Clustering Tools for Integration of Satellite Remote Sensing Imagery and Proximal Soil Sensing Data

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Sites and Data Description
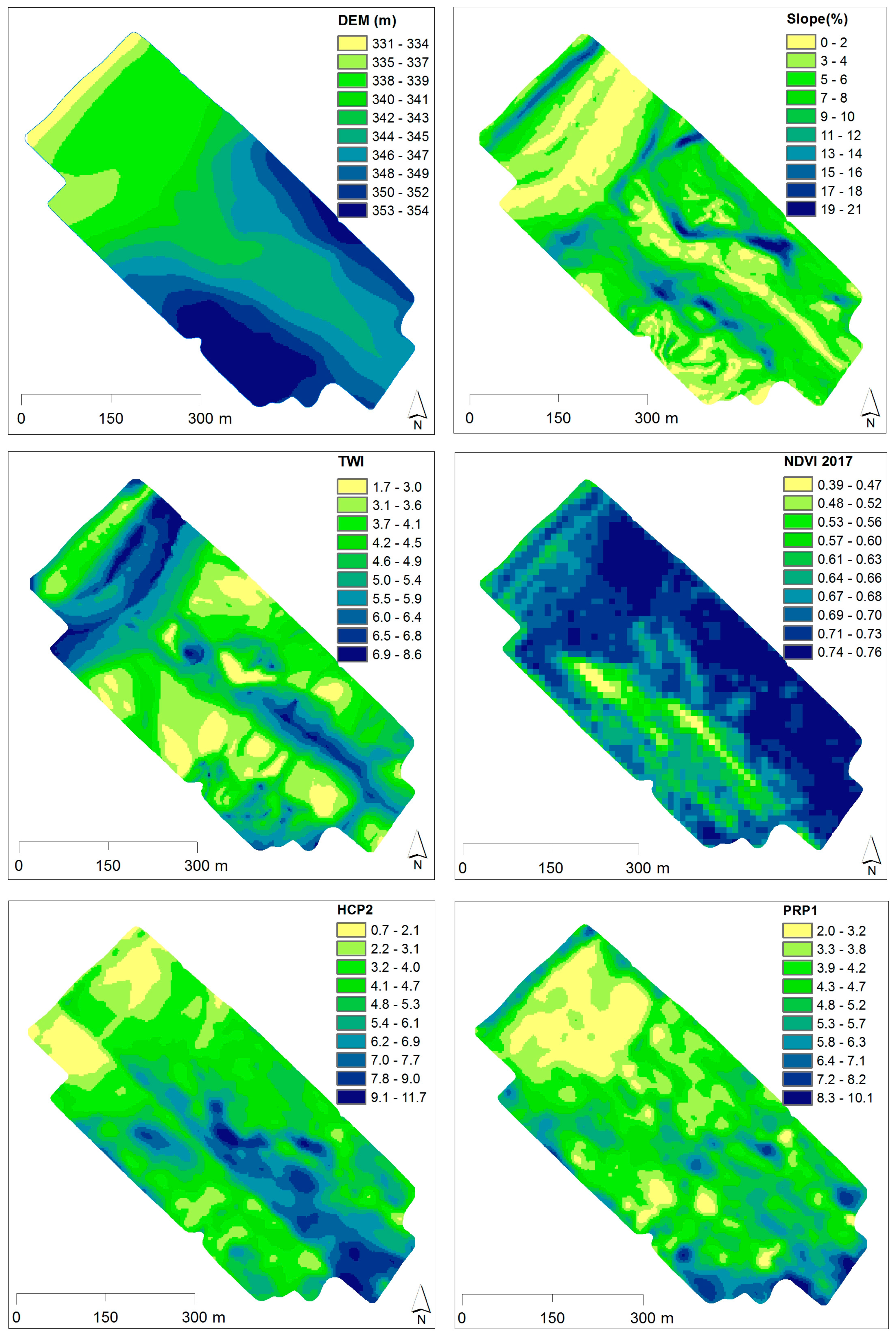
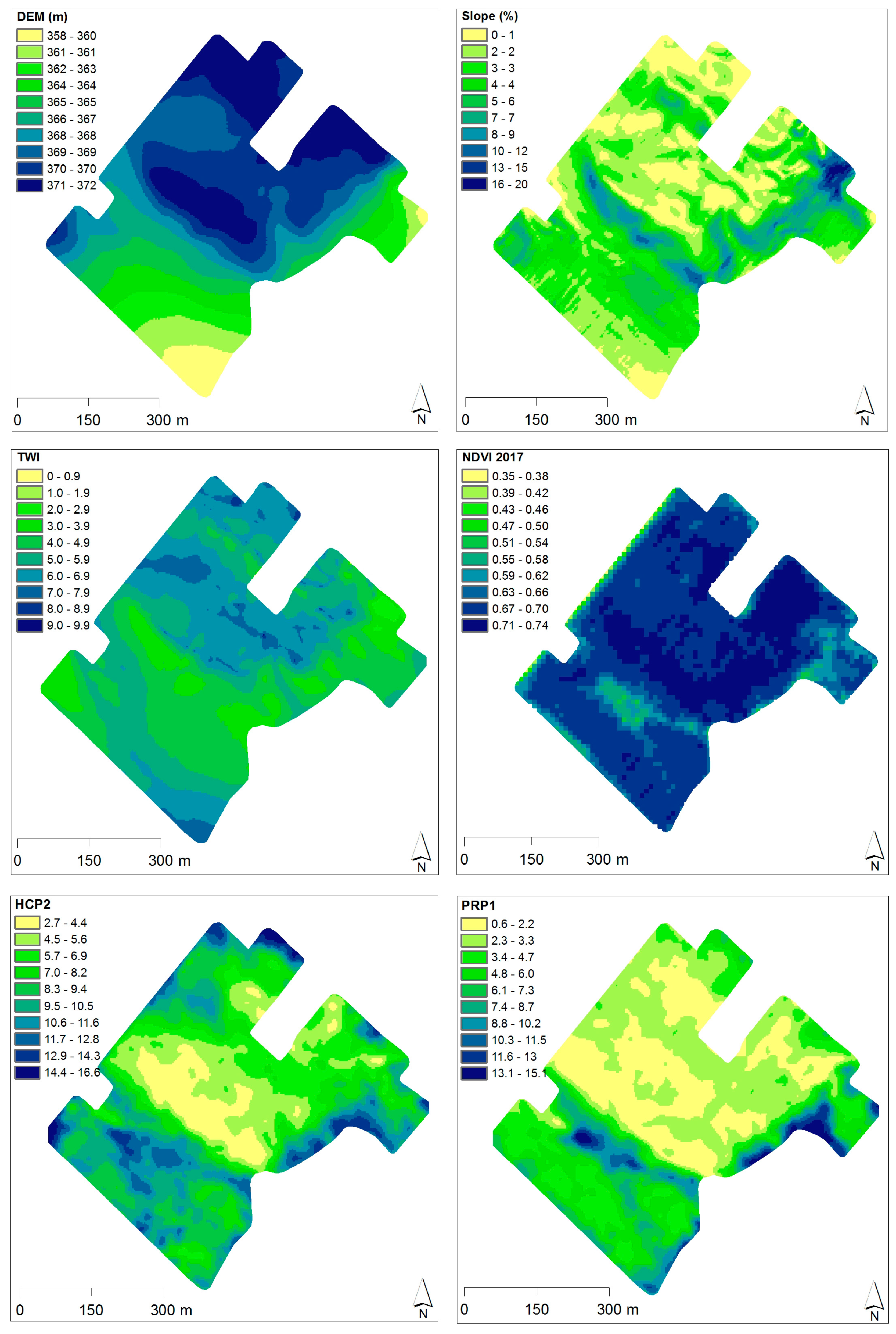
2.2. Interpolated Maps of Selected Sensor Variables
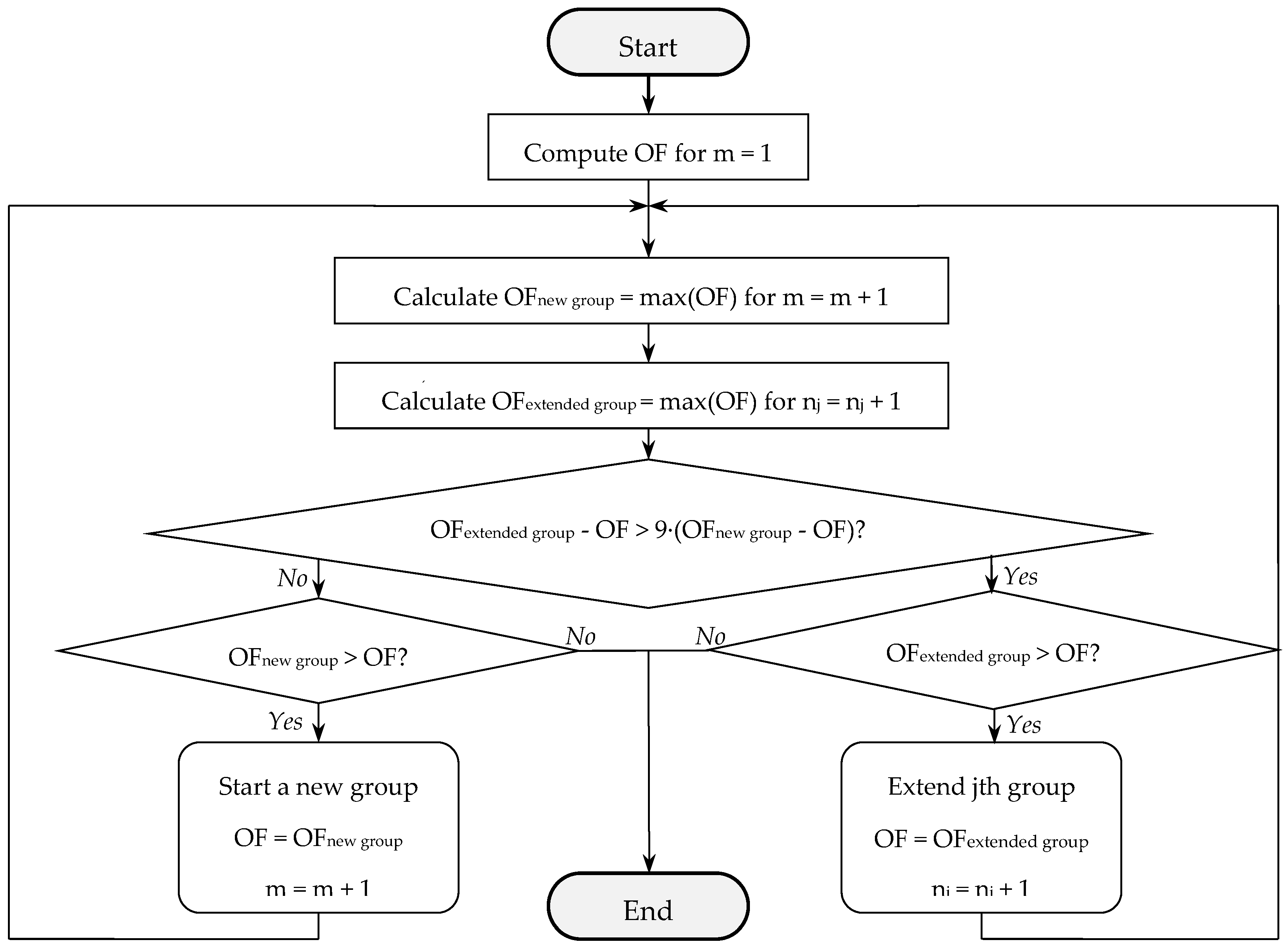
2.3. Data Clustering Algorithms
3. Results and Discussion
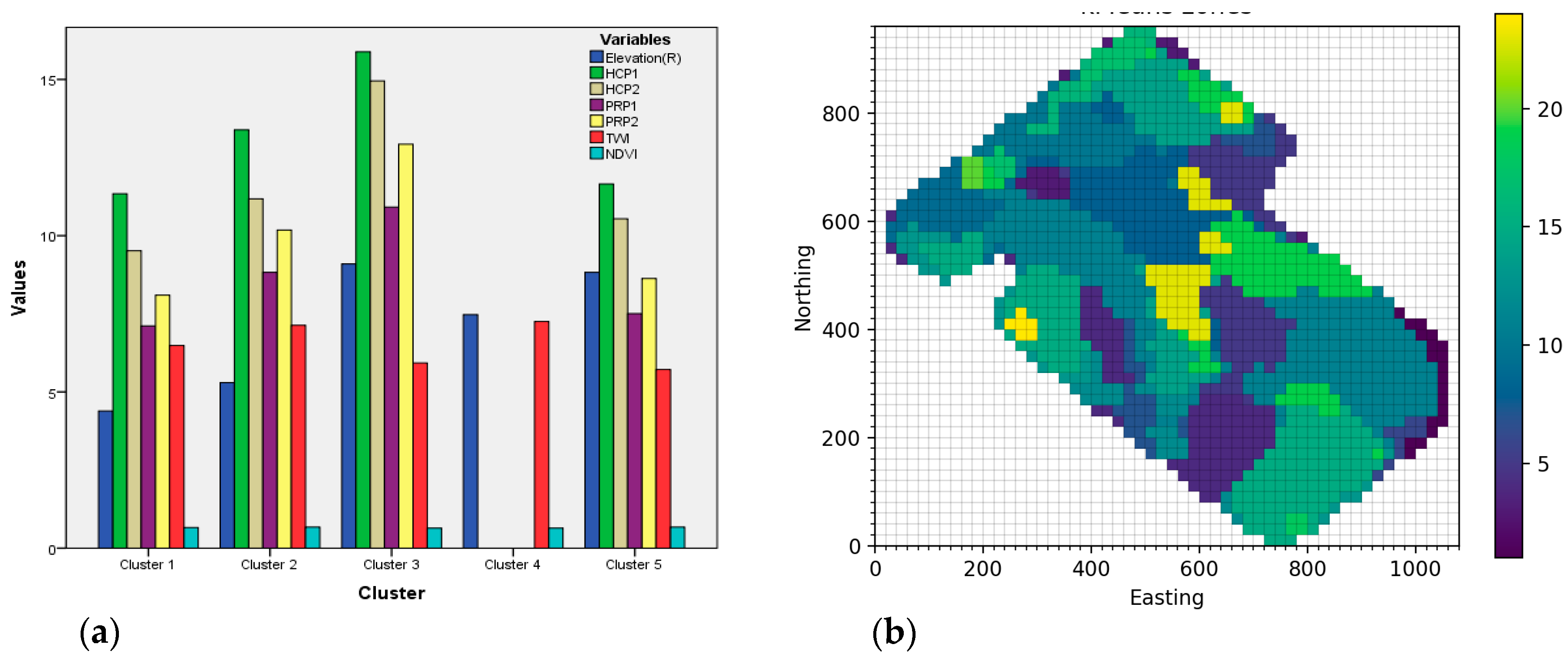
3.1. c-Means Clustering
3.2. k-Means Clustering
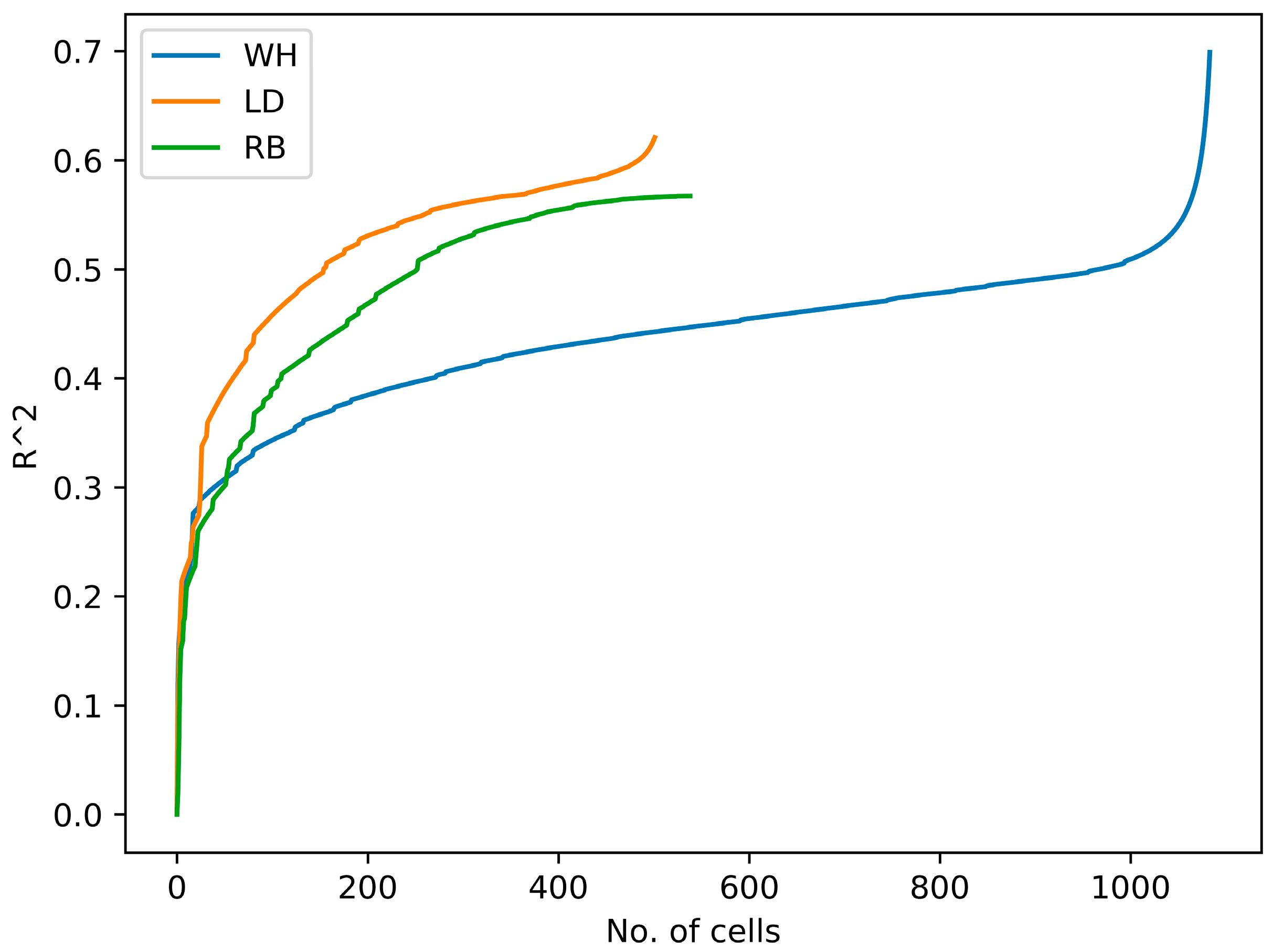
3.3. NSA Clustering
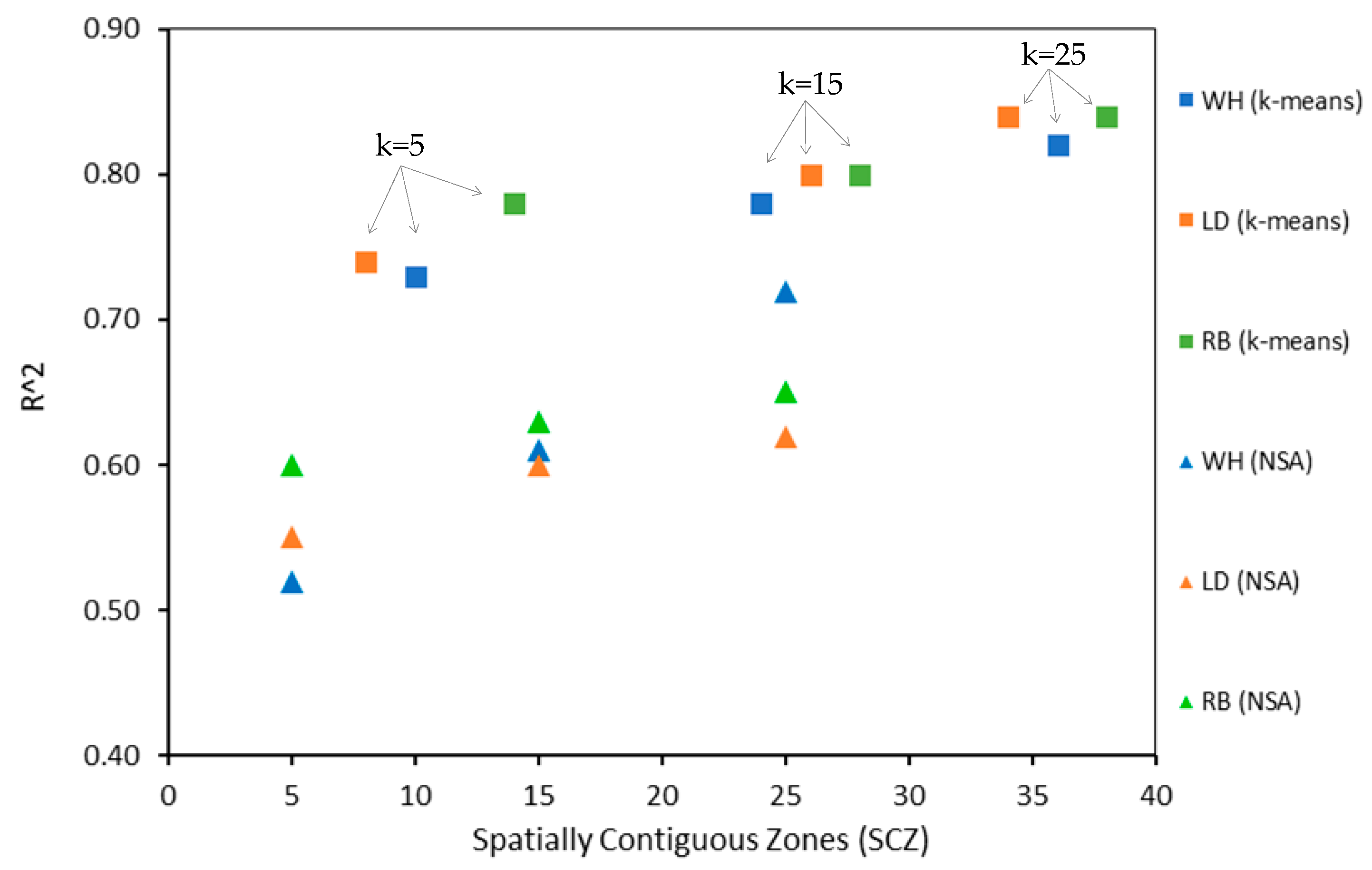
3.4. Comparison of k-Means and NSA Clustering
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, N.; Wang, M.; Wang, N. Precision Agriculture—A Worldwide Overview. Comput. Electron. Agric. 2002, 36, 113–132. [Google Scholar] [CrossRef]
- Shatar, T.M.; McBratney, A. Subdividing a Field into Contiguous Management Zones Using a K-Zones Algorithm. In 3rd European Conference on Precision Agriculture; Grenier, G., Blackmore, S., Eds.; Agro-Montpellier ENSAM: Montpellier, France, 2001; pp. 115–120. [Google Scholar]
- Fridgen, J.J.; Kitchen, N.R.; Sudduth, K.A.; Drummond, S.T.; Wiebold, W.J.; Fraisse, C.W. Management Zone Analyst (MZA): Software for Subfield Management Zone Delineation. Agron. J. 2004, 96, 100–108. [Google Scholar] [CrossRef]
