Abstract
Despite the significant recycling potential, a massive generation of plastic waste is observed year after year. One of the causes of this phenomenon is the issue of ineffective waste stream sorting, primarily arising from the uncertainty in the composition of the waste stream. The recycling process cannot be carried out without the proper separation of different types of plastics from the waste stream. Current solutions in the field of automated waste stream identification rely on small-scale datasets that insufficiently reflect real-world conditions. For this reason, the article proposes a real-time identification model based on a CNN (convolutional neural network) and a newly constructed, self-built dataset. The model was evaluated in two stages. The first stage was based on the separated validation dataset, and the second was based on the developed test bench, a replica of the real system. The model was evaluated under laboratory conditions, with a strong emphasis on maximally reflecting real-world conditions. Once included in the sensor fusion, the proposed approach will provide full information on the characteristics of the waste stream, which will ultimately enable the efficient separation of plastic from the mixed stream. Improving this process will significantly support the United Nations’ 2030 Agenda for Sustainable Development.
1. Introduction
Despite being in use for over a century, the global production and consumption of plastics are still increasing exponentially [1]. This ultimately contributes to the massive generation of plastic waste, which raises many environmental concerns associated with prolonged degradation time. However, it is possible to significantly reduce the negative environmental impacts by utilizing plastic’s recycling potential, allowing for multiple recycling cycles while preserving its original value and functionality [2]. For recycling to be feasible, a crucial preliminary action is the efficient sorting of collected waste [3] to separate different types of plastics for further processing. Despite the availability of numerous advanced technologies designed to support this process [4,5], successful waste sorting remains a complex and demanding task due to unresolved issues related to the inherent uncertainty of the waste stream.
The solid waste stream indicates high heterogeneity and variability in composition [6]. These attributes are consistently identified as key factors contributing to the challenges in optimizing waste-sorting processes aimed at maximizing the recovery of recyclable materials [7]. The primary challenge lies in identifying the composition of the stream, which consists of a wide variety of materials. For this reason, numerous studies have been published in recent years reviewing this issue. A summary of such publications highlighting the key conclusions and limitations of existing developments is presented in Table 1.

Table 1.
Summary of selected review publications in the area of automatic waste stream identification.
In [3], more than fifty studies were reviewed to identify the physical enablers, datasets, and machine learning algorithms used for waste identification in indirect separation systems. A broader coverage is included in [8], where almost two hundred papers were analyzed over a 20-year period on the subject of optical sensors and machine learning algorithms for sensor-based material flow characterization. Similarly, ref. [10] reviewed over two hundred studies that used machine learning algorithms for municipal solid waste management, including automatic stream identification. In [9], an extensive review was presented addressing the development trajectory, current state, and future opportunities and challenges of utilizing computer vision for waste sorting. In another study [11], commonly utilized sensor-based technologies for solid waste sorting, including spectroscopic- and computer vision-based classification, were found. It should be noted that all these review publications from the past few years highlight similar limitations of existing solutions for automated waste stream identification. The most frequently reported limitations across all studies include testing under controlled laboratory conditions and challenges arising from using small-scale datasets, such as failure to account for waste diversity or insufficient generalization of models. On the one hand, this highlights the necessity of developing large-scale datasets that account for the specific characteristics of waste originating from different regions. On the other hand, laboratory conditions should be adjusted to replicate real-world scenarios strongly.
Object detection models have been intensively developed in recent years. In [11], the lines of development of object detection algorithms were presented, stating that currently, there are three mainstream series of object detectors: R-CNN, YOLO, and SSD. A comparative analysis demonstrated that YOLO outperforms both R-CNN and SSD due to its higher speed and feature extraction capabilities. Similar conclusions were drawn in [13], where YOLO, compared to R-CNN, demonstrated superior real-time performance with shorter inference times. Given that automatic waste stream identification requires the real-time, rapid detection of multiple objects within a single frame, accounting for variations in size and orientation, the YOLO series is one of the most commonly utilized frameworks [14]. Table 2 summarizes recent publications on automatic waste identification using YOLO.
Table 2.
Summary of selected publications from recent years in the area of automatic waste identification based on CNN YOLO.
In [15], an improved YOLOv5 model was proposed considering the requirements of construction waste, i.e., small-object detection and inter-object occlusion. Household waste was subjected to automatic detection and classification in [16,19,20], where self-made datasets were used to train and validate YOLO models. Among studies of this type, the issue of detecting river floating waste can also be found [18]. Plastic waste is also the subject of research. However, it is typically limited to only four [13] or two types [17] of plastics. The analysis of the summary presented in Table 2 reveals three significant limitations. As already highlighted by review articles, a recurring constraint in many studies is that model testing is conducted under laboratory conditions. Most studies evaluate the model by partitioning a portion of the utilized dataset (what has been referred to as static validation), where waste remains stationary during testing. Only in [17] was dynamic validation performed, in which waste moved along a conveyor belt. However, the detection was limited to only PET and PET-G classes. Another limitation concerns the omission of contaminants present in the waste stream, which should serve as the background of the prepared samples rather than being the target of detection. This approach was implemented only in [15,20], where access to recordings from a real-world system was available. The final observed limitation is the low level of detail in the classification of plastic waste. Plastic is most commonly treated as a single class or, at best, divided into a maximum of four classes without distinguishing, for instance, different colors of PET, which is crucial from a recycling perspective.
Considering the identified limitations, this paper aims to develop a model for the automatic identification of plastic waste streams that takes into account the requirements of real-world waste-sorting facilities, such as the presence of contaminants and the transportation of waste on a conveyor belt with variable speed. The research contributes to the development of more sustainable waste management solutions by improving the efficiency of plastic waste sorting, thereby addressing the sustainability challenge of ecosystem degradation and its associated risks to human well-being. By enhancing the accuracy of automatic waste identification, the proposed approach supports circular economy principles, mitigates environmental pollution and reduces the unintended release of plastic waste into ecosystems. Due to the drawbacks of publicly available datasets, the model will incorporate a preparation process of the dataset. Additionally, the model will be based on CNNs, as they have achieved the best results in image classification in recent years. The main contributions of our paper are the following:
- We based the YOLO model training process on a self-built dataset consisting of over 4000 images of waste, including contamination.
- We have distinguished six classes reflecting the most commonly separated types of plastic, i.e., blue PET, white PET, green PET, HDPE, tetrapak, and, in addition to plastic, aluminum waste.
- We developed a set of recommendations for dataset creation aimed at automatic waste identification.
- We have applied a combination of three YOLO models to the multi-class waste classification issue.
- The model validation was conducted in a laboratory environment using a test setup and waste samples designed to closely replicate real-world conditions, with waste moving on a conveyor and being detected in real time by a camera.
