear discriminant, on the space of dissimilarities. Zhou et al. [
8] employed a gray clustering approach to select relevant indicators and subsequently utilized a logistic regression model for analysis. Classic statistical models often rely on assumptions of linearity, normality, and independence among variables, which are too idealized.
To overcome these limitations, many machine-learning methods have been developed for extracting and modeling information from observations. For example, Wang et al. [
9] proposed an improved FS-Boosting model for corporate bankruptcy prediction, while Zhao et al. [
10] explored the use of Kernel Extreme Learning Machine (KELM) for bankruptcy prediction using a two-step lattice strategy to find optimal parameters. Tavana et al. [
11] employed Artificial Neural Networks (ANNs) and Bayesian Networks (BNs) to measure the liquidity risk of banks, and Zeng et al. [
12] proposed the Group Sparse Principal Component Analysis Support Vector Machine (GSPCA-SVM) model.
The Cox proportional hazards model is a widely used semiparametric model in the field of survival analysis, which is employed to investigate the impact of covariates on the likelihood of survival. It has the advantage of not being restricted by the distribution of variables and takes into account the survival time and status of the enterprise. Lane et al. [
13] first introduced the Cox model in financial risk early warning and used the stepwise regression method to select the final variables from 21 variables. Im et al. [
14] proposed a time-varying Cox proportional hazards model that demonstrated the effectiveness of dynamic assessment in predicting credit default risk. Ding et al. [
15] proposed a discrete transformation survival model using Box–Cox transformations to reduce the impact of data on the model. Lin et al. [
16] introduced social network factors into the Cox model to investigate the impact of top managers’ social networks on firms’ ability to overcome financial distress.
The variable selection problem is the core of financial risk early warning models, as researchers need to select influential factors from a large number of possible variables. Commonly used methods for indicator selection include stepwise regression, dimensionality reduction, and penalized variable selection. Huang et al. [
17] used the LASSO method to select important variables from different categories of financial indicators, while Xu et al. [
18] constructed a financial early warning model using factor analysis to downscale indicators into two dimensions. Yang and Xu [
19] employed stepwise regression to examine the impact of political relations on green innovation outcomes in companies. Herman et al. [
20] employed two clustering analysis methods to evaluate the financial performance of firms. Although the stepwise regression method is simple in principle, Breiman [
21] pointed out its lack of stability, and the dimensionality reduction method may not be applicable to high-dimensional data, resulting in a loss of information.
The penalty method, which can simultaneously accomplish parameter estimation and variable selection, has been widely investigated by scholars as it overcomes the drawbacks of classic methods, such as high computational complexity and poor stability. The
penalty function, also known as
regularization, is an important type of penalty method that penalizes the number of non-zero elements in regression coefficients for variable selection. However, due to the discontinuity of this penalty function, obtaining stable results for variable selection using
penalty methods directly is difficult. Therefore, researchers have explored using other penalty functions to achieve variable selection. Tibshirani [
22] proposed LASSO, which can achieve both variable selection and continuous stability of estimation and has been widely used. However, this method does not have the Oracle property [
23], which is the best property of the penalized variable selection method. Since then, many penalty function methods have been proposed by domestic and foreign researchers. For example, Fan and Li proposed Smoothly Clipped Absolute Deviation (SCAD) [
23], and the parameter estimates obtained via the SCAD penalty function are approximately unbiased. Zou [
24] proposed Adaptive LASSO based on LASSO, and Zhang first used a concave penalty function for variable selection and proposed the Minimum Concave Penalty (MCP) [
25]. These penalty methods can be regarded as convex and non-convex approximations of the
penalty, and none of them use the
penalty directly. Therefore, it is possible that the final model still includes variables with small effects.
