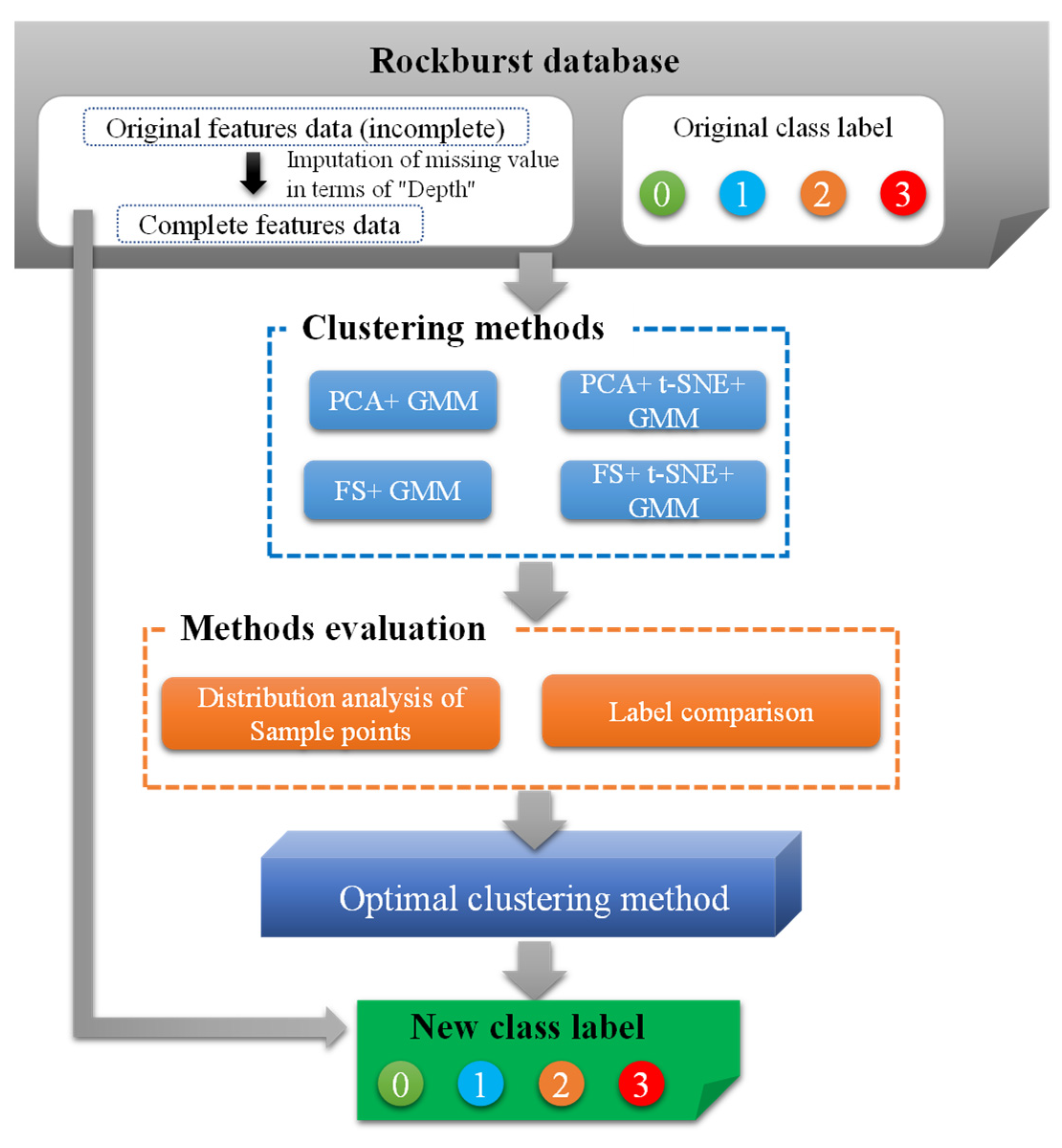
2.3.1. Dimensionality Reduction and the Clustering Method
Generally, samples that belong to the same class exhibit higher similarity, implying that they are more closely distributed in feature space. Clustering serves as an effective unsupervised learning method to achieve classification based on the sample distribution. Moreover, when dealing with datasets with a large number of features, appropriate dimensionality reduction becomes crucial. In this paper, four combination methods (Case 5–Case 8 in
Table 3) for dimensionality reduction and clustering are developed and evaluated. For this purpose, PCA, t-SNE, and GMM were performed in Python using the scikit-learn library [
45], thereby facilitating efficient and accurate data analysis.
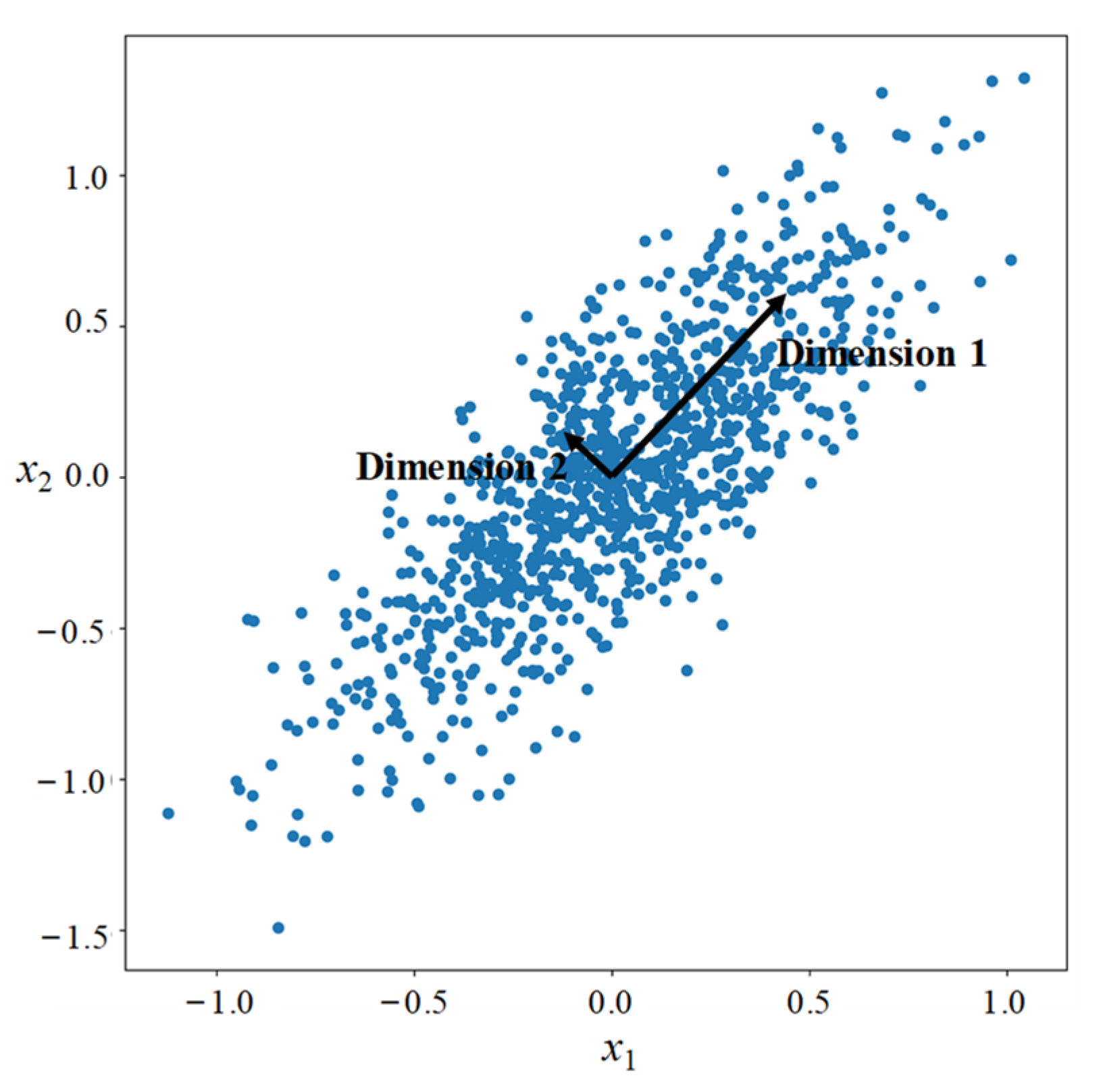
PCA is a widely used dimensionality reduction method that transforms the original coordinate space into a new orthogonal space (
Figure 5) [
46,
47]. The original coordinates of feature points are noted
X (
x1,
x2…,
xm), with a size of
n ×
m, where
n represents the number of features and
m represents the number of points. During PCA processing,
X is initially mapped to the matrix
A using min–max normalization. The values of the elements in
A (
a1,
a2…,
am) lie within the range of [0, 1]. Next, a decentralization matrix
B is obtained by subtracting
(the mean of
A along the row direction) from
A, as indicated in Equation (1). Subsequently, the new coordinates
Xpca of feature points can be calculated using Equation (2), where
U is composed of eigenvectors of covariance matrix
S of
B. The components (or factor loadings)
ui of
U can be computed using Equation (3), and the components (
u1,
u2…,
un) are assigned successively based on the eigenvalues (or variances) of the covariance matrix
S. Notably, the first component of
Xpca captures the largest variance, thus retaining the most pertinent information of the samples in the initial dimensions.
