
Prediction of Carbon Emission of the Transportation Sector in Jiangsu Province-Regression Prediction Model Based on GA-SVM
Abstract
:1. Introduction
2. Materials and Methods
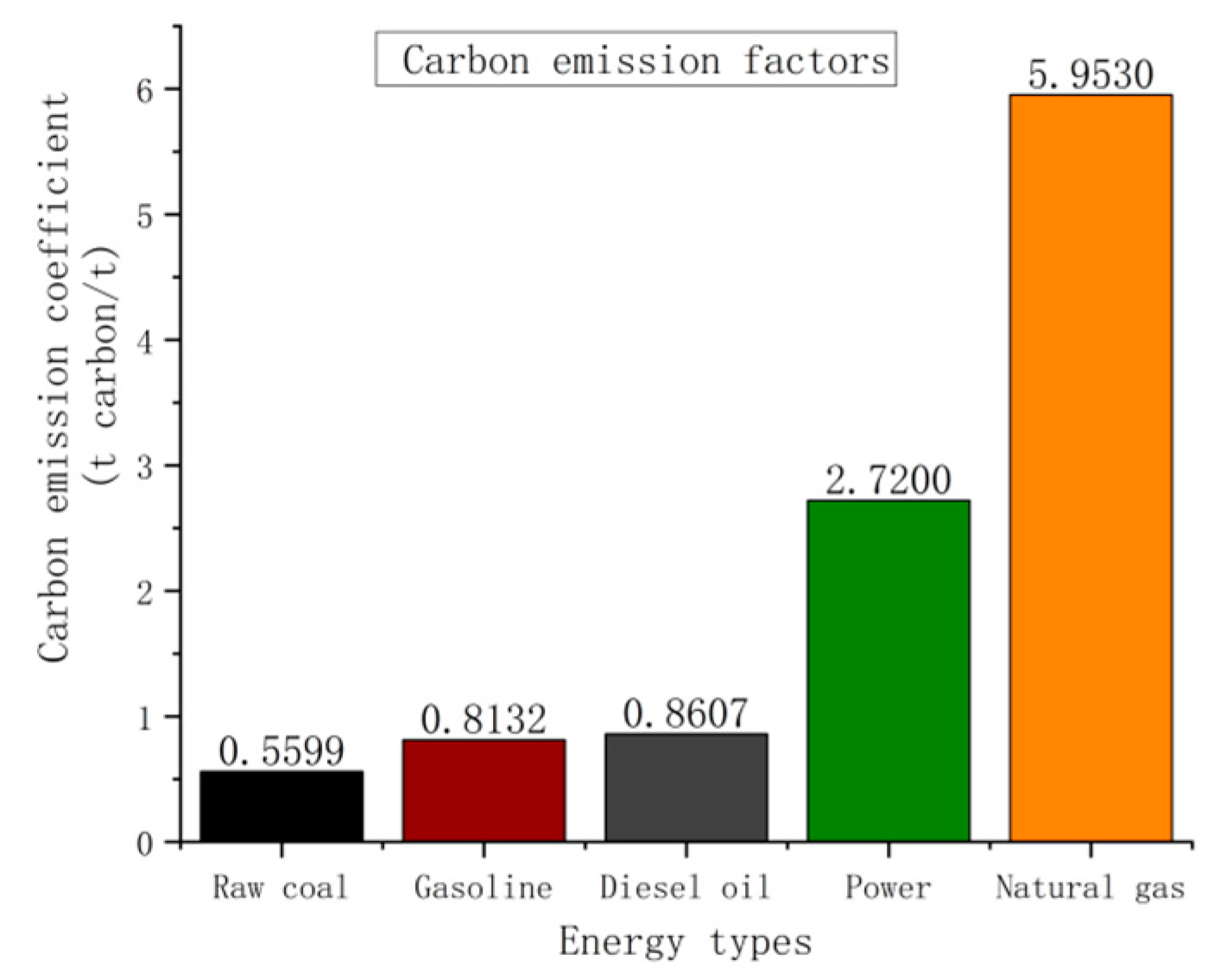
2.1. Establishment of Transportation Carbon Emission Measurement Model
2.2. Support Vector Machine Regression Prediction Model
2.3. Genetic Algorithm Improved Prediction Model
2.3.1. Selection
2.3.2. Crossover
2.3.3. Mutation
2.4. Combining Models
3. Case Study
3.1. Data Selection of Transportation Carbon Emission Examples
3.2. Data Covariance Diagnosis and Dimensionality Reduction
3.3. GA-SVM Simulation Prediction
3.4. Comparison of Three Simulation Predictions
3.5. Three Scenarios Predict Carbon Peak Times
- (1)
- Encourage the use of shared bicycles, buses, and other public transportation, and improve the organization of the road system and urban traffic management. Public transportation can reduce traffic congestion and create a controlled, organized traffic flow. The problem of using public transit for the final mile to get home can be resolved by introducing new shared bicycles. Traffic can be organized more rationally, local blockages can be avoided, commute times can be cut down through improved road system structure and traffic control levels.