- Khosla, R.; Westfall, D.G.; Reich, R.M.; Mahal, J.S.; Gangloff, W.J. Spatial Variation and Site-Specific Management Zones. In Geostatistical Applications for Precision Agriculture; Oliver, M.A., Ed.; Springer Science: Berlin, Germany, 2010; pp. 195–219. [Google Scholar]
- De Benedetto, D.; Castrignano, A.; Diacono, M.; Rinaldi, M.; Ruggieri, S.; Tamborrino, R. Field Partition by Proximal and Remote Sensing Data Fusion. Biosyst. Eng. 2013, 114, 372–383. [Google Scholar] [CrossRef]
- Dhawale, N.M.; Adamchuk, V.I.; Prasher, S.O.; Dutilleul, P.R.L.; Ferguson, R.B. Spatially Constrained Geospatial Data Clustering for Multilayer Sensor-Based Measurements. In Geospatial Theory, Processing, Modeling and Applications; ISPRS Technical Commission II Symposium: Toronto, ON, Canada, 2014; Volume 40, pp. 187–190. [Google Scholar]
- Castrignanò, A.; Buttafuoco, G.; Quarto, R.; Vitti, C.; Langella, G.; Terribile, F.; Venezia, A. A Combined Approach of Sensor Data Fusion and Multivariate Geostatistics for Delineation of Homogeneous Zones in an Agricultural Field. Sensors (MDPI) 2017, 17, 2794. [Google Scholar] [CrossRef] [PubMed]
- Albornoz, E.M.; Kemerer, A.C.; Galarza, R.; Mastaglia, N.; Melchiori, R.; Martínez, C.E. Development and Evaluation of an Automatic Software for Management Zone Delineation. Precis. Agric. 2018, 19, 463–476. [Google Scholar]
