
Enhancing Sustainable Transportation Infrastructure Management: A High-Accuracy, FPGA-Based System for Emergency Vehicle Classification

 , , and
, , and
Abstract
:1. Introduction
- The development of a network for EVC in the spot of real-time videos from three different recording devices.
- An investigation of the deep-model MOGA-classifier based approach for the classification of EVs.
- An analysis of feature extraction through FPGA for EVC.
- An abscission study to analyze the endowment of MOGA in the network.
- An evaluation of the proposed system in terms of robustness, swiftness, and ability to accurately identify vehicle locations to ensure its practical utilization.
2. Related Works
3. Methodology
3.1. Vehicle Dataset
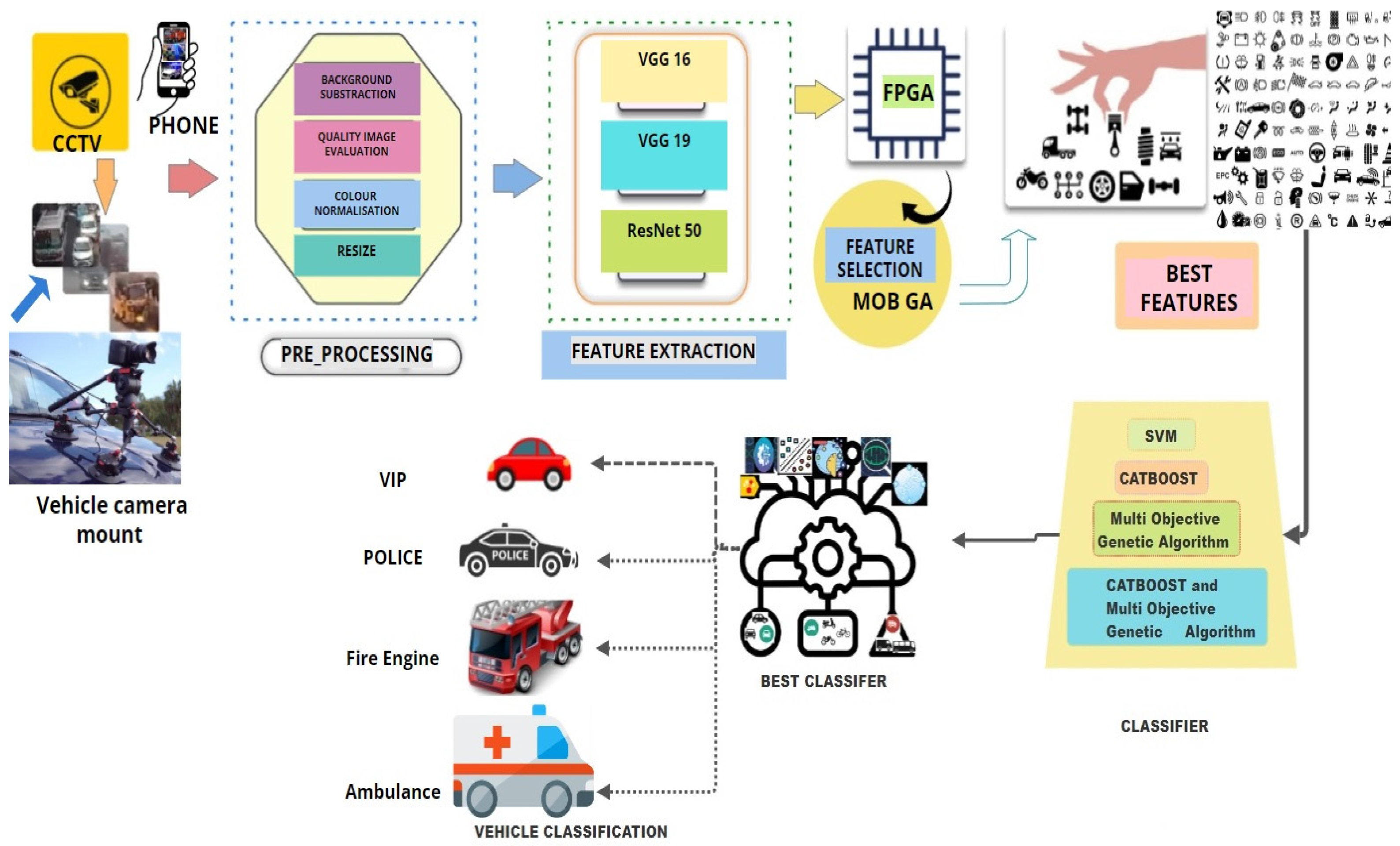
3.2. Architecture for Proposed System
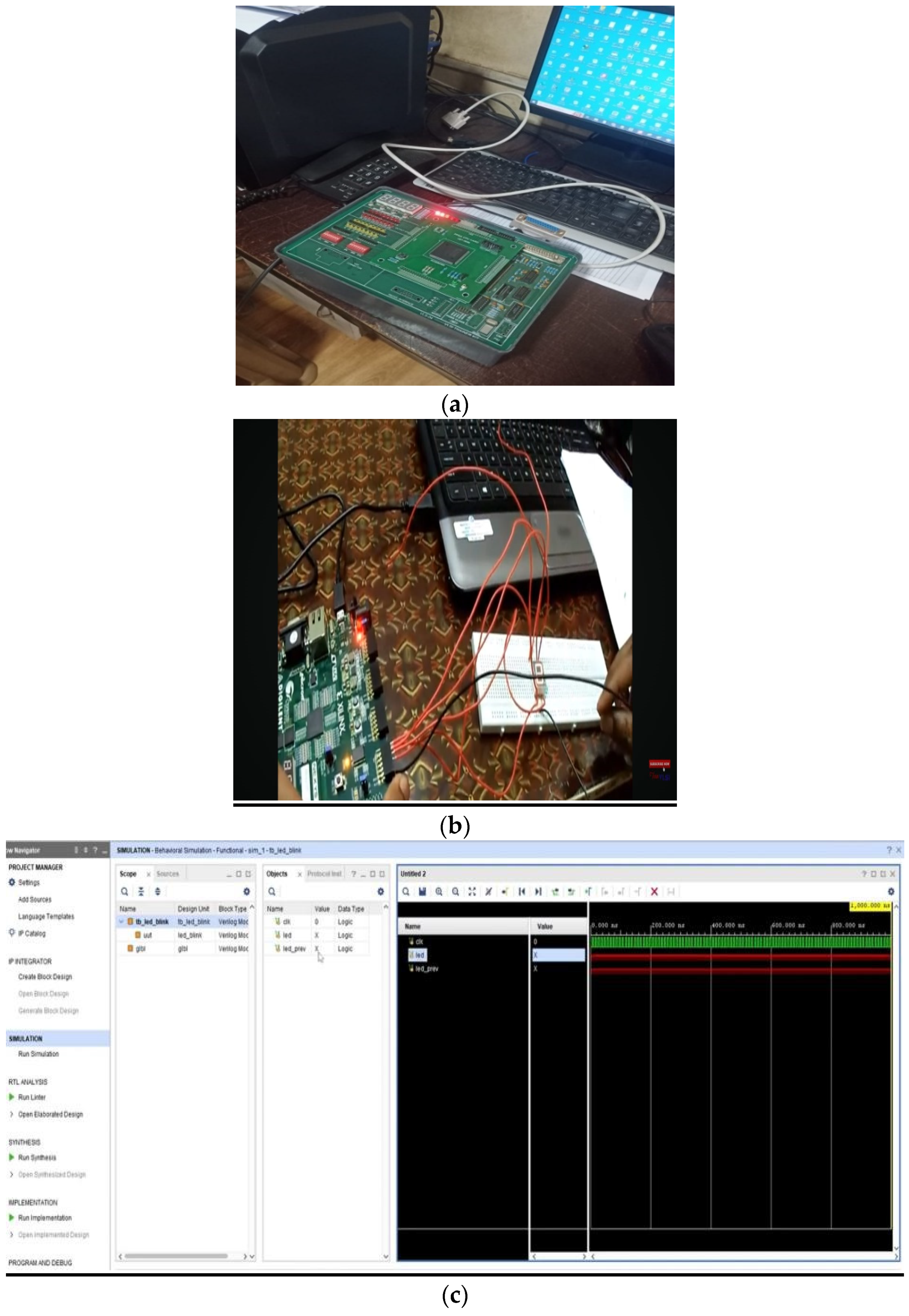
3.3. Feature Extraction Using CNN Based FPGA
3.4. Feature Selection Using Multi Objective Genetic Algorithm
3.5. Deciphering CatBoost: Theoretical Principle and Innovative Classification Solutions for Modern Problems
