
Regional Truck Travel Characteristics Analysis and Freight Volume Estimation: Support for the Sustainable Development of Freight


Abstract
:1. Introduction
2. Data Characteristics
3. Data Processing
4. Methodology
4.1. Travel Chain Identification
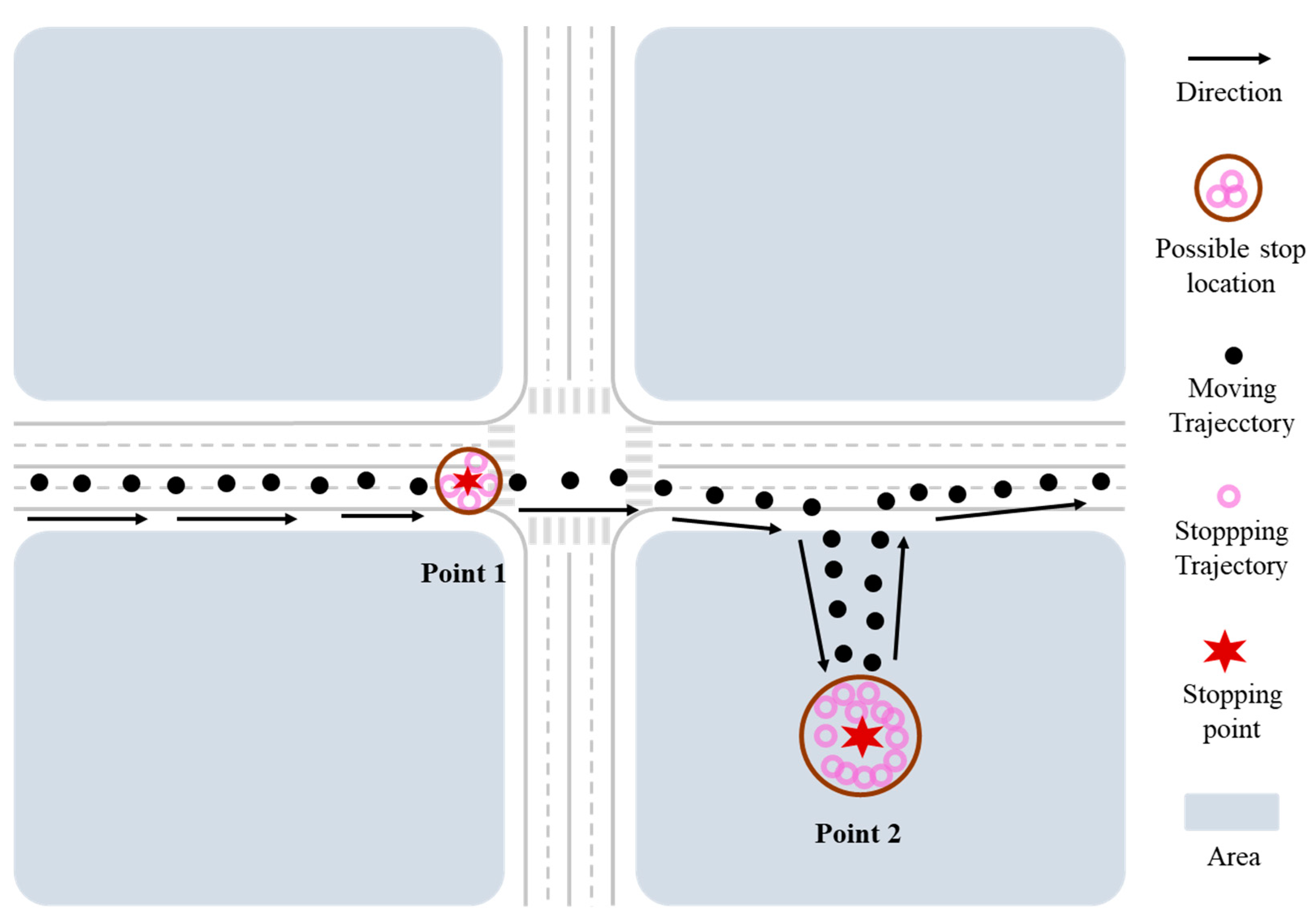
4.1.1. Stopping Point Identification
4.1.2. Trip Identification
4.2. Trip Chain Expansion
4.3. Freight Volume Estimation
5. Results and Discussion
5.1. Truck Travel Characteristics
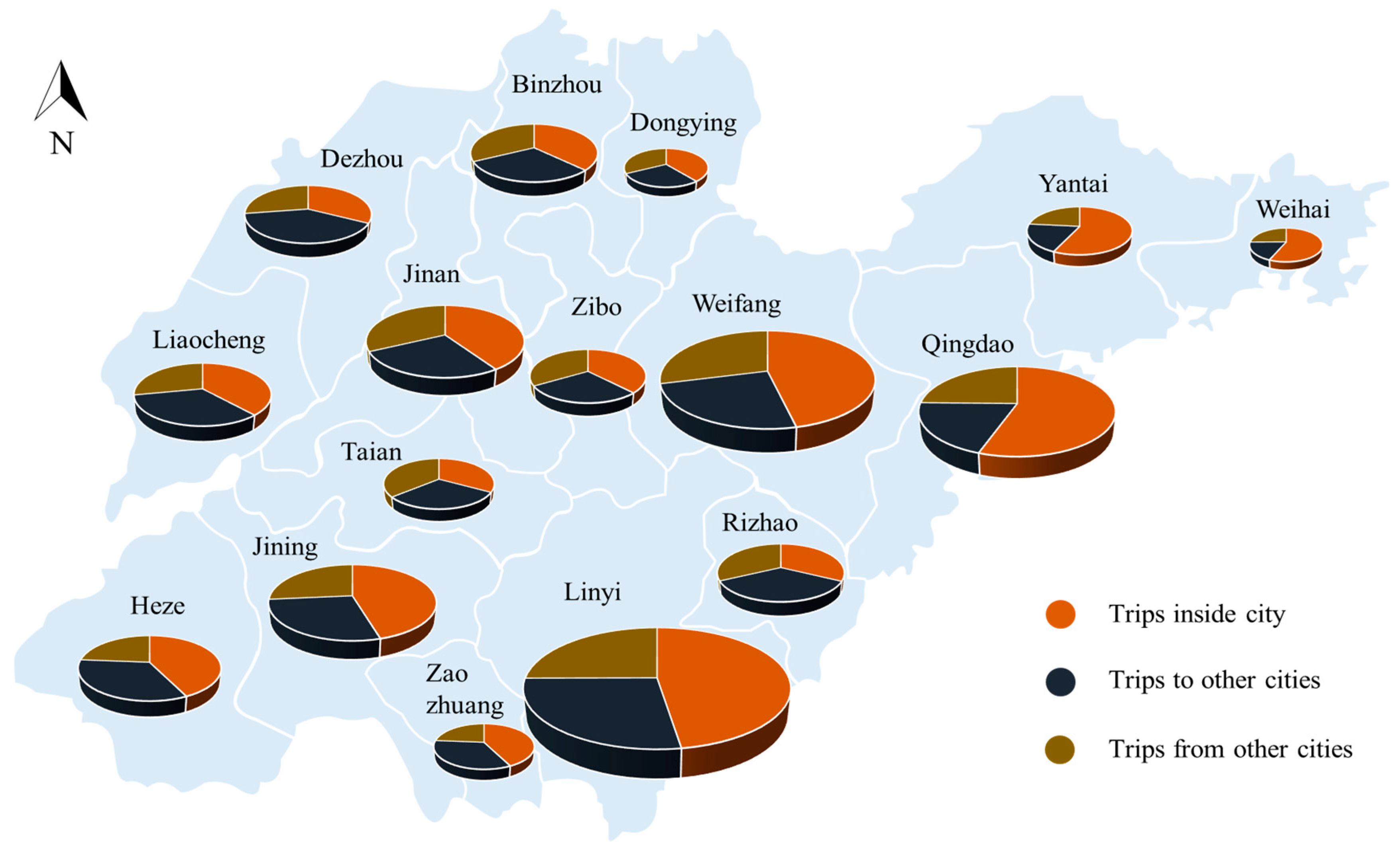
5.2. Analysis of Inter-City Freight Volumes
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Flamini, M.; Nigro, M.; Pacciarelli, D. The value of real-time traffic information in urban freight distribution. J. Intell. Transp. Syst. 2018, 22, 26–39. [Google Scholar] [CrossRef]
- Balla, B.S.; Sahu, P.K. Assessing regional transferability and updating of freight generation models to reduce sample size requirements in national freight data collection program. Transp. Res. Part APolicy Pract. 2023, 175, 103780. [Google Scholar] [CrossRef]
- Yin, C.; Zhang, Z.; Zhang, X.; Chen, J.; Tao, X.; Yang, L. Hub seaport multimodal freight transport network design: Perspective of regional integration development. Ocean Coast. Manag. 2023, 242, 106675. [Google Scholar] [CrossRef]
- Akhavan, M.; Ghiara, H.; Mariotti, I.; Sillig, C. Logistics global network connectivity and its determinants. A European City network analysis. J. Transp. Geogr. 2020, 82, 102624. [Google Scholar] [CrossRef]
- Yang, Y.; Jia, B.; Yan, X.Y.; Li, J.; Yang, Z.; Gao, Z. Identifying intercity freight trip ends of heavy trucks from GPS data. Transp. Res. Part E Logist. Transp. Rev. 2022, 157, 102590. [Google Scholar] [CrossRef]
- Cassiano, D.R.; Bertoncini, B.V.; de Oliveira, L.K. A conceptual model based on the activity system and transportation system for sustainability urban freight transport. Sustainability 2021, 13, 5642. [Google Scholar] [CrossRef]
- Nuzzolo, A.; Crisalli, U.; Comi, A. A restocking tour model for the estimation of OD freight vehicle in urban areas. Procedia-Soc. Behav. Sci. 2011, 20, 140–149. [Google Scholar] [CrossRef]
- Toilier, F.; Gardrat, M. Driver survey vs GPS Tour data: Strength and weaknesses of the two sources in order to model the drivers’ journeys. Transp. Res. Procedia 2024, 76, 169–182. [Google Scholar] [CrossRef]
