
Extraction of Maize Distribution Information Based on Critical Fertility Periods and Active–Passive Remote Sensing
Abstract
1. Introduction
2. Study Area and Data Preprocessing
2.1. Study Area
2.1.1. Sample Point Data
2.1.2. Image Data and Preprocessing
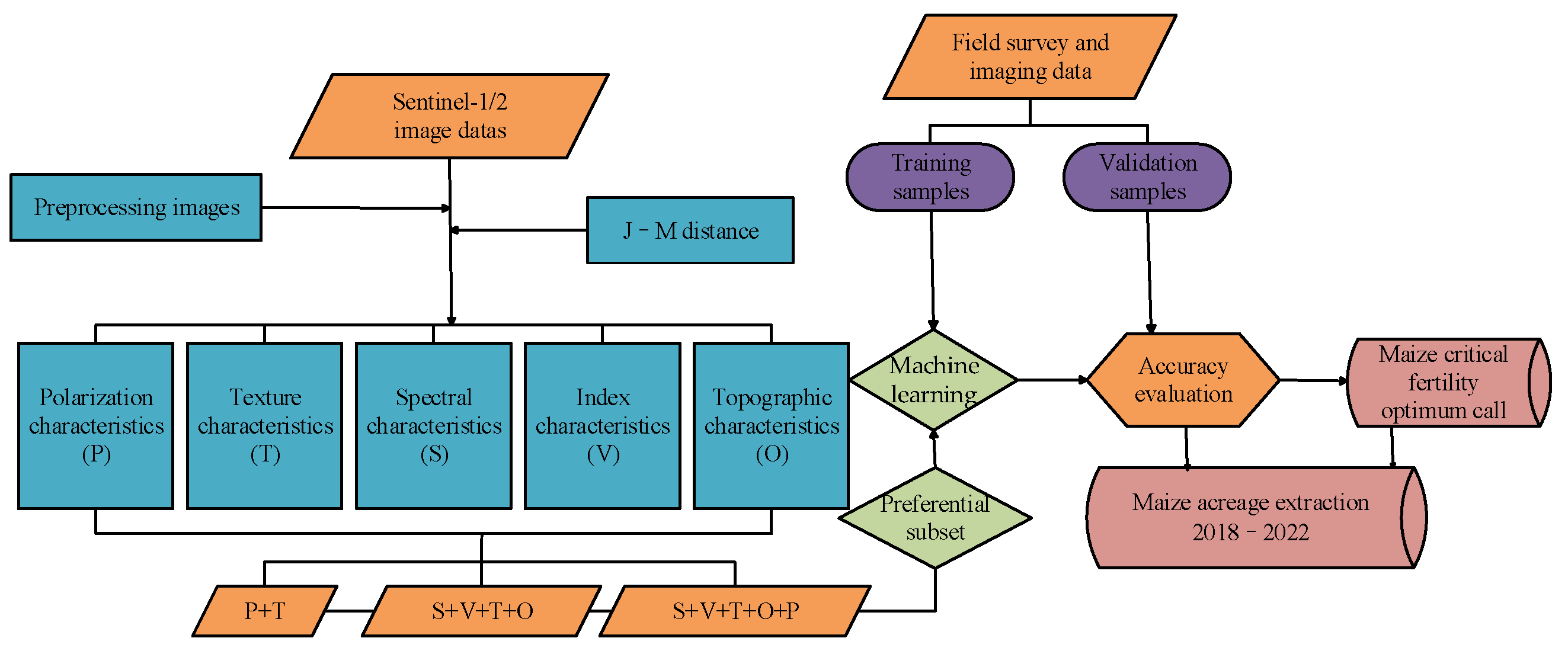
3. Research Methods
3.1. Characteristic Variable
3.2. Classification Methods
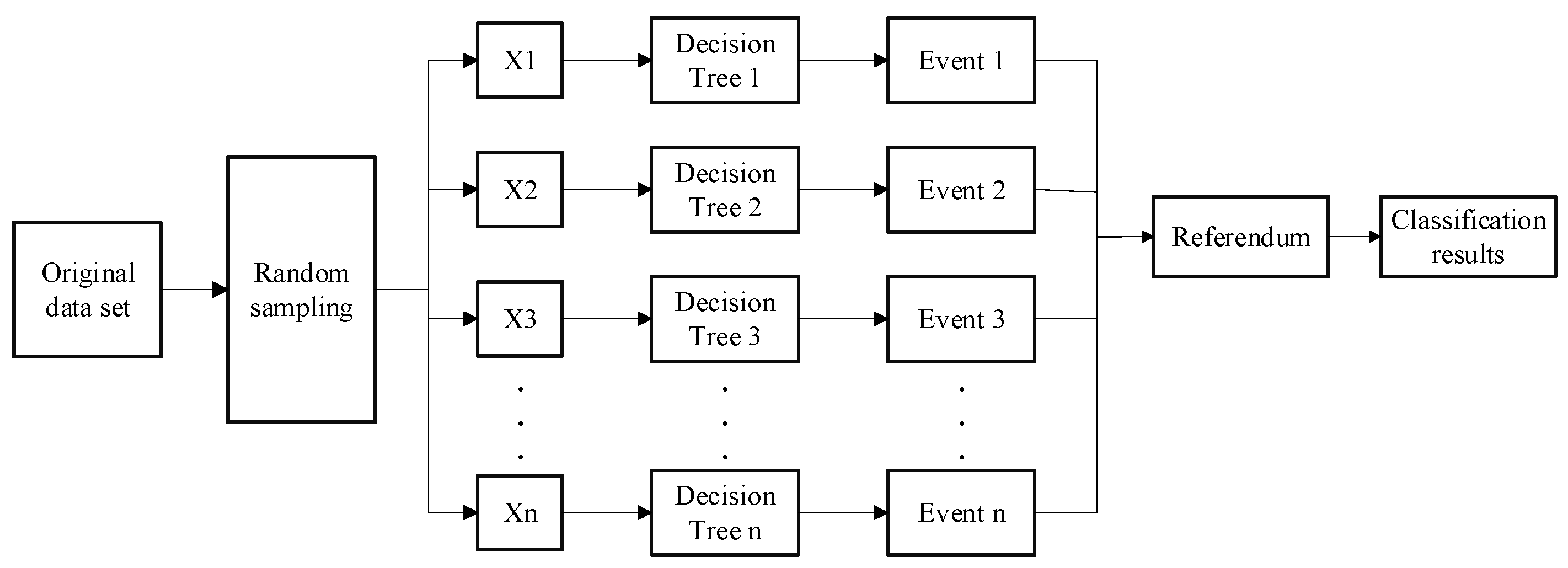
3.2.1. Random Forest Algorithm
3.2.2. Support Vector Machine (SVM) Algorithm
3.2.3. Decision Tree (DT) Algorithm
3.2.4. Naive Bayes (NB) Algorithm
3.2.5. K-Nearest Neighbor (KNN) Algorithm
3.3. Separability Calculations
3.4. Feature Preferences
3.5. Precision Evaluation
4. Results and Discussion