- Deng, X.; Wang, Y.; Peng, H. Clustering of High-Resolution Remote Sensing Imagery. In Third International Asia-Pacific Environmental Remote Sensing Remote Sensing of the Atmosphere, Ocean, Environment, and Space; Ungar, S., Mao, S., Yasuoka, Y., Eds.; SPIE: Hangzhou, China, 2003. [Google Scholar]
- Adamchuk, V.I.; Hummel, J.W.; Morgan, M.T.; Upadhyaya, S.K. On-the-Go Soil Sensors for Precision Agriculture. Comput. Electron. Agric. 2004, 44, 71–91. [Google Scholar] [CrossRef]
- Berkhin, P. A Survey of Clustering Data Mining Techniques. In Grouping Multidimensional Data; Springer: Berlin/Heidelberg, Germany, 2006; pp. 25–71. [Google Scholar] [Green Version]
- Cohen, S.; Cohen, Y.; Alchanatis, V.; Levi, O. Combining Spectral and Spatial Information from Aerial Hyperspectral Images for Delineating Homogenous Management Zones. Biosyst. Eng. 2013, 114, 435–443. [Google Scholar] [CrossRef]
- De Benedetto, D.; Castrignanò, A.; Rinaldi, M.; Ruggieri, S.; Santoro, F.; Figorito, B.; Gualano, S.; Diacono, M.; Tamborrino, R. An Approach for Delineating Homogeneous Zones by Using Multi-Sensor Data. Geoderma 2013, 199, 117–127. [Google Scholar] [CrossRef]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On Digital Soil Mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Vrindts, E.; Mouazen, A.M.; Reyniers, M.; Maertens, K.; Maleki, M.R.; Ramon, H.; De Baerdemaeker, J. Management Zones Based on Correlation between Soil Compaction, Yield and Crop Data. Biosyst. Eng. 2005, 92, 419–428. [Google Scholar] [CrossRef]
