Energy-Saving Speed Planning for Electric Vehicles Based on RHRL in Car following Scenarios

 ,
,
Abstract
:1. Introduction
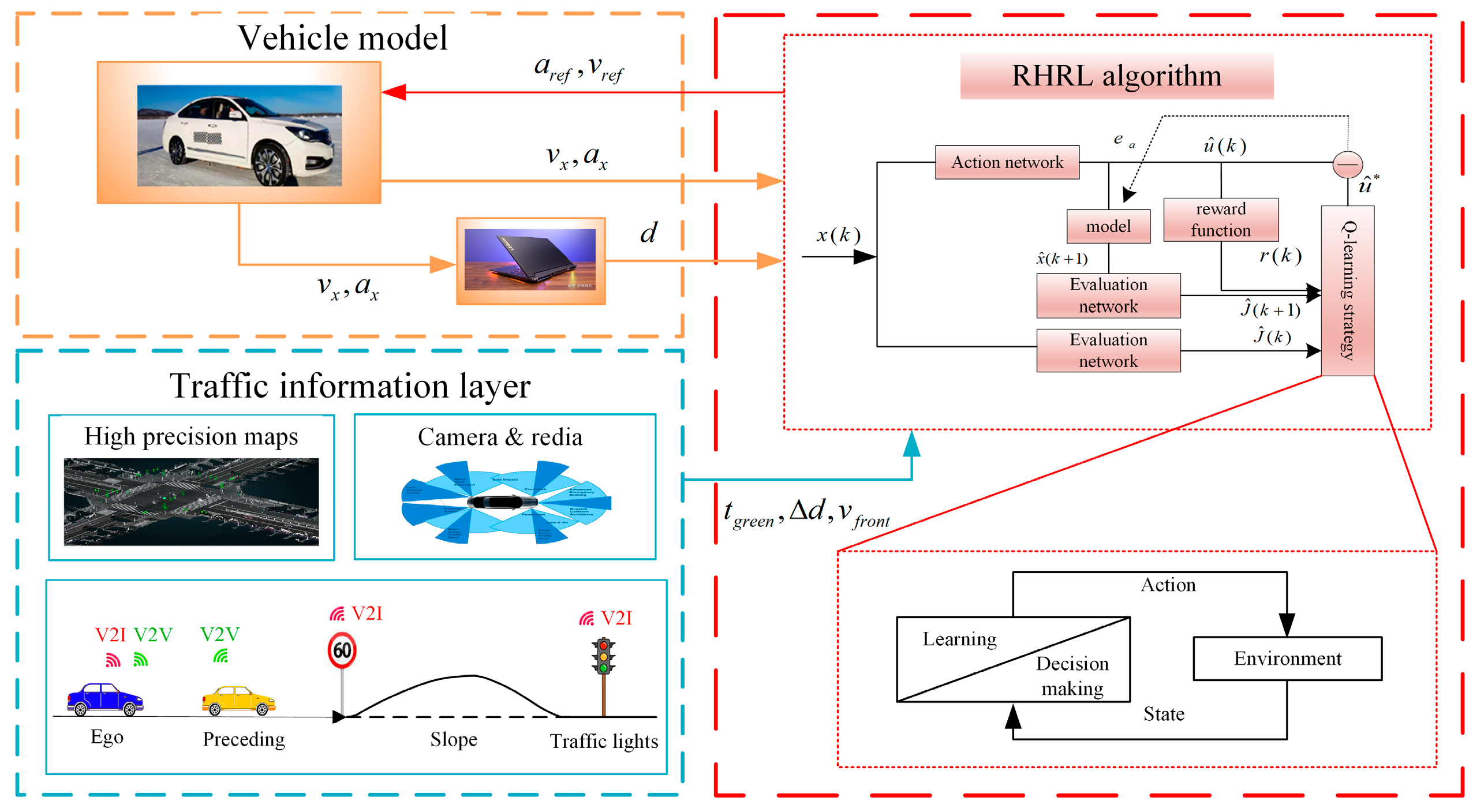
- A RHRL algorithm is put forward to enhance the eco-driving strategy for EVs. This algorithm takes into account both the road gradient and the car following scenario at signalized intersections. More precisely, it begins by acquiring driving conditions, including the timing data of road signals and the speed data of the leading vehicle, through V2I and V2V communication.
