

Community Governance Based on Sentiment Analysis: Towards Sustainable Management and Development


 , and
, and
Abstract
:1. Introduction
- Community speech text data contain rich sentiment information, and its corresponding corpus of text sentiment data is small or not even publicly available. The text emotional classification algorithm in the general field cannot learn the characteristics.
- Community speech texts rely on the audio-to-text conversion between residents and property in the community data center, including positive and negative sentiments about service quality, service efficiency, and community environmental governance. However, these texts have problems such as conversion errors, frequent communication dialogues with staff members prone to long community texts, the traditional long text extraction method being single, and problems such as data loss and gradient explosion. These problems make it difficult to extract sentiment features from long community dialogue texts, which affects the accuracy of the sentiment classification of community speech texts.
- In the training process of the traditional text sentiment classification model, the difficulty of classifying positive and negative sentiment samples of unbalanced community speech texts and the adjustment of training weight coefficients have yet to be considered, which will lead to low accuracy for classification models.
- To address the problem of the small size of community speech text sentiment corpus, we construct a sentiment knowledge enhancement pre-trained language model which extracts the joint features of sentiment information and semantics. Based on the sentiment knowledge enhancement model and community corpus, data migration and fine-tuning of the community speech text is realized, which constructs community speech text. This method can enhance the community speech text corpus’s sentiment feature representation capability.
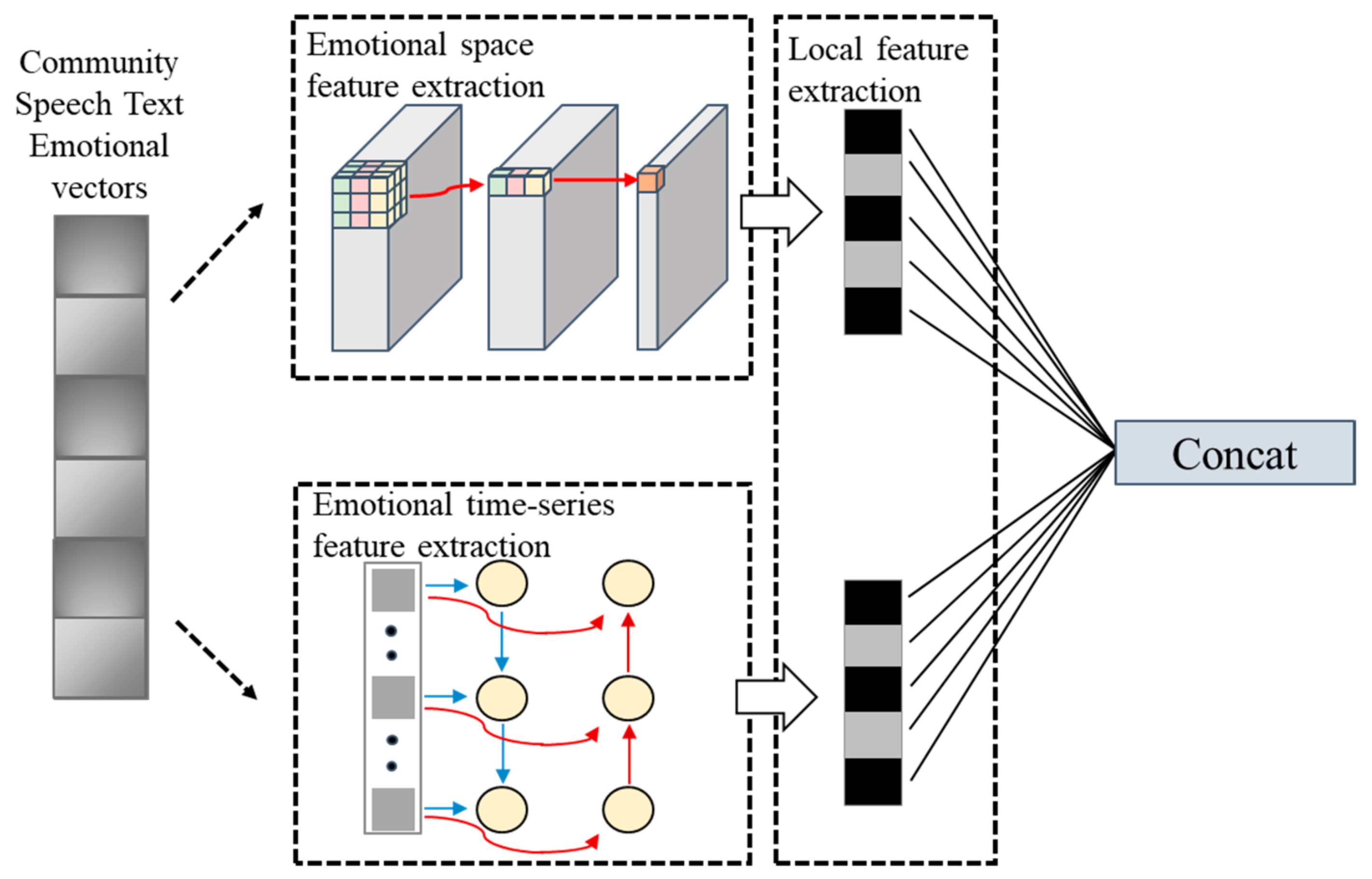
- To address the problem that single feature extraction method only one-sidedly considers the sentiment text information under the temporal order, we propose a dual-channel feature extraction method that integrates space and time series. Three types of features are obtained: spatial sentiment features, temporal order sentiment features, and local features. The spatial-based feature extraction method obtains the global sentiment features of community speech texts. The time-series-based feature extraction method obtains the historical and future features in the context. Consequently, emotional features in community speech texts can be fully extracted.