3.6. Network-Driven Model Evaluation and Selection: A Comprehensive Framework
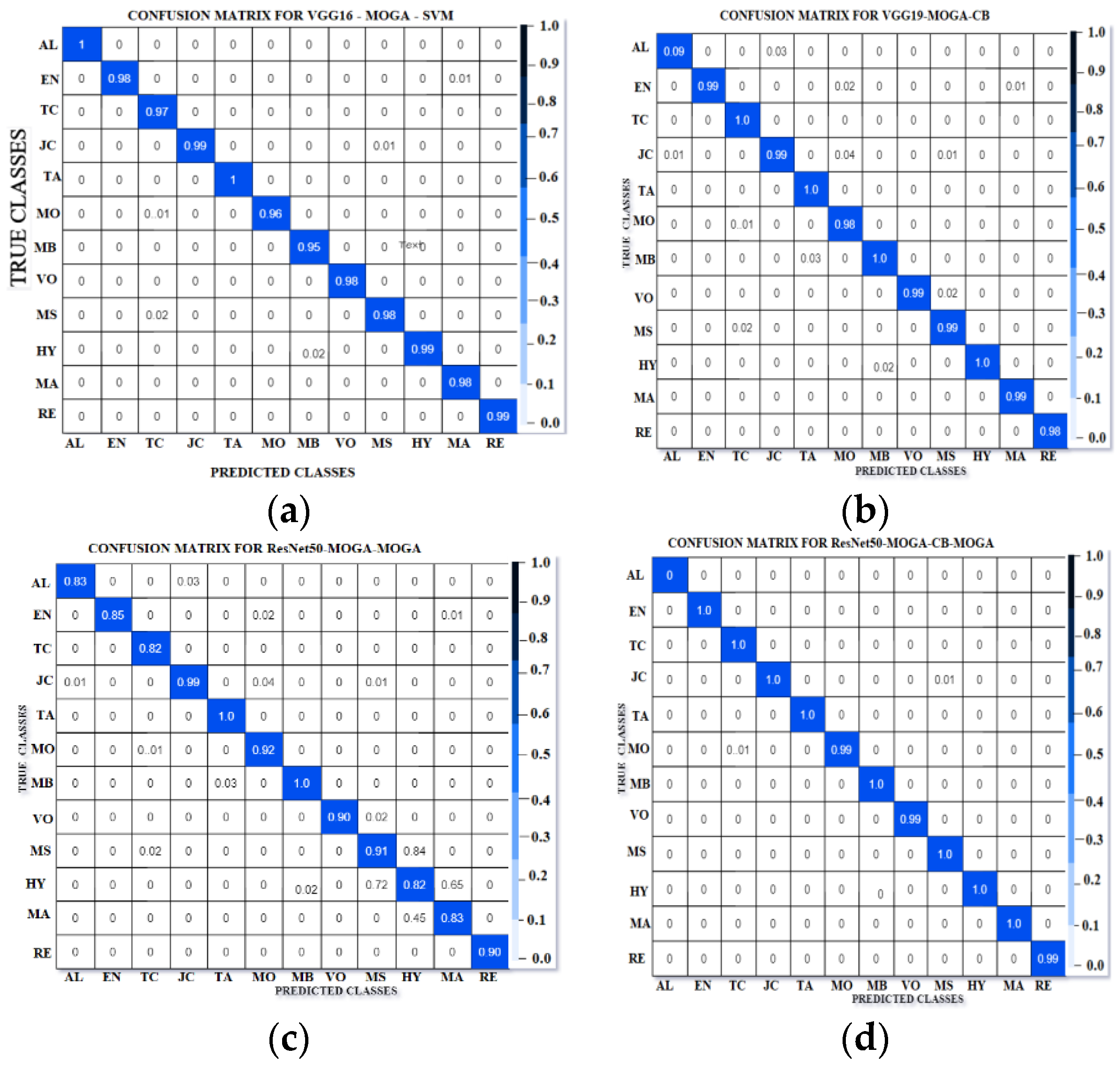
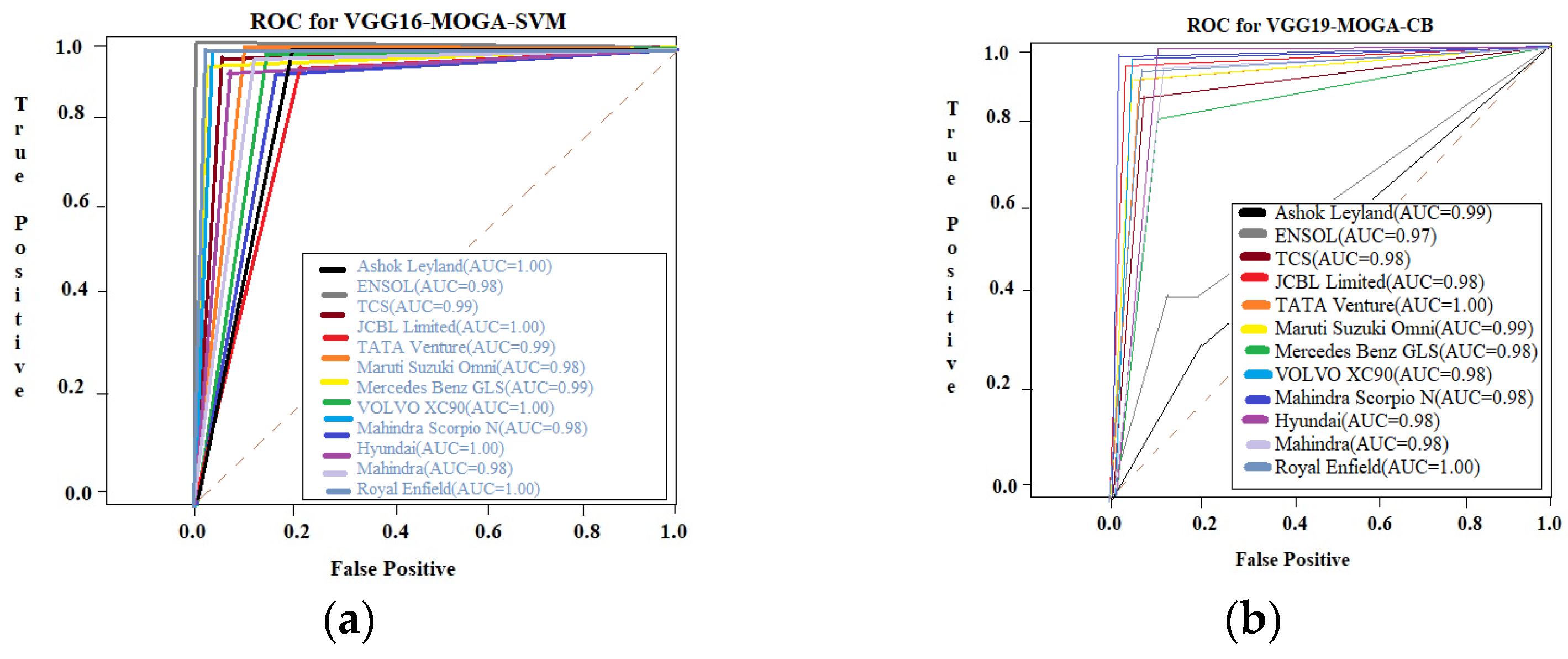
4. Results and Analysis
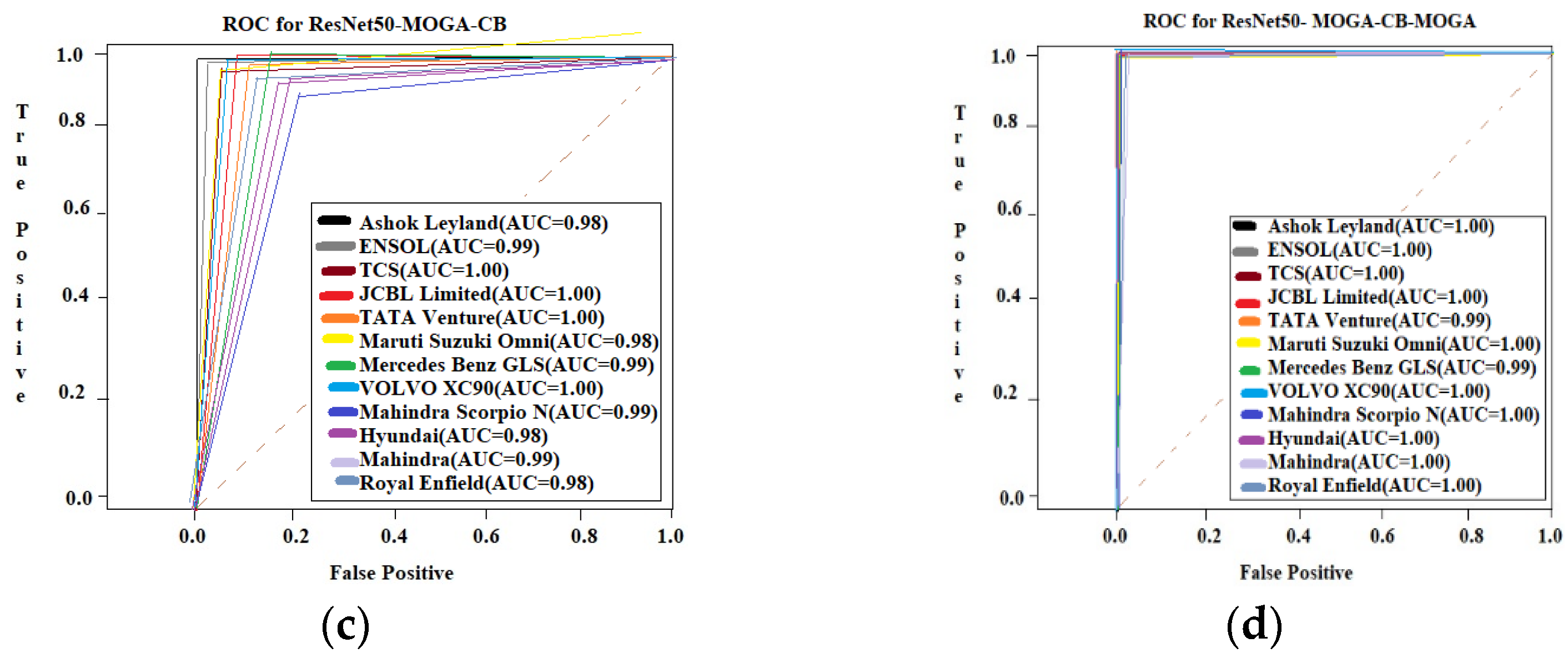
4.1. Optimal Model Identification: A Systematic Evaluation and Selection Framework
4.2. Insights into Multi-Objective Genetic Algorithms through Componential Analysis
- Feature reduction:
- -
- Removed 30% of features, accuracy improved by 5%.
