
A Garbage Detection and Classification Model for Orchards Based on Lightweight YOLOv7


Abstract
:1. Introduction
2. Related Work
2.1. Dataset
2.2. Garbage Classification Model
- ResNet-based methods. An intelligent garbage classification system based on ResNet50 and Support Vector Machine (SVM) was proposed by Adedeji et al. [15]. It employed ResNet50 for feature extraction and SVM to categorise the extracted features with an accuracy of 87% on the Trash dataset. Yaqing G, based on ResNet50, designed a lightweight garbage classification model, GA_MobileNet [16]. It reduces the computational effort and parameters by using deep convolution and grouped convolution, and improves the accuracy of the model by channel attention mechanism. The proposed methodology addresses the issue of garbage classification on embedded devices.
- DenseNet-based methods. Susanth G S et al. validated VGG16, AlexNet, ResNet50, DesneNet169 on the dataset TrashNet and found that DenseNet169 performs better and achieves 94.9% detection accuracy [17]. Mao W L et al. used a genetic algorithm to optimise the hyperparameters of the DenseNet121 fully connected layer to improve the accuracy [18]. Experimentally, it was demonstrated that using two fully connected layers as classifiers for DenseNet121 performs better on the garbage classification task than the original DenseNet121 equipped with full-domain average pooling and softmax classifiers.