- Demissie, M.G.; Kattan, L. Estimation of truck origin-destination flows using GPS data. Transp. Res. Part E Logist. Transp. Rev. 2022, 159, 102621. [Google Scholar] [CrossRef]
- Siripirote, T.; Sumalee, A.; Watling, D.P.; Shao, H. Updating of travel behavior model parameters and estimation of vehicle trip chain based on plate scanning. J. Intell. Transp. Syst. 2014, 18, 393–409. [Google Scholar] [CrossRef]
- Adam, A.; Finance, O.; Thomas, I. Monitoring trucks to reveal Belgian geographical structures and dynamics: From GPS traces to spatial interactions. J. Transp. Geogr. 2021, 91, 102977. [Google Scholar] [CrossRef]
- Van Dijk, J. Identifying activity-travel points from GPS-data with multiple moving windows. Comput. Environ. Urban Syst. 2018, 70, 84–101. [Google Scholar] [CrossRef]
- Laranjeiro, P.F.; Merchán, D.; Godoy, L.A.; Giannotti, M.; Yoshizaki, H.T.; Winkenbach, M.; Cunha, C.B. Using GPS data to explore speed patterns and temporal fluctuations in urban logistics: The case of São Paulo, Brazil. J. Transp. Geogr. 2019, 76, 114–129. [Google Scholar] [CrossRef]
- He, Z.; Zhao, P.; Xiao, Z.; Huang, X.; Li, Z.; Kang, T. Exploring the distance decay in port hinterlands under port regionalization using truck GPS data. Transp. Res. Part E Logist. Transp. Rev. 2024, 181, 103390. [Google Scholar] [CrossRef]
- Darayi, M.; Barker, K.; Nicholson, C.D. A multi-industry economic impact perspective on adaptive capacity planning in a freight transportation network. Int. J. Prod. Econ. 2019, 208, 356–368. [Google Scholar] [CrossRef]
- Chupin, A.; Morkovkin, D.; Bolsunovskaya, M.; Boyko, A.; Leksashov, A. Techno-Economic Sustainability Potential of Large-Scale Systems: Forecasting Intermodal Freight Transportation Volumes. Sustainability 2024, 16, 1265. [Google Scholar] [CrossRef]
- Jin, W.Z.; Zhang, Q. Study on Regional Freight Transportation Investigation and Statistics. J. Highw. Transp. Res. Dev. 2005, 04, 139–143. [Google Scholar]
- Müller, S.; Wolfermann, A.; Huber, S. A nation-wide macroscopic freight traffic model. Procedia-Soc. Behav. Sci. 2012, 54, 221–230. [Google Scholar] [CrossRef]
