Identification of Urban Functional Areas by Coupling Satellite Images and Taxi GPS Trajectories




Abstract
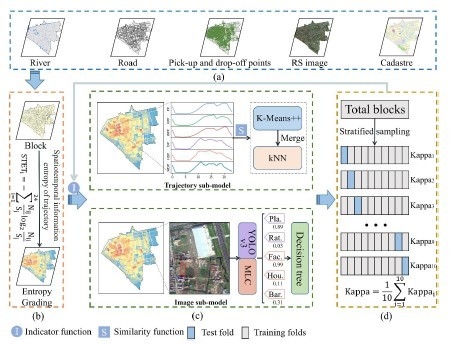
:
1. Introduction
- (1)
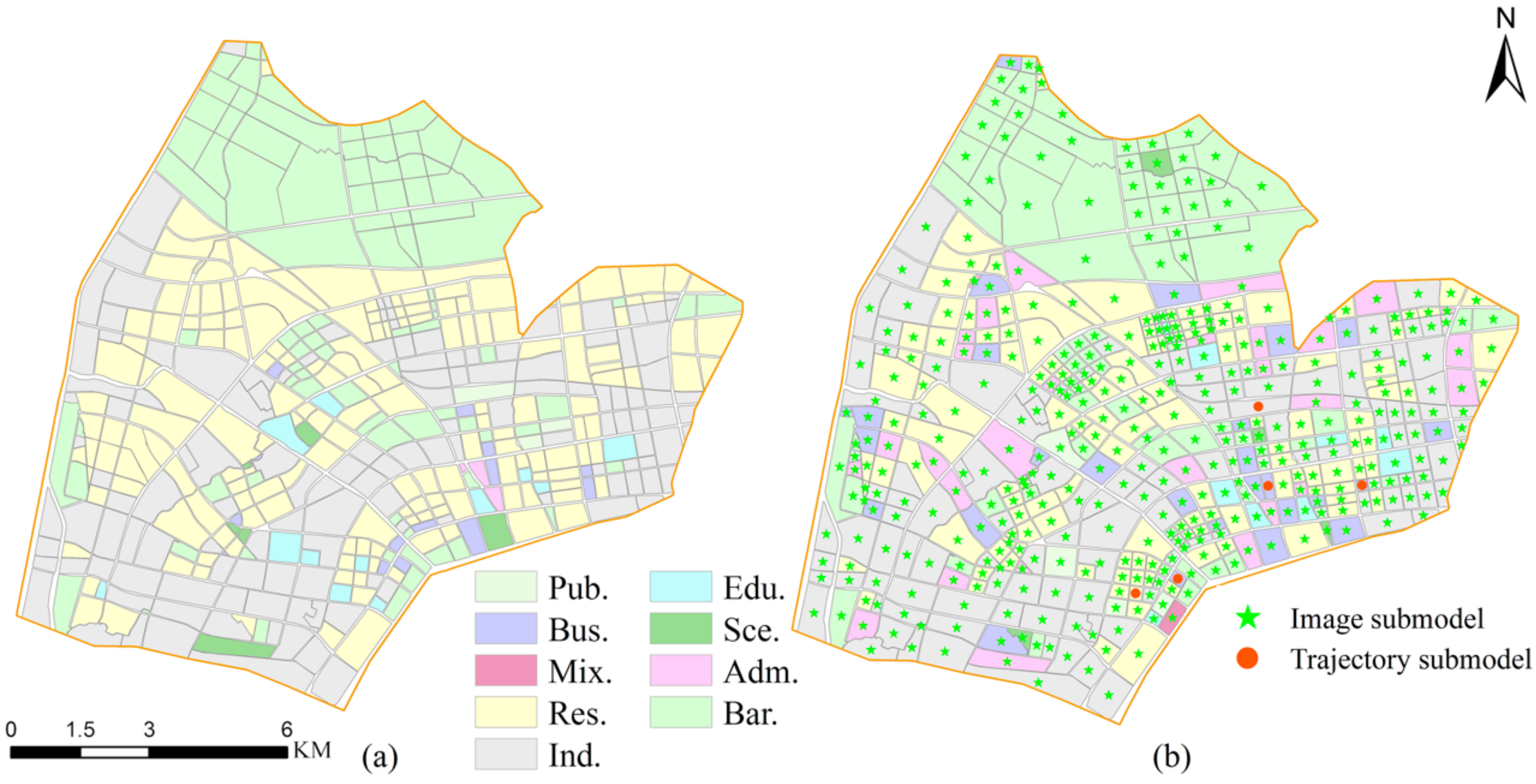
- An integrated model of UFA identification was proposed. The functional type of some blocks was identified by the trajectory sub-model, while that of others was by the image sub-model. All these depend on the sufficiency of information of the trajectory data in the block. This new model can allow the advantages of social-sensing data and satellite images to be fully exploited and, thus, improves the identification accuracy.