2. Materials and Methods
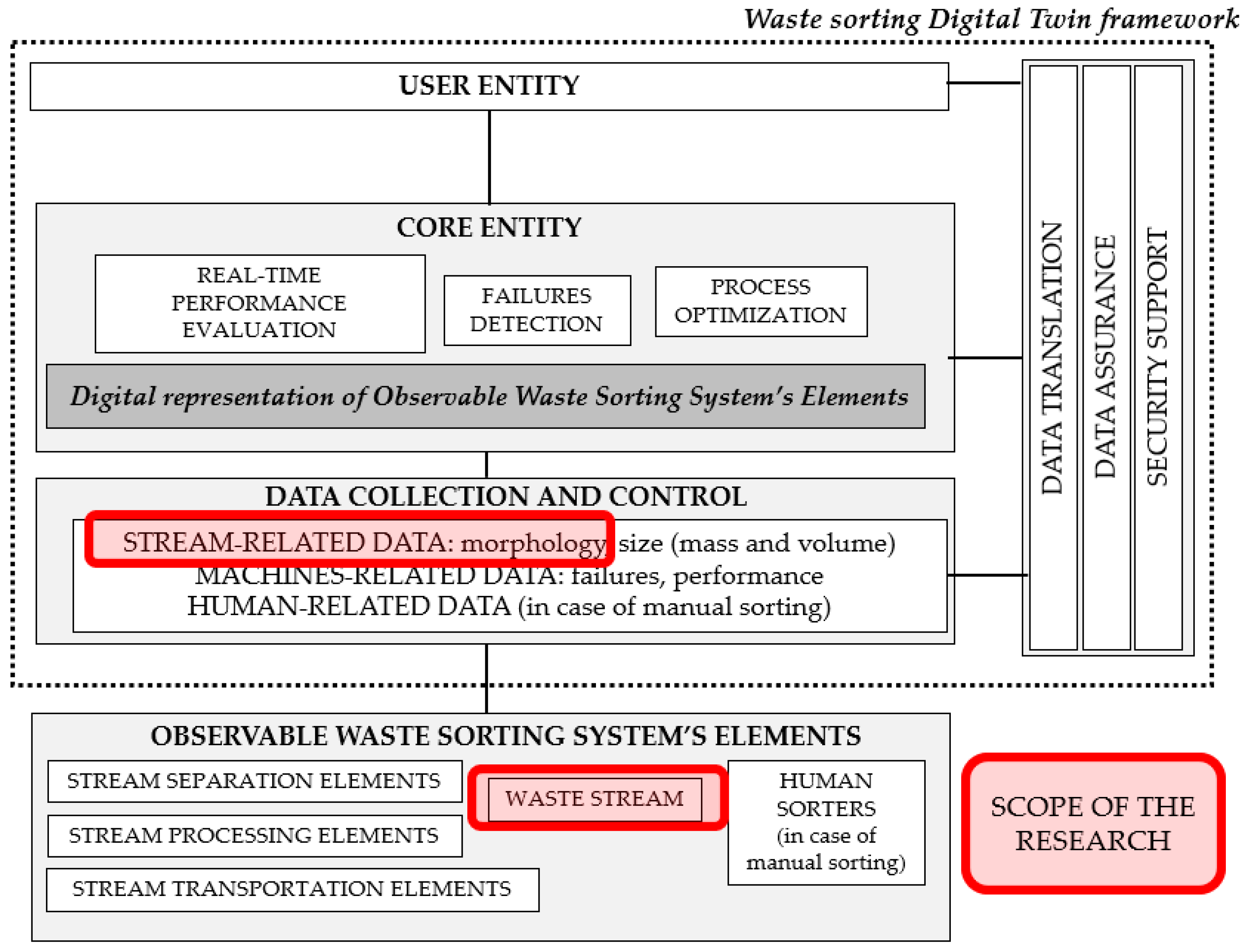
The considered automatic waste stream identification is part of an ongoing project funded by the National Centre for Research and Development, entitled “Cyber-physical waste stream control system”. The project aims to develop a cyber-physical control system for municipal waste sorting, i.e., a Digital Twin of a waste-sorting system. The structure of the Digital Twin consists of three fundamental components: the physical system, its digital replica, and a bidirectional link connecting the two [21]. A detailed description of the indicated elements and the Digital Twin framework for waste-sorting systems is presented in [22]. The foundation of the Digital Twin’s operation is the automatic collection of data from the real-world system. Automatic identification of waste stream is therefore one of the key components of the data collection and control layer. The scope of this publication can thus be placed in the Digital Twin framework, as shown in Figure 1.
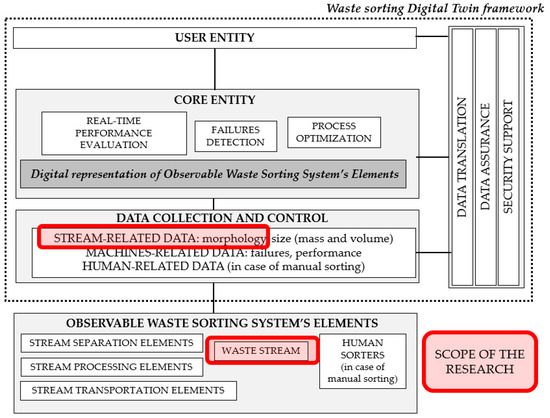
Figure 1.
Scope of research in the context of the Digital Twin framework for waste-sorting systems.
Based on the results of the literature review, waste characterization, and stream monitoring requirements, the automatic identification of the stream was developed using CNN, specifically the YOLOv5 model.
2.1. Automatic Waste Identification Model Based on YOLOv5
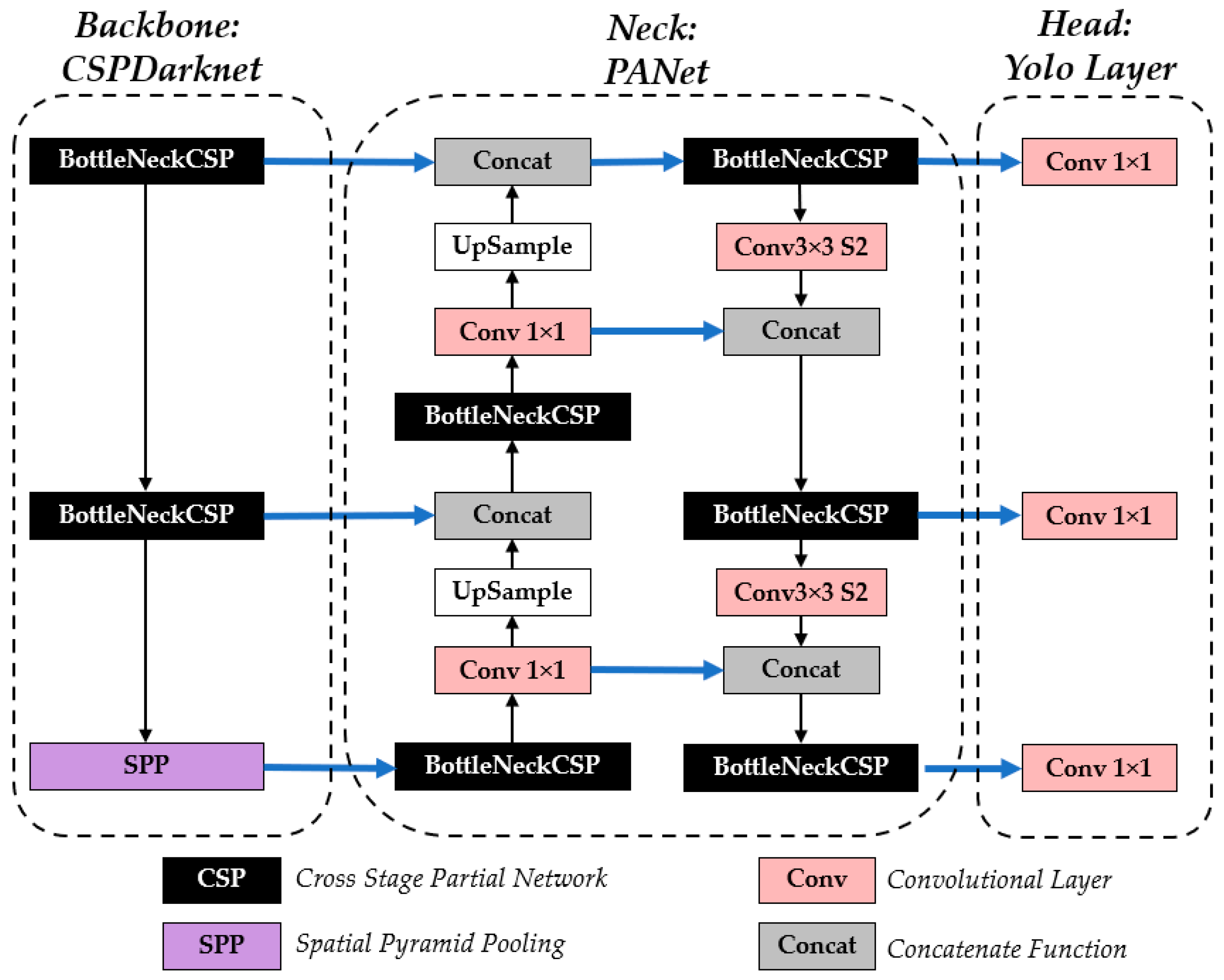
The YOLO series are CNN-based frameworks commonly used in object detection and classification, including waste detection. Its three core components include the backbone, neck, and head. The backbone, a convolutional neural network, encodes image data into multi-scale feature maps. These maps are then refined by the neck, which consists of layers that enhance and integrate feature representations. Finally, the head module utilizes the processed features to predict object bounding boxes and class labels [23]. The general architecture of YOLOv5 is shown in Figure 2.
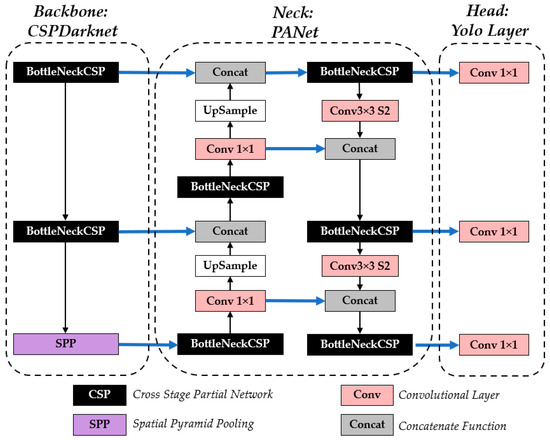
Figure 2.