- Methods based on the combination of transfer learning and convolutional neural networks. Feng J et al. proposed a method for garbage image classification based on transfer learning and Inception-v3 [19,20], which retains the excellent feature extraction capability of the Inception-v3 model while being able to have high recognition accuracy when there is insufficient image data. Cao L used transfer learning to train a model specifically for recognising garbage categories based on the Inception-v3 model, using transfer learning to train a model specialised in recognising garbage categories, improving the recognition rate through algorithmic research and model modification [21]. Yang et al. developed a novel framework called GarbageNet for incremental learning, to address the problems of a lack of sufficient garbage image data, high cost of category incrementation and noisy labels [22]. Their approach uses an incremental learning method to make the model continuously learn and update from new samples, while eliminating the effect of noisy labels through AFM (AttentiveFeatureMixup). Chen Yu et al. proposed a garbage classification method based on the improved YOLO algorithm, which uses CSPDarknet-53 as the backbone feature extraction network, effectively solving the problem of excessive inference computation and ensuring the accuracy of the model. Meanwhile, by adding several new spatial pyramid pooling (SPP) modules, a better fusion of global and local features is achieved [23].
3. Methodology
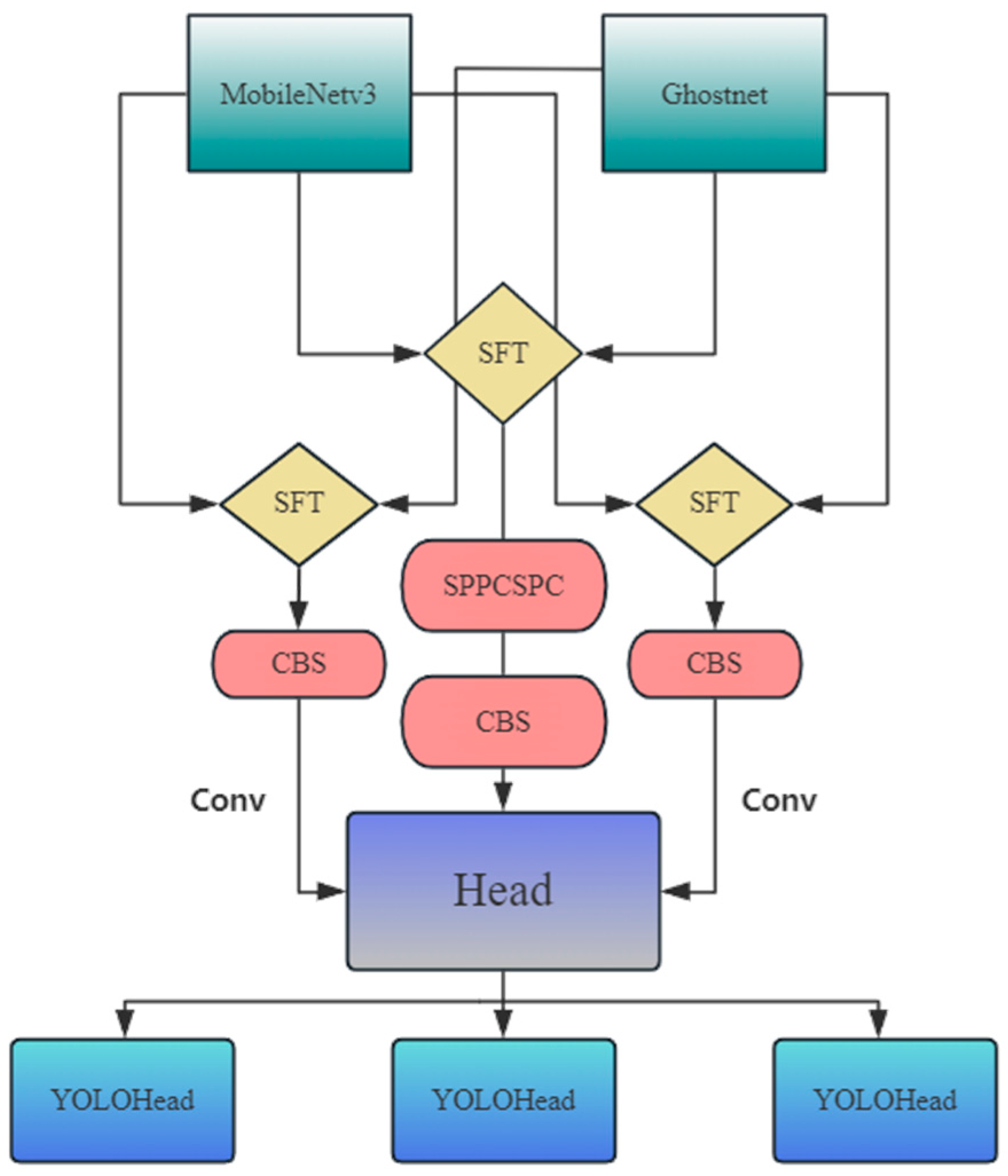
