
Short-Term Photovoltaic Power Generation Prediction Based on Copula Function and CNN-CosAttention-Transformer


Abstract
:1. Introduction
- (1)
- To solve the problem of the poor performance of some traditional correlation coefficient methods, the Copula function is used to calculate the correlation coefficient, which can more flexibly and accurately measure the nonlinear and asymmetrical correlation relationships between time series, and is used to select features with high correlations with photovoltaic power generation power.
- (2)
- Considering the data characteristics of photovoltaic power generation power, the 1D-CNN model is used to capture local patterns and trends in time-series data, while the attention mechanism based on cosine similarity is used to capture long-distance dependencies in time-series data, and its attention focus is dynamically adjusted according to the current input.
- (3)
- The CA-Transformer model is established, using the parallel structure of the CNN and CosAttention to capture patterns at different time scales, and is compared with other models (LSTM, Transformer), proving the effectiveness of the model.
2. Background Theories
2.1. Basic Theory of Copula Functions
2.2. Convolutional Neural Network
2.3. CosAttention
2.4. Transformer
3. Model Construction and Evaluation Metrics
3.1. Copula Function Correlation Analysis Method
3.2. CA-Transformer Model
3.3. Model Evaluation Metrics
4. Experiment
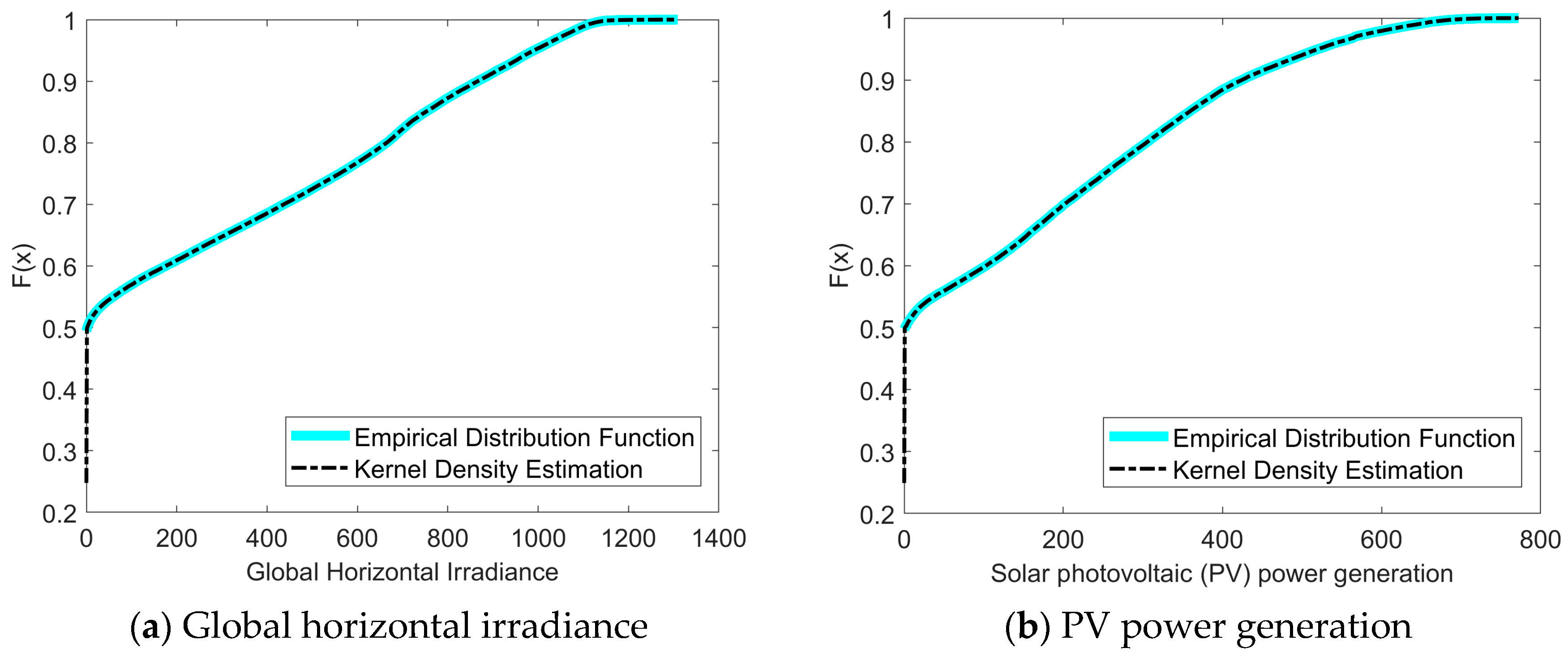
4.1. Experimental Data
4.2. Correlation Analysis Based on Copula Function
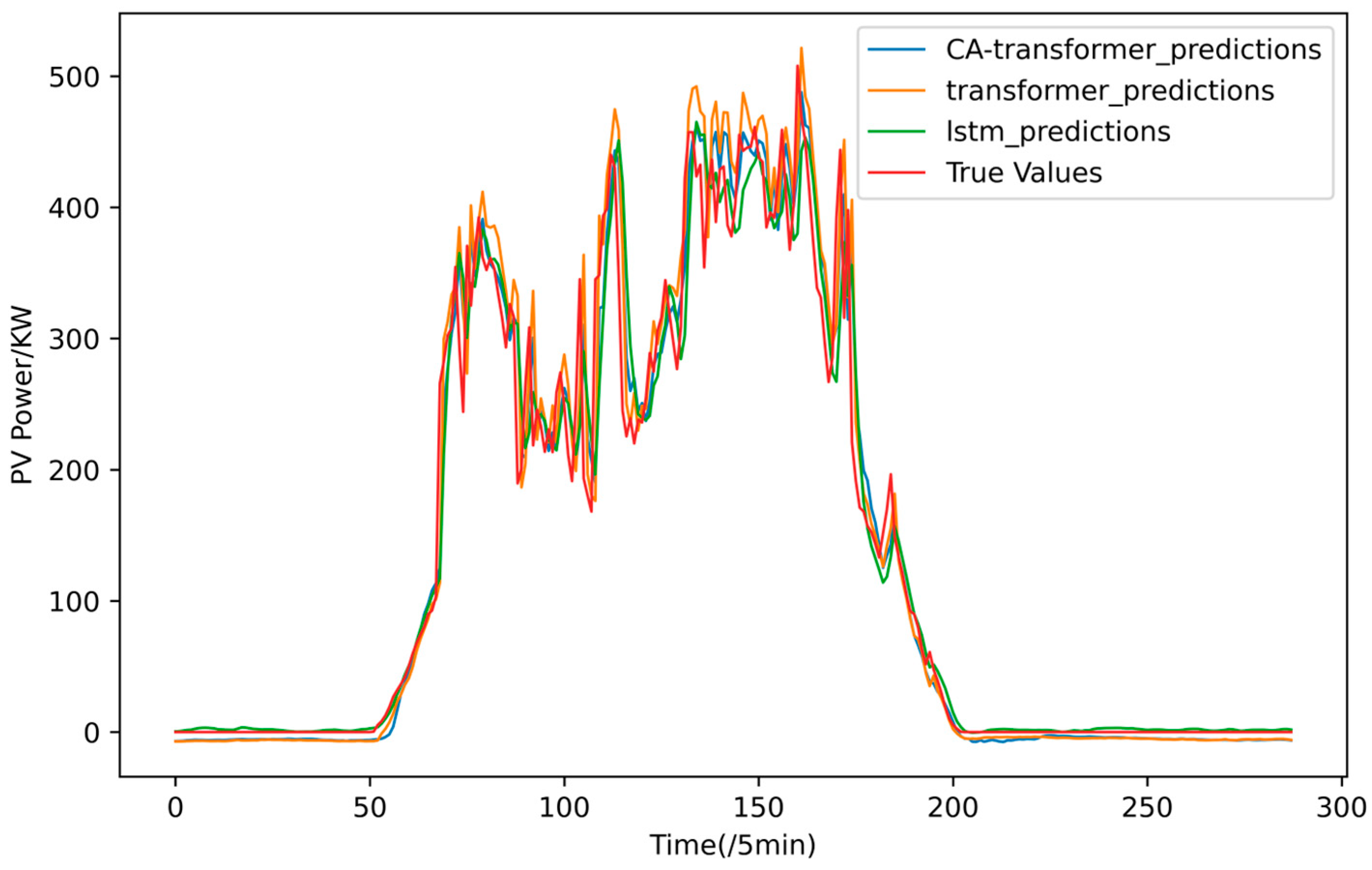
4.3. Prediction Results with CA-Transformer
4.4. Comparison of Prediction Results
5. Conclusions
- (1)
- To establish a photovoltaic power generation prediction model, it is necessary to extract key meteorological factors that affect photovoltaic power generation. Common algorithms cannot comprehensively measure the nonlinearity and trend correlations between photovoltaic power generation and meteorological factors. This paper uses the Copula function to measure the nonlinear relationships and trend correlations between meteorological variables and photovoltaic power generation, which not only reduces the sample size but also improves prediction accuracy.