Architectural diagram of YOLOv5 [24,25,26].
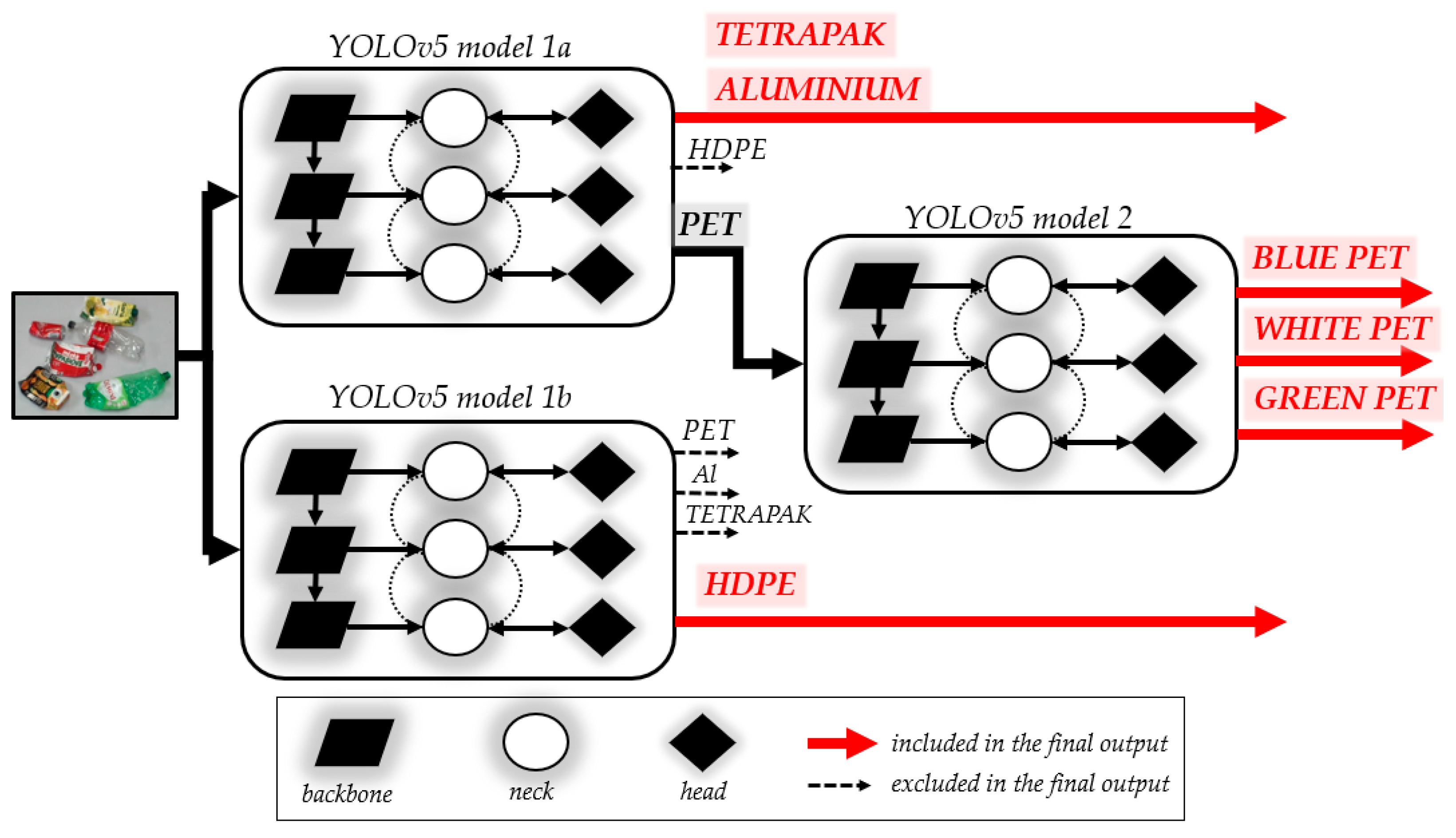
The automated waste stream identification model proposed in this paper is based on YOLOv5. Due to the complexity of detecting multiple waste classes and based on the results of our preliminary studies, we employed a combination of three YOLO models. Instead of burdening a single model with all the classes, the division into smaller models allows for focusing on a smaller set of classes in each case. This approach enables a more precise tailoring of the model to the specific characteristics of the waste. Such a strategy significantly improves detection accuracy and prevents situations where a single model might struggle to distinguish very similar classes. The use of three models allows for more accurate differentiation between classes, which is crucial in the context of waste sorting. Initially, the image is processed by two parallel models (1a and 1b). Each of them detects the same four waste classes (PET, HDPE, tetrapak, and Al), but these models are parameterized differently in terms of confidence score so that one focuses on PET, tetrapak, and Al, while the other focuses on the HDPE class. The other classes are ignored in both models. In the case of detecting the PET class, the output from model 1a is further processed by model 2, which assigns one of three colors to this class: blue, white, or green. The architecture of the proposed model is illustrated in Figure 3.
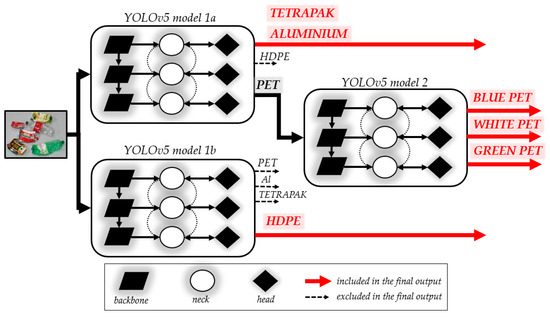
Figure 3.
Architecture of the proposed model for automatic waste stream identification based on YOLOv5.
2.2. Dataset Preparation
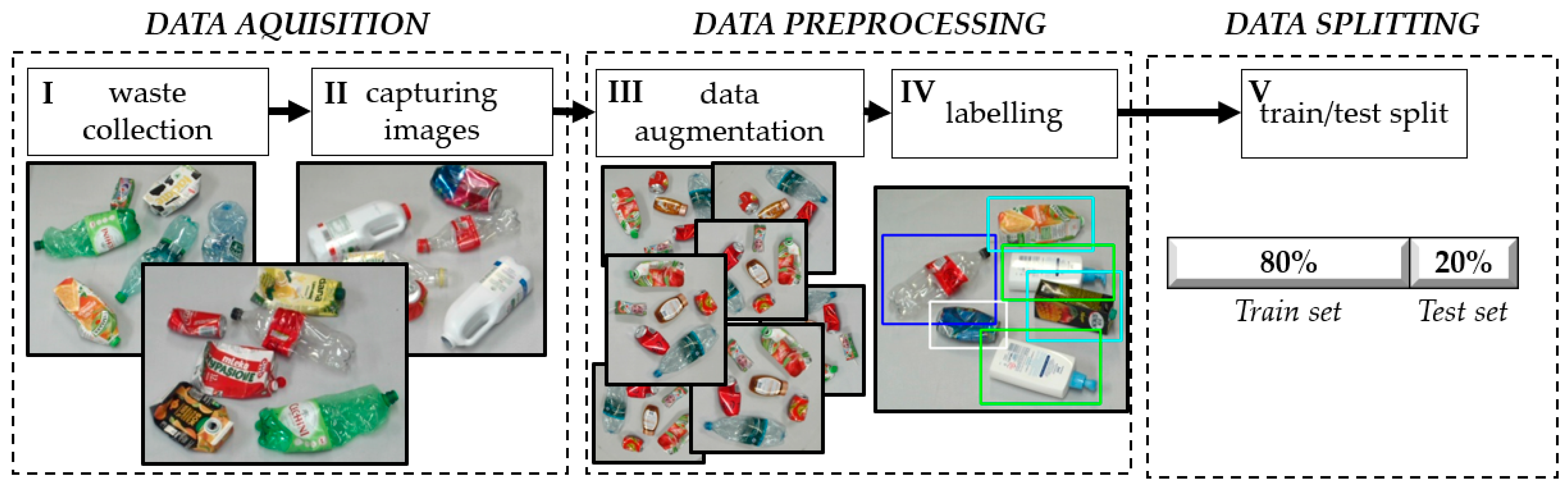
A large-scale dataset, including many plastic waste images of different types, should be implemented in detection and classification models. There are several publicly available datasets with waste images, but they are insufficient for advanced sorting systems. Indeed, effective detection and classification of waste moving along the conveyor requires considering factors such as the piling of waste, the high irregularity of shapes, or the presence of contaminants that are not subjected to sorting. The development of a new complex dataset is the first major action needed when considering the problem of automatic waste identification. In the case of self-built datasets, the procedure for their creation is typically described only briefly in publications. Since the dataset significantly impacts both the learning efficiency and the subsequent performance of the model in a real-world system, this study presents the sequential steps required for the development of a self-built dataset. The main stages of dataset creation for automatic waste identification are presented in Figure 4.
