1. Introduction
We have moved into a
Big Data Era [
1,
2], and an enormous amount of data are expected to be processed to accomplish different special tasks. With rapid remote sensing technology development springing up, optical satellite images are widely used for automatical applications, such as different applications of target detection [
3,
4,
5,
6,
7,
8] and scene classification [
9]. However, clouds cover more than 50% of the surface of the earth [
10,
11,
12], and consequently, clouds might be great challenges when automatically processing the images. Therefore, automatic cloud detection is a very significant part for satellite imagery processing.
Researches have been concentrated on the topic of cloud detection for years, and two main streams of cloud detection method form. The first group of methods is physical, which concentrates on the reflectance of different bands and the relationships between them (probably the ratio between the reflectance between two bands). The automatic cloud cover assessment (ACCA) [
13,
14] was one method among the physical ones. This method used the band information of band 2–6 of Landsat7 ETM+, where warm cloud mask, cold cloud mask, non-cloud masks and snow masks can be obtained through this method. Later, a modified version of ACCA was developed for Gaofen-1 wide field of view (GF-1 WFV) imagery [
15], where Band 2–4 are used in the very first steps to obtain cloud masks (both high confidence and low confidence) and clear sky. Another series of physical cloud detection methods are Fmask [
16,
17,
18], which suits Landsat series and Sentinel 2 imagery. It is worth noting that Fmask considered almost all the band information with more physical tests conducted such as water test and whiteness test, and cloud shadow detection is carefully designed through the projection analysis, which can be viewed as an extension of the ACCA method. In [
18], Mountainous Fmask (MFmask) was proposed for better cloud detection results in the mountainous region, where snow and ice are better separated from clouds. MFC Algorithm [
19], which utilized the reflectance of all band information, the relationship of bands in GF-1 WFV imagery and also analyze the cloud shadow, can also be viewed as a type of Fmask algorithm. It is a typical physical method. Besides, there are some other physical methods producing cloud masks, which mainly use the reflectance information of the imagery bands. In [
20], similar to ACCA, a combination of reflectance of single band and multiband, the band ratio and the band difference was used for cloud detection of Landsat 8 (utilizing Band 1–8), NPP VIIRS (utilizing Band 1–11) and MODIS (utilizing Band 1–20) imagery. In [
21], both intensity of pixels and seed points/region ratio, which is the extended information of brightness, was used for cloud detection in IKONOS, ZY-3 and Tianhui 1 imagery. In [
22], Fisher A extracted cloud mask by the relationships between the green band and the shortwave infrared band, the red band and the near-infrared band of SPOT-5 imagery. In [
23], cloud masks were obtained by band reflectance relationships among blue, green, red and near-infrared bands of multi-temporal imagery. VEN
S, FORMOSAT-2, Sentinel-2 and Landsat series imagery were supported by this multi-temporal cloud detection. Although these methods can obtain fine cloud masks, they rely on the reflectance of the imagery bands and the previous threshold setting, which lacks the flexibility and may not be appropriate in difficult situations where there are bright land covers in the imagery, and the reflectance of these land covers is similar to the cloud.
To make more use of the imagery, especially from those which only contain four or fewer image bands, the other group of cloud detection methods use statistical techniques based on the physical information. The statistical methods based on physical information often process the images by extracting all types of features (including the physical information of the image) and they have been widely used in the field of computer vision. For instance, histograms of oriented gradients are extracted as image features for human detection [
24], local binary patterns are used for face authentication [
25] and adaptive orientation description and structural context description are designed for detecting coherent groups in crowd scenes [
26]. Similar ideas are also adopted in cloud detection. In [
10], imagery bands in RGB color space were shifted to HSI color space to obtain the confidence map in the cloud detection process, and image filtering technologies were applied in the method to refine the cloud masks. In [
11], color features, local statistical features, texture features and structural features represented the image features, and a special cloud detector based on least squares was designed for cloud discrimination. In [
27], graph models that cooperated with color features were used in the cloud segmentation for all-sky images. In [
28], brightness features and texture features containing the average gradient and gray level co-occurrence matrix (GLCM) [
29,
30] are combined to form the final features, and support vector machine [
31] is used to discriminate these final features into the two certain categories. In [
32], pixels were grouped into superpixels [
33], whose SIFT [
34] features and RGB features were the evidence to evaluate whether the superpixel was the cloud. These methods often extract not only the brightness of the image pixels but also other variable features and obtain fine cloud detection masks. However, these simple features are often hand-crafted, which are hard to design. Besides, these features are still in low-level, which may not be robust enough in imagery with special land covers, such as snow, ice and desert.
In recent years, the benefits from the development of computational ability, neural network methods [
35,
36,
37,
38,
39], have been widely used in classification. In 2012, Alex Krizhevsky et al. [
35] won the first prize in the ImageNet [
40]. In 2014, very deep convolutional networks (VGG) [
36] and inception networks [
37] have been proposed to improve the accuracy of image classification tasks. A year later, He et al. constructed residual networks [
38] to achieve more success in this field. Besides, in [
39], single neural network with high efficiency is also developed for classification. Based on the different forms of networks for classification, the technology of segmentation also leaps. By substituting the last fully connection layer with a convolutional layer, fully convolutional networks [
41] transferred the very first input image into groups of image classification score maps to acquire the image segmentation results. To enlarge the field of view, Chen et al. adapted atrous convolutional networks in deeplab [
42]. For object detection, Lin et al. [
43] constructed feature pyramid networks to summarize different levels of features to build more abundant features, which assist the network in performing better. All the methods above help to solve image processing problems, and those would enlighten researchers in the field of remote sensing.
However, there are significant differences between remote sensing images and natural images. More importantly, when satellites are capturing images, they are in a depression angle and a relatively stable altitude. Thus, all the objects in the land cover are at the same resolution. Therefore, satellite images will have different color and texture distributions. When convolutional neural networks methods are applied to remote sensing image analyzing tasks, characteristics of the images above should be taken into consideration. For cloud detection, there has been research on it using the convolutional neural networks. For instance, Xie et al. [
12] first segmented the imagery into superpixels with the improved simple linear iteration clustering (SLIC), and then the image patches around the corresponding pixels were classified into two categories: cloud or non-cloud. Zhan et al. [
44] discriminated pixels in GF-1 WFV imagery into cloud, snow and background by fusing the prediction from different levels in the deep learning network. These cloud detection methods, which benefit from the high-level features obtained by convolutional neural networks, can produce relatively more reliable cloud masks. However, works still need to be done to improve the accuracy of cloud detection, for the features of the convolutional neural networks are still not utilized.