- Yan, L.; Zhou, S.; Feng, L. Delineation of Site-Specific Management Zones Based on Temporal and Spatial Variability of Soil Electrical Conductivity. Pedosphere 2007, 17, 156–164. [Google Scholar]
- Cressie, N.; Kang, E.L. High-Resolution Digital Soil Mapping: Kriging for Very Large Datasets. In Proximal Soil Sensing; Viscarra Rossel, R.A., McBratney, A.B., Minasny, B., Eds.; Springer: Dordrecht, The Netherlands, 2010; pp. 49–63. [Google Scholar]
- Jiang, Q.; Fu, Q.; Wang, Z. Study on Delineation of Irrigation Management Zones Based on Management Zone Analyst Software. In International Conference on Computer and Computing Technologies in Agriculture; Springer: Berlin/Heidelberg, Germany, 2010; pp. 419–427. [Google Scholar]
- Adamchuk, V.I.; Viscarra Rossel, R.A. Precision Agriculture: Proximal Soil Sensing. In Encyclopedia of Agrophysics; Gliński, J., Horabik, J., Lipiec, J., Eds.; Springer: Dordrecht, The Netherlands, 2011; pp. 650–656. [Google Scholar]
- Dhawale, N.; Adamchuk, V.; Huang, H.; Ji, W.; Lauzon, S.; Biswas, A.; Dutilleul, P. Integrated Analysis of Multilayer Proximal Soil Sensing Data. In Proceedings of the International Conference on Precision Agriculture, St. Louis, MO, USA, 31 July–4 August 2016. [Google Scholar]
- Samet, H. An Overview of Hierarchical Spatial Data Structures. In Proceedings of the Fifth Israeli Symposium on Artificial Intelligence, Vision, and Pattern Recognition, Tel-Aviv, Ganei-Hata’arucha, Israel, 27–28 December 1988; pp. 331–351. [Google Scholar]