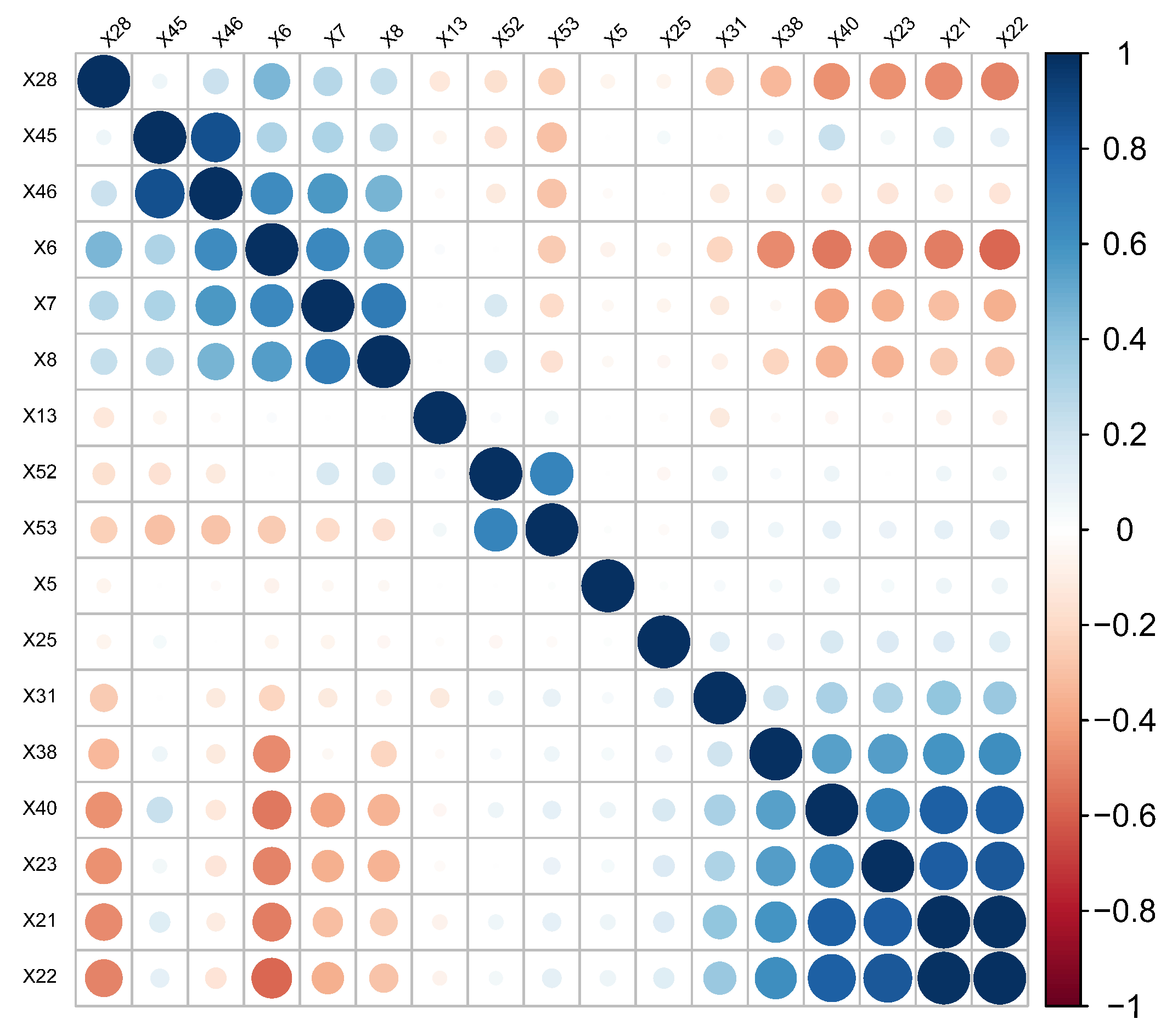
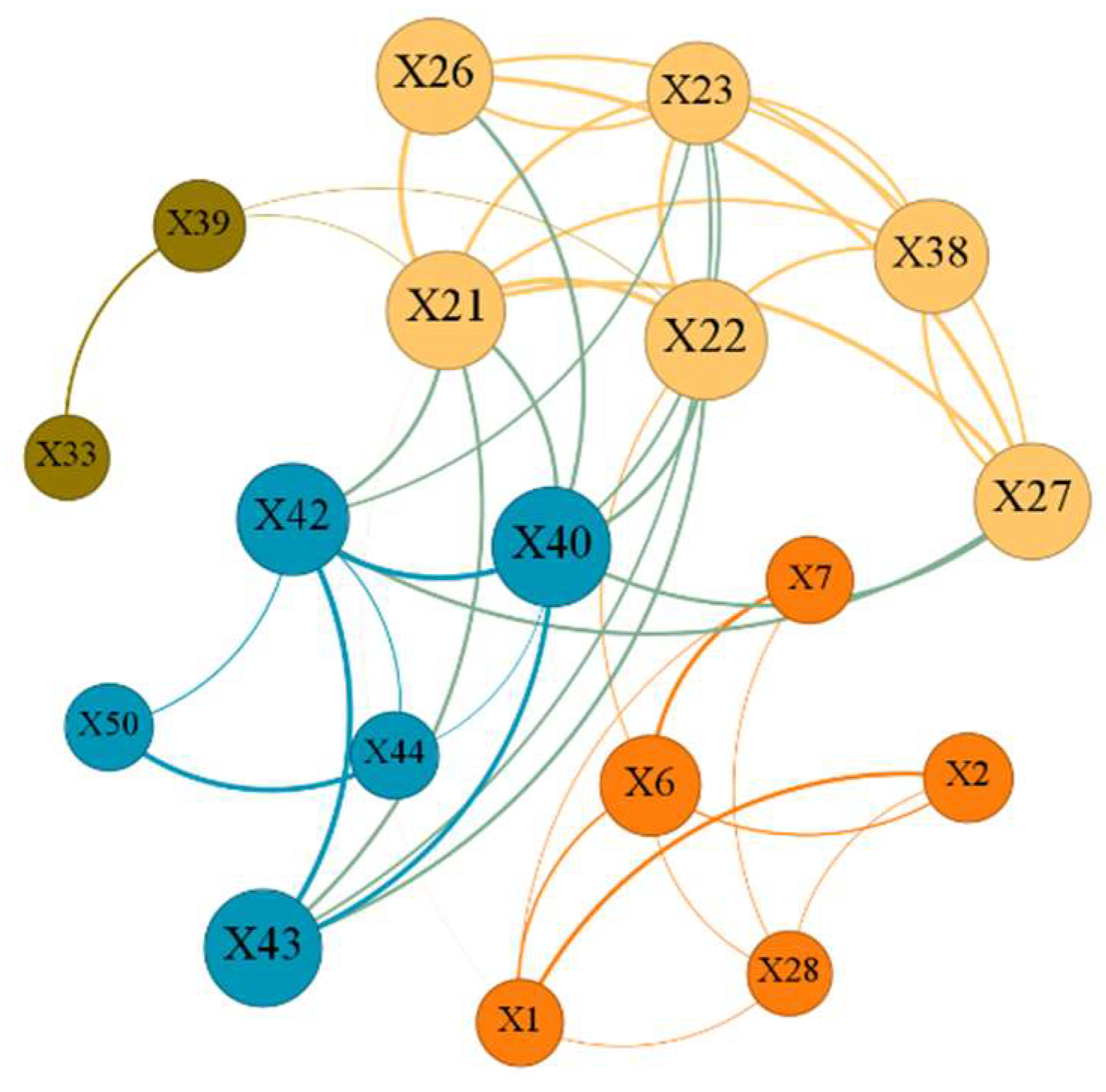
There are numerous correlations between the financial indicators of listed companies, and ignoring them can result in the loss of important information. Moreover, these correlations can affect the accuracy of predictions, making it crucial to capture them. One common approach to solving this problem is to construct network structures on graphs in a penalized manner. Huang et al. [
26] applied different kinds of graph network structures in a high-dimensional model, and the network structure relationships of graphs improved the effectiveness of variable selection. Hallac et al. [
27] combined graph structure and LASSO to perform clustering and optimization with graph structure. In his study, he also proposed the Alternating Direction Method of Multipliers. (ADMM) algorithm for solving LASSO problems with graph structures and proved that many common optimization problems can be solved by converting them into Net-LASSO forms. Liu et al. [
28] explored a graph structure-based variable integration approach to financial distress forecasting and proposed a genetic algorithm for parameter selection optimization. Wang et al. [
29] introduced graph structure in high-dimensional Linear Discriminant Analysis (LDA) and demonstrated that the method could improve classification accuracy and variable selection. Huang and Liang [
30] demonstrated that the SCAD-Net penalty has excellent properties and performed simulation analysis and experiments on several large cancer datasets.