3.1. YOLO Algorithm
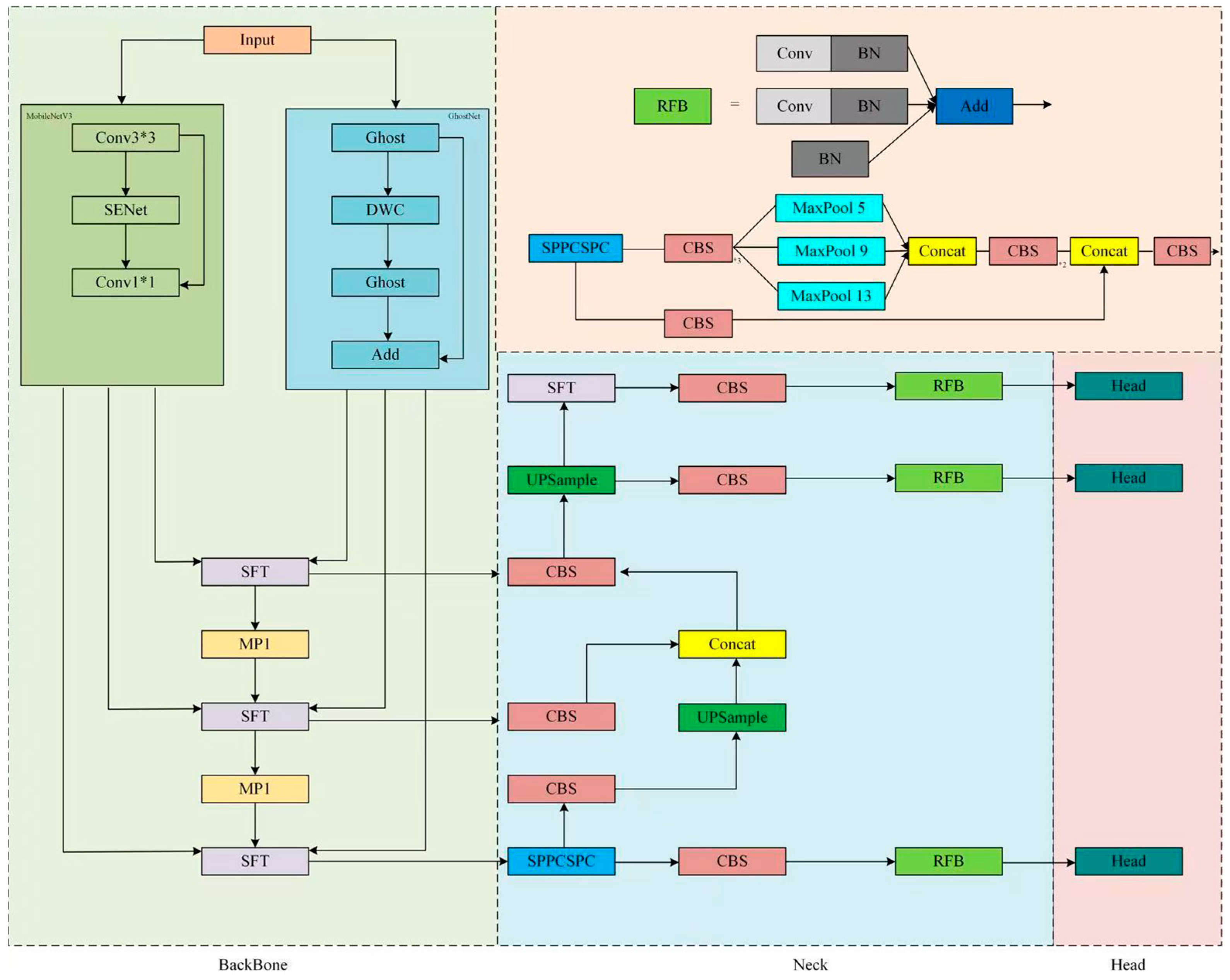
3.2. Lightweight Backbone Network
3.3. Semantic Feature-Wise Relation Network
FFM (Feature Fusion Module)
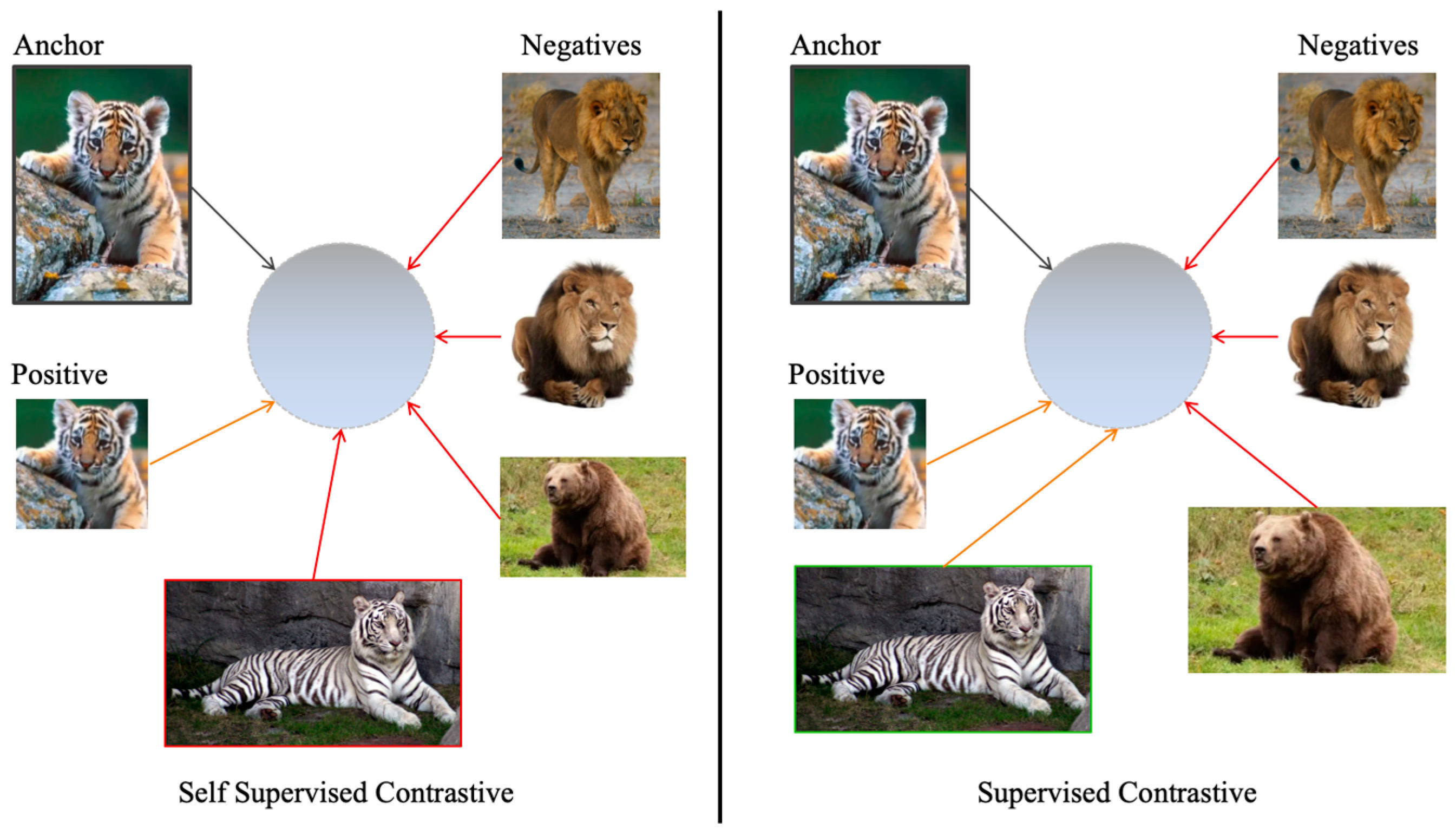
3.4. Contrastive Learning
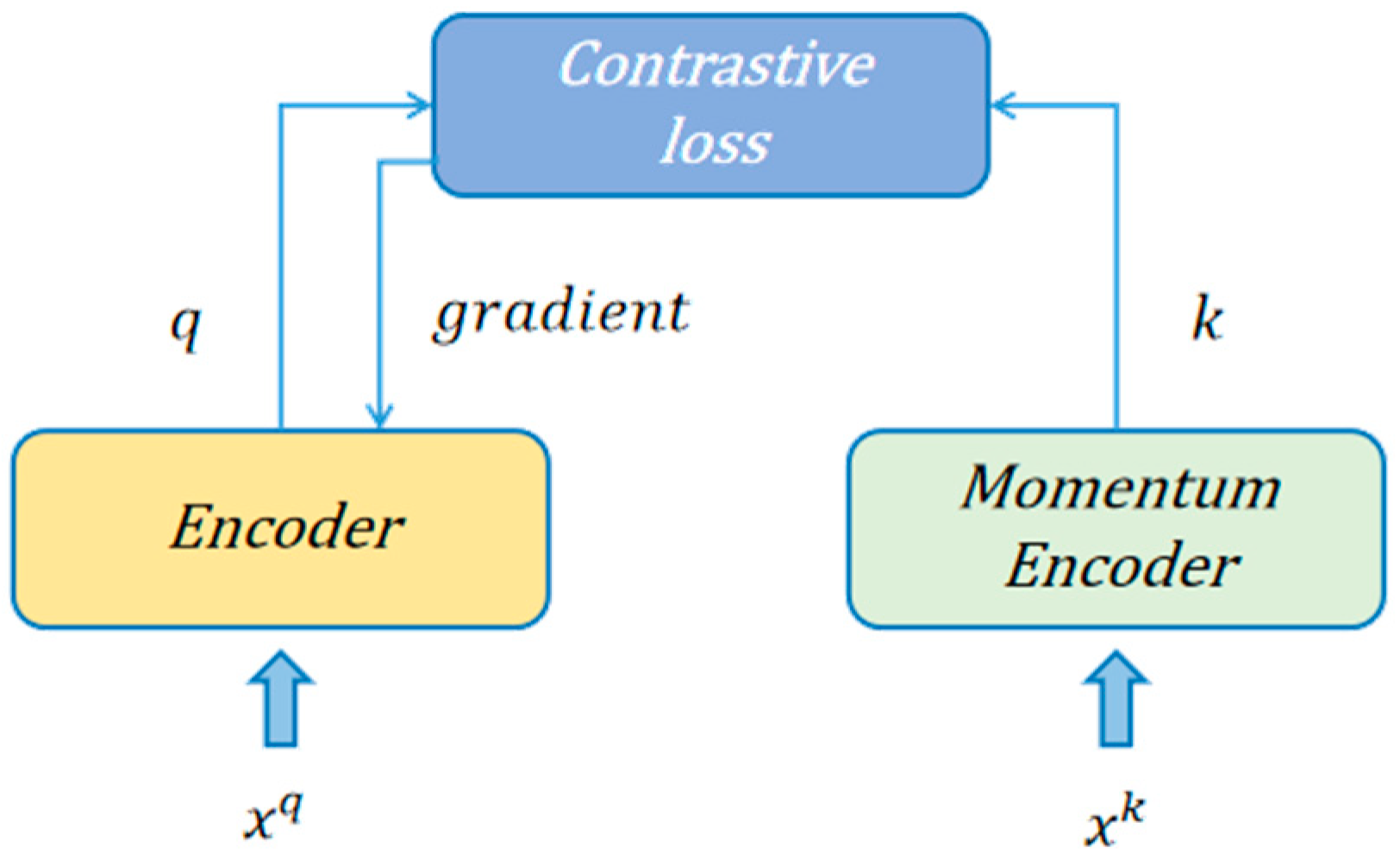
3.4.1. Self-Supervised Contrastive Learning
3.4.2. Supervised Contrastive Learning
3.5. Loss Function
4. Experiment and Result
4.1. Dataset Collation
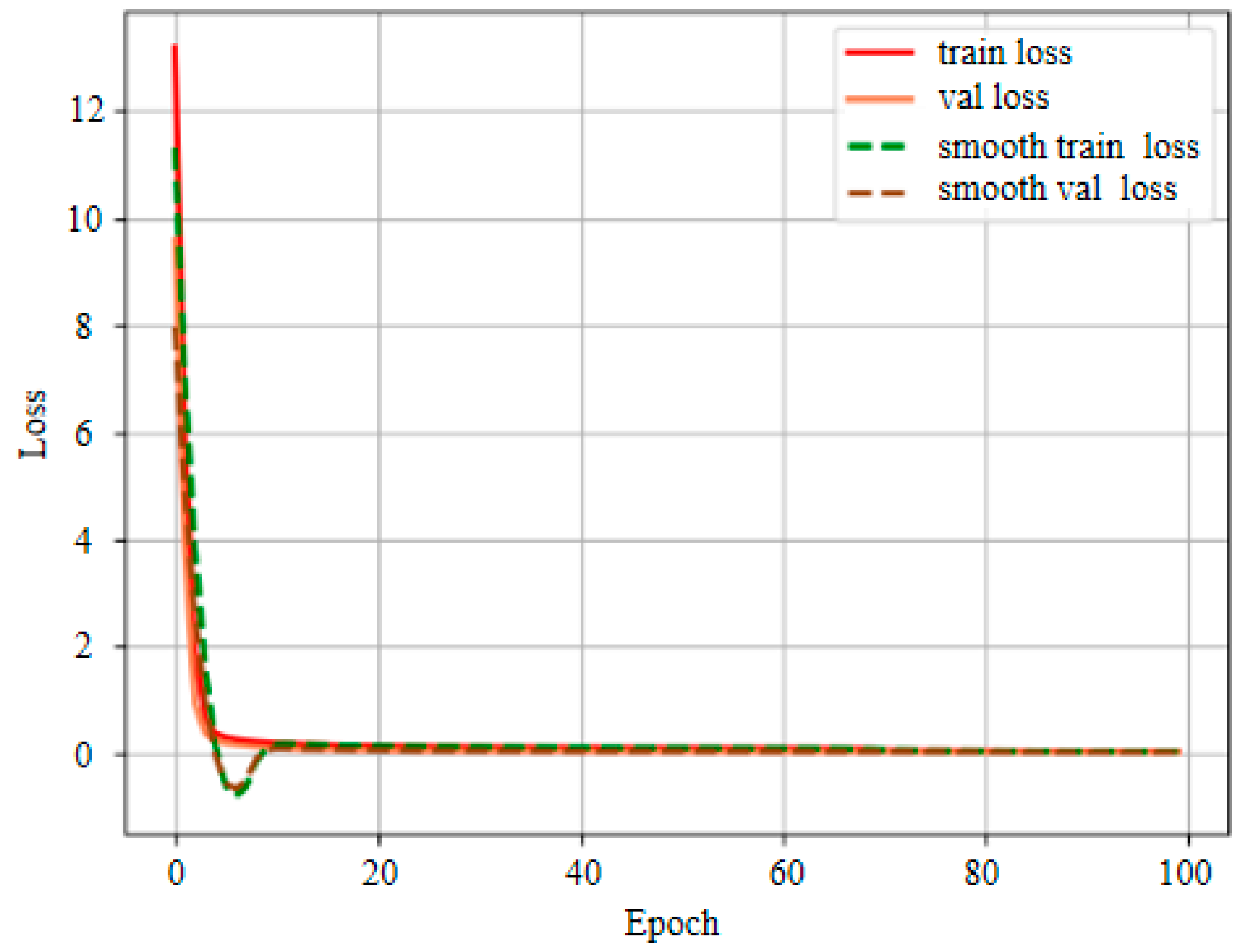
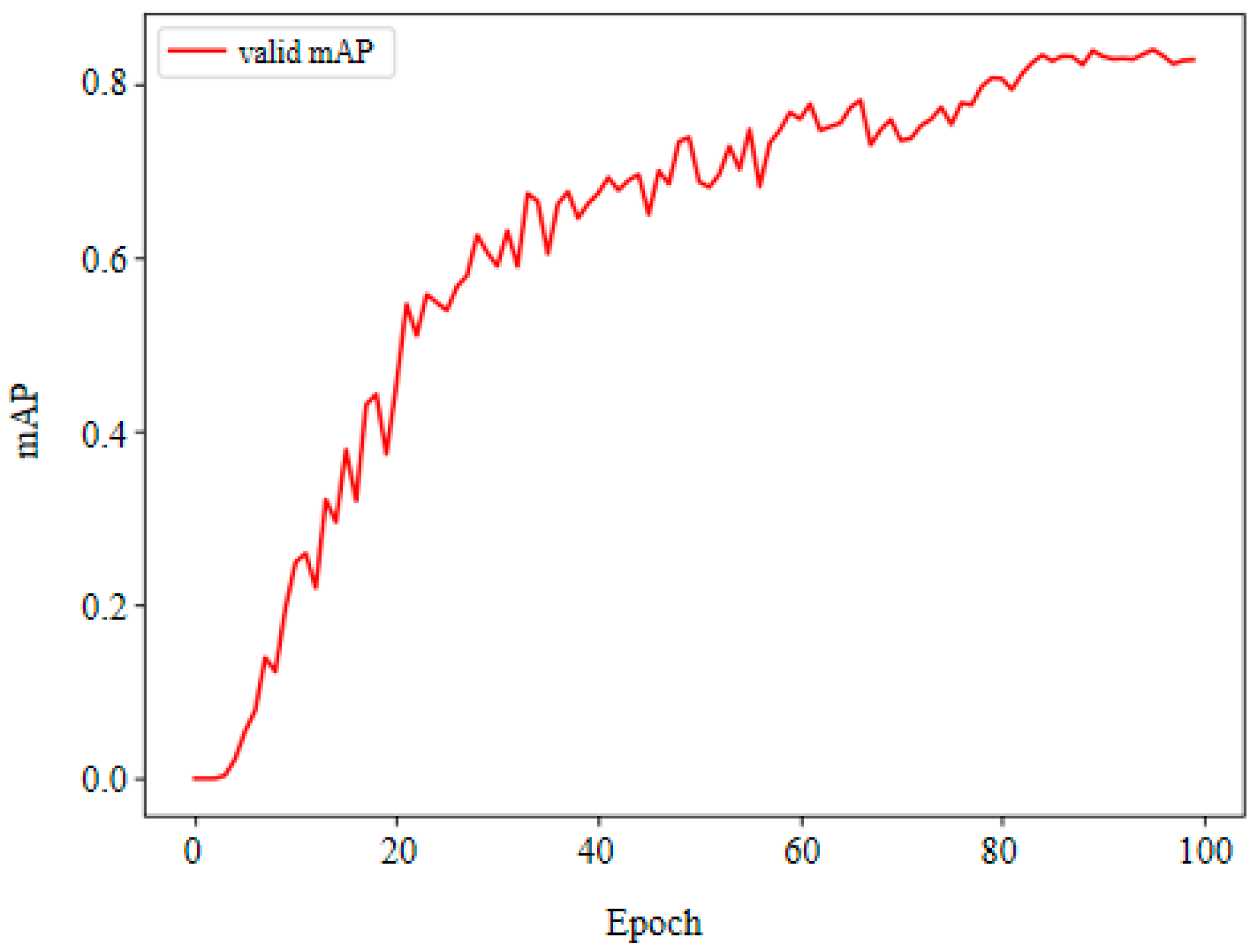
4.2. Experimental Settings
4.3. Evaluation Indicators
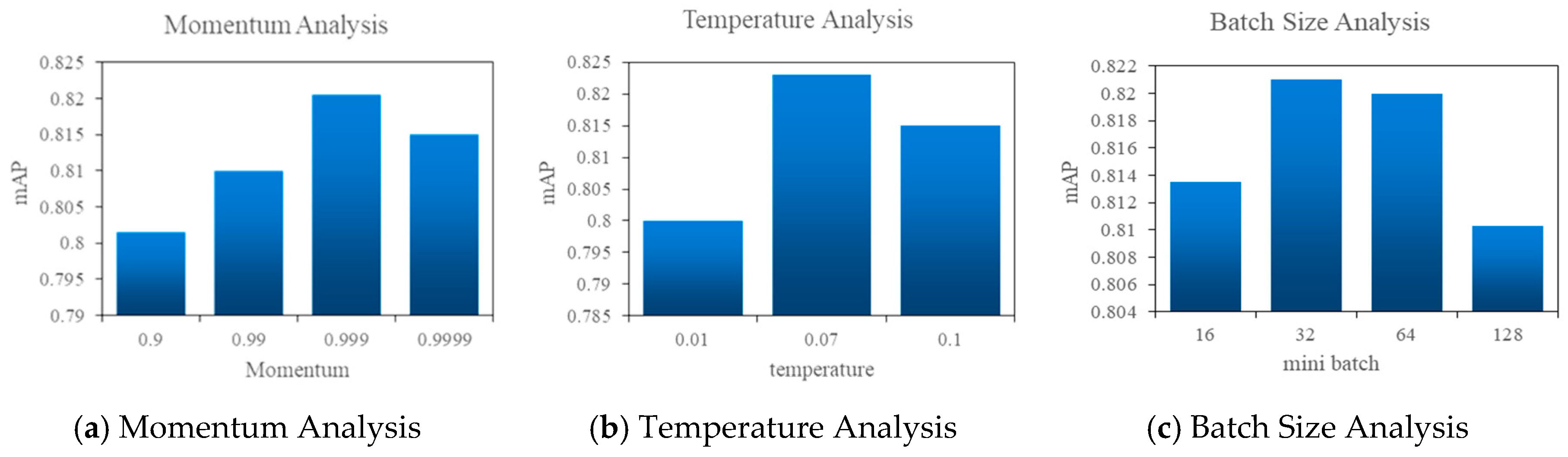
4.4. Hyperparametric Sensitivity Analysis for Contrastive Learning
4.5. Ablation Experiment
4.5.1. Analysis of Lightweight Models
4.5.2. Analysis of Convergence Layer Strategy
4.6. Contrastive Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koop, S.H.; van Leeuwen, C.J. The challenges of water, waste and climate change in cities. Environ. Dev. Sustain. 2017, 19, 385–418. [Google Scholar] [CrossRef]
- Tripathi, N.; Hills, C.D.; Singh, R.S.; Atkinson, C.J. Biomass waste utilisation in low-carbon products, harnessing a major potential resource. Clim. Atmos. Sci. 2019, 2, 1–10. [Google Scholar] [CrossRef]
- Seidavi, A.; Zaker-Esteghamati, H.; Scanes, C.G. Byproducts from Agriculture and Fisheries: Adding Value for Food, Feed, Pharma and Fuels; John Wiley & Sons: Hoboken, NJ, USA, 2019; pp. 1–10. [Google Scholar]
