
Gamified Text Testing for Sustainable Fairness

Abstract
:1. Introduction
2. Related Work
2.1. Artificial Intelligence Fairness
2.2. Gamification and Artificial Intelligence
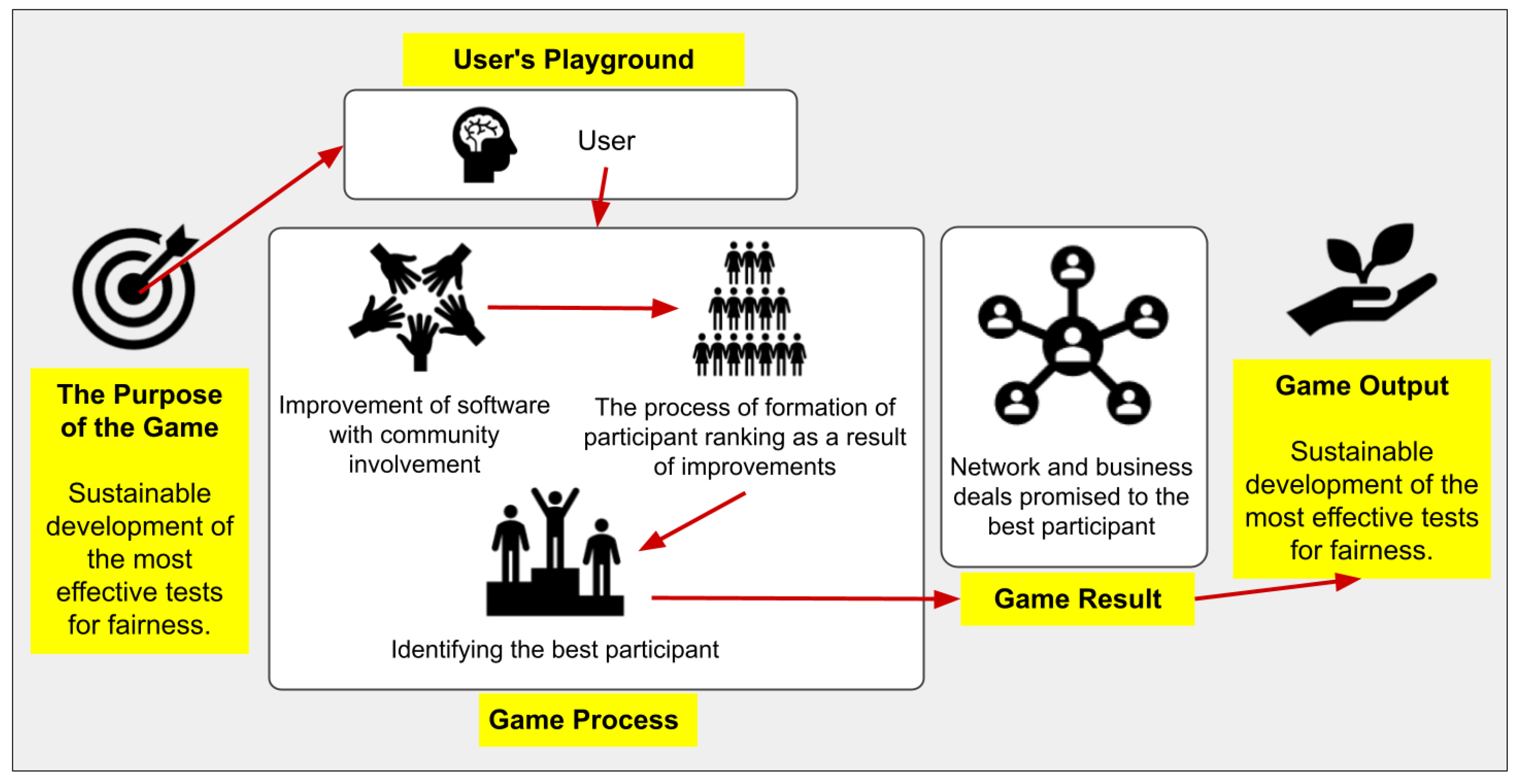
3. Method
3.1. Gamification Elements
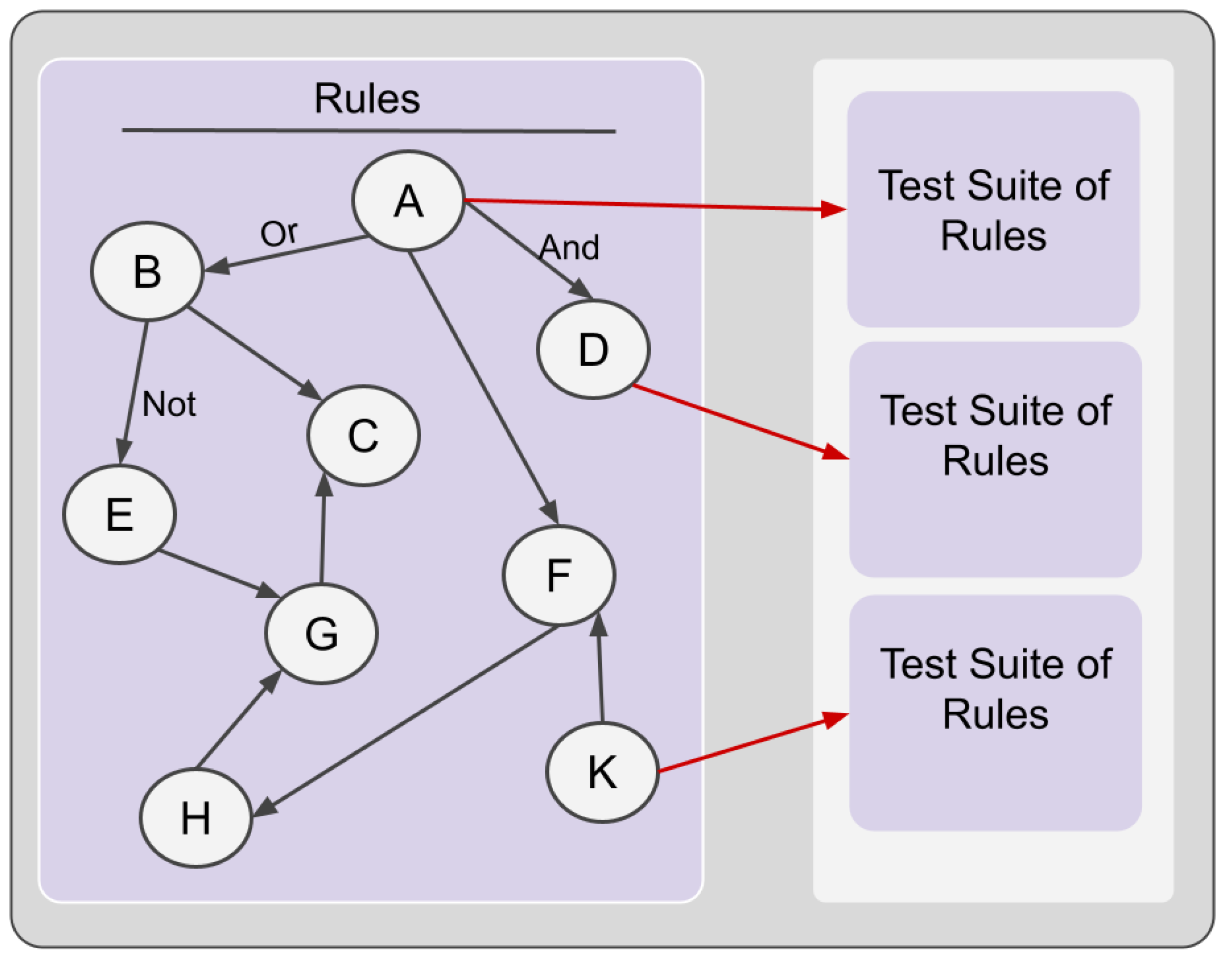
3.1.1. Rule and Comment
3.1.2. Text Testing
3.1.3. Score
3.2. Player Action Steps
4. Sample Scenario
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kleinberg, J.; Mullainathan, S.; Raghavan, M. Inherent Trade-Offs in the Fair Determination of Risk Scores. arXiv 2016, arXiv:1609.05807. [Google Scholar]
- Grgic-Hlaca, N.; Redmiles, E.M.; Gummadi, K.P.; Weller, A. Human Perceptions of Fairness in Algorithmic Decision Making: A Case Study of Criminal Risk Prediction. In Proceedings of the 2018 World Wide Web Conference, International World Wide Web Conferences Steering Committee, Lyon, France, 23–27 April 2018; pp. 903–912. [Google Scholar]
- Plane, A.C.; Redmiles, E.M.; Mazurek, M.L.; Tschantz, M.C. Exploring User Perceptions of Discrimination in Online Targeted Advertising. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; pp. 935–951. [Google Scholar]
- Makhlouf, K.; Zhioua, S.; Palamidessi, C. Machine learning fairness notions: Bridging the gap with real-world applications. Inf. Process. Manag. 2021, 58, 102642. [Google Scholar] [CrossRef]
- Tian, H.; Zhu, T.; Liu, W.; Zhou, W. Image fairness in deep learning: Problems, models, and challenges. Neural Comput. Appl. 2022, 34, 12875–12893. [Google Scholar] [CrossRef]
