Abstract
In the context of sustainable manufacturing, efficient collaboration between humans and machines is crucial for improving assembly quality and efficiency. However, traditional methods for action recognition and human–robot collaborative assembly often face challenges such as low efficiency, low accuracy, and poor robustness. To solve such problems, this paper proposes an assembly action-recognition method based on a hybrid convolutional neural network. Firstly, an assembly action-recognition model is proposed using skeletal sequences and a hybrid convolutional neural network model combining Spatial Temporal Graph Convolutional Networks (ST-GCNs) and One-Dimensional Convolutional Neural Networks (1DCNNs) to sense and recognize human behavior actions during the assembly process. This model combines the joint spatial relationship and temporal information extraction ability of the ST-GCN model with the temporal feature extraction ability of the 1DCNN model. By incorporating Batch Normalization (BN) layers and Dropout layers, the generalization performance of the model is enhanced. Secondly, the model is validated on a self-constructed dataset of assembly actions, and the results show that the recognition accuracy of the model can reach 91.7%, demonstrating its superiority. Finally, a digital workshop application system based on digital twins is developed. To test the effectiveness of the proposed method, three sets of control experiments were designed to evaluate both objective and subjective aspects and verify the feasibility of the method presented in this paper. Compared with traditional assembly systems, the proposed method optimizes the recognition of human–robot collaborative assembly actions and applies them to intelligent control systems using digital-twin technology. This intelligent assembly method improves assembly efficiency and saves assembly time. It enables efficient and sustainable collaboration between humans and robots in assembly, leading to a positive and sustainable impact on the manufacturing industry.
1. Introduction
With the rapid development of technologies such as industrial Internet, artificial intelligence, big data, and cloud computing, the manufacturing industry is facing significant opportunities for transformation from the digital network stage to the intelligent direction. In smart manufacturing production, assembly is a key process, the quality of which directly determines the product’s quality [1]. However, in traditional production manufacturing, a work mode of complete separation between humans and machines is usually adopted. Although robots can perform relatively simple or highly repetitive assembly tasks, they still cannot handle complex or highly flexible tasks. In addition, the interaction methods of traditional industrial robots are mainly limited to traditional touch-based hardware devices such as keyboards and mice, which restrict human activity areas and also limit the robot’s task execution to the settings made by humans. Collaborative assembly methods with humans and robots can leverage the strengths of both parties. Robots provide enormous power, high precision, and tirelessness, while humans contribute their strong cognitive abilities. Therefore, in order to improve the speed, accuracy, and safety of assembly, human–robot collaboration has gradually become a development trend, replacing some traditional manual assembly workstations [2,3].
Although collaborative robots have been applied in various manufacturing productions, problems such as low robot motion flexibility and low human–robot collaboration efficiency still exist due to the difficulty in recognizing human intentions [4]. In the human–robot collaborative assembly process, humans and robots usually work in the same workspace to perform assembly tasks. Robot malfunctions or mistakes made by assembly personnel may affect the assembly progress and even the operation of the entire production line. Therefore, the interaction behavior of robots with humans and the perception of actions during the collaboration process are crucial. Liau and Ryu [5] developed a Human–Robot Collaboration (HRC) mold assembly status recognition system based on object and action recognition using pre-trained YOLOv5. The system enhanced the sustainability of mold assembly and reduced labor and assembly time. Zhang et al. [6] proposed an observation method based on deep learning to analyze human actions during the assembly process. It was built on a Recurrent Neural Network (RNN) and predicts future motion trajectories of humans to guide robot action planning. The effectiveness of this method was validated through an example of assembling an engine. Lv et al. [7] proposed a human–robot cooperation assembly framework based on digital-twin technology. The framework adopted the Double Deep Deterministic Policy Gradient (DDPG) optimization model to reduce time loss in part selection and repair. It demonstrates the enhanced efficiency and safety achieved in human–robot cooperation during assembly using digital-twin technology. Berg et al. [8] proposed a task action-recognition method for human–robot cooperation assembly based on Hidden Markov Models. By recognizing actions, the robot becomes aware of the task the human is currently executing, enabling flexible adjustments to adapt to human working styles. Lin et al. [9] used deep learning algorithms to classify muscle signals of human body movements to determine the intention of human motion. This not only enhanced communication and efficiency in human–robot collaboration but also enabled the detection of human fatigue, thus achieving sustainable human–machine collaborative workspaces.
Currently, human motion recognition mainly captures the actions of personnel through devices such as sensors and cameras and transmits them in real-time to the robot control system for processing [10]. Among the other sensors as data sources for human behavior analysis, cameras are very popular since computer vision technology allows accurate perception and recognition of human poses and actions, making interaction between humans and robots more natural and flexible [11,12]. And using camera-based visual recognition methods can reduce the complexity and cost of collecting assembly motion data, while also lightening the burden on humans. Camera-based visual posture-recognition methods can be further divided into posture recognition based on RGB video data and posture recognition based on skeleton data obtained from human depth images. The latter represents the posture behavior of individuals using the position variations of a few simple joints, which demonstrates good robustness in the face of complex backgrounds, lighting changes, and viewpoint variations, resulting in better recognition performance [13]. However, due to the influence of camera sensor accuracy and noise, robots often encounter issues such as the inability to perceive actions or poor recognition accuracy and real-time performance when recognizing human motions. These not only greatly impact the smoothness and efficiency of assembly but may also pose threats to humans themselves. To overcome these problems, in recent years, motion-recognition methods based on deep learning have gradually developed. By learning large amounts of data, these methods achieve higher recognition accuracy and better real-time performance, thereby improving the efficiency and safety of human–robot collaboration. For example, action recognition based on Convolutional Neural Networks (CNNs) using skeletal features has achieved good results [14,15]. Zhu et al. [16] proposed a deep neural network architecture based on a bidirectional Long Short-Term Memory Convolutional Neural Network (LSTM-CNN) for recognizing human postures using human skeletal data. Although these methods can effectively learn temporal features, most of them do not make good use of the spatial structural information present in human actions. Orazio et al. [17] implemented real-time tracking of human skeletons using the Open AI framework, extracting key features and inputting them into a neural network for posture recognition. Cherubini et al. [18] used the OpenPose 3D skeletal extraction library to obtain human skeletal joint coordinates and applied convolutional neural networks for gesture detection, which was then used in human–robot interaction. Yan et al. [19] first proposed the application of graph neural networks to skeleton-based action-recognition tasks, namely the ST-GCN. The incorporation of spatial and temporal convolutions into skeleton behavior-recognition tasks shows excellent robustness and novelty. Dallel et al. [20] used digital twins and VR technology to simulate industrial workstation assembly tasks under robotic arm cooperation and trained a human action-recognition model using ST-GCN. However, ST-GCN has a relatively weak expressive ability for temporal information and it requires improvement in terms of capturing the behavioral characteristics of individuals in different application scenarios. Liu et al. [21] improved the model’s ability to extract temporal features by incorporating residual networks into the time information processing of the node. Cao et al. [22] proposed a new partition self-attention spatial-temporal graph convolutional network (NP-AGCN).
The use of human motion recognition technology in assembly can overcome the limitations of traditional assembly methods and improve the efficiency of collaborative tasks and the assembly process. It can also accurately monitor, quickly correct, and adaptively adjust human operations, ensuring assembly stability and quality. This paper aims to address the issues in human–robot collaborative assembly using a method based on visual cameras and hybrid convolutional neural networks for human action recognition. Specifically, the study utilizes camera capture of human actions and further improves the performance and application potential of assembly action-recognition tasks through the study of a hybrid convolutional neural network combining ST-GCN and 1DCNN for assembly action-recognition models. The ST-GCN model is utilized to address the spatial and temporal feature extraction of human skeletal topology, enhancing the generalization performance of the model. The 1DCNN model is used to further enhance the capability of extracting temporal features.
The organization of this paper is outlined as follows: related research is introduced in Section 1; the assembly action-recognition method based on an ST-GCN and 1DCNN hybrid neural network is elaborated in Section 2; the validation experiments and results of the algorithm model are presented in Section 3; and the effectiveness of the application case is showcased in Section 4. Finally, the research is summarized in Section 5, its contributions are discussed, and future work is outlined.