- (2)
- Improve the energy system. In energy, Jiangsu has been dominated by gasoline and diesel, which is in demand for transportation energy; these are the primary sources of carbon emissions. We can also observe the gradual expansion of alternative energy sources such as electricity and natural gas. Future generations still need to support new energy sources more vigorously while reducing their reliance on fossil fuels.
- (3)
- Innovation in science and technology endeavors to overcome new energy technology constraints and to access cleaner and effective new energy sources. Improve the technologies used to process carbon emissions and the entire carbon emission control process.
- (4)
- Carry out various afforestation activities to improve vegetation coverage.
- (5)
- Actively carry out carbon collection projects to turn carbon dioxide into resources.
4. Conclusions
- (1)
- The novelty of this study is manifested in the selection of methods and data processing. First, in the selection of methods, since the sample size of carbon emissions is generally small, the support vector machine model performs well in small sample prediction and is suitable for predicting such samples. Secondly, in terms of data processing, PLS is selected for covariance diagnosis to avoid the instability of the interpretation model caused by discarding the original variables.
- (2)
- From the perspective of prediction accuracy, the GA-SVM prediction model has a lower MAPE (%) value than the other two comparative prediction models and a higher that is closer to 1 than the other two models. It is not easy to fall into the optimal local solution. Compared with other reference methods, it can be seen that the MAPE value of the GA-SVM prediction model is less than 0.03%, which is more accurate than the prediction model in other references.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matthews, H.D.; Caldeira, K. Transient climate–carbon simulations of planetary geoengineering. Proc. Natl. Acad. Sci. USA 2007, 104, 9949–9954. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trenberth, K.E. The definition of el nino. Bull. Am. Meteorol. Soc. 1997, 78, 2771–2778. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, R.; Liu, M.; Bi, J. The carbon emissions of Chinese cities. Atmos. Chem. Phys. 2012, 12, 6197–6206. [Google Scholar] [CrossRef] [Green Version]
- Pao, H.T.; Tsai, C.M. Modeling and forecasting the CO2 emissions, energy consumption, and economic growth in Brazil. Energy 2011, 36, 2450–2458. [Google Scholar] [CrossRef]
- Huang, S.; Xiao, X.; Guo, H. A novel method for carbon emission forecasting based on EKC hypothesis and nonlinear multivariate grey model: Evidence from transportation sector. Environ. Sci. Pollut. Res. 2022, 29, 60687–60711. [Google Scholar] [CrossRef]
- Sun, W.; Wang, C.; Zhang, C. Factor analysis and forecasting of CO2 emissions in Hebei, using extreme learning machine based on particle swarm optimization. J. Clean. Prod. 2017, 162, 1095–1101. [Google Scholar] [CrossRef]
- Hong, T.; Jeong, K.; Koo, C. An optimized gene expression programming model for forecasting the national CO2 emissions in 2030 using the metaheuristic algorithms. Appl. Energy 2018, 228, 808–820. [Google Scholar] [CrossRef]
- Wen, L.; Yuan, X. Forecasting CO2 emissions in China’s commercial department, through BP neural network based on random forest and PSO. Sci. Total Environ. 2020, 718, 137194. [Google Scholar] [CrossRef]
- Fang, D.; Zhang, X.; Yu, Q.; Jin, T.C.; Tian, L. A novel method for carbon dioxide emission forecasting based on improved Gaussian processes regression. J. Clean. Prod. 2018, 173, 143–150. [Google Scholar] [CrossRef]