- Asudeh, A.; Jin, Z.; Jagadish, H.V. Assessing and Remedying Coverage for a Given Dataset. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–12 April 2019; pp. 554–565. [Google Scholar]
- Friedler, S.A.; Scheidegger, C.; Venkatasubramanian, S. On the (im)possibility of fairness. arXiv 2016, arXiv:1609.07236. [Google Scholar] [CrossRef]
- Friedler, S.A.; Scheidegger, C.; Venkatasubramanian, S. The (Im)possibility of fairness: Different value systems require different mechanisms for fair decision making. Commun. ACM 2021, 64, 136–143. [Google Scholar] [CrossRef]
- Pitoura, E. Social-minded Measures of Data Quality: Fairness, Diversity, and Lack of Bias. J. Data Inf. Qual. 2020, 12, 1–8. [Google Scholar] [CrossRef]
- Pitoura, E.; Stefanidis, K.; Koutrika, G. Fairness in rankings and recommendations: An overview. VLDB J. 2022, 31, 431–458. [Google Scholar] [CrossRef]
- Kim, B.; Park, J.; Suh, J. Transparency and accountability in AI decision support: Explaining and visualizing convolutional neural networks for text information. Decis. Support Syst. 2020, 134, 113302. [Google Scholar] [CrossRef]
- Hamari, J. Gamification. In The Blackwell Encyclopedia of Sociology; Wiley: Hoboken, NJ, USA, 2019; pp. 1–3. [Google Scholar]
- Jennings, J. Urban Planning, Community Participation, and the Roxbury Master Plan in Boston. Ann. Am. Acad. Political Soc. Sci. 2004, 594, 12–33. [Google Scholar] [CrossRef]
- Pelling, N. The (short) prehistory of gamification, Funding Startups (& other impossibilities). J. Nano Dome 2011. Available online: https://nanodome.wordpress.com/2011/08/09/the-short-prehistory-of-gamification/ (accessed on 16 September 2022).
