3.1. Methodology and Data
This section first overviews the heterogeneity of Chinese provinces in terms of their water pollution levels and the factors influencing them (
Table 2, as for the location see
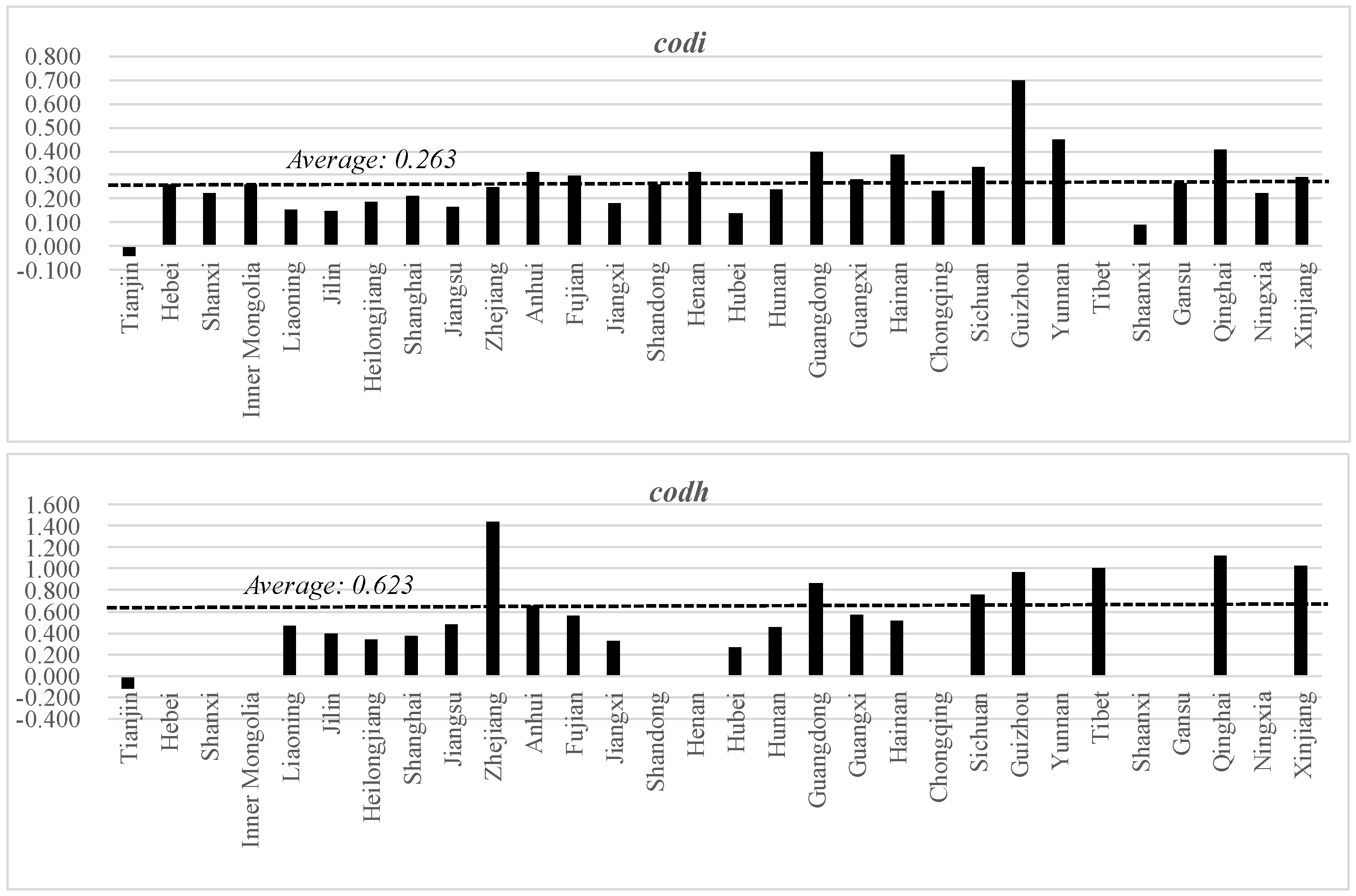
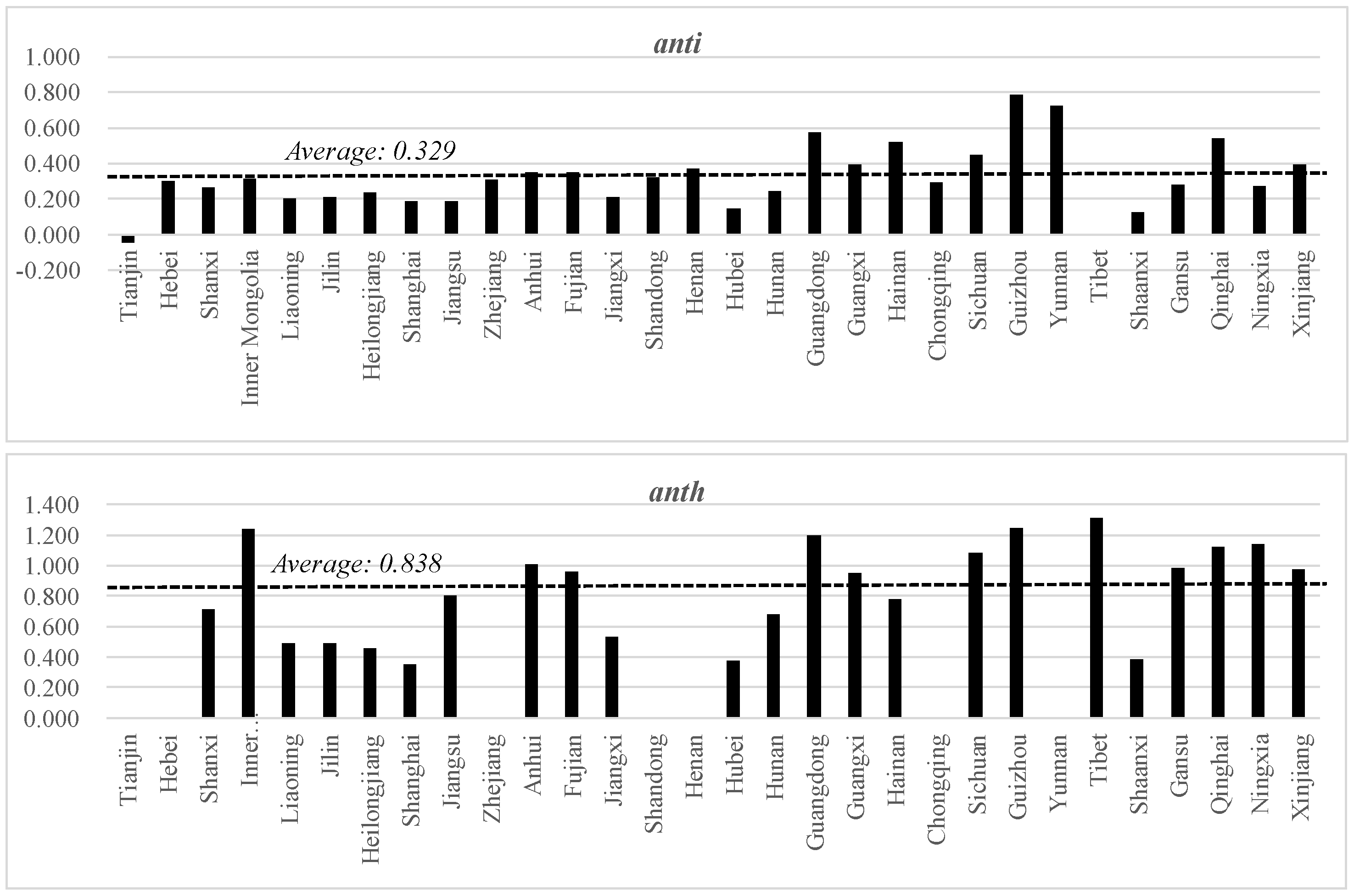
Appendix A). According to the China Statistical Yearbook, in 2020, the industrial discharge of COD per million persons varied from 65 tons in Beijing to 700 tons in Jiangsu; the household discharge of COD was from 1848 tons in Beijing to 11,488 tons in Guangxi; the industrial discharge of ammonia nitrogen was from 2 tons in Beijing to 36 tons in Jiangxi; and the household discharge of ammonia nitrogen was from 94 tons in Tianjin to 1149 tons in Guangxi. The economic factors influencing pollution should be considered; the gross regional product (GRP) per capita in 2010 differed from 127,816 yuan in Beijing to 28,171 yuan in Gansu; the secondary industry’s value added as a percentage of GRP (affecting industrial discharges) differed from 46.2% in Fujian to 16.0% in Beijing; and the urban population as a percentage of the total population (affecting household discharges) differed from 89.3% in Shanghai to 35.8% in Tibet. In addition, there are policy priority areas that are designated as key regions for water pollution control by the Chinese government and that are imposed with several regulations to improve water quality. This includes three river (Huai, Hai, and Liao) and three lake (Tai, Chao, and Dianchi) basins (hereafter, 3Rs3Ls) that are spread across 11 provinces (last column of
Table 1 [
3]). The authors identified the 11 provinces based on Wang et al. [
3].
