1. Introduction
Geospatial object detection makes full use of remote-sensing images with high resolution to generate bounding boxes and the specific classification scores, which means significant image analysis and understanding. The automatic and efficient object detection using satellite images has many applications in both military and civilian areas, such as airplane detection [
1] and vehicle detection [
2,
3,
4]. Although numerous methods have been put forward, there are still some challenges to be solved in geospatial object detection. Firstly, the quantity and quality of remote-sensing images have undergone rapid development and made great progress, which demands fast and effective approaches to real-time object localization. Secondly, the high-resolution satellite images are slightly different from traditional digital images captured in ordinary life. The remote-sensing images are taken from the upper airspace, causing a downward perspective with orientation variations. Moreover, the changing illumination, unusual aspect ratios, dense situations and complex backgrounds make the geospatial object detection more challenging [
5]. Lastly, compared with the existing large-scale natural image datasets, there is a small number of well-annotated satellite images and they require expensive labor and plenty of time. Several existing geospatial datasets mostly focus on one object category, such as the Aircraft data set [
6], Aerial-Vehicle data set [
7], and High Resolution Ship Collections 2016 (HRSC2016) [
8] for ship detection. In contrast, although the Northwestern Polytechnical University very high spatial resolution-10 (NWPU VHR-10) data set [
9] contains ten different geospatial object classes, there are totally about 3600 object instances which are insufficient. Considering the application prospects and the above challenges, our contributions to geospatial object detection are significant.
Traditional object detection methods focus on the feature extraction and classification problem [
10]. The feature descriptors construct comprehensive feature representation from the raw images, such as local binary patterns (LBP) [
11], histogram of oriented gradients (HOG) [
12], bag-of-words (BoW) [
13] and texture-based features [
14,
15]. Supervised or weakly supervised learning algorithms are then employed to train the object detection model using the extracted features [
16,
17]. Three different features, LBP, HOG and Haar-like, are applied for training the car object classifier from aerial images [
4]. A deformable part-based model is trained based on the multi-scale HOG feature pyramids, which shows effectiveness in object detection with remote-sensing imagery [
18]. For solving the challenge of detecting geospatial objects with complex shapes, the BoW model with sparse coding is presented as information representation [
19]. In another detection framework, the new rotation invariant HOG feature is proposed [
20] for targets with complex shape. Kinds of machine learning algorithm are applied to generate the object category of each class based on the feature representation. The support vector machine (SVM) has been widely used and has a good performance in many geospatial object detection applications [
21], such as airplane detection [
18], and ship detection [
22]. For better detection of multi-class geospatial objects, a part detector composed of a set of linear SVMs is proposed, which demonstrates strong discriminant ability [
9]. The adaptive boosting (AdaBoost) algorithm combines a series of weak classifiers to obtain a strong classifier, and has played an important role in vehicle detection [
23], ship detection [
24] and airport runway detection [
15]. In conclusion, these machine learning methods to classify object categories and locate the objects’ bounding boxes mainly rely on the designed features, which requires human prior knowledge. Although the above approaches have demonstrated impressive performance, human creativity for designing discriminative feature descriptors is still a challenge in specific geospatial object detection with remote-sensing images.
Recently, with the rapid development of deep learning, the convolutional neural network (CNN) has proven to be successful in detecting objects. Instead of designing handcrafted features, CNN architecture has a powerful ability of learning feature representations. Generally, there are two classical technology solutions in the CNN-based object detection, which are region-based methods and single shot methods. The region-based CNN (R-CNN) model [
25] applies the CNN to obtain the feature representation of proposal regions that are then classified into object categories with an SVM classifier. For better computational efficiency, feature extraction, object classification and bounding boxes regression are unified to a Fast R-CNN [
26] detection framework. Because the region proposals generation with selective search methods [
27] is time-consuming, a Region Proposal Network (RPN) is proposed to generate detection proposals. The Faster R-CNN [
28] merges RPN and Fast R-CNN into an end-to-end architecture by sharing convolutional features, which demonstrates faster computation speed as well as effective detection results. On the other hand, the single shot methods regard object detection as a regression problem that directly determines target localization and corresponding class confidence, such as You Only Look Once (YOLO) [
29], YOLO9000 [
30], Single Shot MultiBox Detector (SSD) [
31] and Region-based Fully Convolutional Networks (R-FCN) [
32]. These single shot models are faster with high detection accuracy than region-based approaches. Specifically, for small objects detection, a multi-scale deconvolution fusion module [
33] is designed to generate multiple features. Feature maps from different layers are combined through deconvolution module and element-wise fusion methods [
34]. The improved YOLOv3 [
35] makes predictions at three different convolution layers. With the merger of low-level features and high-level semantic information, stronger feature representation is obtained to achieve better object detection performance, especially for small targets.