Inspired by the previous cloud detection methods and the recent deep learning networks, in this paper, we present a novel cloud detection method based on multilevel features behind the imagery. The motivation of our work comes from these three aspects: (1) the key to the success of convolution networks is the robust image features that the networks produce. The robust features are the core to detect cloud on hard images, for example, images with snow, ice and other difficult land covers; (2) the features of different levels of the neural network should be utilized, for low-level features contain abundant details of small cloud, cloud boundary and land cover details, while high-level features contain more semantic information about the cloud covering area and the type of land cover. Therefore, before the final decision, these features should all be preserved for completeness; (3) guided filtering is a moderate filtering technique to be introduced in the cloud detection method to refine the cloud mask, for not only false alarms can be wiped out to achieve better results, but also the filter goes beyond smoothing: the filtering output captures the structure information of the input guided image.
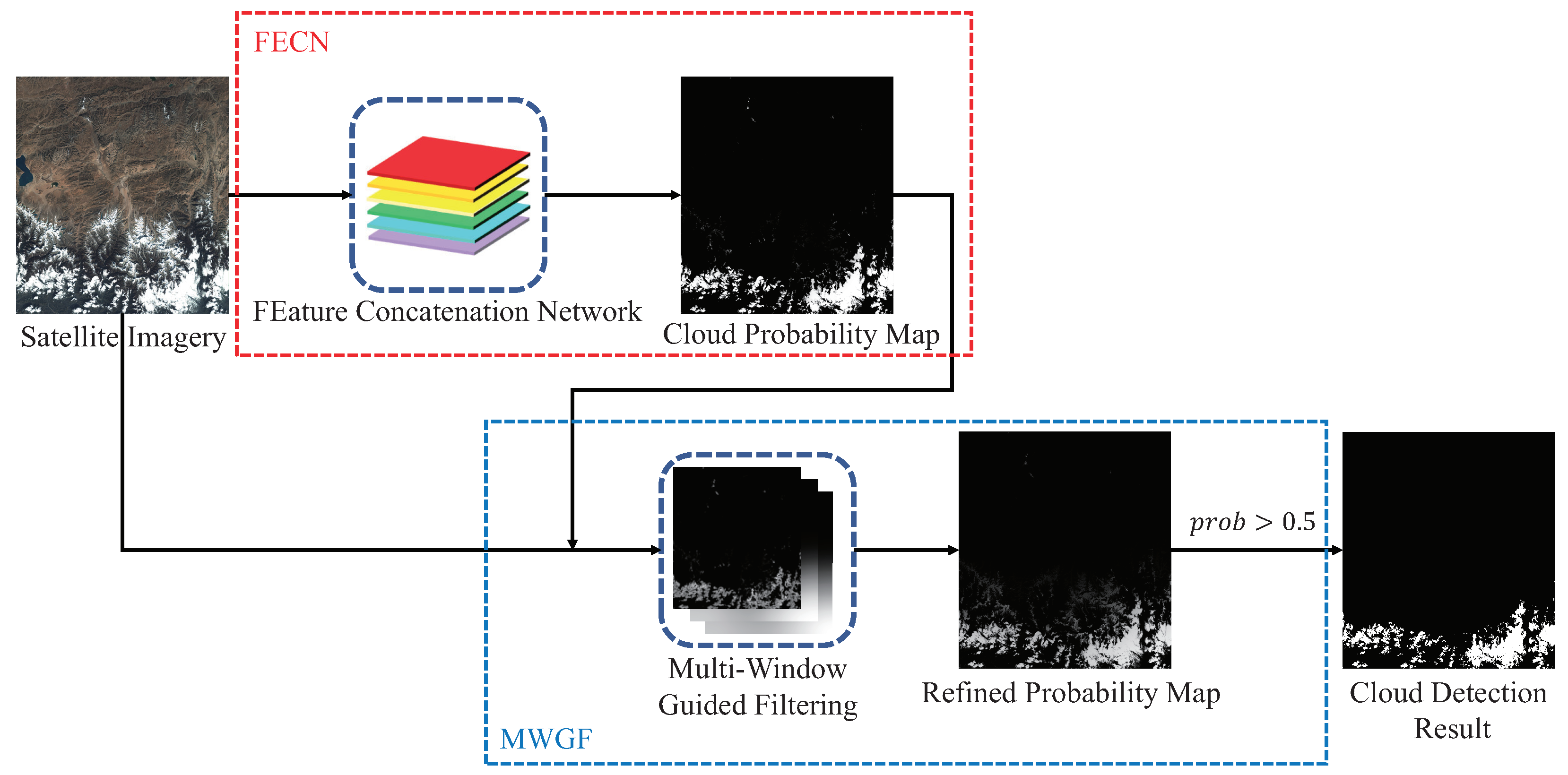
Based on these motivations, we propose our cloud detection method with two major processes (see
Figure 1): the first is
FEature Concatenation Network, FECN, a particular type of fully convolutional neural network, and the other is
Multi-Window Guided Filtering, MWGF. In the first process, we construct the fully convolutional neural network framework based on VGG-16 and introduce extra convolution layers for producing an equal number of feature maps from different levels of the neural network. With these balanced feature maps, the final score layer in the network will explore each of them and finally give the probability map of the cloud to realize the pixel-wise prediction. In the second process, we use a composite filtering technique for better cloud refining. Guided filtering [
45,
46] is proved to be edge-preserved and the filtering output can learn the structure information of the guided image to some extent. Different from the previous cloud detection algorithms in [
10,
19], we applied filtering on cloud probability maps instead of binary cloud masks. Besides, we use multiple guided filters with different window sizes to excavate multilevel of cloud structure features and the surroundings of the imagery and to obtain better cloud masks.
The main contributions are summarized as follows,
FEature Concatenation Network for cloud detection. Since different levels of the network contain different levels of image information, the final cloud detection results can be improved by making decisions from the concatenated features for the full use of the image information. Extensive experiments are conducted to compare different forms of utilizing multilevel features and the specific types of the network.
Multi-Window Guided Filtering for better cloud mask refining. Different from the conventional guided filtering, the proposed filtering technology excavates multilevel structural features from the imagery. Filters with smaller window sizes can capture smaller structure features, especially the details of the imagery, while the filters with larger window sizes can grasp larger structure information, which seems to be the first-glance cloud distribution of the whole imagery. By combining the refined cloud probability maps filtered by different window sizes, the final cloud masks can be improved.