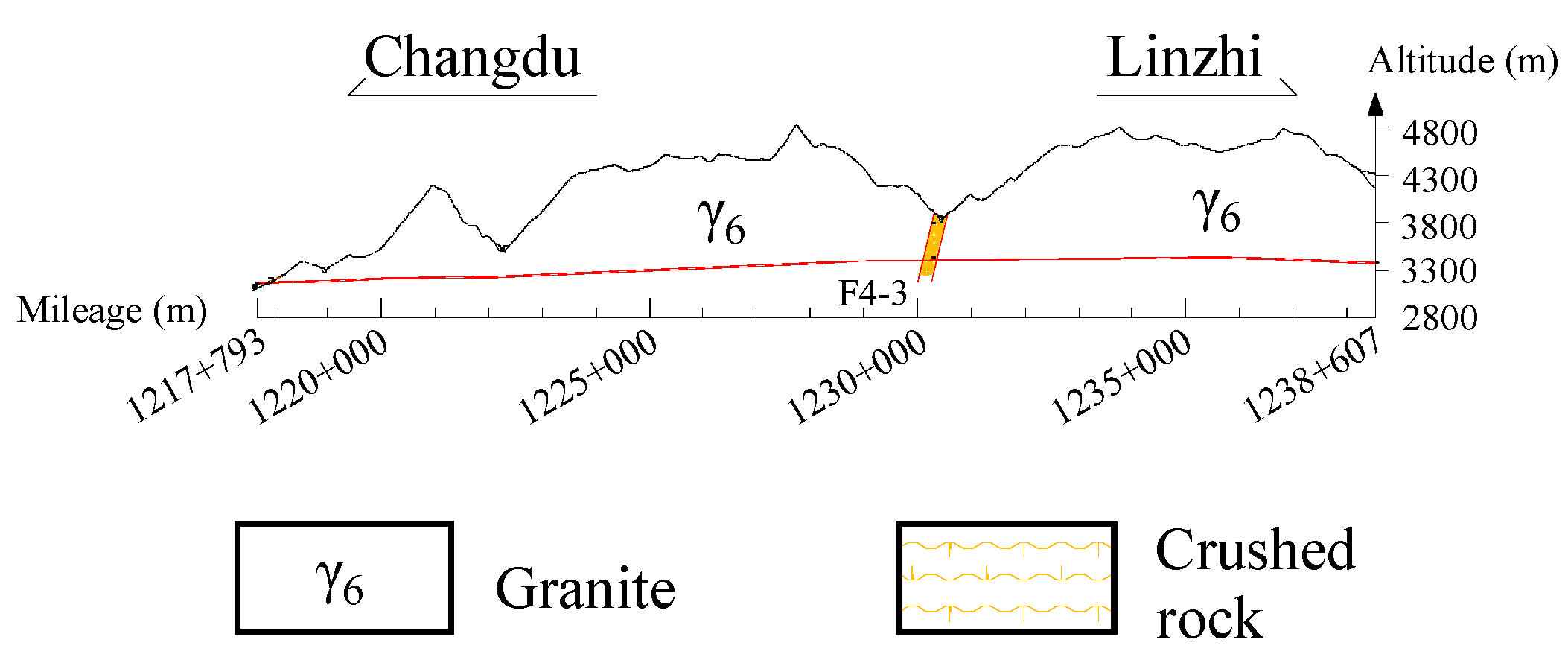
In this study, the original rockburst dataset is processed using PCA. Based on the calculated eigenvalues, it is observed that the first five components account for 94% of the variance information in the samples. Specifically, 42% is attributed to the first component (F1), 21% to the second component (F2), 18% to the third component (F3), 7.3% to the fourth component (F4), and 5.6% to the fifth component (F5), thus establishing their significance.
The factor loadings were plotted in two-dimensional spaces (F1–F2, F2–F3, F3–F4, F4–F5), and the correlation coefficient matrix between the initial features and the scores on PCA factors is also presented. These visualizations and detailed information can be found in
Supplementary Materials Figure S1 and Table S2, which reveal how each feature contributes to the principal components. Upon analyzing the correlation coefficient matrix, it becomes evident that the first five factors show significant linear relationships with specific features. In fact, the maximum absolute value of the correlation coefficient exceeds 0.6. Consequently, the features that contribute the most to each component are identified, as listed in
Table 5.
For a deeper understanding of the roles of features in relation to the principal components, a varimax rotation was performed. The loading matrix involving the rotated factors and the correlation coefficient matrix between initial features and scores on rotated factors are provided in
Supplementary Materials Tables S3 and S4. In this case, the rotated factors are denoted RF1, RF2, RF3, RF4, and RF5. From this analysis, it is evident that certain features exhibit strong associations with the rotated factors, as in
Table 6. Notably, features such as
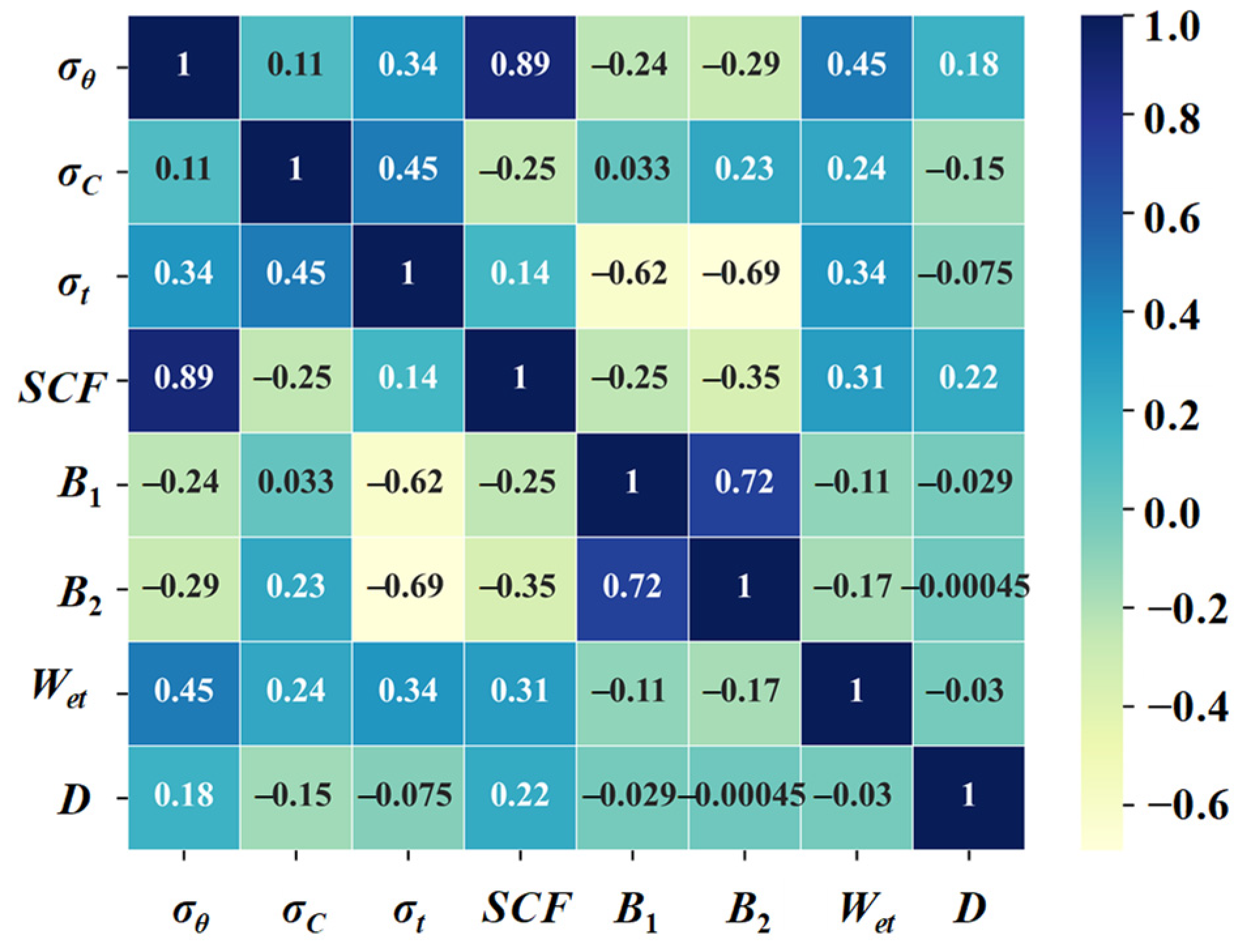
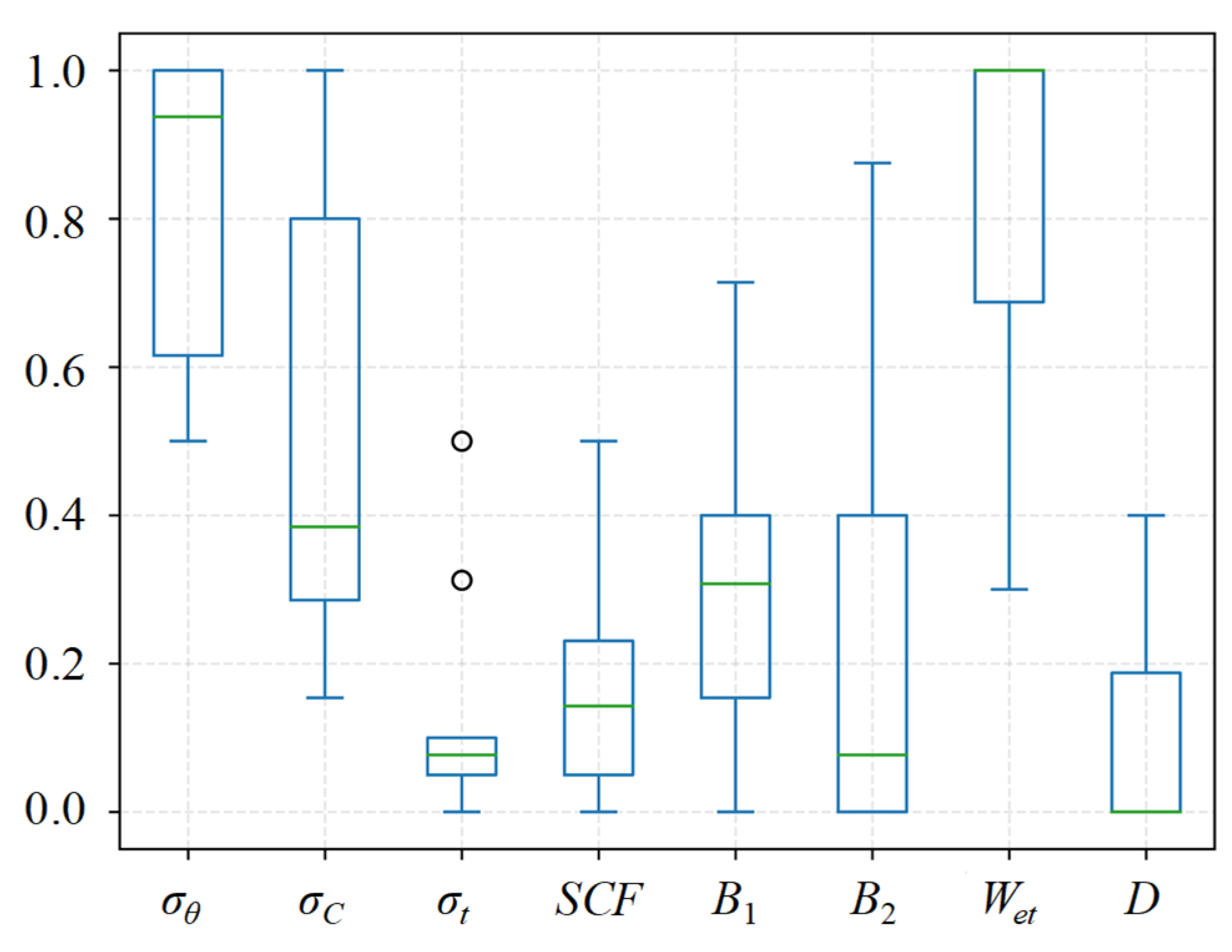
σt,
B1, and
B2 are highly aligned with RF1, which can be attributed to the marked negative correlation between
σt and
B1 and
B2, as depicted in
Figure 1. A similar trend is observed in relation to RF3. Taking both
Table 5 and
Table 6 into comprehensive consideration, it can be deduced that
σt,
σc, σθ,
D, and
Wet are the primary contributors to the principal components.
Furthermore, the