- (2)
- The combination of the RNN and cosine self-attention fully utilizes the advantages of both. The RNN is good at handling dependency relationships in sequential data, while cosine self-attention can better capture global information and long-distance dependencies. The self-attention mechanism uses cosine similarity instead of the dot product as the measure of self-attention, which can better capture similarities in time-series data. Finally, after integrating multiple feature representations and inputting them into the Transformer model, the powerful feature extraction and sequence processing capabilities of the Transformer can be fully utilized to further enhance prediction performance.
- (3)
- Through comparative experiments, the predictive performance of the proposed photovoltaic power prediction model, CA-Transformer, based on the Copula function is demonstrated, and the predictive performance is intuitively displayed, proving the effectiveness of the proposed method.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| PV | Photovoltaic |
| NWP | Numerical weather prediction |
| MC | Markov chain |
| AR | Autoregressive |
| AI | Artificial intelligence |
| SVM | Support vector machine |
| RF | Random forest |
| RNN | Recurrent neural network |
| LSTM | Short-term memory |
| CNN | Convolutional neural network |
| GRU | Gated recurrent unit |
| NLP | Natural Language Processing |
| CA-Transformer | CNN-CosAttention-Transformer |
| 1D-CNN | One-dimensional convolutional neural network |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| R-Square |
References
- International Renewable Energy Agency. Available online: https://www.irena.org/Energy-Transition/Technology/Solar-energy (accessed on 20 February 2023).
- International Energy Agency. Available online: https://www.iea.org/reports/solar-pv (accessed on 20 February 2023).
- Zhou, Y. Artificial intelligence in renewable systems for transformation towards intelligent buildings. Energy AI 2022, 10, 100182. [Google Scholar] [CrossRef]
- Al-Shetwi, A.Q.; Hannan, M.A.; Jern, K.P.; Mansur, M.; Mahlia, T.M.I. Grid-connected renewable energy sources: Review of the recent integration requirements and control methods. J. Clean. Prod. 2020, 253, 17. [Google Scholar] [CrossRef]
- Blaga, R.; Sabadus, A.; Stefu, N.; Dughir, C.; Paulescu, M.; Badescu, V. A current perspective on the accuracy of incoming solar energy forecasting. Prog. Energy Combust. Sci. 2019, 70, 119–144. [Google Scholar] [CrossRef]
- Viscondi, G.D.; Alves-Souza, S.N. A Systematic Literature Review on big data for solar photovoltaic electricity generation forecasting. Sustain. Energy Technol. Assess. 2019, 31, 54–63. [Google Scholar] [CrossRef]
- Sobri, S.; Koohi-Kamali, S.; Abd Rahim, N. Solar photovoltaic generation forecasting methods: A review. Energy Convers. Manag. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Wang, F.; Lu, X.X.; Mei, S.W.; Su, Y.; Zhen, Z.; Zou, Z.B.; Zhang, X.M.; Yin, R.; Dui, N.; Khah, M.S.; et al. A satellite image data based ultra-short-term solar PV power forecasting method considering cloud information from neighboring plant. Energy 2022, 238, 16. [Google Scholar] [CrossRef]
- Markovics, D.; Mayer, M.J. Comparison of machine learning methods for photovoltaic power forecasting based on numerical weather prediction. Renew. Sustain. Energy Rev. 2022, 161, 17. [Google Scholar] [CrossRef]