- Within the RHRL framework, it leverages a rolling time domain approach to make predictions within each time window. In the evaluation stage, Q-learning is used to obtain the optimal evaluation value, so that the vehicle can reach a reasonable speed.
- Iterations using Transformer networks in rolling optimization.
- The effectiveness of the algorithm is verified based on the vehicle simulation results, and the energy saving performance of the car following scenario is compared with that under the ACC method.
2. Model Building
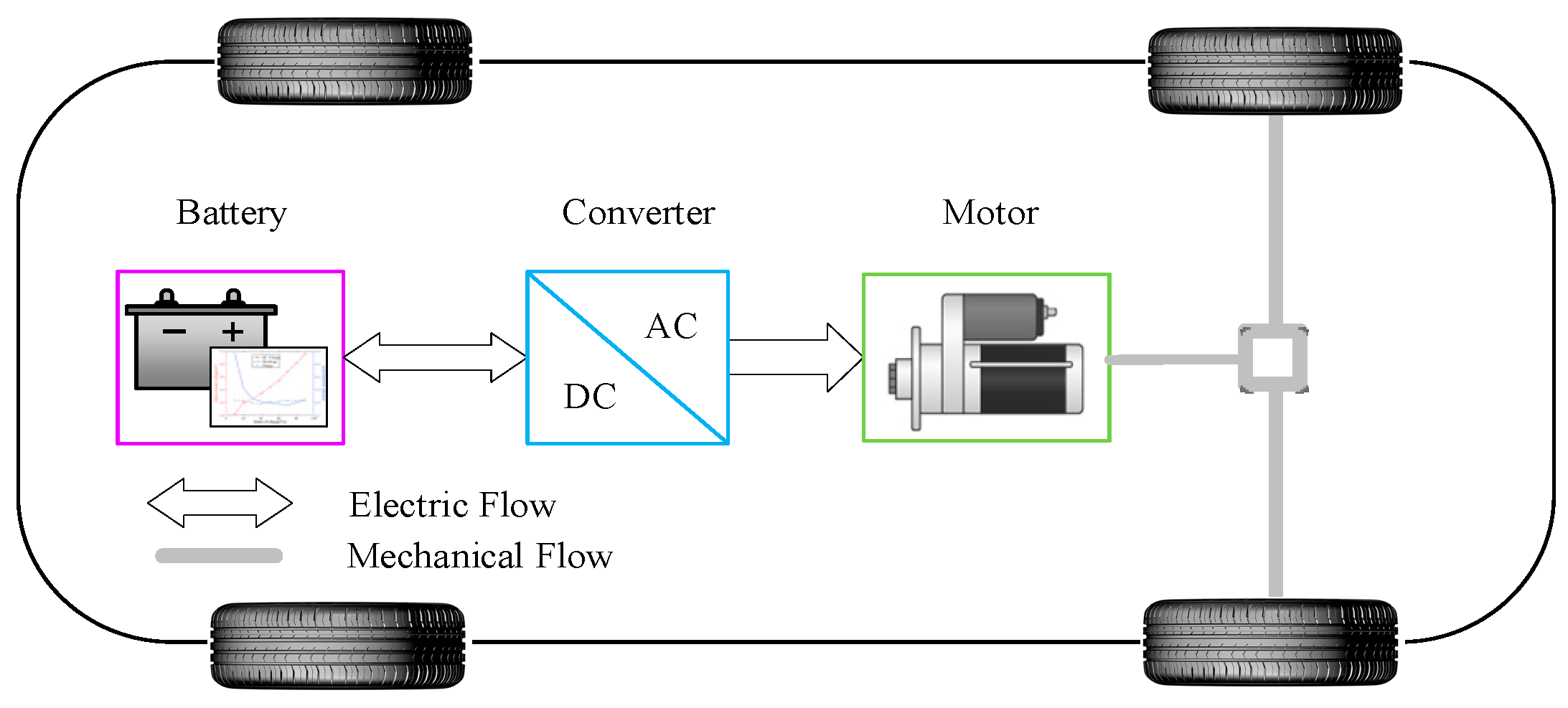
2.1. Vehicle Dynamics Model
2.2. Battery Model
3. Eco-Driving Optimization Functions and Constraints
3.1. Eco-Driving Objective Function
3.2. Speed Dynamic Programming Based on Transformer and RL
3.2.1. Action Network
3.2.2. Reward Network
3.2.3. Evaluation Network
| Algorithm 1 RHRL algorithm. |
| Obtain the timing information of road signal lights and the speed information of the preceding vehicle through V2I and V2V, and then set the length of the prediction layer and the sampling time interval. The initial state of the vehicle represents the initial values of parameters such as action network, criticism network, and learning rate. The maximum number of iterations is na. 1: for do 2: for do 3: Apply the action network to get . 4: The next state estimate is obtained from the model and the state values. comes from the reward function. 5: Input and into the evaluation network to get and . 6: Observe and update Q. 7: for do 8: (Equation (24)) 9: end for 10: Update action network and evaluation network. 11: end for 12: end for |
4. Simulation Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, X.; Doering, O.C.; Tyner, W.E. The economic competitiveness and emissions of battery electric vehicles in China. Appl. Energy 2015, 156, 666–675. [Google Scholar] [CrossRef]
- Skrucany, T.; Semanova, S.; Milojević, S.; Ašonja, A. New Technologies Improving Aerodynamic Properties of Freight Vehicles. Appl. Eng. Lett. J. Eng. Appl. Sci. 2019, 4, 48–54. [Google Scholar] [CrossRef]
- Liu, K.; Wang, J.; Yamamoto, T.; Morikawa, T. Modelling the multilevel structure and mixed effects of the factors influencing the energy consumption of electric vehicles—ScienceDirect. Appl. Energy 2016, 183, 1351–1360. [Google Scholar] [CrossRef]
- Li, W.; Stanula, P.; Egede, P.; Kara, S.; Herrmann, C. Determining the Main Factors Influencing the Energy Consumption of Electric Vehicles in the Usage Phase. Procedia CIRP 2016, 48, 352–357. [Google Scholar] [CrossRef]
- Al-Wreikat, Y.; Serrano, C.; Sodré, J.R. Effects of ambient temperature and trip characteristics on the energy consumption of an electric vehicle. Energy 2022, 238, 122028. [Google Scholar] [CrossRef]
- Bi, X.; Yang, S.; Zhang, B.; Wei, X. A Novel Hierarchical V2V Routing Algorithm Based on Bus in Urban VANETs. IEICE Trans. Commun. 2022, E105-B, 1487–1497. [Google Scholar] [CrossRef]