Supplementary Materials show the factor scores on the principal components (
Supplementary Materials Figure S2), it can be observed that the distribution of feature points becomes progressively denser from F1 to F5, indicating the efficacy of the PCA procedure.
In Case 5 (PCA + GMM), the original eight features are directly reduced to three dimensions using PCA to visualize the dataset effectively. In Case 6 (PCA + t-SNE + GMM), the original eight features are first reduced to five dimensions using PCA, and then further reduced using t-SNE with the same dimensionality reduction function.
- 2.
Feature Selection (FS)
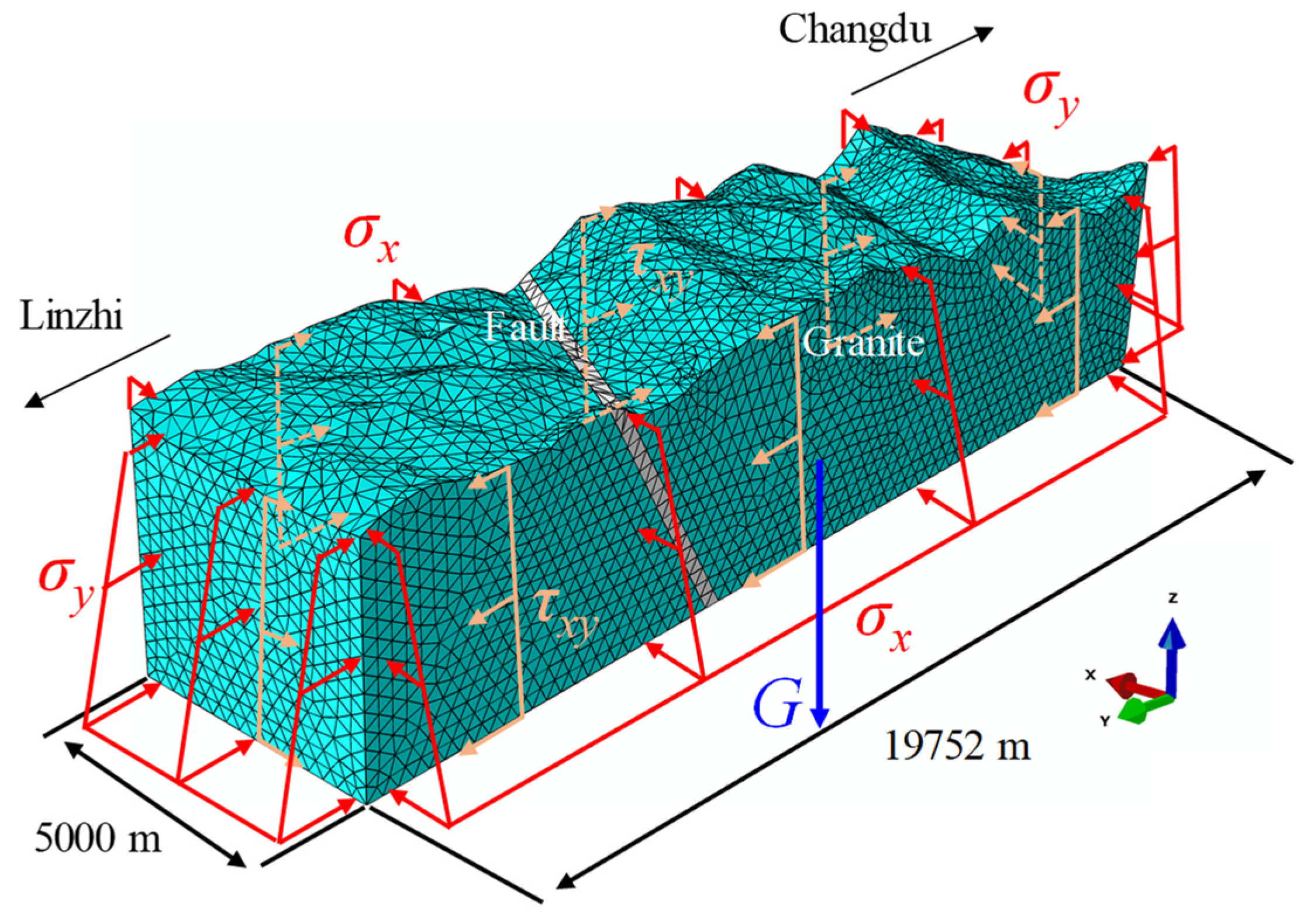
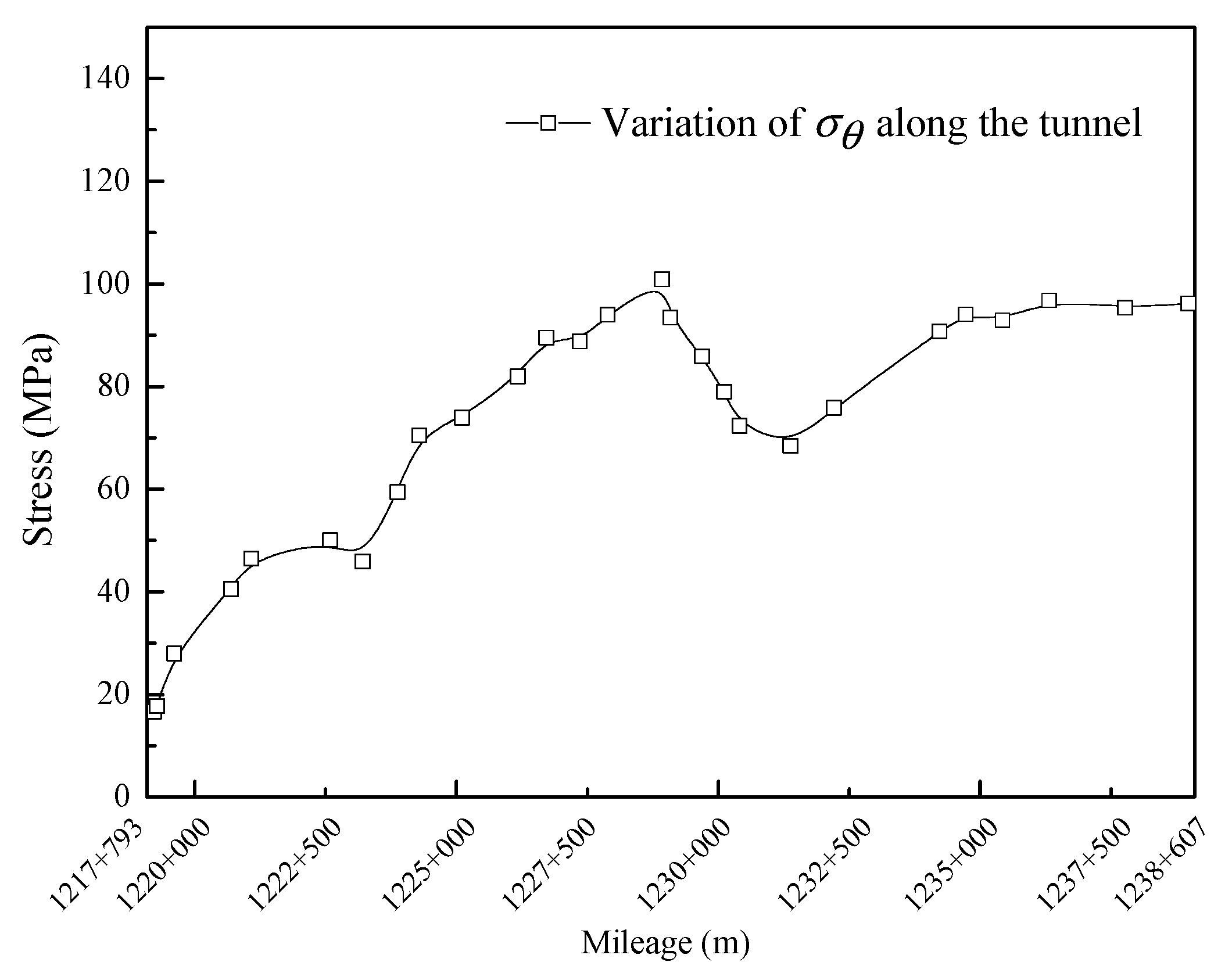
FS aims to identify influential and relatively independent features based on their physical meaning. Among the eight features mentioned above, SCF, B1, and B2 are expressed as functions of σθ, σc, and σt, respectively. Therefore, the former three features are initially eliminated. The buried depth D mainly influences the stress state of the surrounding rock; however, σθ provides more explicit information. Additionally, given the occurrence of missing values for D in some practical engineering cases, features associated with stress tend to favor selecting σθ over D. Considering that rockbursts often occur due to the extremely high compression stress that exceeds a rock’s capacity, σt has little effect on rockburst prediction. Consequently, σθ, σc, and Wet are selected as the ultimate dominant features. Here, σθ and σc reflect the possibility of rockburst, in other words, the closer σθ approaches σc, the greater the likelihood of rockburst occurrence. On the other hand, Wet reflects the hazard degree of rockburst; that is, a higher Wet value signifies a greater release of energy when a rockburst takes place.
- 3.
t-distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE [
48] is another dimensionality reduction method, distinguished by its remarkable capability to visualize high-dimensional data within an embedded space. This method transforms the affinities of sample points to probabilities using Student’s t-distributions. It facilitates optimizing the arrangement of data points in the new low-dimensional space, meticulously capturing their similarities and relationships in the original high-dimensional space. The new coordinates of feature points (