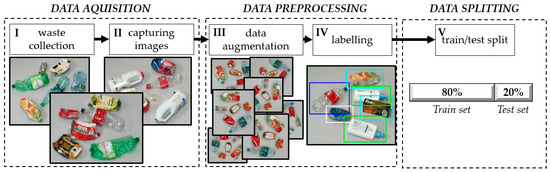
Figure 4.
Main stages of dataset creation for automatic waste identification.
The first two stages are related to the data acquisition process. The input data for detection and classification models consist of images. Therefore, it is necessary to collect waste and subsequently capture images of it. The collected waste should include not only the target objects (Figure 5a) but also contaminants (Figure 5b) that typically appear in real-world sorting facilities due to errors in source separation. Such errors arise because people often misclassify waste, incorrectly assigning non-plastic items to plastic waste bins. Regarding contaminants, it is important to emphasize that their inclusion in a self-built dataset poses the greatest challenge. Contaminants exhibit significantly higher variability compared to the fractions intended for sorting. They may include textiles, wood, glass, paper, and many other materials. For this reason, a detailed representation of contaminants in a self-built dataset is realistically feasible only through the utilization of recorded waste streams from an actual sorting facility. In our study, contaminants were included to a limited extent, with an effort to construct a sample set that is as diverse as possible. We primarily gathered textiles, plastic bags, films, and paper with volumes comparable to those of the detected waste fractions. Additionally, it is necessary to collect multiple instances of the same type of waste to account for the high variation in shape, primarily resulting from different levels of compression.

Figure 5.
Example of collected waste: (a) including only target objects; (b) including contaminants.
The waste classes considered include blue PET, white PET, green PET, HDPE, Tetrapak, and aluminum. For each class, waste was collected while ensuring a balanced number of instances across all categories. The collected waste was then photographed in small groups, positioned differently on the conveyor belt—both in the center and near the edges. Additionally, images were captured with overlapping waste items to reflect real-world conditions.
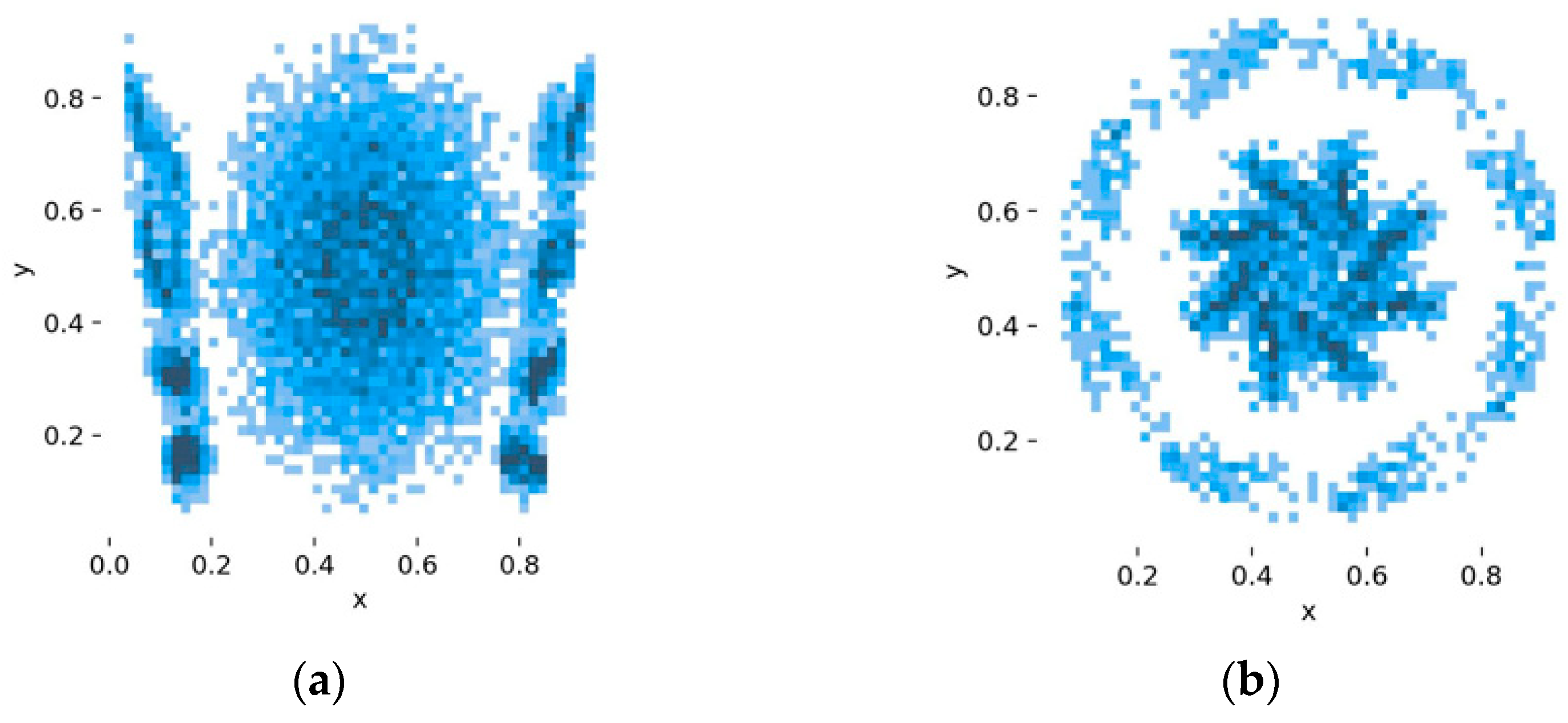
The collected images require preprocessing before being used for model training, which consists of two main steps: augmentation and labeling. Augmentation is optional; however, it is commonly performed to expand the dataset by applying transformations such as rotation or scaling. In contrast, labeling is a mandatory step for training the YOLO model, as it provides the necessary annotations for object detection. In the case of data augmentation for waste moving along a conveyor belt, geometric transformation is a key augmentation technique. In our dataset, we applied rotation. The final dataset, after augmentation, consisted of 2242 images used in models 1A and 1B. This dataset was further expanded with additional images for model 2, specifically for detecting blue PET, white PET, and green PET, resulting in a total of 4042 images. Each image underwent a labeling process involving the annotation of the detected classes. The summary of the applied labels is presented in Figure 6.
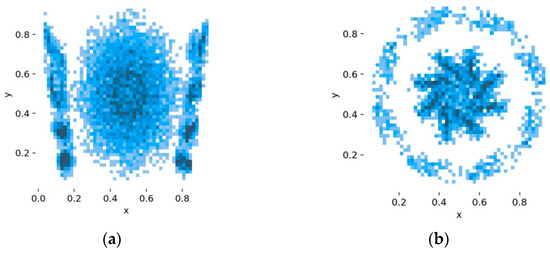
Figure 6.
Distribution of label locations for (a) basic dataset (for model 1a and 1b) and (b) extended dataset (for model 2).
The final step in preparing the dataset for use in the YOLO model is to split it into two parts, the training and test sets, with the most commonly accepted ratio being 80/20.
As a summary, Table 3 presents a set of recommendations for each stage of the dataset creation process for waste identification.
Table 3.
Summary of selected publications from recent years in the area of automatic waste.
