1. Introduction
In the past few decades, cities have witnessed urban sprawl and continuous population growth in tandem with the demand for transportation. Residents in urban areas generally have two options for transportation: public transit or private cars. Public transit is emphasized over private cars in some aspects, including traffic congestion relief [
1], emissions reduction [
2,
3], air quality improvement [
4], and a lower price, since the same amount of travel demand can be satisfied by much fewer vehicles. For these reasons, public transit is regarded as a vital part of sustainable transportation and is supported by the government. A reliable public transport system encourages residents to choose environmentally friendly travel modes and promotes sustainable development in three dimensions: environment, economy, and society [
5].
One problem in bus operations is called bus bunching, referring to the phenomenon when two or more buses serving the same line arrive at a stop simultaneously [
6]. Several factors contribute to this problem. Compared with metro systems that are equipped with tracks and run underground, bus operations are more susceptible to road conditions (e.g., signal control, accidents, congestion, and weather). In addition to external disturbances, the differences in driving behavior increase the variability of bus travel time, and the uncertainties in passengers’ demand also cause the variability of bus dwell time. The external and internal disruption could result in irregular service headways, and the deviations from the regular headways accumulate and amplify when buses move along the corridor. The buses with larger headways are likely to serve more passengers than average at stops and will be further delayed.
Bus bunching is undesirable for both transit users and transit operators. For passengers, bus bunching would lead to longer waiting times and travel times due to irregular and larger headways. For transit operators, the occupancy profiles are highly unbalanced since the leading buses tend to load more passengers and the following buses have fewer, resulting in the issue of wasting bus resources. Another disadvantage for operators is higher costs, as they need to provide a higher frequency of bus services to offset the longer waiting time caused by bunching.
One major characteristic of bus bunching lies in the irregular headways between buses, and equalizing the headways is the common approach to addressing this problem. With even headways, buses will have a more balanced load distribution, and passengers will experience reduced waiting time and travel time.
Many researchers have proposed various control strategies to alleviate the bus bunching problem caused by the inherent instability of the bus transit system, such as bus holding, stop-skipping, rescheduling, and traffic signal priority. In recent years, machine learning has achieved remarkable success in many fields and has been an attractive topic in both academia and industry. By contrast with supervised and unsupervised learning, reinforcement learning mainly relies on the experience generated by the interaction with the environment to make sequential decisions, aiming to maximize the expected reward. Novel control methods built upon reinforcement learning can handle complex decision problems and have already surpassed humans in domains such as Go and electronic games [
7,
8,
9]. With the application of reinforcement learning-based holding strategies, this study aims to address bus bunching and improve reliability in the bus transit system, considering the uncertainty of bus travel times and passenger demands.
The remainder of this paper is structured as follows:
Section 2 reviews the literature on control strategies and the application of reinforcement learning to bus control. In
Section 3, the characteristics and assumptions of the bus system are presented.
Section 4 formulates the real-time holding problem as a decentralized partially observable Markov decision process (Dec-POMDP), introduces the deep reinforcement learning framework, and provides details of the event-driven simulator.
Section 5 conducts experiments and analyzes the performance of the proposed approach against other strategies.
Section 6 summarizes the findings and provides directions for future work.
2. Literature Review
To achieve reliability and effectiveness in bus systems, a variety of control strategies have been proposed and proven to be useful. By allowing buses to skip some stops, stop-skipping control is expected to narrow the large headways so that the rear buses can catch up with the preceding buses [
10,
11,
12]. The main idea of the rescheduling strategy is to modify the dispatching time of future trips from the terminal (the first stop) [
13,
14]. The traffic signal priority strategy focuses on the optimization of the traffic flow by defining the combination of traffic lights for delaying or releasing buses [
15,
16]. Another strategy to prevent bunching is speed regulation, which controls the bus’s speed along its route to maintain a regular headway [
17,
18,
19]. However, these solutions have some limitations in practice: Stop-skipping will force the waiting passengers at skipped stops to board the next bus, which in turn frustrates their interest in using public transport. Speed regulation requires a non-congested road situation in which the bus can be less affected by the surroundings and then freely adjust its speed.
