


A Prediction Hybrid Framework for Air Quality Integrated with W-BiLSTM(PSO)-GRU and XGBoost Methods



Abstract
:1. Introduction
2. Materials and Methods
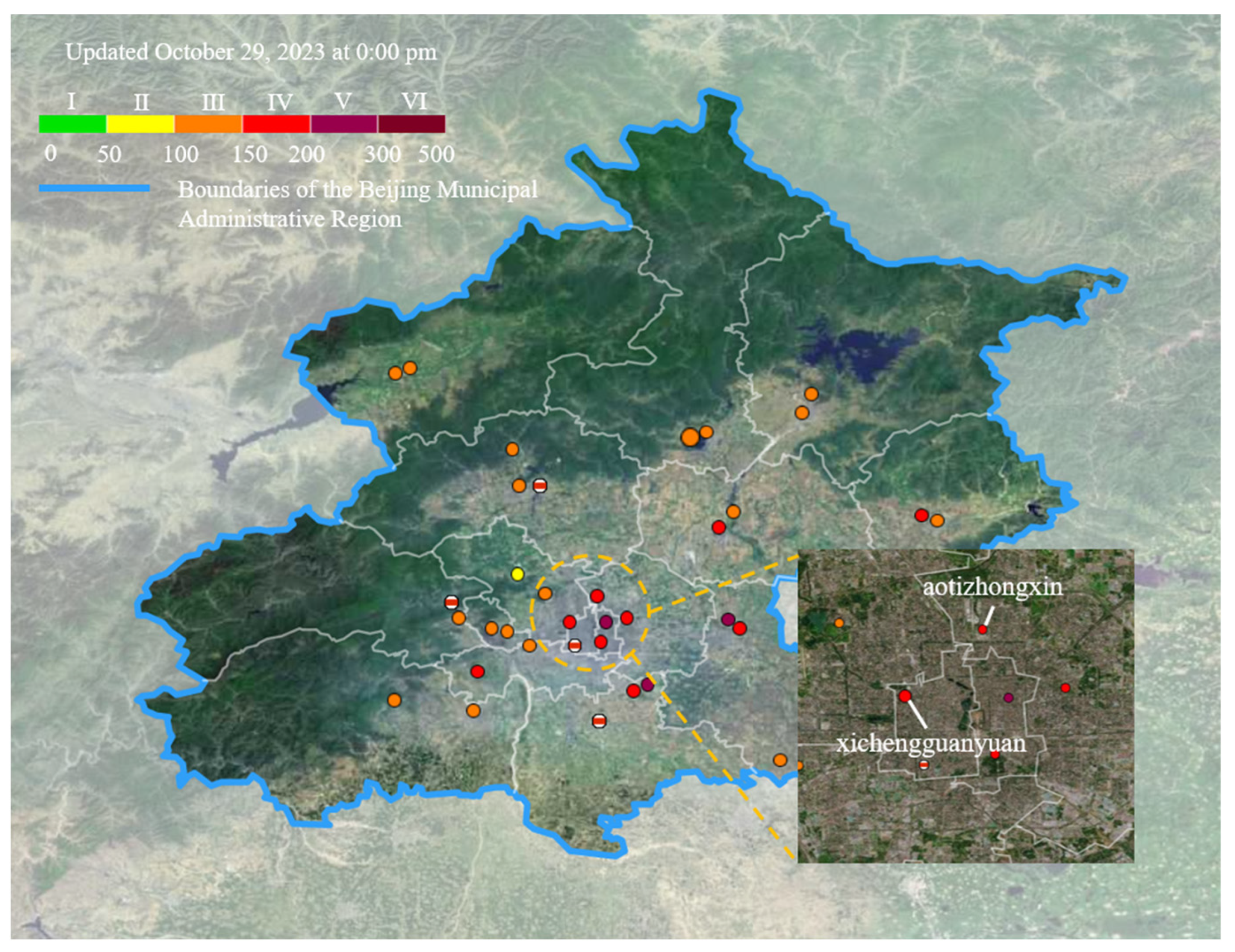
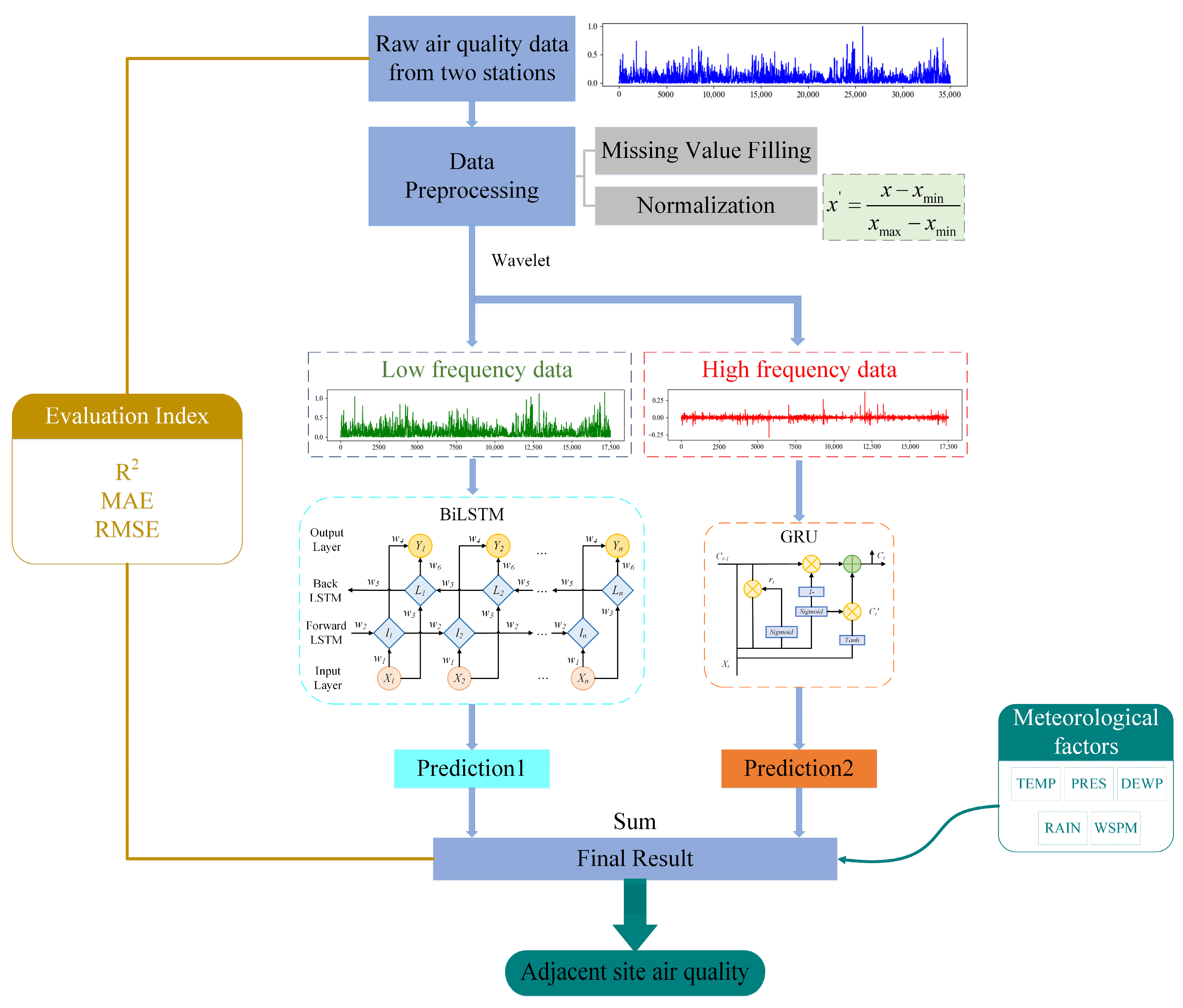
2.1. Data Description and Preprocessing
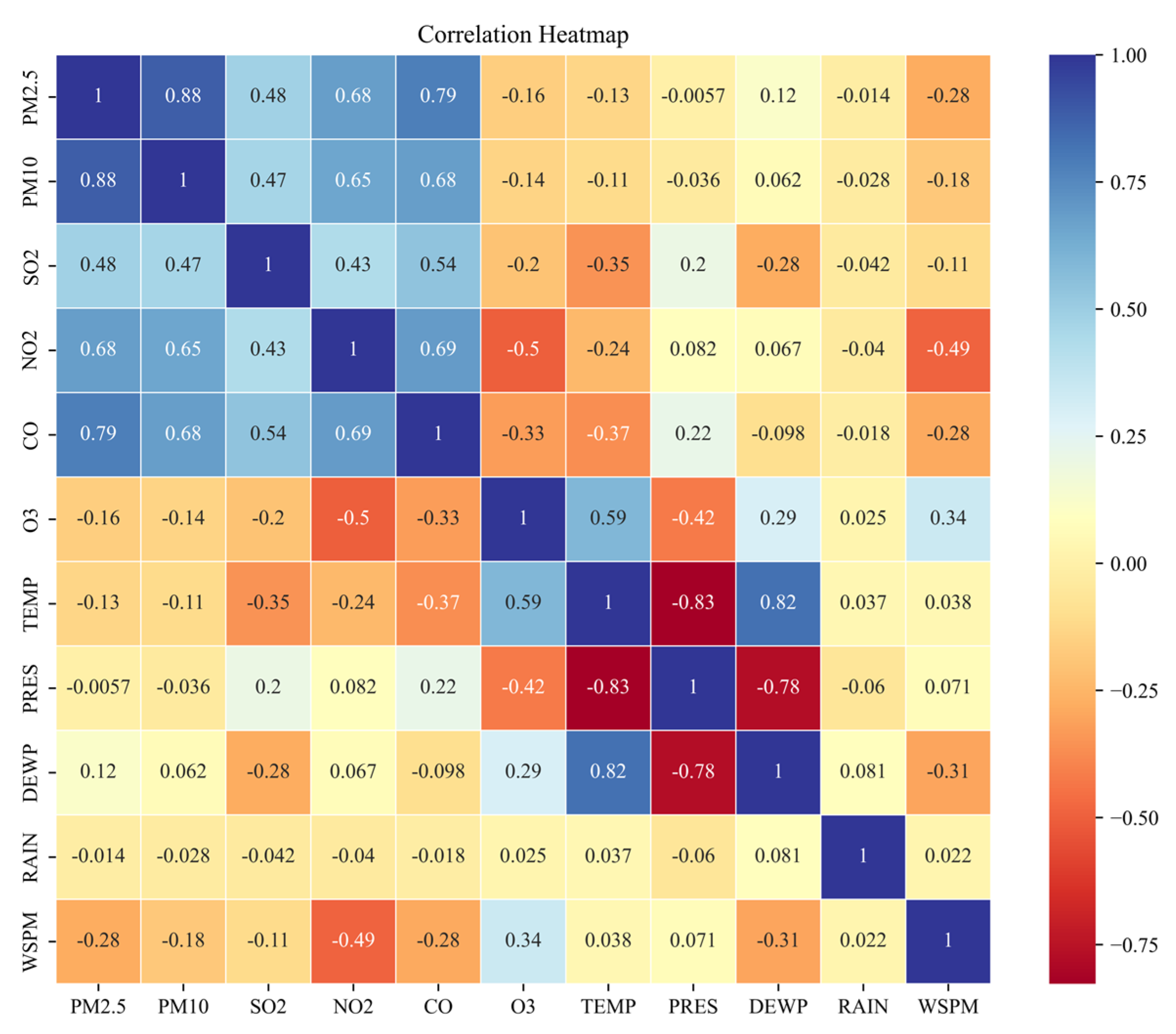
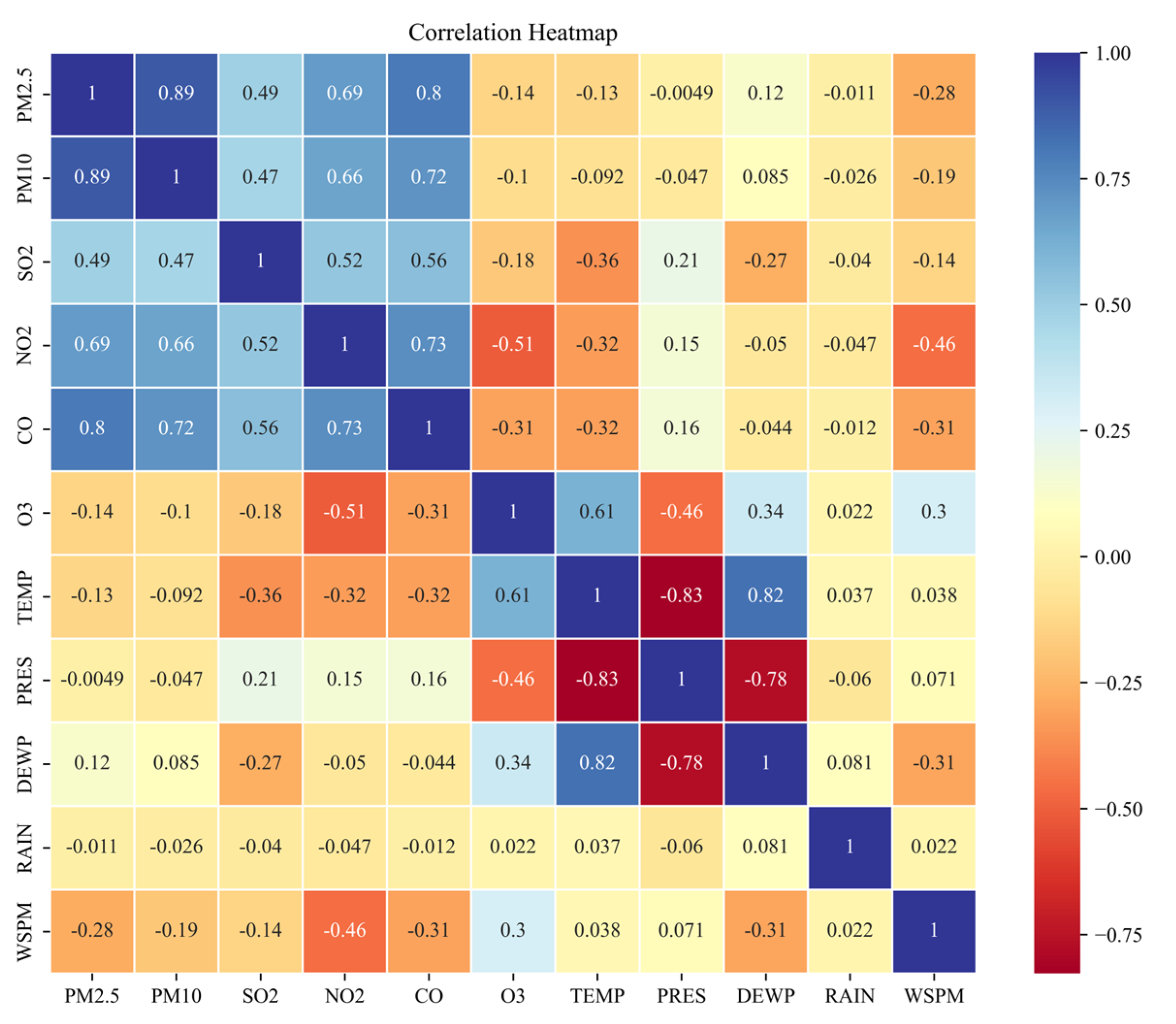
2.2. Correlation Analysis
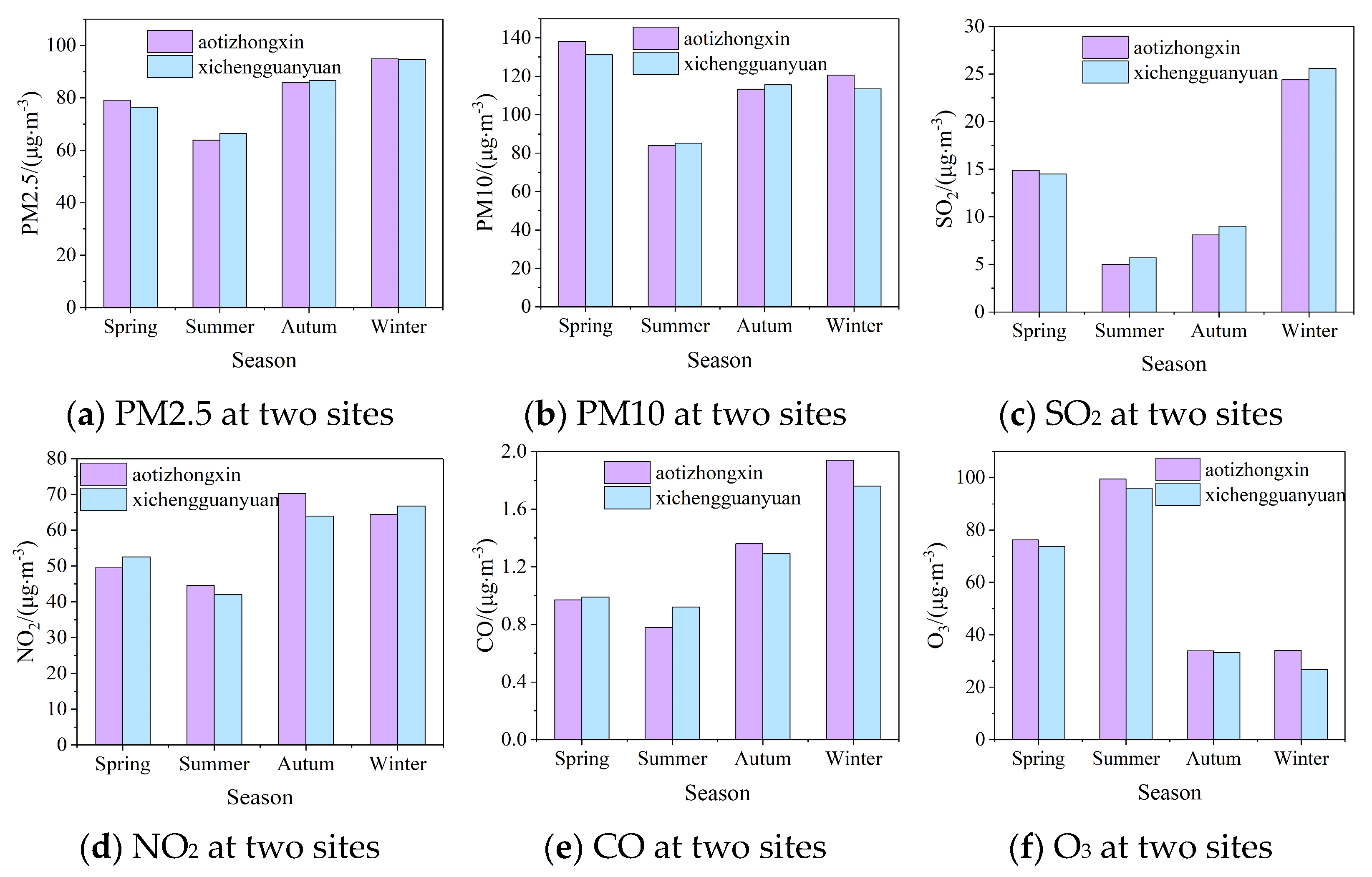
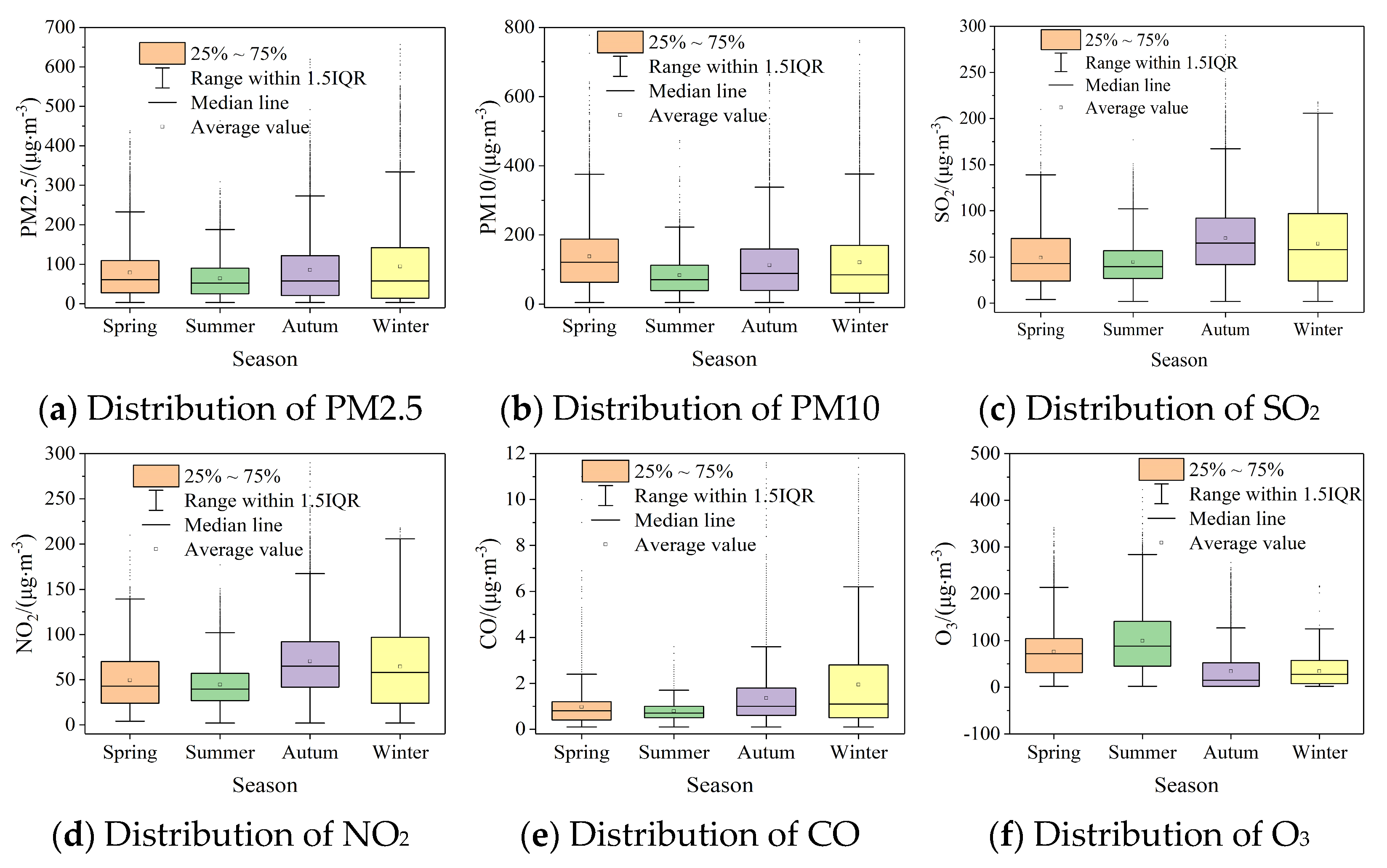
2.3. Characterization of Temporal Changes in Contamination
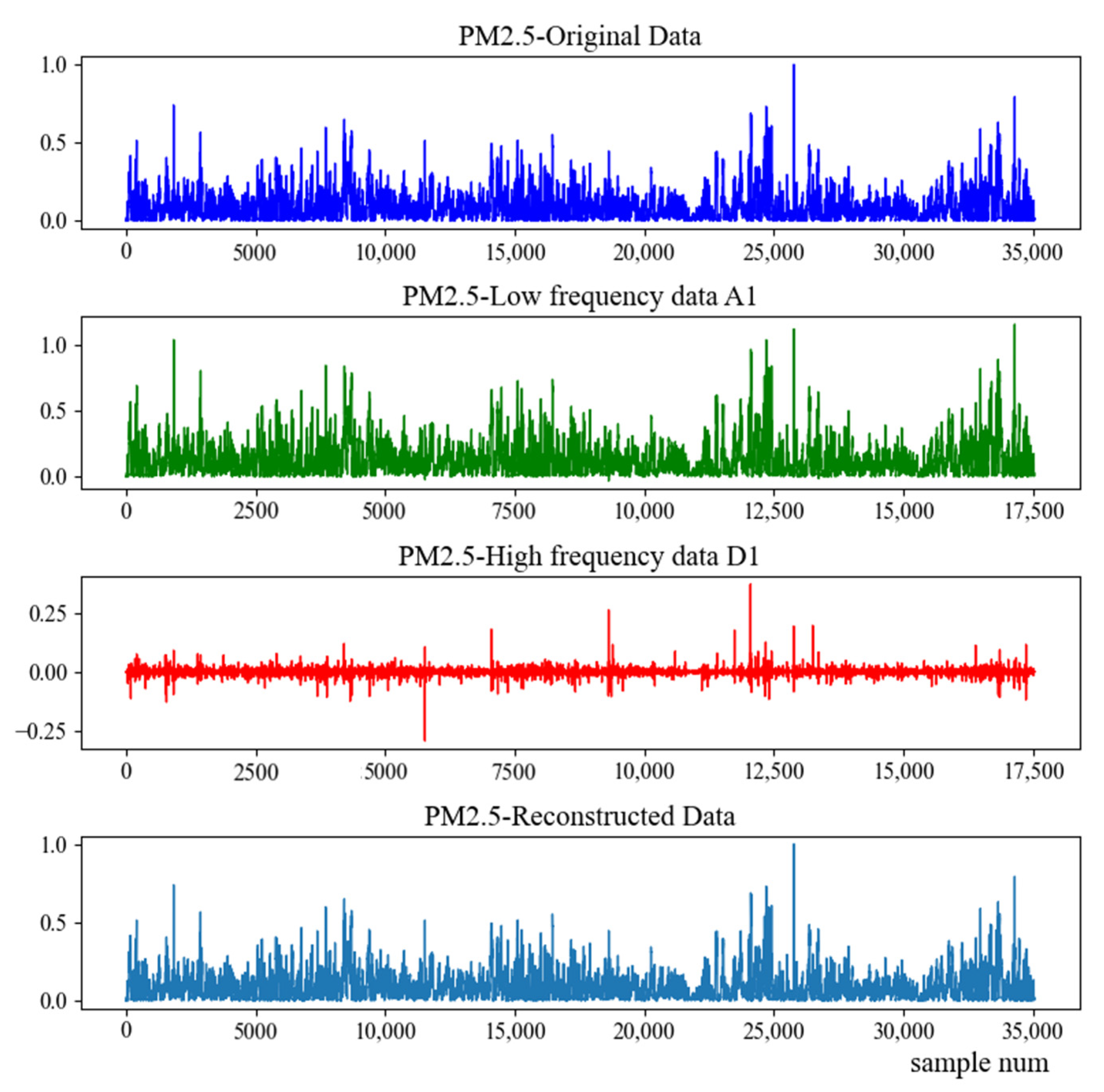
2.4. Wavelet Transform
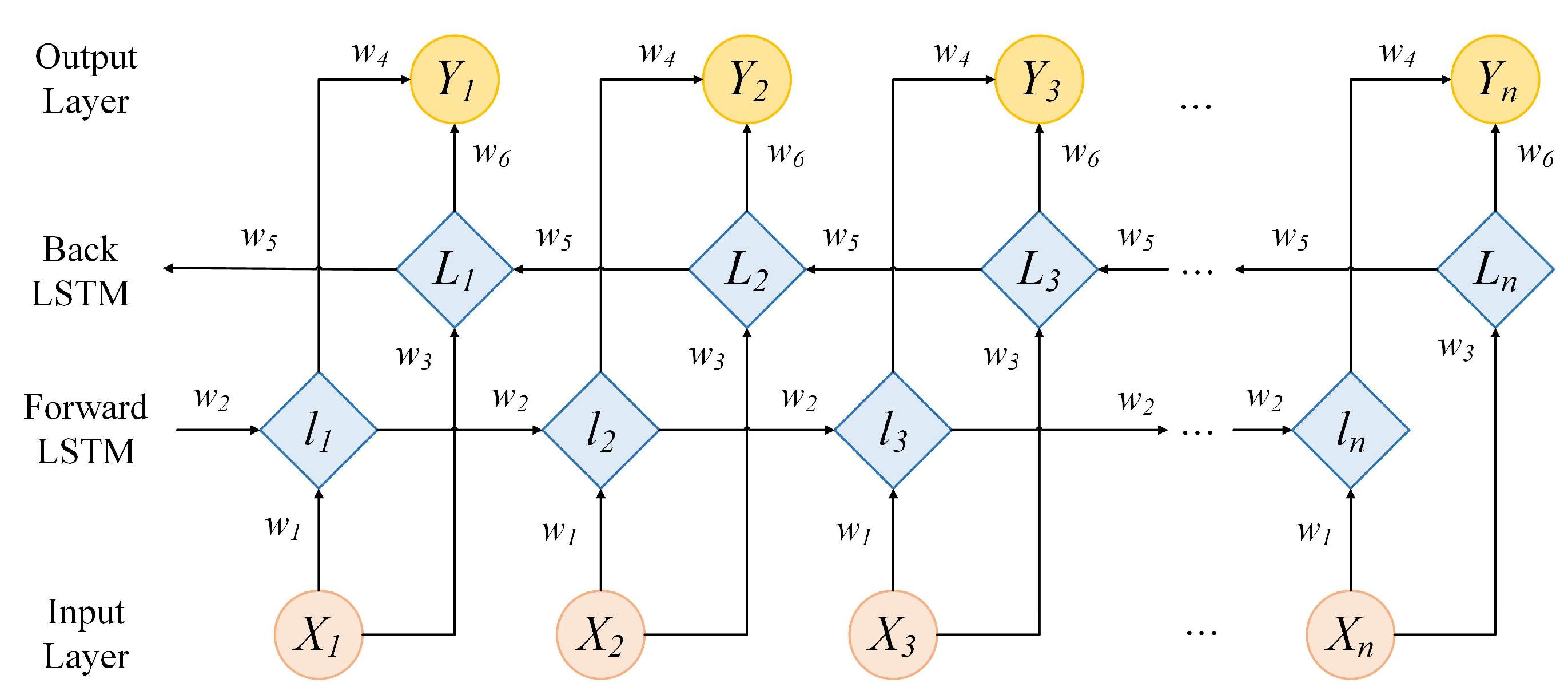
2.5. Bidirectional Long Short-Term Memory (BiLSTM)
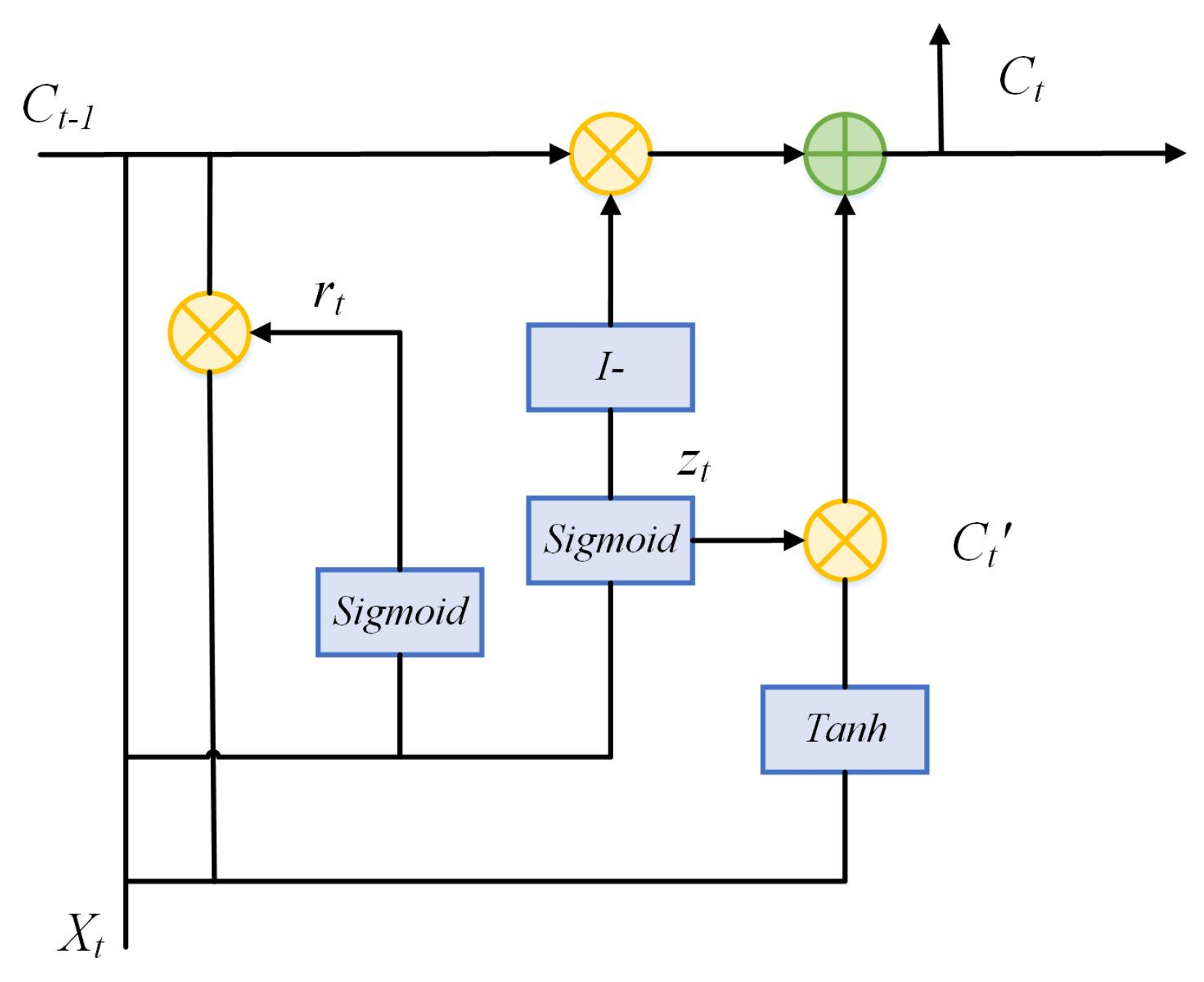
2.6. Gated Recurrent Unit (GRU)
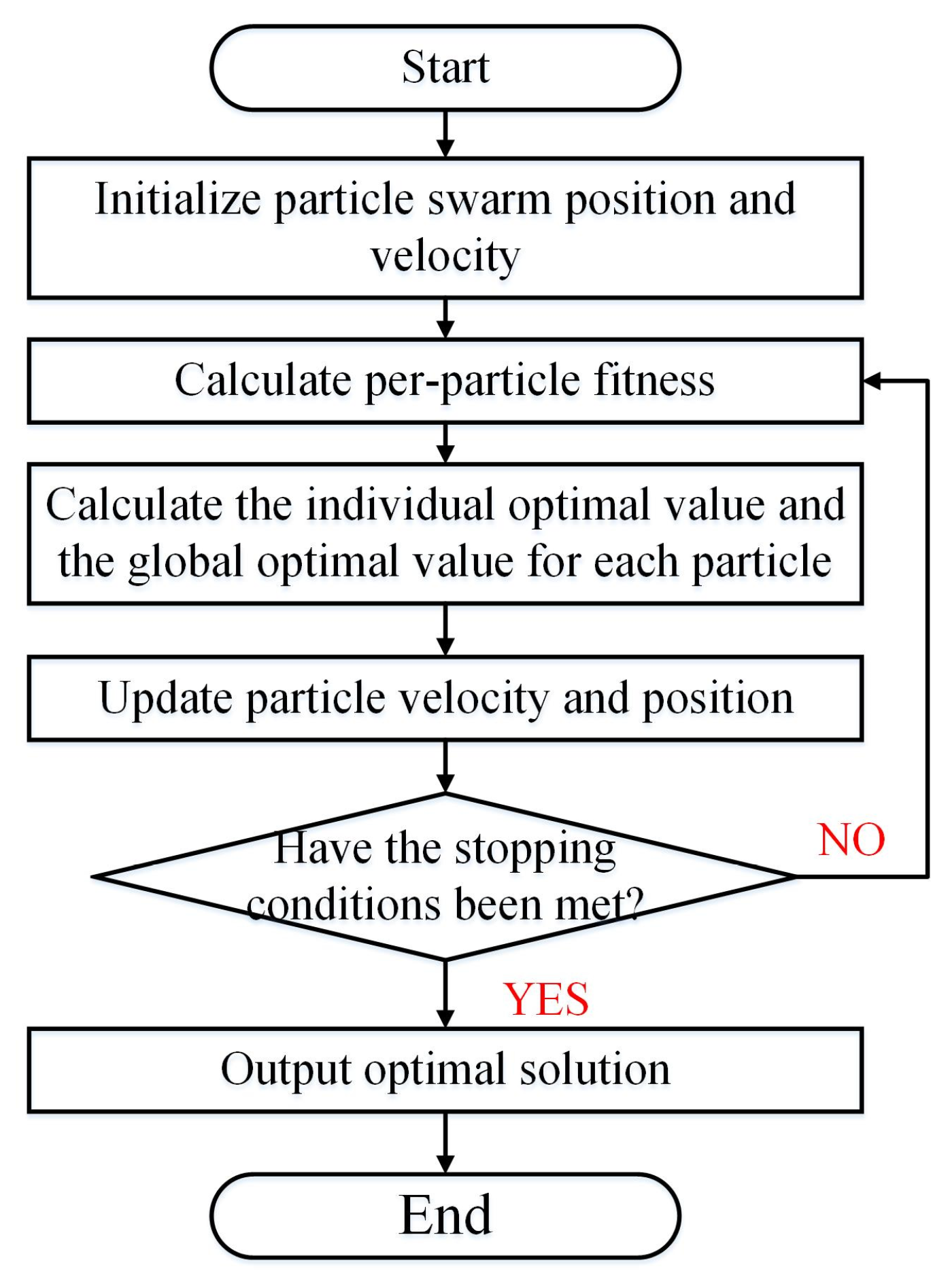
2.7. Particle Swarm Algorithm (PSO)
2.8. XGBoost
2.9. Model Evaluation Metrics
3. Results
3.1. Experiments Settings
3.2. Air Quality Prediction Model
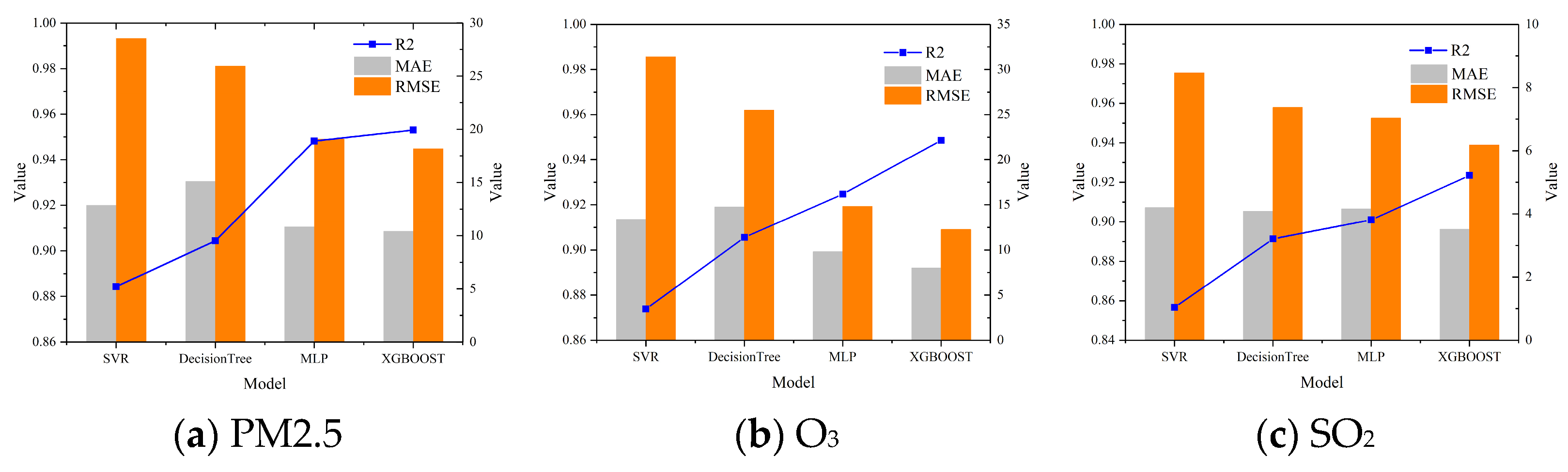
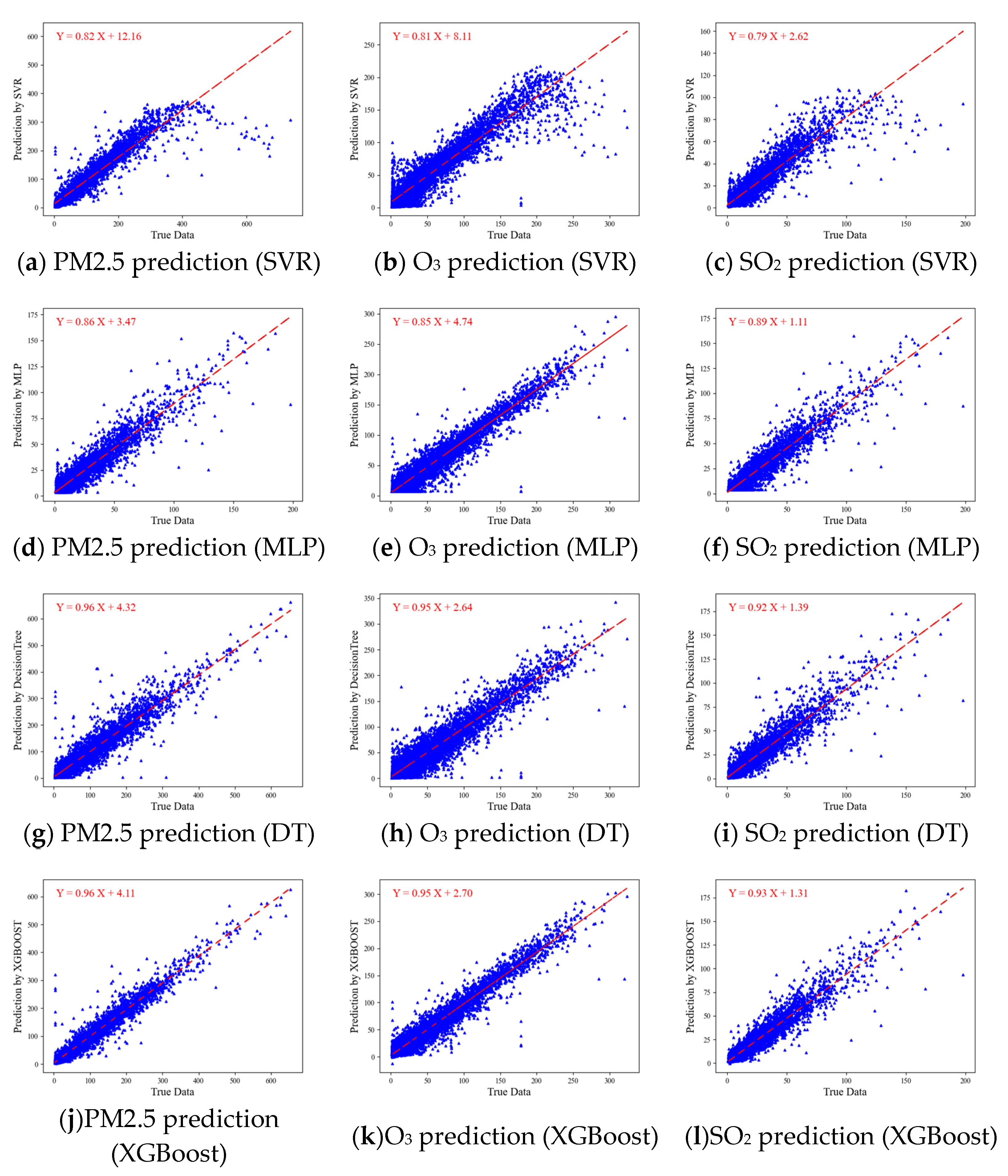
3.3. Prediction Model Validation and Sustainability Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, K.; Fan, X.Y.; Yang, X.Y.; Zhou, Z.L. An AQI decomposition ensemble model based on SSA-LSTM using improved AMSSA-VMD decomposition reconstruction technique. Environ. Res. 2023, 232, 116365. [Google Scholar] [CrossRef] [PubMed]
- Zareba, M.; Dlugosz, H.; Danek, T.; Weglinska, E. Big-Data-Driven Machine Learning for Enhancing Spatiotemporal Air Pollution Pattern Analysis. Atmosphere 2023, 14, 760. [Google Scholar] [CrossRef]
- Danek, T.; Weglinska, E.; Zareba, M. The influence of meteorological factors and terrain on air pollution concentration and migration: A geostatistical case study from Krakow, Poland. Sci. Rep. 2022, 12, 11050. [Google Scholar] [CrossRef] [PubMed]
- Brandao, R.; Foroutan, H. Air Quality in Southeast Brazil during COVID-19 Lockdown: A Combined Satellite and Ground-Based Data Analysis. Atmosphere 2021, 12, 583. [Google Scholar] [CrossRef]
- Orach, J.; Rider, C.F.; Carlsten, C. Concentration-dependent health effects of air pollution in controlled human exposures. Environ. Int. 2021, 150, 106424. [Google Scholar] [CrossRef]
- Huang, W.X.; Cheng, X.W. Multiple Regression Method for Estimating Concentration of Pm2.5 Using Remote Sensing and Meteorological Data. J. Environ. Prot. Ecol. 2017, 18, 417–424. [Google Scholar]