z1,
z2…,
zm) in low-dimensional space can be derived by minimizing the Kullback–Leibler (KL) divergence, also known as relative entropy, as expressed in Equation (4). In this equation,
Pj|i (Equation (5)) represents the conditional probability affinity of the
jth point given the
ith point in the original high-dimensional space, while
qj|i (Equation (6)) represents the conditional probability affinity of the
jth point given the
ith point in the low-dimensional space. The relative entropy quantifies the disparity between two probability distributions (
Pj|i and
qj|i). As
qj|i approaches
Pj|i, the relative entropy diminishes, aiding in the retention of inherent similarities and correlations among feature points in the new low-dimensional space.
In this method, similar samples are positioned in close proximity to enhance the clustering effect. In Case 6 (PCA + t-SNE + GMM) and Case 8 (FS + t-SNE + GMM), the data undergoes t-SNE processing and is presented as a three-dimensional form within the embedded space for visualization.
- 4.
Gaussian Mixture Model (GMM)
The GMM is an unsupervised clustering method, endowed with the capability to relabel samples based on the likelihood of their affiliation with each class. It assumes that samples stem from a mixture of a finite count (i.e., the number of classes
K) of Gaussian distributions
ϕ (
xi|
μk,
σk) (
k = 1, 2…,
K). Consequently, each sample holds an associated probability
rik (
i = 1, 2…,
m) for each class. This ‘soft’ classification is more flexible than other ‘hard’ classification methods [
34]. Moreover,
rik is computed using the EM algorithm, and the relevant procedure is displayed in Algorithm 1.
| Algorithm 1 EM algorithm in GMM. |
Step 1 Initialize: Parameters of different Gaussian distributions {μk, σk, αk}, in which μk, σk, αk,k are the mean, variance, probability of kth Gaussian distribution respectively.
Step 2 Update the probability rik that the ith sample belongs to kth Gaussian distribution:
.
Step 3 Update the μk+1: .
Step 4 Update the σk+1: .
Step 5 Update the αk+1: .
Step 6 If , or , or :
Store the variables {μk+1, σk+1, αk+1};
Start the next iteration from Step 2.