Among these control strategies, bus holding control, in which a bus is detained for an extra period at a stop, has emerged as a widely applied method to intervene in bus operations in practice due to its maneuverability. Fu and Yang investigated two holding control strategies with real-time information: one-headway-based holding control and two-headway-based holding control. The former considered only the headway to the front bus (i.e., forward headway), while the latter takes forward headway and backward headway into account [
20]. Zhao et al. proposed a holding control approach based on negotiation between two agents, aiming to minimize passengers’ waiting time while considering nonstationary passenger arrivals [
21]. Considering vehicle capacity constraints, Zolfaghari et al. formulated a mathematical control model minimizing the waiting time of both passengers who arrive at a stop and those who are left behind at a stop due to an overloaded bus [
22]. To maintain regular headways, scholars introduced an adaptive control scheme that dynamically determines bus holding times based on real-time headway information [
23,
24]. Moreira-Matias et al. developed a mathematical model that incorporates dynamic running times and demand to produce a plan of holding times for all running vehicles [
25]. While bus overtaking is not allowed in most works, Wu et al. proposed a propagation model that considers overtaking, distributed passenger boarding behavior, and bus capacity, introducing a quasi-first-depart-first-hold rule to minimize the deviation from the targeted headway [
26]. Different from the aforementioned studies, which only utilized actual data, Andres and Nair managed to address bus bunching by first predicting headway data and then adopting dynamic holding strategies based on predicted data [
27]. However, these traditional approaches primarily focus on the short-term impact of each single decision and may teach short-sighted strategies. It would be important to explore the long-term effect of each control decision and achieve system-wide efficiency.
The recent process of deep reinforcement learning has facilitated the development of innovative solutions utilizing real-time information. Recent works in reinforcement learning have shown great promise for solving complex sequential decision-making problems since this emerging technique based on the sequential process excels at capturing long-term feedback [
28,
29,
30]. As urban transportation is a complex system, reinforcement learning has been quickly adopted by scholars in the field of transportation to aid in the development of intelligent transportation systems. Researchers presented a distributed cooperative holding control formulation based on a multi-agent reinforcement learning (MARL) framework to optimize real-time operations of the public transport system [
31]. However, their approach has limitations in utilizing the full potential of deep reinforcement learning and learned policies with limited state space. Using unlimited state space, a study introduced a deep reinforcement learning approach to implement real-time holistic holding control for high-frequency services [
32]. In an effort to achieve headway equalization, a dynamic holding control strategy in a multi-agent deep reinforcement learning framework was successfully implemented in a deterministic environment [
33]. To address bus bunching, some researchers proposed a machine learning-based procedure merging holding control with adjusting cruising speed, which controls the travel time between stops and ignores the road conditions [
34,
35]. Although these novel reinforcement learning methods have showcased satisfying results, this brief literature review shows some research gaps: Most proposed reinforcement learning algorithms are trained on simulators with fixed time steps, making the learning process computationally expensive and limiting their application to the real world. Moreover, previous works often assume deterministic inter-stop travel times and demand patterns and thus overlook the stochastic nature of bus systems.
To solve the problem of the computation-consuming fixed-time-step simulator and the stochastic nature of traffic flows and passenger demand, the present paper presents a reinforcement learning framework to achieve bus system efficiency. The main contributions of the work are summarized as follows: (1) A novel deep reinforcement learning framework is proposed for real-time holding control in a multi-agent system. By formulating the holding problem as a decentralized partially observable Markov decision process, we introduce a decentralized policy for making decisions and adopt a novel algorithm based on deep Q-network and parameter sharing to train the agent. The learned policy can capture the long-term effect of each control decision and is superior to baseline strategies; (2) an event-driven simulator is developed, on which the experiments and result analyses are conducted. Compared to the traditional fixed-time-step simulator, the event-based technique mitigates the problem of data sparsity and achieves a substantial computational advantage. Moreover, the policy trained on such a simulator could effectively transfer to the real world; (3) we consider a bus transit system, taking into account the stochastic vehicle travel times and passenger demand, which characterize the stochasticity of the bus system. Notation is defined as needed throughout the paper and is summarized in
Table 1 for the reader’s convenience.