- (2)
- A new index was designed and named STET, which was used as an index to measure the information of the trajectory data of blocks. A suitable sub-model was then selected to identify the UFA based on the STET index.
- (3)
- In the image sub-model, the multilabel classification method based on the residual neural network (MLC-ResNets) and You Only Look Once (YOLO) v3 algorithms were used to identify the land uses in the satellite image. Features with typical interpretation keys, such as schools, were identified using YOLO v3, while other features, such as residential areas, were identified using MLC-ResNets.
2. Study Area and Datasets
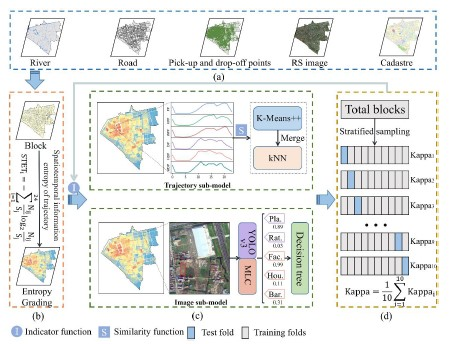
2.1. Study Area
2.2. Datasets and Data Processing
3. Methodology
3.1. Blocks and STET
3.1.1. Generation of Blocks
3.1.2. STET Computing
3.2. Trajectory-Based Sub-Model
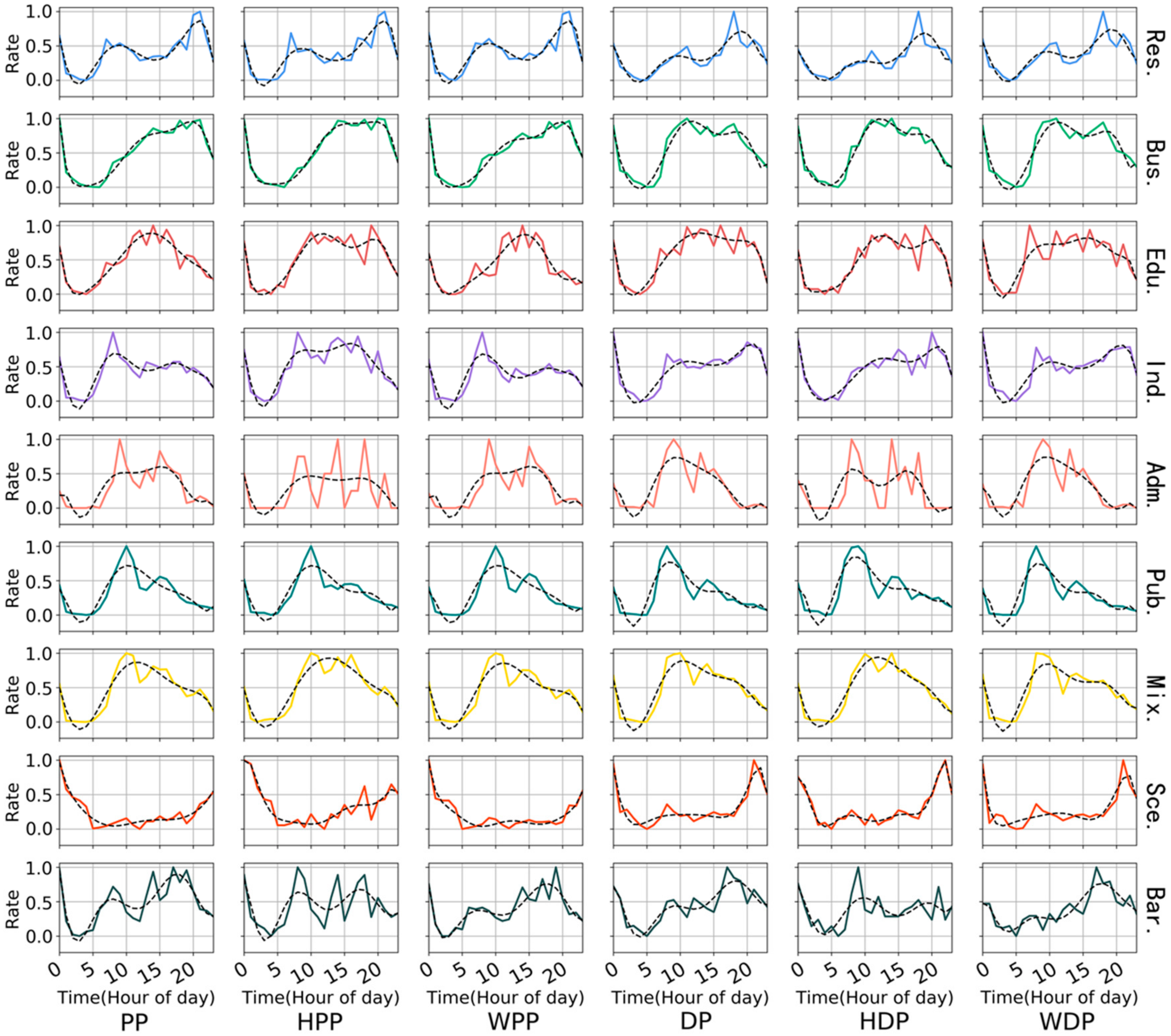
3.2.1. Time Frequency Series and K-Means++
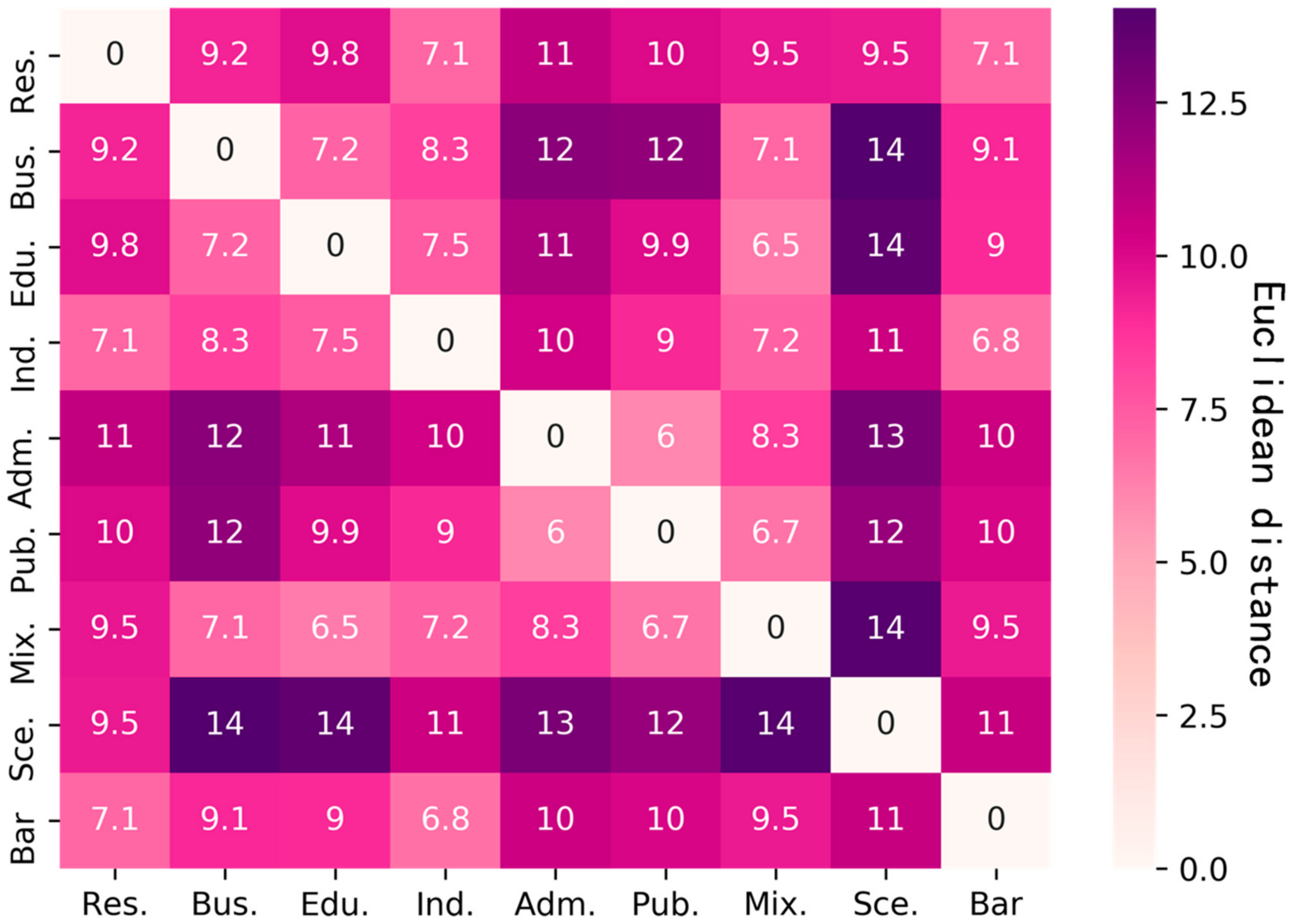