- Qiao, W.; Lu, H.; Zhou, G.; Azimi, M.; Yang, Q.; Tian, W. A hybrid algorithm for carbon dioxide emissions forecasting based on improved lion swarm optimizer. J. Clean. Prod. 2020, 244, 118612. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Holden, C. Ehrlich versus Commoner: An environmental fallout. Science 1972, 177, 245–247. [Google Scholar] [CrossRef] [PubMed]
- Kaya, Y. Impact of Carbon Dioxide Emission Control on GNP Growth: Interpretation of Proposed Scenarios; Intergovernmental Panel on Climate Change/Response Strategies Working Group: Paris, France, 1989. [Google Scholar]
- Stern, P.C.; Dietz, T. The value basis of environmental concern. J. Soc. Issues 1994, 50, 65–84. [Google Scholar] [CrossRef]
- Ang, B.W. The LMDI approach to decomposition analysis: A practical guide. Energy Policy 2005, 33, 867–871. [Google Scholar] [CrossRef]
- Zhang, C.; Nian, J. Panel estimation for transport sector CO2 emissions and its affecting factors: A regional analysis in China. Energy Policy 2013, 63, 918–926. [Google Scholar] [CrossRef]
- Wang, T.; Li, H.; Zhang, J.; Lu, Y. Influencing factors of carbon emission in China’s road freight transport. Procedia-Soc. Behav. Sci. 2012, 43, 54–64. [Google Scholar] [CrossRef] [Green Version]
- Yan, J.; Su, B.; Liu, Y. Multiplicative structural decomposition and attribution analysis of carbon emission intensity in China, 2002–2012. J. Clean. Prod. 2018, 198, 195–207. [Google Scholar] [CrossRef]
- Kim, K.D.; Ko, H.K.; Lee, T.J.; Kim, D.S. Comparison of greenhouse gas emissions from road transportation of local government by calculation methods. J. Korean Soc. Atmos. Environ. 2011, 27, 405–415. [Google Scholar] [CrossRef] [Green Version]
- Eggleston, H.S.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K. IPCC Guidelines for National Greenhouse Gas Inventories: Volume 2-Energy; IGES: Hayama, Japan, 2006. [Google Scholar]
- Blum, A. Machine Learning Theory; Carnegie Melon Universit, School of Computer Science: Pittsburgh, PA, USA, 2007; Volume 26. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Li, H. Lagrange Multipliers and Their Applications; Department of Electrical Engineering and Computer Science, University of Tennessee: Knoxville, TN, USA, 2008. [Google Scholar]
- Micchelli, C.A.; Pontil, M.; Bartlett, P. Learning the Kernel Function via Regularization. J. Mach. Learn. Res. 2005, 6, 1099–1125. [Google Scholar]
- Amari, S.I.; Wu, S. Improving support vector machine classifiers by modifying kernel functions. Neural Netw. 1999, 12, 783–789. [Google Scholar] [CrossRef] [PubMed]
- Mayer, D.G.; Belward, J.A.; Widell, H.; Burrage, K. Survival of the fittest—Genetic algorithms versus evolution strategies in the optimization of systems models. Agric. Syst. 1999, 60, 113–122. [Google Scholar] [CrossRef]
- Yao, J.B.; Yao, B.Z.; Li, L.; Jiang, Y.L. Hybrid model for displacement prediction of tunnel surrounding rock. Neural Netw. World 2012, 22, 263. [Google Scholar] [CrossRef] [Green Version]
- Michalewicz, Z. Genetic Algorithms, Numerical Optimization, and Constraints. In Proceedings of the Sixth International Conference on Genetic Algorithms, Pittsburgh, PA, USA, 15–19 July 1995; Morgan Kauffman: San Mateo, CA, USA, 1995; Volume 195. [Google Scholar]
- Li, X.Z.; Kong, J.M. Application of GA–SVM method with parameter optimization for landslide development prediction. Nat. Hazards Earth Syst. Sci. 2014, 14, 525–533. [Google Scholar] [CrossRef] [Green Version]
- Statistics, Energy. China Energy Statistics Yearbook (2002–2020); National Energy Department, Government of China: Beijing, China, 2020.