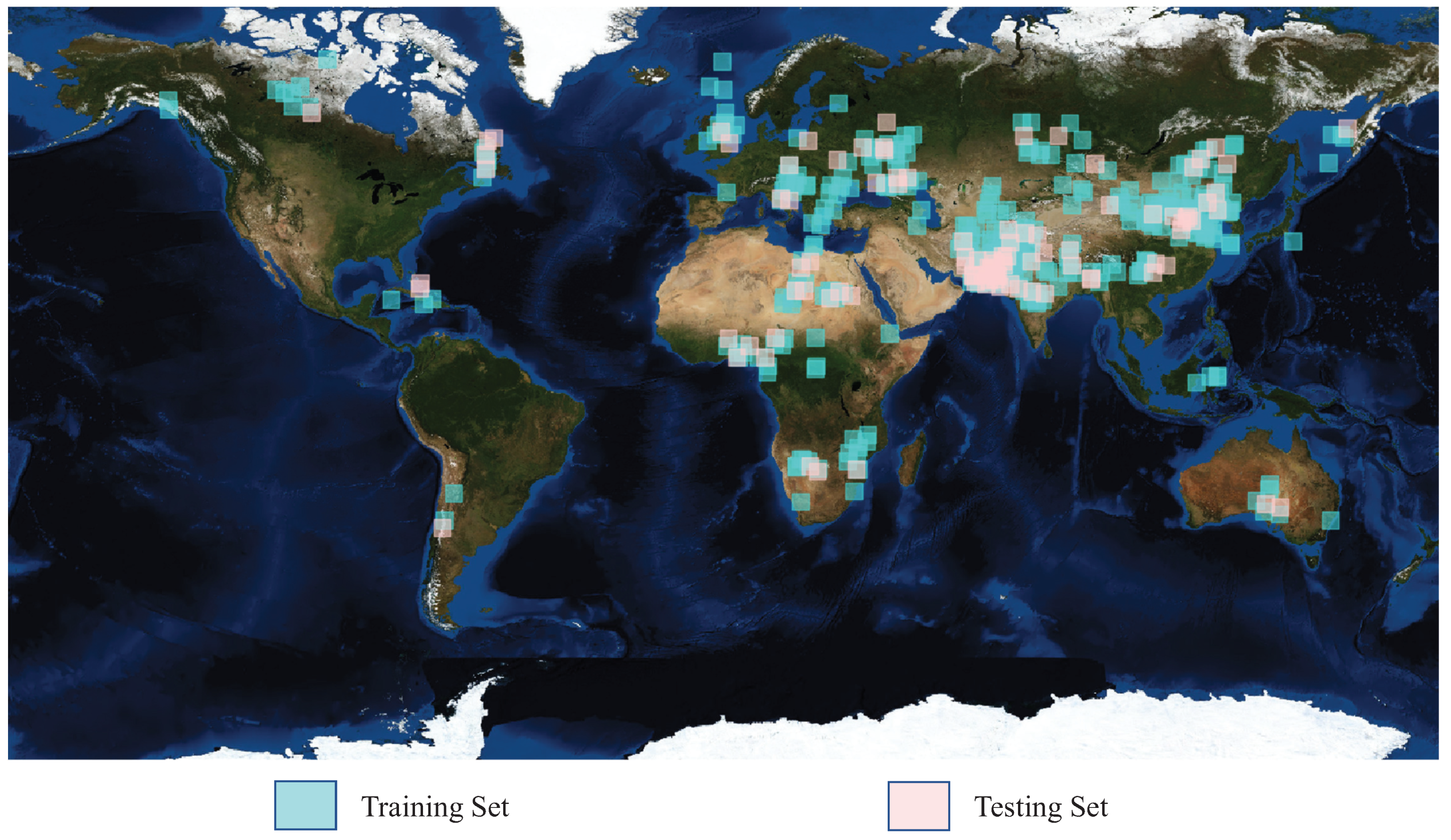
A novel cloud detection method on satellite images for Big Data Era. The proposed cloud detection method utilizes multilevel image features by combining FEature Concatenation Network and Multi-Window Guided Filtering. Our method can outperform other state-of-the-art cloud detection methods qualitatively and quantitatively on a challenging dataset with 502 GF-1 WFV images, which contains different land features such as ice, snow, desert, sea and vegetation and is the largest cloud dataset to the best of our knowledge.
The following content is structured as follows. An introduction to the framework of fully convolutional network is given in
Section 2. In
Section 3 and
Section 4, FECN and MWGF are introduced respectively. In
Section 5, experiments about the proposed cloud detection method are conducted with discussion and analysis. Finally,
Section 6 concludes this paper.
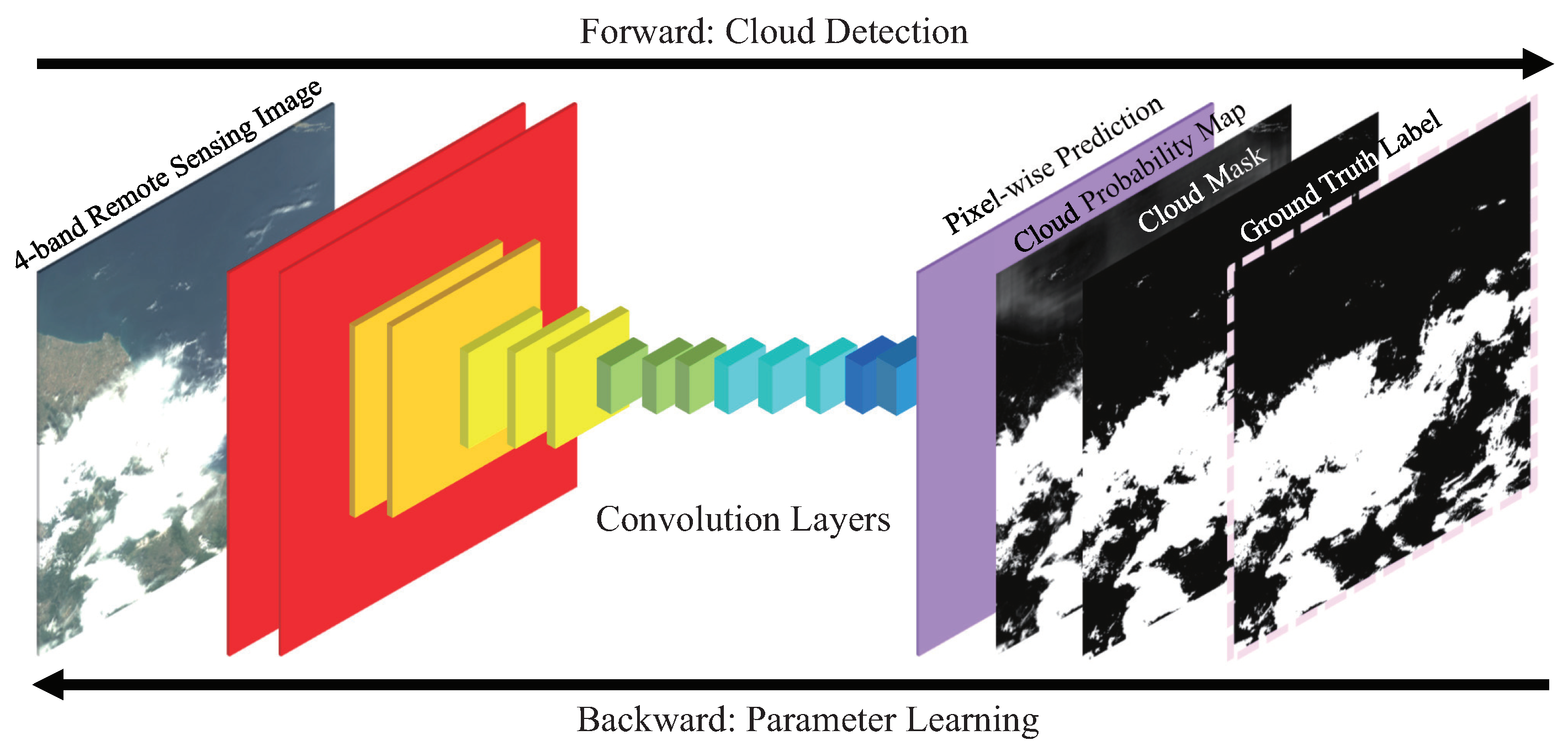
2. The Framework of Fully Convolutional Networks
DCNN is effective in a majority of patch-based image processing applications, such as image classification and object detection. The definition of patch-based image processing application is that we need to design methods for recognizing the whole or part of the image into a category. For image segmentation, which is a pixel-based image processing application, DCNN is often required to recognize every pixel of one image, therefore Fully Convolutional Networks (FCN) [
41] is created. Different from DCNN, FCN predicts a label map with the same size as the input image.