3.2.2. Clustering Analysis
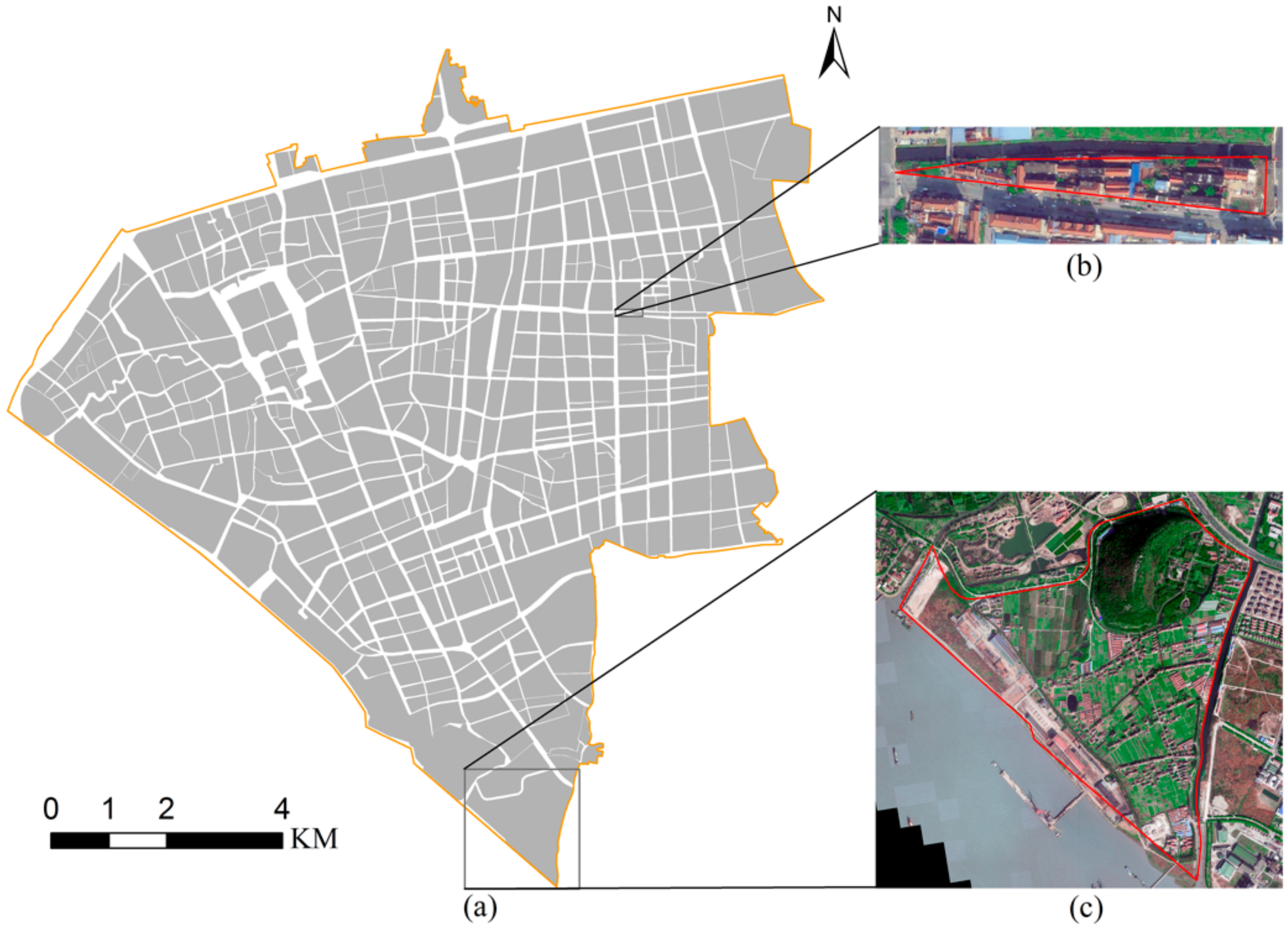
3.3. Image-Based Sub-Model
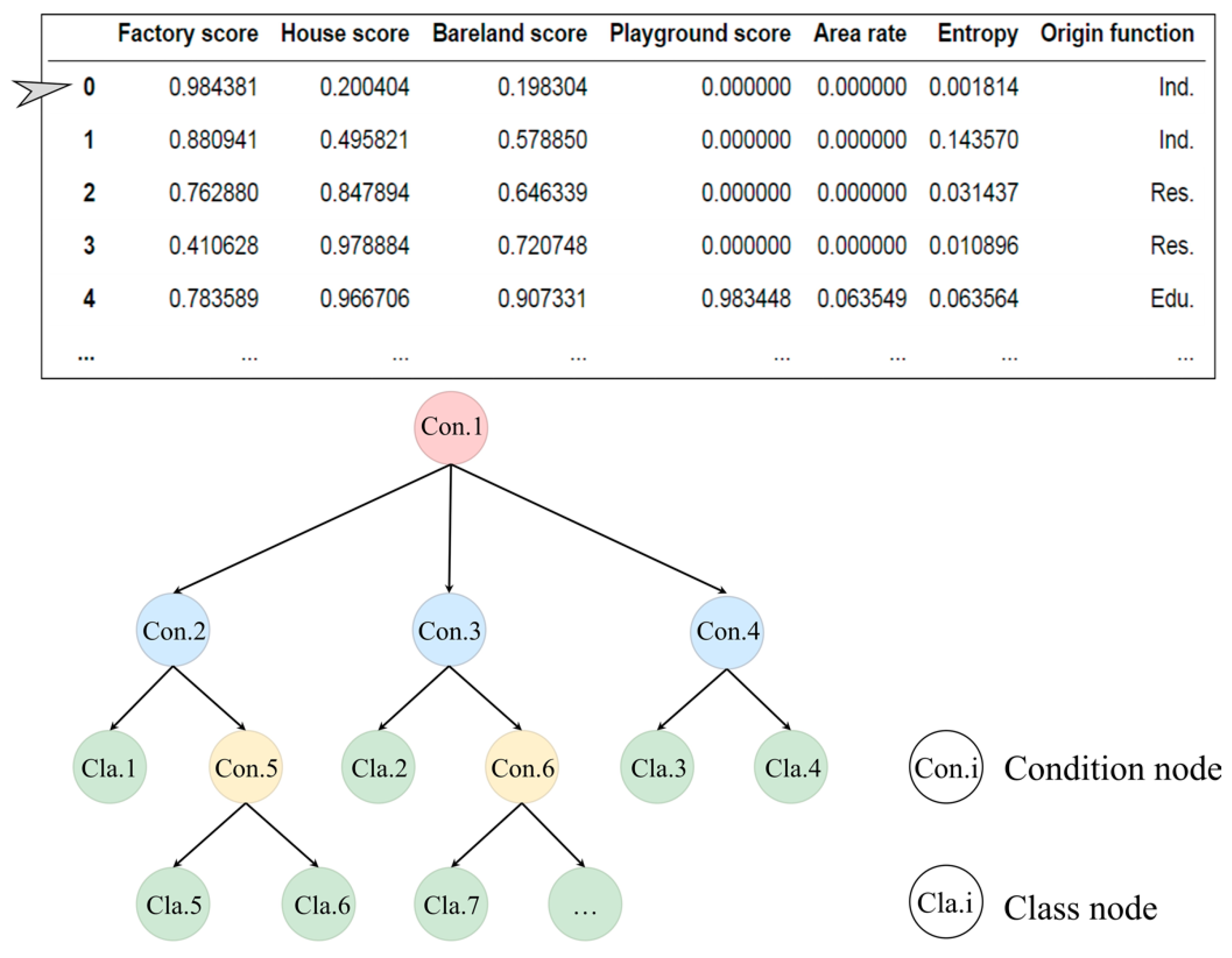
3.3.1. MLC-ResNets, YOLO v3 and Decision Tree
3.3.2. Image Analysis
3.4. Model Verification Method
3.4.1. Stratified Random Sampling
3.4.2. K-fold Cross-Validation
3.4.3. Kappa Coefficient
4. Results and Discussion
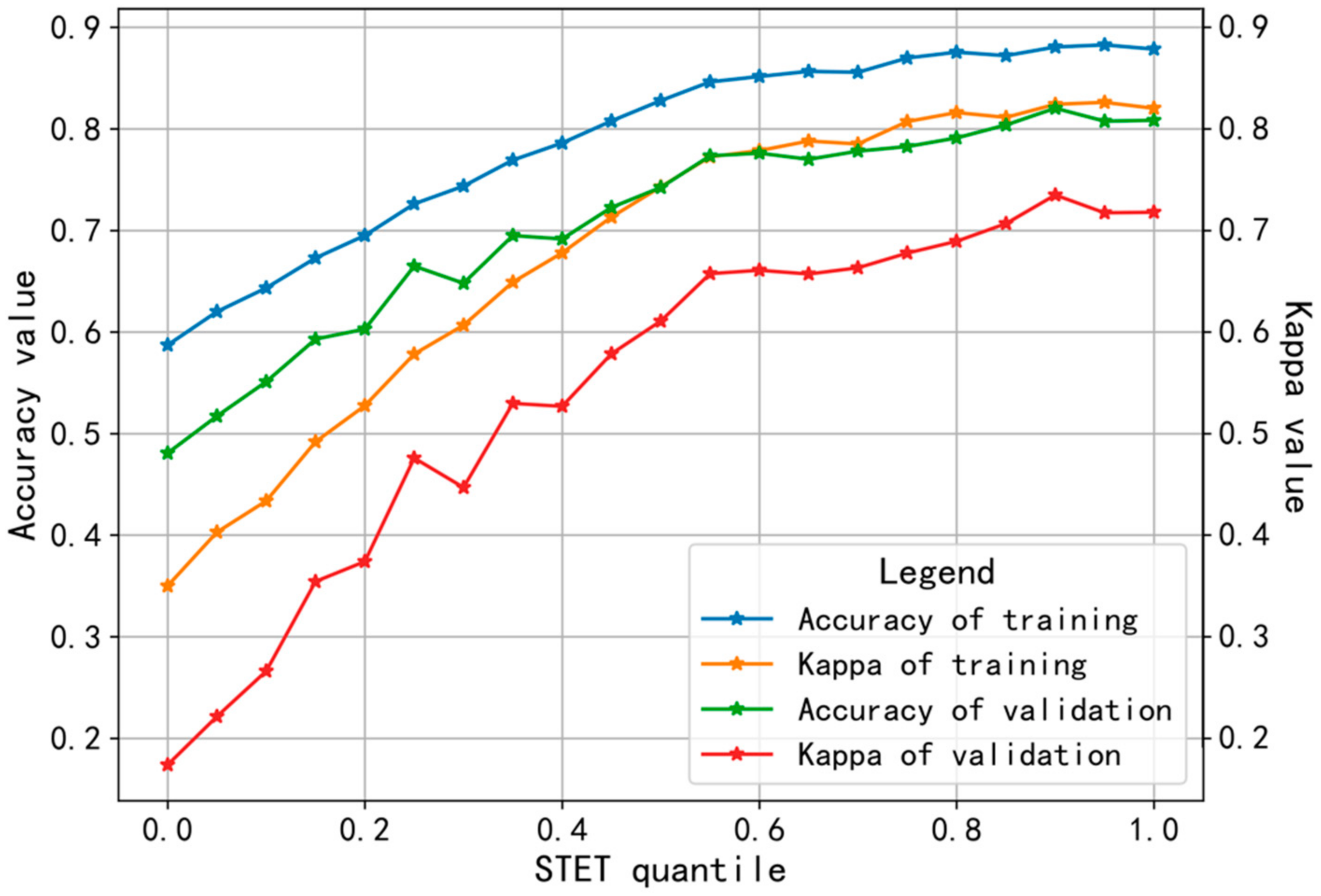
4.1. STET Analysis
4.2. Results of the Trajectory Sub-Model
4.2.1. HDS Result
4.2.2. Cluster Result
4.3. Results of the Image Sub-Model
4.3.1. Image Classification Result
4.3.2. Decision Tree Result
4.4. Model Parameter Adjustment
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wei, C.; Padgham, M.; Cabrera Barona, P.; Blaschke, T. Scale-free relationships between social and landscape factors in urban systems. Sustainability 2017, 9, 84. [Google Scholar] [CrossRef] [Green Version]