- Wu, Y.; Huang, Z.; Hofmann, H.; Liu, Y.; Huang, J.; Hu, X.; Peng, J.; Song, Z. Hierarchical predictive control for electric vehicles with hybrid energy storage system under vehicle-following scenarios. Energy 2022, 251, 123774. [Google Scholar] [CrossRef]
- Jin, Q.; Wu, G.; Boriboonsomsin, K.; Barth, M.J. Power-Based Optimal Longitudinal Control for a Connected Eco-Driving System. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2900–2910. [Google Scholar] [CrossRef]
- Ye, F.; Hao, P.; Qi, X.; Wu, G.; Boriboonsomsin, K.; Barth, M.J. Prediction-Based Eco-Approach and Departure at Signalized Intersections with Speed Forecasting on Preceding Vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1378–1389. [Google Scholar] [CrossRef]
- Bae, S.; Choi, Y.; Kim, Y.; Guanetti, J.; Borrelli, F.; Moura, S. Real-time ecological velocity planning for plug-in hybrid vehicles with partial communication to traffic lights. In Proceedings of the 2019 IEEE 58th Conference on Decision and Control (CDC), Nice, France, 11–13 December 2019; pp. 1279–1285. [Google Scholar]
- Schwickart, T.; Voos, H.; Hadji-Minaglou, J.-R.; Darouach, M.; Rosich, A. Design and simulation of a real-time implementable energy-efficient model-predictive cruise controller for electric vehicles. J. Frankl. Inst. 2015, 352, 603–625. [Google Scholar] [CrossRef]
- Kim, J.; Ahn, C. Real-Time Speed Trajectory Planning for Minimum Fuel Consumption of a Ground Vehicle. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2324–2338. [Google Scholar] [CrossRef]
- Xiong, X.; Sha, J.; Jin, L. Optimizing coordinated vehicle platooning: An analytical approach based on stochastic dynamic programming. Transp. Res. Part B Methodol. 2021, 150, 482–502. [Google Scholar] [CrossRef]
- Wang, Y.; Jiao, X. Dual Heuristic Dynamic Programming Based Energy Management Control for Hybrid Electric Vehicles. Energies 2022, 15, 3235. [Google Scholar] [CrossRef]
- Chen, S.; Hu, M.; Guo, S. Fast dynamic-programming algorithm for solving global optimization problems of hybrid electric vehicles. Energy 2023, 273, 127207. [Google Scholar] [CrossRef]
- Zhu, Z.; Gupta, S.; Pivaro, N.; Deshpande, S.R.; Canova, M. A GPU Implementation of a Look-Ahead Optimal Controller for Eco-Driving Based on Dynamic Programming. In Proceedings of the 2021 European Control Conference (ECC), Delft, The Netherlands, 29 June–2 July 2021; pp. 899–904. [Google Scholar]
- Sun, W.; Chen, Y.; Wang, J.; Wang, X.; Liu, L. Research on TVD Control of Cornering Energy Consumption for Distributed Drive Electric Vehicles Based on PMP. Energies 2022, 15, 2641. [Google Scholar] [CrossRef]
- Wei, X.; Wang, J.; Sun, C.; Liu, B.; Huo, W.; Sun, F. Guided control for plug-in fuel cell hybrid electric vehicles via vehicle to traffic communication. Energy 2022, 267, 126469. [Google Scholar] [CrossRef]
- Xu, S.; Peng, H. Design and Comparison of Fuel-Saving Speed Planning Algorithms for Automated Vehicles. IEEE Access 2018, 6, 9070–9080. [Google Scholar] [CrossRef]