This study follows the original form of the EKC: the standard nonlinear model in which water pollution per capita is regressed by income per capita and its square. The original EKC postulates an inverted-U-shaped nexus between pollution per capita and income per capita.
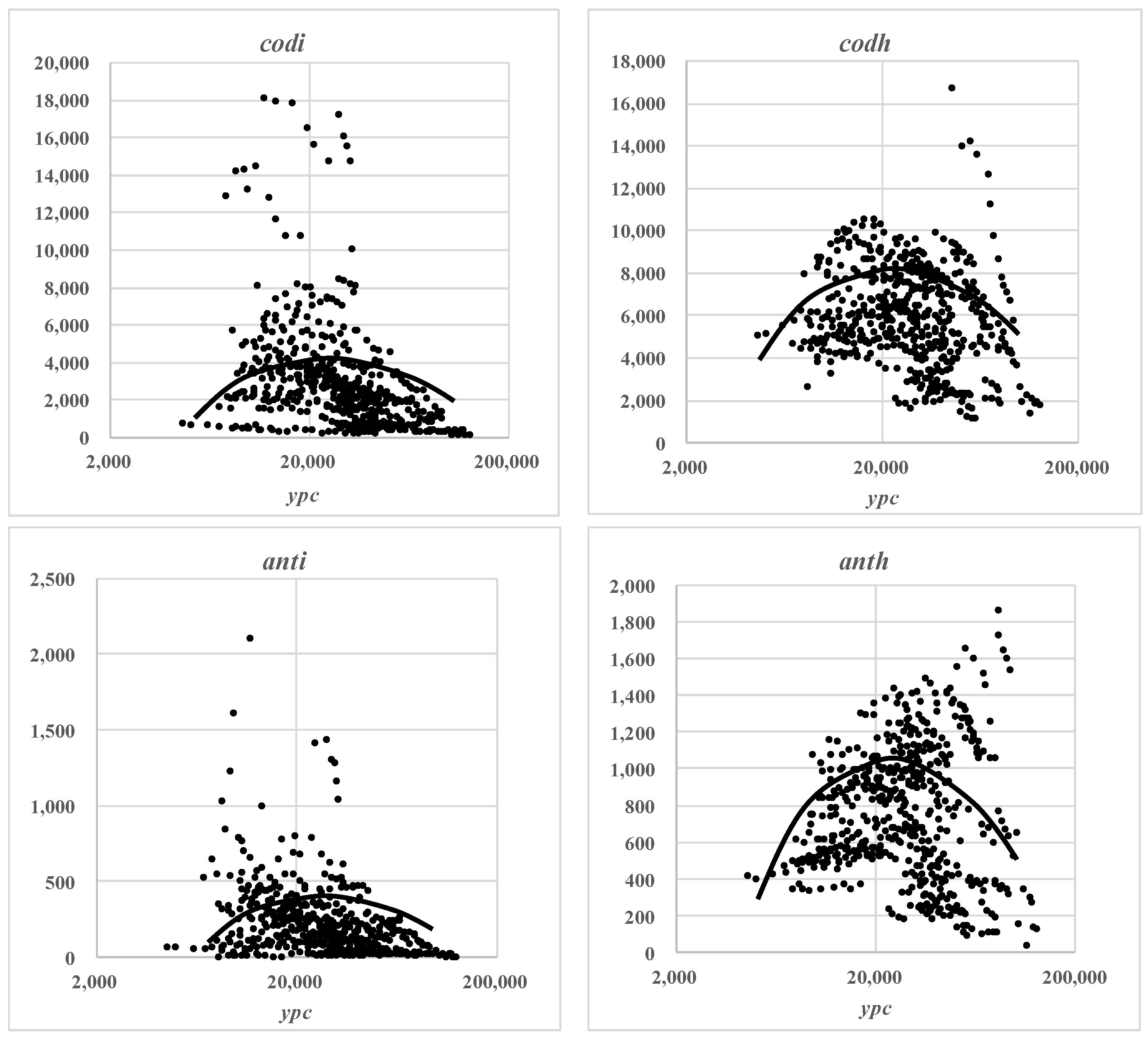
Figure 1 depicts the relationships between the water pollution indicators (vertical axis) and the GRP per capita (horizontal axis) in the total 31 sampled Chinese provinces and periods for 2003−2019; they roughly appear to be inverted-U-shaped. The patterns should be further examined by the subsequent econometric tests by controlling the other factors affecting pollution.