2. Materials and Methods
2.1. Technical Framework of Human–Robot Collaborative Assembly Method
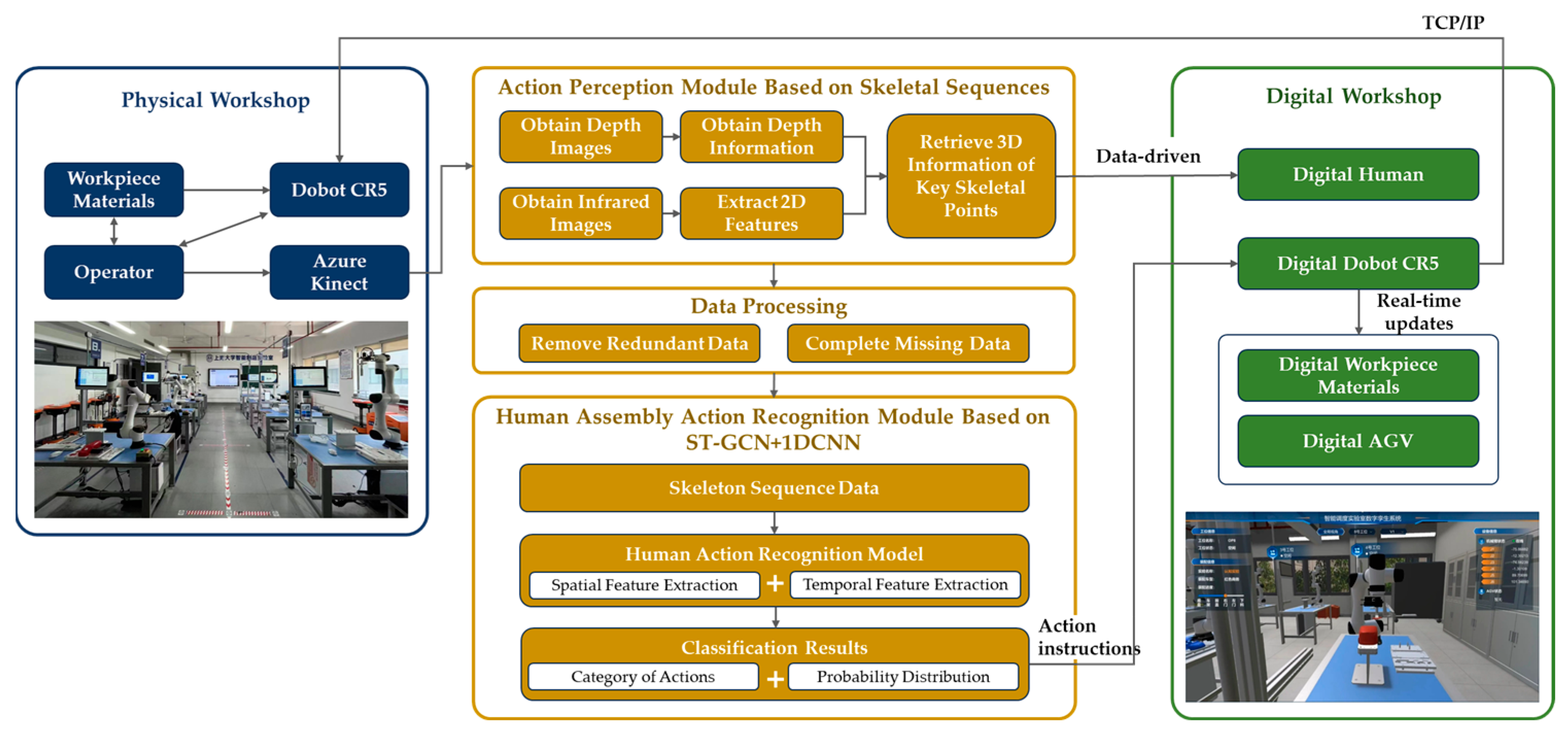
This study aims to improve the efficiency and quality of industrial assembly, achieving collaboration between humans and machines. Specifically, it can be divided into three aspects. Firstly, by utilizing computer vision and depth perception technology, the perception of human actions in the physical workshop is realized during the assembly process. This enables robots to understand human actions, reducing communication costs with human workers and increasing work efficiency. Secondly, the skeletal point sequence of the human body is obtained and subjected to data processing. Finally, based on the perceived information, algorithm models are used to classify and recognize human actions. This allows the monitoring of important nodes in the assembly process and provides a foundation for understanding human assembly behavior. Additionally, it facilitates the generation of corresponding instruction responses and assembly guidance through digital workshops, enabling automated reasoning of the assembly process and improving the efficiency and quality of the entire assembly workflow. Based on the above analysis, this paper constructs a research framework for action recognition in human–robot collaborative assembly, as shown in Figure 1.
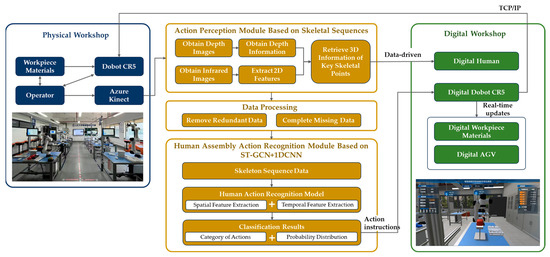
Figure 1.
Research framework for human–robot collaborative assembly methods.
2.2. Action Data Based on Skeletal Sequences
The process of human action data perception in this article is shown in Figure 2. First, the Azure Kinect visual sensor is used to capture the human skeletal key points during the assembly process, and data collection is conducted using the data acquisition system built with Unity to obtain the human skeletal data. The human skeletal data are organized into skeletal sequence data based on timestamps to form a dataset. This dataset is then used as input to the action-recognition model to realize the real-time action-recognition function.

Figure 2.
The process of perceiving human motion data.
Among them, the human skeletal sequence is the information that describes the connectivity and topological structure of skeletal joints, including local shape features and overall structural topological features [23]. It can effectively analyze and apply the spatial temporal characteristics and motion patterns of human movements. The skeletal motion sequence is composed of multiple motion frames, and each motion frame corresponds to the positional information of skeletal key points at a certain moment, namely the location information of skeletal key points. By connecting the skeletal key points of each motion frame in chronological order, the skeletal motion sequence can be obtained. According to the human–robot cooperation assembly requirements in this paper, the focus is on the main skeletal points such as shoulder joints, elbow joints, hip joints, knee joints, and torso, while details such as fingers are ignored.
The skeletal point data are organized and arranged according to the acquisition timestamp and key point number. The skeletal sequence is represented as a three-dimensional matrix with dimensions of , as follows:
Each row represents the information of n key points at a certain time point, and each column represents the coordinate changes of a key point within frames. represents the coordinate information of the -th skeletal key point in space.
2.3. Hybrid Models for Assembly Action Recognition
In this study, an assembly action-recognition model based on human–robot collaboration was proposed. This model adopts skeleton sequences and a hybrid convolutional neural network (ST-GCN + 1DCNN) to capture human motion information. Firstly, sensor data are collected to capture human skeleton sequence data and pre-process them. Then, the preprocessed data are input into the ST-GCN network for feature extraction and representation learning. Finally, the extracted features are fed into a 1DCNN for action classification.
2.3.1. ST-GCN
The Graph Convolutional Neural Network (GCN) is a deep learning method for processing graph data, which is used to preserve the structural information of the graph [24]. It obtains new node information by integrating the information associated with the edges connected to the nodes. ST-GCN is an extension of GCN that is suitable for action-recognition tasks. ST-GCN models skeletal points or skeletal sequences of the human body during motion as spatial-temporal graphs and applies spatial and temporal convolutions to learn feature representations in the graph.
