
Sustainable Brand Reputation: Evaluation of iPhone Customer Reviews with Machine Learning and Sentiment Analysis


Abstract
:1. Introduction
2. Literature
3. Materials and Methods
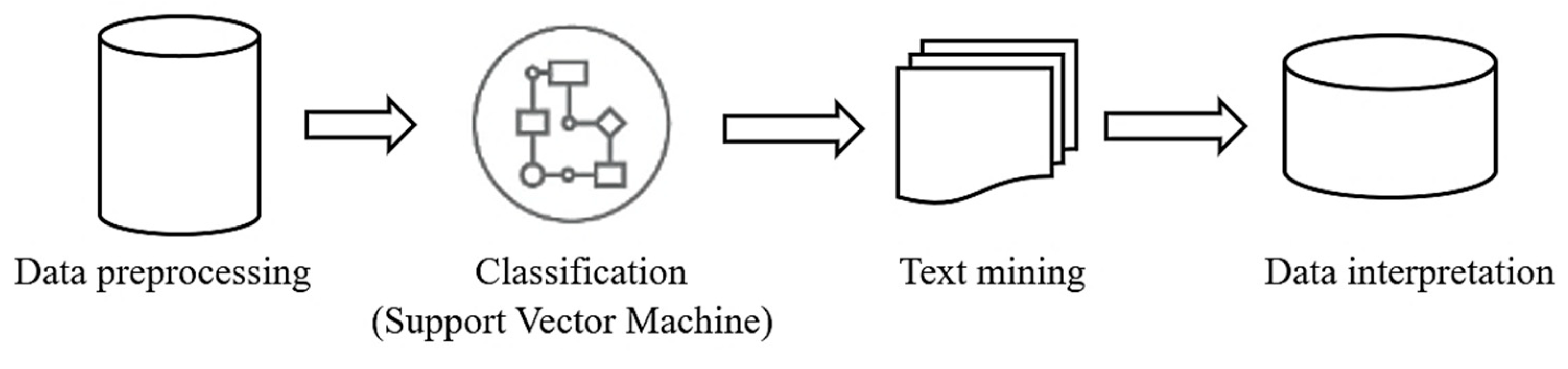
3.1. Data Collection
3.2. Data Pre-Processing
3.3. Text Mining
3.3.1. Feature Extraction
3.3.2. Term Weighting
3.4. Machine Learning
Support Vector Machines
3.5. Sentiment Analysis
3.6. Brand Reputation
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- De Chernatony, L. Brand management through narrowing the gap between brand identity and brand reputation. J. Mark. Manag. 1999, 15, 157–179. [Google Scholar] [CrossRef]
- Forman, J.; Argenti, P.A. How corporate communication influences strategy implementation, reputation and the corporate brand: An exploratory qualitative study. Corp. Reput. Rev. 2005, 8, 245–264. [Google Scholar] [CrossRef]
- Dhaoui, C.; Webster, C.M.; Tan, L.P. Social media sentiment analysis: Lexicon versus machine learning. J. Consum. Mark. 2017, 34, 480–488. [Google Scholar] [CrossRef]
- He, W.; Zhang, W.; Tian, X.; Tao, R.; Akula, V. Identifying customer knowledge on social media through data analytics. J. Enterp. Inf. Manag. 2019, 32, 152–169. [Google Scholar] [CrossRef]
- Hassani, H.; Beneki, C.; Unger, S.; Mazinani, M.T.; Yeganegi, M.R. Text mining in big data analytics. Big Data Cogn. Comput. 2020, 4, 1. [Google Scholar] [CrossRef]
- Rust, R.T.; Rand, W.; Huang, M.H.; Stephen, A.T.; Brooks, G.; Chabuk, T. Real-time brand reputation tracking using social media. J. Mark. 2021, 85, 21–43. [Google Scholar] [CrossRef]
- Mousavi, R.; Johar, M.; Mookerjee, V.S. The voice of the customer: Managing customer care in Twitter. Inf. Syst. Res. 2020, 31, 340–360. [Google Scholar] [CrossRef]
- Trendyol. Whoweare. 2024. Available online: https://www.trendyol.com/whoweare (accessed on 13 June 2024).