- It is challenging to train a classification model under the unbalanced number of positive and negative sentiment texts. We present an improved cross-entropy loss function for community speech text to adjust the weights of the hard-to-distinguish emotional texts in the model and update the parameters. The proposed method can reduce the impact of unbalanced texts and improve the accuracy of text emotional classification.
2. Related Works
3. Algorithm Principle
3.1. Community Speech Text Acquisition
3.2. Construction of Classification Model Based on Sentiment Text Knowledge Enhancement
3.2.1. Text Vectorization Combined with Location Information
3.2.2. Community Corpus Construction Based on SKEP
3.2.3. Dual-Channel Sentiment Text Feature Extraction
3.2.4. Classification Model Training Based on Improved Cross-Entropy Loss Function
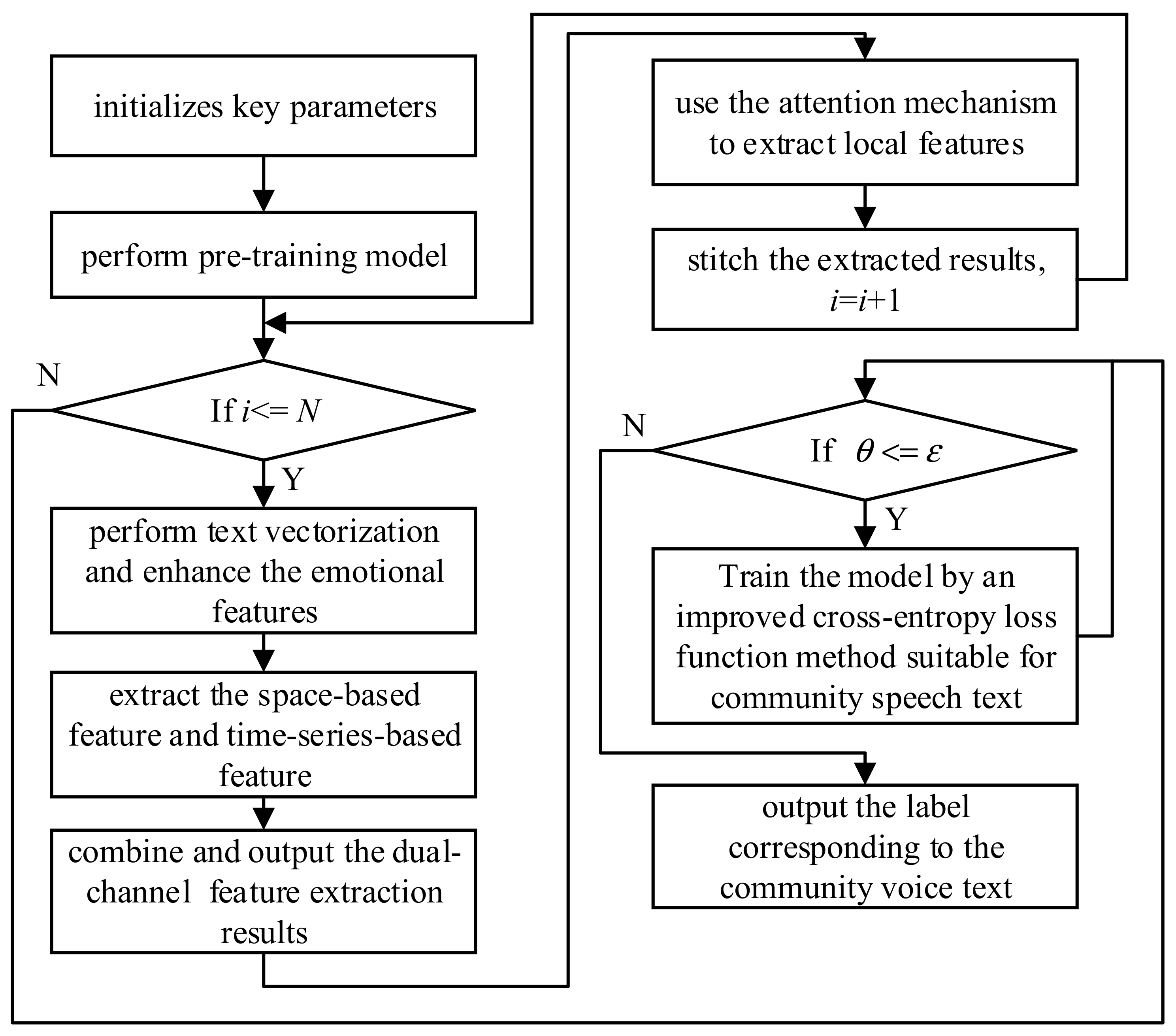
4. Algorithm Implementation
| Algorithm 1: Community Speech Text Sentiment Classification Algorithm Combining Dual-Channel Features and Attention Mechanism | |
| Input: | community speech text data |
| Output: | labels corresponding to all community speech texts data |
| 1: maxlength = 256; batchsize = 8; kernel = [3,4,5]; learningrate = 5 × 10−5; dim = 1024; | |
| 2: while 1 | |
| 3: Perform pre-training model and vectorize text on the obtained community speech text; | |
| 4: for i = 1, 2, …, do | |