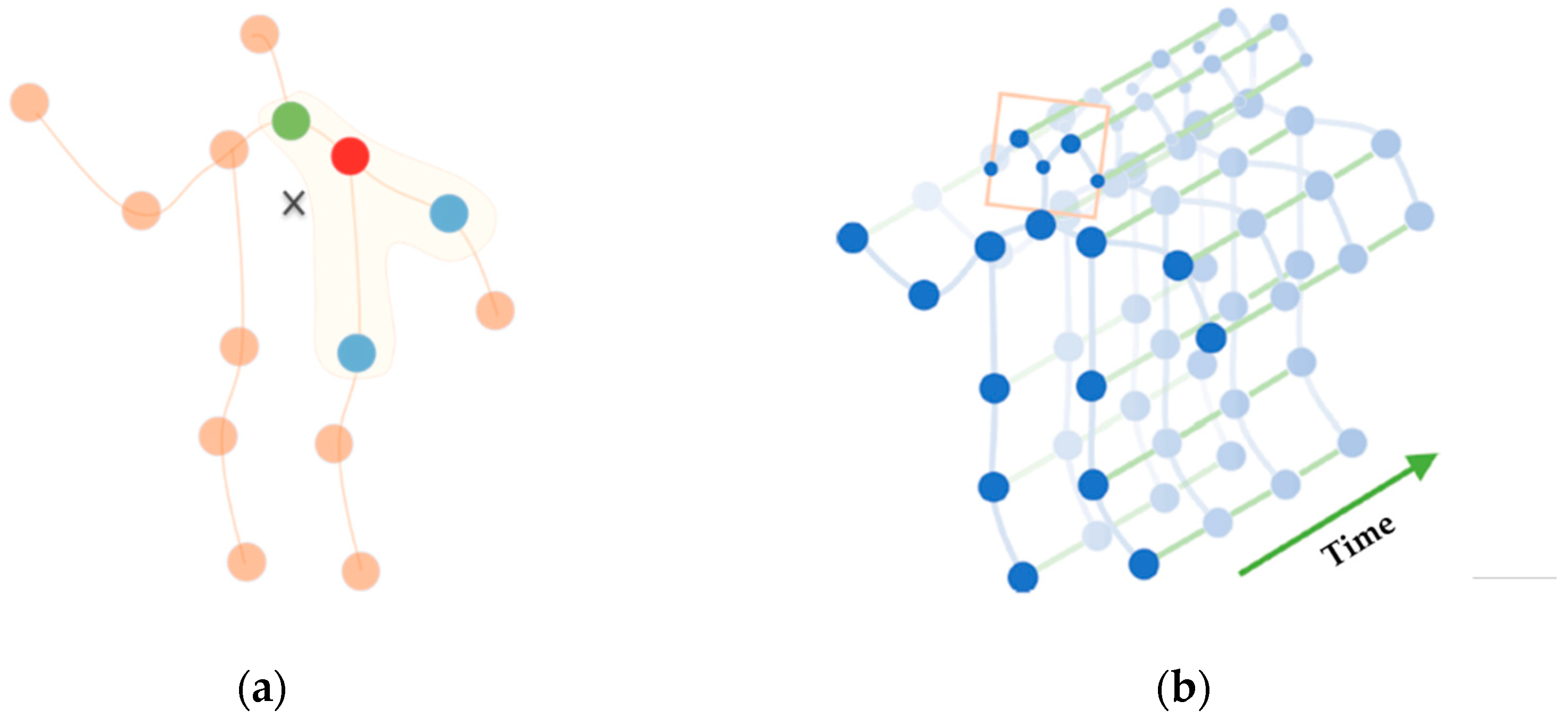
In this study, the key points of human skeletal data are regarded as vertices of the graph and skeletal connections are regarded as edges. The application of graph convolution to human skeletal data has been successfully demonstrated as shown in Figure 3a. Different colors in the figure represent different subsets, and each color corresponds to a weight vector. However, modeling only based on the skeletal graph can only describe the information of each frame but cannot express the correlation between frames or convey the key action information of the position changes between frames. Therefore, this study constructs a spatial-temporal model by connecting the same nodes of adjacent skeletal graphs and performs spatial-temporal modeling on the skeletal graph sequence. As shown in Figure 3b, each node in the spatial-temporal graph corresponds to a joint of the human body. There are two types of edges in the spatial-temporal graph: one is the spatial edges formed by the natural connectivity between nodes in the spatial dimension, and the other is the trajectory edges between the same nodes in the time dimension.
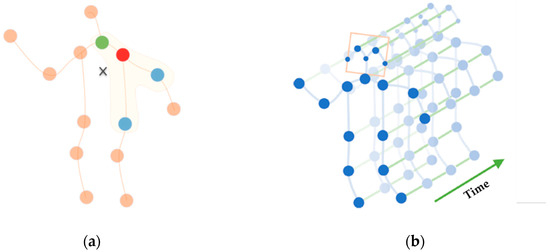
Figure 3.
(a) Spatial modeling; (b) spatial-temporal modeling.
The purpose of the spatial-temporal graph convolutional model used in this study is to learn the motion trajectories of key nodes during the temporal variation process and use them to distinguish different action categories.
2.3.2. 1DCNN
To further enhance the modeling capability of temporal sequences, we have used a 1DCNN. 1DCNN essentially operates on the same principles as convolutional neural networks, which are primarily used for feature extraction in two-dimensional images. However, 1DCNN only focuses on the time dimension, making it widely applicable to tasks related to time series. Despite the difference in dimensions, it also possesses advantages such as the translation invariance shown by CNN [25].
2.3.3. ST-GCN + 1DCNN Hybrid Neural Network Model
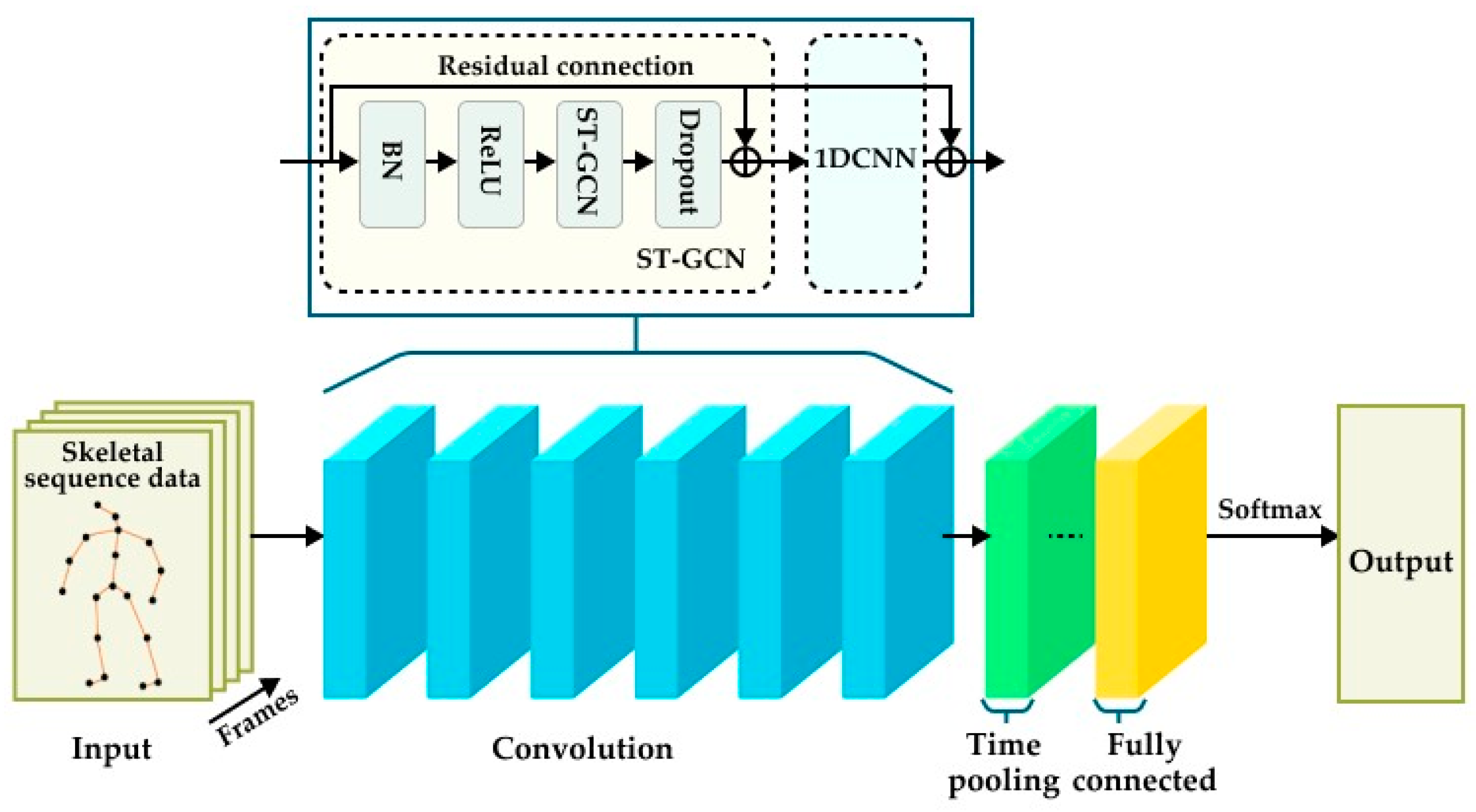
The structure of the action–perception model constructed in this article is shown in Figure 4. First, the skeleton connections create a topological graph structure, and the skeleton graph connections and data are input into the network structure together. Due to the correlation between the characteristics of human skeletal data and the possible presence of noise and incomplete data, a BN layer is added to the input layer of the network structure when processing these data. This layer normalizes the human skeletal data, giving it a consistent scale and reducing the correlation between features. This enhances the interpretability of the data and the generalization ability of the network. The middle part consists of a core network model, which is composed of 6 layers of spatiotemporal convolutions combined with residual structures. The batch size of this network model is set to 32, and the channel size of each layer is set to 64. A dropout layer with a probability of 0.5 is added. It can introduce randomness during the training process. By dropping a portion of the key point data, it reduces the impact of certain key points on action recognition. This decreases the model’s excessive reliance on certain key points, further improving the robustness and generalization ability of the model, preventing overfitting, and allowing it to better adapt to various types of actions. Finally, a global average pooling layer and a fully connected layer are added at the end of the model, which aims to map and consider the features of all different key points and provide the basis for classification.