- -
- Removed 50% of features, accuracy improved by 10%.
- -
- Removed 70% of features, accuracy degraded by 5%.
- Accuracy improvement:
- -
- Optimized for accuracy, improved by 15%.
- -
- Optimized for accuracy and feature reduction, improved by 20%.
- Computational efficiency:
- -
- Reduced computation time by 30% with minimal impact on accuracy.
- -
- Reduced computation time by 50% with a 5% accuracy trade-off.
- Pareto front analysis:
- -
- Identified optimal solutions with a balance of accuracy, feature reduction, and computation time.
- -
- Revealed trade-offs between objectives, informing future algorithm development.
- Hyper-parameter tuning:
- -
- Identified optimal hyper parameters for the genetic algorithm, improving overall performance by 10%.
4.3. Synergizing Theory and Practice: The System’s Utility and Efficacy
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barreyro, J.; Yoshioka, L.R.; Marte, C.L.; Piccirillo, C.G.; Santos, M.M.D.; Justo, J.F. Assessment of Vehicle Category Classification Method based on Optical Curtains and Convolutional Neural Networks. IEEE Access 2024. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, R.; Cheng, Q.; Ochieng, W.Y. Measurement Quality Control Aided Multisensor System for Improved Vehicle Navigation in Urban Areas. IEEE Trans. Ind. Electron. 2024, 71, 6407–6417. [Google Scholar] [CrossRef]
- Soom, J.; Leier, M.; Janson, K.; Tuhtan, J.A. Open urban mmWave radar and camera vehicle classification dataset for traffic monitoring. IEEE Access 2024, 12, 65128–65140. [Google Scholar] [CrossRef]
- Sun, R.; Dai, Y.; Cheng, Q. An Adaptive Weighting Strategy for Multisensor Integrated Navigation in Urban Areas. IEEE Internet Things J. 2023, 10, 12777–12786. [Google Scholar] [CrossRef]
- Basak, S.; Suresh, S. Vehicle detection and type classification in low resolution congested traffic scenes using image super resolution. Multimed. Tools Appl. 2024, 83, 21825–21847. [Google Scholar] [CrossRef]
- Xiao, Z.; Fang, H.; Jiang, H.; Bai, J.; Havyarimana, V.; Chen, H.; Jiao, L. Understanding Private Car Aggregation Effect via Spatio-Temporal Analysis of Trajectory Data. IEEE Trans. Cybern. 2023, 53, 2346–2357. [Google Scholar] [CrossRef] [PubMed]
- Arthur, E.; Muturi, T.; Adu-Gyamfi, Y. Training Vehicle Detection and Classification Models with Less Data: An Active Learning Approach. Transp. Res. Rec. 2024, 01920211. [Google Scholar] [CrossRef]
- Xiao, Z.; Shu, J.; Jiang, H.; Min, G.; Chen, H.; Han, Z. Overcoming Occlusions: Perception Task-Oriented Information Sharing in Connected and Autonomous Vehicles. IEEE Netw. 2023, 37, 224–229. [Google Scholar] [CrossRef]
- Maity, S.; Pawan, K.S.; Dmitrii, K.; Ram, S. Current Datasets and Their Inherent Challenges for Automatic Vehicle Classification. In Machine Learning for Cyber Physical System: Advances and Challenges; Springer Nature: Cham, Switzerland, 2024; pp. 377–406. [Google Scholar]
- Yang, J.; Yang, K.; Xiao, Z.; Jiang, H.; Xu, S.; Dustdar, S. Improving Commute Experience for Private Car Users via Blockchain-Enabled Multitask Learning. IEEE Internet Things J. 2023, 10, 21656–21669. [Google Scholar] [CrossRef]
- Ma, S.; Yang, J.J. Image-Based Vehicle Classification by Synergizing Features from Supervised and Self-Supervised Learning Paradigms. Eng Adv. Eng. 2023, 4, 444–456. [Google Scholar] [CrossRef]
- Farid, A.; Hussain, F.; Khan, K.; Shahzad, M.; Khan, U.; Mahmood, Z. A fast and accurate real-time vehicle detection method using deep learning for unconstrained environments. Appl. Sci. 2023, 13, 3059. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, Y.; Yu, H.; Du, X.; Guizani, M. Intersection Fog-Based Distributed Routing for V2V Communication in Urban Vehicular Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 2409–2426. [Google Scholar] [CrossRef]
- Cynthia Sherin, B.; Kayalvizhi, J. Effective vehicle classification and re-identification on stanford cars dataset using convolutional neural networks. In Proceedings of the 3rd International Conference on Artificial Intelligence: Advances and Applications: ICAIAA 2022, Jaipur, India, 23–24 April 2022; Springer Nature: Singapore, 2023; pp. 177–190. [Google Scholar]
- Sun, G.; Song, L.; Yu, H.; Chang, V.; Du, X.; Guizani, M. V2V Routing in a VANET Based on the Autoregressive Integrated Moving Average Model. IEEE Trans. Veh. Technol. 2019, 68, 908–922. [Google Scholar] [CrossRef]