- Nasiruzzaman, A.B.M. Using MATLAB to develop standalone graphical user interface (GUI) software packages for educational purposes. In MATLAB-Modelling, Programming and Simulations; IntechOpen: London, UK, 2010; pp. 17–40. [Google Scholar]
- Qian, X.; Lee, S.; Soto, A.M.; Chen, G. Regression model to predict the higher heating value of poultry waste from proximate analysis. Resources 2018, 7, 39. [Google Scholar] [CrossRef] [Green Version]
- Sunaryono, D.; Siswantoro, J.; Anggoro, R. Android based course attendance system using face recognition. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 304–312. [Google Scholar] [CrossRef]
- Ardjani, F.; Sadouni, K.; Benyettou, M. Optimization of SVM Multiclass by Particle Swarm (PSO-SVM). In Proceedings of the 2010 2nd International Workshop on Database Technology and Applications, Wuhan, China, 27–28 November 2010. [Google Scholar]
- Ciotti, M.; Ciccozzi, M.; Terrinoni, A.; Jiang, W.C.; Wang, C.B.; Bernardini, S. The COVID-19 pandemic. Crit. Rev. Clin. Lab. Sci. 2020, 57, 365–388. [Google Scholar] [CrossRef]
- Qin, W.; Wei, Y.; Yang, X. Research on Grey Wave Forecasting Model. In Advances in Grey Systems Research; Springer: Berlin/Heidelberg, Germany, 2010; pp. 349–359. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Raw Coal | Gasoline | Diesel Oil | Power | Natural Gas | |
|---|---|---|---|---|---|
| 2002 | 7406.0 | 14,369.0 | 705.5 | 61.0 | 924.3 |
| 2003 | 7458.0 | 16,743.0 | 778.6 | 64.1 | 978.0 |
| 2004 | 7523.0 | 19,790.0 | 872.8 | 66.8 | 1109.2 |
| 2005 | 7588.0 | 23,984.0 | 969.7 | 69.1 | 1222.0 |
| 2006 | 7655.0 | 27,868.0 | 1032.4 | 71.4 | 1367.0 |
| 2007 | 7723.0 | 33,798.0 | 1221.4 | 73.7 | 1596.1 |
| 2008 | 7762.0 | 39,967.0 | 1349.7 | 74.9 | 1766.0 |
| 2009 | 7810.0 | 44,272.0 | 1370.1 | 76.3 | 1423.3 |
| 2010 | 7869.0 | 52,787.0 | 1381.9 | 78.2 | 1604.0 |
| 2011 | 8023.0 | 61,947.0 | 1535.2 | 79.1 | 1777.8 |
| 2012 | 8120.0 | 67,896.0 | 1604.2 | 79.9 | 1949.8 |
| 2013 | 8192.0 | 74,844.0 | 1725.3 | 80.6 | 1451.1 |
| 2014 | 8281.0 | 81,550.0 | 1782.1 | 81.5 | 1550.6 |
| 2015 | 8315.0 | 89,426.0 | 1699.5 | 82.5 | 1566.4 |
| 2016 | 8381.0 | 96,840.0 | 1733.7 | 83.2 | 1591.9 |
| 2017 | 8423.0 | 107,150.0 | 1884.2 | 84.2 | 1659.5 |
| 2018 | 8446.0 | 115,930.0 | 1987.2 | 84.9 | 1692.1 |
| 2019 | 8469.0 | 123,607.0 | 2111.4 | 85.6 | 1737.0 |
| 2020 | 8477.0 | 127,285.0 | 2230.5 | 86.2 | 1057.1 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| 2002 | 7406 | 14,369 | 705.50 | 61.0 | 924.3 | 1549.12 | 0.1059 | 44.70 | 1127.012 |
| 2003 | 7458 | 16,743 | 778.61 | 64.1 | 978.0 | 1817.44 | 0.1189 | 46.77 | 1484.242 |
| 2004 | 7523 | 19,790 | 872.82 | 66.8 | 1109.2 | 2398.64 | 0.1217 | 48.18 | 1812.580 |
| 2005 | 7588 | 23,984 | 969.66 | 69.1 | 1222.0 | 3068.88 | 0.1007 | 50.11 | 1833.537 |
