
Developing the Actual Precipitation Probability Distribution Based on the Complete Daily Series
 ,
,
Abstract
:1. Introduction
2. Methods
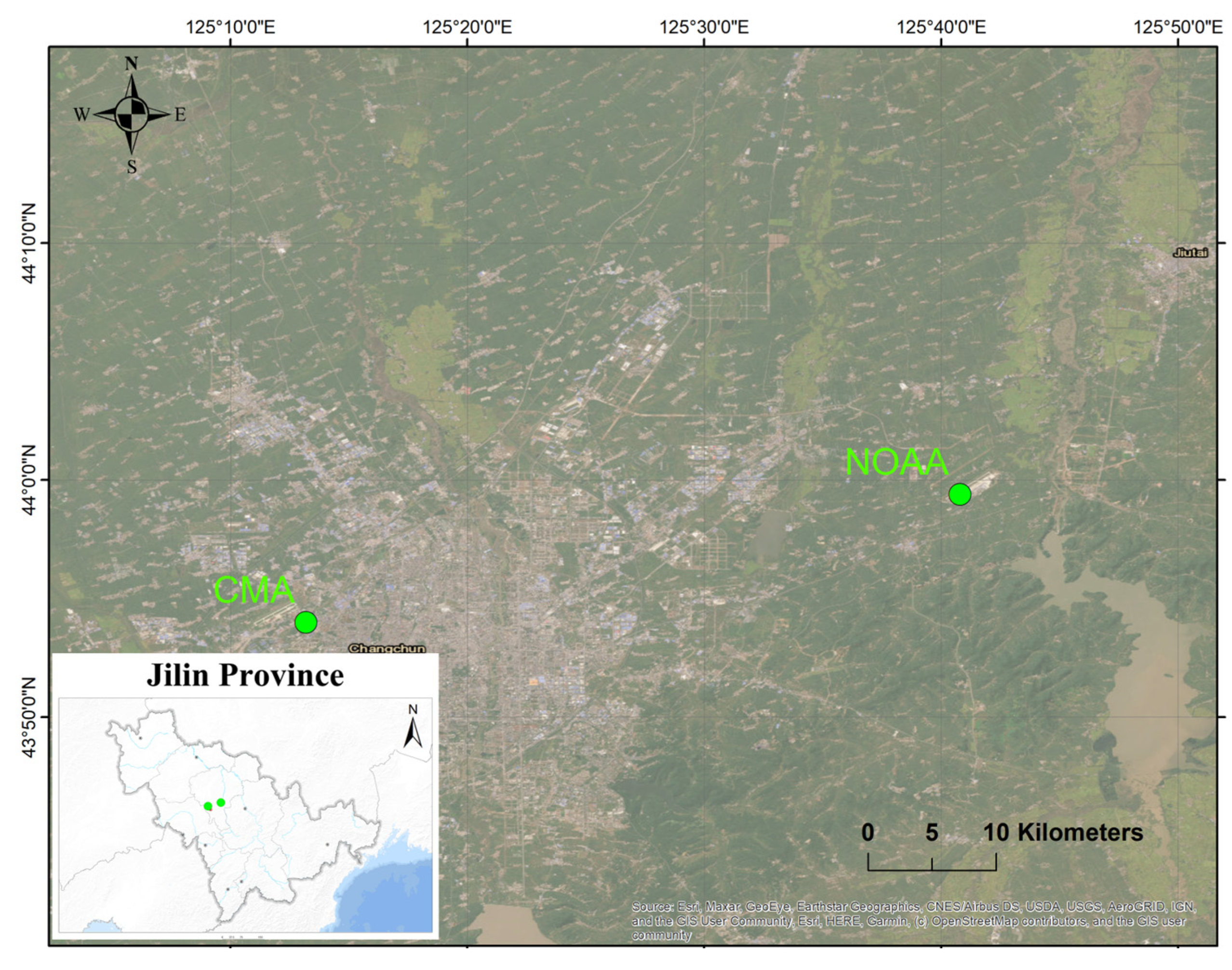
2.1. Data Preprocessing
2.2. Probability Distributions
2.3. Skill Assessment
2.4. Trend Analysis
3. Results and Discussion