2.3. Experimental Environment
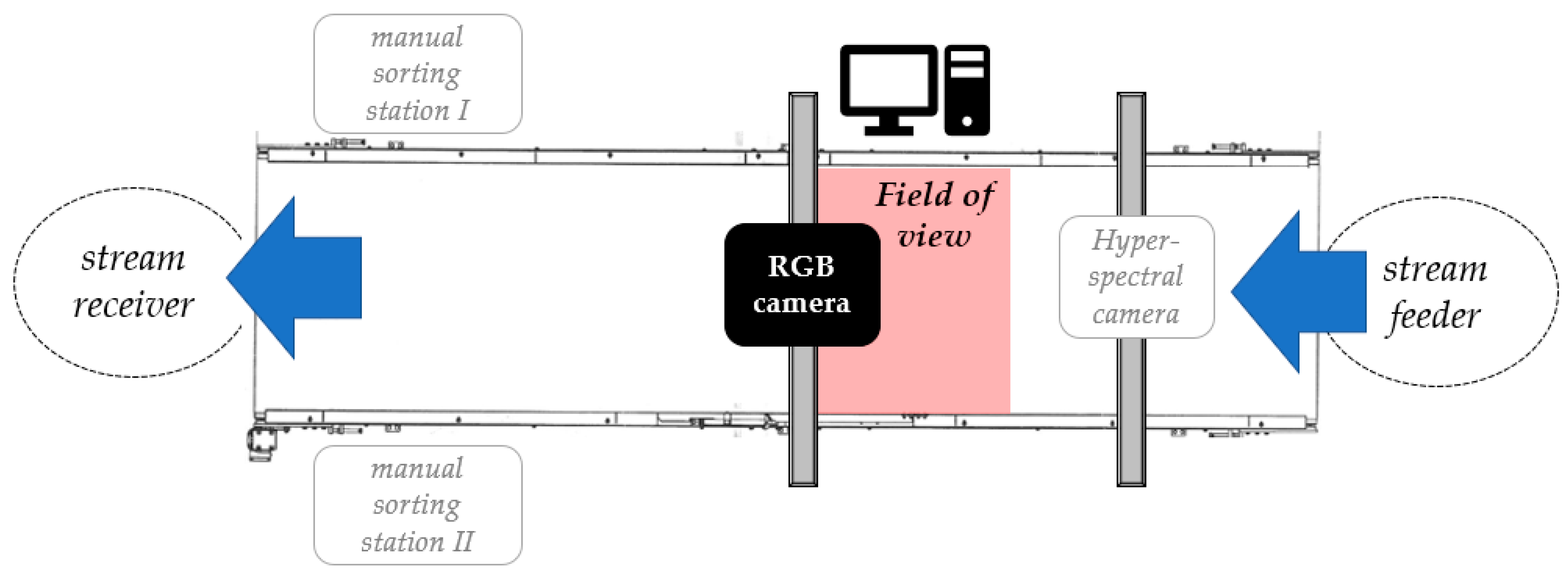
In advanced sorting systems, waste is transported between separating points (i.e., NIR separators, sorting robots, etc.). Effective sorting requires automatic identification at multiple stages of the sorting process (at the beginning—input stream; at the end—sorting residues; and before subsequent separation points). Regardless of the sorting stage, automatic identification using computer vision requires placing an RGB camera above the conveyor transporting the waste. To best replicate real-world conditions for the final model validation, a test bed representing a fragment of a real sorting system was constructed, namely, a manual waste-sorting cabin. The components of the developed test bed include the following:
- Conveyor belt (speed 0–0.5 m/s, 1.2 × 5 m);
- RGB camera positioned above the conveyor (4 K, 30 fps, 5–50 mm zoom lens);
- Computer;
- Input stream feeder;
- Output stream receiver;
- Two manual sorting stations (not considered in this paper);
- Hyperspectral camera (not in the scope of the study).
The scheme of the test bed and its real appearance are shown in Figure 7 and Figure 8, respectively.
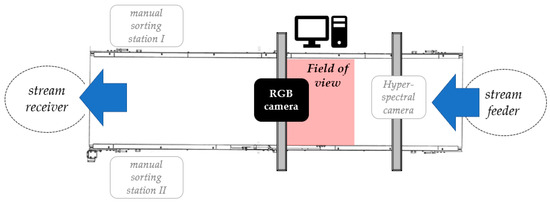
Figure 7.
Scheme of the developed test bed.

Figure 8.
The developed test bed.
2.4. Waste Sample Preparation for Model Validation
The primary limitation of previously applied approaches in automatic waste identification models is testing solutions under laboratory conditions based on a designated subset of the utilized dataset. The final validation of the model should be conducted under real-world conditions, considering the movement of waste along a conveyor. In the absence of access to a real sorting system, this was substituted by constructing a representative fragment of a real system and using waste samples that reflect the morphology of the Polish plastic waste stream.
In Poland, waste segregation is implemented at the source of generation. This means that waste is placed in designated containers for paper, glass, mixed waste, and plastics before collection. Metal waste is also disposed of in the plastic waste container; therefore, aluminum cans were included in the developed dataset.
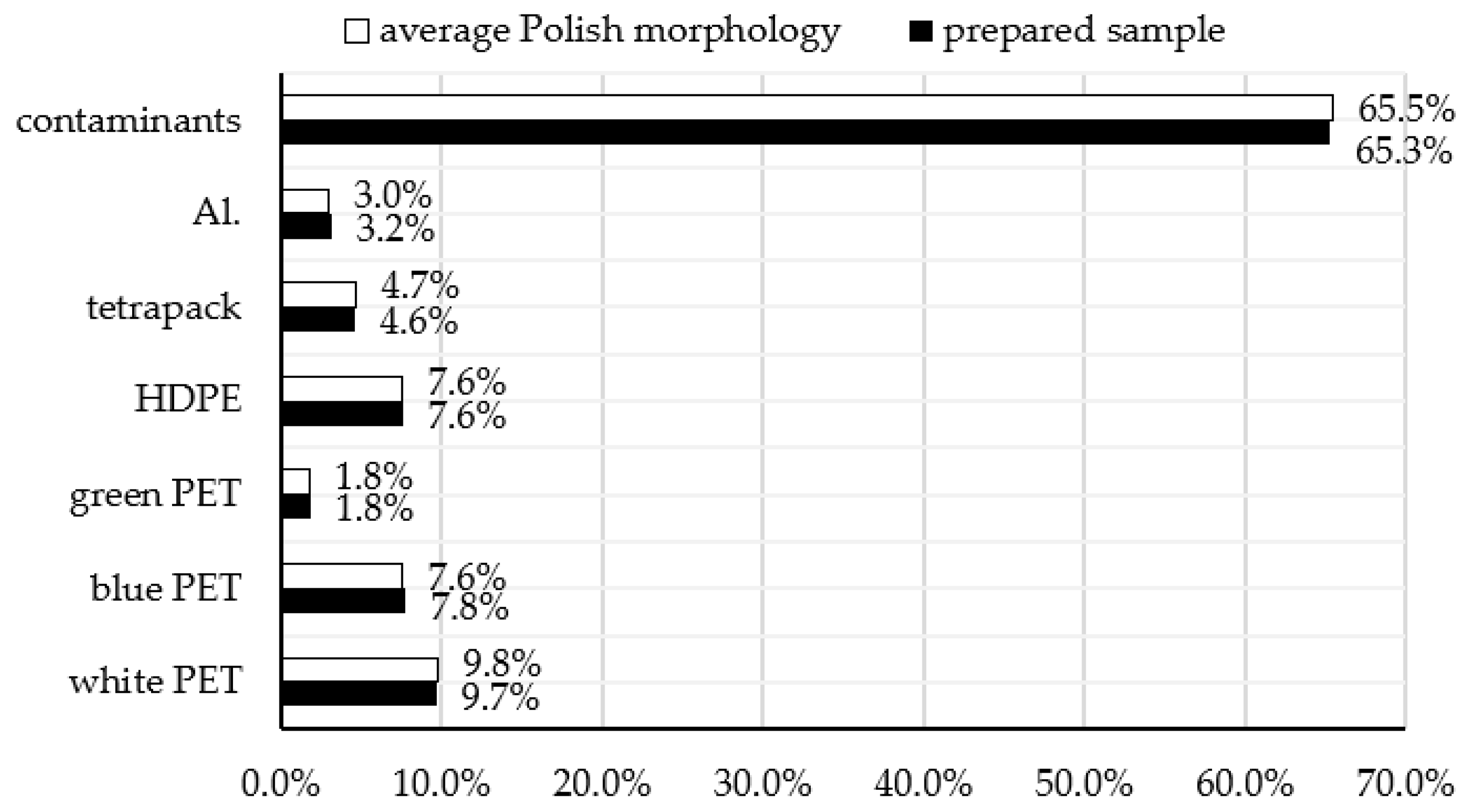
For the final validation of the developed model, a 5 kg waste sample reflecting the morphology of Polish municipal waste was prepared based on the Institute of Environmental Protection—National Research Institute (IOS-PIB) report. The morphology of the prepared sample is shown in Figure 9.