The main research questions of this article can be summarized into two aspects. Firstly, we investigate how to select representative indicators from a large number of financial metrics using dimensionality reduction methods for financial risk warnings in Chinese listed companies. Secondly, we investigate how to introduce regularization techniques and graph structure models from high-dimensional statistical methods to improve the variable selection effect.
By combining ideas from previous literature, this paper proposes a graph structure model for variable selection that incorporates correlation information between explanatory variables. This model is then integrated into the Cox model to establish a GR-Cox model with a graph structure, which is applied to financial early warning for listed enterprises. The innovations of this paper include the following: (1) introducing the graph structure model into the variable selection to incorporate th ecorrelation information among explanatory variables and smoothing the coefficients; (2) applying the graph structure model to financial risk early warning for listed companies, utilizing the graph structure relationship among variables to improve variable selection and forecasting accuracy; (3) providing an algorithmic procedure for solving optimization problems containing and Laplace penalty terms under the coordinate descent method.
The remainder of this paper is structured as follows: in
Section 2, we present the GR-Cox model with a graph structure, which incorporates the Cox model,
penalty, and graph structure. Additionally, we provide an algorithm for solving the model.
Section 3 consists of a Monte Carlo simulation analysis, where we set the relevant parameters and conduct numerical simulations. Furthermore, we analyze the obtained results. In
Section 4, we focus on empirical analysis by selecting financial indicators of listed companies. This section primarily covers the selection of financial indicators, the analysis of correlation among these indicators, the model’s results, and prediction analysis. Finally, in
Section 5, we offer a summary of our findings and provide an outlook for future research.
5. Conclusions
The presence of correlation information between financial indicators may affect the accuracy of classic financial early warning models in the area of financial risk early warning systems. To address this issue, a complex network theory is utilized to construct a graph structure based on the sample information of financial indicators. This approach not only captures the level of correlation between two financial indicators but also the interconnections within the system where all indicators are situated. This paper presents the GR-Cox model, which integrates the graph network structure into the Cox proportional hazards model. Variable selection is accomplished via regularization, and a quadratic approximation is employed for the partial likelihood function of Cox. An alternative parameter is introduced for the solution, and a coefficient estimation is performed using the coordinate descent algorithm. Simulation results demonstrate the superior indicator selection effect and accuracy of the GR-Cox model compared to the comparison models.