- Cobourn, W.G. An enhanced PM2.5 air quality forecast model based on nonlinear regression and back-trajectory concentrations. Atmos. Environ. 2010, 44, 3015–3023. [Google Scholar] [CrossRef]
- Carbajal-Hernandez, J.J.; Sanchez-Fernandez, L.P.; Carrasco-Ochoa, J.A.; Martinez-Trinidad, J.F. Assessment and prediction of air quality using fuzzy logic and autoregressive models. Atmos. Environ. 2012, 60, 37–50. [Google Scholar] [CrossRef]
- Masseran, N.; Safari, M.A.M. Statistical Modeling on the Severity of Unhealthy Air Pollution Events in Malaysia. Mathematics 2022, 10, 3004. [Google Scholar] [CrossRef]
- Agarwal, A.; Sahu, M. Forecasting PM2.5 concentrations using statistical modeling for Bengaluru and Delhi regions. Environ. Monit. Assess. 2023, 195, 502. [Google Scholar] [CrossRef]
- Li, C.S.; Xie, Z.Y.; Chen, B.; Kuang, K.J.; Xu, D.W.; Liu, J.F.; He, Z.S. Different Time Scale Distribution of Negative Air Ions Concentrations in Mount Wuyi National Park. Int. J. Environ. Res. Public Health 2021, 18, 5037. [Google Scholar] [CrossRef] [PubMed]
- Pohoata, A.; Lungu, E. A Complex Analysis Employing ARIMA Model and Statistical Methods on Air Pollutants Recorded in Ploiesti, Romania. Rev. Chim. 2017, 68, 818–823. [Google Scholar] [CrossRef]
- Sekhar, S.R.M.; Siddesh, G.M.; Tiwari, A.; Khator, A.; Singh, R. Identification and Analysis of Nitrogen Dioxide Concentration for Air Quality Prediction Using Seasonal Autoregression Integrated with Moving Average. Aerosol Sci. Eng. 2020, 4, 137–146. [Google Scholar] [CrossRef]
- Islam, M.M.; Sharmin, M.; Ahmed, F. Predicting air quality of Dhaka and Sylhet divisions in Bangladesh: A time series modeling approach. Air Qual. Atmos. Health 2020, 13, 607–615. [Google Scholar] [CrossRef]
- Rahman, R.R.; Kabir, A. Spatiotemporal analysis and forecasting of air quality in the greater Dhaka region and assessment of a novel particulate matter filtration unit. Environ. Monit. Assess. 2023, 195, 824. [Google Scholar] [CrossRef]
- Pan, J.N.; Chen, S.T. Monitoring long-memory air quality data using ARFIMA model. Environmetrics 2008, 19, 209–219. [Google Scholar] [CrossRef]
- Hajmohammadi, H.; Heydecker, B. Multivariate time series modelling for urban air quality. Urban Clim. 2021, 37, 100834. [Google Scholar] [CrossRef]
- Alvarez Aldegunde, J.A.; Fernandez Sanchez, A.; Saba, M.; Quinones Bolanos, E.; Ubeda Palenque, J. Analysis of PM2.5 and Meteorological Variables Using Enhanced Geospatial Techniques in Developing Countries: A Case Study of Cartagena de Indias City (Colombia). Atmosphere 2022, 13, 506. [Google Scholar] [CrossRef]