- Xu, H.Y. Development Report on Treatment Industry of Urban Domestic Refuse in 2017. China Environ. Prot. Ind. 2018, 7, 9–15. [Google Scholar]
- Zhang, L. The Legal Theory and Practice of Citizens’ Environmental Legal Obligations: A Study Sample of Garbage Classification and Disposal. J. China Univ. Polit. Sci. Law 2021, 3, 32–42. [Google Scholar]
- Gong, F.; Deng, C.; Dai, Y. Summary of collection and pre-treatment processes for urban household waste. China Eng. Consult. 2017, 2, 72–74. [Google Scholar]
- Islam, M.S.B.; Sumon, M.S.I.; Majid, M.E.; Kashem, S.B.A.; Nashbat, M.; Ashraf, A.; Khandakar, A.; Kunju, A.K.A.; Hasan-Zia, M.; Chowdhury, M.E. ECCDN-Net: A deep learning-based technique for efficient organic and recyclable waste classification. Waste Manag. 2025, 193, 363–375. [Google Scholar] [CrossRef]
- Hurst, W.; Ebo Bennin, K.; Kotze, B.; Mangara, T.; Nnamoko, N.; Barrowclough, J.; Procter, J. Solid Waste Image Classification Using Deep Convolutional Neural Network. Infrastructures 2022, 7, 47. [Google Scholar] [CrossRef]
- Liu, Y. Four feasible methods for urban waste treatment. Dev. Orientat. Build. Mater. 2014, 12, 82. [Google Scholar]
- Yang, M.; Thung, G. Classification of Trash for Recyclability Status: CS229 Project Report; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Zhou, Y.; Wang, Z.; Zheng, S.; Zhou, L.; Dai, L.; Luo, H.; Zhang, Z.; Sui, M. Optimization of automated garbage recognition model based on resnet-50 and weakly supervised cnn for sustainable urban development. Alex. Eng. J. 2024, 108, 415–427. [Google Scholar] [CrossRef]