- Deterding, S.; Dixon, D.; Khaled, R.; Nacke, L. From game design elements to gamefulness. In Proceedings of the 15th International Academic MindTrek Conference on Envisioning Future Media Environments—MindTrek ’11, Tampere, Finland, 28–30 September 2011; ACM Press: New York, NY, USA, 2011. [Google Scholar]
- Kanat, I.E.; Siloju, S.; Raghu, T.S.; Vinze, A.S. Gamification of emergency response training: A public health example. In Proceedings of the 2013 IEEE International Conference on Intelligence and Security Informatics, Seattle, WA, USA, 4–7 June 2013; pp. 134–136. [Google Scholar]
- Romano, M.; Díaz, P.; Aedo, I. Gamification-less: May gamification really foster civic participation? A controlled field experiment. J. Ambient Intell. Humaniz. Comput. 2022, 13, 4451–4465. [Google Scholar] [CrossRef]
- Malone, T.W. Toward a theory of intrinsically motivating instruction. Cogn. Sci. 1981, 5, 333–369. [Google Scholar] [CrossRef]
- Ryan, R.M.; Deci, E.L. Self-determination theory and the facilitation of intrinsic motivation, social development, and well-being. Am. Psychol. 2000, 55, 68–78. [Google Scholar] [CrossRef]
- Chouldechova, A.; Roth, A. A snapshot of the frontiers of fairness in machine learning. Commun. ACM 2020, 63, 82–89. [Google Scholar] [CrossRef]
- Kay, M.; Matuszek, C.; Munson, S.A. Unequal Representation and Gender Stereotypes in Image Search Results for Occupations. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 3819–3828. [Google Scholar]
- Angwin, J.; Larson, J.; Mattu, S.; Kirchner, L. Machine Bias. Propublica. 2016. Available online: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing (accessed on 23 September 2022).