- FastCompanyTurkey. Turkey’s Top 100 Internet Companies. 2024. Available online: https://fastcompany.com.tr/dergi/turkiyenin-en-buyuk-100-internet-sirketi-2023/ (accessed on 11 July 2024).
- Loureiro, S.M.C.; Sarmento, E.M.; Bellego, L.G. The effect of corporate brand reputation on brand attachment and brand loyalty: Automobile sector. Cogent Bus. Manag. 2017, 4, 1360031. [Google Scholar] [CrossRef]
- Greyser, S.A. Corporate brand reputation and brand crisis management. Manag. Decis. 2009, 47, 590–602. [Google Scholar] [CrossRef]
- Vidya, N.A.; Fanany, M.I.; Budi, I. Twitter sentiment to analyze net brand reputation of mobile phone providers. Procedia Comput. Sci. 2015, 72, 519–526. [Google Scholar] [CrossRef]
- Sharma, S.K.; Daga, M.; Gemini, B. Twitter sentiment analysis for brand reputation of smart phone companies in India. In Proceedings of ICETIT 2019: Emerging Trends in Information Technology; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Isah, H.; Trundle, P.; Neagu, D. Social media analysis for product safety using text mining and sentiment analysis. In Proceedings of the 2014 14th UK Workshop on Computational Intelligence (UKCI), Bradford, UK, 8–10 September 2014. [Google Scholar]
- Li, L.; Goh, T.T.; Jin, D. How textual quality of online reviews affect classification performance: A case of deep learning sentiment analysis. Neural Comput. Appl. 2020, 32, 4387–4415. [Google Scholar] [CrossRef]
- Mostafa, L. Machine learning-based sentiment analysis for analyzing the travelers reviews on Egyptian hotels. In The International Conference on Artificial Intelligence and Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Hossain, M.S.; Rahman, M.F. Customer sentiment analysis and prediction of insurance products’ reviews using machine learning approaches. FIIB Bus. Rev. 2023, 12, 386–402. [Google Scholar] [CrossRef]
- Rasool, A.; Tao, R.; Marjan, K.; Naveed, T. Twitter sentiment analysis: A case study for apparel brands. J. Phys. Conf. Ser. 2019, 1176, 022015. [Google Scholar] [CrossRef]
- Loukili, M.; Messaoudi, F.; El Ghazi, M. Sentiment analysis of product reviews for e-commerce recommendation based on machine learning. Int. J. Adv. Soft Comput. Its Appl. 2023, 15, 1. [Google Scholar]
- Ahmad, S.; Tyagi, N.; Chandra, U.; Maaz, M. Sentiment Analysis Evaluating Net Brand Reputation of Mobile Phones Using Polarity. In Proceedings of the 2018 Fifth International Conference on Parallel, Distributed and Grid Computing (PDGC), Solan, India, 20–22 December 2018. [Google Scholar]
- CIRP. CIRP—Apple Report. 2024. Available online: https://cirpapple.substack.com/p/iphone-owners-keep-phones-longer (accessed on 11 July 2024).
- Statista. iPhone—Statistics & Facts. 2024. Available online: https://www.statista.com/topics/870/iphone/ (accessed on 11 July 2024).
- Keys, B. Brand Keys Loyalty Leaders 2022 Survey. 2022. Available online: https://brandkeys.com/wp-content/uploads/2020/11/PRESS-RELEASE-2022-Loyalty-Leaders-List.pdf (accessed on 11 July 2024).
- Mickalowski, K.; Mickelson, M.; Keltgen, J. Apple’s iPhone launch: A case study in effective marketing. Bus. Rev. 2008, 9, 283–288. [Google Scholar]
- Statcounter. Mobile Vendor Market Share Turkey. 2024. Available online: https://gs.statcounter.com/vendor-market-share/mobile/turkey (accessed on 13 June 2024).