- Bianco, S.; Gaviraghi, E.; Schettini, R. Efficient Deep Learning Models for Litter Detection in the Wild. In Proceedings of the 2024 IEEE 8th Forum on Research and Technologies for Society and Industry Innovation (RTSI), Milano, Italy, 18–20 September 2024; pp. 601–606. [Google Scholar]
- Huawei. Huawei Cloud Artificial Intelligence Competition Garbage Classification Challenge Cup 2020. Available online: https://www.huaweicloud.com/zhishi/dasai-19ljfl.html (accessed on 13 April 2024).
- Panwar, H.; Gupta, P.; Siddiqui, M.K.; Morales-Menendez, R.; Bhardwaj, P.; Sharma, S.; Sarker, I.H. AquaVision: Automating the detection of waste in water bodies using deep transfer learning. Case Stud. Chem. Environ. Eng. 2020, 2, 100026. [Google Scholar] [CrossRef]
- Adedeji, O.; Wang, Z. Intelligent waste classification system using deep learning convolutional neural network. Procedia Manuf. 2019, 35, 607–612. [Google Scholar] [CrossRef]
- Yaqing, G.; Ge, B. Research on Lightweight Convolutional Neural Network in Garbage Classification. IOP Conf. Ser. Earth Environ. Sci. 2021, 781, 032011. [Google Scholar] [CrossRef]
- Sai Susanth, G.; Jenila Livingston, L.M.; Agnel Livingston, L.G.X. Garbage Waste Segregation Using Deep Learning Techniques. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1012, 012040. [Google Scholar] [CrossRef]
- Mao, W.-L.; Chen, W.-C.; Wang, C.-T.; Lin, Y.-H. Recycling waste classification using optimized convolutional neural network. Resour. Conserv. Recy. 2021, 164, 105132. [Google Scholar] [CrossRef]