- Ali, A.; Sarkar, R.; Das, D.K. IRUVD: A new still-image based dataset for automatic vehicle detection. Multimed. Tools Appl. 2024, 83, 6755–6781. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, Y.; Liao, D.; Yu, H.; Du, X.; Guizani, M. Bus-Trajectory-Based Street-Centric Routing for Message Delivery in Urban Vehicular Ad Hoc Networks. IEEE Trans. Veh. Technol. 2018, 67, 7550–7563. [Google Scholar] [CrossRef]
- Ye, Y.; Chen, W.; Chen, F.; Jia, W.; Lu, Q. Night-time vehicle model recognition based on domain adaptation. Multimed. Tools Appl. 2024, 83, 9577–9596. [Google Scholar]
- Sun, G.; Wang, Z.; Su, H.; Yu, H.; Lei, B.; Guizani, M. Profit Maximization of Independent Task Offloading in MEC-Enabled 5G Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2024, 1–13. [Google Scholar] [CrossRef]
- Hasanvand, M.; Mahdi, N.; Elaheh, M.; Arezu, S. Machine learning methodology for identifying vehicles using image processing. Artif. Intell. Appl. 2023, 1, 170–178. [Google Scholar] [CrossRef]
- Sun, G.; Sheng, L.; Luo, L.; Yu, H. Game Theoretic Approach for Multipriority Data Transmission in 5G Vehicular Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24672–24685. [Google Scholar] [CrossRef]
- Alghamdi, A.S.; Ammar, S.; Muhammad, K.; Khalid, T.M.; Wafa, S.A. Vehicle classification using deep feature fusion and genetic algorithms. Electronics 2023, 12, 280. [Google Scholar] [CrossRef]
- Qu, Z.; Liu, X.; Zheng, M. Temporal-Spatial Quantum Graph Convolutional Neural Network Based on Schrödinger Approach for Traffic Congestion Prediction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8677–8686. [Google Scholar] [CrossRef]
- Tan, S.H.; Joon, H.C.; Chow, C.-O.; Jeevan, K.; Hung, Y.L. Artificial intelligent systems for vehicle classification: A survey. Eng. Appl. Artif. Intell. 2024, 129, 107497. [Google Scholar] [CrossRef]
- Luo, J.; Wang, G.; Li, G.; Pesce, G. Transport infrastructure connectivity and conflict resolution: A machine learning analysis. Neural Comput. Appl. 2022, 34, 6585–6601. [Google Scholar] [CrossRef]
- Pandharipande, A.; Cheng, C.-H.; Dauwels, J.; Gurbuz, S.Z.; Ibanez-Guzman, J.; Li, G.; Piazzoni, A.; Wang, P.; Santra, A. Sensing and machine learning for automotive perception: A review. IEEE Sens. J. 2023, 23, 11097–11115. [Google Scholar] [CrossRef]
- Chen, B.; Hu, J.; Ghosh, B.K. Finite-time tracking control of heterogeneous multi-AUV systems with partial measurements and intermittent communication. Sci. China Inf. Sci. 2024, 67, 152202. [Google Scholar] [CrossRef]
- Boonsirisumpun, N.; Okafor, E.; Surinta, O. Vehicle image datasets for image classification. Data Brief 2024, 53, 110133. [Google Scholar] [CrossRef]
- Chen, B.; Hu, J.; Zhao, Y.; Ghosh, B.K. Finite-time observer based tracking control of uncertain heterogeneous underwater vehicles using adaptive sliding mode approach. Neurocomputing 2022, 481, 322–332. [Google Scholar] [CrossRef]
- Sathyanarayana, N.; Anand, M.N. Vehicle type detection and classification using enhanced relieff algorithm and long short-term memory network. J. Inst. Eng. Ser. B 2023, 104, 485–499. [Google Scholar] [CrossRef]
- He, S.; Chen, W.; Wang, K.; Luo, H.; Wang, F.; Jiang, W.; Ding, H. Region Generation and Assessment Network for Occluded Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2024, 19, 120–132. [Google Scholar] [CrossRef]
- Kussl, S.; Omberg, K.S.; Lekang, O.-I. Advancing Vehicle Classification: A Novel Framework for Type, Model, and Fuel Identification Using Nonvisual Sensor Systems for Seamless Data Sharing. IEEE Sens. J. 2023, 23, 19390–19397. [Google Scholar] [CrossRef]
- Mohammadzadeh, A.; Taghavifar, H.; Zhang, C.; Alattas, K.A.; Liu, J.; Vu, M.T. A non-linear fractional-order type-3 fuzzy control for enhanced path-tracking performance of autonomous cars. IET Control. Theory Appl. 2024, 18, 40–54. [Google Scholar] [CrossRef]
- Berwo, M.A.; Asad, K.; Yong, F.; Hamza, F.; Shumaila, J.; Jabar, M.; Zain, U.A.; Syam, M.S. Deep learning techniques for vehicle detection and classification from images/videos: A survey. Sensors 2023, 23, 4832. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, Y.; Zhao, L.; Mi, B. A refinement and abstraction method of the SPZN formal model for intelligent networked vehicles systems. KSII Trans. Internet Inf. Syst. TIIS 2024, 18, 64–88. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, J.; An, Z. Vehicle recognition algorithm based on Haar-like features and improved Adaboost classifier. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 807–815. [Google Scholar] [CrossRef]