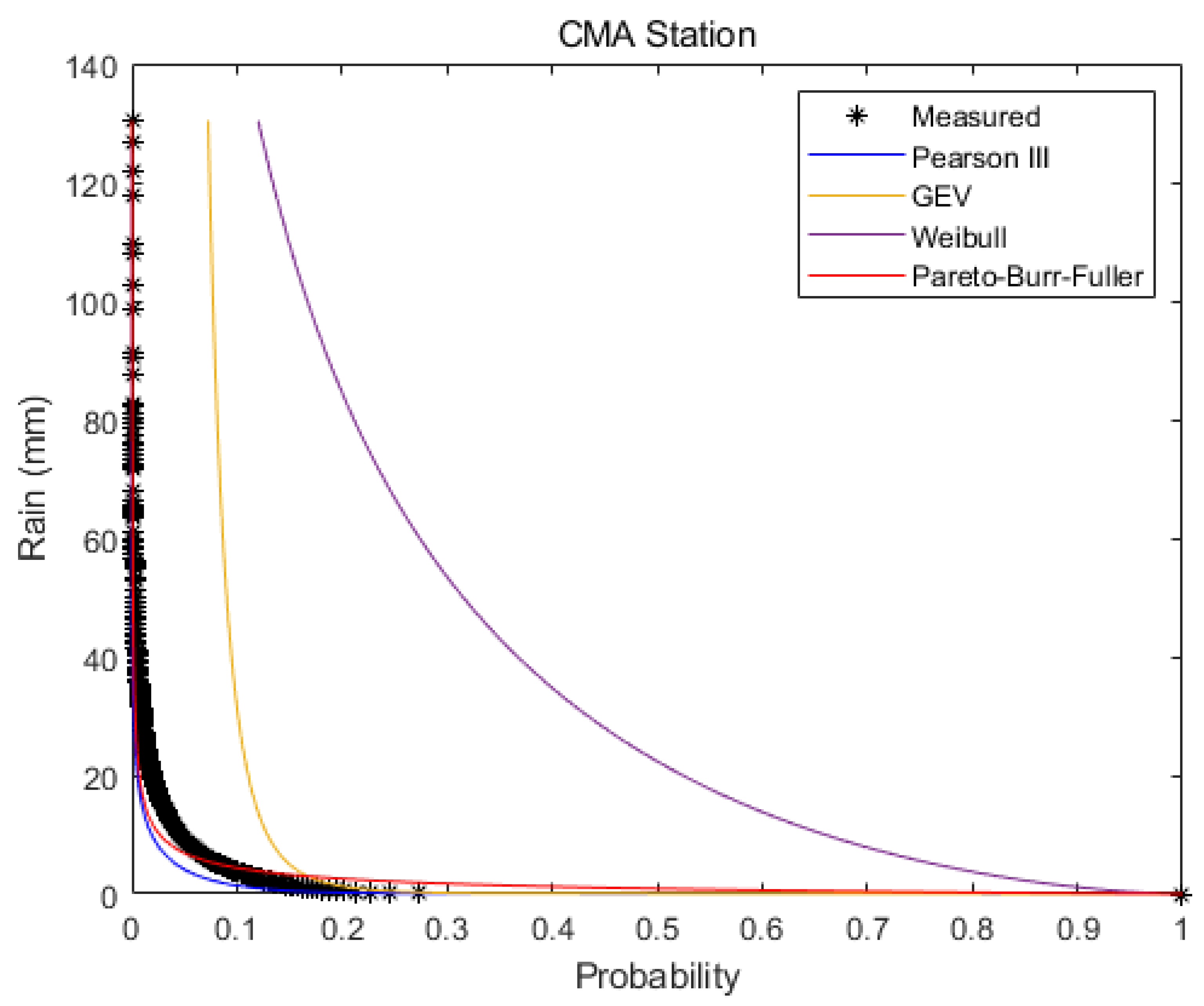
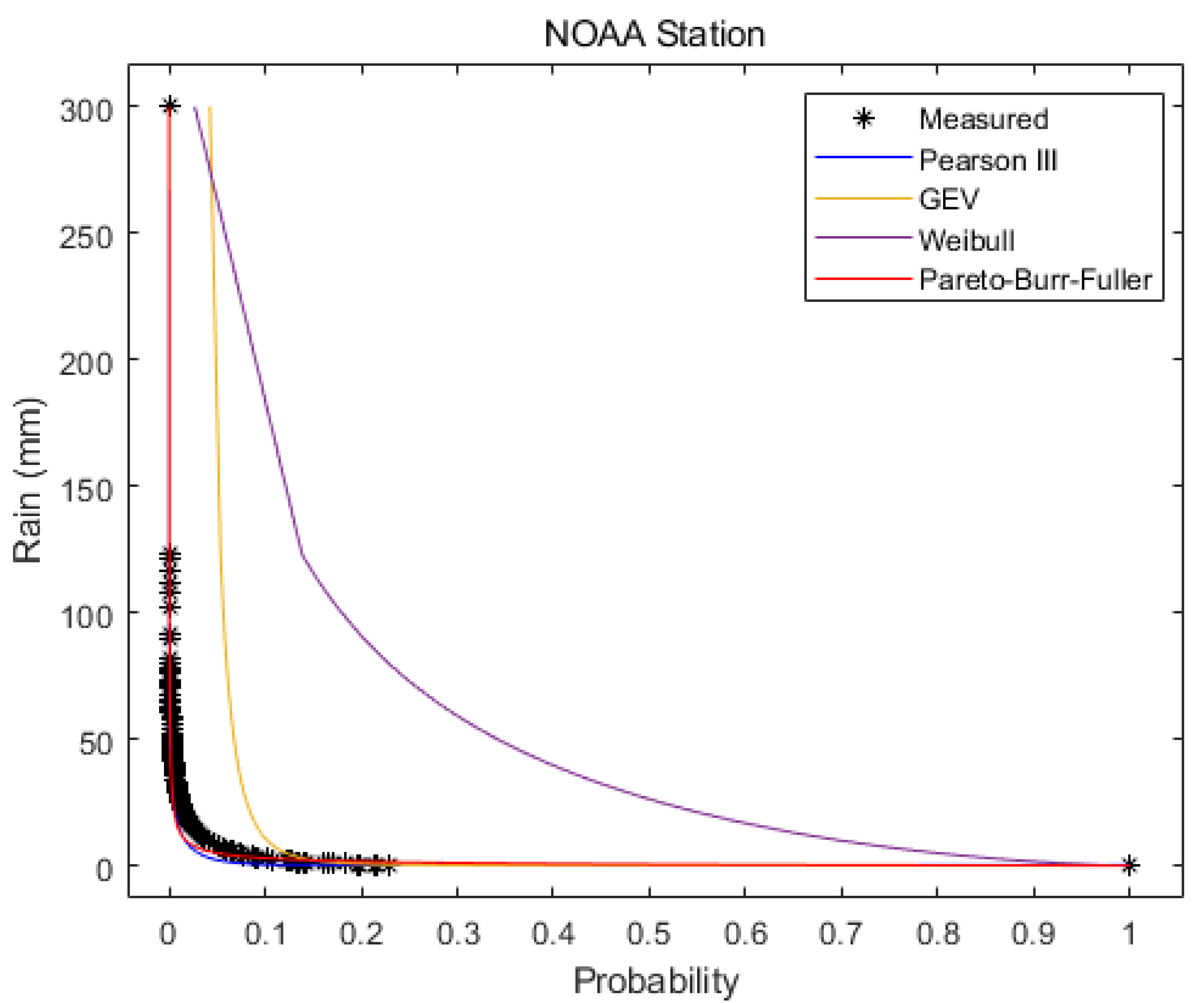
3.1. Frequency Distributions of the Daily Versus Wet-Day Series
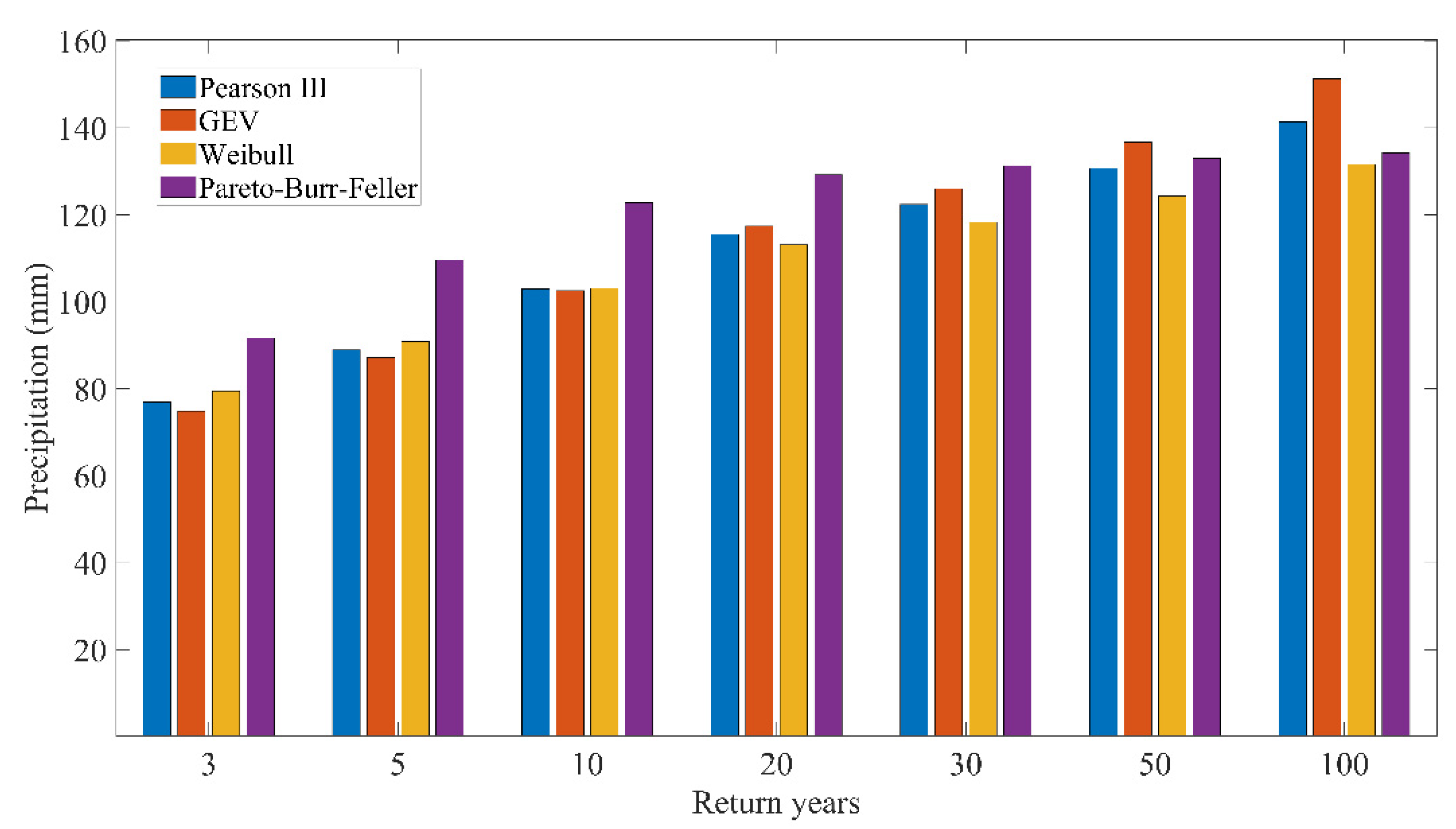
3.2. Return Periods Corresponding to the Daily Versus Wet-Day Series
3.3. Threshold of Data Independence
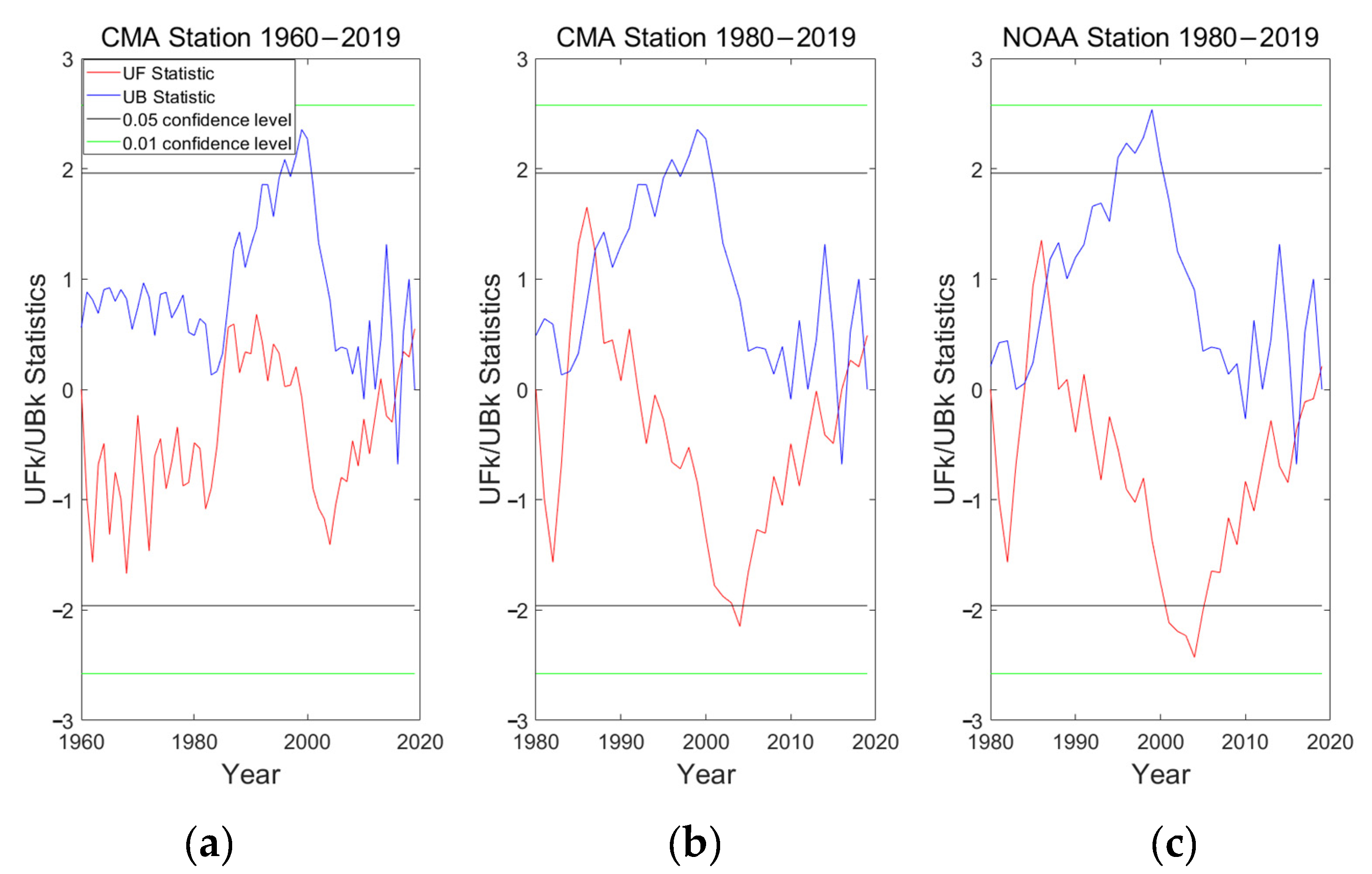