3. Bus System Model Formulation
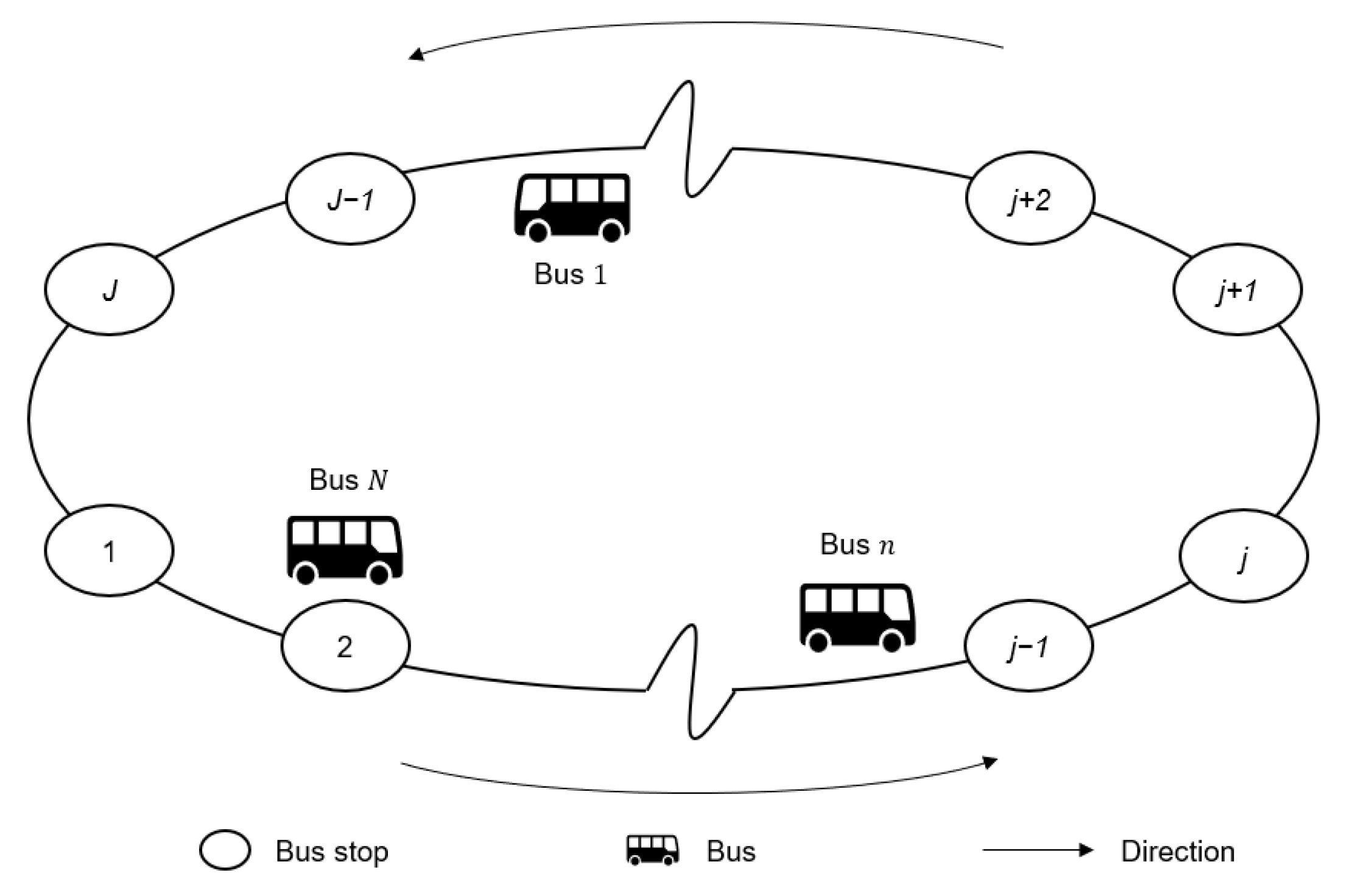
Consider the one-way loop bus corridor depicted in
Figure 1, consisting of
bus stops and a fleet of
homogenous buses providing
trips. A single bus may serve multiple trips. Buses are dispatched from stop 1 at a regular interval
, serve all stops downstream (2, 3, …,
), and return to stop 1. Upon arrival at a bus stop, the buses require dwell times for passenger boarding and alighting, and control decisions are made after the dwelling process is completed. Overtaking is not allowed along the corridor, i.e., the leading bus trip
always precedes the following bus trip
. We assume that bus capacity is unlimited and passenger arrival follows a Poisson process. The assumption of unlimited capacity has minimal effects on the results, as the proposed approach ensures a balanced load among buses.