In geospatial object detection using remote-sensing images, CNNs have also been widely applied [
6,
36,
37,
38]. A single value decompensation (SVD) inspired by the CNN structure is designed for ship detection in spaceborne optical images [
39]. In view of exploring the semantic and spatial information in remote-sensing images, a dense feature pyramid network with rotation anchors is proposed [
40]. As for synthetic aperture radar (SAR) ship detection, the contextual region-based CNN with multilayer fusion is employed [
41]. To address object rotation variations in satellite images, a rotation-invariant CNN (RICNN) is presented through adding a rotation-invariant layer and defining a new objective function [
42]. Because of the scarcity of manually annotated satellite images, a pre-trained Faster R-CNN on large-scale ImageNet dataset is transferred for multi-class geospatial object detection [
5]. Considering the imbalanced number of targets and background samples, a hard example mining technique is implemented to improve the efficiency of training process and detection accuracy [
43,
44]. Actually, there are many small and dense targets in remote-sensing images, which are hard to be detected. To address this issue, feature maps from different layers with various receptive fields are used to detect geospatial targets [
45]. The multi-scale feature maps from different CNN layers make a significant contribution to detecting multi-scale objects, especially for small objects [
46]. These multi-layer features are aggregated to be a single high-level feature map through the transfer connection block [
47]. Although the CNN-based approaches have proven to be successful and effective in detecting geospatial objects such as ships, airplanes, and vehicles, there are still some limitations and challenges of these models. Multiple down-sampling layers in the basic CNN generate high-level features with global semantic information, which also means losing lots of local details. The size of the feature maps after multiple down-sample is 1/16 of input images. The small objects with a few pixels in extent are hard to accurately detect. Another problem that object-detection methods struggle with