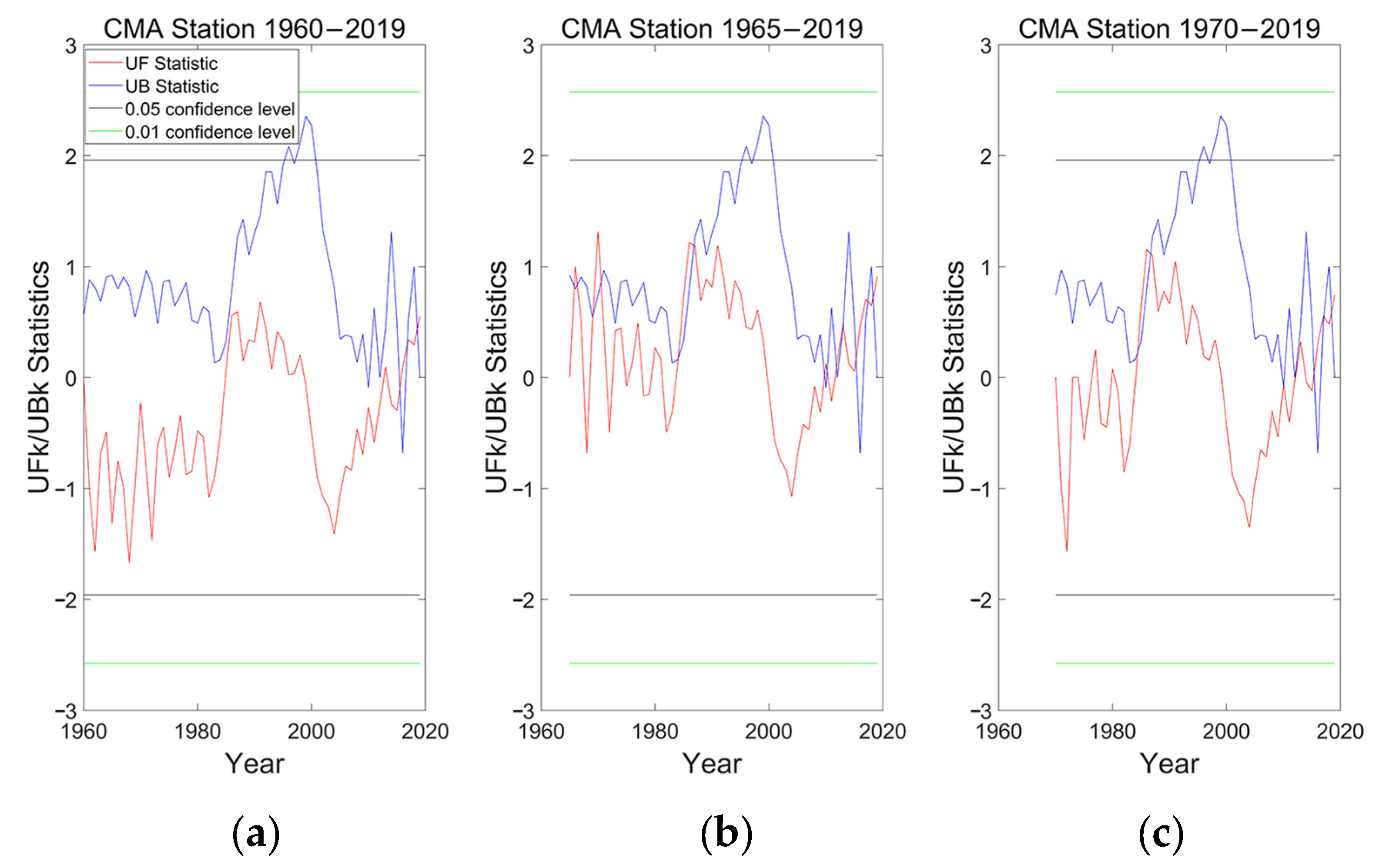
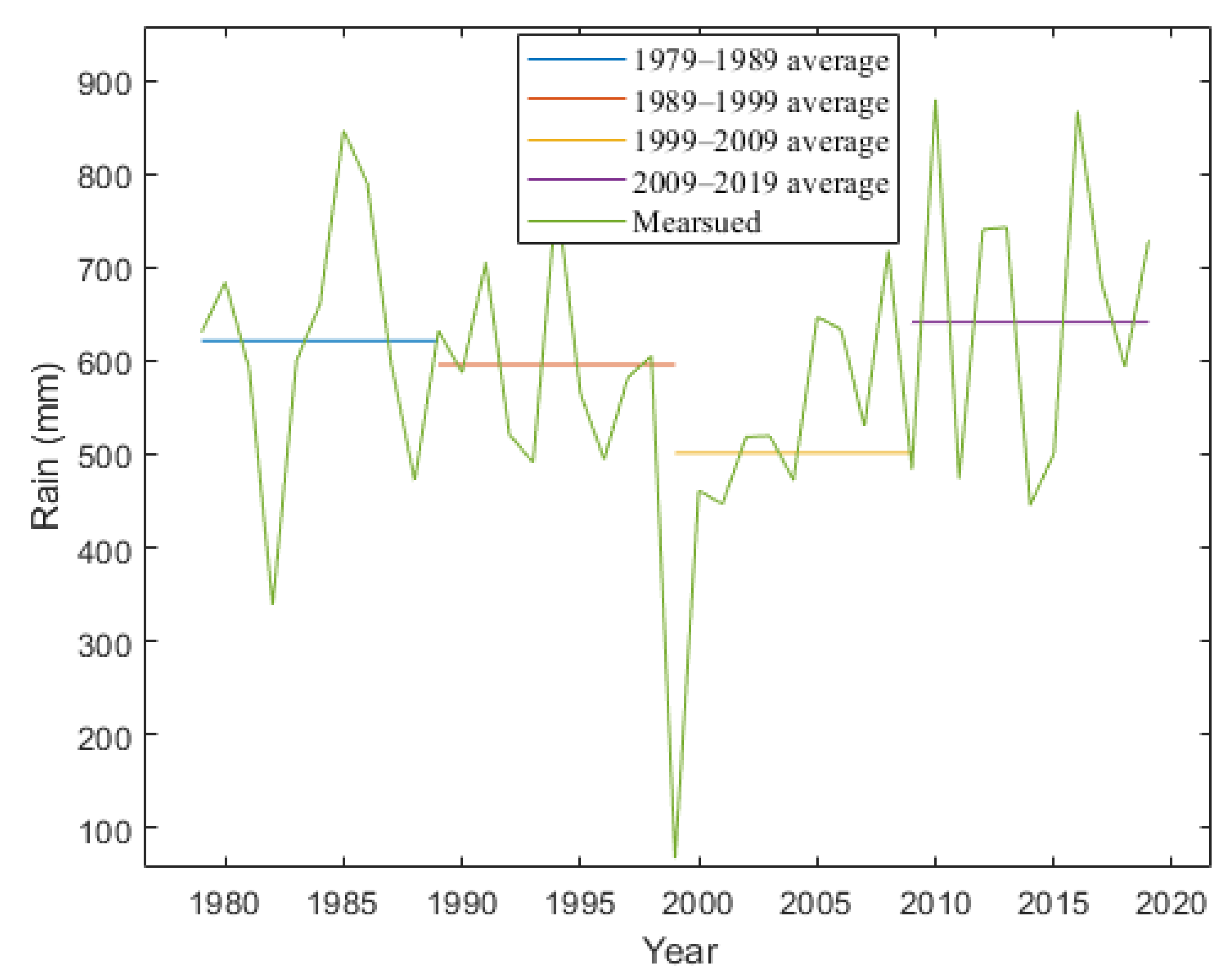
3.4. Trend Analysis
3.5. Missing Gaps
4. Conclusions
- (1)
- The use of complete time series in precipitation frequency analysis gave more realistic estimates of probabilities than the traditional methods relying on rainy days only. Based on the two separate weather stations, the Pearson III and PBF distributions established from the complete daily series were at least 458% and 227% more accurate in fitting with the observed complete daily series than the distributions established from the wet-day-only series. The return periods of historic rainfall should also be determined from the complete daily series rather than the wet-day-only series, since the latter might overestimate the rain depths of the studied return periods by at least 76% if the depths of the corresponding return periods are more closely represented by the real condition.