- He, H.; Han, M.; Liu, W.; Cao, J.; Shi, M.; Zhou, N. MPC-based longitudinal control strategy considering energy consumption for a dual-motor electric vehicle. Energy 2022, 253, 124004. [Google Scholar] [CrossRef]
- Wang, S.; Lin, X. Eco-driving control of connected and automated hybrid vehicles in mixed driving scenarios. Appl. Energy 2020, 271, 115233. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Sinopoli, B.; Kolmanovsky, I.; Baruah, S. MPC-Based Emergency Vehicle-Centered Multi-Intersection Traffic Control. IEEE Trans. Control. Syst. Technol. 2022, 31, 166–178. [Google Scholar] [CrossRef]
- Mahdinia, I.; Arvin, R.; Khattak, A.J.; Ghiasi, A. Safety, Energy, and Emissions Impacts of Adaptive Cruise Control and Cooperative Adaptive Cruise Control. Transp. Res. Rec. J. Transp. Res. Board 2020, 2674, 253–267. [Google Scholar] [CrossRef]
- Liu, T.; Hu, X.; Li, S.E.; Cao, D. Reinforcement Learning Optimized Look-Ahead Energy Management of a Parallel Hybrid Electric Vehicle. IEEE/ASME Trans. Mechatron. 2017, 22, 1497–1507. [Google Scholar] [CrossRef]
- Lee, H.; Kang, C.; Park, Y.-I.; Kim, N.; Cha, S.W. Online Data-Driven Energy Management of a Hybrid Electric Vehicle Using Model-Based Q-Learning. IEEE Access 2020, 8, 84444–84454. [Google Scholar] [CrossRef]
- Lee, H.; Cha, S.W. Energy Management Strategy of Fuel Cell Electric Vehicles Using Model-Based Reinforcement Learning with Data-Driven Model Update. IEEE Access 2021, 9, 59244–59254. [Google Scholar] [CrossRef]
- Lee, H.; Kim, N.; Cha, S.W. Model-Based Reinforcement Learning for Eco-Driving Control of Electric Vehicles. IEEE Access 2020, 8, 202886–202896. [Google Scholar] [CrossRef]
- Shi, J.; Qiao, F.; Li, Q.; Yu, L.; Hu, Y. Application and Evaluation of the Reinforcement Learning Approach to Eco-Driving at Intersections under Infrastructure-to-Vehicle Communications. Transp. Res. Rec. J. Transp. Res. Board 2018, 2672, 89–98. [Google Scholar] [CrossRef]
- Shu, H.; Liu, T.; Mu, X.; Cao, D. Driving Tasks Transfer Using Deep Reinforcement Learning for Decision-Making of Autonomous Vehicles in Unsignalized Intersection. IEEE Trans. Veh. Technol. 2021, 71, 41–52. [Google Scholar] [CrossRef]
- Bai, Z.; Shangguan, W.; Cai, B.; Chai, L. Deep reinforcement learning based high-level driving behavior decision-making model in heterogeneous traffic. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8600–8605. [Google Scholar]
- Liu, X.; Liu, Y.; Chen, Y.; Hanzo, L. Enhancing the Fuel-Economy of V2I-Assisted Autonomous Driving: A Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2020, 69, 8329–8342. [Google Scholar] [CrossRef]
- Li, G.; Gorges, D. Ecological Adaptive Cruise Control for Vehicles with Step-Gear Transmission Based on Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4895–4905. [Google Scholar] [CrossRef]