| 2006 | 7655 | 27,868 | 1032.40 | 71.4 | 1367.0 | 3644.79 | 0.0956 | 51.90 | 2039.071 |
| 2007 | 7723 | 33,798 | 1221.35 | 73.7 | 1596.1 | 4099.16 | 0.0825 | 53.20 | 2153.981 |
| 2008 | 7762 | 39,967 | 1349.70 | 74.9 | 1766.0 | 4707.74 | 0.0791 | 54.30 | 2454.832 |
| 2009 | 7810 | 44,272 | 1370.07 | 76.3 | 1423.3 | 5154.46 | 0.0742 | 55.60 | 2566.292 |
| 2010 | 7869 | 52,787 | 1381.88 | 78.2 | 1604.0 | 6111.57 | 0.0688 | 60.60 | 2859.385 |
| 2011 | 8023 | 61,947 | 1535.17 | 79.1 | 1777.8 | 7513.99 | 0.0622 | 62.00 | 3092.492 |
| 2012 | 8120 | 67,896 | 1604.18 | 79.9 | 1949.8 | 8474.64 | 0.0609 | 63.00 | 3355.649 |
| 2013 | 8192 | 74,844 | 1725.34 | 80.6 | 1451.1 | 10,536.80 | 0.0584 | 64.40 | 3582.324 |
| 2014 | 8281 | 81,550 | 1782.09 | 81.5 | 1550.6 | 11,028.70 | 0.0571 | 65.70 | 3852.806 |
| 2015 | 8315 | 89,426 | 1699.46 | 82.5 | 1566.4 | 7374.00 | 0.0541 | 67.50 | 4019.513 |
| 2016 | 8381 | 96,840 | 1733.70 | 83.2 | 1591.9 | 8290.69 | 0.0515 | 68.90 | 4180.560 |
| 2017 | 8423 | 107,150 | 1884.23 | 84.2 | 1659.5 | 9726.51 | 0.0498 | 70.20 | 4493.663 |
| 2018 | 8446 | 115,930 | 1987.16 | 84.9 | 1692.1 | 9684.01 | 0.0487 | 71.20 | 4765.136 |
| 2019 | 8469 | 123,607 | 2111.42 | 85.6 | 1737.0 | 11,114.57 | 0.0487 | 72.50 | 5100.959 |
| 2020 | 8477 | 127,285 | 2230.46 | 86.2 | 1057.1 | 11,538.86 | 0.0484 | 73.44 | 5226.856 |
| Variable | VIF | 1/VIF |
|---|---|---|
| Population | 176.546 | 0.005664 |
| GDP per capita | 3233.207 | 0.000309 |
| Civil vehicle ownership | 360.834 | 0.002771 |
| Industry structure | 225.794 | 0.004429 |
| Passenger turnover | 4.104 | 0.243665 |
| Freight turnover | 54.136 | 0.018472 |
| Carbon emission intensity | 82.210 | 0.012164 |
| Urbanization rate | 640.636 | 0.001561 |
| Dependent Variable | One Principal Component | Two Principal Component | Three Principal Component | Four Principal Component |
|---|---|---|---|---|
| C9 | 0.974 | 0.985 | 0.998 | 0.999 |
| Comparison Parameters | GA-SVM | PSO-SVM | WOA-SVM |
|---|---|---|---|
| 0.9082 | 0.8450 | 0.1203 | |
| MAPE (%) | 0.0297 | 0.3208 | 0.6435 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, Z.; Zha, X.; Lu, M.; Ma, T.; Lu, Z. Prediction of Carbon Emission of the Transportation Sector in Jiangsu Province-Regression Prediction Model Based on GA-SVM. Sustainability 2023, 15, 3631. https://doi.org/10.3390/su15043631
Huo Z, Zha X, Lu M, Ma T, Lu Z. Prediction of Carbon Emission of the Transportation Sector in Jiangsu Province-Regression Prediction Model Based on GA-SVM. Sustainability. 2023; 15(4):3631. https://doi.org/10.3390/su15043631
Chicago/Turabian StyleHuo, Zhenggang, Xiaoting Zha, Mengyao Lu, Tianqi Ma, and Zhichao Lu. 2023. "Prediction of Carbon Emission of the Transportation Sector in Jiangsu Province-Regression Prediction Model Based on GA-SVM" Sustainability 15, no. 4: 3631. https://doi.org/10.3390/su15043631