- Hassan, L.A.H.; Mahmassani, H.S.; Chen, Y. Reinforcement learning framework for freight demand forecasting to support operational planning decisions. Transp. Res. Part E Logist. Transp. Rev. 2020, 137, 101926. [Google Scholar] [CrossRef]
- Miller, S.; Vander Laan, Z.; Marković, N. Scaling GPS trajectories to match point traffic counts: A convex programming approach and Utah case study. Transp. Res. Part E Logist. Transp. Rev. 2020, 143, 102105. [Google Scholar] [CrossRef]
- Li, F.; Tu, R.; Zeng, L.; Zhang, S.; Liu, M.; Lu, X. Integrated positioning with double-differenced 5G and undifferenced/double-differenced GPS. Measurement 2023, 218, 113114. [Google Scholar] [CrossRef]
- Lyu, Z.; Pons, D.; Zhang, Y.; Ji, Z. Freight Operations Modelling for Urban Delivery and Pickup with Flexible Routing: Cluster Transport Modelling Incorporating Discrete-Event Simulation and GIS. Infrastructures. 2021, 6, 180. [Google Scholar] [CrossRef]
- Orellana, R.; Carvajal, R.; Juan, C.A. Maximum Likelihood Infinite Mixture Distribution Estimation Utilizing Finite Gaussian Mixtures—ScienceDirect. IFAC-PapersOnLine 2018, 51, 706–711. [Google Scholar] [CrossRef]
- Manole, T.; Khalili, A. Estimating the number of components in finite mixture models via the group-sort-fuse procedure. Ann. Stat. 2021, 49, 3043–3069. [Google Scholar] [CrossRef]
- Sornette, D. Critical Phenomena in Natural Sciences: Chaos, Fractals, Selforganization and Disorder: Concepts and Tools; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Marković, D.; Gros, C. Power laws and self-organized criticality in theory and nature. Phys. Rep. 2014, 536, 41–74. [Google Scholar] [CrossRef]
- Chehade, A.; Shi, Z.; Krivtsov, V. Power–law nonhomogeneous Poisson process with a mixture of latent common shape parameters. Reliab. Eng. Syst. Saf. 2020, 203, 107097. [Google Scholar] [CrossRef]
- Gingerich, K.; Maoh, H.; Anderson, W. Classifying the purpose of stopped truck events: An application of entropy to GPS data. Transp. Res. Part C: Emerg. Technol. 2016, 64, 17–27. [Google Scholar] [CrossRef]
- Łukawska, M.; Paulsen, M.; Rasmussen, T.K.; Jensen, A.F.; Nielsen, O.A. A joint bicycle route choice model for various cycling frequencies and trip distances based on a large crowdsourced GPS dataset. Transp. Res. Part A Policy Pract. 2023, 176, 103834. [Google Scholar] [CrossRef]