- Arabie, P.; Hubert, L.J. An Overview of Combinatorial Data Analysis. In Clustering and Classification; Arabie, P., Soete, G.D., Hubert, L.J., Eds.; World Scientific Pub. Co.: Singapore, 1996; pp. 5–63. [Google Scholar]
- Fisher, D. Iterative Optimization and Simplification of Hierarchical Clustering. J. Artif. Intell. Res. 1996, 4, 147–178. [Google Scholar] [CrossRef]
- Burrough, P.A.; Van Gaans, P.F.M.; Hootsmans, R. Continuous Classification in Soil Survey: Spatial Correlation, Confusion and Boundaries. Geoderma 1997, 77, 115–135. [Google Scholar] [CrossRef]
- Ruß, G.; Brenning, A. Data Mining in Precision Agriculture: Management of Spatial Information. In Computational Intelligence for Knowledge-Based Systems Design; Hüllermeier, E., Kruse, R., Hoffmann, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 350–359. [Google Scholar]
- Johnson, S.C. Hierarchical Clustering Schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Sadahiro, Y. Cluster Perception in the Distribution of Point Objects. Cartogr. Int. J. Geogr. Inf. Geovisualization 1997, 34, 49–62. [Google Scholar] [CrossRef]
- Fraisse, C.W.; Sudduth, K.A.; Kitchen, N.R. Delineation of Site-Specific Management Zones by Unsupervised Classification. Trans. ASAE 2001, 44, 155–166. [Google Scholar] [CrossRef]
- Motwani, M. A Study on Initial Centroids Selection for Partitional Clustering Algorithms. Adv. Intell. Syst. Comput. 2019, 731, 211–220. [Google Scholar]