is the target diversity. Due to the multiple resolution of remote-sensing images and difference of object categories, it is also important to improve the generalization ability of CNN-based detection models.
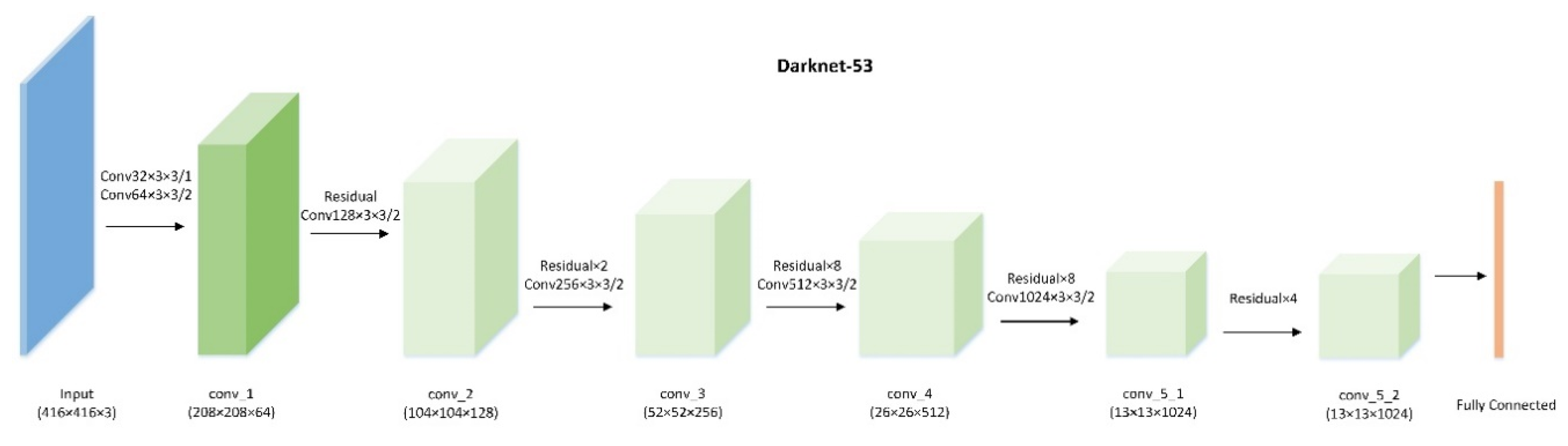
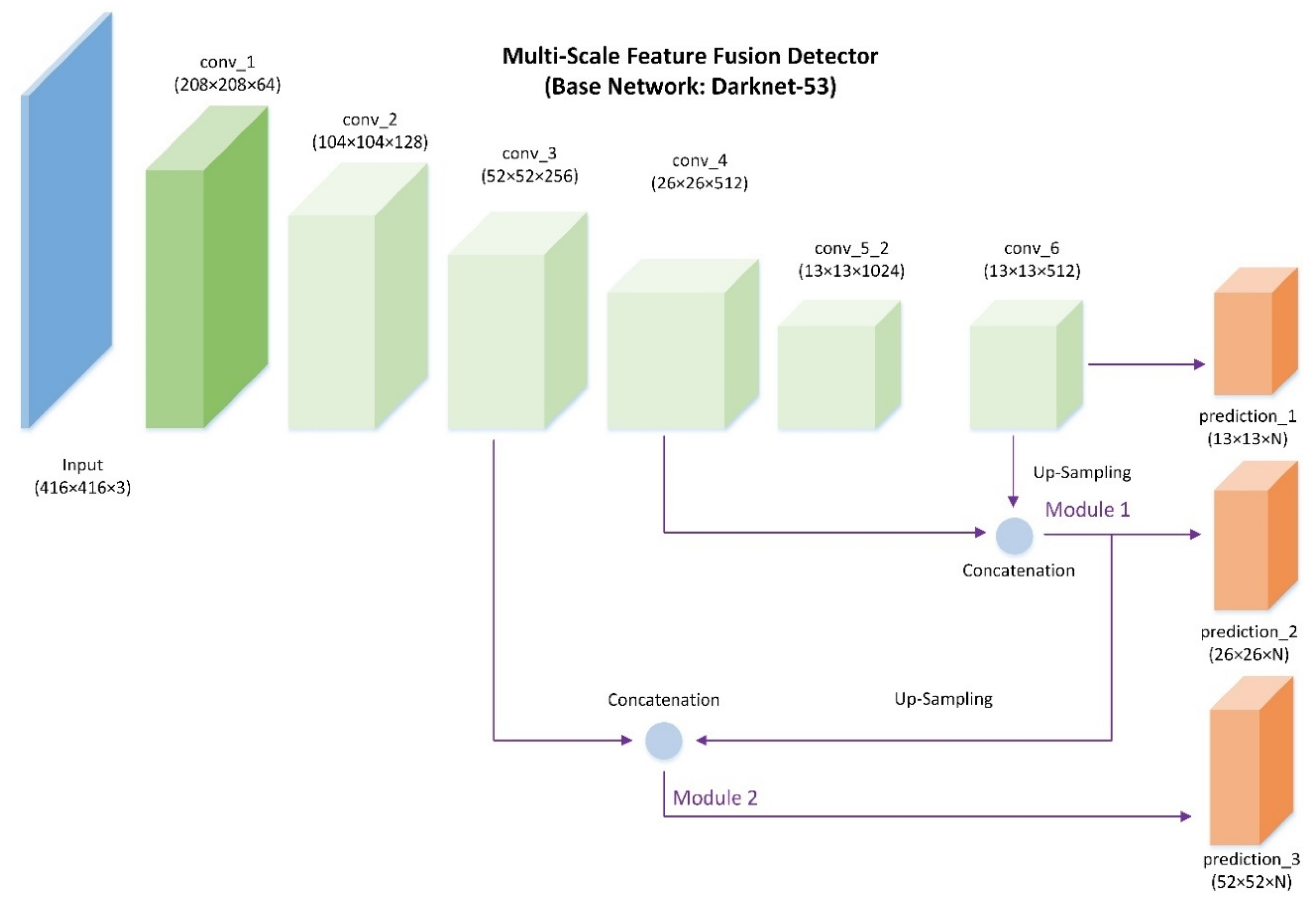
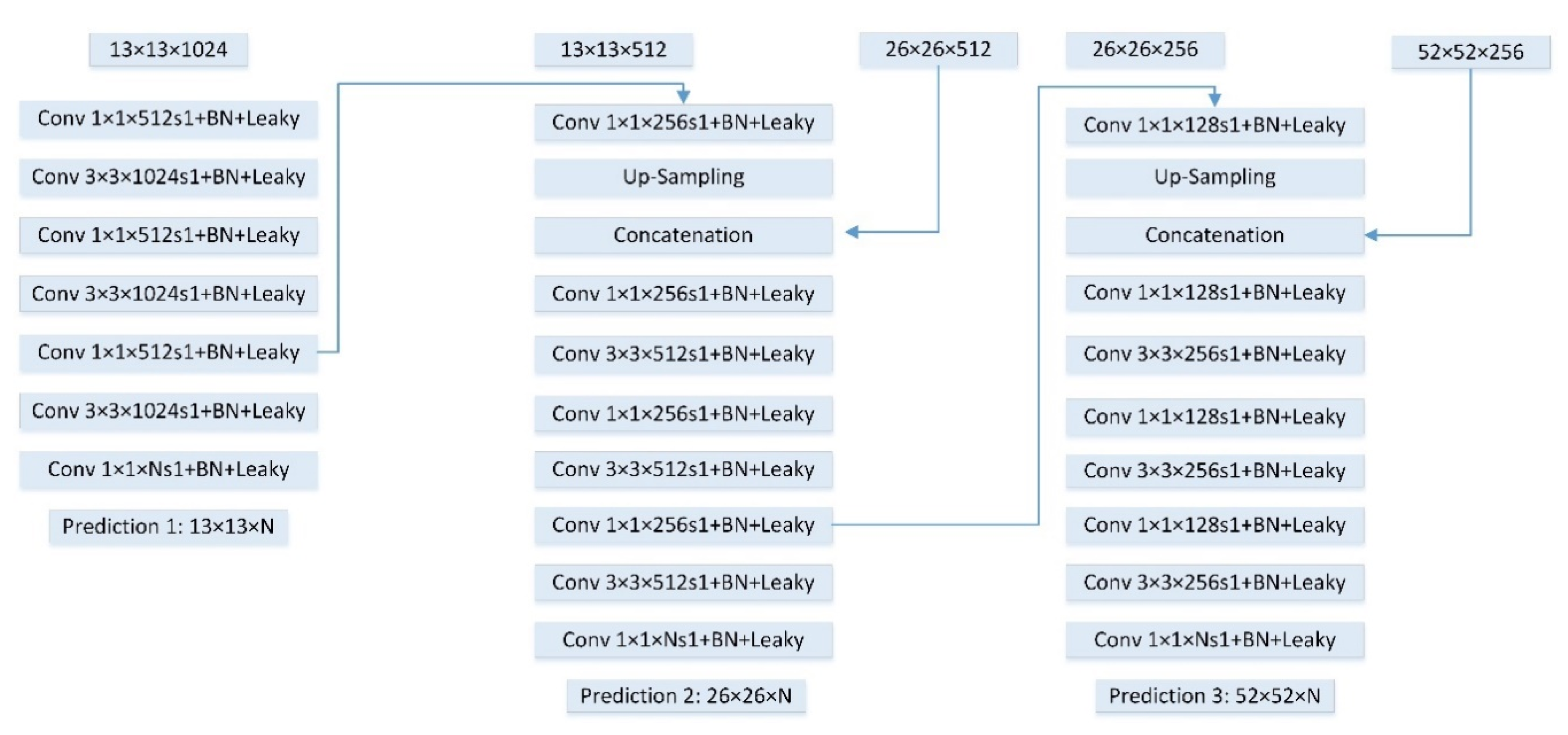
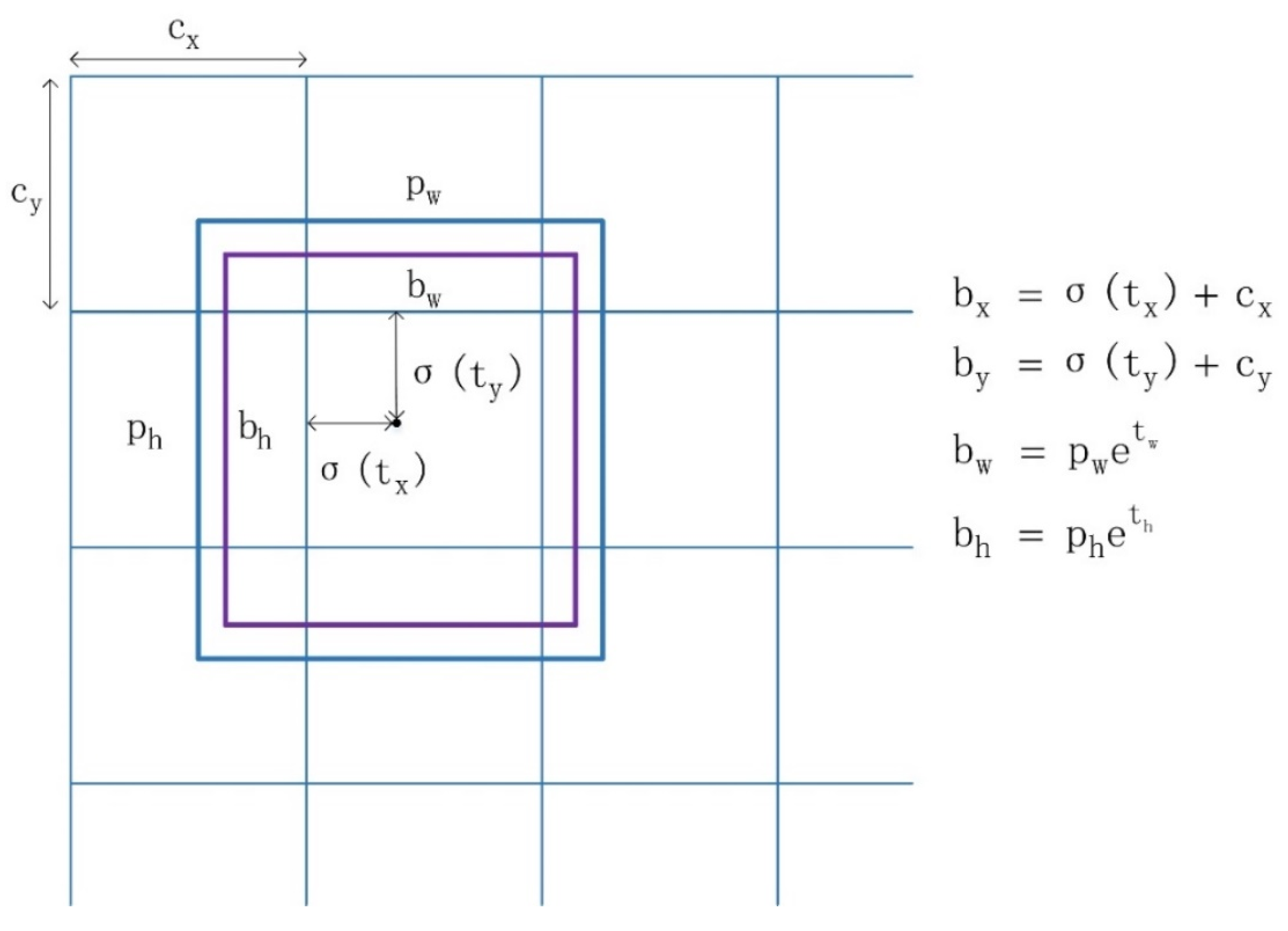
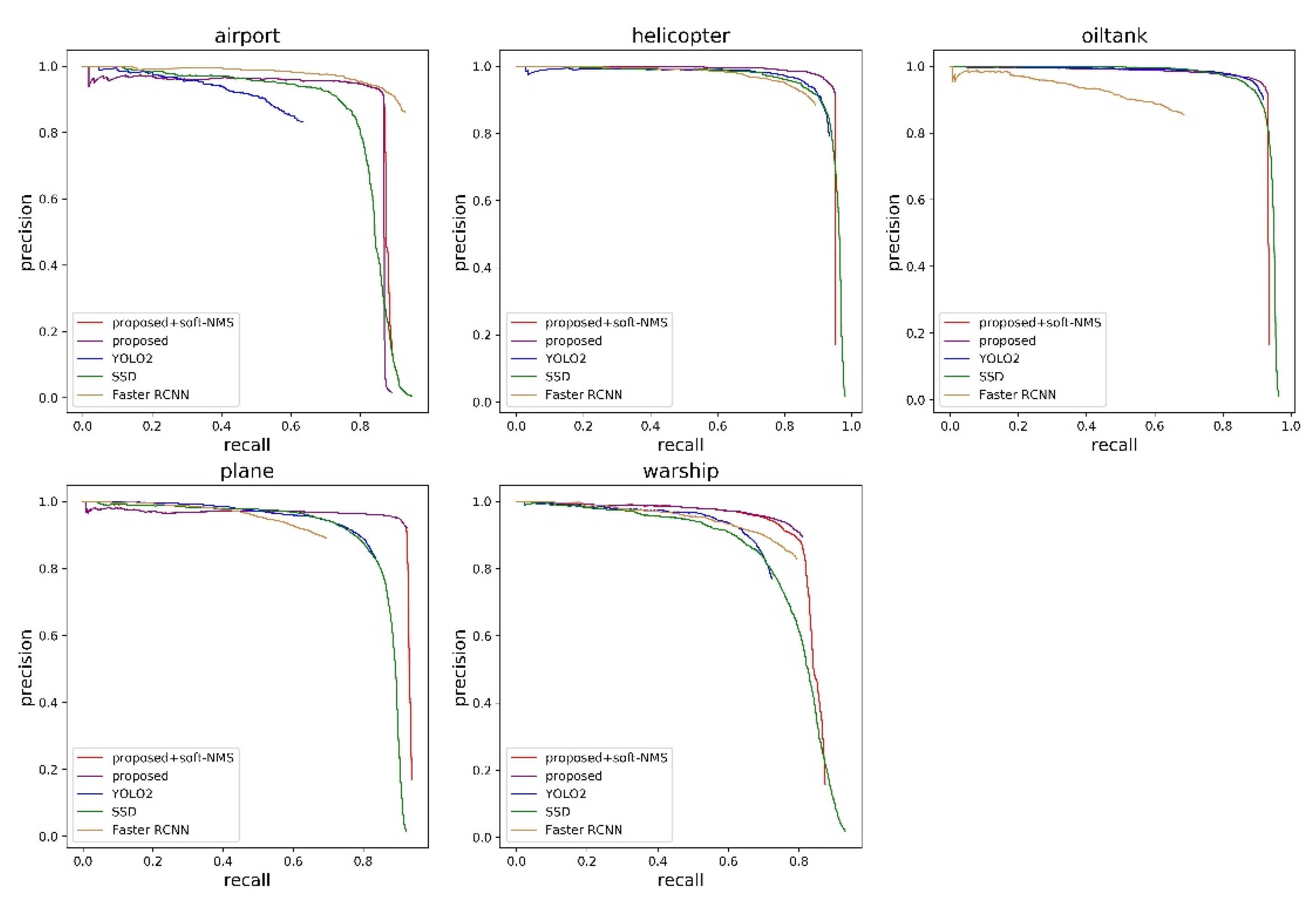
To tackle the above issues, a multi-scale feature fusion detector is proposed in this paper. Compared with region-based CNN models, our work is motivated by the SSD and YOLO approaches [
30,
33,
34,
48]. SSD generates bounding boxes’ location and classifies object categories from multiple feature maps in different layers. The