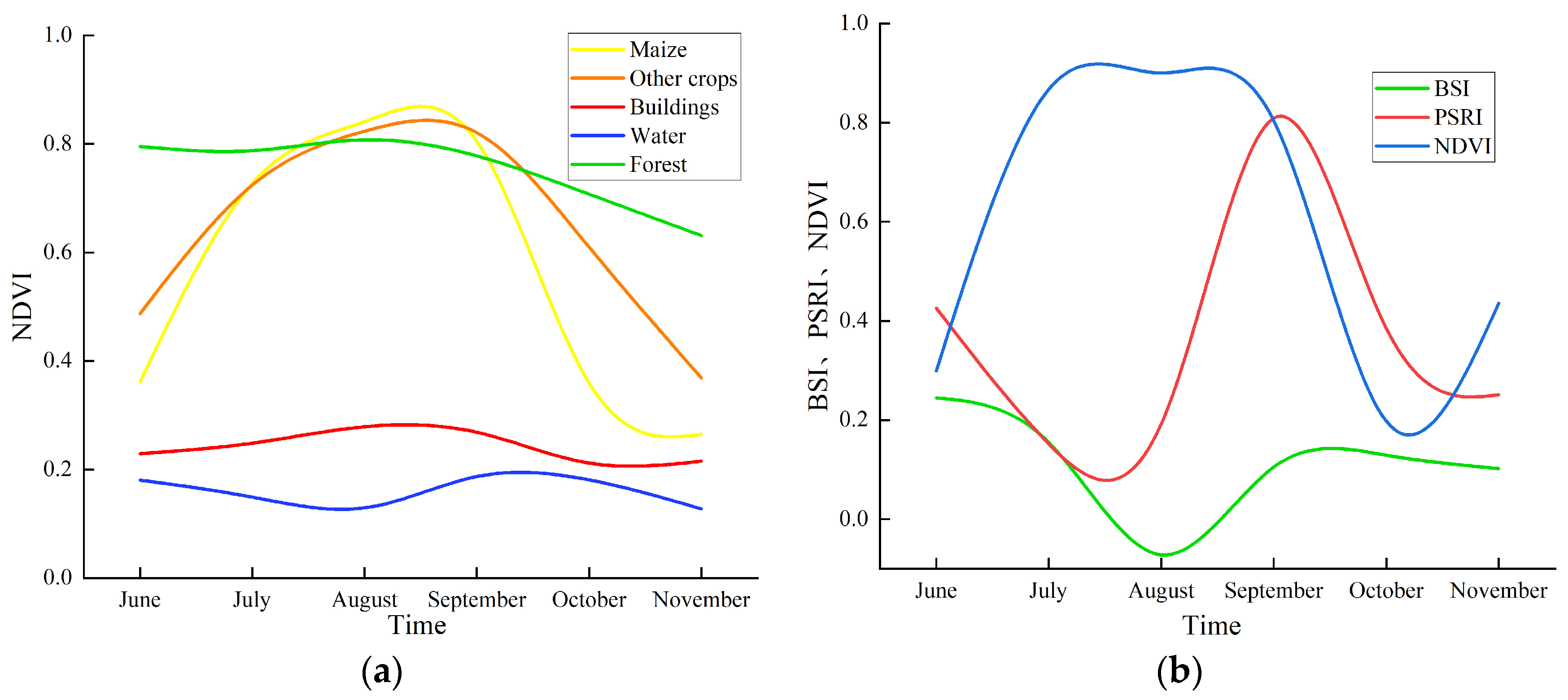
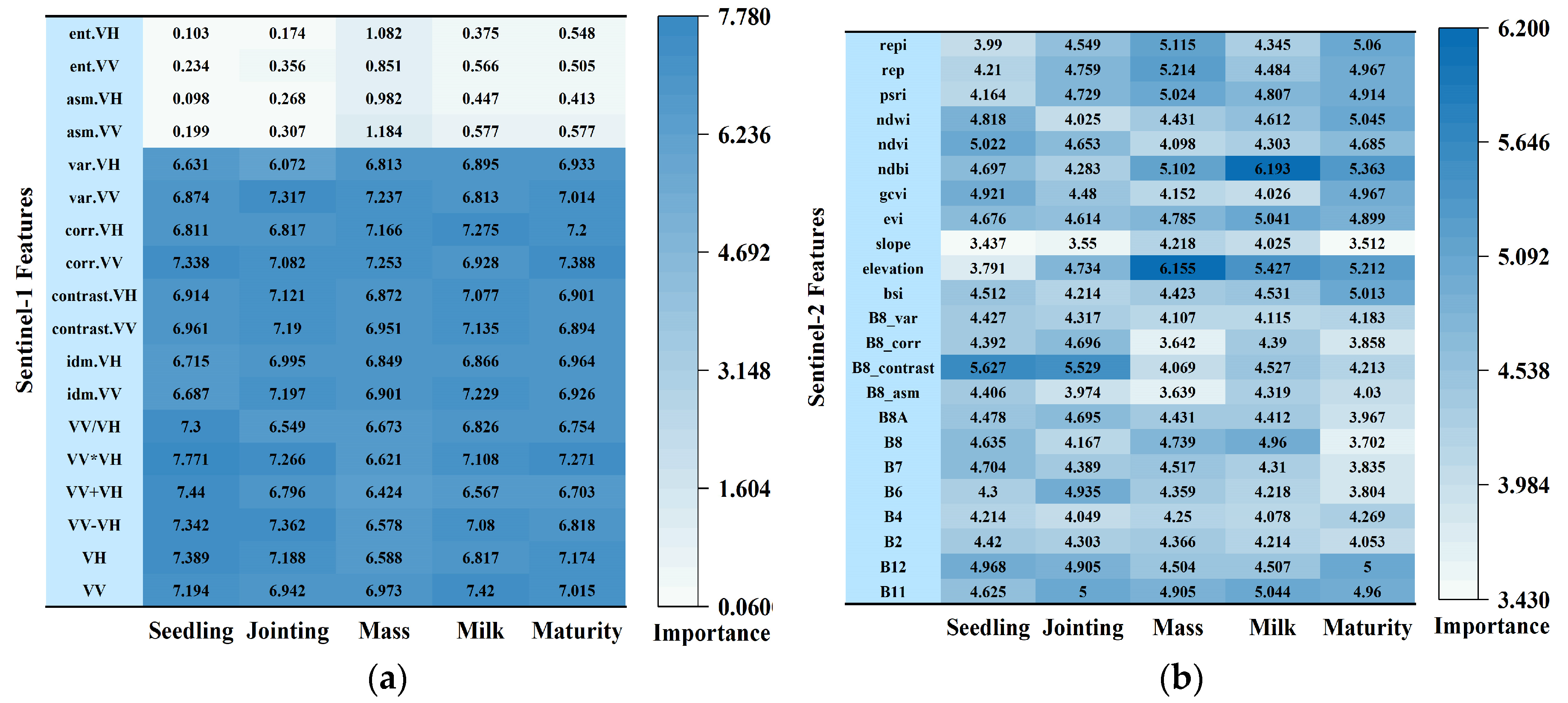
4.1. Analysis of Feature Selection
4.2. Analysis of Critical Time Phases
4.3. Separability Results for Different Land Use Types
4.4. Categorization Results
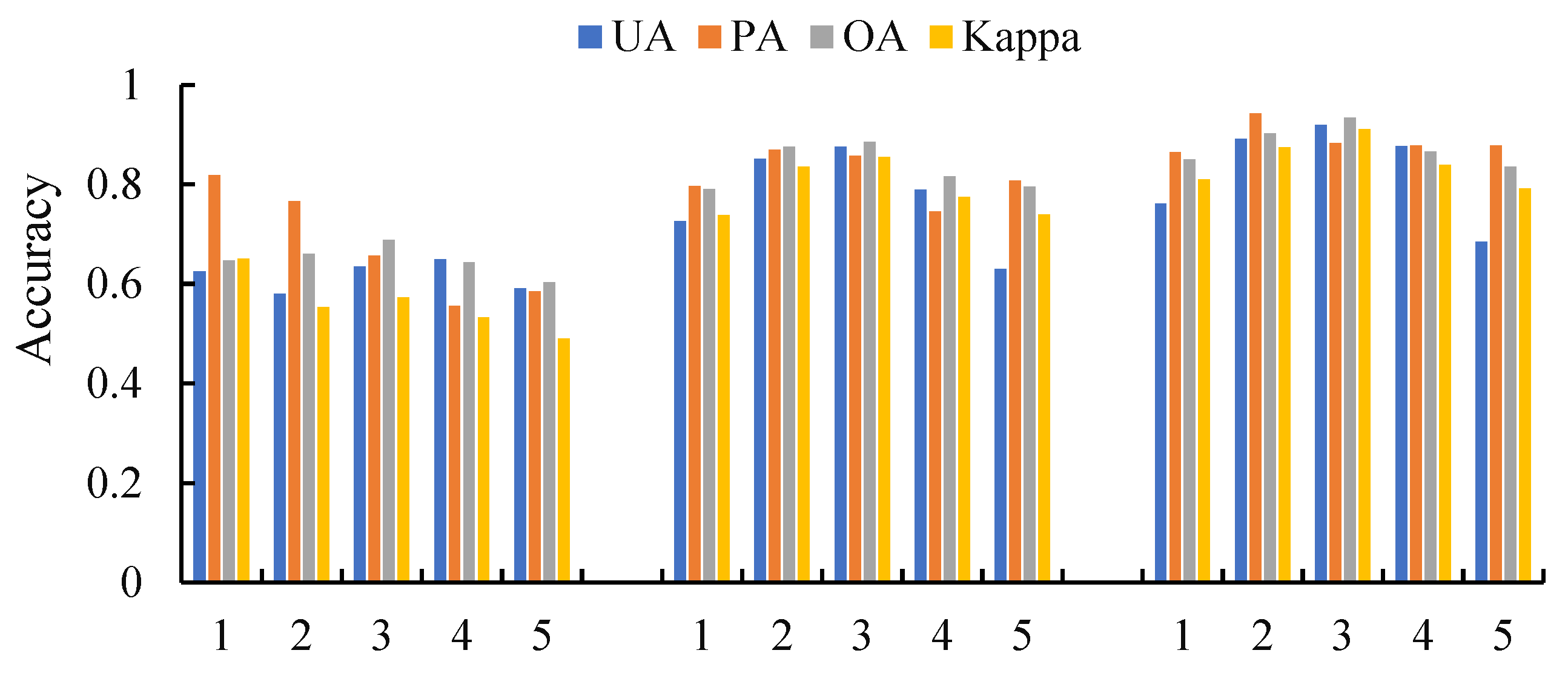
4.4.1. Classification of Single-Source Data
4.4.2. Classification of Multi-Source Data Fusion
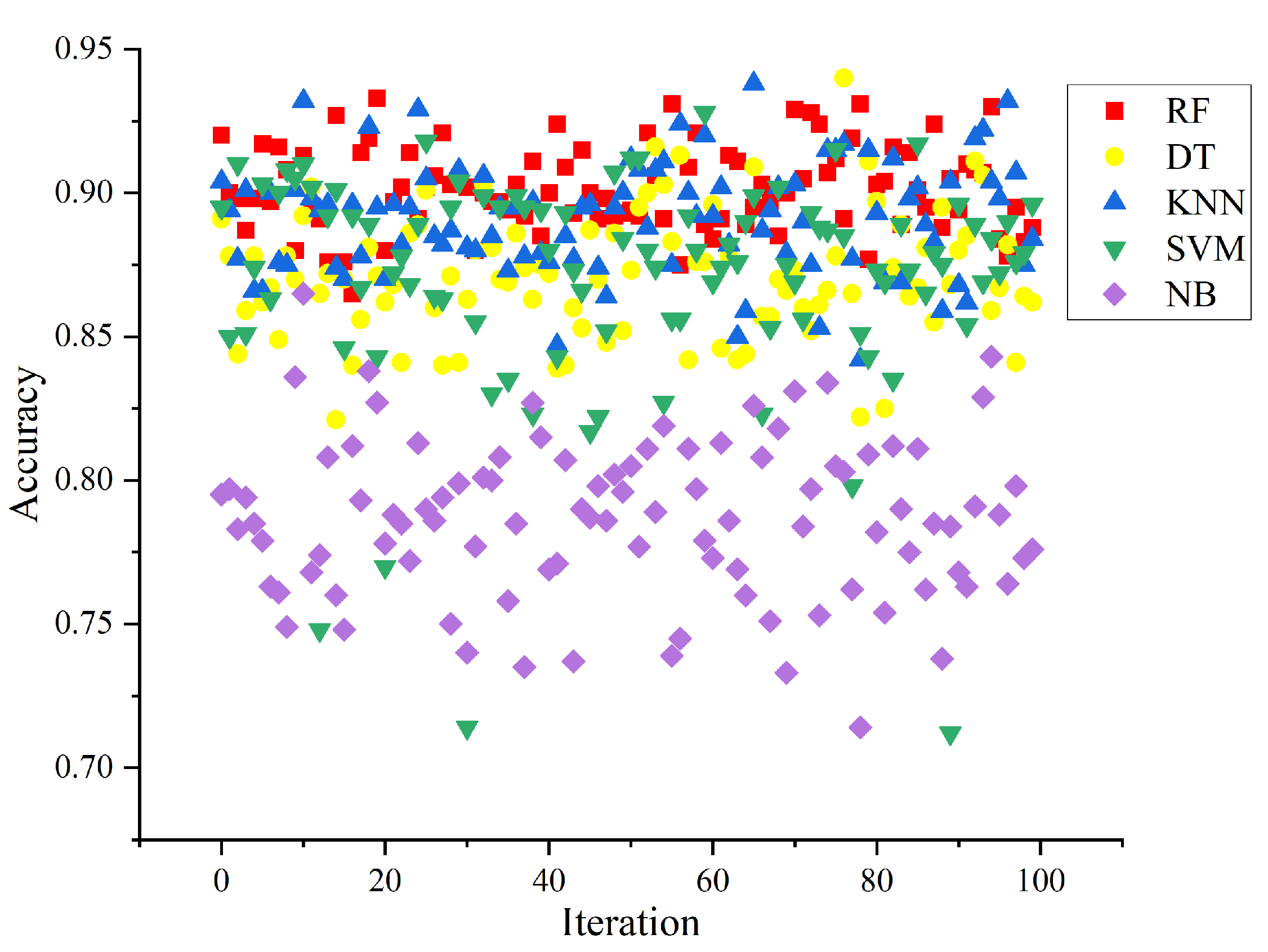
4.5. Comparative Analysis of Classification Accuracy
4.6. Results of Maize Area Extraction and Accuracy Confirmation
4.7. Discussion
4.8. Uncertainty and Outlook
- This study utilized Sentinel-1 and Sentinel-2 images with a spatial resolution of 10 m, which may have introduced limitations due to the potential presence of mixed land cover types within individual pixels, thus affecting classification accuracy. Furthermore, the northern part of the study area is characterized by a complex mountainous terrain, which could also have influenced the results. Future research should incorporate high-resolution images to produce more detailed datasets and investigate their impact on classification performance.
- The machine learning methods and feature variables employed in this study are tailored to a specific study area, and their generalizability to other regions or larger areas remains uncertain, warranting further investigation. Future research should evaluate the applicability of these models and variables in diverse geographical contexts. Additionally, deep learning models, which have shown promise in remote sensing applications, could be explored as alternative approaches for the extraction of maize planting areas.
- To further enhance the extraction of maize areas from multi-source data, future research should focus on capturing the developmental characteristics of maize across different growth stages. By continuously optimizing the selection of feature types from Sentinel-1 and Sentinel-2 for each phenological phase, the classification process could more precisely reflect changes at each stage. This refined feature selection is expected to improve classification accuracy and strengthen the overall performance of maize area detection.