| 5: Perform pre-training model on the obtained community speech text; | |
| 6: for i = 1, 2, …, do | |
| 7: if (i ≤ ) then | |
| 8: Perform text vectorization on each piece of community speech and text, and enhance the emotional features of community speech and text; | |
| 9: end if | |
| 10: end for | |
| 11: for i = 1, 2, …, do | |
| 12: if (i ≤ ) then | |
| 13: Extract sentiment of community speech texts through space-based feature extraction methods; | |
| 14: Extract sentiment from community speech and text through time-series-based feature extraction method; | |
| 15: Output the feature vectors by the dual-channels are combined with the attention mechanism to extract local features; | |
| 16: Stitch the extracted results together; | |
| 17: end if | |
| 18: end for | |
| 19: Train the model through an improved cross-entropy loss function method suitable for community speech text; | |
| 20: for i = 1, 2,…, do | |
| 21: if (i ≤ ) then | |
| 22: ; | |
| 23: if ( ) then | |
| 24: Output the label corresponding to the community speech text; | |
| 25: end if | |
| 26: end if | |
| 27: end for | |
| 28: end | |
5. Algorithm Analysis
5.1. Experimental Data and Parameters
5.2. Results and Discussion
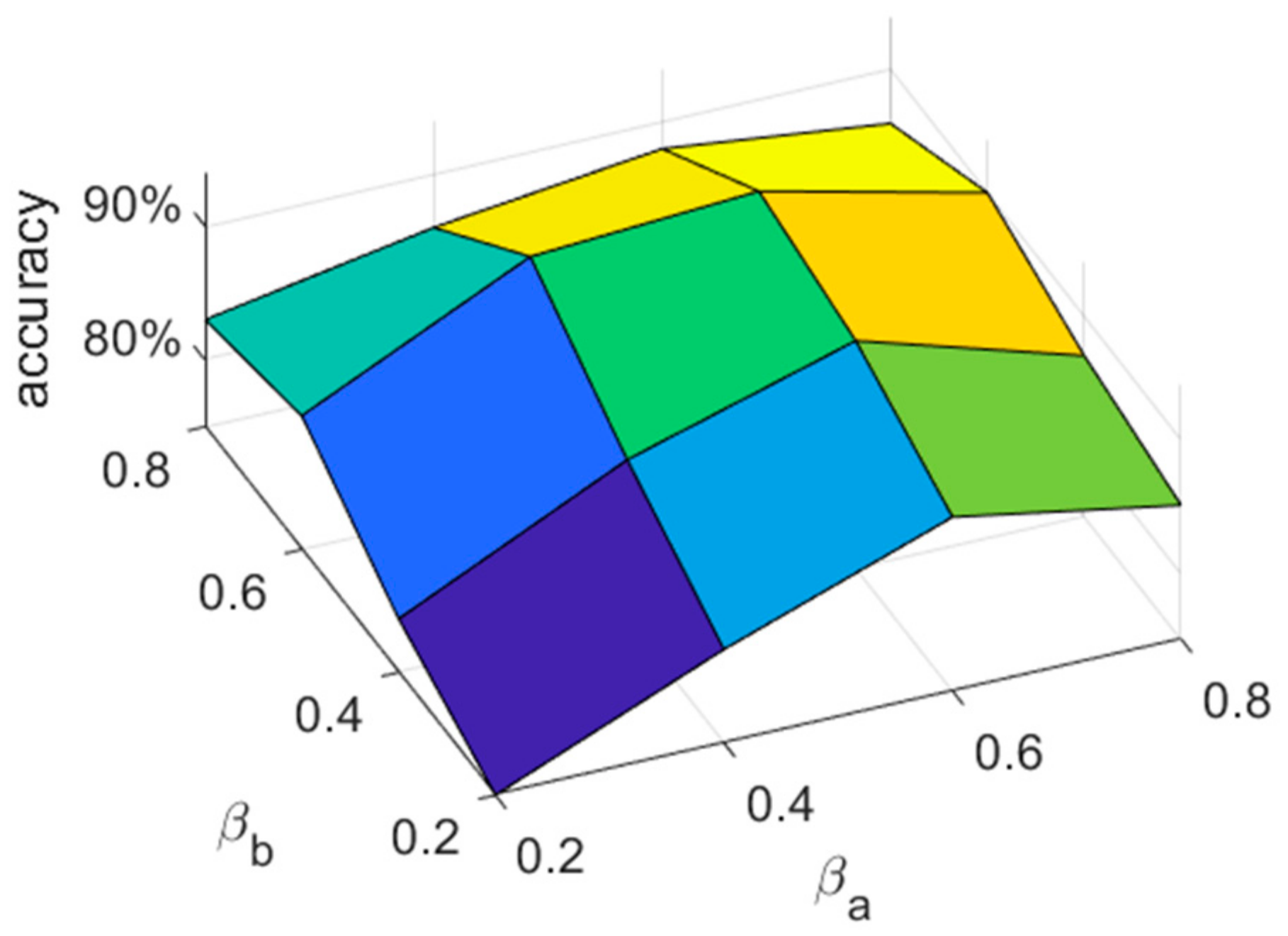
5.2.1. Parameter Selection Analysis
5.2.2. Algorithm Experiment
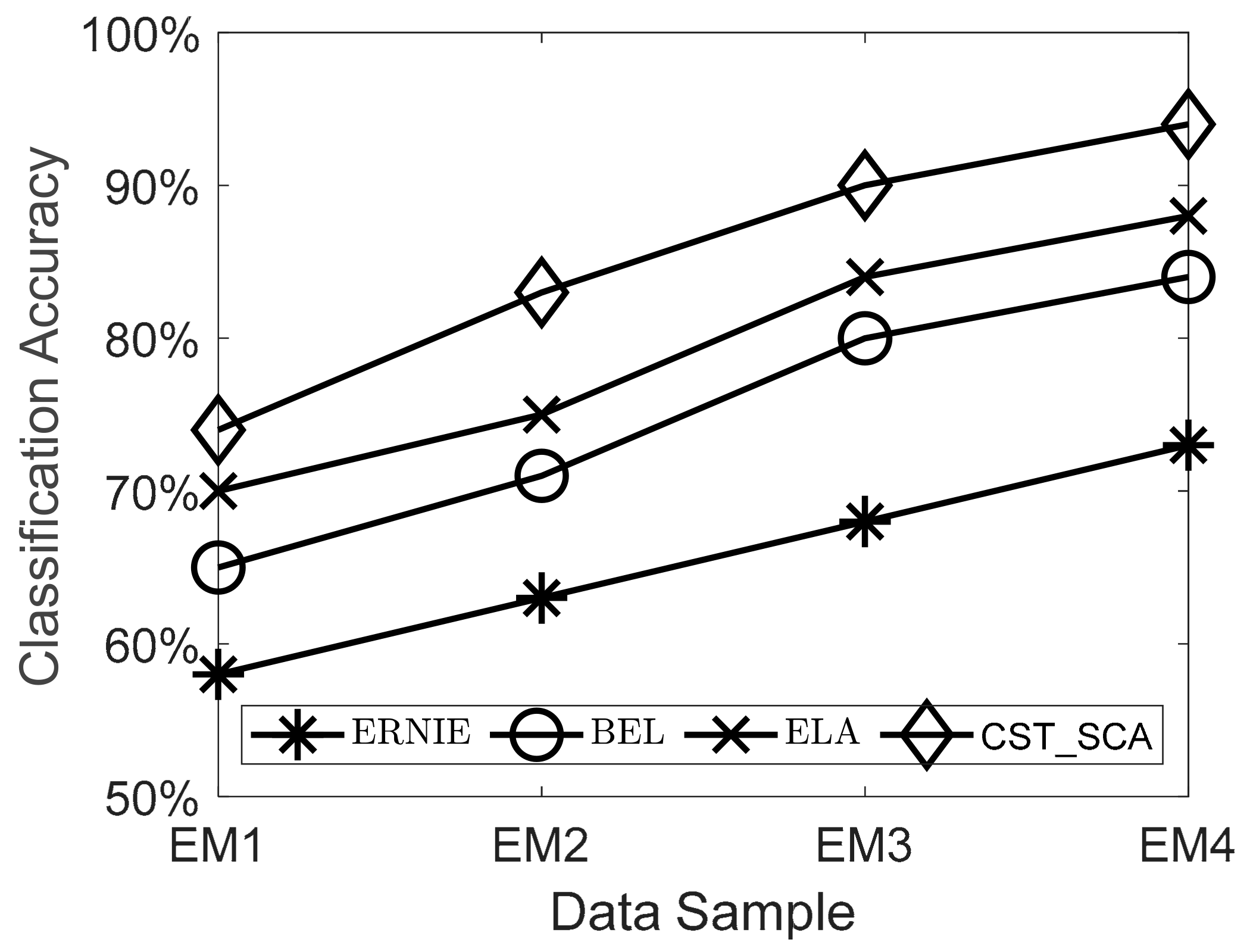