- Meng, X.; Liu, C.; Zhang, L.N.; Wang, W.D.; Stowell, J.; Kan, H.D.; Liu, Y. Estimating PM2.5 concentrations in Northeastern China with full spatiotemporal coverage, 2005–2016. Remote Sens. Environ. 2021, 253, 112203. [Google Scholar] [CrossRef]
- Liu, W.; Guo, G.; Chen, F.J.; Chen, Y.H. Meteorological pattern analysis assisted daily PM2.5 grades prediction using SVM optimized by PSO algorithm. Atmos. Pollut. Res. 2019, 10, 1482–1491. [Google Scholar] [CrossRef]
- Di, Q.; Amini, H.; Shi, L.H.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapustin, A.; et al. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 2019, 130, 104909. [Google Scholar] [CrossRef]
- Huang, Y.; Yu, J.H.; Dai, X.H.; Huang, Z.; Li, Y.Y. Air-Quality Prediction Based on the EMD-IPSO-LSTM Combination Model. Sustainability 2022, 14, 4889. [Google Scholar] [CrossRef]
- Hu, S.; Liu, P.F.; Qiao, Y.X.; Wang, Q.; Zhang, Y.; Yang, Y. PM2.5 concentration prediction based on WD-SA-LSTM-BP model: A case study of Nanjing city. Environ. Sci. Pollut. Res. 2022, 29, 70323–70339. [Google Scholar] [CrossRef] [PubMed]
- Mo, X.Y.; Zhang, L.; Li, H.; Qu, Z.X. A Novel Air Quality Early-Warning System Based on Artificial Intelligence. Int. J. Environ. Res. Public Health 2019, 16, 3505. [Google Scholar] [CrossRef]
- Kim, H.S.; Han, K.M.; Yu, J.; Kim, J.; Kim, K.; Kim, H. Development of a CNN plus LSTM Hybrid Neural Network for Daily PM2.5 Prediction. Atmosphere 2022, 13, 2124. [Google Scholar] [CrossRef]
- Wang, Z.C.; Xie, F. Medium and long-term trend prediction of urban air quality based on deep learning. Int. J. Environ. Technol. Manag. 2022, 25, 22–37. [Google Scholar] [CrossRef]
- Yang, Y.T.; Mei, G.; Izzo, S. Revealing Influence of Meteorological Conditions on Air Quality Prediction Using Explainable Deep Learning. IEEE Access 2022, 10, 50755–50773. [Google Scholar] [CrossRef]
- Sun, X.T.; Xu, W. Deep Random Subspace Learning: A Spatial-Temporal Modeling Approach for Air Quality Prediction. Atmosphere 2019, 10, 560. [Google Scholar] [CrossRef]
- Liu, B.; Yan, S.; Li, J.Q.; Qu, G.Z.; Li, Y.; Lang, J.L.; Gu, R.T. A Sequence-to-Sequence Air Quality Predictor Based on the n-Step Recurrent Prediction. IEEE Access 2019, 7, 43331–43345. [Google Scholar] [CrossRef]
- Chen, H.Q.; Guan, M.X.; Li, H. Air Quality Prediction Based on Integrated Dual LSTM Model. IEEE Access 2021, 9, 93285–93297. [Google Scholar] [CrossRef]