- The quality of the remote sensing images collected during different maize growth stages can vary, potentially influencing the results. Satellites are subject to both internal and external factors when capturing ground images, with meteorological conditions being a major influence. Although efforts are made to screen for cloud cover, the impact of weather conditions on the accurate recognition of maize remains a concern and cannot be entirely eliminated.
5. Conclusions
- 1.
- The classification accuracy of fused active–passive remote sensing images for the 2022 maize tasseling period improved by 24.6% relative to that of the single-source Sentinel-1 images, with the Kappa coefficient increasing by 0.34. Compared with the single-source Sentinel-2 images, the accuracy improved by 4.86% and the Kappa coefficient increased by 0.05. Thus, using multi-source data with the random forest algorithm provided a higher accuracy and better classification of maize than using the Sentinel-1 or Sentinel-2 images. Based on multi-source data, RF had a higher classification accuracy in the tasseling stage than the SVM, DT, NB, and KNN methods.
- 2.
- During the tasseling period, the general accuracy of the extracted maize planted area was at its maximum. The multi-source data fusion random forest classification in 2022 had an overall accuracy of over 85% and Kappa coefficients over 0.79. Among these, the tasseling stage had the highest overall accuracy at 93.38% and a Kappa coefficient of 0.91, indicating that this method can help the agricultural insurance department assess risks promptly and verify the planted area quickly.
- 3.
- This study used the random forest method to extract the maize area in Jiaozuo City from 2018 to 2022. The extracted accuracies were 93.83%, 98.77%, 97.9%, 97%, and 98.06%, respectively. The remotely extracted maize planted area in Jiaozuo City showed a growing trend in 2019–2022, which is consistent with the Statistical Yearbook. The extracted data were combined with active–passive remote sensing fusion images taken during the tasseling stage. Furthermore, the random forest’s ability to identify features was influenced by the terrain factor. Specifically, steep slopes are less suitable for maize planting, while flatter areas support a larger maize planting range. Furthermore, the classification effect in flat terrain is superior to that in complex terrain.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Reng, J.; Tang, H.; Shi, Y.; Len, P.; Liu, J.; Wang, L.; Wu, W.; Yao, Y.; Hasiyuya. Progress and perspectives on agricultural remote sensing research and applications in China. J. Remote Sens. 2016, 20, 748–767. [Google Scholar] [CrossRef]
- Meng, S.; Zhong, Y.; Luo, C.; Hu, X.; Wang, X.; Huang, S. Optimal Temporal Window Selection for Winter Wheat and Rapeseed Mapping with Sentinel-2 Images: A Case Study of Zhongxiang in China. Remote Sens. 2020, 12, 226. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, J.; Duan, Y.; Yang, Z. Transferring Deep Convolutional Neural Network Models for Generalization Mapping of Autumn Crops. Natl. Remote Sens. Bull. 2024, 28, 661–676. [Google Scholar] [CrossRef]
- Tang, H. Progress and Prospect of Agricultural Remote Sensing Research. J. Agric. 2018, 8, 175–179. [Google Scholar] [CrossRef]
- Dong, J.; Wu, W.; Huang, J.; You, N.; He, Y.; Yan, H. State of the Art and Perspective of Agricultural Land Use Remote Sensing Information Extraction. J. Geo-Inf. Sci. 2020, 22, 772–783. [Google Scholar] [CrossRef]
- Guo, J.; Zhu, l.; Jin, B. Crop Classification Method with Differential Characteristics Based on Multi-temporal PolSAR Images. Trans. Chin. Soc. Agric. Mach. 2018, 49, 192–198. [Google Scholar]
- Chen, Q.; Cao, W.; Shang, J.; Liu, J.; Liu, X. Superpixel-Based Cropland Classification of SAR Image with Statistical Texture and Polarization Features. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4503005. [Google Scholar] [CrossRef]
- Useya, J.; Shengbo, C. Exploring the Potential of Mapping Cropping Patterns on Smallholder Scale Croplands Using Sentinel-1 SAR Data. Chin. Geogr. Sci. 2019, 20, 626–639. [Google Scholar] [CrossRef]
- Liao, C.; Wang, J.; Huang, X.; Shang, J. Contribution of Minimum Noise Fraction Transformation of Multi-Temporal RADARSAT-2 Polarimetric SAR Data to Cropland Classification. Can. J. Remote Sens. 2018, 44, 215–231. [Google Scholar] [CrossRef]
- PAN, Z.; HU, Y.; WANG, G. Detection of Short-Term Urban Land Use Changes by Combining SAR Time Series Images and Spectral Angle Mapping. Front. Earth Sci. 2019, 13, 495–509. [Google Scholar] [CrossRef]
- Liang, J.; Liu, D. A Local Thresholding Approach to Flood Water Delineation Using Sentinel-1 SAR Imagery. ISPRS J. Photogramm. Remote Sens. 2020, 159, 53–62. [Google Scholar] [CrossRef]