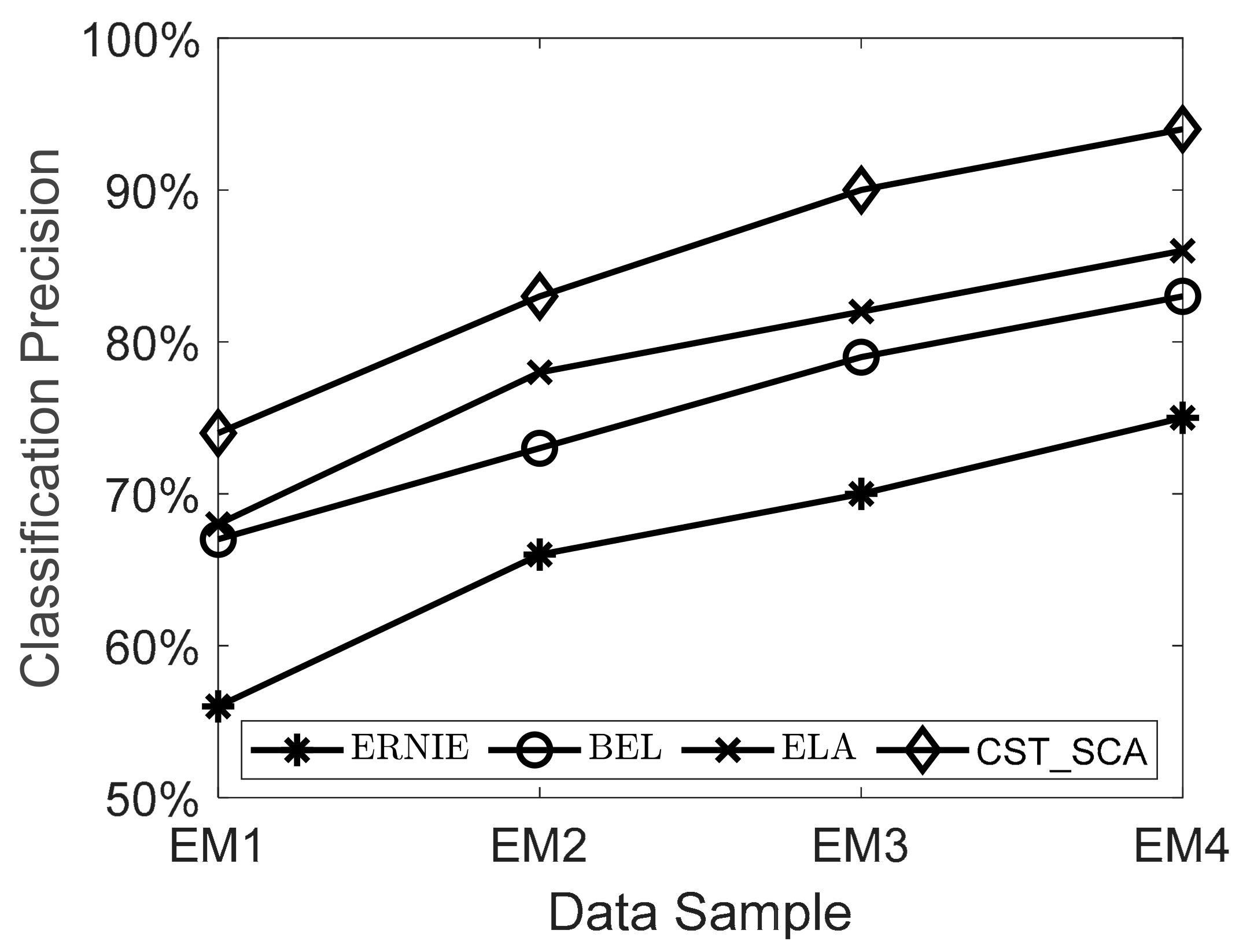
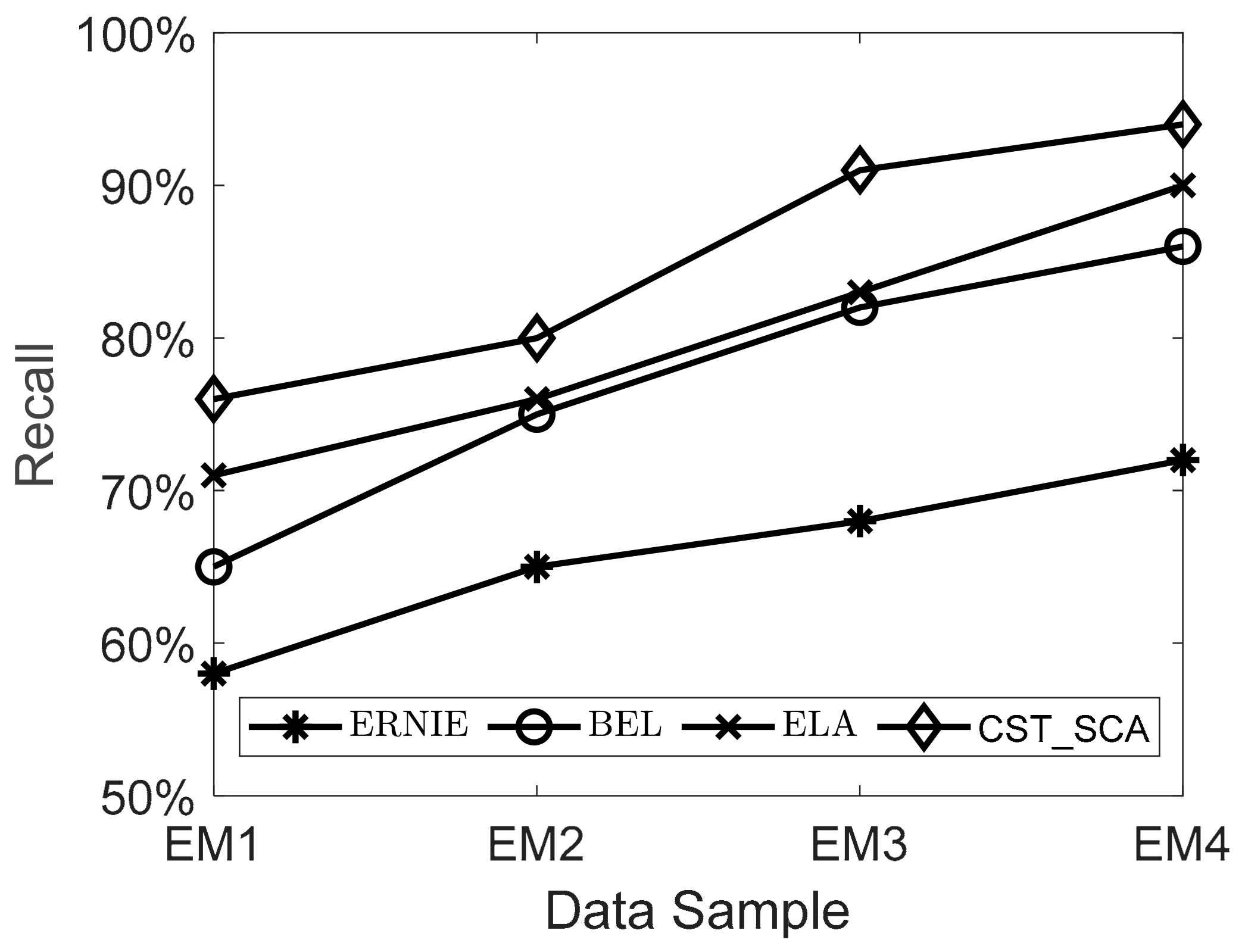
5.2.3. Algorithm Performance Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, S.; Cao, W.; Xu, W.; Bian, J. Revisiting the evaluation of end-to-end event extraction. In Findings of the Association for Computational Linguistics, Proceedings of the ACL-IJCNLP 2021, Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4609–4617. [Google Scholar]
- Saura, J.R.; Palos-Sanchez, P.; Grilo, A. Detecting indicators for startup business success: Sentiment analysis using text data mining. Sustainability 2019, 11, 917. [Google Scholar] [CrossRef]
- Reyes-Menendez, A.; Saura, J.R.; Filipe, F. Marketing challenges in the #MeToo era: Gaining business insights using an exploratory sentiment analysis. Heliyon 2020, 6, 03626–03637. [Google Scholar]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Van Atteveldt, W.; Van der Velden MA, C.G.; Boukes, M. The validity of sentiment analysis: Comparing manual annotation, crowd-coding, dictionary approaches, and machine learning algorithms. Commun. Methods Meas. 2021, 15, 121–140. [Google Scholar] [CrossRef]
- Nassif, A.B.; Elnagar, A.; Shahin, I.; Henno, S. Deep learning for Arabic subjective sentiment analysis: Challenges and research opportunities. Appl. Soft Comput. 2021, 98, 106836–106862. [Google Scholar] [CrossRef]