- (2)
- A clear threshold of 137 days was found in this study to separate the persistent or autocorrelated time series from the antipersistent or independent time series based on the climacogram analysis. This threshold, possibly varied case by case, was proposed as a practical way to validate the GEV model or as such required data independence and predetermine the lowest time step for the long-term trend tests.
- (3)
- The choice of the starting and ending points had a significant influence on the M-K test and easily led to different mutation points for trend analysis.
- (4)
- The test of K-permutation sampling revealed that the lack of data would affect the accuracy of the frequency analysis only after the missing data reached 70% of the whole dataset. The wet-day series were less affected by the data gaps than the complete time series.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhong, S.; Zhuang, Y.; Hu, S.; Chen, Z.; Ding, W.; Feng, Y.; Deng, T.; Liu, X.; Zhang, Y.; Xu, D.; et al. Verification and Assessment of Real-time Forecasts of Two Extreme Heavy Rain Events in Zhengzhou by Operational NWP Models. J. Trop. Meteorol. 2021, 27, 406–417. [Google Scholar]
- Benson, M.A. Uniform Flood-Frequency Estimating Methods for Federal Agencies. Water Resour. Res. 1968, 4, 891–908. [Google Scholar] [CrossRef]
- Fréchet, M. Sur la loi de probabilité de l’écart maximum. Ann. Soc. Math. Pol. 1927, 6, 93–116. [Google Scholar]
- Weibull, W. A statistical distribution function of wide applicability. J. Appl. Mech. 1951, 18, 293–297. [Google Scholar] [CrossRef]
- Gumbel, E.J. Statistics of Extremes; Courier Corporation: North Chelmsford, MA, USA, 1958. [Google Scholar]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Jenkinson, A.F. The frequency distribution of the annual maximum (or minimum) values of meteorological elements. Q. J. R. Meteorol. Soc. 1955, 81, 158–171. [Google Scholar] [CrossRef]
- Serinaldi, F.; Petroselli, A.; Grimaldi, S. A continuous simulation model for design-hydrograph estimation in small and ungauged watersheds. Hydrol. Sci. J. 2012, 57, 1035–1051. [Google Scholar]
- Grimaldi, S.; Volpi, E.; Langousis, A.; Papalexiou, S.M.; De Luca, D.L.; Piscopia, R.; Nerantzaki, S.D.; Papacharalampous, G.; Petroselli, A. Continuous hydrologic modelling for small and ungauged basins: A comparison of eight rainfall models for sub-daily runoff simulations. J. Hydrol. 2022, 610, 127866. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R. Regional Frequency Analysis; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Lin, B.; Bonnin, G.M.; Martin, D.L.; Parzybok, T.; Yekta, M.; Riley, D. Regional Frequency Studies of Annual Extreme Precipitation in the United States Based on Regional L-Moments Analysis. In Proceedings of the World Environmental and Water Resource Congress 2006: Examining the Confluence of Environmental and Water Concerns, Omaha, NB, USA, 21–25 May 2006. [Google Scholar]
- Hosking, J.R. L-moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B Methodol. 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Wilks, D. Multisite generalization of a daily stochastic precipitation generation model. J. Hydrol. 1998, 210, 178–191. [Google Scholar] [CrossRef]
- Naghavi, B.; Yu, F.X. Regional frequency analysis of extreme precipitation in Louisiana. J. Hydraul. Eng. 1995, 121, 819–827. [Google Scholar] [CrossRef]
- Xie, Y. Urban drainage and waterlogging disaster prevention planning. China Water Wastewater 2013, 29, 105–108. [Google Scholar]
- Shao, Y.-m.; Shao, D.-n.; Ma, J.-s. Practice and Suggestion on New Generation of Formula of Urban Rainstorm Intensity. China Water Wastewater 2012, 28, 19–22. [Google Scholar]
- Yifan, J.; Songbai, S. Optimization of flood frequency distribution parameter estimation method based on TL-moments. Water Resour. Prot. 2021, 37, 34–39. [Google Scholar]
- Ye, L.; Hanson, L.S.; Ding, P.; Wang, D.; Vogel, R.M. The probability distribution of daily precipitation at the point and catchment scales in the United States. Hydrol. Earth Syst. Sci. 2018, 22, 6519–6531. [Google Scholar] [CrossRef]
- Yevjevich, V. Probability and Statistics in Hydrology; Water Resources Publications: Highlands Ranch, CO, USA, 1972. [Google Scholar]