Else if:
End the iteration. |
2.3.2. Methods Evaluation
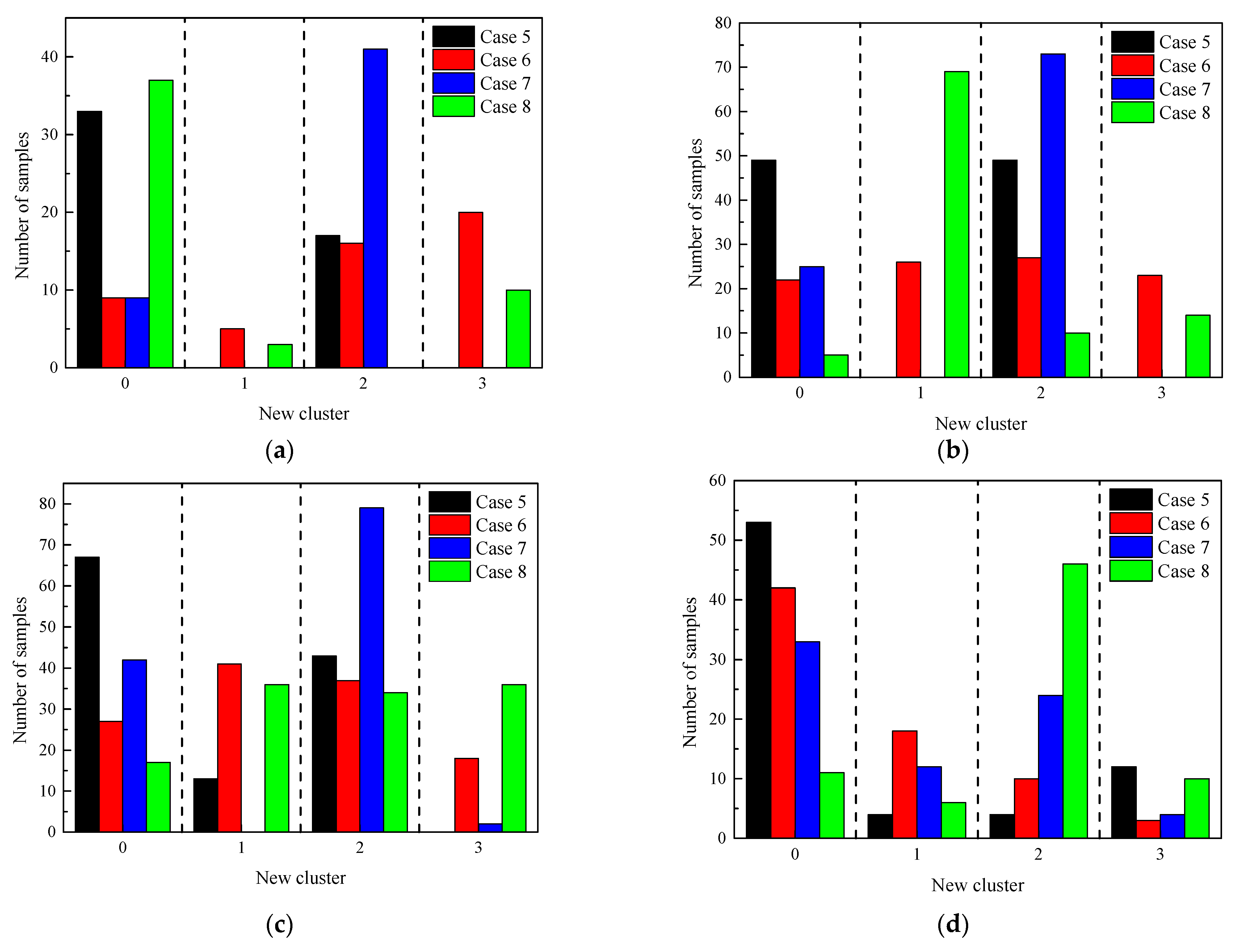
The clustering results obtained from the four combination methods are represented in
Figure 6 and
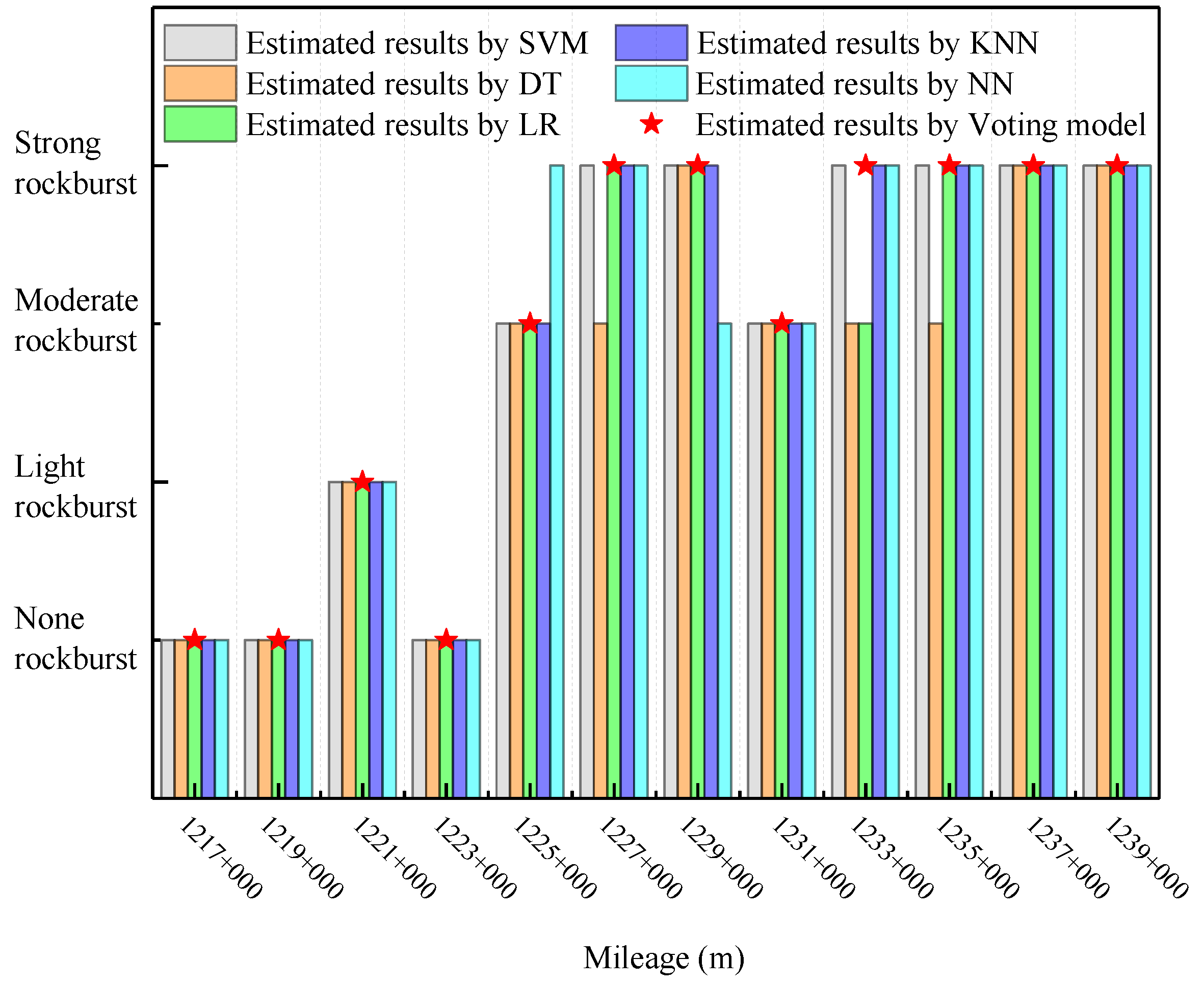
Figure 7. Before analyzing the results, it is important to clarify that the new cluster labels do not directly correspond to the original class labels. The meaning of the new cluster labels should be defined based on the sample distribution within each original class. Generally, a cluster with the maximum number of samples in a certain original class should be relabeled with the same class label. This relabeling process ensures that the new clusters represent similar rockburst intensities as the original class labels, enabling a more meaningful interpretation of the clustering results.