- Li, R.; Lin, Z.; Lin, H.; Wang, W.; Meng, D. Text Emotion Analysis: A Survey. J. Comput. Res. Dev. 2018, 55, 30–52. [Google Scholar]
- Estrada ML, B.; Cabada, R.Z.; Bustillos, R.O.; Graff, M. Opinion mining and emotion recognition applied to learning environments. Expert Syst. Appl. 2020, 150, 113265. [Google Scholar] [CrossRef]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Awan, I. Detection and classification of social media-based extremist affiliations using sentiment analysis techniques. Hum.-Cent. Comput. Inf. Sci. 2019, 9, 1–23. [Google Scholar]
- Vashishtha, S.; Susan, S. Fuzzy rule based unsupervised sentiment analysis from social media posts. Expert Syst. Appl. 2019, 138, 112834. [Google Scholar] [CrossRef]
- Consoli, S.; Barbaglia, L.; Manzan, S. Fine-grained, aspect-based sentiment analysis on economic and financial lexicon. Knowl.-Based Syst. 2022, 1, 108781–108795. [Google Scholar] [CrossRef]
- Xu, G.X.; Yu, Z.; Yao, H.; Li, F.; Meng, Y.; Wu, X. Chinese text sentiment analysis based on extended sentiment dictionary. IEEE Access 2019, 1, 43749–43762. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, Z.; Yao, X.; Yang, Q. A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach. Inf. Process. Manag. 2021, 58, 102656–102670. [Google Scholar] [CrossRef]
- Nayel, H.; Amer, E.; Allam, A.; Mohammed, H. Machine learning-based model for sentiment and sarcasm detection. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 9 April 2021; pp. 386–389. [Google Scholar]