- Markert, K.N.; Chishtie, F.; Anderson, E.R.; Saah, D.; Griffin, R.E. On the Merging of Optical and SAR Satellite Imagery for Surface Water Mapping Applications. Results Phys. 2018, 9, 275–277. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, Y.; Xun, L. Crop Classification Based on Multi-source Remote Sensing Data Fusion and LSTM Algorithm. Chin. Soc. Agric. Eng. 2019, 35, 129–137. [Google Scholar] [CrossRef]
- Li, C.; Chen, W.; Wang, Y.; Ma, C.; Wang, Y.; Li, Y. Extraction of Winter Wheat Planting Area in County Based on Multi-sensor Sentinel Data. Trans. Chin. Soc. Agric. Mach. 2021, 52, 207–215. [Google Scholar] [CrossRef]
- Ma, Z.; Liu, C.; Xue, H.; Li, J.; Fang, X.; Zhou, J. Identification of Winter Wheat by Integrating Active and Passive Remote Sensing Data Based on Google Earth Engine Platform. Trans. Chin. Soc. Agric. Mach. 2021, 52, 195–205. [Google Scholar] [CrossRef]
- Wu, X.; Hua, S.; Zhang, S.; Gu, L.; Ma, C.; Li, C. Extraction of Winter Wheat Distribution Information Based on Multi-phenological Feature Indices Derived from Sentinel-2 Date. Trans. Chin. Soc. Agric. Mach. 2023, 54, 207–216. [Google Scholar]
- Liu, S.; Peng, D.; Zhang, B.; Chen, Z.; Yu, L.; Chen, J.; Pan, Y.; Zheng, S.; Hu, J.; Lou, Z.; et al. The Accuracy of Winter Wheat Identification at Different Growth Stages Using Remote Sensing. Remote Sens. 2022, 14, 893. [Google Scholar] [CrossRef]
- Lv, W.; Song, X.; Yang, H. Extraction of Maize Acreage Based on Deep Learning and Multi-source Remote Sensing Data. Jiangsu Agric. Sci. 2023, 51, 171–178. [Google Scholar] [CrossRef]
- Xie, Y.; Wang, J.; Liu, Y. Research on Winter Wheat Planting Area Identification Method Based on Sentinel-1/2 Data Feature Optimization. Trans. Chin. Soc. Agric. Mach. 2024, 55, 231–241. [Google Scholar] [CrossRef]
- Qu, C.; Li, P.; Zhang, C. A Spectral Index for Winter Wheat Mapping Using Multi-Temporal Landsat NDVI Data of Key Growth Stages. ISPRS J. Photogramm. Remote Sens. 2021, 175, 431–447. [Google Scholar] [CrossRef]
- Virnodkar, S.; Pachghare, V.K.; Patil, V.C.; Jha, S.K. Performance Evaluation of RF and SVM for Sugarcane Classification Using Sentinel-2 NDVI Time-Series. In Progress in Advanced Computing and Intelligent Engineering. Advances in Intelligent Systems and Computing; Panigrahi, C.R., Pati, B., Mohapatra, P., Buyya, R., Li, K.C., Eds.; Springer: Singapore, 2021; Volume 1199. [Google Scholar] [CrossRef]
- Ponganan, N.; Horanont, T.; Artlert, K.; Nuallaong, P. Land Cover Classification Using Google Earth Engine’s Object-Oriented and Machine Learning Classifier. In Proceedings of the 2021 2nd International Conference on Big Data Analytics and Practices (IBDAP), Bangkok, Thailand, 26–27 August 2021; pp. 33–37. [Google Scholar] [CrossRef]
- Zhou, R.; Yang, C.; Li, E.; Cai, X.; Yang, J.; Xia, Y. Object-Based Wetland Vegetation Classification Using Multi-Feature Selection of Unoccupied Aerial Vehicle RGB Imagery. Remote Sens. 2021, 13, 4910. [Google Scholar] [CrossRef]
- Palchowdhuri, Y.; Valcarce-Diñeiro, R.; King, P.; Sanabria-Soto, M. Classification of multi-temporal spectral indices for crop type mapping: A case study in Coalville, UK. J. Agric. Sci. 2018, 156, 24–36. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and Photographic Infrared Linear Combinations for Monitoring Vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Huete, A.R. A Soil-Adjusted Vegetation Index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Tian, X.; Zhang, Y.; Liu, R.; Wei, J. Winter Wheat Planting Area Extraction over Wide Area Using Vegetation Red Edge Information of Multi-temporal Sentinel-2 Images. Natl. Remote Sens. Bull. 2022, 26, 1988–2000. [Google Scholar] [CrossRef]
- Majasalmi, T.; Rautiainen, M. The Potential of Sentinel-2 Data for Estimating Biophysical Variables in a Boreal Forest: A Simulation Study. Remote Sens. Lett. 2016, 7, 427–436. [Google Scholar] [CrossRef]
- McFEETERS, S.K. The Use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of Normalized Difference Built-up Index in Automatically Mapping Urban Areas from TM Imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Schlerf, M.; Atzberger, C.; Hill, J. Remote Sensing of Forest Biophysical Variables Using HyMap Imaging Spectrometer Data. Remote Sens. Environ. 2005, 95, 177–194. [Google Scholar] [CrossRef]
- Delegido, J.; Verrelst, J.; Alonso, L.; Moreno, J. Evaluation of Sentinel-2 Red-Edge Bands for Empirical Estimation of Green LAI and Chlorophyll Content. Sensors 2011, 11, 7063–7081. [Google Scholar] [CrossRef]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m Crop Type Maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef] [PubMed]