- Abbasi, A.; Chen, H.; Salem, A. Sentiment analysis in multiple languages: Feature selection for opinion classification in web forums. ACM Trans. Inf. Syst. (TOIS) 2008, 26, 1–34. [Google Scholar] [CrossRef]
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2013, 26, 97–107. [Google Scholar]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Baek, S.; Jung, W.; Han, S.H. A critical review of text-based research in construction: Data source, analysis method, and implications. Autom. Constr. 2021, 132, 103915. [Google Scholar] [CrossRef]
- Jiang, J.; Zhai, C. An empirical study of tokenization strategies for biomedical information retrieval. Inf. Retr. 2007, 10, 341–363. [Google Scholar] [CrossRef]
- Chai, C.P. Comparison of text preprocessing methods. Nat. Lang. Eng. 2023, 29, 509–553. [Google Scholar] [CrossRef]
- Joshi, R.M.; Treiman, R.; Carreker, S.; Moats, L.C. How words cast their spell. Am. Educ. 2008, 32, 6–16. [Google Scholar]
- Stamatatos, E. Plagiarism detection using stopword n-grams. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 2512–2527. [Google Scholar] [CrossRef]
- Khyani, D.; Siddhartha, B.S.; Niveditha, N.M.; Divya, B.M. An interpretation of lemmatization and stemming in natural language processing. J. Univ. Shanghai Sci. Technol. 2021, 22, 350–357. [Google Scholar]
- Yazdani, A.; Safdari, R.; Golkar, A.; Niakan Kalhori, R. Words prediction based on N-gram model for free-text entry in electronic health records. Health Inf. Sci. Syst. 2019, 7, 6. [Google Scholar] [CrossRef] [PubMed]
- Kayakuş, M.; Yiğit Açıkgöz, F. Classification of news texts by categories using machine learning methods. Alphanumeric J. 2022, 10, 155–166. [Google Scholar] [CrossRef]
- Kayakuş, M.; Yiğit Açıkgöz, F. Fake News Detection on Twitter with Machine Learning Methods. J. Abant Soc. Sci. 2023, 23, 1017–1027. [Google Scholar]
- Hotho, A.; Nürnberger, A.; Paaß, G. A brief survey of text mining. J. Lang. Technol. Comput. Linguist. 2005, 20, 19–62. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Hira, Z.M.; Gillies, D.F. A review of feature selection and feature extraction methods applied on microarray data. Adv. Bioinform. 2015, 2015, 198363. [Google Scholar] [CrossRef] [PubMed]
- Liebeskind, C.; Dagan, I.; Schler, J. Semiautomatic construction of cross-period thesaurus. J. Comput. Cult. Herit. (JOCCH) 2016, 9, 1–26. [Google Scholar] [CrossRef]
- Doval, Y.; Gómez-Rodríguez, C. Comparing neural-and N-gram-based language models for word segmentation. J. Assoc. Inf. Sci. Technol. 2019, 70, 187–197. [Google Scholar] [CrossRef] [PubMed]
- García, M.; Maldonado, S.; Vairetti, C. Efficient n-gram construction for text categorization using feature selection techniques. Intell. Data Anal. 2021, 25, 509–525. [Google Scholar] [CrossRef]