Figure 2 shows a typical FCN framework for cloud detection.
Similar to traditional convolutional neural networks, there are network layers in the structure of fully convolutional networks. Typically, convolution layers, pooling layers and activation layers are the main part of the network layers. Besides, softmax layers are on the bottom of the network structure for producing output label maps and cross entropy loss layers are used for training. Inputs of the network are vectors , where every () is a BGRI (blue, green, red and infrared) image cube with size and b is the number of image batches.
There are many convolution layers processing input data
I inside the fully convolutional network structure. Convolution layers are combined with convolutional kernel matrices
K. Through the
lth convolution layer, input data
of this layer will be affected by the convolutional kernel matrices
with the following calculation,
where * is a multi-dimensional convolution operator and the output is
. Based on covolution layers, high-level features maps which are the output matrix
in the above Equation (
1) can be extracted.
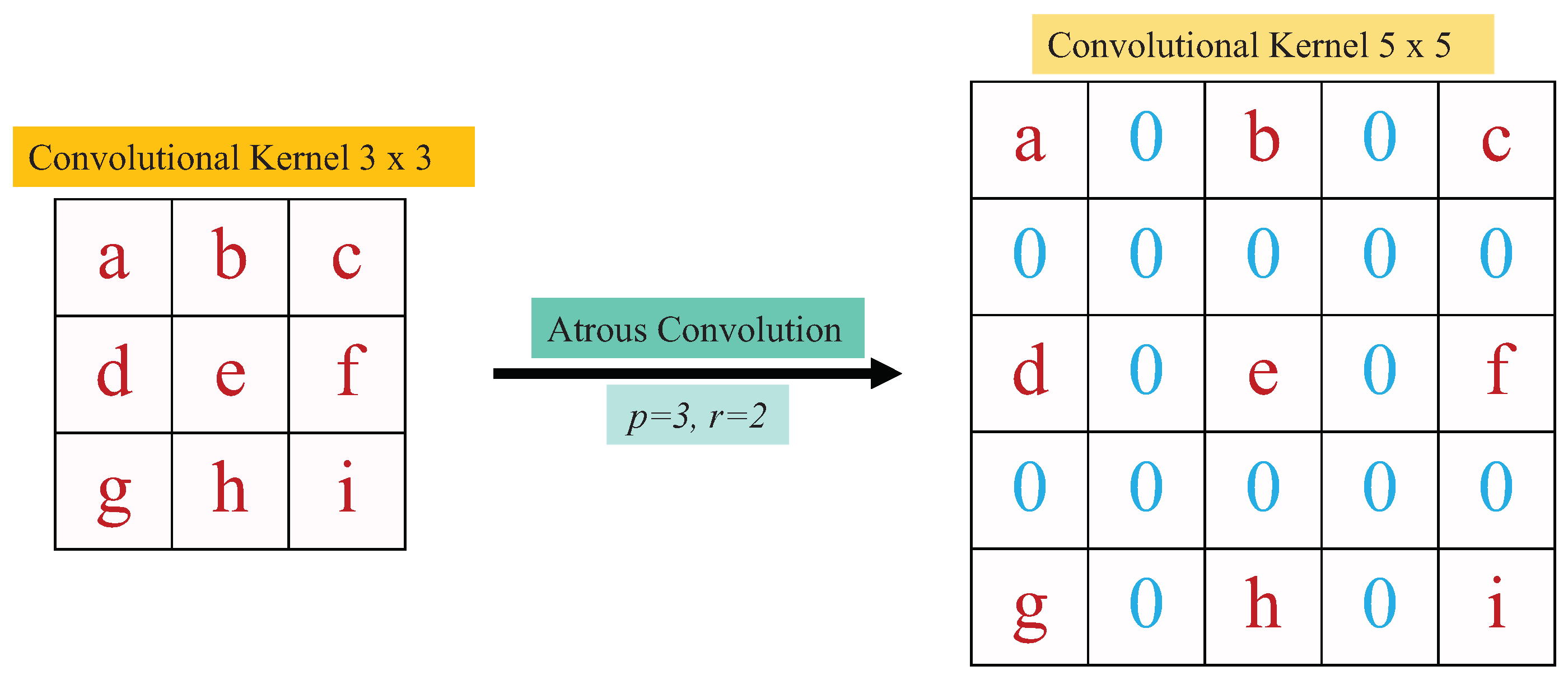
Atrous convolution [
42] is also very useful in cloud detection, for it can widen the field-of-view of convolutional kernels without increasing the number of parameters for computation [
4,
42]. For atrous convolution, the original convolutional kernel size
is shifted to
-
, where
r represents
zeros introducing to the convolutional kernel between consecutive kernel values as
Figure 3 illustrates atrous convolution.
Pooling layer, acting as a down-sampling filter, often follow a series of convolutional layers. It is not only designed for reducing the size of feature maps to reduce the amount of computation, but also for reducing the risk of overfitting [
47]. Max pooling, which may be the most common form of pooling, is defined as the following Equation (
2),
where the digital number of pixel
i which belongs to the output down-sampled feature map
is calculated by the maximum of the pixel values of
in window (i), which size is
. To our knowledge, the window size
s is often set to 2, and several max pooling layers are installed in the framework separately.
As Equation (
1) shows, convolutional layers are linear layers. Although max pooling will make the network a little nonlinear according to Equation (
2), the framework still needs to be more nonlinear to fix the cloud detection tasks well. To make the learned features more expressive, as Equation (
3) displays, element-wise activate functions are often settled after convolutional layers.
where
is the input features,
is the output and
is the activate function. There are many types of activation functions, such as ReLU [
48], ELU [
49] and PReLU [
50]. For computational simplicity, we use ReLU in our framework, as Equation (
4) shows.