- Xu, D.; Tian, Z.; Lai, R.; Kong, X.; Tan, Z.; Shi, W. Deep learning based emotion analysis of microblog texts. Inf. Fusion 2020, 64, 1–11. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Huang, F.; Li, X.; Yuan, C.; Zhang, S.; Zhang, J.; Qiao, S. Attention-Emotion-Enhanced Convolutional LSTM for Sentiment Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4332–4345. [Google Scholar] [CrossRef] [PubMed]
- Kumar, P.; Raman, B. A BERT based dual-channel explainable text emotion recognition system. Neural Netw. 2022, 2, 392–407. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8968–8975. [Google Scholar]
- Tian, H.; Gao, C.; Xiao, X.; Liu, H.; He, B.; Wu, H.; Wang, H.; Wu, F. SKEP: Sentiment knowledge enhanced pre-training for sentiment analysis. In Proceedings of the Association for Computational Linguistics 2020 (ACL2020), Virtual, 4 July 2020; pp. 1–10. [Google Scholar]
- Brauwers, G.; Frasincar, F. A survey on aspect-based sentiment classification. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, F.; Liu, S.; Wu, Y.; Wang, L. A hybrid VMD–BiGRU model for rubber futures time series forecasting. Appl. Soft Comput. 2019, 84, 105739. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Sentiment Methods | Learning Paradigm | Sentiment Task |
|---|---|---|---|