- Feng, J.-W.; Tang, X.-Y. Office Garbage Intelligent Classification Based on Inception-v3 Transfer Learning Model. J. Phys. Conf. Ser. 2020, 1487, 012008. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Cao, L.; Xiang, W. Application of Convolutional Neural Network Based on Transfer Learning for Garbage Classification. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1032–1036. [Google Scholar]
- Yang, J.; Zeng, Z.; Wang, K.; Zou, H.; Xie, L. GarbageNet: A unified learning framework for robust garbage classification. IEEE Trans. Artif. Intell. 2021, 2, 372–380. [Google Scholar] [CrossRef]
- Chen, Y.; Liang, Y.; Tang, Y.H.; Pan, B. Garbage detection and classification based on improved YOLO algorithm. J. Inner. Mongolia Univ. (Nat. Sci. Ed.) 2022, 53, 538–544. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Chen, Y.; Zheng, B.; Zhang, Z.; Wang, Q.; Shen, C.; Zhang, Q. Deep Learning on Mobile and Embedded Devices: State-of-the-art, Challenges, and Future Directions. ACM Comput. Surv. (CSUR) 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:170404861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. In Proceedings of the Advances in neural information processing systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Perez, E.; Strub, F.; de Vries, H.; Dumoulin, V.; Courville, A. FiLM: Visual Reasoning with a General Conditioning Layer. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Ethayarajh, K. How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. arXiv 2019, arXiv:190900512. [Google Scholar]