- De Gruijter, J.J.; Walvoort, D.J.J.; Van Gaans, P.F.M. Continuous Soil Maps—A Fuzzy Set Approach to Bridge the Gap between Aggregation Levels of Process and Distribution Models. Geoderma 1997, 77, 169–195. [Google Scholar] [CrossRef]
- Gui-Fen, C.; Li-Ying, C.; Guo-Wei, W.; Bao-Cheng, W.; Da-You, L.; Sheng-Sheng, W. Application of a Spatial Fuzzy Clustering Algorithm in Precision Fertilisation. N. Z. J. Agric. Res. 2007, 50, 1249–1254. [Google Scholar] [CrossRef]
- Panda, S.; Sahu, S.; Jena, P.; Chattopadhyay, S. Comparing Fuzzy-C Means and K-Means Clustering Techniques: A Comprehensive Study. Adv. Intell. Soft Comput. 2012, 166, 451–460. [Google Scholar]
- Orhan, U.; Hekim, M.; Ozer, M. EEG Signals Classification Using the K-Means Clustering and a Multilayer Perceptron Neural Network Model. Expert Syst. Appl. 2011, 38, 13475–13481. [Google Scholar] [CrossRef]
- Saifuzzaman, M.; Adamchuk, V.; Huang, H.-H.; Ji, W.; Rabe, N.; Biswas, A. Data Clustering Tools for Understanding Spatial Heterogeneity in Crop Production by Integrating Proximal Soil Sensing and Remote Sensing Data. In Proceedings of the 14th International Conference on Precision Agriculture, Montreal, QC, Canada, 24–27 June 2018; International Society of Precision Agriculture: Monticello, IL, USA; p. 14. Available online: http://www.ispag.org (accessed on 20 June 2018).