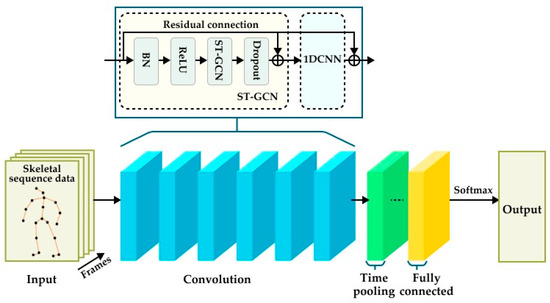
Figure 4.
Mixed convolutional neural network model architecture diagram.
The fully connected layer aggregates the feature maps after multiple layers of spatiotemporal graph convolutions, 1DCNN, and pooling into a one-dimensional vector input by taking the average, and then calculates the output by applying linear mapping to each layer’s input. The diagnostic results of this output will also be input to Softmax for the final prediction. The Softmax regression function maps the corresponding values of all possible categories obtained from linear regression classification to between 0 and 1, representing the probability value of the input data belonging to each different category. Based on the probabilities of each action label, the action label with the highest probability is determined as the model’s prediction.
The mixed convolutional neural network method can comprehensively understand and recognize human body movements in human–robot collaborative assembly tasks. The fused feature representation includes a comprehensive expression of time and space, static and dynamic information, which more fully reflects the characteristics and requirements of the assembly task. Based on these feature representations, this model can achieve higher accuracy in recognizing assembly actions.
3. Experimental Results and Performance Evaluation
The hybrid convolutional neural network action-recognition algorithm is implemented based on the Pytorch framework. The hardware environment uses a Windows 10× 64 system computer, manufactured by Lenovo Legion in China. It is equipped with an Intel i7-10875H processor, NVIDIA RTX2060 graphics card, and 16 GB of memory. In the Anaconda environment, the Python 3.6 environment is configured, and the CPU version of torch 1.9.1 and the corresponding torch vision are installed to complete the environment setup.
3.1. Data Set Construction
This study uses the Azure Kinect depth camera and SDKs provided by the developer (Body Tracking SDK v1.0.1 and Sensor SDK v1.4.0) to collect assembly motion data. All actions were performed at this workstation. Some actions were completed individually by humans, while others were collaboratively performed by humans and robots. A total of 12 participants took part in the data collection, with a gender ratio of 7:5 (male:female). The average age was 22 years old, with a height range of 155–193 cm and a weight range of 44–102 kg.
During the data collection process, participants sit diagonally in front of the Azure Kinect depth camera. They are instructed to perform ten sets of actions that may occur during the assembly process, with each set repeated ten times. The data collection for each set takes approximately 20–25 min. To enhance the versatility of the dataset in action recognition, the experimenter explains the assembly process and the required actions to the participants before collection, without restricting specific action behaviors.
To achieve the visualization of the data collection process, a Unity visualization scene was constructed. The body joints of the participants were superimposed with virtual objects and lines. The studied human–robot collaborative assembly application mainly collects the skeletal point motion sequences of the upper body. Each frame is collected based on 24 skeletal joint node data. The data form collected for each frame action in each dataset should be a matrix of 24 (skeletal key points) × 3 (dimensions), that is, the data size = a total number of frames × 24. If there is a skeletal missing problem within a single frame, linear interpolation will be used for data supplementation. Each piece of data is stored with a format of “timestamp (running time) + joint name (Joint Type) + pos: + three-dimensional coordinates of the skeletal joint”. Each set of actions is outputted as a txt file.
The data collection of actions is shown in Table 1. There are a total of seven categories of action types, with 120 collections for each category. Therefore, a dataset of 120 samples can be obtained for each action type. Each action dataset is labeled as “Action + ‘Num’ + ‘-x’”. ‘Num’ represents the action type label, and ‘x’ represents the dataset index.

Table 1.
Dataset collection.
3.2. Loss Function
The cross-entropy loss function is widely used in classification tasks. This function can avoid problems such as gradient vanishing and gradient explosion, while also possessing the characteristic of faster weight updates for larger errors and slower weight updates for smaller errors. This enables the model to learn and adjust the parameters more efficiently to improve the classification accuracy. Therefore, this paper uses the cross-entropy loss function to reflect the difference between the model’s predicted results and the true labels. The basic formula for calculating the cross-entropy loss function is as follows:
Based on the above model structure, this paper adopts the formula of binary cross-entropy loss function for calculation. The formula can be expressed as
represents the total number of samples in the dataset; represents the true label of the -th sample data (with a value of 0 or 1); represents the output probability of the -th sample prediction. is used to measure the loss when , where the loss is . It indicates that as the prediction probability increases, the loss decreases accordingly. When approaches infinite, the loss gradually approaches positive infinity, which means a higher cost for misclassifying positive samples. is used to measure the loss when , that is, the loss is . It indicates that the lower the predicted probability belonging to positive samples, the lower the loss. When approaches 1, the loss approaches positive infinity, indicating a higher cost for misclassifying negative samples.
The model adopts the Stochastic Gradient Descent (SGD) algorithm for stochastic gradient descent. The initial learning rate of the model is set to 0.1. Every 10 epochs form a stage, and the learning rate decreases by a factor of 0.1. The total training lasts for 50 epochs.
The dataset is divided into a training set and a testing set at a ratio of 8:2. During the testing phase, the recognition performance is evaluated based on Top-1 and Top-5. The Top-1 evaluation criterion selects the action category with the highest predicted probability as the result. The Top-5 evaluation criterion considers the top five predictions with the highest probabilities. As long as the correct category appears among them, it is considered a correct prediction. The hybrid convolutional neural network model repeats six layers of spatial-temporal graph convolution, and the hyperparameters of each layer are shown in Table 2.
Table 2.
Hyperparameters of the convolutional layer of the model spatial-temporal map.
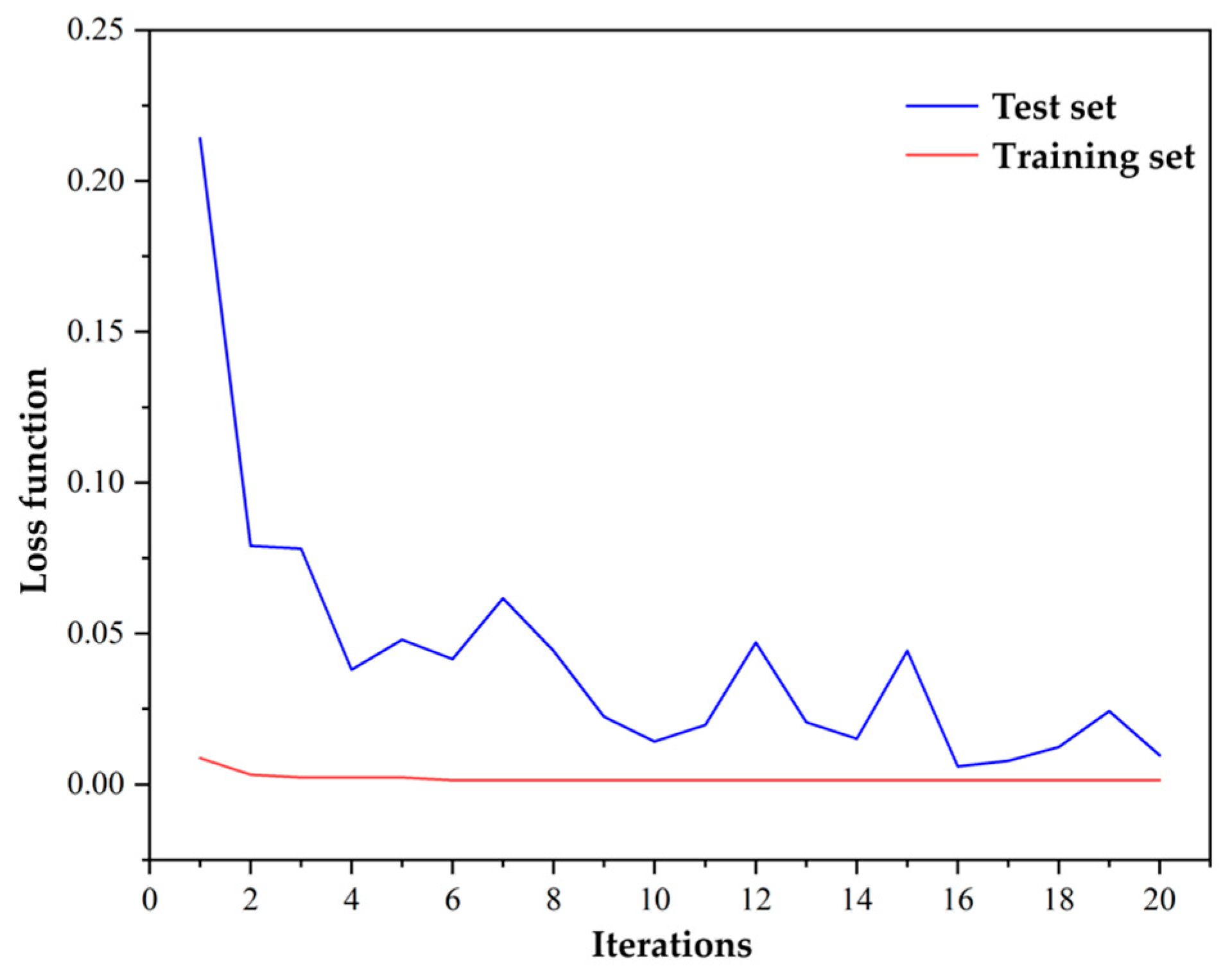
The performance of the loss function of the hybrid convolutional neural network model on the training and testing sets varies with the number of iterations, as shown in Figure 5. The loss changes are recorded for each epoch during the training process. After 20 rounds of iteration, the loss in the training set decreased from 0.23 to 0.02. Additionally, the corresponding Top-1 accuracy reached 90% and the Top-5 accuracy reached 98%.