- Becker, S.; Hinton, G.E. Self-organizing neural network that discovers surfaces in random-dot stereograms. Nature 1992, 355, 161–163. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Sun, Y.; Shi, Y.; Hong, L. On sampling strategies for neural network-based collaborative filtering. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 767–776. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1734–1747. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 18661–18673. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 38, 8574–8586. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Categories | Amount |
|---|---|---|
| 1 | glass | 819 |
| 2 | dry battery | 322 |
| 3 | plastic product | 286 |
| 4 | broken pots/dishes | 387 |
| 5 | plastic mulch films | 629 |
| 6 | rusty tool | 489 |
| 7 | metal-can | 328 |
| 8 | cardboard | 567 |
| 9 | plastic bottle | 524 |
| 10 | cigarette butt | 438 |
| 11 | coconut shell | 286 |
| 12 | pineapple shell | 232 |
| 13 | oyster shell | 302 |
| 14 | branch | 319 |
| 15 | pesticide container | 293 |
| 16 | fertiliser-bag | 416 |
| Backbone | Size | mAP |
|---|---|---|
| MobileNetV1 | 53 | 0.776 |
| MobileNetV2 | 48 | 0.791 |
| MobileNetV3 | 55 | 0.805 |
| GhostNet | 43 | 0.812 |
| Backbone1 | Backbone2 | Fusion Model | mAP |
|---|---|---|---|
| GhostNet | MobileNetV3 | Add | 0.828 |