| [10] | rule-based and dictionary-based methods | a novel fuzzy rule involving multiple dictionaries and datasets | social media posts |
| [11] | sentiment dictionary based and semantic polarity rules | economic and financial lexicon | |
| [12] | extended sentiment dictionary | Chinese dictionary | |
| [13] | statistical-based machine learning methods | optimized machine learning algorithm | online reviews |
| [14] | supervised machine learning algorithm based on support vector machine | internet public opinion status | |
| [15] | deep learning-based text sentiment classification methods | CNN_Text_Word2vec | microblog |
| [16] | attention-based bidirectional deep model | twitter dataset | |
| [17] | attention–emotion-enhanced convolutional LSTM | social networking (online) | |
| [18] | transfer learning-based methods | BERT_CNN_BiLSTM | analyze the inter- and intra-cluster distances and the intersection of these clusters |
| [19] | ERNIE 2.0 | GLUE benchmarks and several similar tasks in Chinese | |
| [20] | SKEP | sentence-level aspect-level opinion role |
| Parameter | Value |
|---|---|
| max length | 256 |
| dim | 1024 |
| batch size | 8 |
| dropout | 0.1 |
| learning rate | 5 × 10−5 |
| convolution kernel size | [2,3,4] |
| Epoch | 0 | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|---|
| A | 0.44 | 0.59 | 0.65 | 0.7 | 0.73 | 0.75 |