- Pozzi, A.; Bae, S.; Choi, Y.; Borrelli, F.; Raimondo, D.M.; Moura, S. Ecological velocity planning through signalized intersections: A deep reinforcement learning approach. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC), Jeju, Republic of Korea, 14–18 December 2020; pp. 245–252. [Google Scholar]
- Ramsey, D.; German, R.; Bouscayrol, A.; Boulon, L. Comparison of equivalent circuit battery models for energetic studies on electric vehicles. In Proceedings of the 2020 IEEE Vehicle Power and Propulsion Conference (VPPC), Gijon, Spain, 18 November–16 December 2020; pp. 1–5. [Google Scholar]
- Zhang, Z.; Ding, H.; Guo, K.; Zhang, N. Eco-Driving Cruise Control for 4WIMD-EVs Based on Receding Horizon Reinforcement Learning. Electronics 2023, 12, 1350. [Google Scholar] [CrossRef]
- Albeaik, S.; Bayen, A.; Chiri, M.T.; Gong, X.; Hayat, A.; Kardous, N.; Keimer, A.; McQuade, S.T.; Piccoli, B.; You, Y. Limitations and Improvements of the Intelligent Driver Model (IDM). SIAM J. Appl. Dyn. Syst. 2022, 21, 1862–1892. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Lee, H.; Kim, K.; Kim, N.; Cha, S.W. Energy efficient speed planning of electric vehicles for car-following scenario using model-based reinforcement learning. Appl. Energy 2022, 313, 118460. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Value [Unit] | Symbol | Value [Unit] |
|---|---|---|---|
| m | 1800 [kg] | A | 2.06 [m2] |
| μ | 0.75 | 1.18 [kg/m3] | |
| R | 0.322 [m] | g | 9.8 [m/s2] |
| CD | 0.36 | f | 0.0074 |
| Parameter | Value [Unit] | Parameter | Value [Unit] |
|---|---|---|---|
| Torque_motor_min | 10 [Nm] | Torque_motor_max | 800 [Nm] |
| N_motor_min | 50 [rpm] | N_motor_max | 1350 [rpm] |
| PW_batt_min | −339 [kW] | PW_batt_max | 339 [kW] |
| SOC_min | 4.8% | SOC_max | 99.2% |
| Intersection | Position (m) | Intersection | Position (m) |
|---|---|---|---|
| 1 | 107 | 6 | 4776 |
| 2 | 1067 | 7 | 5485 |
| 3 | 2624 | 8 | 6129 |
| 4 | 3292 | 9 | 8296 |
| 5 | 3978 | 10 | 9891 |
| Intersection | Position (m) | Intersection | Position (m) |
|---|---|---|---|
| 1 | 1624 | 8 | 6763 |
| 2 | 2657 | 9 | 7730 |
| 3 | 2857 | 10 | 8173 |
| 4 | 3041 | 11 | 8806 |
| 5 | 3601 | 12 | 9173 |
| 6 | 3894 | 13 | 9491 |
| 7 | 5201 | 14 | 10,440 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Zhang, N.; Li, Z.; Zhuo, Z.; Zhang, Y.; Zhang, Y.; Ding, H. Energy-Saving Speed Planning for Electric Vehicles Based on RHRL in Car following Scenarios. Sustainability 2023, 15, 15947. https://doi.org/10.3390/su152215947
Xu H, Zhang N, Li Z, Zhuo Z, Zhang Y, Zhang Y, Ding H. Energy-Saving Speed Planning for Electric Vehicles Based on RHRL in Car following Scenarios. Sustainability. 2023; 15(22):15947. https://doi.org/10.3390/su152215947
Chicago/Turabian StyleXu, Haochen, Niaona Zhang, Zonghao Li, Zichang Zhuo, Ye Zhang, Yilei Zhang, and Haitao Ding. 2023. "Energy-Saving Speed Planning for Electric Vehicles Based on RHRL in Car following Scenarios" Sustainability 15, no. 22: 15947. https://doi.org/10.3390/su152215947