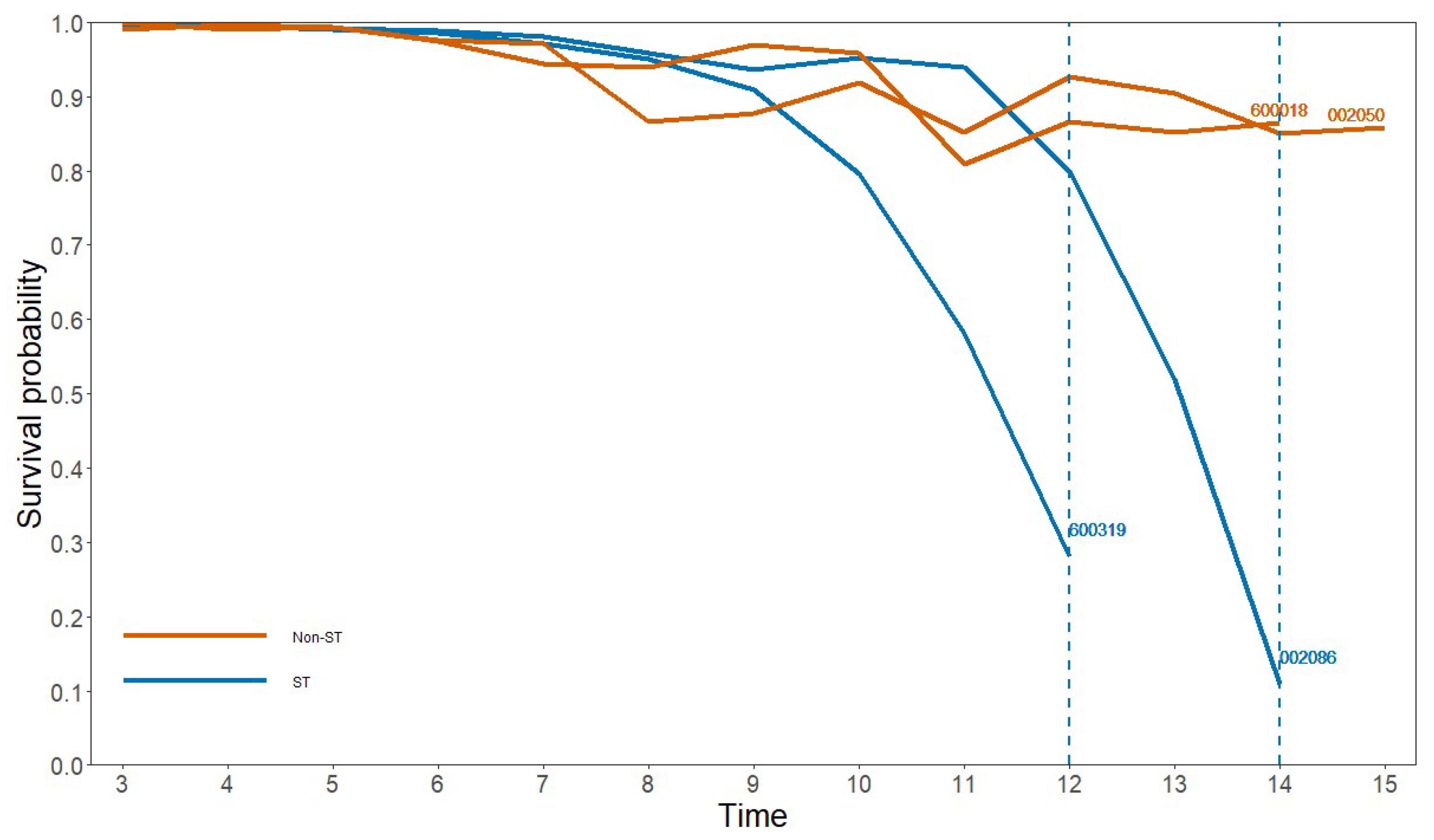
We analyzed 826 companies using 54 indicators from seven aspects. Ultimately, 10 indicators were included in the final financial risk prediction model. The model passed the likelihood ratio, Wald, and score tests. Specifically, the GR-Cox model selected two indicators from the solvency category, five indicators from the profitability category, and one indicator each from the cash flow, development capacity, and per share metrics categories. The coefficients of the gearing ratio, equity ratio, and operating cost ratio were 0.173, 0.054, and 0.013, respectively, indicating their positive impact on the likelihood of financial risk in listed companies. Increasing the values of these financial indicators would lead to a higher probability of financial risk. On the other hand, increasing the values of the remaining seven financial indicators will reduce the probability of a company’s financial risk. It is important for company managers, investors, and creditors to closely monitor these financial indicators and make appropriate adjustments when assessing the potential for future financial distress. Empirical research demonstrates that the GR-Cox model possesses the capability to dynamically forecast the survival probability of companies. During the initial years of a company’s listing, its survival probability remains at a relatively high level. However, as the operational pressures on the company intensify, if it encounters a financial risk, the GR-Cox model can accurately calculate the decrease in the survival probability. Compared with other models, our model exhibits high accuracy for both ST and non-ST samples, showcasing its outstanding predictive performance.
This study offers several avenues for further exploration. The prior coefficients of the model are obtained from ridge regression estimation, but more effective prior information can be obtained via other methods in future studies. Additionally, other penalties such as SCAD and MCP can be applied in variable selection, or other group class penalties such as Group LASSO can be used. The proposed model can also be extended to other risk control areas. For example, in banking, insurance, and bond markets, the model can be used to assess customers’ credit risks, predict default probabilities, and assist institutions in making informed decisions. Furthermore, the model can be expanded to other areas such as supply chain finance, personal credit assessment, and bank bankruptcy prediction, providing accurate default warnings and risk management tools for various stakeholders.







{kind=link}
{kind=link}
{kind=link}