At stop 1, the bus fleet initiates its first cycle (bus trip
) with planned headways
, and we have the initial condition
for the first bus trip at stop 1:
For trip
(
) at stop 1, a bus cannot commence a new trip until it has completed the previous trip
, and the bus returns to stop 1 from the terminal stop (i.e., stop
). This can be expressed as:
When the bus
arrives at downstream stops
, the arrival time is written as:
The departure time of the bus
from the stop
is calculated as:
The dwell time,
, refers to the duration required to complete the boarding and alighting activities. We assume that the boarding and alighting times are linear functions of the number of passengers. Since most buses have two doors allowing for simultaneous boarding and alighting processes, the dwell time is determined by the longer duration between the boarding and alighting times:
The number of passengers boarding at a stop is determined by headway and arrival rate:
When a bus arrives at a stop, a portion of the passengers onboard will alight from the bus:
The number of passengers onboard a bus is updated after the passenger boarding and alighting process finishes at a stop:
In addition, considering all buses adhere to a strict sequential order to avoid overtaking, we ensure that a bus enters a stop after its predecessor has departed. The constraint is implemented as follows:
4. Methodology
Based on the design of the bus system model developed in
Section 3, we next present the deep reinforcement learning framework.
4.1. Event-Driven Simulator
An essential component for effectively applying deep reinforcement learning approaches is a suitable learning environment. However, the high stochasticity and randomness of the real-world environment make it difficult to train deep reinforcement learning algorithms. Additionally, the training process requires plenty of trajectories generated by repeated interaction with the environment, so relying solely on historical data is insufficient for training and evaluating algorithms. Researchers commonly build simulators calibrated with historical data to mimic the real-world environment.
Many methods for training reinforcement learning algorithms use simulators performed with fixed time steps. These simulators will result in a sparse number of decision activities in this holding problem since the bus control process is asynchronous and event-driven. The decisions are triggered by bus arrivals, and no holding decisions are made when buses are running along sections between stops. This case can be framed as a decentralized partially observable Markov decision process, detailed in the next section [
36]. Naturally, we view this multi-agent decision process as an event-driven process in which the bus agents choose actions when specific events occur, such as bus arrivals. Consequently, we developed an event-driven simulator.
By employing event-driven simulators, one can focus on specific timestamps regardless of redundant timestamps, significantly reducing the length of an episode. As a result, the training process becomes much more time-saving with such simulators. Considering the presence of numerous bus lines and buses in a metropolitan area, utilizing event-driven simulators will achieve a significant computational advantage.
4.2. Dec-POMDP and Parameter Sharing
In the framework, buses are running along the loop corridor. When a bus arrives at a stop, the bus system generates the states, and the holding decision is made based on the states. The reward is obtained upon the bus arriving at the next stop, according to the definition in
Section 4.3. Since each single bus can be treated as an independent agent, we model the holding problem as a Markov game and solve it via reinforcement learning [
37]. In its general form, a Markov game is defined by a tuple
, where
is the number of agents,
is the set of states,
is the set of joint actions,
denotes the state transition function from the current state to the next state after taking a joint action,
is a discount factor,
is the set of reward functions, and each reward
is determined by the current state and the joint actions:
. A policy dictates how agents execute joint action at each state, and the agents’ goal is to find an optimal policy that maximizes the expected sum of discounted rewards.