We now turn to econometric approaches. The first specification in Equation (1) applies a fixed-effect model for provincial panel-data estimation in order to explicitly demonstrate the province-specific pollution effects and also run the alternative models in Equations (2) and (3) by replacing the fixed effects with the possible pollution contributors (pollution-control capacity, industrialization, and urbanization) to the province-specific pollution effects. The equations for the estimation are as follows:
where the subscript
it denotes the 31 sampled Chinese provinces for the years 2003−2019, respectively;
codi,
codh,
anti, and
anth represent the water pollutants: industrial COD, household COD, industrial ammonia nitrogen, and household ammonia nitrogen, respectively, expressed as tons per million persons;
ypc shows the gross regional product (GRP) per capita in yuan at constant prices in 2010;
edu denotes the number of higher education graduates per million persons;
ind shows the secondary industry value added as a percentage of GRP;
urb represents the urban population as a percentage of the total population;
fi and
ft show a time-invariant country-specific fixed effect and a country-invariant time-specific fixed effect, respectively;
ε denotes a residual error term; α
0…2, β
0…4, and γ
0…4 represent estimated coefficients; and ln shows a logarithm form, which is set to avoid scaling issues for the water pollutants and GRP per capita. The data source of all the variables is the China Statistical Yearbook. The study constructs a set of panel data for the 31 sample provinces for the period 2003−2019. (This study excluded the year 2020 when the COVID-19 pandemic seriously affected economic activities). The list and descriptive statistics for the variable data are displayed in
Table 3 and
Table 4, respectively.
The notes on the specifications of the estimation models in (1), (2), and (3) are required for an additional description as follows. Equation (1) applies a fixed-effect model, represented by
fi and
ft, for provincial panel-data estimation. The Hausman test is generally used for choosing between a fixed-effect model and a random effect model [
25]. This study, however, focused on demonstrating province-specific pollution effects explicitly; time-specific factors such as economic fluctuations due to external shocks, such as the Asian financial crises in 1997–1998 and the global financial crises in 2008–2009, were considered. In addition, adopting the fixed-effect model contributes to alleviating the endogeneity problem by absorbing the unobserved time-invariant heterogeneity among the sample provinces. The estimation sets Beijing as the benchmark province for extracting the province-specific pollution effects, because Beijing shows the best performance in water pollution control (
Table 1). The significantly positive coefficient of the province-specific fixed effect suggests that the water pollution in the particular province is more serious than that in Beijing. The ordinary hypothesis of the EKC postulating the inverted-U-shaped path between water pollution and GRP per capita would be verified if α
1, β
1, γ
1 > 0 and α
2, β
2, γ
2 < 0 are significant with reasonable levels of turning points.
Equations (2) and (3) represent the alternative models for industrial discharges and household discharges, respectively. Equation (2) replaces the province-specific fixed effects with the possible pollution contributors of the fixed effects: pollution-control capacity (
edu) and industrialization (
ind). Equation (3) replaces them with pollution-control capacity (
edu) and urbanization (
urb). This study uses the number of graduates of higher education (
edu) to represent the capacity to control pollution because the pollution controllability depends highly on human resources and capital in order to address the pollution level in each province. We attempted to apply the variable of treatment plant capacity as the capacity to control pollution.