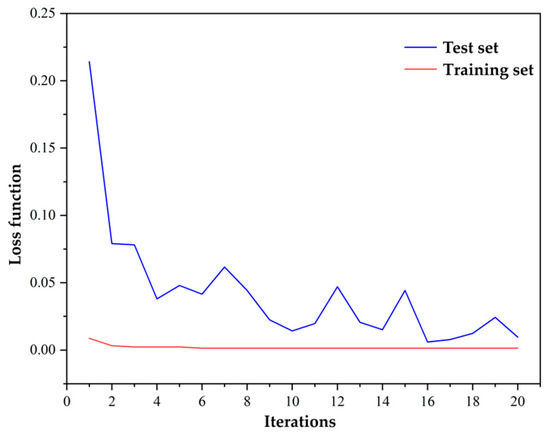
Figure 5.
Testing set and training set loss function variation.
3.3. Performance Evaluation Metrics
Action recognition is essentially a multi-classification problem [26]. The research on action-recognition algorithms mainly focuses on the accuracy of the model. The calculation of this metric is based on a confusion matrix, as shown in Table 3.
Table 3.
Confusion matrix.
Accuracy refers to the proportion of correctly classified samples among all samples, which is used to measure the overall classification accuracy of a model. It can reflect the classification performance and generalization ability of the model and is the most commonly used evaluation metric. This index applies to the whole model. In this study, it refers to the proportion of the sum of all correctly identified assembly actions in all samples during human–robot collaborative assembly. It represents the accuracy of the model in predicting all assembly actions. The formula can be expressed as
Precision refers to the proportion of true positive samples among all true-positive samples, which is used to measure the reliability of positive samples in the model’s classification results. It can be used to reflect the error rate of the model. This index aims at the prediction accuracy of a specific category. In this study, it refers to the number of real samples of each assembly action accounted for by the number of all predicted samples for this action during human–robot collaborative assembly. It represents the accuracy of the model in predicting a specific assembly action. The formula can be expressed as
Recall refers to the proportion of true-positive samples among all predicted positive samples. It is used to measure the probability of correctly identifying true-positive samples and can reflect the model’s false-negative rate. The formula can be expressed as
F1 score is considered the harmonic mean of precision and recall, used to evaluate the accuracy of binary classification models. The formula can be expressed as
3.4. Model Validity Verification
To verify the effectiveness of the proposed hybrid convolutional neural network model, a control experiment was conducted as shown in Table 4. The experiment focused on achieving high accuracy in recognizing human skeletal sequences to improve assembly efficiency. The hybrid convolutional neural network model proposed in this paper was compared with other methods, and the Top-1 accuracy and Top-5 accuracy of each model were listed. Through experiments, this paper verifies the effectiveness of the basic static graph convolutional network and further improves the accuracy to 83.4% by incorporating 1DCCN. Finally, the recognition accuracy of the complete hybrid convolutional model is compared with them, further increasing the accuracy to 91.7%. From the table, it can be seen that the hybrid convolutional neural network model effectively utilizes the prior knowledge of human skeletal sequences and considers both temporal and spatial features, resulting in significantly higher recognition accuracy than existing methods.
Table 4.
Comparison of the accuracy of the hybrid convolutional algorithm with other algorithms on the dataset of this paper.
Specifically, less than 10 incorrect judgments were made out of 100 test samples. This shows that the proposed hybrid convolutional neural network model has good generalization performance and can make reliable predictions for unknown samples. However, the dataset used in this paper is relatively small, which may have impacted the overall accuracy rate. It can be inferred that the accuracy rate of 91.7% is far from reaching the upper limit of the model. While this study aimed to improve the method itself rather than expand the dataset, it is reasonable to believe that with a larger annotation dataset, the model could achieve a classification accuracy above 99%.
In conclusion, the proposed hybrid convolutional neural network model surpassed existing methods in recognizing human skeletal sequences. Its ability to leverage prior knowledge and consider both temporal and spatial features resulted in significantly higher accuracy rates. Although there are limitations associated with the dataset size, our results suggest great potential for future improvements and applications in the field.
To further evaluate the comprehensive performance of the proposed ST-GCN+1DCNN action-recognition method, it is compared with the GCN + 1DCNN action-recognition method, as shown in Table 5, and the comparative results are obtained.
Table 5.
Comprehensive comparison of ST-GCN + 1DCNN and GCN + 1DCNN with this paper’s dataset.
In terms of accuracy, the recall rate, and the F1 score, the recognition method of ST-GCN + 1DCNN is significantly superior to the recognition method of GCN + 1DCNN. The results of the ST-GCN + 1DCNN method are consistently higher than those of the GCN + 1DCNN method in terms of the accuracy and recall rate, indicating that the ST-GCN + 1DCNN action-recognition method not only classifies actions more accurately but also provides more accurate division between positive and negative samples. The combination of the F1 score further shows that the proposed ST-GCN + 1DCNN hybrid convolutional neural network model can identify target actions more accurately and has better overall performance in action-recognition tasks. This indicates that compared to the GCN + 1DCNN model, the hybrid model proposed in this paper, which models temporal and spatial features of action sequences through graph structures for feature propagation and information aggregation, can better capture the temporal and spatial characteristics of action sequences.
4. Application
4.1. Assembly Scene and Objects
4.1.1. Assembly Scene
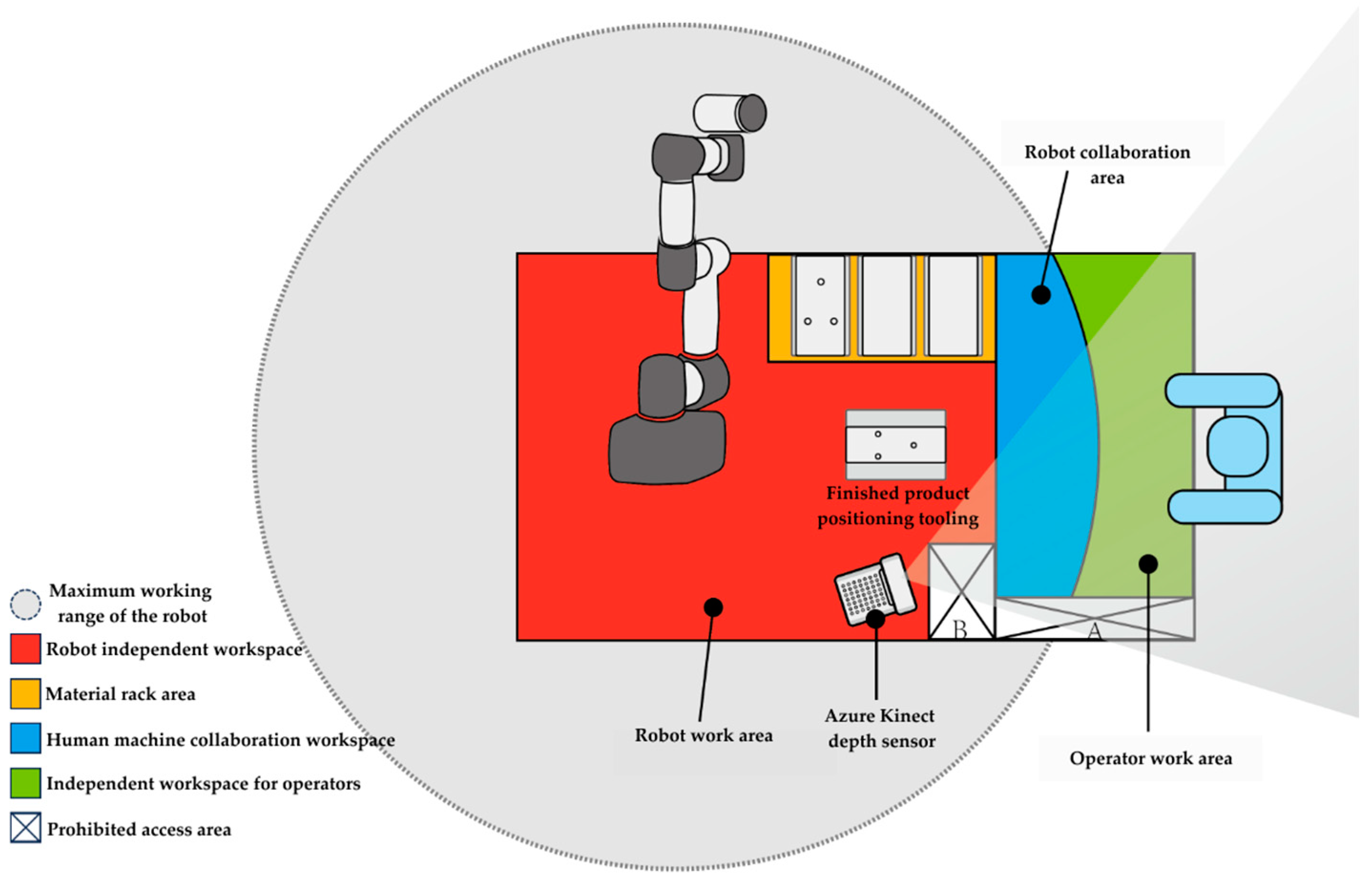
Based on the actual needs of the assembly object and assembly process, this paper adopts a collaborative assembly mode, which arranges humans and robots in the same workstation for joint operation. The assembly workstation includes an operation platform, collaborative robots, computers, depth vision sensors, and relevant components of the assembly object. Assembly personnel are essential parts of the assembly workstation. Among them, the assembly-related components include positioning fixtures, imitation fixtures, and assembly workpieces. Figure 6 shows the layout diagram of the human–robot collaborative assembly workstation.