To solve the multi-agent reinforcement learning problem, one way is to train a centralized policy that maps the current state of the environment to joint action. However, this will lead to exponential growth in the state and action spaces with the number of agents [
38]. Moreover, the central controller incurs a significant communication overhead as it needs to communicate with each agent to exchange information in centralized settings [
39]. Coupled with the event-driven process, we deal with the intractability by factoring the joint action into individual components for each agent and modeling the holding problem as a decentralized partially observable Markov decision process. In discrete action systems, the size of the action space is reduced from
to
. Since all the individual agents in a decentralized reinforcement learning system can operate in parallel based on their individual action spaces, the learning speed is faster compared to a centralized agent exploring a larger action space [
40]. Another reason to adopt the decentralized framework lies in the uniqueness of the holding problem. The control decisions are triggered by vehicle arrivals, which means that one vehicle instead of all vehicles needs to take an action at a specific timestamp. The decentralized framework guarantees the asynchronous decision-making of the control problem.
In this framework, each bus agent has access to only partial observations of the environment and must make a decision based on its local observations. In the context of Dec-POMDP, an agent executes a decentralized policy that maps an agent’s local observations to an action. In our case, each individual bus agent observes its observations and determines its holding time based on the local observations upon arriving at a stop.
In addition, when agents are homogeneous, their policies can be trained more effectively using parameter sharing. With the parameter sharing approach, a common policy is adopted for all agents, allowing the training of the policy with the collective experiences of all agents. In this study, we enable agents to execute decentralized policies with shared parameters so that some off-the-shelf reinforcement learning algorithms, such as deep Q-network (DQN) or deep deterministic policy gradient, can be extended to multi-agent systems.
4.3. Components of Reinforcement Learning
Building upon the formulation in
Section 3, we consider a bus system with
bus trips and
stops. The basic components of the reinforcement learning framework for this holding problem are described below.
State: Within the Dec-POMDP context, the state used to determine the holding time relies on the agent’s local information. The state is defined as a four-dimensional vector indicating detailed information when the bus trip arrives at the stop , denoted as : the index of a stop is the location the bus is in; headway represents the bus trip’s regularity status; and account for bus load and passenger demand.
Action: A bus trip determines its holding time once it arrives at a bus stop. The holding duration is formulated as , where is a fixed positive value for the constraint of applying in practice and is a nonnegative integer. This design is a practical consideration. The discrete values can be encoded in a user interface, and the bus driver can easily interpret and execute these commands compared to continuous values. In our simulation experiments, we set and an action space . denotes no holding action executed and immediate dispatch of the bus after finishing passenger boarding and alighting.
Reward: One effective way to avoid bus bunching is to achieve headway equalization. To that end, the reward function is defined as the absolute value of the difference between the actual headway and the planned headway. The reward for an independent bus agent is designed as: . The closer the actual headway is to the planned one, the greater the reward.
In the aforementioned settings, the holding control process is framed as an event-driven process, and an event-driven simulator is built to train and test the proposed algorithm on it. When the bus trip arrives at the stop , it receives the state and chooses a holding action , leading to a state transition. It should be noted that once this bus trip arrives at the next stop , it will observe the next state and the reward feedback is calculated accordingly.
4.4. Training Algorithm
For the finite action space in this problem, the Q-learning algorithm is commonly suggested. Considering that the state space is infinite, we adopt an adapted version of the DQN method called PS-DQN, which incorporates the parameter sharing technique. The procedure of the PS-DQN training process is summarized in Algorithm 1.
| Algorithm 1. Training procedure of PS-DQN algorithm in a multi-agent system. |
Initialize the memory buffer to capacity .