- Huete, A.R.; Liu, H.Q.; Batchily, K.; van Leeuwen, W. A Comparison of Vegetation Indices over a Global Set of TM Images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Shen, Y.; Li, Q.; Du, X.; Wang, H.; Zhang, Y. Indicative Features for Identifying Corn and Soybean Using Remote Sensing Imagery at Middle and Later Growth Season. Natl. Remote Sens. Bull. 2022, 26, 1410–1422. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs Neurons: Comparison between Random Forest and ANN for High-Resolution Prediction of Building Energy Consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An Assessment of the Effectiveness of a Random Forest Classifier for Land-Cover Classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Vincenzi, S.; Zucchetta, M.; Franzoi, P.; Pellizzato, M.; Pranovi, F.; De Leo, G.A.; Torricelli, P. Application of a Random Forest Algorithm to Predict Spatial Distribution of the Potential Yield of Ruditapes philippinarum in the Venice Lagoon, Italy. Ecol. Model. 2011, 222, 1471–1478. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.; Chen, J.; Zhang, C.; Liu, L.; Cao, X.; Zang, Y.; Zhu, X.; Cui, X. Mapping Winter Wheat in North China Using Sentinel 2A/B Data: A Method Based on Phenology-Time Weighted Dynamic Time Warping. Remote Sens. 2020, 12, 1274. [Google Scholar] [CrossRef]
- Wang, X.; Hou, M.; Shi, S.; Hu, Z.; Yin, C.; Xu, L. Winter Wheat Extraction Using Time-Series Sentinel-2 Data Based on Enhanced TWDTW in Henan Province, China. Sustainability 2023, 15, 1490. [Google Scholar] [CrossRef]
- An, Q.; Yang, B.; Guo, L. Method for object-oriented feature selection based on genetic algorithm with multi spectral images. Trans. Chin. Soc. Agric. Eng. 2008, 24, 181–185. [Google Scholar]
- Wang, Y.; Qi, Q.; Liu, Y. Unsupervised Segmentation Evaluation Using Area-Weighted Variance and Jeffries-Matusita Distance for Remote Sensing Images. Remote Sens. 2018, 10, 1193. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification Based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2020, 12, 76. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree Species Classification with Random Forest Using Very High Spatial Resolution 8-Band WorldView-2 Satellite Data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review. Remote Sens. 2021, 13, 2450. [Google Scholar] [CrossRef]
- Jiuzhong, W.; Haifeng, T.; Mingquan, W.U.; Li, W.; Changyao, W. Rapid Mapping of Winter Wheat in Henan Province. J. Geo-Inf. Sci. 2017, 19, 846–853. [Google Scholar] [CrossRef]
- Deng, L.; Shen, Z. Winter Wheat Planting Area Extraction Technique Using Multi-Temporal Remote Sensing Images Based on Field Parcel. In Proceedings of the International Conference on Geoinformatics and Data Analysis, Prague, Czech Republic, 20–22 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 77–82. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, H.; Lyu, X.; Du, W. Improving Typical Urban Land-Use Classification with Active-Passive Remote Sensing and Multi-Attention Modules Hybrid Network: A Case Study of Qibin District, Henan, China. Sustainability 2022, 14, 14723. [Google Scholar] [CrossRef]
- Hao, P.; Tang, H.; Chen, Z.; Liu, Z. Early-Season Crop Mapping Using Improved Artificial Immune Network (IAIN) and Sentinel Data. PeerJ 2018, 6, e5431. [Google Scholar] [CrossRef]
- Lou, Z.; Lu, X.; Li, S. Yield Prediction of Winter Wheat at Different Growth Stages Based on Machine Learning. Agronomy 2024, 14, 1834. [Google Scholar] [CrossRef]
- Liu, T.; Li, P.; Zhao, F.; Liu, J.; Meng, R. Early-Stage Mapping of Winter Canola by Combining Sentinel-1 and Sentinel-2 Data in Jianghan Plain China. Remote Sens. 2024, 16, 3197. [Google Scholar] [CrossRef]
- Wittstruck, L.; Jarmer, T.; Waske, B. Multi-Stage Feature Fusion of Multispectral and SAR Satellite Images for Seasonal Crop-Type Mapping at Regional Scale Using an Adapted 3D U-Net Model. Remote Sens. 2024, 16, 3115. [Google Scholar] [CrossRef]
- Huang, X.; Huang, J.; Li, X.; Shen, Q.; Chen, Z. Early Mapping of Winter Wheat in Henan Province of China Using Time Series of Sentinel-2 Data. GIScience Remote Sens. 2022, 59, 1534–1549. [Google Scholar] [CrossRef]
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-Optical Fusion for Crop Type Mapping Using Deep Learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H.; Tao, X. Deep Learning Based Winter Wheat Mapping Using Statistical Data as Ground References in Kansas and Northern Texas, US. Remote Sens. Environ. 2019, 233, 111411. [Google Scholar] [CrossRef]
- Zhao, F.; Sun, R.; Zhong, L.; Meng, R.; Huang, C.; Zeng, X.; Wang, M.; Li, Y.; Wang, Z. Monthly Mapping of Forest Harvesting Using Dense Time Series Sentinel-1 SAR Imagery and Deep Learning. Remote Sens. Environ. 2022, 269, 112822. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, L.; Zhang, Z.; Tian, F. An Unsupervised Domain Adaptation Deep Learning Method for Spatial and Temporal Transferable Crop Type Mapping Using Sentinel-2 Imagery. ISPRS J. Photogramm. Remote Sens. 2023, 199, 102–117. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fertility of Maize | Dates |
|---|---|
| Seedling stage | 20 May 2022–30 June 2022 |