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. Density-Based Clustering Algorithms for Discovering Clusters. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Liu, Y.; Xiong, N.; Zhao, Y.; Vasilakos, A.V.; Gao, J.; Jia, Y. Multi-Layer Clustering Routing Algorithm for Wireless Vehicular Sensor Networks. IET Commun. 2010, 4, 810. [Google Scholar] [CrossRef]
- Viscarra Rossel, R.A.; Adamchuk, V.I.; Sudduth, K.A.; McKenzie, N.J.; Lobsey, C. Proximal Soil Sensing: An Effective Approach for Soil Measurements in Space and Time. Adv. Agron. 2011, 113, 237–283. [Google Scholar]
- Córdoba, M.A.; Bruno, C.I.; Costa, J.L.; Peralta, N.R.; Balzarini, M.G. Protocol for Multivariate Homogeneous Zone Delineation in Precision Agriculture. Biosyst. Eng. 2016, 143, 95–107. [Google Scholar] [CrossRef]
- González-Fernández, A.B.; Rodríguez-Pérez, J.R.; Ablanedo, E.S.; Ordoñez, C. Vineyard Zone Delineation by Cluster Classification Based on Annual Grape and Vine Characteristics. Precis. Agric. 2017, 18, 525–573. [Google Scholar] [CrossRef]
- Lazarevic, A.; Xu, X.; Fiez, T.; Obradovic, Z. Clustering-Regression-Ordering Steps for Knowledge Discovery in Spatial Databases. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 10–16 July 1999; pp. 2530–2534. [Google Scholar]
- Walters, R.W.; Jenq, R.R.; Hall, S.B. Evaluating Farmer Defined Management Zone Maps for Variable Rate Fertilizer Application. Precis. Agric. 2000, 2, 201–215. [Google Scholar]
- Khosla, R.; Fleming, K.; Delgado, J.A.; Shaver, T.M.; Westfall, D.G. Use of Site-Specific Management Zones to Improve Nitrogen Management for Precision Agriculture. J. Soil Water Conserv. 2002, 57, 513–518. [Google Scholar]
- Mondal, P.; Jain, M.; Defries, R.S.; Galford, G.L.; Small, C. Sensitivity of Crop Cover to Climate Variability: Insights from Two Indian Agro-Ecoregions. J. Environ. Manag. 2014, 148, 21–30. [Google Scholar] [CrossRef]
- Huang, Y.; Lan, Y.; Thomson, S.J.; Fang, A.; Hoffmann, W.C.; Lacey, R.E. Development of Soft Computing and Applications in Agricultural and Biological Engineering. Comput. Electron. Agric. 2010, 71, 107–127. [Google Scholar] [CrossRef]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Roberts, D.F.; Adamchuk, V.I.; Shanahan, J.F.; Ferguson, R.B.; Schepers, J.S. Estimation of Surface Soil Organic Matter Using a Ground-Based Active Sensor and Aerial Imagery. Precis. Agric. 2011, 12, 82–102. [Google Scholar] [CrossRef]
- Viña, A.; Gitelson, A.A.; Nguy-robertson, A.L.; Peng, Y. Remote Sensing of Environment Comparison of Different Vegetation Indices for the Remote Assessment of Green Leaf Area Index of Crops. Remote Sens. Environ. 2011, 115, 3468–3478. [Google Scholar] [CrossRef]
- U.S. Department of Agriculture (USDA). Management Zone Analyst Version 1.0 Software; U.S. Department of Agriculture: Washington, DC, USA, 2000.