Initialize the action-value function with random weights and target the action-value function with weights .
for episode to do
for trip to do
Initialize initial state;
if trip arrives at stop then
Obverse the current observation ;
Select action using the -greed policy with regard to ;
Execute action on an event-driven simulator and observe the next observation and reward ;
Store the experience () in the memory buffer ;
Sample a minibatch of experiences from ;
Calculate the target values via Equation (11);
Update by minimizing Equation (12);
end if
end for
Reset every episodes
end for |
We establish two sets of feedforward neural networks (FNN): the evaluation network and the target network . Both networks have the same architecture and are used to represent the action-value (also known as ) function, which maps from state and action to -values. The evaluation network updates its parameters at each training step, while the target network parameters are updated with a delay and remain fixed between individual updates. The advantage of using a separate target network is that it improves the stability of the training process.
Every time an event of bus arrival is triggered, this bus agent
observes its local state at the stop
,
. After the boarding and alighting process finishes, the agent takes an action
according to the
ε-greedy policy (i.e., selecting an action that produces the maximum Q-value with probability 1-
ε and selecting a random action with probability
ε). To balance exploration and exploitation, we apply the search-then-converge procedure [
41]. The agent’s exploration rate is higher at the beginning of training and decays to a minimum value during training. Once the bus imposes an action, the bus system environment changes accordingly. By the time the agent reaches the next stop
, it will observe the next state
and receive the reward
. This process generates an experience defined by
). With buses running in the bus system, we will accumulate a collection of experiences and store them in a memory buffer.
The goal of the algorithm is to learn a policy to enable the agents to achieve the expected discounted cumulative reward as large as possible. We draw a batch of experiences from the buffer and put the current states
and executed actions
as the input into the evaluation network and derive the predicted Q-values
where
is the parameters of the evaluation network. Consequently, we can calculate the target Q-values
:
where
is the immediate reward,
is the discount factor, and
is the parameters of the target network. The evaluation network is updated through supervised learning by minimizing the mean square loss function, which is formulated as:
Finally, we perform a gradient descent step on the loss function with respect to the evaluation network parameters . During this step, we update the evaluation network while keeping the target network unchanged. The target network is cloned from the evaluation network Q after a certain number of delay steps . This separation between updating the networks helps stabilize the learning process.
6. Conclusions
This paper introduces a novel approach based on deep reinforcement learning to tackle the issue of bus bunching. The proposed framework leverages the principles of reinforcement learning to enable each bus to act as an independent agent and implement a holding strategy, ultimately aiming to achieve global headway equalization. To facilitate the learning process, a real-time event-driven transit simulator has been developed, providing a realistic environment for training and evaluation. Furthermore, an efficient learning algorithm called PS-DQN has been devised, specifically tailored to train the deep neural network used in the framework.
Extensive experiments have been conducted to assess the effectiveness of the deep reinforcement learning framework against three baseline strategies. The results clearly demonstrate the superiority of the proposed approach across multiple performance metrics. Firstly, the framework achieves more equal headway distribution, effectively reducing the occurrence of bus bunching. This contributes to a more stable and reliable bus service. Additionally, the average waiting time for passengers is significantly reduced compared to the baseline strategies, indicating improved service quality and passenger satisfaction. The proposed framework addresses the issue of uneven bus loads at stops, ensuring efficient utilization of vehicle resources and improved passenger comfort. Finally, the average occupancy variation at stops is also decreased by the reinforcement learning-based approach.
Overall, the extensive experimental results validate the effectiveness of the deep reinforcement learning framework in improving various aspects of bus service performance. By achieving more equal headway, reducing average waiting time, balancing bus loads, and minimizing occupancy variability, the proposed approach offers a promising solution to address the challenges associated with bus bunching, ultimately enhancing the quality and efficiency of bus services.
For future work, besides achieving headway equalization in this paper, other objectives could be considered, such as minimizing the waiting time and/or trip travel time of passengers, minimizing the operational cost of operators, etc. Hence, the reward function in the reinforcement learning framework should be specifically designed. In addition, the integration of different control strategies, such as holding, stop-skipping, and speed control, has been a promising research direction that can derive better results than a single strategy.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}