- Huang, Y.; Feng, B.; Cao, Y.; Guo, Z.; Zhang, M.; Zheng, B. Collaborative on-demand dynamic deployment via deep reinforcement learning for IoV service in multi edge clouds. J. Cloud Comput. 2023, 12, 119. [Google Scholar] [CrossRef]
- Chiang, C.-Y.; Jaber, M.; Chai, K.K.; Loo, J.; Chai, M. Distributed acoustic sensor systems for vehicle detection and classification. IEEE Access 2023, 11, 31293–31303. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, W.; Zhou, X.; Liao, Q.; Luo, Q.; Ni, L.M. FraudTrip: Taxi Fraudulent Trip Detection from Corresponding Trajectories. IEEE Internet Things J. 2021, 8, 12505–12517. [Google Scholar] [CrossRef]
- Pemila, M.; Pongiannan, R.K.; Megala, V. Implementation of Vehicles Classification using Extreme Gradient Boost Algorithm. In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; IEEE: Bhilai, India, 2022; pp. 1–6. [Google Scholar]
- Deng, Z.W.; Zhao, Y.Q.; Wang, B.H.; Gao, W.; Kong, X. A preview driver model based on sliding-mode and fuzzy control for articulated heavy vehicle. Meccanica 2022, 57, 1853–1878. [Google Scholar] [CrossRef]
- Pemila, M.; Pongiannan, R.K.; Narayanamoorthi, R.; Sweelem, E.A.; Hendawi, E.; Abu El-Sebah, M.I. Real Time Classification of Vehicles Using Machine Learning Algorithm on the Extensive Dataset. IEEE Access 2024, 12, 98338–98351. [Google Scholar] [CrossRef]
- Gao, W.; Wei, M.; Huang, S. Optimization of aerodynamic drag reduction for vehicles with non-smooth surfaces and research on aerodynamic characteristics under crosswind. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2023. [Google Scholar] [CrossRef]
- Shvai, N.; Hasnat, A.; Meicler, A.; Nakib, A. Accurate classification for automatic vehicle-type recognition based on ensemble classifiers. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1288–1297. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Q.; Cheng, H.H.; Peng, W.; Xu, W. A Review of Vision-Based Traffic Semantic Understanding in ITSs. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19954–19979. [Google Scholar] [CrossRef]
- Pemila, M.; Pongiannan, R.K.; Kareem, M.A.; Amr, Y. Application of an ensemble CatBoost model over complex dataset for vehicle classification. PLoS ONE 2024, 19, e0304619. [Google Scholar]
- Chen, J.; Xu, M.; Xu, W.; Li, D.; Peng, W.; Xu, H. A Flow Feedback Traffic Prediction Based on Visual Quantified Features. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10067–10075. [Google Scholar] [CrossRef]
- Pemila, M.; Pongiannan, R.; Pandey, V.; Mondal, P.; Bhaumik, S. An Efficient Classification for Light Motor Vehicles using CatBoost Algorithm. In Proceedings of the 2023 Fifth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 22–24 February 2023; IEEE: Bhilai, India, 2023; pp. 1–7. [Google Scholar]
- Chen, J.; Wang, Q.; Peng, W.; Xu, H.; Li, X.; Xu, W. Disparity-Based Multiscale Fusion Network for Transportation Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18855–18863. [Google Scholar] [CrossRef]
- Zhang, S.; Lu, X.; Lu, Z. Improved CNN-based CatBoost model for license plate remote sensing image classification. Signal Process. 2023, 213, 109196. [Google Scholar] [CrossRef]
- Li, S.; Chen, J.; Peng, W.; Shi, X.; Bu, W. A vehicle detection method based on disparity segmentation. Multimed. Tools Appl. 2023, 82, 19643–19655. [Google Scholar] [CrossRef]
- Aldania, A.N.A.; Soleh, A.M.; Notodiputro, K.A. A comparative study of CatBoost and double random forest for multi-class classification. J. RESTI Rekayasa Sist. Teknol. Informasi 2023, 7, 129–137. [Google Scholar] [CrossRef]
- Yue, W.; Li, J.; Li, C.; Cheng, N.; Wu, J. A Channel Knowledge Map-Aided Personalized Resource Allocation Strategy in Air-Ground Integrated Mobility. IEEE Trans. Intell. Transp. Syst. 2024, 1–14. [Google Scholar] [CrossRef]
- Mani, P.; Komarasamy, P.R.G.; Rajamanickam, N.; Alroobaea, R.; Alsafyani, M.; Afandi, A. An Efficient Real-Time Vehicle Classification from a Complex Image Dataset Using eXtreme Gradient Boosting and the Multi-Objective Genetic Algorithm. Processes 2024, 12, 1251. [Google Scholar] [CrossRef]
- Xu, X.; Liu, W.; Yu, L. Trajectory prediction for heterogeneous traffic-agents using knowledge correction data-driven model. Inf. Sci. 2022, 608, 375–391. [Google Scholar] [CrossRef]
- Singh, P.; Gupta, S.; Gupta, V. Multi-objective hyperparameter optimization on gradient-boosting for breast cancer detection. Int. J. Syst. Assur. Eng. Manag. 2023, 15, 1676–1686. [Google Scholar] [CrossRef]
- Zhu, C. Intelligent robot path planning and navigation based on reinforcement learning and adaptive control. J. Logist. Inform. Serv. Sci. 2023, 10, 235–248. [Google Scholar] [CrossRef]