- Ketu, S. Spatial Air Quality Index and Air Pollutant Concentration prediction using Linear Regression based Recursive Feature Elimination with Random Forest Regression (RFERF): A case study in India. Nat. Hazards 2022, 114, 2109–2138. [Google Scholar] [CrossRef]
- Jiang, W.X.; Zhu, G.C.; Shen, Y.Y.; Xie, Q.; Ji, M.; Yu, Y.T. An Empirical Mode Decomposition Fuzzy Forecast Model for Air Quality. Entropy 2022, 24, 1803. [Google Scholar] [CrossRef] [PubMed]
- Phruksahiran, N. Improvement of air quality index prediction using geographically weighted predictor methodology. Urban Clim. 2021, 38, 100890. [Google Scholar] [CrossRef]
- Zhang, Q.; Wu, S.; Wang, X.W.; Sun, B.Z.; Liu, H.M. A PM2.5 concentration prediction model based on multi-task deep learning for intensive air quality monitoring stations. J. Clean. Prod. 2020, 275, 122722. [Google Scholar] [CrossRef]
- Cai, J.X.; Dai, X.; Hong, L.; Gao, Z.T.; Qiu, Z.C. An Air Quality Prediction Model Based on a Noise Reduction Self-Coding Deep Network. Math. Probl. Eng. 2020, 2020, 3507197. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Hu, Y.; Shao, J.; Chi, T.H. Deep learning architecture for air quality predictions. Environ. Sci. Pollut. Res. 2016, 23, 22408–22417. [Google Scholar] [CrossRef]
- Liu, B.; Yan, S.; Li, J.Q.; Li, Y. Forecasting PM2.5 Concentration using Spatio-Temporal Extreme Learning Machine. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (Icmla 2016), Anaheim, CA, USA, 18–20 December 2016; pp. 950–953. [Google Scholar]
- Sui, S.S.; Han, Q.L. Multi-view multi-task spatiotemporal graph convolutional network for air quality prediction. Sci. Total Environ. 2023, 893, 164699. [Google Scholar] [CrossRef]
- Liu, C.C.; Lin, T.C.; Yuan, K.Y.; Chiueh, P.T. Spatio-temporal prediction and factor identification of urban air quality using support vector machine. Urban Clim. 2022, 41, 101055. [Google Scholar] [CrossRef]
- Freeman, B.S.; Taylor, G.; Gharabaghi, B.; The, J. Forecasting air quality time series using deep learning. J. Air Waste Manag. Assoc. 2018, 68, 866–886. [Google Scholar] [CrossRef]
- Aarthi, C.; Ramya, V.J.; Falkowski-Gilski, P.; Divakarachari, P.B. Balanced Spider Monkey Optimization with Bi-LSTM for Sustainable Air Quality Prediction. Sustainability 2023, 15, 1637. [Google Scholar] [CrossRef]
- Gu, K.Y.; Zhou, Y.; Sun, H.; Zhao, L.M.; Liu, S.K. Prediction of air quality in Shenzhen based on neural network algorithm. Neural Comput. Appl. 2020, 32, 1879–1892. [Google Scholar] [CrossRef]