After layers of the network, deep feature maps are acquired, and classification needs to be done. In a fully convolutional network, fully connected layers in classification networks are transformed into convolution layers with kernels. Through this transformation, spatial information of the original input image is kept through the whole network. Similarly to classification neural networks, the convolutional layers produce maps of scores of each class as fully connected layers do. In our work, we distinguish these layers as “score layers”.
To value the distance of the network output and the label, softmax layer is used to produce the probabilities, as Equation (
5) shows,
where
C is the number of categories, and
S and
P are input and output of the softmax layer respectively. In detail,
is the score map of class
c produced by score layers and
represents the probability map of the corresponding class. In cloud detection tasks,
C is set to 2, as the pixel is either cloud pixel or non-cloud pixel. Therefore, if the probability of cloud of one pixel in the input image is more than
, this pixel is classified into cloud pixel.
Loss layers are installed in the network for the purpose of making the network trainable. As many image segmentation tasks do, cross entropy loss layer is employed in our work to connect the predicted maps and ground truths. Equation (
6) shows the loss function, where
denotes the ground truths. Here, the target of training the network is to minimize this loss
L. Gradients are calculated and back-propagation technologies are used for gradient delivering and convolutional kernel updating. The process is conducted iteratively and the network will run in the training phase.
Table 1 lists the baseline of the network almost as [
44] did. In
Table 1, ReLU layers are used right after each convolution layer but not listed for simplicity.
3. FEature Concatenation Network for Cloud Detection
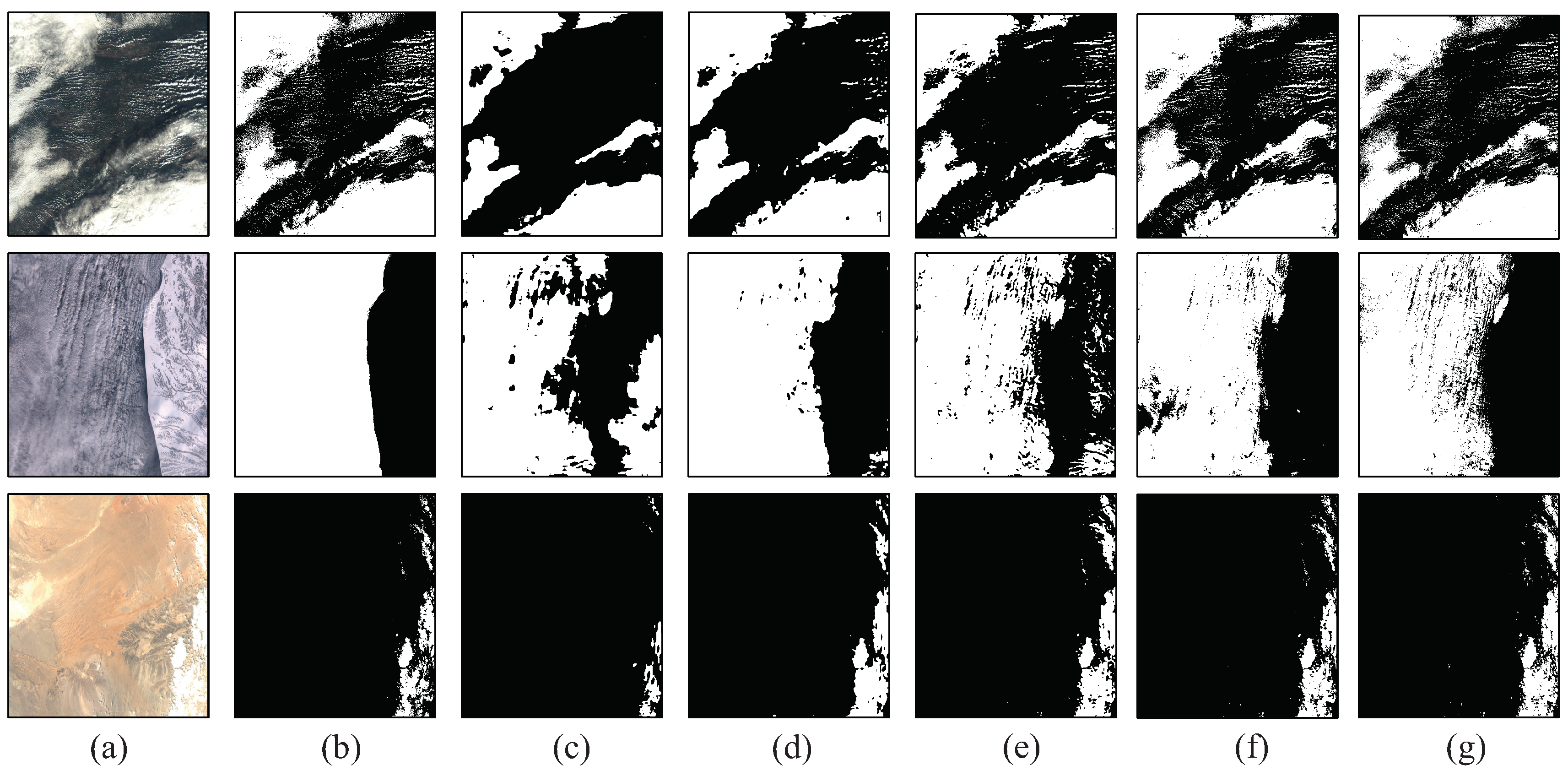
Cloud detection is not an easy task, for not only should the algorithm detect whether there are clouds in the image, but also where the clouds are in the images. FCN in the previous section is a relatively good algorithm for cloud detection, as it can extract multilevel features of the images and obtain cloud masks. In the early stages of the network, as the downsampling rate is low and the image has not passed enough convolutional layers, the information of boundary and texture of the satellite images is clear, while in the late stages, the effectiveness of deep convolutional layers and pooling layers assists the network in learning the background information and leads to more abstract features, which are close to the final classification information. However, in the satellite imagery, there are a variety of clouds from tiny ones to enormous ones above different types of land covers such as common land, snow, desert, sea and even clouds, as
Figure 4 shows. The baseline FCN only analyzes the features in the late stages, which contain blurred boundary and texture of the image, according to
Table 1. Therefore, the baseline FCN should be optimized to be moderate for cloud detection tasks.