- Sun, X.; Fu, J. Many-objective optimization of BEV design parameters based on gradient boosting decision tree models and the NSGA-III algorithm considering the ambient temperature. Energy 2024, 288, 129840. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, Y.; Liu, R.; Wei, C.; Du, H.; Yin, C. Short-Term Lateral Behavior Reasoning for Target Vehicles Considering Driver Preview Characteristic. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11801–11810. [Google Scholar] [CrossRef]
- Qian, L.; Chen, Z.; Huang, Y.; Stanford, R.J. Employing categorical boosting (CatBoost) and meta-heuristic algorithms for predicting the urban gas consumption. Urban Clim. 2023, 51, 101647. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, Y. A Blockchain-Enabled Framework for Vehicular Data Sensing: Enhancing Information Freshness. IEEE Trans. Veh. Technol. 2024, 1–14. [Google Scholar] [CrossRef]
- Demir, S.; Şahin, E.K. Liquefaction prediction with robust machine learning algorithms (SVM, RF, and XGBoost) supported by genetic algorithm-based feature selection and parameter optimization from the perspective of data processing. Environ. Earth Sci. 2022, 81, 459. [Google Scholar] [CrossRef]
- Li, J.; Ling, M.; Zang, X.; Luo, Q.; Yang, J.; Chen, S.; Guo, X. Quantifying risks of lane-changing behavior in highways with vehicle trajectory data under different driving environments. Int. J. Mod. Phys. C 2024. [Google Scholar] [CrossRef]
- Hamdaoui, F.; Bougharriou, S.; Mtibaa, A. Optimized Hardware Vision System for Vehicle Detection based on FPGA and Combining Machine Learning and PSO. Microprocess. Microsyst. 2022, 90, 104469. [Google Scholar] [CrossRef]
- Wang, F.; Xin, X.; Lei, Z.; Zhang, Q.; Yao, H.; Wang, X.; Tian, Q.; Tian, F. Transformer-Based Spatio-Temporal Traffic Prediction for Access and Metro Networks. J. Light. Technol. 2024, 42, 5204–5213. [Google Scholar] [CrossRef]
- Ilyukhin, A.V.; Seleznev, V.S.; Antonova, E.O.; Abdulkhanova, M.Y.; Marsova, E.V. Implementation of FPGA-based camera video adapter for vehicle identification tasks based on EUR 13 classification. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; Volume 1159, p. 012008. [Google Scholar]
- Zhao, J.; Song, D.; Zhu, B.; Sun, Z.; Han, J.; Sun, Y. A Human-Like Trajectory Planning Method on a Curve Based on the Driver Preview Mechanism. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11682–11698. [Google Scholar] [CrossRef]
- Zhai, J.; Li, B.; Lv, S.; Zhou, Q. FPGA-based vehicle detection and tracking accelerator. Sensors 2023, 23, 2208. [Google Scholar] [CrossRef] [PubMed]
- Zhu, B.; Sun, Y.; Zhao, J.; Han, J.; Zhang, P.; Fan, T. A Critical Scenario Search Method for Intelligent Vehicle Testing Based on the Social Cognitive Optimization Algorithm. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7974–7986. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Vehicle Name | Class Name | No of Images | Sample Images |
|---|---|---|---|---|
| 1 | Fire Engine | Ashok Leyland ENSOL TCS | 1538 |  |
| 2 | Ambulance | JCBL Limited TATA Venture MarutiSuzuki Omni | 200 |  |
| 3 | VIP/HNWI | Mercedes Benz GLS VOLVO XC90 Mahindra Scorpio N | 1500 |  |
| 4 | Police | Hyundai Mahindra Royal Enfield | 2500 |  |
| Assets | Handy Features | Deployment | Utilization (%) |
|---|---|---|---|
| Look Up Table | 42,100 | 24,410 | 56 |
| Flip-Flop | 105,300 | 32,204 | 30 |
| 4 KB-RAM | 120 | 37 | 23 |
| Digital Signal Processor | 210 | 57 | 20 |
| Network | 1-Fold | 2-Fold | 3-Fold | 4-Fold | 5-Fold | 6-Fold | 7-Fold | 8-Fold | 9-Fold | 10-Fold | Avg. Acc |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16-MOGA-SVM | 92.10 | 93.00 | 94.00 | 92.30 | 93.20 | 93.10 | 92.40 | 93.15 | 93.90 | 93.29 | 93.23 |
| VGG19-MOGA-CB | 96.20 | 97.10 | 97.90 | 96.30 | 97.20 | 97.00 | 96.40 | 97.15 | 97.80 | 97.29 | 97.24 |
| ResNet50-MOGA-MOGA | 85.90 | 86.95 | 87.70 | 85.92 | 86.85 | 86.80 | 85.95 | 86.90 | 86.75 | 86.89 | 86.77 |
| ResNet50-MOGA-CB-MOGA | 98.90 | 98.95 | 99.80 | 98.92 | 99.85 | 98.88 | 99.82 | 98.93 | 99.87 | 99.89 | 99.89 |
| Authors | Techniques | Data Description | Accuracy |
|---|---|---|---|
| Ma, Shihan, and Jidong J. Yang [12] | ViT + data2vec + YOLOR model | 13 FHWA vehicle classes | 97.2% |
| Farid, Annam, Farhan Hussain, [14] | YOLO-v5 | 600 images contain 3 classes | 99.92% |
| Hasanvand, Mohamad, Mahdi Nooshyar [22] | SVM algorithm | 7 images of vehicles | 97.1 |
| Alghamdi, Ahmed S., Ammar Saeed, Muhammad Kamran [24] | Cubic SVM kernel | 196 cars images | 99.7% |