- Gunasekar, S.; Kumar, G.J.R.; Kumar, Y.D. Sustainable optimized LSTM-based intelligent system for air quality prediction in Chennai. Acta Geophys. 2022, 70, 2889–2899. [Google Scholar] [CrossRef]
- Gunasekar, S.; Kumar, G.J.R.; Agbulu, G.P. Air Quality Predictions in Urban Areas Using Hybrid ARIMA and Metaheuristic LSTM. Comput. Syst. Sci. Eng. 2022, 43, 1271–1284. [Google Scholar] [CrossRef]
- Liu, T.Y.; You, S.B. Analysis and Forecast of Beijing’s Air Quality Index Based on ARIMA Model and Neural Network Model. Atmosphere 2022, 13, 512. [Google Scholar] [CrossRef]
- Abu Bakar, M.A.; Ariff, N.M.; Nadzir, M.S.M.; Wen, O.L.; Suris, F.N.A. Prediction of Multivariate Air Quality Time Series Data using Long Short-Term Memory Network. Malays. J. Fundam. Appl. Sci. 2022, 18, 52–59. [Google Scholar] [CrossRef]
- Hamza, M.A.; Shaiba, H.; Marzouk, R.; Alhindi, A.; Asiri, M.M.; Yaseen, I.; Motwakel, A.; Rizwanullah, M. Big Data Analytics with Artificial Intelligence Enabled Environmental Air Pollution Monitoring Framework. Cmc-Comput. Mater. Contin. 2022, 73, 3235–3250. [Google Scholar] [CrossRef]
- Bai, W.; Li, F.Y. PM2.5 concentration prediction using deep learning in internet of things air monitoring system. Environ. Eng. Res. 2023, 28, 210456. [Google Scholar] [CrossRef]
- Zhang, Q.; Geng, G.N.; Wang, S.W.; Richter, A.; He, K.B. Satellite remote sensing of changes in NO(x) emissions over China during 1996–2010. Chin. Sci. Bull. 2012, 57, 2857–2864. [Google Scholar] [CrossRef]
- Maji, K.J.; Ye, W.F.; Arora, M.; Nagendra, S.M.S. Ozone pollution in Chinese cities: Assessment of seasonal variation, health effects and economic burden. Environ. Pollut. 2019, 247, 792–801. [Google Scholar] [CrossRef]
- Feng, Z.P.; Liang, M.; Chu, F.L. Recent advances in time-frequency analysis methods for machinery fault diagnosis: A review with application examples. Mech. Syst. Signal Process. 2013, 38, 165–205. [Google Scholar] [CrossRef]
- Jin, N.; Zeng, Y.; Yan, K.; Ji, Z. Multivariate Air Quality Forecasting with Nested Long Short Term Memory Neural Network. IEEE Trans. Ind. Inform. 2021, 17, 8514–8522. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.S.; Hu, C.H.; Zhang, J.X. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Kulshrestha, A.; Krishnaswamy, V.; Sharma, M. Bayesian BILSTM approach for tourism demand forecasting. Ann. Tour. Res. 2020, 83, 102925. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.F.; Zhang, S.; Han, J.C.; Wang, G.Q.; Zhang, M.X.; Lin, Q.S. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Gong, Y.J.; Li, J.J.; Zhou, Y.C.; Li, Y.; Chung, H.S.H.; Shi, Y.H.; Zhang, J. Genetic Learning Particle Swarm Optimization. IEEE Trans. Cybern. 2016, 46, 2277–2290. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Pan, S.W.; Zheng, Z.C.; Guo, Z.; Luo, H.N. An optimized XGBoost method for predicting reservoir porosity using petrophysical logs. J. Pet. Sci. Eng. 2022, 208, 109520. [Google Scholar] [CrossRef]
- Wu, K.H.; Chai, Y.Y.; Zhang, X.L.; Zhao, X. Research on Power Price Forecasting Based on PSO-XGBoost. Electronics 2022, 11, 3763. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Day | Month | Year | Hour (h) | PM2.5 (μg·m−3) | PM10 (μg·m−3) | SO2 (μg·m−3) | NO2 (μg·m−3) | CO (μg·m−3) | O3 (μg·m−3) | TEMP (°C) | PRES (hpa) | DEWP (°C) | RAIN (mm) | WSPM (m/s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 03 | 2013 | 0 | 4 | 4 | 4 | 7 | 0.3 | 77 | −0.7 | 1023 | −18.8 | 0 | 4.4 |
| 01 | 03 | 2013 | 1 | 8 | 8 | 4 | 7 | 0.3 | 77 | −1.1 | 1023.2 | −18.2 | 0 | 4.7 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | ||
| … | … | … | … | … | … | … | … | … | … | … | … | … | ||
| 26 | 06 | 2015 | 2 | 108 | 108 | 2 | 12 | 0.5 | 152 | 21.1 | 995.6 | 19.4 | 5.3 | 0.7 |
| 26 | 06 | 2015 | 3 | 104 | 104 | 2 | 16 | 0.6 | 130 | 20.8 | 995.7 | 19.6 | 9.6 | 0.3 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | ||
| 28 | 02 | 2017 | 22 | 21 | 44 | 12 | 87 | 0.7 | 35 | 10.5 | 1014.4 | −12.9 | 0 | 1.2 |
| 28 | 02 | 2017 | 23 | 19 | 31 | 10 | 79 | 0.6 | 42 | 8.6 | 1014.1 | −15.9 | 0 | 1.3 |
| Parameter | Value |
|---|---|
| Number of layers | 3 |
| Number of neurons per layer | 135 |
| Optimizer | Adam |
| Learning rate | 0.01 |
| Activation function | Relu |
| Loss function | Mean_absolute_error |
| Batch_size | 94 |
| Epochs | 50 |
| Dropout | 0.16 |
| Parameter | Value |
|---|---|
| Number of layers | 2 |
| Number of neurons per layer | 150 |
| Optimizer | Adam |
| Learning rate | 0.01 |
| Activation function | Relu |
| Loss function | Mean_absolute_error |
| Batch_size | 32 |
| Epochs | 50 |
| Dropout | 0.2 |
| Site | Experimental Indicators | Model | R2 | MAE | RMSE |
|---|---|---|---|---|---|
| aotizhongxin | PM2.5 | SVR | 0.8754 | 0.0008 | 0.0289 |
| Random Forest | 0.9354 | 0.0110 | 0.0232 | ||
| LSTM | 0.9409 | 0.0137 | 0.0253 | ||