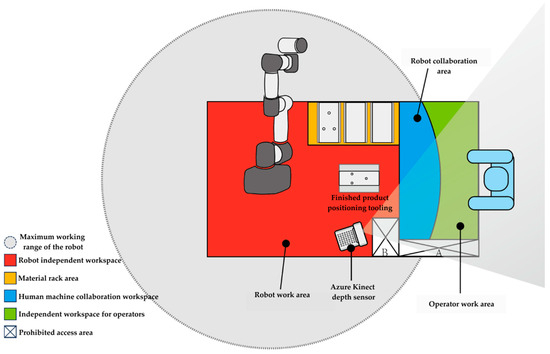
Figure 6.
Human–robot collaborative assembly operation stations.
4.1.2. Assembly Objects and Processes
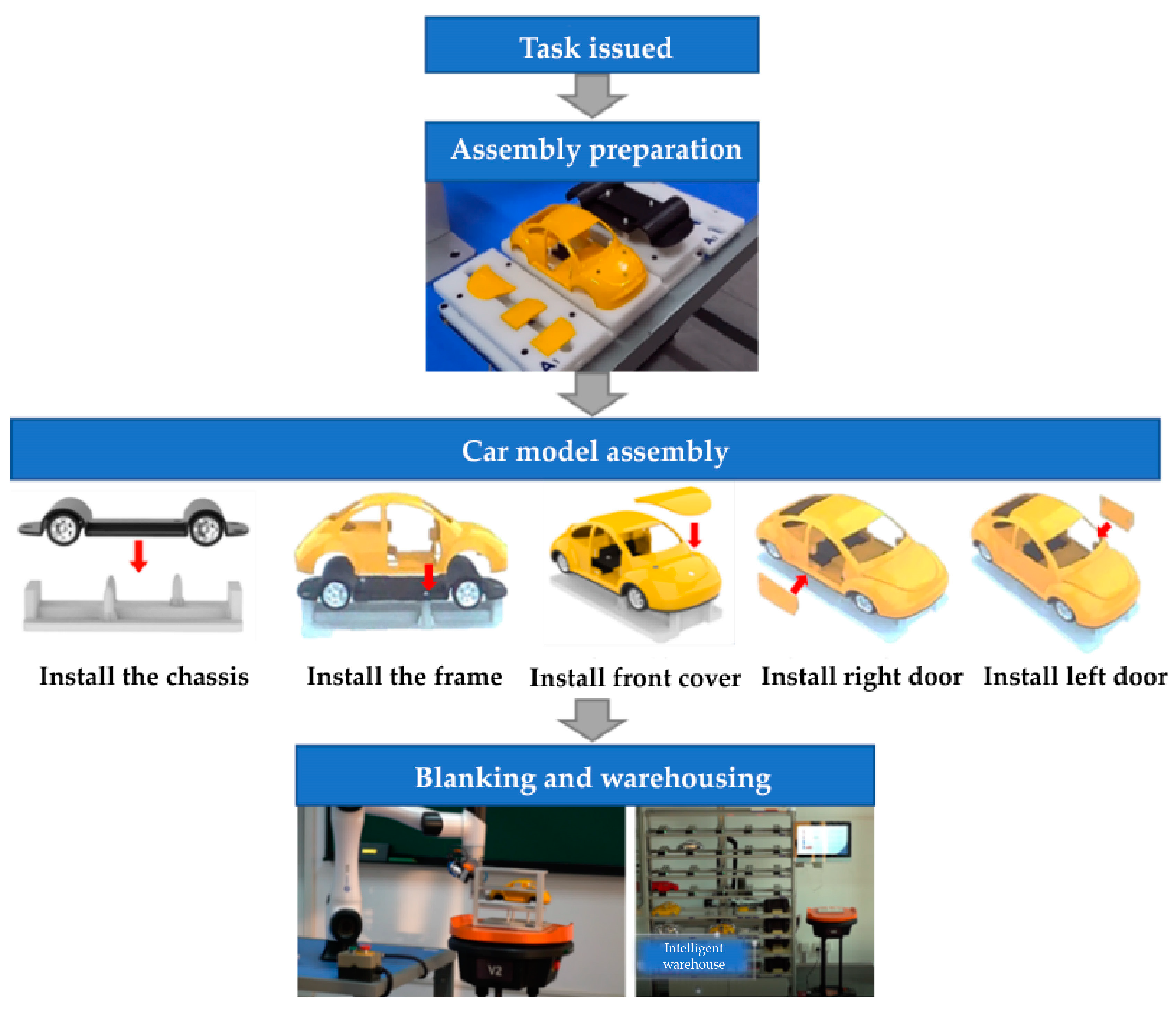
This paper discusses the basic goal of human–robot collaborative assembly tasks, which is to complete an assembly task of assembling a car model together with humans and robots. Each type of model consists of six parts, including the left door, right door, front cover, chassis, base, and tire (including the axle). The specific assembly process is shown in Figure 7. Dobot CR5 is chosen as the collaborative robot, which is mainly responsible for gripping, installing, and unloading, and uses customized end components for operations. The assembly task of the car model is usually assigned based on the different working characteristics of humans and robots. According to the task assignment, humans and robots sequentially or simultaneously execute different assembly sub-steps. This study combines perception and recognition of human assembly actions with historical analysis to assess proficiency and intention and provides guidance for each assembly decision step.

Figure 7.
Assembly flowchart.
4.2. Application Effects and Comparisons
4.2.1. Experimental Environment and Assembly Task Settings
The human–robot collaborative assembly system has weak perception capabilities for the human body and the environment. Digital-twin technology has the functions of monitoring, prediction, and optimization, and it can provide effective collaboration strategies for human–robot collaborative assembly. Therefore, this application is based on digital-twin technology to conduct a virtual simulation of a single-stack human–robot collaborative assembly environment, collaborative robots, and human assembly behavior, thereby enabling data transmission and interaction during the assembly process and constructing a digital-twin assembly application scenario. To validate the usability and effectiveness of the proposed human–robot collaborative assembly action-recognition method based on the hybrid convolutional neural network combining ST-GCN and 1DCNN, a digital-twin integration system for the above assembly is developed in this section using Unity for the usability testing of the method.
As a controllable platform, the digital-twin workshop application system has the capability of integrating simulation data of different objects in the physical workshop. And it integrates the action-recognition method based on an ST-GCN and 1DCNN hybrid convolutional neural network to test and validate the performance of the method in actual assembly tasks. Additionally, the system has the ability to simulate and replicate the collaborative assembly process between humans and robots. It also provides real-time assembly visualization information and control instructions to operators, helping them to better comprehend the assembly process and perform tasks accurately. This ultimately leads to an improvement in assembly efficiency.