Appendix B showed that the daily treatment capacity of sewage (
tcs) was positively correlated with water pollution. It suggests that the treatment plant capacities have only chased after the pollution and thus are equipped with no significant power for pollution control. The importance of human capital in controlling environmental pollution has been studied widely [
26,
27,
28]. The adoption of industrialization (
ind) and urbanization (
urb) is based on Liu et al.’s study [
22]; secondary industry output can be a main indicator for industrial water use, and urban population can be an indicator for household water use. We considered the adoption of the indicators directly measuring industrial and household waste water discharge rates. However, these data are available only for 2003–2015 (the Government has stopped publishing these data since 2016). Another problem is that the level of waste water discharge itself can be affected by pollution control variables, which leads to a multicollinearity problem. Thus, this study alternatively used the indirect indicators, including industrialization and urbanization.
Appendix C attempted the estimation using the direct indicators and still found negative coefficients for the pollution control variable (
edu), despite some instabilities in the coefficients due to the problems above. No multicollinearity problem exists in the regressors’ combinations in Equations (2) and (3), namely, (
ypc,
edu,
ind) and (
ypc,
edu,
urb). This is because the variance inflation factors (VIFs), reflecting the level of collinearity between the regressors, indicate lower values than the criteria of collinearity (10 points) in each equation. The VIF values of
ypc,
edu, and
ind in Equation (2) are 2.793, 2.765, and 1.017, respectively, and those of
ypc,
edu, and
urb in Equation (3) are 5.417, 2.737, and 4.111, respectively, according to the authors’ estimation. The pollution-control capacity (
edu) is expected to impart a negative coefficient for water pollution because the higher capacity enables the mitigation of pollution. The coefficients of industrialization (
ind) and urbanization (
urb), which deteriorate water quality, are supposed to be positive in the respective equations.
The explanatory variables in Equations (1)–(3),
ypc,
ind, and
urb were lagged by one year. This helps avoid reverse causality in the model specifications, including the endogenous interaction between the dependent and independent variables. For the pollution-control capacity (
edu), a 10-year lag was applied because it takes a long time for graduates of higher education to be trained for capacity building for pollution control.
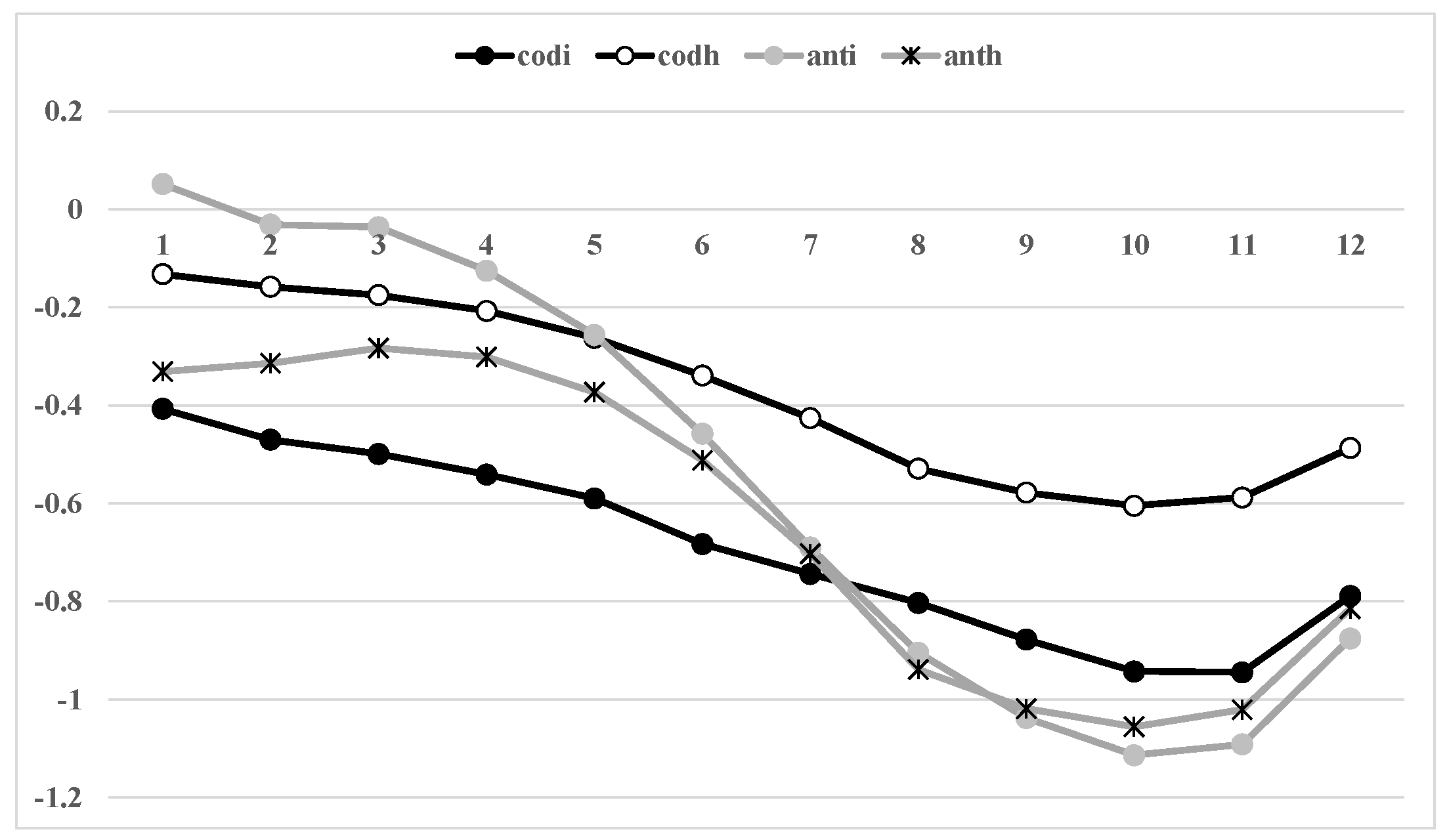
Figure 2 displays the magnitudes of negative coefficients for the pollution-control capacity (
edu) using time series lag patterns from Equations (2) and (3), estimated for each water pollutant; the impacts of the capacity on pollution levels are negatively maximized around the 10-year lag, though the impact sizes differ according to the difference in the effects by their treatment processes.