| BiLSTM | 0.9429 | 0.0129 | 0.0249 | ||
| W-BiLSTM | 0.9450 | 0.0147 | 0.0244 | ||
| W-BiLSTM-GRU | 0.9537 | 0.0113 | 0.0224 | ||
| W-BiLSTM(PSO)-GRU | 0.9747 | 0.0076 | 0.0158 | ||
| PM10 | SVR | 0.8920 | 0.0004 | 0.0196 | |
| Random Forest | 0.8625 | 0.0195 | 0.0389 | ||
| LSTM | 0.9029 | 0.0113 | 0.0189 | ||
| BiLSTM | 0.9078 | 0.0097 | 0.0184 | ||
| W-BiLSTM | 0.9237 | 0.0085 | 0.0137 | ||
| W-BiLSTM-GRU | 0.9318 | 0.0076 | 0.0129 | ||
| W-BiLSTM(PSO)-GRU | 0.9572 | 0.0058 | 0.0100 | ||
| SO2 | SVR | 0.8127 | 0.0006 | 0.0246 | |
| Random Forest | 0.8986 | 0.0111 | 0.0215 | ||
| LSTM | 0.8918 | 0.0082 | 0.0156 | ||
| BiLSTM | 0.9050 | 0.0077 | 0.0146 | ||
| W-BiLSTM | 0.9242 | 0.0070 | 0.0131 | ||
| W-BiLSTM-GRU | 0.9291 | 0.0065 | 0.0126 | ||
| W-BiLSTM(PSO)-GRU | 0.9421 | 0.0045 | 0.0116 | ||
| NO2 | SVR | 0.7545 | 0.0031 | 0.055 | |
| Random Forest | 0.8440 | 0.0357 | 0.0506 | ||
| LSTM | 0.8996 | 0.0268 | 0.0427 | ||
| BiLSTM | 0.9040 | 0.0256 | 0.0417 | ||
| W-BiLSTM | 0.9263 | 0.0256 | 0.0366 | ||
| W-BiLSTM-GRU | 0.9355 | 0.0223 | 0.0342 | ||
| W-BiLSTM(PSO)-GRU | 0.9770 | 0.0143 | 0.0198 | ||
| CO | SVR | 0.7969 | 0.0023 | 0.0478 | |
| Random Forest | 0.8881 | 0.0223 | 0.0424 | ||
| LSTM | 0.9118 | 0.0226 | 0.0477 | ||
| BiLSTM | 0.9167 | 0.0255 | 0.0464 | ||
| W-BiLSTM | 0.9458 | 0.0201 | 0.0374 | ||
| W-BiLSTM-GRU | 0.9461 | 0.0215 | 0.0373 | ||
| W-BiLSTM(PSO)-GRU | 0.9771 | 0.0119 | 0.0226 | ||
| O3 | SVR | 0.7443 | 0.0028 | 0.0533 | |
| Random Forest | 0.8367 | 0.0349 | 0.0539 | ||
| LSTM | 0.9195 | 0.0243 | 0.0361 | ||
| BiLSTM | 0.9225 | 0.0225 | 0.0355 | ||
| W-BiLSTM | 0.9310 | 0.0227 | 0.0335 | ||
| W-BiLSTM-GRU | 0.9383 | 0.0202 | 0.0317 | ||
| W-BiLSTM(PSO)-GRU | 0.9852 | 0.0107 | 0.0159 |
| Site | Experimental Indicators | Model | R2 | MAE | RMSE |
|---|---|---|---|---|---|
| xichengguanyuan | PM2.5 | SVR | 0.8779 | 0.0014 | 0.0370 |
| Random Forest | 0.9261 | 0.0191 | 0.0321 | ||
| LSTM | 0.9468 | 0.0166 | 0.03165 | ||
| BiLSTM | 0.9502 | 0.0161 | 0.0306 | ||
| W-BiLSTM | 0.9612 | 0.0146 | 0.0270 | ||
| W-BiLSTM-GRU | 0.9697 | 0.0158 | 0.0238 | ||
| W-BiLSTM(PSO)-GRU | 0.9707 | 0.0125 | 0.0226 | ||
| PM10 | SVR | 0.7498 | 0.0015 | 0.0389 | |
| Random Forest | 0.8951 | 0.0154 | 0.0289 | ||
| LSTM | 0.9073 | 0.0177 | 0.0313 | ||
| BiLSTM | 0.9135 | 0.0166 | 0.0302 | ||
| W-BiLSTM | 0.9330 | 0.0161 | 0.0266 | ||
| W-BiLSTM-GRU | 0.9337 | 0.0151 | 0.0264 | ||
| W-BiLSTM(PSO)-GRU | 0.9658 | 0.0108 | 0.0186 | ||