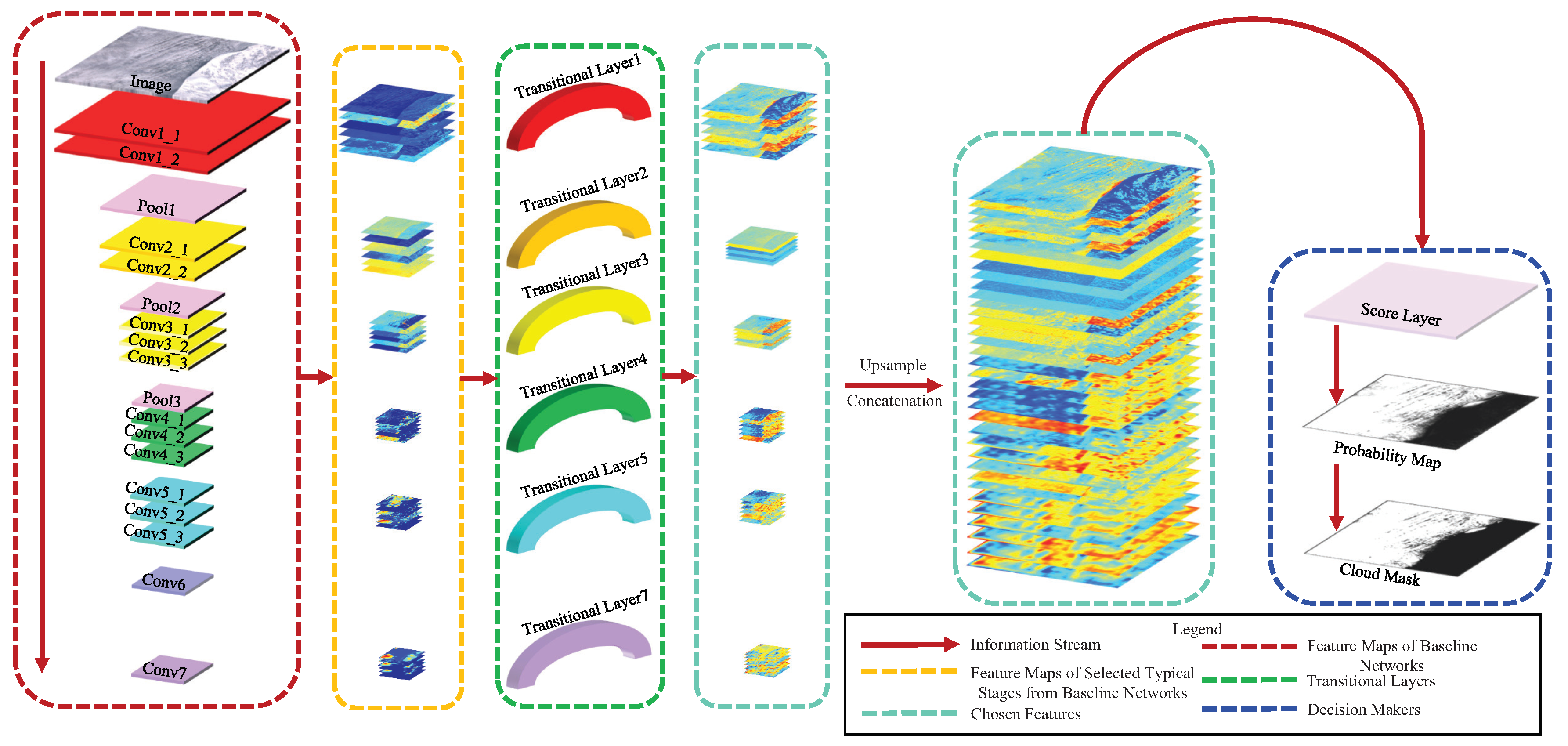
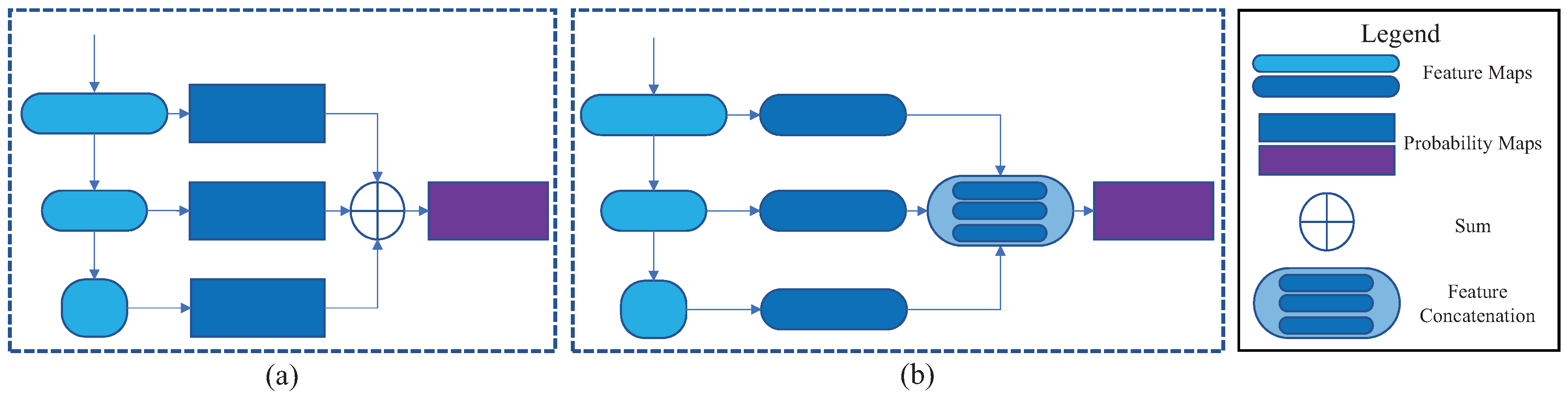
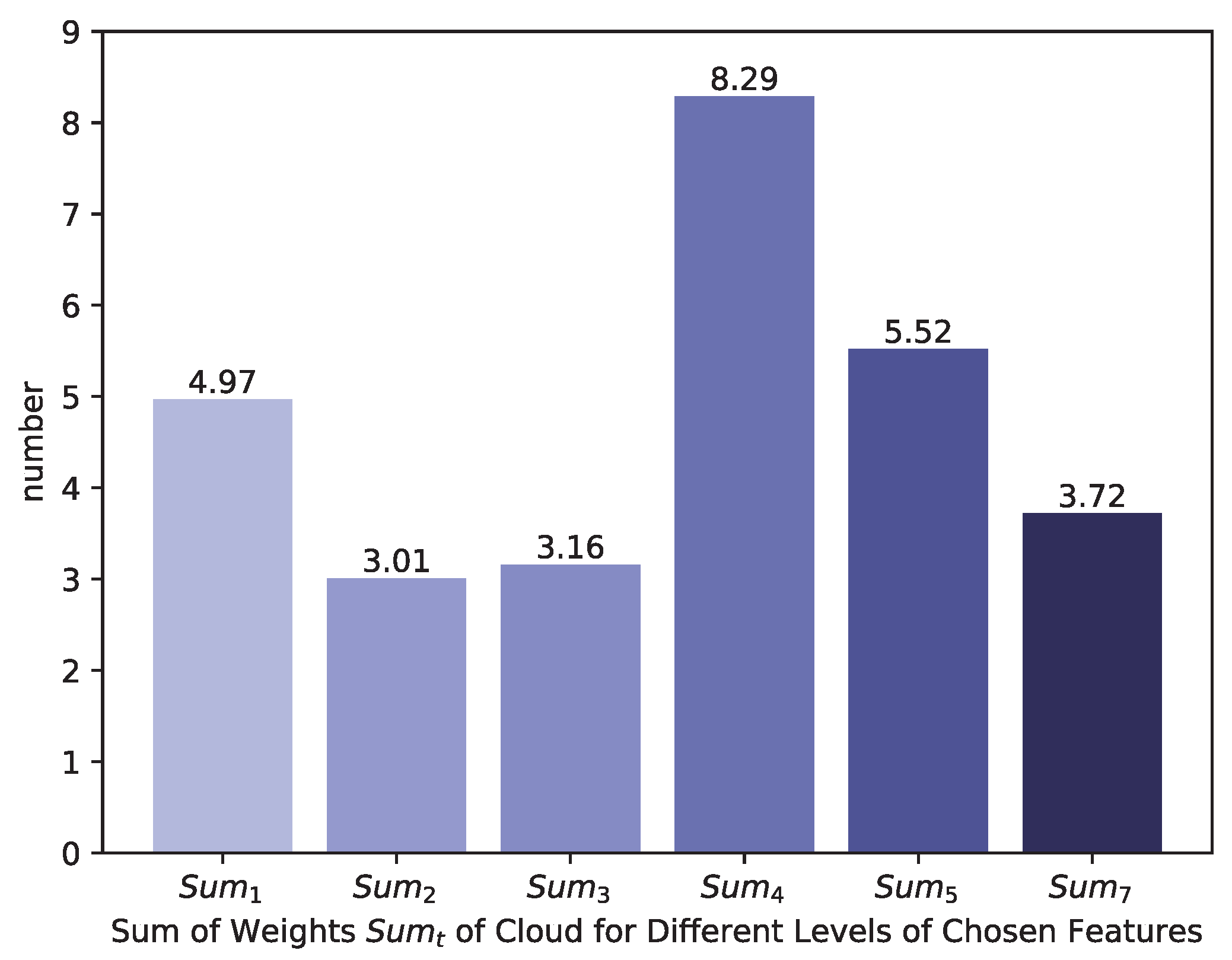
In our work, we collect multilevel features from the baseline network and make the score layer decide which features are essential for cloud detection. As
Figure 5 illustrates, we add
Transitional Layers right after several typical convolution layers of the baseline network for a dimensional transformation. These convolution features extracted by the added convolutional Transitional Layers are viewed as
Chosen Features from the baseline network. We concatenate Chosen Features into one synthetical feature vector, where it contains both simple boundary, texture features together with deep, abstract features. Therefore, the score layer should carefully choose the decisive features in the synthetical feature vector instead of only choosing the features in the late stages of the baseline network. It is also worth noting that because the number of feature maps in the baseline network is different, we design Transitional Layers to balance the feature dimensions of all the different feature maps. For most convolutional networks, the number of low-level features is often less than that of high-level features. For instance, there are 64 feature maps produced by the low-level ‘conv1_2’ but 4096 feature maps produced by the high-level ‘conv7’ (see
Table 1). Considering that features in every level should be in the same significance in the cloud detection tasks, we make a dimensional transformation by adding convolutional Transition Layers, and therefore the numbers of feature maps produced by the extra convolution layers are the same. As we concatenate multilevel features in the baseline network, we call our optimized network