- Yamamoto, M.; Church, K.W. Using suffix arrays to compute term frequency and document frequency for all substrings in a corpus. Comput. Linguist. 2001, 27, 1–30. [Google Scholar] [CrossRef]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF* IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Srinivasan, P. A comparison of two-poisson, inverse document frequency and discrimination value models of document representation. Inf. Process. Manag. 1990, 26, 269–278. [Google Scholar] [CrossRef]
- Kim, S.-W.; Gil, J.-M. Research paper classification systems based on TF-IDF and LDA schemes. Hum.-Centric Comput. Inf. Sci. 2019, 9, 30. [Google Scholar] [CrossRef]
- Yetiz, F.; Terzioğlu, M.; Kayakuş, M. An Analysis of Turkish Deposit Banks’ Customer Forecasting with Machine Learning Methods. Sosyoekonomi 2021, 29, 413–432. [Google Scholar] [CrossRef]
- Kayakuş, M. The Estimation of Turkey’s Energy Demand Through Artificial Neural Networks and Support Vector Regression Methods. Alphanumeric J. 2020, 8, 227–236. [Google Scholar] [CrossRef]
- Erdoğan, H.; Terzioğlu, M.; Kayakuş, M. Forecasting the Number of Tourists Coming to Turkey for Accommodation from Germany Using Artificial Intelligence Techniques. Eur. J. Sci. Technol. 2021, 27, 961–971. [Google Scholar]
- Roy, A.; Chakraborty, S. Support vector machine in structural reliability analysis: A review. Reliab. Eng. Syst. Saf. 2023, 233, 109126. [Google Scholar] [CrossRef]
- Elizondo, D. The linear separability problem: Some testing methods. IEEE Trans. Neural Netw. 2006, 17, 330–344. [Google Scholar] [CrossRef] [PubMed]
- Suykens, J.A. Support vector machines: A nonlinear modelling and control perspective. Eur. J. Control 2001, 7, 311–327. [Google Scholar] [CrossRef]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Sadegh, M.; Ibrahim, R.; Othman, Z.A. Opinion mining and sentiment analysis: A survey. Int. J. Comput. Technol. 2012, 2, 171–178. [Google Scholar]
- Liu, B. Sentiment analysis and subjectivity. Handb. Nat. Lang. Process. 2010, 2, 627–666. [Google Scholar]
- Hemmatian, F.; Sohrabi, M.K. A survey on classification techniques for opinion mining and sentiment analysis. Artif. Intell. Rev. 2019, 52, 1495–1545. [Google Scholar] [CrossRef]
- Min, W.N.S.W.; Zulkarnain, N.Z. Comparative evaluation of lexicons in performing sentiment analysis. J. Adv. Comput. Technol. Appl. (JACTA) 2020, 2, 14–20. [Google Scholar]
- Dowling, G.R. Corporate reputations: Should you compete on yours? Calif. Manag. Rev. 2004, 46, 19–36. [Google Scholar] [CrossRef]