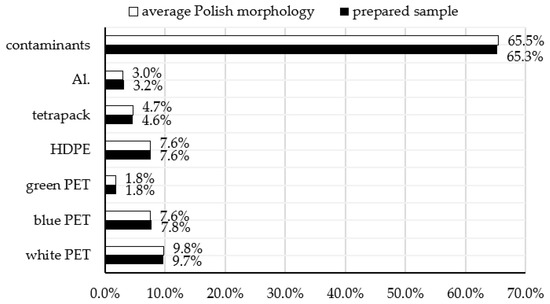
Figure 9.
The morphology of the Polish plastic waste stream compared to the morphology of the prepared sample.
The presented figure confirms the significance of considering contaminants in the development of automatic identification models. In the average morphology of the Polish plastic waste stream, contaminants account for more than 50%.
3. Results
3.1. Model Performance Based on Validation Data Separated from the Self-Built Dataset
The proposed automatic waste stream identification model is based on three YOLOv5 models. The performance of each model was evaluated using precision, recall, and mean average precision (mAP), which are commonly used evaluation metrics for detection problems [27]. In the learning stage of the model, the indicated metrics represent a global perspective without considering each class separately.
Precision indicates the ratio of correct object detections (TP) to the total number of detections (both correct TP and incorrect FP), defined as follows:
Recall represents the ratio of correct object detections to the total number of actual objects, defined as follows:
Mean average precision (mAP) denotes the average performance of the detector across all recall values, which is equivalent to the area under the precision–recall curve. It can be mathematically expressed as Equation (4):
In addition, it measures the performance of an object detection model by averaging the area under the precision–recall curve across all classes. In this context, mAP_0.5 represents the average precision computed at a fixed IoU threshold of 0.5, whereas mAP_0.5:0.95 is a more rigorous and comprehensive metric, averaging precision over multiple IoU thresholds from 0.5 to 0.95 in increments of 0.05.
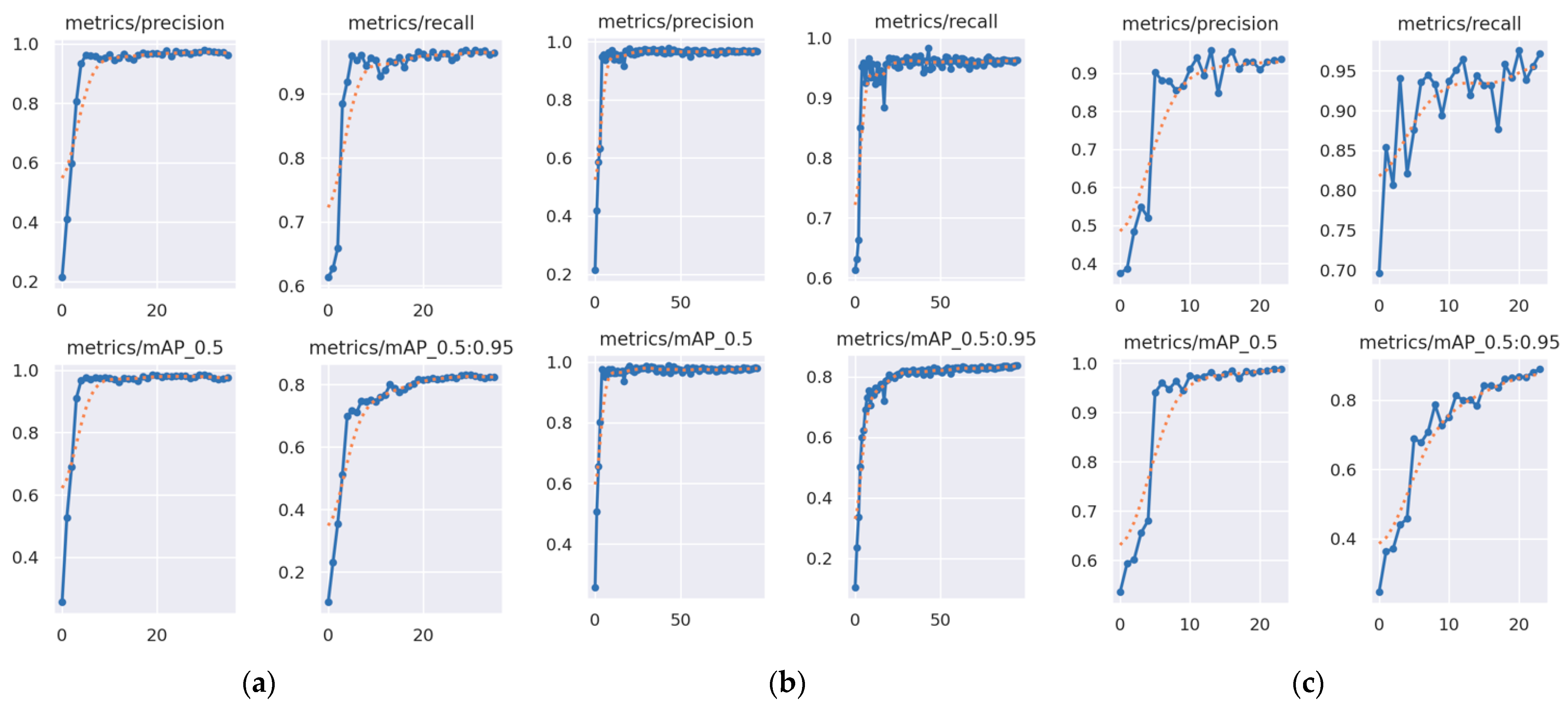
The progression of precision, recall, and mAP throughout the YOLOv5 training process for each of the three models used is presented in Figure 10.
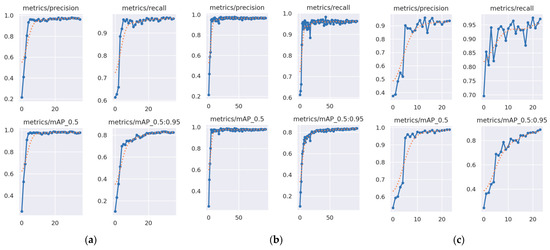
Figure 10.
Progression of precision, recall, and mAP throughout the YOLOv5 training process (actual results with solid line and smoothed trend with dotted line) for (a) model 1a, (b) model 1b, and (c) model 2.
The comparison of the final performance metrics for each of the three models is presented in Table 4.
Table 4.
Comparison of the final performance metrics of each model.