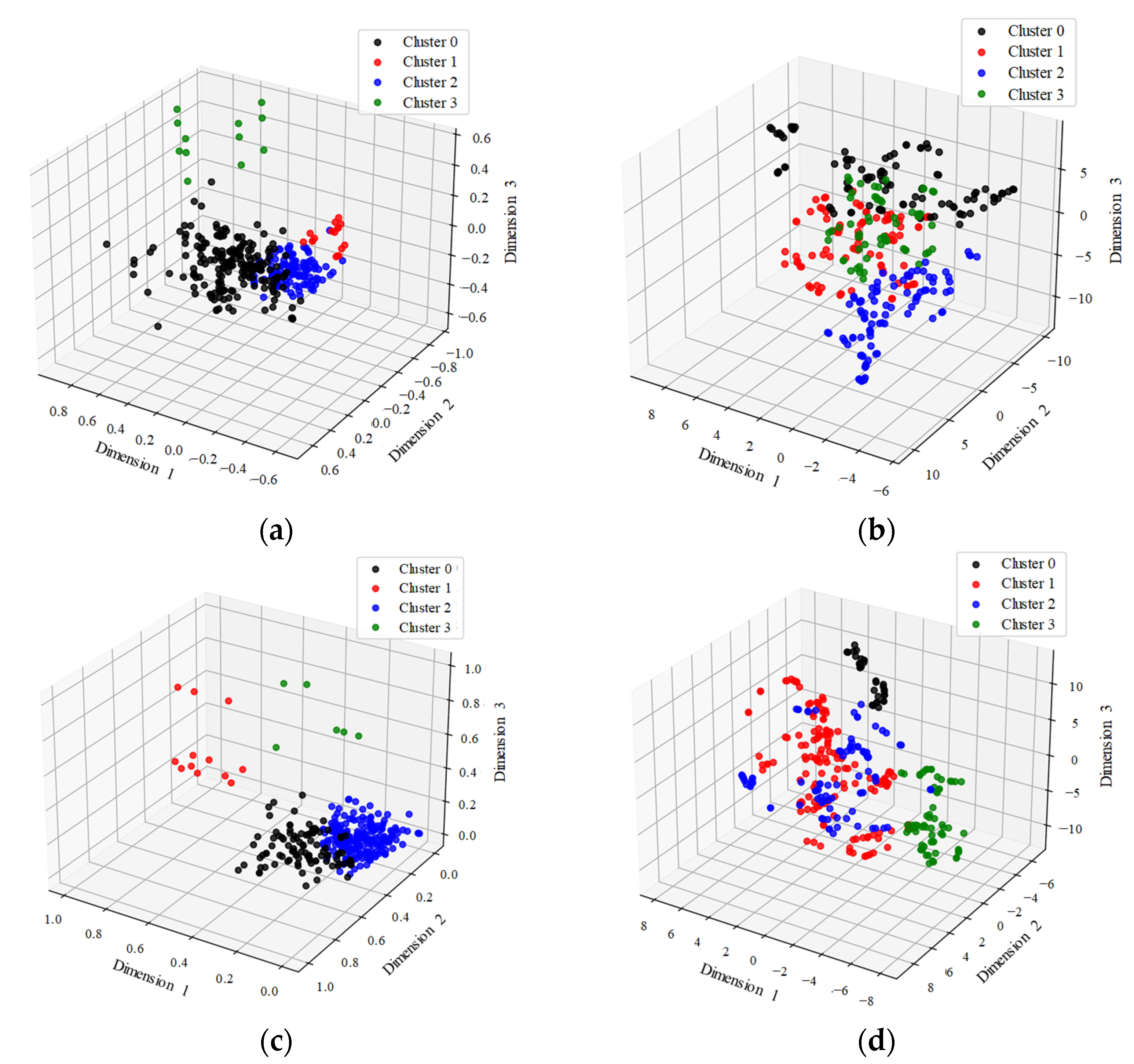
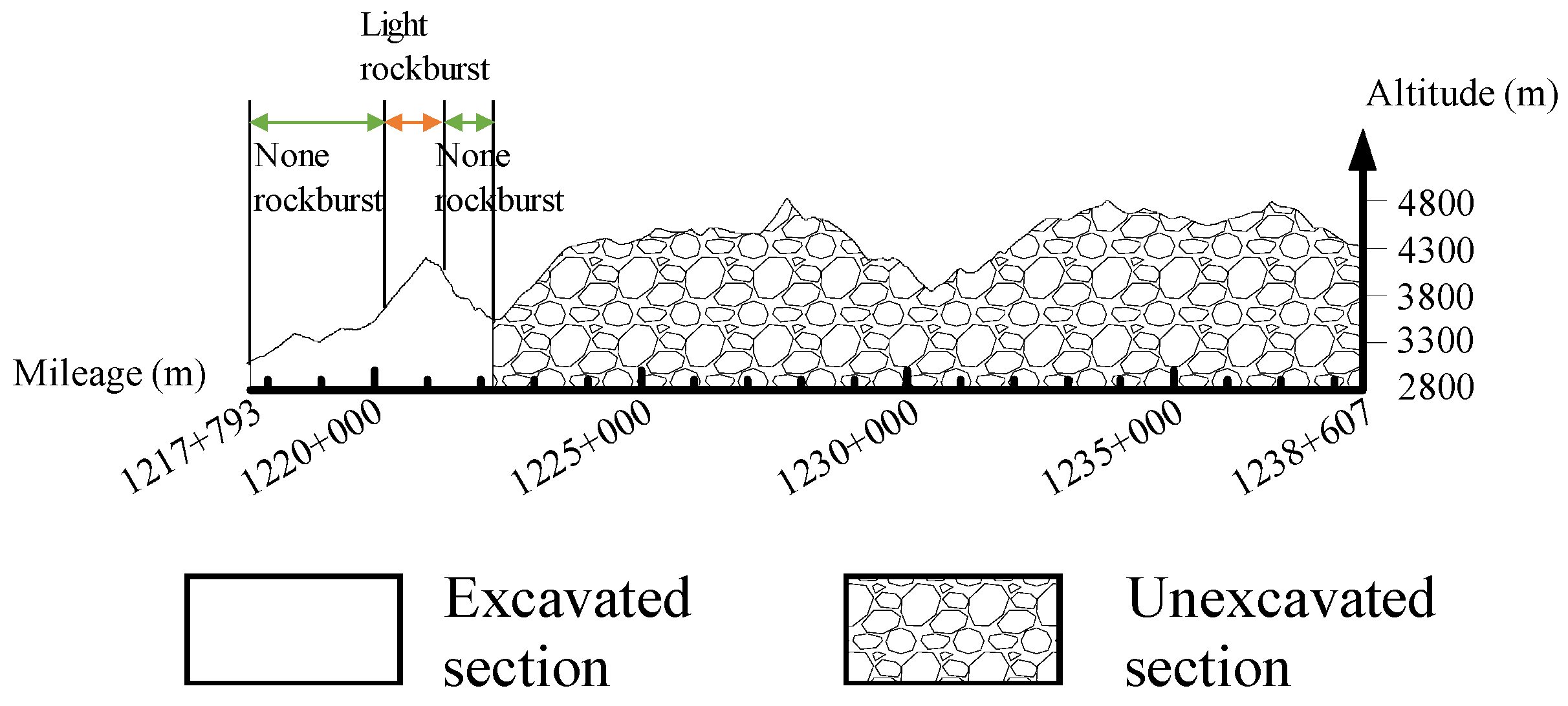
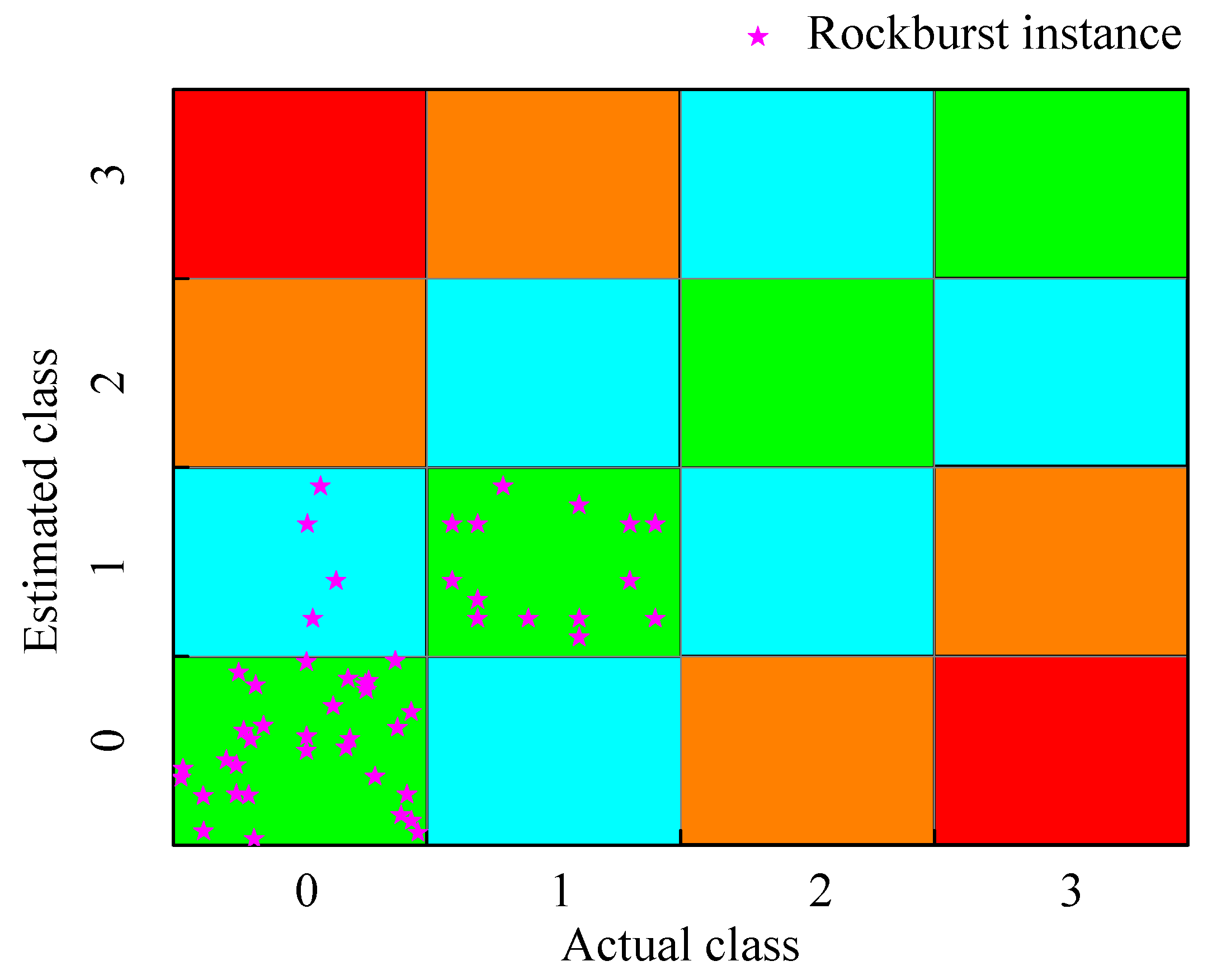
In
Figure 6, it can be observed that most samples are clustered into two categories in Case 5, i.e., cluster 0 and cluster 2. A similar issue can be seen in Case 7.