feature maps with different resolutions in SSD make predictions respectively. In order to aggregate low-level and high-level features, we implement a feature fusion module that concatenates multi-scale feature maps. The low-level features with more accurate details and high-level features with semantic information are fused together to make final object predictions. Instead of the greedy non-maximum suppression (NMS), a soft-NMS strategy [
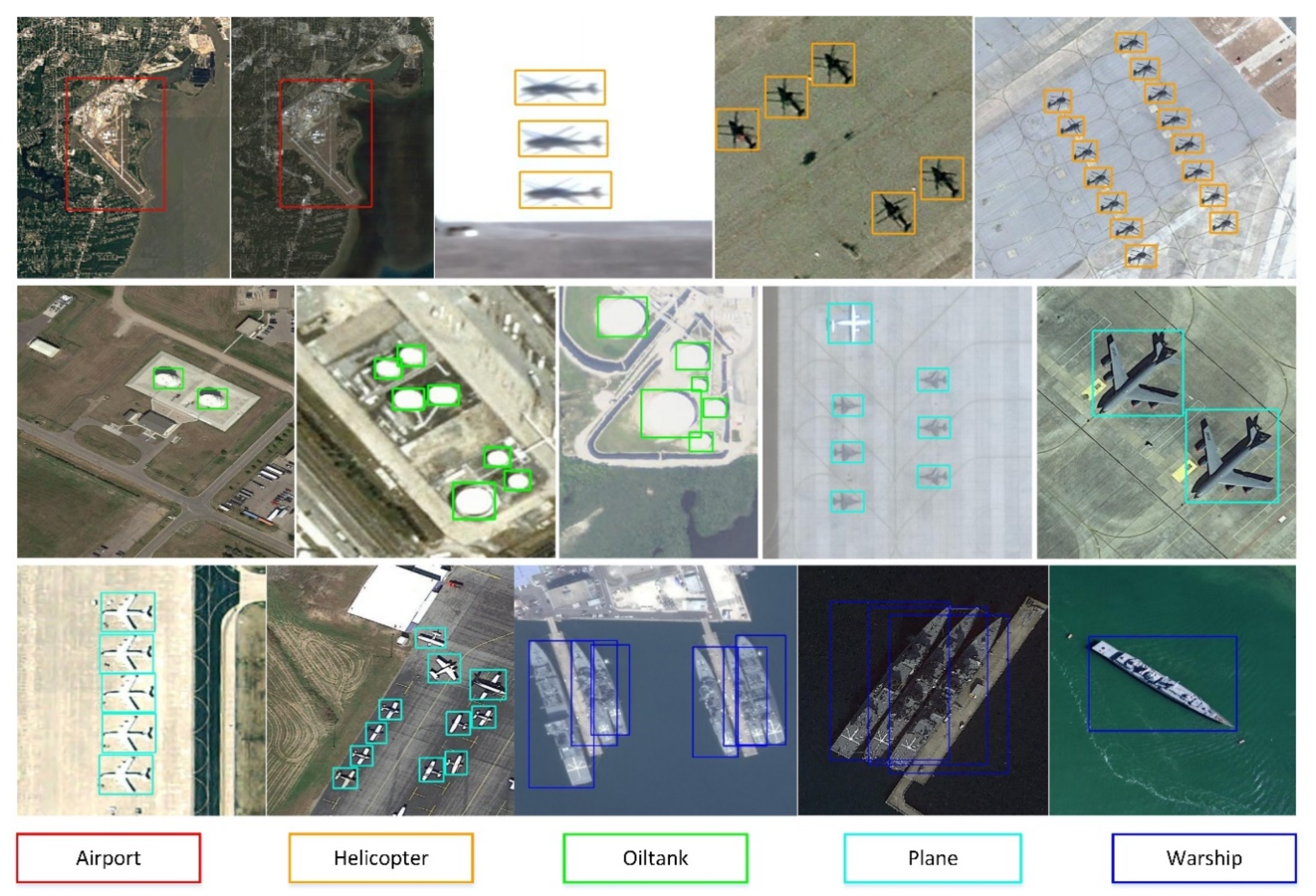
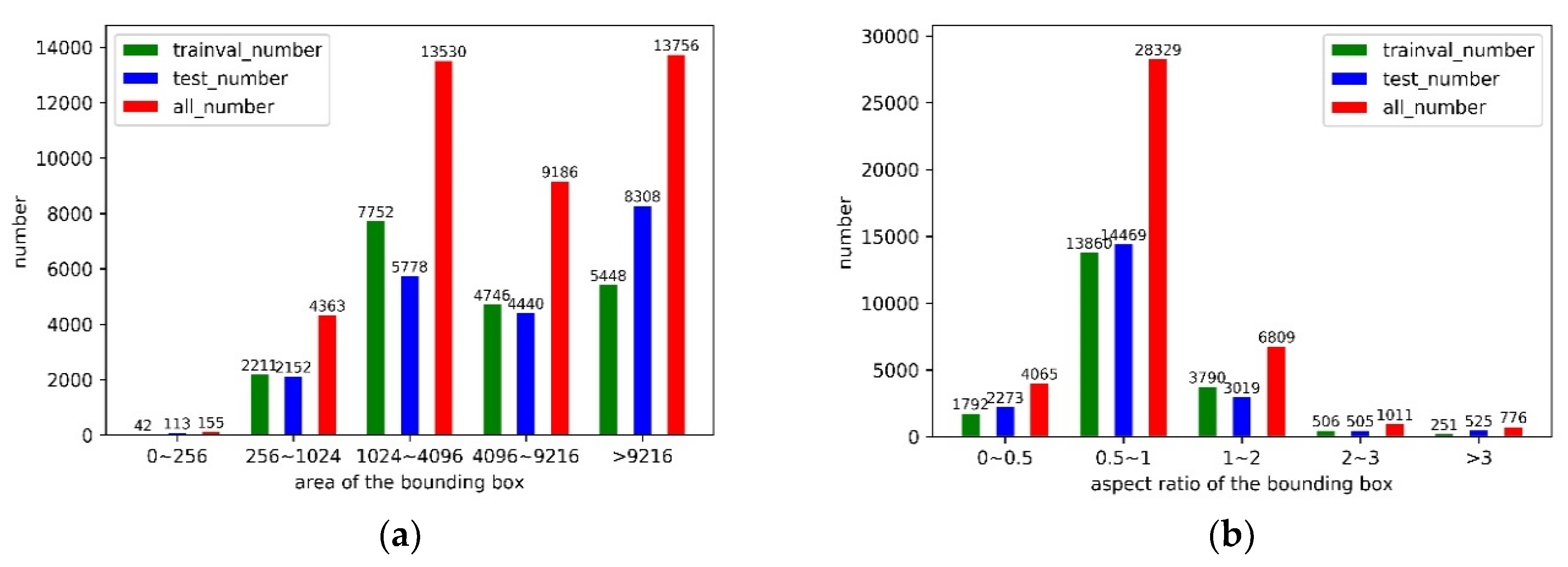
49] is applied to improve detection performance. Lastly, we also construct a large-scale remote-sensing dataset for geospatial object detection (RSD-GOD) with 40,990 well-annotated instances. There are a total of 5 object categories in the RSD-GOD: airport, plane, helicopter, warship, and oiltank. The constructed RSD-GOD remote-sensing dataset is open and available to the community, and can be found at:
https://github.com/ZhuangShuoH/geospatial-object-detection.
The main contributions of our work are summarized as follows:
- (1)
We produce and release a large-scale RSD-GOD with handcrafted annotations, which can be used for further geospatial object detection development especially in martial applications.
- (2)
We apply a single shot detection framework with the multi-scale feature fusion module for detection on three different scales. The different feature maps in different layers are merged to make object predictions, which means more abundant information is explored together. The proposed method achieves a good tradeoff between superior detection accuracy and computation efficiency. In addition, the designed network shows an effective performance at detecting small targets.
- (3)
The soft-NMS algorithm is applied through reassigning the neighboring bounding box a decayed score, which improves the detection performance of dense objects.
The rest of this paper is organized as follows.
Section 2 presents the large-scale dataset of RSD-GOD and the main framework of the feature fusion network.
Section 3 shows the analysis and discussion of the experimental results. Finally, conclusions are drawn in
Section 4.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}