- El Adlouni, S.; Bobée, B.; Ouarda, T.B.M.J. On the tails of extreme event distributions in hydrology. J. Hydrol. 2008, 355, 16–33. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Uncertainty, entropy, scaling and hydrological stochastics. 1. Marginal distributional properties of hydrological processes and state scaling/Incertitude, entropie, effet d’échelle et propriétés stochastiques hydrologiques. 1. Propriétés distributionnel. Hydrol. Sci. J. 2005, 50, 381–404. [Google Scholar]
- Koutsoyiannis, D. Uncertainty, entropy, scaling and hydrological stochastics. 2. Time dependence of hydrological processes and time scaling/Incertitude, entropie, effet d’échelle et propriétés stochastiques hydrologiques. 2. Dépendance temporelle des processus hydrologiques et échelle temporelle. Hydrol. Sci. J. 2005, 50, 405–426. [Google Scholar]
- Shoji, T.; Kitaura, H. Statistical and geostatistical analysis of rainfall in central Japan. Comput. Geosci. 2006, 32, 1007–1024. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D. Stochastic synthesis approximating any process dependence and distribution. Stoch. Environ. Res. Risk Assess. 2018, 32, 1493–1515. [Google Scholar] [CrossRef]
- Iliopoulou, T.; Koutsoyiannis, D. Projecting the future of rainfall extremes: Better classic than trendy. J. Hydrol. 2020, 588, 125005. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Montanari, A. Negligent killing of scientific concepts: The stationarity case. Hydrol. Sci. J. 2015, 60, 1174–1183. [Google Scholar] [CrossRef]
- Borah, P.; Hazarika, S.; Prakash, A. Assessing the state of homogeneity, variability and trends in the rainfall time series from 1969 to 2017 and its significance for groundwater in north-east India. Nat. Hazards 2022, 111, 585–617. [Google Scholar] [CrossRef]
- Said, M.; Komakech, H.C.; Munishi, L.K.; Muzuka, A.N.N. Evidence of climate change impacts on water, food and energy resources around Kilimanjaro, Tanzania. Reg. Environ. Chang. 2019, 19, 2521–2534. [Google Scholar] [CrossRef]
- Suescún, D.; Villegas, J.C.; León, J.D.; Flórez, C.P.; García-Leoz, V. Vegetation cover and rainfall seasonality impact nutrient loss via runoff and erosion in the Colombian Andes. Reg. Environ. Chang. 2017, 17, 827–839. [Google Scholar] [CrossRef]
- Lal, M. Implications of climate change in sustained agricultural productivity in South Asia. Reg. Environ. Chang. 2011, 11, 79–94. [Google Scholar] [CrossRef]
- Yun, P.; Jianxin, X.; Huatang, R. The Variations of Rainfall Belt and Its Impact in China. China Rural Water Hydropower 2015, 5, 45–48. [Google Scholar]
- Li, W.; Zhao, S.; Chen, Y.; Wang, Q.; Ai, W. State of China’s Climate in 2020. Atmos. Ocean. Sci. Lett. 2021, 14, 9–14. [Google Scholar] [CrossRef]
- Li, Q. Comparative study of parameter estimation methods for Pearson type III curves based on numerical integration. Water Resour. Plan. Des. 2018, 12, 54–59. [Google Scholar]
- He, S.; Li, Z.; Liu, X. An improved GEV boosting method for imbalanced data classification with application to short-term rainfall prediction. J. Hydrol. 2023, 617, 128882. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Statistics of extremes and estimation of extreme rainfall: I. Theoretical investigation. Hydrol. Sci. J. 2004, 49, 575–590. [Google Scholar] [CrossRef]
- Montoya, J.; Díaz-Francés, E.; Figueroa, G. Estimation of the reliability parameter for three-parameter Weibull models. Appl. Math. Model. 2019, 67, 621–633. [Google Scholar] [CrossRef]
- Reza Najafi, M.; Moradkhani, H. Analysis of runoff extremes using spatial hierarchical Bayesian modeling. Water Resour. Res. 2013, 49, 6656–6670. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D. Climacogram versus autocovariance and power spectrum in stochastic modelling for Markovian and Hurst–Kolmogorov processes. Stoch. Environ. Res. Risk Assess. 2015, 29, 1649–1669. [Google Scholar] [CrossRef]
- Iliopoulou, T.; Koutsoyiannis, D. Revealing hidden persistence in maximum rainfall records. Hydrol. Sci. J. 2019, 64, 1673–1689. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. HESS Opinions “A random walk on water”. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef]
- Hurst, H.E. Long-term storage capacity of reservoirs. Trans. Am. Soc. Civ. Eng. 1951, 116, 770–799. [Google Scholar] [CrossRef]
- Kendall, M.G. Rank Correlation Methods; J.F. Griffin Publishing: Williamstown, MA, USA, 1948. [Google Scholar]
- Mann, H.B. Nonparametric tests against trend. Econom. J. Econom. Soc. 1945, 13, 245–259. [Google Scholar] [CrossRef]
- Hamed, K.H.; Rao, A.R. A modified Mann-Kendall trend test for autocorrelated data. J. Hydrol. 1998, 204, 182–196. [Google Scholar] [CrossRef]