| SO2 | SVR | 0.7944 | 0.0009 | 0.0305 | |
| Random Forest | 0.8177 | 0.0172 | 0.0358 | ||
| LSTM | 0.8254 | 0.0092 | 0.0236 | ||
| BiLSTM | 0.8324 | 0.0088 | 0.0231 | ||
| W-BiLSTM | 0.8523 | 0.0081 | 0.0217 | ||
| W-BiLSTM-GRU | 0.9185 | 0.0084 | 0.0162 | ||
| W-BiLSTM(PSO)-GRU | 0.9450 | 0.0055 | 0.0133 | ||
| NO2 | SVR | 0.7524 | 0.0032 | 0.0562 | |
| Random Forest | 0.8533 | 0.0353 | 0.0506 | ||
| LSTM | 0.9111 | 0.0263 | 0.0403 | ||
| BiLSTM | 0.9117 | 0.0255 | 0.0402 | ||
| W-BiLSTM | 0.9162 | 0.0290 | 0.0391 | ||
| W-BiLSTM-GRU | 0.9343 | 0.0231 | 0.0347 | ||
| W-BiLSTM(PSO)-GRU | 0.9792 | 0.0131 | 0.0194 | ||
| CO | SVR | 0.8298 | 0.0013 | 0.0367 | |
| Random Forest | 0.8768 | 0.0186 | 0.0351 | ||
| LSTM | 0.9135 | 0.0172 | 0.0347 | ||
| BiLSTM | 0.9200 | 0.0173 | 0.0334 | ||
| W-BiLSTM | 0.9290 | 0.0217 | 0.0314 | ||
| W-BiLSTM-GRU | 0.9467 | 0.0152 | 0.0272 | ||
| W-BiLSTM(PSO)-GRU | 0.9759 | 0.0097 | 0.0174 | ||
| O3 | SVR | 0.7642 | 0.0025 | 0.0497 | |
| Random Forest | 0.8394 | 0.0333 | 0.0560 | ||
| LSTM | 0.9087 | 0.0227 | 0.0359 | ||
| BiLSTM | 0.9125 | 0.0168 | 0.0304 | ||
| W-BiLSTM | 0.9251 | 0.0209 | 0.032 | ||
| W-BiLSTM-GRU | 0.9281 | 0.0191 | 0.0318 | ||
| W-BiLSTM(PSO)-GRU | 0.9726 | 0.0133 | 0.0201 |
| Parameter | Value |
|---|---|
| learning_rate | 0.08 |
| n_estimators | 300 |
| gamma | 0.07 |
| min_child_weight | 1 |
| subsample | 1 |
| max_depth | 3 |
| min_child_weight | 1 |
| n_jobs | 1 |
| max_delta_step | 0 |
| reg_alpha | 0 |
| reg_lambda | 1 |
| colsample_bytree | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, W.; Chen, X.; He, Z.; Zhou, S. A Prediction Hybrid Framework for Air Quality Integrated with W-BiLSTM(PSO)-GRU and XGBoost Methods. Sustainability 2023, 15, 16064. https://doi.org/10.3390/su152216064
Chang W, Chen X, He Z, Zhou S. A Prediction Hybrid Framework for Air Quality Integrated with W-BiLSTM(PSO)-GRU and XGBoost Methods. Sustainability. 2023; 15(22):16064. https://doi.org/10.3390/su152216064
Chicago/Turabian StyleChang, Wenbing, Xu Chen, Zhao He, and Shenghan Zhou. 2023. "A Prediction Hybrid Framework for Air Quality Integrated with W-BiLSTM(PSO)-GRU and XGBoost Methods" Sustainability 15, no. 22: 16064. https://doi.org/10.3390/su152216064
APA StyleChang, W., Chen, X., He, Z., & Zhou, S. (2023). A Prediction Hybrid Framework for Air Quality Integrated with W-BiLSTM(PSO)-GRU and XGBoost Methods. Sustainability, 15(22), 16064. https://doi.org/10.3390/su152216064