| Jointing stage | 1 July 2022–25 July 2022 |
| Tasseling stage | 26 July 2022–15 August 2022 |
| Milk stage | 16 August 2022–5 September 2022 |
| Ripening stage | 5 September 2022–15 September 2022 |
| Sensors | Group | Characteristic Variable |
|---|---|---|
| Sentinel-1 | Polarization features | VV |
| VH | ||
| VV + VH, VV − VH, VV × VH, VV/VH | ||
| Sentinel-2 | Spectral features | Blue, green, and red bands (B2, B3, B4) |
| Red band (B5, B6, B7) | ||
| Near-infrared band (B8, B8A) | ||
| Short infrared band (B11, B12) | ||
| Exponential features | Normalized Difference Vegetation Index (NDVI) | |
| Bare Soil Index (BSI) | ||
| Plant Senescence Reflectance Index (PSRI) | ||
| Red-edge Position Index (REPI) | ||
| Normalized Difference Water Index (NDWI) | ||
| Enhanced Vegetation Index (EVI) | ||
| Normalized Difference Building Index (NDBI) | ||
| Green Chlorophyll Vegetation Index (GCVI) | ||
| Topographic features | Elevation | |
| Aspect | ||
| Shadow | ||
| Slope | ||
| Sentinel-1/2 | Texture features | Contrast |
| Correlation | ||
| Variance | ||
| Inverse Difference Moment (IDM) | ||
| Entropy | ||
| Angular Second Moment (ASM) |
| Type of Training Samples | Seedling Stage | Jointing Stage | Tasseling Stage | Milk Stage | Ripening Stage |
|---|---|---|---|---|---|
| Other crops | 1.81 | 1.92 | 1.98 | 1.77 | 1.83 |
| Building | 1.99 | 1.99 | 1.99 | 1.98 | 1.97 |
| Water | 1.99 | 1.99 | 1.99 | 1.99 | 1.99 |
| Forest | 1.97 | 1.99 | 1.99 | 1.99 | 1.98 |
| Classifications | Sentinel-1 | Sentinel-2 | ||||||
|---|---|---|---|---|---|---|---|---|
| UA/% | PA/% | OA/% | Kappa | UA/% | PA/% | OA/% | Kappa | |
| Seedling stage | 72.62 | 81.85 | 64.70 | 0.65 | 72.62 | 79.64 | 79.02 | 0.74 |
| Jointing stage | 58.03 | 76.56 | 66.01 | 0.55 | 85.07 | 86.96 | 87.51 | 0.83 |
| Tasseling stage | 63.48 | 65.65 | 68.78 | 0.57 | 87.50 | 85.71 | 88.52 | 0.86 |
| Milk stage | 64.85 | 55.53 | 64.25 | 0.53 | 78.84 | 74.54 | 81.55 | 0.77 |
| Ripening stage | 89.04 | 58.44 | 60.33 | 0.49 | 63.01 | 80.71 | 79.53 | 0.74 |
| All stages | 62.29 | 56.32 | 58.20 | 0.46 | 64.91 | 78.43 | 75.85 | 0.68 |
| Classifications | Seedling Stage | Jointing Stage | Tasseling Stage | Milk Stage | Ripening Stage | All Stages | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UA/% | PA/% | UA/% | PA/% | UA/% | PA/% | UA/% | PA/% | UA/% | PA/% | UA/% | PA/% | |
| Maize | 76.11 | 86.44 | 89.09 | 94.23 | 91.90 | 88.23 | 87.71 | 87.77 | 68.49 | 87.72 | 56.45 | 62.50 |
| Other crops | 76.92 | 66.66 | 88.13 | 85.24 | 90.65 | 85.24 | 82.00 | 86.10 | 79.16 | 61.29 | 71.64 | 66.66 |
| Building | 93.87 | 95.83 | 88.67 | 95.91 | 92.52 | 96.42 | 87.72 | 83.22 | 90.01 | 91.84 | 93.33 | 98.24 |
| Water | 100 | 100 | 90.90 | 100 | 92.00 | 100 | 96.97 | 96.30 | 95.98 | 96.16 | 97.65 | 94.16 |
| Forest | 88.09 | 86.04 | 95.55 | 82.69 | 93.22 | 91.85 | 86.47 | 86.33 | 93.22 | 90.16 | 82.05 | 75.92 |
| OA/% | 85.00 | 90.17 | 93.38 | 86.51 | 83.53 | 76.77 | ||||||
| Kappa | 0.81 | 0.87 | 0.91 | 0.84 | 0.79 | 0.69 | ||||||
| Classification Methods | RF | SVM | DT | NB | KNN |
|---|---|---|---|---|---|
| OA | 93.38 | 91.76 | 90.94 | 82.72 | 91.18 |
| Kappa | 0.91 | 0.89 | 0.88 | 0.78 | 0.89 |
| Mean Accuracy | 0.902 | 0.870 | 0.871 | 0.786 | 0.891 |
| Standard Deviation of Accuracy | 0.014 | 0.037 | 0.021 | 0.027 | 0.019 |
| Year | Extracted Area (hm2) | Statistical Area (hm2) | Absolute Error (hm2) | Accuracy (%) | OA (%) | Kappa |
|---|---|---|---|---|---|---|
| 2018 | 113,708 | 121,190 | 7482 | 93.83 | 91.45 | 0.89 |
| 2019 | 117,944 | 119,410 | 1466 | 98.77 | 94.97 | 0.93 |
| 2020 | 120,809 | 123,400 | 2591 | 97.90 | 91.81 | 0.89 |
| 2021 | 122,596 | 126,390 | 3794 | 97.00 | 94.72 | 0.93 |
| 2022 | 124,490 | 126,960 | 2470 | 98.06 | 93.38 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, X.; Zhang, X.; Yu, H.; Lu, X.; Zhou, J.; Feng, J.; Su, H. Extraction of Maize Distribution Information Based on Critical Fertility Periods and Active–Passive Remote Sensing. Sustainability 2024, 16, 8373. https://doi.org/10.3390/su16198373
Lv X, Zhang X, Yu H, Lu X, Zhou J, Feng J, Su H. Extraction of Maize Distribution Information Based on Critical Fertility Periods and Active–Passive Remote Sensing. Sustainability. 2024; 16(19):8373. https://doi.org/10.3390/su16198373
Chicago/Turabian StyleLv, Xiaoran, Xiangjun Zhang, Haikun Yu, Xiaoping Lu, Junli Zhou, Junbiao Feng, and Hang Su. 2024. "Extraction of Maize Distribution Information Based on Critical Fertility Periods and Active–Passive Remote Sensing" Sustainability 16, no. 19: 8373. https://doi.org/10.3390/su16198373
APA StyleLv, X., Zhang, X., Yu, H., Lu, X., Zhou, J., Feng, J., & Su, H. (2024). Extraction of Maize Distribution Information Based on Critical Fertility Periods and Active–Passive Remote Sensing. Sustainability, 16(19), 8373. https://doi.org/10.3390/su16198373