- Shamma, H.M.; Hassan, S.S. Customer and non-customer perspectives for examining corporate reputation. J. Prod. Brand Manag. 2009, 18, 326–337. [Google Scholar] [CrossRef]
- Chun, R. Corporate reputation: Meaning and measurement. Int. J. Manag. Rev. 2005, 7, 91–109. [Google Scholar] [CrossRef]
- Walsh, G.; Beatty, S.E. Customer-based corporate reputation of a service firm: Scale development and validation. J. Acad. Mark. Sci. 2007, 35, 127–143. [Google Scholar] [CrossRef]
- Zaichkowsky, J.L.; Parlee, M.; Hill, J. Managing industrial brand equity: Developing tangible benefits for intangible assets. Ind. Mark. Manag. 2010, 39, 776–783. [Google Scholar] [CrossRef]
- Guzman, F. A brand building literature review. ICFAI J. Brand Manag. 2005, 2, 30–48. [Google Scholar]
- Tingchi Liu, M.; Anthony Wong, I.; Shi, G.; Chu, R.; Brock, J.L. The impact of corporate social responsibility (CSR) performance and perceived brand quality on customer-based brand preference. J. Serv. Mark. 2014, 28, 181–194. [Google Scholar] [CrossRef]
- Park, C.W.; Jaworski, B.J.; MacInnis, D.J. Strategic brand concept-image management. J. Mark. 1986, 50, 135–145. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I liked it very well |
| I liked it very much, you can buy it with peace of mind, it is perfect, everything came in perfect condition, and it is original with warranty, approved from the iPhone website, I recommend it, it is perfect. |
| The product arrived without any problems, the shipping was fast, the packaging was good. Thanks to the seller and the cargo company |
| It arrived without any problems; it arrived well wrapped and the shipping was fast. |
| It came to me quickly and securely. Thank you trendyol… |
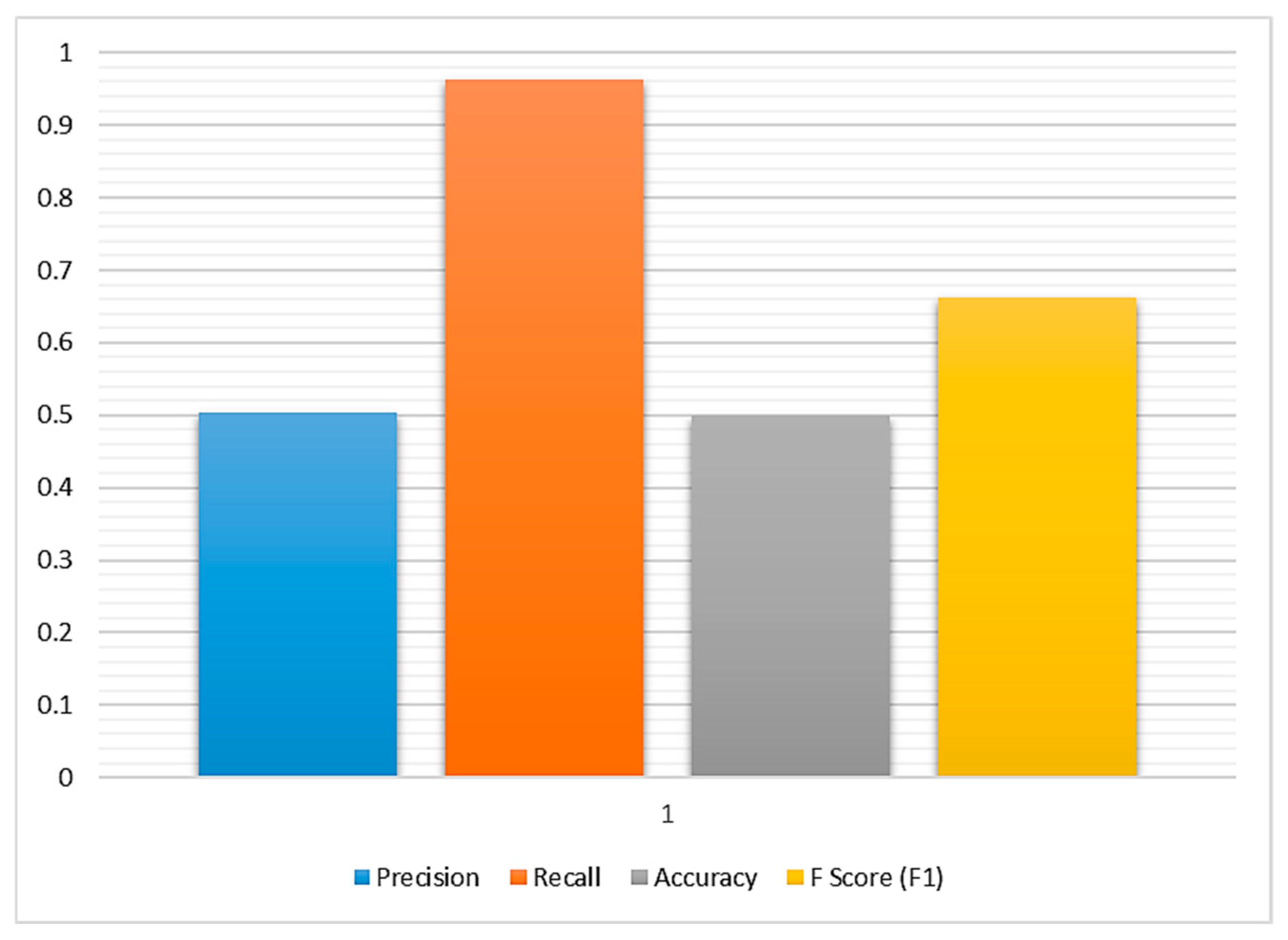
| Precision | Recall | Accuracy | F Score (F1) |
|---|---|---|---|
| 0.504 | 0.963 | 0.500 | 0.662 |
| Emotion Status | Number of Comments |
|---|---|
| Positive | 8547 |
| Negative | 1299 |
| Neutral | 154 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kayakuş, M.; Yiğit Açikgöz, F.; Dinca, M.N.; Kabas, O. Sustainable Brand Reputation: Evaluation of iPhone Customer Reviews with Machine Learning and Sentiment Analysis. Sustainability 2024, 16, 6121. https://doi.org/10.3390/su16146121
Kayakuş M, Yiğit Açikgöz F, Dinca MN, Kabas O. Sustainable Brand Reputation: Evaluation of iPhone Customer Reviews with Machine Learning and Sentiment Analysis. Sustainability. 2024; 16(14):6121. https://doi.org/10.3390/su16146121
Chicago/Turabian StyleKayakuş, Mehmet, Fatma Yiğit Açikgöz, Mirela Nicoleta Dinca, and Onder Kabas. 2024. "Sustainable Brand Reputation: Evaluation of iPhone Customer Reviews with Machine Learning and Sentiment Analysis" Sustainability 16, no. 14: 6121. https://doi.org/10.3390/su16146121