| P | 0.42 | 0.55 | 0.65 | 0.71 | 0.77 | 0.77 |
| Epoch | 0 | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|---|
| A | 0.48 | 0.64 | 0.73 | 0.78 | 0.81 | 0.82 |
| P | 0.51 | 0.67 | 0.74 | 0.79 | 0.82 | 0.84 |
| Epoch | 0 | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|---|
| A | 0.56 | 0.69 | 0.8 | 0.84 | 0.86 | 0.87 |
| P | 0.63 | 0.75 | 0.83 | 0.85 | 0.88 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yan, Z.; Wu, Q.; Wang, K.; Miao, K.; Wang, Z.; Chen, Y. Community Governance Based on Sentiment Analysis: Towards Sustainable Management and Development. Sustainability 2023, 15, 2684. https://doi.org/10.3390/su15032684
Zhang X, Yan Z, Wu Q, Wang K, Miao K, Wang Z, Chen Y. Community Governance Based on Sentiment Analysis: Towards Sustainable Management and Development. Sustainability. 2023; 15(3):2684. https://doi.org/10.3390/su15032684
Chicago/Turabian StyleZhang, Xudong, Zejun Yan, Qianfeng Wu, Ke Wang, Kelei Miao, Zhangquan Wang, and Yourong Chen. 2023. "Community Governance Based on Sentiment Analysis: Towards Sustainable Management and Development" Sustainability 15, no. 3: 2684. https://doi.org/10.3390/su15032684
APA StyleZhang, X., Yan, Z., Wu, Q., Wang, K., Miao, K., Wang, Z., & Chen, Y. (2023). Community Governance Based on Sentiment Analysis: Towards Sustainable Management and Development. Sustainability, 15(3), 2684. https://doi.org/10.3390/su15032684