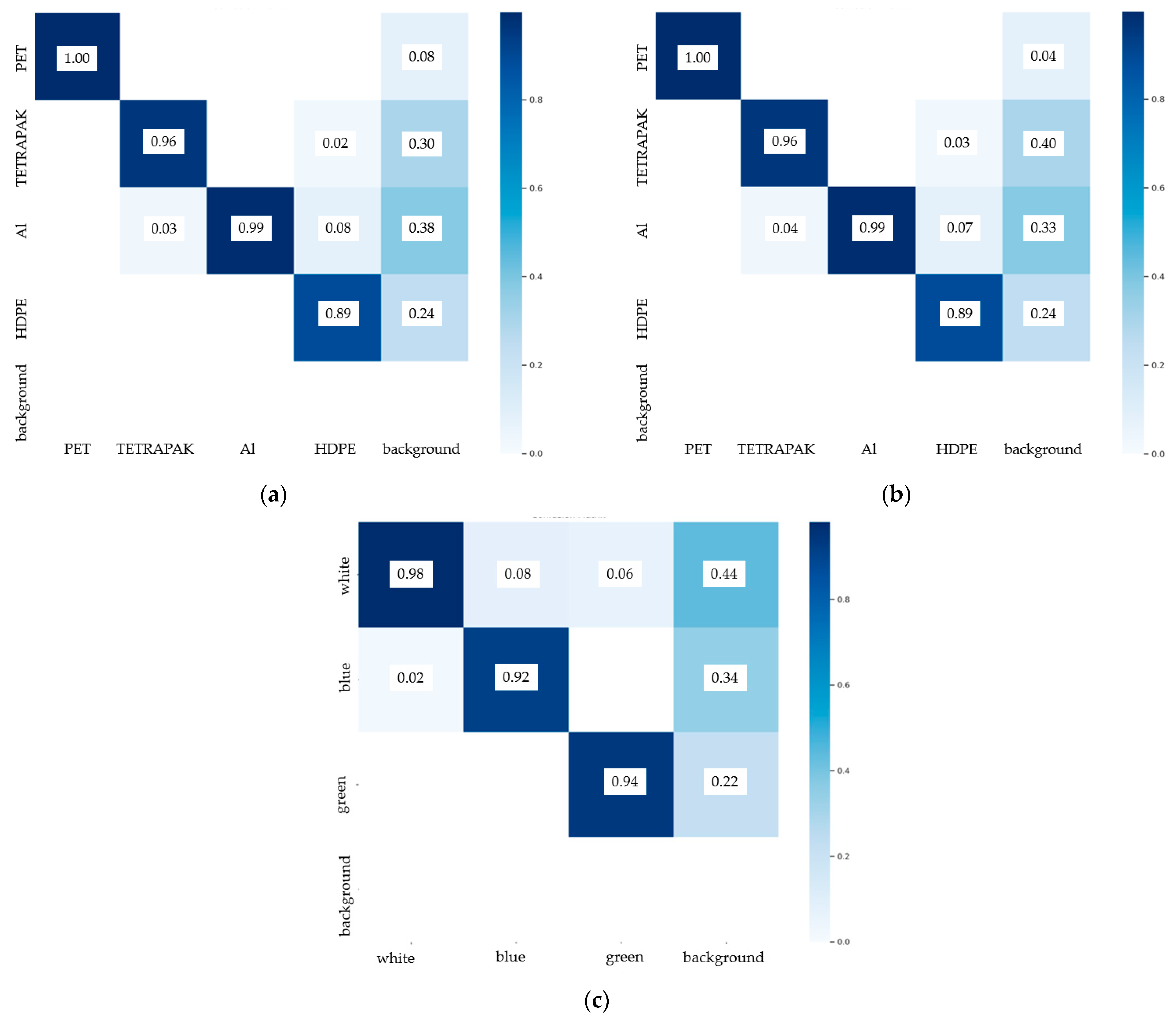
Additionally, Figure 11 presents the confusion matrices generated by the trained YOLO models.
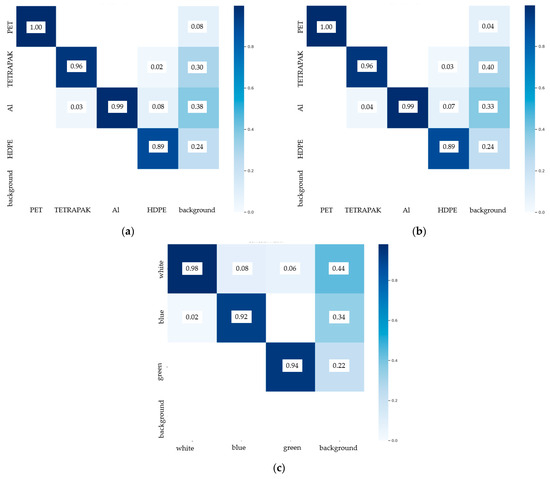
Figure 11.
Confusion matrices generated by the trained YOLO models: (a) model 1a, (b) model 1b, and (c) model 2.
3.2. Model Performance Under Replicated Real-World Conditions
The lack of access to the real system was replaced by its replica in laboratory conditions using the developed test bed (described in Section 2.3). The mapping of real conditions mainly focused on using a conveyor with parameters consistent with those used in a real waste-sorting plant, using a waste stream with real-world morphology, and repeatedly loading the stream onto the conveyor to generate a random arrangement of waste with occlusion effects. The model was tested using waste samples with average Polish morphology (described in Section 2.4) moving at a speed of 0.2 m/s on the conveyor. The sample was fed onto the conveyor eight times consecutively. The visualization of the model’s performance under conditions replicating a real-world sorting facility is presented in Figure 12.

Figure 12.
The visualization of the model’s performance under conditions replicating a real-world sorting facility (the red box shows detected HDPE, while the pink one – tetrapak).
The final results (model output) were analyzed to determine the accuracy, precision, recall, and F1-score for each detected class. These metrics are calculated based on four groups of results for each class separately:
- TPs—True Positives (e.g., HDPE detected, which is actually HDPE);
- FPs—False Positives (e.g., HDPE detected, which is actually a different fraction);
- TNs—True Negatives (e.g., a fraction other than HDPE detected, which is actually a fraction other than HDPE);
- FNs—False Negatives (e.g., HDPE not detected).
The comparison of the final performance metrics for each class is presented in Table 5.
Table 5.
Comparison of the final performance metrics for each class.
4. Discussion
The primary performance measures of models 1a, 1b, and 2 show that model 2 is the best overall, achieving the highest recall and mAP values, making it the most accurate and generalizable. Model 1b offers a good balance between precision and recall, slightly outperforming 1a in mAP. The combination of high recall (1a), high precision (1b), and strong classification accuracy (2) suggests an optimized pipeline that balances detection and classification accuracy. Model 1a focuses on detecting Tetrapak, aluminum, and PET, while model 1b is trained primarily for HDPE detection. This approach improves the accuracy of HDPE detection, which is often more challenging. Since model 1b disregards all non-HDPE objects, and model 1a does not output HDPE, the system minimizes false detections and enhances classification confidence. Model 2 improves the accuracy of sorting PET based on color, which is crucial for recycling.
The confusion matrices indicate that the additional model trained for HDPE successfully eliminated the misclassification of HDPE as PET. It is also evident that model 1a struggles with detecting HDPE, often confusing it with Tetrapak and aluminum. Additionally, each model occasionally detects background objects due to contamination resembling the target fractions. Therefore, the proposed model effectively detects the assigned waste classes, but a significant challenge remains in misclassifying contaminants as sortable objects. This highlights the importance of introducing contaminants into self-built datasets for automatic waste identification, as real-world waste streams often contain more contaminants than recyclable materials—a situation particularly relevant in countries such as Poland. In further research, a more comprehensive examination of contaminants in the stream should be planned. Regarding misclassification problems, given that our dataset is balanced, future focus should be placed on post-processing techniques such as threshold adjustment and non-maximum suppression (NMS). Adjusting the confidence threshold could help reduce false positives by filtering out low-confidence detections while maintaining high recall. Additionally, fine-tuning the NMS parameters can mitigate cases where multiple overlapping detections are incorrectly assigned to different classes. These refinements would improve the model’s precision and robustness, particularly in complex waste streams where object occlusion and visual similarities between classes pose additional challenges.
The final validation eliminated a key limitation present in most models available in the literature, which are typically not tested under real-world conditions. A binary classification accuracy ranging from 0.94 to 0.98 indicates a high level of correct detections among all identified objects. If an object is classified, the probability of assigning it to the wrong class remains low. The achieved precision values, ranging from 0.89 to 1.00, demonstrate high classification accuracy for each waste fraction. Once an object is detected, the model very rarely misclassifies it. The highest probability of such an error, at 0.11, was observed for the Tetrapak fraction. The recall values can also be considered high. The lowest recall was recorded for HDPE (0.76), while recall values ranged between 0.85 and 0.9 for the remaining fractions. These values indicate a low probability of failing to detect an object of a given class. PET classes (blue, green, and white) show strong overall performance, with particularly high precision, but there is room to improve recall, especially for green and white PET. Tetrapak and aluminum have a good balance of precision and recall, with minor improvements possible in precision for Tetrapak. HDPE is the weakest in terms of recall, which could mean that more HDPE objects are not being detected. Given the challenges associated with HDPE detection, a recall of 0.76 can be considered acceptable. However, it remains the lowest recall among all detected fractions, highlighting an area for improvement. Since the dataset is balanced, rebalancing techniques will not be applicable in this case. Therefore, potential corrective actions should focus on hyperparameter tuning to enhance HDPE detection performance.
Under conditions that replicate real-world scenarios, the results remain within acceptable limits, indicating a high potential for the practical applicability of the developed model in waste-sorting systems.
Potential Enhancements to Existing Solid Waste Management Technologies
The satisfactory results discussed above generate several possibilities for their application, thereby contributing to the advancement of existing solid waste management solutions. The developed model can be applied in the following areas:
- Real-time system monitoring—The developed model enables continuous real-time waste stream composition monitoring. This capability facilitates the detection of stream variations. By providing instant feedback, it supports decision making.
- Data collection layer of the waste-sorting system’s Digital Twin—A fundamental characteristic of Digital Twins is the bidirectional data flow, which involves both data acquisition and system control. The proposed model is a foundational component for the development of the data collection layer within a Digital Twin framework, specifically in the context of waste composition.