The human–robot collaborative assembly scene was used as the test scene, with a car model as the assembly object. Selected participants were assigned to three groups for the experiment. The group performing a dynamic collaborative assembly task served as the experimental group, while the groups performing a pure manual assembly task and a fixed-process assembly task served as the control groups. The pure manual assembly task is to take the material parts and assemble the car model according to the subjective habits of the participant. The fixed-process assembly task is that the participant and the robot cooperate to complete the assembly according to the list of fixed assembly steps, as shown in Figure 8a. The dynamic collaborative assembly task is that the participant performs assembly according to the human action-recognition results and prompts in the digital-twin system, and the robot assists according to the perception and decision results. The dynamic collaborative assembly task is shown in Figure 8b. The total time required for each group of participants to complete their respective assembly tasks was collected to represent assembly efficiency. Additionally, after completing the assembly tasks, the participants were invited to fill out the System Usability Scale (SUS) questionnaire to obtain their subjective perception [27]. Finally, the usability results were obtained by integrating objective data and subjective data.

Figure 8.
(a) Fixed-process assembly; (b) dynamic collaborative assembly.
A total of 15 participants were invited to participate in this test, with ages ranging from 21 to 30 years old, and a male-to-female ratio of 3:1. These 15 participants were divided into three groups for testing, with 5 participants in each group. Each group consisted of two participants (male-to-female ratio of 1:1) with assembly proficiency, while the remaining three participants were all first-time assembly task performers.
4.2.2. Testing Results and Performance Evaluation
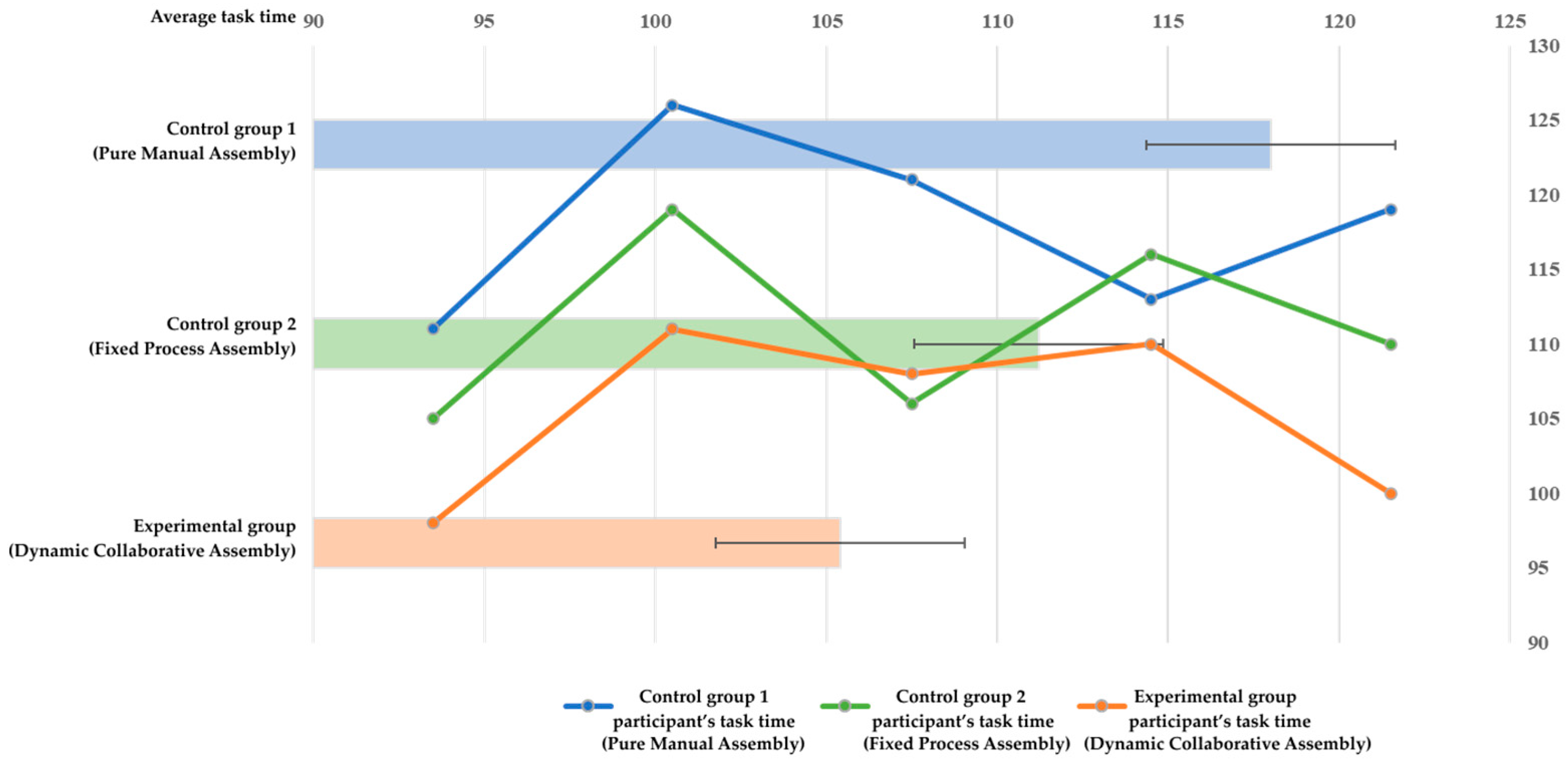
All groups of participants were able to successfully complete the assembly task, and the time statistics for each group’s assembly task are shown in Figure 9.
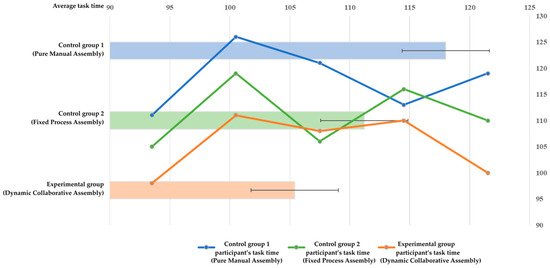
Figure 9.
Time-consumption statistics for assembly tasks.
The average time consumption of the integrated analysis experimental group and two control groups (control group 2 based on actual time consumption) shows that the assembly time consumption of human–robot collaborative assembly, whether it is fixed-process assembly or dynamic collaborative assembly, is generally less than that of pure manual assembly, which can significantly improve assembly efficiency.
To evaluate whether different assembly methods have a significant impact on task time consumption, three sets of test data were statistically analyzed using one-way analysis of variance (ANOVA) [28]. The results are shown in Table 6.
Table 6.
One-way ANOVA.
The results indicate that different assembly methods for the same assembly task show a significant difference effect at the 0.05 level ( = 5.399, p = 0.021 < 0.05), indicating that the assembly method has a significant impact on assembly efficiency and is less likely to be influenced by random factors. After implementing the proposed DT-based dynamic collaborative assembly method, the assembly efficiency was significantly improved by 10.68% compared to the pure manual assembly method and improved by 5.22% compared to the fixed-process assembly method.
To further calculate the effect size, partial eta-squared () and value are used as effect size indicators. measures the extent of variance explained by the between-group differences, indicating the magnitude of the differences. value measures the average difference between different groups relative to the variation within each group and also indicates the effect size. The larger the value of and , the greater the magnitude of the difference, indicating a larger effect size, and the smaller, vice versa. The calculation formulas are shown in Equations (8) and (9).
The analysis results of the effect size are shown in Table 7, with a partial eta squared value of 0.474, indicating that different assembly methods have a significant impact on task completion time. value of 0.949 also indicates a large effect size, further confirming the significant impact of assembly methods on task completion time.
Table 7.
Effect size indicator.
Comprehensively considering the above factors, different assembly methods have significant impacts on assembly efficiency (task time). By recognizing the assembly actions of the human operator, the proposed dynamic collaborative assembly mode allows the robot to accurately understand the intentions and actions of the human operator. This improves collaboration between the robot and the human, ensuring precise cooperation during assembly and reducing unnecessary movements. It also reduces the time for setting the robot’s motion flow, reduces the cost and delay of human–robot interaction, and thereby decreases the assembly time and improves the efficiency of assembly. In addition, through the digital-twin system, the action-recognition results can be fed back to the human operator in real time. The operator can understand the assembly status and progress in a timely manner and adjust accordingly based on feedback information, reducing errors and correcting mistakes. This method comprehensively realizes mutual understanding between humans and machines, further improving the accuracy and efficiency of assembly.