Figure 7a,c provides insights into understanding this peculiar situation, These figures represent the low-dimensional data space generated in Case 5 and Case 7, respectively, using dimensionality reduction methods.
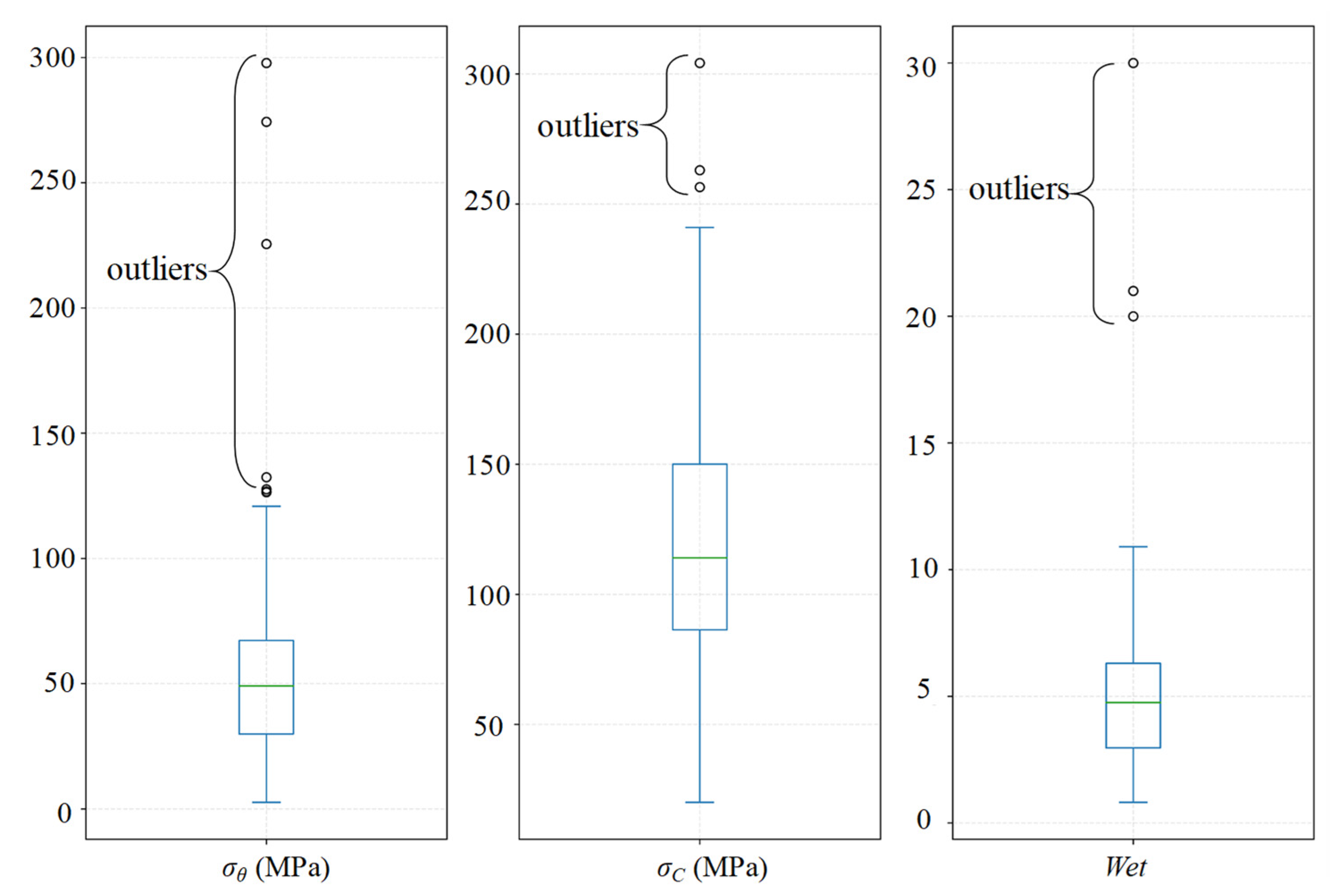
In Case 5 and Case 7, the inherent Euclidean distance characteristics of sample points, with respect to the dominative feature dimensions, are preserved in the low-dimensional space. Consequently, certain sample points that are distant from the others are retained in a similar manner, resulting in the presence of outliers.