- Waste-sorting system control—The automatic identification of waste stream composition enables dynamic process adjustments and improved operational control in sorting facilities.
- Sensor-based sorting—The integration of the proposed model with sensor-based sorting technologies enhances the efficiency of automated waste separation. By providing accurate and high-speed waste identification, the model supports optical sorters and robotic sorting systems operation.
5. Conclusions
In advanced waste sorting systems, the automatic identification of the waste stream is crucial to efficiently separate materials intended for recycling and contribute to advancing sustainability goals. It is primarily used by automated and robotic sorting components but also for monitoring the waste stream at various stages of processing, which enables the system to be controlled. The waste detection and classification model presented in this paper is one of the components of the municipal waste-sorting system’s Digital Twin, which is a part of the ongoing project “Cyber-physical waste stream control system”. The proposed model is based on the combination of three YOLOv5 models focused on classifying elements of the waste stream into the following classes: blue PET, white PET, green PET, HDPE, tetrapak, and aluminum. The model was trained using a self-built dataset, and its performance was validated in a replica of a real-world sorting system fragment.
The next step in the development of the data collection layer of the Digital Twin is the application of a lidar sensor for measuring the volume of transported waste. The developed model focuses only on the composition of the waste stream, i.e., detecting the number of pieces of waste needed to be sorted. From the point of view of the sorting system control and in the context of the requirements of the Digital Twins, knowledge only of the stream composition is insufficient. In fact, the composition of the stream must be supplemented with information about its size. This size can be partially estimated by mass using the detection results by assuming constant weights of the detected fractions. However, this does not take into account contaminants, so the size determined in this way may be severely underestimated. Therefore, the automatic detection of stream composition should be complemented by volume measurement. The final fusion of the RGB camera with the lidar sensor will enable the real-time collection of all key characteristics of the waste stream, including morphology, as well as volumetric and mass measurements.
Author Contributions
Conceptualization, R.G. and A.D.; methodology, R.G.; software, M.F.; validation, R.G., A.D. and M.F.; formal analysis, R.G.; investigation, A.D. and M.F.; resources, R.G. and A.D.; data curation, M.F.; writing—original draft preparation, A.D.; writing—review and editing, R.G.; visualization, A.D.; supervision, R.G.; project administration, R.G.; funding acquisition, R.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by The National Centre for Research and Development, LEADER program, grant number 0212/L-13/2022. The APC was funded by the Faculty of Mechanical Engineering, Wroclaw University of Science and Technology.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets presented in this article are not readily available because the data are part of an ongoing research project.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of the data; in the writing of the manuscript; or in the decision to publish the results.
References
- Alhazmi, H.; Almansour, F.H.; Aldhafeeri, Z. Plastic waste management: A review of existing life cycle assessment studies. Sustainability 2021, 13, 5340. [Google Scholar] [CrossRef]
- Milios, L.; Davani, A.E.; Yu, Y. Sustainability impact assessment of increased plastic recycling and future pathways of plastic waste management in Sweden. Recycling 2018, 3, 33. [Google Scholar] [CrossRef]
- Arbeláez-Estrada, J.C.; Vallejo, P.; Aguilar, J.; Tabares-Betancur, M.S.; Ríos-Zapata, D.; Ruiz-Arenas, S.; Rendón-Vélez, E. A Systematic Literature Review of Waste Identification in Automatic Separation Systems. Recycling 2023, 8, 86. [Google Scholar] [CrossRef]
- Satav, A.G.; Kubade, S.; Amrutkar, C.; Arya, G.; Pawar, A. A state-of-the-art review on robotics in waste sorting: Scope and challenges. Int. J. Interact. Des. Manuf. 2023, 17, 2789–2806. [Google Scholar] [CrossRef]
- Lubongo, C.; Alexandridis, P. Assessment of Performance and Challenges in Use of Commercial Automated Sorting Technology for Plastic Waste. Recycling 2022, 7, 11. [Google Scholar] [CrossRef]
- Tanguay-Rioux, F.; Legros, R.; Spreutels, L. On the limits of empirical partition coefficients for modeling material recovery facility unit operations in municipal solid waste management. J. Clean. Prod. 2021, 293, 126016. [Google Scholar] [CrossRef]
- Tanguay-Rioux, F.; Spreutels, L.; Héroux, M.; Legros, R. Mixed modeling approach for mechanical sorting processes based on physical properties of municipal solid waste. Waste Manag. 2022, 144, 533–542. [Google Scholar] [CrossRef]
- Kroell, N.; Chen, X.; Greiff, K.; Feil, A. Optical sensors and machine learning algorithms in sensor-based material flow characterization for mechanical recycling processes: A systematic literature review. Waste Manag. 2022, 149, 259–290. [Google Scholar] [CrossRef]
- Lu, W.; Chen, J. Computer vision for solid waste sorting: A critical review of academic research. Waste Manag. 2022, 142, 29–43. [Google Scholar] [CrossRef]
- Xia, W.; Jiang, Y.; Chen, X.; Zhao, R. Application of machine learning algorithms in municipal solid waste management: A mini review. Waste Manag. Res. 2022, 40, 609–624. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J. Sensor-Based Technologies in Effective Solid Waste Sorting: Successful Applications, Sensor Combination, and Future Directions. Environ. Sci. Technol. 2022, 56, 17531–17544. [Google Scholar] [CrossRef]
- Maier, G.; Gruna, R.; Langle, T.; Beyerer, J. A Survey of the State of the Art in Sensor-Based Sorting Technology and Research. IEEE Access 2024, 12, 6473–6493. [Google Scholar] [CrossRef]
- Son, J.; Ahn, Y. AI-based plastic waste sorting method utilizing object detection models for enhanced classification. Waste Manag. 2025, 193, 273–282. [Google Scholar] [CrossRef]
- Ali, M.L.; Zhang, Z. The YOLO Framework: A Comprehensive Review of Evolution, Applications, and Benchmarks in Object Detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- Zhou, Q.; Liu, H.; Qiu, Y.; Zheng, W. Object Detection for Construction Waste Based on an Improved YOLOv5 Model. Sustainability 2023, 15, 681. [Google Scholar] [CrossRef]
- Ren, Y.; Li, Y.; Gao, X. An MRS-YOLO Model for High-Precision Waste Detection and Classification. Sensors 2024, 24, 4339. [Google Scholar] [CrossRef]
- Choi, J.; Lim, B.; Yoo, Y. Advancing Plastic Waste Classification and Recycling Efficiency: Integrating Image Sensors and Deep Learning Algorithms. Appl. Sci. 2023, 13, 10224. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, J.; Zhao, L.; Zhang, H.; Li, L.; Ji, Z.; Ganchev, I. Detection of River Floating Garbage Based on Improved YOLOv5. Mathematics 2022, 10, 4366. [Google Scholar] [CrossRef]
- Fan, J.; Cui, L.; Fei, S. Waste Detection System Based on Data Augmentation and YOLO_EC. Sensors 2023, 23, 3646. [Google Scholar] [CrossRef]
- Liu, S.; Chen, R.; Ye, M.; Luo, J.; Yang, D.; Dai, M. Methodology for Real-Time Detection of Domestic Waste. Sensors 2024, 24, 4666. [Google Scholar] [CrossRef]
- Werbińska-Wojciechowska, S.; Giel, R.; Winiarska, K. Digital Twin approach for operation and maintenance of transportation system—systematic review. Sensors 2024, 24, 6069. [Google Scholar] [CrossRef]
- Giel, R.; Dąbrowska, A. A Digital Twin framework for cyber-physical waste stream control system towards Reverse Logistics 4.0. Logforum 2024, 20, 297–306. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Katsamenis, I.; Karolou, E.E.; Davradou, A.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Kalogeras, D. TraCon: A Novel Dataset for Real-Time Traffic Cones Detection Using Deep Learning. Lect. Notes Netw. Syst. 2023, 556, 382–391. [Google Scholar] [CrossRef]
- Jia, X.; Tong, Y.; Qiao, H.; Li, M.; Tong, J.; Liang, B. Fast and accurate object detector for autonomous driving based on improved YOLOv5. Sci. Rep. 2023, 13, 1–13. [Google Scholar] [CrossRef]
- Sirisha, U.; Praveen, S.P.; Srinivasu, P.N.; Barsocchi, P.; Bhoi, A.K. Statistical Analysis of Design Aspects of Various YOLO-Based Deep Learning Models for Object Detection. Int. J. Comput. Intell. Syst. 2023, 16, 1–29. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).