- Korkmaz, D. SolarNet: A hybrid reliable model based on convolutional neural network and variational mode decomposition for hourly photovoltaic power forecasting. Appl. Energy 2021, 300, 20. [Google Scholar] [CrossRef]
- VanDeventer, W.; Jamei, E.; Thirunavukkarasu, G.S.; Seyedmahmoudian, M.; Soon, T.K.; Horan, B.; Mekhilef, S.; Stojcevski, A. Short-term PV power forecasting using hybrid GASVM technique. Renew. Energy 2019, 140, 367–379. [Google Scholar] [CrossRef]
- Lima, M.; Carvalho, P.C.M.; Fernández-Ramírez, L.M.; Braga, A.P.S. Improving solar forecasting using Deep Learning and Portfolio Theory integration. Energy 2020, 195, 14. [Google Scholar] [CrossRef]
- Lopes, F.M.; Silva, H.G.; Salgado, R.; Cavaco, A.; Canhoto, P.; Collares-Pereira, M. Short-term forecasts of GHI and DNI for solar energy systems operation: Assessment of the ECMWF integrated forecasting system in southern Portugal. Sol. Energy 2018, 170, 14–30. [Google Scholar] [CrossRef]
- Sweeney, C.; Bessa, R.J.; Browell, J.; Pinson, P. The future of forecasting for renewable energy. Wiley Interdiscip. Rev. Energy Environ. 2020, 9, 18. [Google Scholar] [CrossRef]
- Halabi, L.M.; Mekhilef, S.; Hossain, M. Performance evaluation of hybrid adaptive neuro-fuzzy inference system models for predicting monthly global solar radiation. Appl. Energy 2018, 213, 247–261. [Google Scholar] [CrossRef]
- Hou, W.; Xiao, J.; Niu, L. Analysis of power generation capacity of photovoltaic power. Electr. Eng. 2016, 17, 53–58. [Google Scholar]
- Miao, S.; Ning, G.; Gu, Y.; Yan, J.; Ma, B. Markov Chain model for solar farm generation and its application to generation performance evaluation. J. Clean. Prod. 2018, 186, 905–917. [Google Scholar] [CrossRef]
- Massidda, L.; Marrocu, M. Use of Multilinear Adaptive Regression Splines and numerical weather prediction to forecast the power output of a PV plant in Borkum, Germany. Sol. Energy 2017, 146, 141–149. [Google Scholar] [CrossRef]
- Agoua, X.G.; Girard, R.; Kariniotakis, G. Short-Term Spatio-Temporal Forecasting of Photovoltaic Power Production. IEEE Trans. Sustain. Energy 2018, 9, 538–546. [Google Scholar] [CrossRef]
- Ibrahim, M.S.; Dong, W.; Yang, Q. Machine learning driven smart electric power systems: Current trends and new perspectives. Appl. Energy 2020, 272, 19. [Google Scholar] [CrossRef]
- Hossain, M.; Mekhilef, S.; Danesh, M.; Olatomiwa, L.; Shamshirband, S. Application of extreme learning machine for short term output power forecasting of three grid-connected PV systems. J. Clean. Prod. 2017, 167, 395–405. [Google Scholar] [CrossRef]
- Tso, G.K.F.; Yau, K.K.W. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Barman, M.; Choudhury, N.B.D. Season specific approach for short-term load forecasting based on hybrid FA-SVM and similarity concept. Energy 2019, 174, 886–896. [Google Scholar] [CrossRef]
- Massaoudi, M.; Chihi, I.; Sidhom, L.; Trabelsi, M.; Refaat, S.S.; Oueslati, F.S. Enhanced Random Forest Model for Robust Short-Term Photovoltaic Power Forecasting Using Weather Measurements. Energies 2021, 14, 3992. [Google Scholar] [CrossRef]
- Niu, D.X.; Wang, K.K.; Sun, L.J.; Wu, J.; Xu, X.M. Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD: A case study. Appl. Soft Comput. 2020, 93, 14. [Google Scholar] [CrossRef]