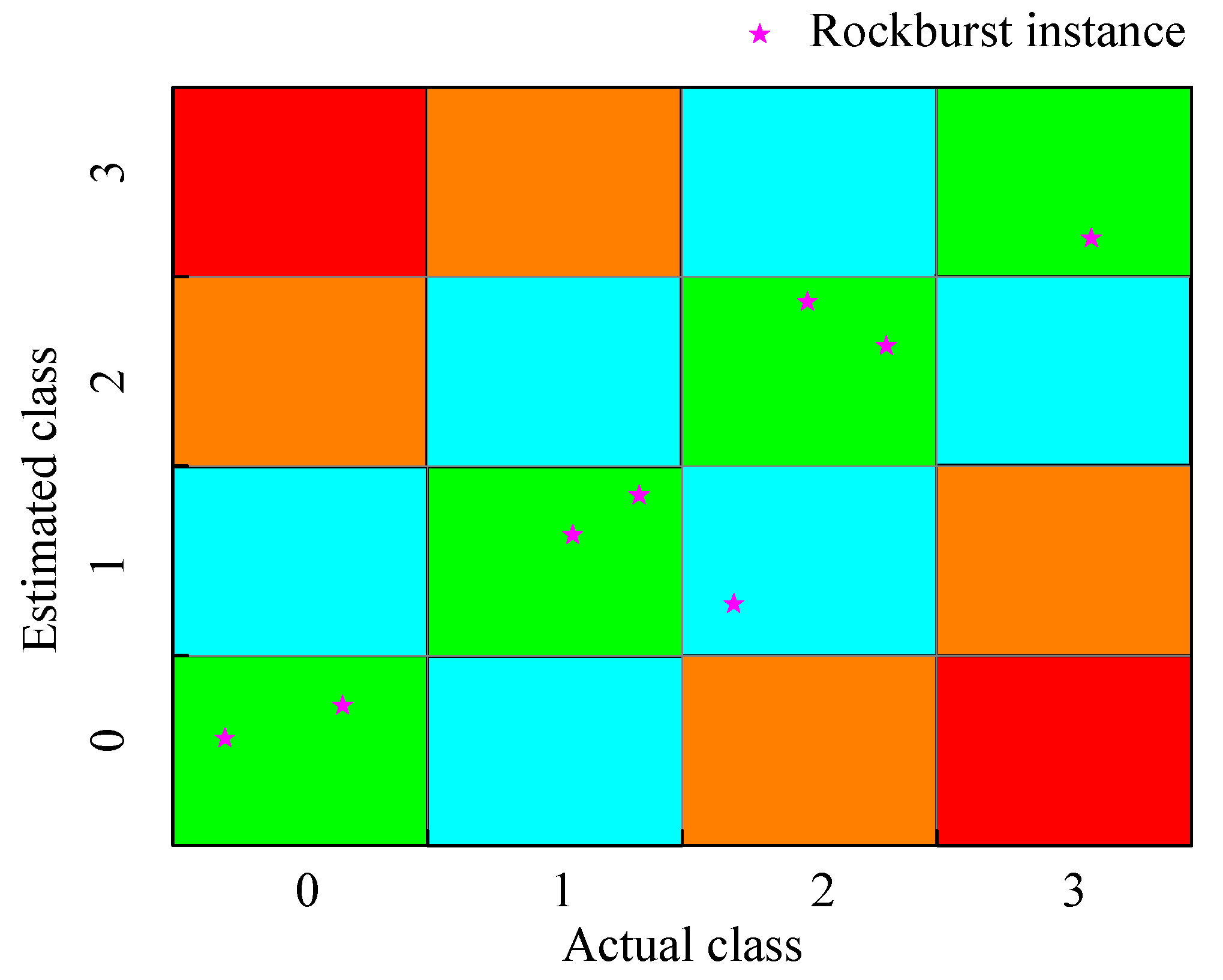
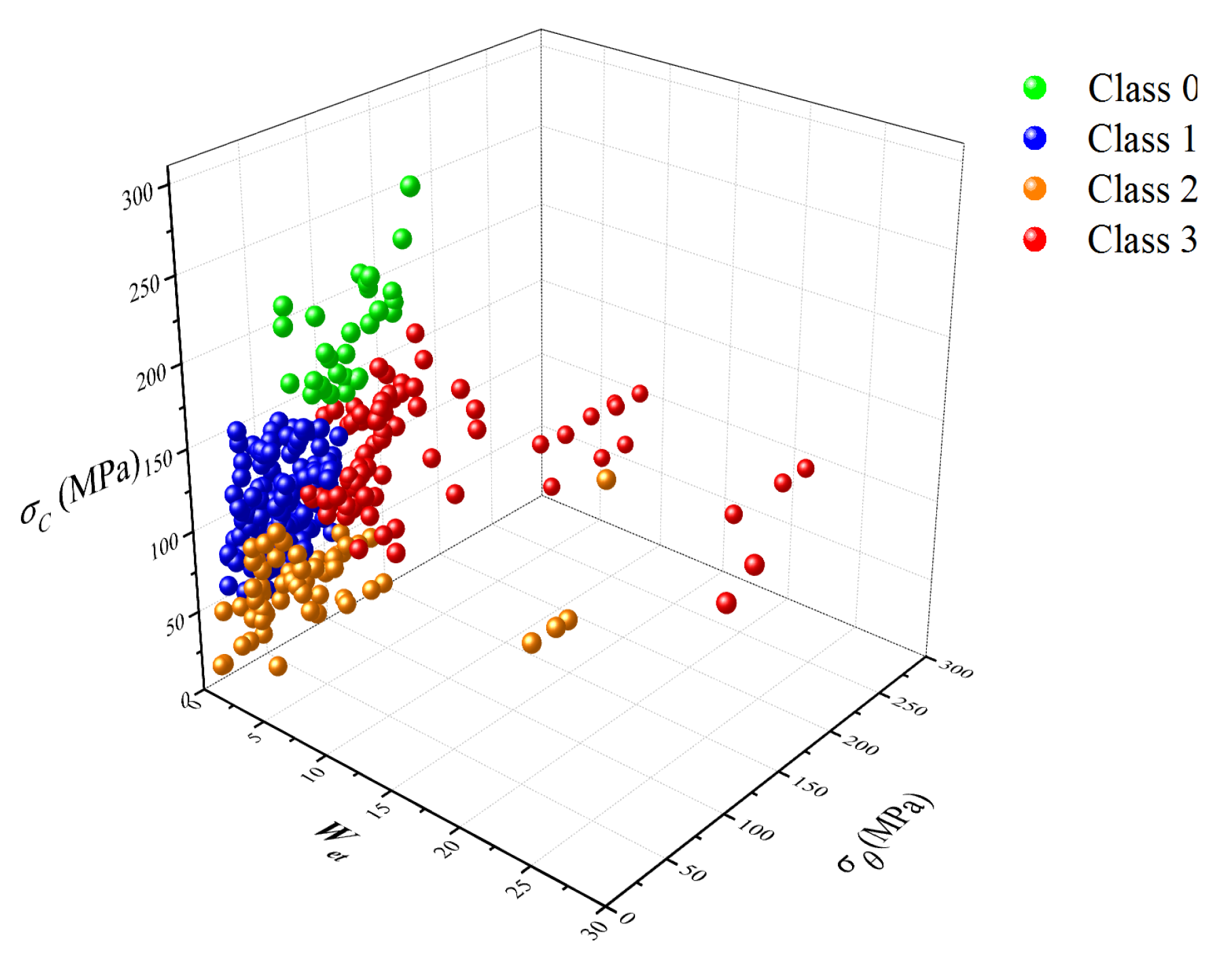
Figure 8 illustrates these outliers across the three dominant feature dimensions of Case 7. As a consequence, these outliers either form a distinct cluster or are divided into two categories in Case 5 and Case 7. It is important to note that these outlier samples might have the same practical class as other normal samples. For instance, both high rockburst samples and extremely high rockburst samples belong to class 3. This scenario leads to misclassification and has an impact on the clustering accuracy.
The clustering effect in Case 6 and Case 8 seems to be satisfactory when observing
Figure 7b,d. Taking into account the methodological variations, it can be concluded that the improved performance of Case 6 and Case 8 is largely attributed to the t-SNE process. This is because t-SNE transforms the Euclidean distance between sample points into probabilities, which in turn mitigates the impact of outliers. Based on the aforementioned relabeling regulation, where the maximum sample count determines the new class label, the new class label for each cluster in Case 6 and Case 8 is listed in
Table 7.
To quantitatively compare the clustering effect between different cases, this paper uses the difference value of labels as the rejection score to measure the disparity between the original class label and the new class label (
Table 8). A higher rejection score indicates less reliability of the relabeling method. Consequently, the rejection scores for the relabeling methods within each original class are listed in
Table 9 along with the total rejection score. It is worth noting that Case 5 and Case 7 are excluded from the comparison since it was challenging to determine the new class label for outlier clusters based on the maximum sample number regulation for these two cases.
Table 9 indicates that the relabeling result using
Wet (Case 3) is the closest to the original class label compared with the other three empirical proneness indices. However, it should be noted that an individual empirical proneness index can only reflect partial characteristics of rockburst, and thus, relying solely on a single feature for relabeling may lead to the loss of other valuable information from the dataset. Therefore, the comparison between Case 6 and Case 8 is expected to draw more attention.
In
Table 9, it is evident that Case 8 outperforms Case 6. The relatively weaker relabeling ability of Case 6 can be attributed to PCA’s reliance on the distribution of sample points. To illustrate this, a simple example is provided in
Figure 9, where the sample points are visualized in the
σθ-
Wet space, and two medium rockburst grades are marked as “Moderate I” and “Moderate II”. In the hypothetical distribution of sample points, as shown in
Figure 9, the sample points within the “Moderate I” zone and the “Moderate II” zone are prone to be clustered into different categories after PCA processing. On the other hand, the sample points within the “None” zone and the “Strong” zone are more likely to be clustered into the same category with a high probability. In practical scenarios, it is crucial to distinguish the sample points within the “None” zone and the “Strong” zone. Consequently, PCA is susceptible to the distribution of sample points, while FS seems to offer more control and better results.
In summary, the FS + t-SNE + GMM combination method is selected as the optimal clustering method, and the original class labels of the samples are replaced with the new class labels generated using this method. The preprocessed dataset is used as input for the machine learning model to achieve the rockburst prediction.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}