- Martin, N. How Social Media Has Changed HowWe Consume News. Forbes Magazine, 13 November 2018. [Google Scholar]
- Ferraro, A.; Serra, X.; Bauer, C. Break the Loop: Gender Imbalance in Music Recommenders. In Proceedings of the 2021 Conference on Human Information Interaction and Retrieval, Online, 14–19 March 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 249–254. [Google Scholar]
- Imana, B.; Korolova, A.; Heidemann, J. Auditing for Discrimination in Algorithms Delivering Job Ads. In Proceedings of the Web Conference 2021, New York, NY, USA, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3767–3778. [Google Scholar]
- Zehlike, M.; Yang, K.; Stoyanovich, J. Fairness in Ranking: A Survey. arXiv 2021, arXiv:2103.14000. [Google Scholar]
- Ekstrand, M.D.; Burke, R.; Diaz, F. Fairness and Discrimination in Retrieval and Recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1403–1404. [Google Scholar]
- Asudeh, A.; Jagadish, H.V. Fairly evaluating and scoring items in a data set. Proc. VLDB Endow. 2020, 13, 3445–3448. [Google Scholar] [CrossRef]
- Oosterhuis, H.; Jagerman, R.; de Rijke, M. Unbiased Learning to Rank: Counterfactual and Online Approaches. In Proceedings of the Web Conference 2020, Taibei, Taiwan, 20–24 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 299–300. [Google Scholar]
- Chierichetti, F.; Kumar, R.; Lattanzi, S.; Vassilvitskii, S. Fair Clustering Through Fairlets. arXiv 2018, arXiv:1802.05733. [Google Scholar]
- Hu, L.; Chen, Y. A Short-term Intervention for Long-term Fairness in the Labor Market. In Proceedings of the 2018 World Wide Web Conference, International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, CHE, Lyon, France, 23–27 April 2018; pp. 1389–1398. [Google Scholar]
- Elbassuoni, S.; Amer-Yahia, S.; Ghizzawi, A. Fairness of Scoring in Online Job Marketplaces. ACM/IMS Trans. Data Sci. 2020, 1, 1–30. [Google Scholar] [CrossRef]
- Olsson, T.; Huhtamäki, J.; Kärkkäinen, H. Directions for professional social matching systems. Commun. ACM 2020, 63, 60–69. [Google Scholar] [CrossRef] [Green Version]
- Machado, L.; Stefanidis, K. Fair Team Recommendations for Multidisciplinary Projects. In Proceedings of the 2019 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Thessaloniki, Greece, 14–17 October 2019; pp. 293–297. [Google Scholar]
- Stoyanovich, J.; Howe, B.; Abiteboul, S.; Miklau, G.; Sahuguet, A.; Weikum, G. Fides: Towards a Platform for Responsible Data Science. In Proceedings of the 29th International Conference on Scientific and Statistical Database Management, Chicago, IL, USA, 27–29 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Bucea-Manea-Tonis, R.; Kuleto, V.; Gudei, S.C.D.; Lianu, C.; Lianu, C.; Ilic, M.P.; Paun, D. Artificial Intelligence Potential in Higher Education Institutions Enhanced Learning Environment in Romania and Serbia. Sustain. Sci. Pract. Policy 2022, 14, 5842. [Google Scholar] [CrossRef]
- Lopez, C.; Tucker, C. Toward Personalized Adaptive Gamification: A Machine Learning Model for Predicting Performance. IEEE Trans. Comput. Intell. AI Games 2020, 12, 155–168. [Google Scholar] [CrossRef] [Green Version]
- Knutas, A.; van Roy, R.; Hynninen, T.; Granato, M.; Kasurinen, J.; Ikonen, J. A process for designing algorithm-based personalized gamification. Multimed. Tools Appl. 2019, 78, 13593–13612. [Google Scholar] [CrossRef] [Green Version]
- Sousa-Vieira, M.E.; Lopez-Ardao, J.C.; Fernandez-Veiga, M.; Rodriguez-Rubio, R.F. Study of the impact of social learning and gamification methodologies on learning results in higher education. Comput. Appl. Eng. Educ. 2022, 31, 131–153. [Google Scholar] [CrossRef]
- Jimenez-Hernandez, E.M.; Oktaba, H.; Diaz-Barriga, F.; Piattini, M. Using web-based gamified software to learn Boolean algebra simplification in a blended learning setting. Comput. Appl. Eng. Educ. 2020, 28, 1591–1611. [Google Scholar] [CrossRef]
- Daghestani, L.F.; Ibrahim, L.F.; Al-Towirgi, R.S.; Salman, H.A. Adapting gamified learning systems using educational data mining techniques. Comput. Appl. Eng. Educ. 2020, 28, 568–589. [Google Scholar] [CrossRef]