FEature Concatenation Network, FECN.
In detail, we add Transitional Layers with
kernels after convolutional layers ‘conv1_2’, ‘conv2_2’, ‘conv3_3’, ‘conv4_3’, ‘conv5_3’ and ‘conv7’ in FECN, and set the score layers after Chosen Features are concatenated, as
Figure 5 displays. For the limitation of GPU memory, the number of Chosen Features after each Transitional Layer is set to 64. Before Chosen Features are concatenated, they are upsampled to the original image size bilinearly.
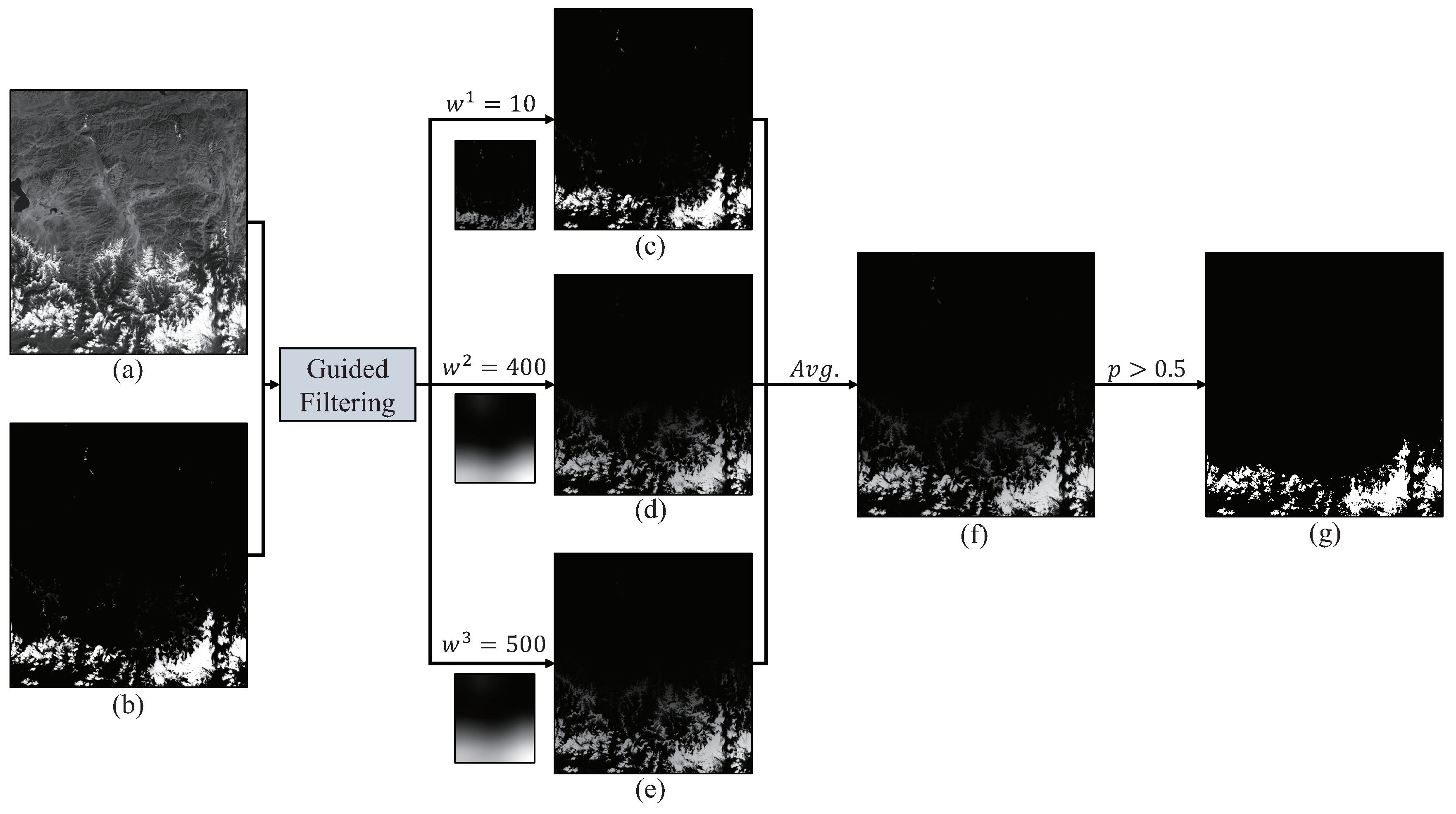
4. Multi-Window Guided Filtering for Cloud Detection
Although FECN works quite well for cloud detecting in most cases, there is still space for improvement. In most cases, FECN can obtain fine cloud masks for it analyzes multilevel features. However, for some difficult cases, such as a wide range of snow or cloud shadows due to multiple layers of clouds, FECN may get unsatisfying results as
Figure 6 shows. Guided filtering [
45,
46], which is in
time complexity, can excavate the potential of the guided image and may refine the input image. It is also applied in remote sensing image processing [
10,
19]. Considering the characteristics of guided filtering, we concentrate on it and extend it into a composite filtering technique, Multi-Window Guided Filtering (MWGF), which involves cloud structure features and the surroundings in multilevel filtering window sizes. It can improve the results acquired by FECN in cloud detection tasks.