- Sen, P.K. Estimates of the regression coefficient based on Kendall’s tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Yue, S.; Wang, C. The Mann-Kendall test modified by effective sample size to detect trend in serially correlated hydrological series. Water Resour. Manag. 2004, 18, 201–218. [Google Scholar] [CrossRef]
- Yildirim, G.; Rahman, A. Homogeneity and trend analysis of rainfall and droughts over Southeast Australia. Nat. Hazards 2022, 112, 1657–1683. [Google Scholar] [CrossRef]
- Yuan, J.; Xu, Y.; Wu, L.; Wang, J.; Wang, Y.; Xu, Y.; Dai, X. Variability of precipitation extremes over the Yangtze River Delta, Eastern China, during 1960–2016. Theor. Appl. Climatol. 2019, 138, 305–319. [Google Scholar] [CrossRef]
- Yilmaz, B. Analysis of hydrological drought trends in the GAP region (southeastern Turkey) by Mann-Kendall test and innovative sen method. Appl. Ecol. Environ. Res. 2019, 17, 3325–3342. [Google Scholar] [CrossRef]
- Wang, J. Determining the most accurate program for the Mann-Kendall method in detecting climate mutation. Theor. Appl. Climatol. 2020, 142, 847–854. [Google Scholar] [CrossRef]
- Wang, C.; Lin, K. Fitting method of Weibull equation: Application of optimum seeking method to the fitting of the progressive curve of plant disease. J. South China Agric. Univ. 1986, 1, 17–20. [Google Scholar]
- Wei, X.G.Z. The analysis for the drought law in Changchun region. Jilin Water Resour. 2008, 6, 19–22. [Google Scholar]
- Gao, Q.; Sun, Y.; You, Q. The northward shift of Meiyu rain belt and its possible association with rainfall intensity changes and the Pacific-Japan pattern. Dyn. Atmos. Ocean. 2016, 76, 52–62. [Google Scholar] [CrossRef]
- Liu, J.; Shen, Z.; Chen, W.; Chen, J.; Zhang, X.; Chen, J.; Chen, F. Dipolar mode of precipitation changes between North China and the Yangtze River valley existed over the entire Holocene: Evidence from the sediment record of Nanyi Lake. Int. J. Climatol. 2021, 41, 1667–1681. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distributions | NSE (Modeled Complete Series vs. Measured Complete Series) | NSE (Modeled Wet-Day Series vs. Measured Complete Series) | NSE (Modeled Wet-Day Series vs. Measured Wet-Day Series) |
|---|---|---|---|
| Pearson III | 0.994 | −0.2404 | 0.990 |
| PBF | 0.881 | −0.5283 | 0.955 |
| GEV | −3.85 × 104 | −4.59 × 104 | −7.06 × 105 |
| Weibull | - | −207.5789 | −71.68 |
| Distributions | NSE (Modeled Complete Series vs. Measured Complete Series) | NSE (Modeled Wet-Day Series vs. Measured Complete Series) | NSE (Modeled Wet-Day Series vs. Measured Wet-Day Series) |
|---|---|---|---|
| Pearson III | 0.930 | −0.2600 | 0.922 |
| PBF | 0.838 | −0.6605 | 0.952 |
| GEV | −2.03 × 1021 | −2.47 × 1021 | −2.34 × 103 |
| Weibull | - | −246.7235 | −62.20 |
| Inputs | 3Y | 5Y | 10Y | 20Y | 30Y | 50Y | 100Y |
|---|---|---|---|---|---|---|---|
| Complete Series | 0.09 | 0.45 | 2.96 | 8.64 | 13.24 | 20.08 | 30.79 |
| Wet-day Series | 3.27 | 7.40 | 15.64 | 25.89 | 32.53 | 41.39 | 54.09 |
| Wet daily series | −0.0112 | 0.1632 | 0.0111 |
| Complete daily series | −0.0214 | 0.1307 | 0.0211 |
| Annual extremes | −0.2293 | −0.2037 | 0.1954 |
| Time Series | Data Type | Trend | NSE | STD |
|---|---|---|---|---|
| 1974–1982 | Complete | Decreasing | 0.9721 | 5.5297 |
| 1982–1990 | Complete | Increasing | 0.9946 | 6.1688 |
| 1974–1982 | Wet day | Decreasing | 0.9603 | 9.6523 |
| 1982–1990 | Wet day | Increasing | 0.9923 | 10.6826 |
| Loss Rate | NSE (Complete) | NSE (Wet Day) |
|---|---|---|
| 10% | 0.98 | 0.99 |
| 20% | 0.97 | 0.99 |
| 30% | 0.97 | 0.99 |
| 40% | 0.97 | 0.99 |
| 50% | 0.97 | 0.99 |
| 60% | 0.97 | 0.99 |
| 70% | 0.12 | 0.98 |
| 80% | 0.31 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, W.; Wang, Z.; Feng, Y.; Xue, L.; Ma, Z.; Tian, L.; Sun, H. Developing the Actual Precipitation Probability Distribution Based on the Complete Daily Series. Sustainability 2023, 15, 13136. https://doi.org/10.3390/su151713136
Zhai W, Wang Z, Feng Y, Xue L, Ma Z, Tian L, Sun H. Developing the Actual Precipitation Probability Distribution Based on the Complete Daily Series. Sustainability. 2023; 15(17):13136. https://doi.org/10.3390/su151713136
Chicago/Turabian StyleZhai, Wangyuyang, Zhoufeng Wang, Youcan Feng, Lijun Xue, Zhenjie Ma, Lin Tian, and Hongliang Sun. 2023. "Developing the Actual Precipitation Probability Distribution Based on the Complete Daily Series" Sustainability 15, no. 17: 13136. https://doi.org/10.3390/su151713136