This study applies the ordinary least squares (OLS) estimator and the Poisson pseudo-maximum likelihood (PPML) estimator for the estimations. The PPML estimator was selected because the sample data with heterogeneity in the provincial properties would be plagued by heteroskedasticity and autocorrelation; in such cases, the OLS estimator leads to bias and inconsistency in the estimates. The PPML estimator corrects for heteroscedastic error structure across panels and autocorrelation with panels, as Silva and Tenreyro [
29] and Kareem et al. [
30] suggest. Therefore, these two estimators are applied to ensure the robustness of the estimations. We used EViews (version 12) (IHS Global Inc., CA, USA) for processing the data and estimations.
3.2. Panel Unit Root and Cointegration Tests
For the subsequent estimation, we investigated the stationary property of the panel data by utilizing panel unit root tests, and if necessary, a panel cointegration test for a set of variables’ data. The panel unit root tests were first conducted on the null hypothesis such that a level and/or the first difference of the individual data have a unit root. In cases where the unit root tests reveal that each variable’s data are not stationary in the level, but stationary in the first difference, a set of variables’ data correspond to the case of I(1); this can be further examined using a co-integration test for the “level” data. If a set of variables’ data are identified to have a co-integration, the use of the “level” data is justified for model estimation.
For the panel unit root tests, this study applied the Levin, Lin, and Chu test [
31] as a common unit root test, and the Fisher-ADF and Fisher-PP tests [
32,
33] as individual unit root tests. The common unit root test assumes a common unit root process across cross-sections, and the individual unit root test allows for individual unit root processes that vary across cross sections. For a panel co-integration test, the study used the Pedroni residual co-integration test (developed by Pedroni [
34]). All of the test equations contained an individual intercept and trend, with the lag length being an automatic selection.
Table 5 presents the test results: the common unit root test rejects the null hypothesis of a unit root at the conventional significance levels for all of the variables. However, the individual tests do not reject a unit root in their levels, except
edu, while rejecting it in their first differences; therefore, the variables almost follow the case of
I(1). The panel co-integration test was conducted further on the combinations of variables in Equations (2) and (3). The panel PP and ADF tests suggested that the level series of a set of variables’ data are co-integrated in the respective combinations. Thus, this study utilizes the level data for the estimation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