- Antonanzas, J.; Pozo-Vázquez, D.; Fernandez-Jimenez, L.A.; Martinez-de-Pison, F.J. The value of day-ahead forecasting for photovoltaics in the Spanish electricity market. Sol. Energy 2017, 158, 140–146. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Gao, M.; Li, J.; Hong, F.; Long, D. Day-ahead power forecasting in a large-scale photovoltaic plant based on weather classification using LSTM. Energy 2019, 187, 115838. [Google Scholar] [CrossRef]
- Agga, A.; Abbou, A.; Labbadi, M.; El Houm, Y. Short-term self consumption PV plant power production forecasts based on hybrid CNN-LSTM, ConvLSTM models. Renew. Energy 2021, 177, 101–112. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, Y.; Leng, M.; Yang, X.; Zhou, Q. LOWESS smoothing and Random Forest based GRU model: A short-term photovoltaic power generation forecasting method. Energy 2022, 256, 124661. [Google Scholar] [CrossRef]
- Zhen, H.; Niu, D.; Wang, K.; Shi, Y.; Ji, Z.; Xu, X. Photovoltaic power forecasting based on GA improved Bi-LSTM in microgrid without meteorological information. Energy 2021, 231, 120908. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999. [Google Scholar]
- Zhao, Z.; Xia, C.; Chi, L.; Chang, X.; Li, W.; Yang, T.; Zomaya, A.Y. Short-Term Load Forecasting Based on the Transformer Model. Information 2021, 12, 516. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Copula | Functional Form | Parameters |
|---|---|---|
| Normal | ||
| T | ||
| Frank | ||
| Clayton | ||
| Gumbel |
| Meteorological Factors | Normal Copula | t-Copula | Gumbel Copula | Clayton Copula | Frank Copula |
|---|---|---|---|---|---|
| Global horizontal radiation | 148.3 | 112.9 | 175.4 | 132.1 | 48.79 |
| Wind speed | 39.20 | 23.25 | 71.28 | 28.19 | 9.558 |
| Temperature | 16.83 | 22.85 | 9.293 | 49.35 | 28.60 |
| Wind direction | 31.57 | 22.60 | 113.7 | 113.7 | 24.43 |
| Max wind speed | 55.99 | 35.69 | 89.80 | 47.12 | 13.05 |
| Air pressure | 18.44 | 23.49 | 33.30 | 33.30 | 18.59 |
| pyranometer value | 175.1 | 136.2 | 213.2 | 133.0 | 61.27 |
| device temperature 1 | 27.12 | 17.03 | 24.53 | 127.5 | 13.93 |
| device temperature 2 | 34.14 | 22.66 | 28.53 | 132.08 | 17.74 |
| Meteorological Factors | Kendall | Spearman |
|---|---|---|
| Global horizontal radiation | 0.7269 | 0.9065 |
| Wind speed | 0.3577 | 0.5172 |
| Temperature | 0.3359 | 0.4801 |
| Wind direction | −0.1649 | −0.2405 |
| Max wind speed | 0.4128 | 0.5889 |
| Air pressure | −0.1121 | −0.1675 |
| Pyranometer value | 0.7168 | 0.8995 |
| Device temperature 1 | 0.5559 | 0.7564 |
| Device temperature 2 | 0.5538 | 0.7542 |
| Model | RMSE | MAE | R2 |
|---|---|---|---|
| CA-Transformer | 39.78 | 23.63 | 0.9512 |
| Transformer | 43.18 | 26.55 | 0.9426 |
| LSTM | 42.15 | 24.13 | 0.9453 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Fu, Z.; Lang, C.; Li, W.; Tao, Q.; Wang, B. Short-Term Photovoltaic Power Generation Prediction Based on Copula Function and CNN-CosAttention-Transformer. Sustainability 2024, 16, 5940. https://doi.org/10.3390/su16145940
Hu K, Fu Z, Lang C, Li W, Tao Q, Wang B. Short-Term Photovoltaic Power Generation Prediction Based on Copula Function and CNN-CosAttention-Transformer. Sustainability. 2024; 16(14):5940. https://doi.org/10.3390/su16145940
Chicago/Turabian StyleHu, Keyong, Zheyi Fu, Chunyuan Lang, Wenjuan Li, Qin Tao, and Ben Wang. 2024. "Short-Term Photovoltaic Power Generation Prediction Based on Copula Function and CNN-CosAttention-Transformer" Sustainability 16, no. 14: 5940. https://doi.org/10.3390/su16145940