| GhostNet | MobileNetV3 | Concat | 0.844 |
| Model | Backbone1 | Backbone2 | P | R | F1 | mAP | Time | Weight |
|---|---|---|---|---|---|---|---|---|
| YOLOv7 | - | - | 0.876 | 0.861 | 0.868 | 0.856 | 6.3 | 36.3 |
| YOLOv7-tiny | - | - | 0.847 | 0.833 | 0.839 | 0.848 | 6.4 | 6.5 |
| YOLOv7-1 | GhostNet | MobileNetV1 | 0.825 | 0.842 | 0.833 | 0.813 | 6.9 | 6.8 |
| YOLOv7-2 | GhostNet | MobileNetV2 | 0.831 | 0.813 | 0.821 | 0.837 | 6.3 | 6.6 |
| YOLOv7-3 | GhostNet | MobileNetV3 | 0.842 | 0.859 | 0.850 | 0.839 | 6.7 | 7.5 |
| YOLOv7-4 | VGG16 | MobileNetV3 | 0.822 | 0.831 | 0.826 | 0.825 | 7.1 | 7.2 |
| Our method | GhostNet | MobileNetV3 | 0.845 | 0.851 | 0.848 | 0.844 | 6.5 | 5.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, X.; Bai, L.; Mo, D. A Garbage Detection and Classification Model for Orchards Based on Lightweight YOLOv7. Sustainability 2025, 17, 3922. https://doi.org/10.3390/su17093922
Tian X, Bai L, Mo D. A Garbage Detection and Classification Model for Orchards Based on Lightweight YOLOv7. Sustainability. 2025; 17(9):3922. https://doi.org/10.3390/su17093922
Chicago/Turabian StyleTian, Xinyuan, Liping Bai, and Deyun Mo. 2025. "A Garbage Detection and Classification Model for Orchards Based on Lightweight YOLOv7" Sustainability 17, no. 9: 3922. https://doi.org/10.3390/su17093922
APA StyleTian, X., Bai, L., & Mo, D. (2025). A Garbage Detection and Classification Model for Orchards Based on Lightweight YOLOv7. Sustainability, 17(9), 3922. https://doi.org/10.3390/su17093922