- GNip, P.G.; Harvát, K.C. Management of Zones in Precision Farming. Agric. Econ. 2003, 49, 416–418. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. A K-Means Clustering Algorithm. Appl. Stat. 2012, 28, 100–108. [Google Scholar] [CrossRef]
- Nazeer, K.A.A.; Sebastian, M.P. Improving the Accuracy and Efficiency of the k-Means Clustering Algorithm. Proc. World Cong. Eng. 2009, I, 1–5. [Google Scholar]
- Vendrusculo, L.G.; Kaleita, A.F. Modeling Zone Management in Precision Agriculture through Fuzzy C-Means Technique at Spatial Database. In Proceedings of the Agricultural and Biosystems Engineering Conference, Louisville, KY, USA, 8–10 August 2011; Volume 4, pp. 2701–2715. [Google Scholar]
- Bragato, G. Fuzzy Continuous Classification and Spatial Interpolation in Conventional Soil Survey for Soil Mapping of the Lower Piave Plain. Geoderma 2004, 118, 1–16. [Google Scholar] [CrossRef]
- Yan, L.; Zhou, S.; Feng, L.; Hong-Yi, L. Delineation of Site-Specific Management Zones Using Fuzzy Clustering Analysis in a Coastal Saline Land. Comput. Electron. Agric. 2007, 56, 174–186. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field ID | Area (ha) | Soil Classes | Target Crops |
|---|---|---|---|
| WH | 39.60 | Loam | Soybean/Wheat |
| LD | 21.00 | Sandy Loam | Soybean |
| RB | 75.00 | Fine Sandy Loam | Soybean/Wheat |
| Field ID | # of Measurements | Elevation (m) | |||||
|---|---|---|---|---|---|---|---|
| Min | Median | Max | Range | STD | Mean | ||
| WH | 28493 | 372.06 | 378.07 | 384.54 | 12.48 | 2.33 | 378.21 |
| LD | 7110 | 332.70 | 344.86 | 354.17 | 21.47 | 5.76 | 343.95 |
| RB | 20813 | 358.41 | 367.67 | 372.16 | 13.75 | 3.63 | 366.64 |
| Field ID | # of Measurements | Sensor Configuration | Apparent Soil Electrical Conductivity (ECa), mS m−1 | |||||
|---|---|---|---|---|---|---|---|---|
| Min | Median | Max | Range | STD | Mean | |||
| WH | 20129 | HCP1 | 4.00 | 12.28 | 25.28 | 21.28 | 1.69 | 12.51 |
| LD | 6931 | 2.58 | 6.90 | 16.08 | 13.50 | 1.55 | 6.96 | |
| RB | 18524 | 1.70 | 9.00 | 17.98 | 16.28 | 2.81 | 9.13 | |
| WH | 20129 | PRP1 | 4.68 | 7.92 | 22.24 | 17.56 | 1.60 | 8.15 |
| LD | 6931 | 0.72 | 4.44 | 14.12 | 13.40 | 1.38 | 4.55 | |
| RB | 18524 | 0.00 | 3.53 | 16.80 | 16.80 | 2.86 | 4.40 | |
| WH | 20129 | HCP2 | 7.42 | 10.46 | 24.42 | 17.00 | 1.79 | 10.83 |
| LD | 6931 | 0.50 | 4.44 | 14.44 | 13.94 | 1.85 | 4.61 | |
| RB | 18524 | 2.50 | 8.45 | 14.99 | 12.49 | 2.65 | 8.22 | |
| WH | 20129 | PRP2 | 5.42 | 9.10 | 23.92 | 18.50 | 1.75 | 9.37 |
| LD | 6931 | 1.08 | 4.68 | 14.60 | 13.52 | 1.50 | 4.75 | |
| RB | 18524 | 0.14 | 5.10 | 15.00 | 14.86 | 2.96 | 5.64 | |
| Satellite Sensor | Spectral Bands | Pixel (m) | Central Wavelength(nm) | Imaging Date | Source |
|---|---|---|---|---|---|
| OrthoPhoto | B, G, R, NIR | 0.2 | - | 23 May 2015 | OMAFRA/OMNRF 1 |
| Sentinel-2 | 2(B), 3(G), 4(R), 8(NIR) | 10.0 | 494, 560, 665, 834 | 21 July 2017 | Planet Labs |
| Sentinel-2 | 5,6,7 (red edge 1,2 &3) | 20.0 | 704, 740, 781 | 21 July 2017 | Planet Labs |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saifuzzaman, M.; Adamchuk, V.; Buelvas, R.; Biswas, A.; Prasher, S.; Rabe, N.; Aspinall, D.; Ji, W. Clustering Tools for Integration of Satellite Remote Sensing Imagery and Proximal Soil Sensing Data. Remote Sens. 2019, 11, 1036. https://doi.org/10.3390/rs11091036
Saifuzzaman M, Adamchuk V, Buelvas R, Biswas A, Prasher S, Rabe N, Aspinall D, Ji W. Clustering Tools for Integration of Satellite Remote Sensing Imagery and Proximal Soil Sensing Data. Remote Sensing. 2019; 11(9):1036. https://doi.org/10.3390/rs11091036
Chicago/Turabian StyleSaifuzzaman, Md, Viacheslav Adamchuk, Roberto Buelvas, Asim Biswas, Shiv Prasher, Nicole Rabe, Doug Aspinall, and Wenjun Ji. 2019. "Clustering Tools for Integration of Satellite Remote Sensing Imagery and Proximal Soil Sensing Data" Remote Sensing 11, no. 9: 1036. https://doi.org/10.3390/rs11091036