MWGF for cloud detection is an extended version of guided filtering [
45,
46], which combines multiple guided filters to excavate multilevel image features. Guided filtering involves a guidance image and another input image which needs to be filtered, and it outputs the refined image. In our work, the probability map
P acquired by FECN is decisive and significant. Therefore, we set it as the input image to be filtered. To utilize all the information of the original image, we create
Y the guidance image, which is defined as follows:
where
B,
G,
R,
are the blue band, green band, red band and near-infrared band of the remote sensing image, respectively.
In MWGF,
L guided filters are used. For a single guided filter, it is a local linear model, i.e., there is a linear connection between
and
Y, where
l ranges from 1 to
L. For a certain pixel
k of a window
in image
Y:
where
and
are coefficients to be calculated from the input image
P. To determine the linear coefficients
and
, we view
as the input
P subtracting some additive noise
H:
Then we minimize the differences with Equation (
8). In detail, we minimize the cost function below in the window
:
In this equation,
is a regularizer penalizing
. Here, a solution to Equation (
10), the linear ridge regression model [
51,
52], is given by
where
and
represent mean and variance value of
Y in
,
is the mean value of
P in
and
denotes the number of pixels in
. Considering a pixel
i is computed for times in the moving overlapping windows
that covers pixel
i, there exists a strategy to reduce the complexity to compute
by averaging (
,
) for all windows
in the image. Thus, the final output
for a certain window size
is defined as the following:
where
and
are the average coefficients of windows which contain the pixel
i.
Here, we find that
is a representative feature of cloud structure and the surroundings as
Figure 7. This is because
is a transform of both
Y and
P. For smaller windows,
P seems to play a more important role and
concentrates on the structure of small clouds or the edges of large clouds, mainly the details of the imagery, while for larger windows, more information of
Y involves and
denotes the structure of larger clouds and even part of the background, which seems to be the first-glance cloud distribution of the imagery. Therefore, the final refined probability map
is also different. For smaller windows, the output is closed to the input
P, which keeps the original clouds as
Figure 8c illustrates, while for the larger windows, the output excavates more about the guided image
Y, which smooths the input
P to some extent as
Figure 8d,e show.
We also find that
is a supplementary representative feature of
. For larger windows as
Figure 9j–n show,
almost equals nothing. This is because the guided image
Y changes a lot within the larger windows
, and
. Thus, we have
According to the above Equations (
12) and (
14), we can easily draw the conclusion that
in larger windows. Therefore, in the method of MWGF for cloud detection tasks,
, a representative feature of cloud structure and the surroundings, plays the most significant role in calculating
.
After calculating
of all the windows, we should summarize them to form a final refined probability map
Q. In our work, we average every
to acquire
Q as the following Equation (
15).
To make our method effective, we examine different window size combination and finally choose them to be the combination of 10, 400 and 500. We also set
= 1 ×
. The following Algorithm 1 is the algorithm of MWGF and
Figure 8 displays its process.
| Algorithm 1 Multi-Window Guided Filtering for Cloud Detection Result Refining |
Input: Cloud probability map P acquired by FECN, the original remote sensing image I, filtering window sizes , , ..., , and penalizing regularizer . Procedures: 1. Calculate Y with I according to Equation ( 7). 2. Calculate with Y for each window size ranging from to based on Equations ( 11)–( 13). 3. Average and form the final refined cloud probability map Q based on Equation ( 15). Output: the final refined cloud probability Q.
|
6. Conclusions
In this paper, we propose a novel cloud detection method by utilizing multilevel image features with two major processes. The proposed method is inspired by the utilization of multilevel features. We first set up FEature Concatenation Network, which is a deep learning network utilizing features from low-level to high-level, to get the cloud probability map. With balanced feature maps from different levels concatenated, the final cloud probability map explores the image information from every level. Further, we refine the cloud probability map by a composite filtering technique, Multi-Window Guided Filtering, which excavates multilevel cloud structure features and the surroundings. By combining the refined cloud probability maps filtered by different window sizes, the refined cloud masks can be improved.
We conduct several groups of experiments to evaluate the performance of our proposed method. Before we conduct these experiments, we collect a challenging dataset with 502 GF-1 WFV images, which contains different land features such as ice, snow, desert, sea and vegetation and the dataset is the largest cloud dataset to the best of our knowledge, which is proper for the research in Big Data Era. First we evaluate the effectiveness of FECN, where we compare two different ways of utilizing multilevel feature information, Prediction Fusion and Feature Concatenation and we also compare different types of FECN. The experimental results show that Feature Concatenation is more effective and FECN_123457 performs better. Further, we examine multiple types of MWGF, where the filter with both small and large window sizes can refine the cloud probability map better. Finally, we compare our method with physical methods, physical methods integrated with statistical techniques and other deep learning methods, where our method outperforms others. Therefore, all these experimental results indicate that our method, which utilizes multilevel features of the imagery, is an effective method of cloud detection.
In our future work, we will focus on improving the computational efficiency of the proposed cloud detection method. Meanwhile, the relationships of the features in the convolutional network will be investigated.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}