| Tan, Shi Hao, Joon Huang Chuah [26] | CNN models | 3 vehicle classes | 99% |
| Boonsirisumpun, Narong [30] | Deep learning | 4356 imagescategorized into five classes | 90.83% |
| Sathyanarayana, N., and Anand [32] | local binary pattern, steerable pyramid transform, and dual tree complex wavelet transform | six vehicle categories | 99.01% and 95.85% |
| Kussl, Sebastian [34] | MEMS | Classify vehicle model, type and fuel | 92.9% |
| Berwo, Michael Abebe [36] | YOLOV4 | Vehicle types | 98% |
| Zhang, Le, Jinsong Wang Chiang, Chia-Yen [38] | Adaboost | 2000 vehicle images | 85.8% |
| Shvai, Nadiya, AbulHasnat [46] | CB algorithm | 5 classes of vehicles | 99.03% |
| Zhang, Songhua, Xiuling Lu [52] | CNN + CB | License Plates of the vehicle | |
| Aldania, AnnisarahmiNurAini [54] | CB + DRF | 5 digit numerical group of 21 alphabets | 92.45 |
| Singh, Priya, Swayam Gupta [58] | NSGA-II algorithm | 7909 images | 94.40% |
| Sun, Xilei, and Jianqin Fu [60] | NSGA -III | Electric consumption 100 km | 96.3% |
| Qian, Leren, Zhongsheng Chen [62] | hybrid Catboost-PPSO | 6 models | TIC values 0.0013 and 0.0540. |
| Demir, Selçuk, and Emrehan [64] | XGBoost | 411 shear wave velocity | 96% |
| Hamdaoui, Faycal, Sana Bougharriou [65] | SVM + HOG + PSO | Vehicle images and video | 97.84% |
| Ilyukhin, A. V., V. S. Seleznev [66] | VGA port board | 7 various color | 25.1 MHz |
| Zhai, Jiaqi, Bin Li, ShunsenLv [67] | YOLO V3 | 1053 identities | 98.2% |
| Gaia, Jeremias, Eugenio Orosco [68] | Alveo U200 Data Center Accelerator Cardand a Zynq UltraScale+ MPSoC ZCU104 EvaluationKit | 5 haralick features | Less than 3 ms |
| Al Amin, Rashed, Mehrab Hasan [69] | YOLO v3 | Traffic light signal | 99% |
| Proposed Method | CNN + MOGA + Classifier | 12 classes of Emergency vehicle | 99.87% |
| CNN Models/ MOGA | Classifier | Avg. Acc | Avg. Prec | Avg. Rec | Avg. Sco | ||||
|---|---|---|---|---|---|---|---|---|---|
| W | W/O | W | W/O | W | W/O | W | W/O | ||
| VGG16 | SVM | 96.88 | 97.06 | 66.40 | 97.04 | 95.76 | 96.40 | 96.03 | 96.55 |
| CB | 97.10 | 97.76 | 97.35 | 98.07 | 97.37 | 98.04 | 97.34 | 98.05 | |
| MOGA | 88.46 | 88.46 | 88.84 | 89.18 | 89.50 | 89.76 | 88.97 | 89.14 | |
| CB-MOGA | 98.01 | 98.61 | 98.28 | 98.73 | 98.05 | 98.47 | 98.15 | 98.59 | |
| VGG19 | SVM | 85.42 | 85.63 | 84.91 | 85.04 | 84.12 | 84.25 | 84.48 | 84.62 |
| CB | 93.44 | 93.53 | 93.37 | 94.33 | 93.31 | 93.83 | 93.72 | 94.08 | |
| MOGA | 74.21 | 75.26 | 77.78 | 77.85 | 69.75 | 70.85 | 70.45 | 72.07 | |
| CB-MOGA | 98.67 | 98.93 | 98.40 | 98.82 | 98.66 | 98.69 | 98.53 | 98.73 | |
| ResNet50 | SVM | 93.37 | 93.45 | 93.35 | 93.55 | 93.59 | 93.66 | 93.49 | 93.60 |
| CB | 91.73 | 91.94 | 91.54 | 92.05 | 90.86 | 91.88 | 91.11 | 91.47 | |
| MOGA | 86.83 | 86.93 | 86.38 | 86.33 | 84.79 | 85.44 | 84.76 | 85.31 | |
| CB-MOGA | 99.13 | 99.60 | 99.15 | 99.60 | 99.19 | 99.66 | 99.17 | 99.63 | |
| Models | Number of Features | Average Accuracy (%) | Average Computation Time (s) | ||||
|---|---|---|---|---|---|---|---|
| MOGA | W | W/O | W | W/O | W | W/O | |
| VGG16-CB | 3085 | 1054 | 98.01 | 98.61 | 22.5 ± 0.86 | 22.0 ± 0.60 | |
| VGG19-CB | 3085 | 1003 | 98.67 | 98.93 | 32.8 ± 0.01 | 37.1 ± 0.76 | |
| ResNet50-CB | 1028 | 1001 | 99.13 | 99.60 | 12.4 ± 0.10 | 13.8 ± 0.45 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mani, P.; Komarasamy, P.R.G.; Rajamanickam, N.; Shorfuzzaman, M.; Abdelfattah, W.M. Enhancing Sustainable Transportation Infrastructure Management: A High-Accuracy, FPGA-Based System for Emergency Vehicle Classification. Sustainability 2024, 16, 6917. https://doi.org/10.3390/su16166917
Mani P, Komarasamy PRG, Rajamanickam N, Shorfuzzaman M, Abdelfattah WM. Enhancing Sustainable Transportation Infrastructure Management: A High-Accuracy, FPGA-Based System for Emergency Vehicle Classification. Sustainability. 2024; 16(16):6917. https://doi.org/10.3390/su16166917
Chicago/Turabian StyleMani, Pemila, Pongiannan Rakkiya Goundar Komarasamy, Narayanamoorthi Rajamanickam, Mohammad Shorfuzzaman, and Waleed Mohammed Abdelfattah. 2024. "Enhancing Sustainable Transportation Infrastructure Management: A High-Accuracy, FPGA-Based System for Emergency Vehicle Classification" Sustainability 16, no. 16: 6917. https://doi.org/10.3390/su16166917
APA StyleMani, P., Komarasamy, P. R. G., Rajamanickam, N., Shorfuzzaman, M., & Abdelfattah, W. M. (2024). Enhancing Sustainable Transportation Infrastructure Management: A High-Accuracy, FPGA-Based System for Emergency Vehicle Classification. Sustainability, 16(16), 6917. https://doi.org/10.3390/su16166917