- Wang, G.; Qian, Y.; Kong, F.; Liu, X.; Liu, Y.; Zhu, Z.; Gao, W.; Zhang, H.; Wang, Y. Non-methane hydrocarbon characteristics and their ozone and secondary organic aerosol formation potentials and sources in the plate and logistics capital of China. Atmos. Pollut. Res. 2023, 14, 101873. [Google Scholar] [CrossRef]
- Cong, L.Z.; Zhang, D.; Wang, M.L.; Xu, H.F.; Li, L. The role of ports in the economic development of port cities: Panel evidence from China. Transp. Policy 2020, 90, 13–21. [Google Scholar] [CrossRef]
- He, Z.; Liu, Q.; Zhao, P. Challenges of passenger and freight transportation in mega-city regions: A systematic literature review. Transp. Res. Interdiscip. Perspect. 2022, 16, 100730. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Heavy Truck ID | Timestamp | Longitude | Latitude |
|---|---|---|---|
| ***** 4E | 2021-08-01 00:08:47 | 117.820335 | 36.07616 |
| ***** 4E | 2021-08-01 00:09:17 | 117.820335 | 36.07617 |
| ***** 4E | 2021-08-01 00:09:47 | 117.82033 | 36.076176 |
| ***** 4E | 2021-08-01 00:10:17 | 117.82032 | 36.076157 |
| ***** 4E | 2021-08-01 00:10:47 | 117.82033 | 36.076202 |
| Truck Type | Small Truck | Medium Truck | Large Truck | Extra-Large Truck | Container |
|---|---|---|---|---|---|
| Vehicle attributes | 2 axels maximum 18 tons | 3 axels maximum 27 tons | 4 axels maximum 36 tons | 5 axels maximum 43 tons | 6 axels maximum 49 tons |
| Percentage of truck types (%) | 25.2 | 13.2 | 14.1 | 43.4 | 4.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, S.; Gu, M.; Ou, J.; Li, Z.; Luan, S. Regional Truck Travel Characteristics Analysis and Freight Volume Estimation: Support for the Sustainable Development of Freight. Sustainability 2024, 16, 6317. https://doi.org/10.3390/su16156317
Sun S, Gu M, Ou J, Li Z, Luan S. Regional Truck Travel Characteristics Analysis and Freight Volume Estimation: Support for the Sustainable Development of Freight. Sustainability. 2024; 16(15):6317. https://doi.org/10.3390/su16156317
Chicago/Turabian StyleSun, Shuo, Mingchen Gu, Jushang Ou, Zhenlong Li, and Sen Luan. 2024. "Regional Truck Travel Characteristics Analysis and Freight Volume Estimation: Support for the Sustainable Development of Freight" Sustainability 16, no. 15: 6317. https://doi.org/10.3390/su16156317