- Bennani, S.; Maalel, A.; Ben Ghezala, H. Adaptive gamification in E-learning: A literature review and future challenges. Comput. Appl. Eng. Educ. 2022, 30, 628–642. [Google Scholar] [CrossRef]
- Chen, Q.; Srivastava, G.; Parizi, R.M.; Aloqaily, M.; Al Ridhawi, I. An incentive-aware blockchain-based solution for internet of fake media things. Inf. Process. Manag. 2020, 57, 102370. [Google Scholar] [CrossRef]
- Duggal, K.; Gupta, L.R.; Singh, P. Gamification and Machine Learning Inspired Approach for Classroom Engagement and Learning. Math. Probl. Eng. 2021, 2021, 9922775. [Google Scholar] [CrossRef]
- Gastil, J. To Play Is the Thing: How Game Design Principles Can Make Online Deliberation Compelling. Am. Behav. Sci. 2022. [Google Scholar] [CrossRef]
- Sevastjanova, R.; Jentner, W.; Sperrle, F.; Kehlbeck, R.; Bernard, J.; El-assady, M. QuestionComb: A Gamification Approach for the Visual Explanation of Linguistic Phenomena through Interactive Labeling. ACM Trans. Interact. Intell. Syst. 2021, 11, 19. [Google Scholar] [CrossRef]
- Minato, S.I. Binary Decision Diagrams and Applications for VLSI CAD; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Schöbel, S.M.; Janson, A.; Söllner, M. Capturing the complexity of gamification elements: A holistic approach for analysing existing and deriving novel gamification designs. Eur. J. Inf. Syst. 2020, 29, 641–668. [Google Scholar] [CrossRef]
- Liu, D.; Santhanam, R.; Webster, J. Toward meaningful engagement: A framework for design and research of gamified information systems. MIS Q. 2017, 41, 1011–1034. [Google Scholar] [CrossRef] [Green Version]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Cangussu, J.W.; DeCarlo, R.A.; Mathur, A.P. A formal model of the software test process. IEEE Trans. Softw. Eng. 2002, 28, 782–796. [Google Scholar] [CrossRef] [Green Version]
- Mathur, A. Foundations of Software Testing, 2nd ed.; Pearson: Delhi, India, 2013. [Google Scholar]
- Chalkidis, I.; Kampas, D. Deep learning in law: Early adaptation and legal word embeddings trained on large corpora. Artif. Intell. Law 2019, 27, 171–198. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning, 4th ed.; MIT Press: Cambridge, MA, USA, 2020; Available online: https://www.google.com/books?hl=tr&lr=&id=tZnSDwAAQBAJ&oi=fnd&pg=PR7&dq=ethem+alpayd%C4%B1n&ots=F3YR7UdwBg&sig=yjp6CpKWhkc2puDmpK4tsoD-X5I (accessed on 28 December 2022).
- Wong, W.E.; Mathur, A.P. Reducing the cost of mutation testing: An empirical study. J. Syst. Softw. 1995, 31, 185–196. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Game Element | Criteria Used | Description | Scoring |
|---|---|---|---|
| Rule and Comment | Zero-Suppressed Decision Diagram Score | Allows parsing and scoring relational rules and comments. High processing power is required | Rule and Comment Score = ZDD score + Centrality score |
| Centrality Score | Allows rules and comments to be scored without parsing them | ||
| Test | Confusion Matrix Score | Generates a test performance score using Accuracy, Precision, Recall, and F1 Score | Test Score = Confusion Matrix Score + Mutation Test Score |
| Mutation Test Score | Generates a test performance score using the Fault Detection Ratio (FDR), Average Percentage of Faults Detected (APFD) FDR/Test Suite Size, FDR/Test Case Time, and FDR/Test Suite Time |
| Predicted | ||
|---|---|---|
| Actual | 3 | 1 |
| 2 | 4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takan, S.; Ergün, D.; Katipoğlu, G. Gamified Text Testing for Sustainable Fairness. Sustainability 2023, 15, 2292. https://doi.org/10.3390/su15032292
Takan S, Ergün D, Katipoğlu G. Gamified Text Testing for Sustainable Fairness. Sustainability. 2023; 15(3):2292. https://doi.org/10.3390/su15032292
Chicago/Turabian StyleTakan, Savaş, Duygu Ergün, and Gökmen Katipoğlu. 2023. "Gamified Text Testing for Sustainable Fairness" Sustainability 15, no. 3: 2292. https://doi.org/10.3390/su15032292