Furthermore, according to the results of the subjective questionnaire, the participants in the experiment gave a better overall evaluation and scores for the human–robot collaborative assembly mode compared to pure manual assembly. The dynamic collaborative assembly mode, which utilizes an action-recognition-based human–robot collaboration assembly approach, showed significant improvements and ranked the best among the three groups in terms of usability and ease of use. This can be attributed to the fact that traditional manual assembly tasks require operators to manually perform each step, constantly focusing on task details and changes. And the fixed-process collaborative assembly method requires human coordination with the robot’s actions for specific assembly processes. However, uncertainties and variations often arise during the collaboration assembly process, necessitating adjustments and changes based on the situation. Due to the operators’ lack of understanding of the robot’s motion patterns, they need to concentrate their attention on the assembly tasks to avoid impacting assembly efficiency or colliding with the robot. In contrast, the proposed dynamic collaborative assembly mode based on human motion recognition facilitates collaboration between robots and humans during the assembly process. This mode offers greater flexibility and can adaptively recognize and comprehend human movements, thereby adjusting the robot’s collaborative behavior in real time based on changes and the needs of human movements. Through this method, operators can focus more attention on key decision-making and tasks, minimizing the need for extensive attention to assembly processes. Consequently, it reduces the cognitive load on operators when adjusting the assembly process, making human–robot collaboration more flexible and efficient.
5. Conclusions
In this study, an assembly action-recognition model based on a hybrid convolutional neural network of ST-GCN and 1DCNN is proposed and implemented. It aims to recognize the assembly behavior of operators during the assembly process. The model uses the ST-GCN model to extract spatial relationships between joints and temporal information of actions. It captures interactions between key points and temporal features using spatiotemporal convolutions. To improve the generalization performance of the model, a residual structure is used to enhance the feature representation of the model. Additionally, a BN layer is further used for data normalization and a dropout layer is used to prevent overfitting. The 1DCNN model is used to enhance the temporal feature extraction ability of the model and improve the classification performance of the model. The model’s usability is validated on an assembly action dataset, achieving a recognition accuracy of 91.7%. A comparison with other neural networks demonstrates the superior performance of this hybrid CNN in assembly action recognition.
Moreover, based on digital-twin technology, a human–robot collaborative assembly integration system using Unity is developed, data transmission and interaction between software and hardware devices are realized, and the feasibility of the human–robot collaborative assembly action-recognition method based on a hybrid convolutional neural network is verified. The experimental results show that the method proposed in this work is significantly better than the pure manual assembly method and the fixed process human–robot collaboration in terms of assembly efficiency.
This study provides new technical support for human–robot collaborative assembly in the field of intelligent manufacturing, with significant implications for improving assembly efficiency and accuracy. However, this study also has some limitations, such as a small dataset size and room for improvement in model generalization capability. Future studies can focus on optimizing the model design, expanding the dataset size, and integrating other technologies and algorithms to further enhance the efficiency and accuracy of the assembly process.
Author Contributions
Conceptualization, Z.G.; formal analysis, Z.G. and W.Y.; methodology, R.Y.; data curation, K.Z.; project administration, L.L.; visualization, Z.L.; writing—original draft, R.Y.; writing—review and editing, Z.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China (Grant No. 2022YFF1400303), Shanghai Industrial Development Innovation Project (Grant No. XTCX-KJ-2022-03), and Zhejiang Provincial Key Laboratory of Integration of Healthy Smart Kitchen System (Grant No: 2014E1004).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The work described has not been submitted elsewhere for publication, in whole or in part, and all the authors listed have approved the manuscript.
References
- Liu, J. The State-of-the-Art, Connotation and Developing Trends of the Products Assembly Technology. J. Mech. Eng. 2018, 54, 2. [Google Scholar] [CrossRef]
- Matheson, E.; Minto, R.; Zampieri, E.G.G.; Faccio, M.; Rosati, G. Human–Robot Collaboration in Manufacturing Applications: A Review. Robotics 2019, 8, 100. [Google Scholar] [CrossRef]
- Gualtieri, L.; Rauch, E.; Vidoni, R. Human-Robot Activity Allocation Algorithm for the Redesign of Manual Assembly Systems into Human-Robot Collaborative Assembly. Int. J. Comput. Integr. Manuf. 2023, 36, 308–333. [Google Scholar] [CrossRef]
- Villani, V.; Pini, F.; Leali, F.; Secchi, C. Survey on Human–Robot Collaboration in Industrial Settings: Safety, Intuitive Interfaces and Applications. Mechatronics 2018, 55, 248–266. [Google Scholar] [CrossRef]
- Liau, Y.Y.; Ryu, K. Status Recognition Using Pre-Trained YOLOv5 for Sustainable Human-Robot Collaboration (HRC) System in Mold Assembly. Sustainability 2021, 13, 12044. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, H.; Chang, Q.; Wang, L.; Gao, R.X. Recurrent Neural Network for Motion Trajectory Prediction in Human-Robot Collaborative Assembly. CIRP Ann. 2020, 69, 9–12. [Google Scholar] [CrossRef]
- Lv, Q.; Zhang, R.; Sun, X.; Lu, Y.; Bao, J. A Digital Twin-Driven Human-Robot Collaborative Assembly Approach in the Wake of COVID-19. J. Manuf. Syst. 2021, 60, 837–851. [Google Scholar] [CrossRef]
- Berg, J.; Reckordt, T.; Richter, C.; Reinhart, G. Action Recognition in Assembly for Human-Robot-Cooperation Using Hidden Markov Models. Procedia CIRP 2018, 76, 205–210. [Google Scholar] [CrossRef]
- Lin, C.J.; Lukodono, R.P. Sustainable Human–Robot Collaboration Based on Human Intention Classification. Sustainability 2021, 13, 5990. [Google Scholar] [CrossRef]
- Gupta, N.; Gupta, S.K.; Pathak, R.K.; Jain, V.; Rashidi, P.; Suri, J.S. Human Activity Recognition in Artificial Intelligence Framework: A Narrative Review. Artif. Intell. Rev. 2022, 55, 4755–4808. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Soylu, A. Human Activity Recognition Using Wearable Sensors, Discriminant Analysis, and Long Short-Term Memory-Based Neural Structured Learning. Sci. Rep. 2021, 11, 16455. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. A Survey of Online Activity Recognition Using Mobile Phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Liu, H.; Chen, C. Enhanced Skeleton Visualization for View Invariant Human Action Recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar]
- Zhu, A.; Wu, Q.; Cui, R.; Wang, T.; Hang, W.; Hua, G.; Snoussi, H. Exploring a Rich Spatial–Temporal Dependent Relational Model for Skeleton-Based Action Recognition by Bidirectional LSTM-CNN. Neurocomputing 2020, 414, 90–100. [Google Scholar] [CrossRef]
- D’Orazio, T.; Attolico, G.; Cicirelli, G.A. Neural Network Approach for Human Gesture Recognition with a Kinect Sensor. In Proceedings of the 3rd International Conference on Pattern Recognition Applications and Methods, ESEO, Angers, Loire Valley, France, 6–8 March 2014; Volume 1, pp. 741–746. [Google Scholar]
- Mazhar, O.; Ramdani, S.; Navarro, B.; Passama, R.; Cherubini, A. Towards Real-Time Physical Human-Robot Interaction Using Skeleton Information and Hand Gestures. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–6. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Dallel, M.; Havard, V.; Dupuis, Y.; Baudry, D. Digital Twin of an Industrial Workstation: A Novel Method of an Auto-Labeled Data Generator Using Virtual Reality for Human Action Recognition in the Context of Human–Robot Collaboration. Eng. Appl. Artif. Intell. 2023, 118, 105655. [Google Scholar] [CrossRef]
- Liu, S.; Bai, X.; Fang, M.; Li, L.; Hung, C.-C. Mixed Graph Convolution and Residual Transformation Network for Skeleton-Based Action Recognition. Appl. Intell. 2022, 52, 1544–1555. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, C.; Wang, P.; Wei, H.; Huang, S.; Li, H. Unsafe Mining Behavior Identification Method Based on an Improved ST-GCN. Sustainability 2023, 15, 1041. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Stathaki, T.; Camarinopoulos, S. Skeleton-Based Human Action Recognition through Third-Order Tensor Representation and Spatio-Temporal Analysis. Inventions 2019, 4, 9. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Eren, L.; Ince, T.; Kiranyaz, S. A Generic Intelligent Bearing Fault Diagnosis System Using Compact Adaptive 1D CNN Classifier. J. Sign Process Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Wang, L.; Feng, W.; Tian, C.; Chen, L.; Pei, J. 3D-Unified Spatial-Temporal Graph for Group Activity Recognition. Neurocomputing 2023, 556, 126646. [Google Scholar] [CrossRef]
- Brooke, J. SUS—A Quick and Dirty Usability Scale. In Usability Evaluation In Industry, 1st ed.; Jordan, P.W., Thomas, B., McClelland, I.L., Weerdmeester, B., Eds.; CRC Press: London, UK, 1996; Volume 21, pp. 189–194. ISBN 978-0-429-15701-1. [Google Scholar]
- Bewick, V.; Cheek, L.; Ball, J. Statistics review 9: One-way analysis of variance. Crit. Care 2004, 8, 130. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).