- Jie, F.; Anjun, T.; Qing, R. On the historical background, scientific intentions, goal orientation, and policy framework of major function-oriented zone planning in China. J. Resour. Ecol. 2010, 1, 289–299. [Google Scholar]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2014, 27, 712–725. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Deng, Z.; Zhu, X.; He, Q.; Tang, L. Land use/land cover classification using time series Landsat 8 images in a heavily urbanized area. Adv. Sp. Res. 2019, 63, 2144–2154. [Google Scholar] [CrossRef]
- Obodai, J.; Adjei, K.A.; Odai, S.N.; Lumor, M. Land use/land cover dynamics using landsat data in a gold mining basin-the Ankobra, Ghana. Remote Sens. Appl. Soc. Environ. 2019, 13, 247–256. [Google Scholar] [CrossRef]
- Li, X.; Zhao, L.; Li, D.; Xu, H. Mapping urban extent using Luojia 1-01 nighttime light imagery. Sensors 2018, 18, 3665. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Zhou, T.; Tao, F.; Zang, F. Correlation Analysis between UBD and LST in Hefei, China, Using Luojia1-01 Night-Time Light Imagery. Appl. Sci. 2019, 9, 5224. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Chen, Y.; Li, Y. The random forest-based method of fine-resolution population spatialization by using the international space station nighttime photography and social sensing data. Remote Sens. 2018, 10, 1650. [Google Scholar] [CrossRef] [Green Version]
- Cao, R.; Tu, W.; Yang, C.; Li, Q.; Liu, J.; Zhu, J.; Zhang, Q.; Li, Q.; Qiu, G. Deep learning-based remote and social sensing data fusion for urban region function recognition. ISPRS J. Photogramm. Remote Sens. 2020, 163, 82–97. [Google Scholar] [CrossRef]
- Zhou, T.; Shi, W.; Liu, X.; Tao, F.; Qian, Z.; Zhang, R. A novel approach for online car-hailing monitoring using spatiotemporal big data. IEEE Access 2019, 7, 128936–128947. [Google Scholar] [CrossRef]
- Jiang, Z.; Evans, M.; Oliver, D.; Shekhar, S. Identifying K Primary Corridors from urban bicycle GPS trajectories on a road network. Inf. Syst. 2016, 57, 142–159. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Jin, B.; Wang, Z.; Liu, H.; Hu, J.; Zhang, L. On geocasting over urban bus-based networks by mining trajectories. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1734–1747. [Google Scholar] [CrossRef]
- Sui, X.; Chen, Z.; Guo, L.; Wu, K.; Ma, J.; Wang, G. Social media as sensor in real world: Movement trajectory detection with microblog. Soft Comput. 2017, 21, 765–779. [Google Scholar] [CrossRef]
- Luo, F.; Cao, G.; Mulligan, K.; Li, X. Explore spatiotemporal and demographic characteristics of human mobility via Twitter: A case study of Chicago. Appl. Geogr. 2016, 70, 11–25. [Google Scholar] [CrossRef] [Green Version]
- Roe, D.R.; Cheatham, T.E., III. PTRAJ and CPPTRAJ: Software for processing and analysis of molecular dynamics trajectory data. J. Chem. Theory Comput. 2013, 9, 3084–3095. [Google Scholar] [CrossRef]
- Baral, R.; Li, T. Exploiting the roles of aspects in personalized POI recommender systems. Data Min. Knowl. Discov. 2018, 32, 320–343. [Google Scholar] [CrossRef]
- Zhou, T.; Liu, X.; Qian, Z.; Chen, H.; Tao, F. Automatic identification of the social functions of areas of interest (AOIs) using the standard hour- day-spectrum approach. ISPRS Int. J. Geo Information 2019, 9, 7. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Tian, Y.; Zhang, X.; Wan, Z. Identification of urban functional regions in chengdu based on taxi trajectory time series data. ISPRS Int. J. Geo Inf. 2020, 9, 158. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Liu, X.; Qian, Z.; Chen, H.; Tao, F. Dynamic update and monitoring of AOI entrance via spatiotemporal clustering of drop-off points. Sustainability 2019, 11, 6870. [Google Scholar] [CrossRef] [Green Version]
- Shirowzhan, S.; Lim, S.; Trinder, J.; Li, H.; Sepasgozar, S.M.E. Data mining for recognition of spatial distribution patterns of building heights using airborne lidar data. Adv. Eng. Inform. 2020, 43, 101033. [Google Scholar] [CrossRef]
- Calabrese, F.; Diao, M.; Di Lorenzo, G.; Ferreir, J., Jr.; Ratti, C. Understanding individual mobility patterns from urban sensing data: A mobile phone trace example. Transp. Res. Part C Emerg. Technol. 2013, 26, 301–313. [Google Scholar] [CrossRef]
- Ma, W.; Zhang, J.; Zhao, Y.; Zhang, P.; Dang, Y.; Zhao, T. Design and establishment of quality model of fundamental geographic information database. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 3. [Google Scholar] [CrossRef] [Green Version]
- Tu, W.; Hu, Z.; Li, L.; Cao, J.; Jiang, J.; Li, Q.; Li, Q. Portraying urban functional zones by coupling remote sensing imagery and human sensing data. Remote Sens. 2018, 10, 141. [Google Scholar] [CrossRef] [Green Version]
- What are Census Blocks? Available online: https://www.census.gov/newsroom/blogs/random-samplings/2011/07/what-are-census-blocks.html (accessed on 17 April 2020).
- Liang, J.; Zhao, X.; Li, D.; Cao, F.; Dang, C. Determining the number of clusters using information entropy for mixed data. Pattern Recognit. 2012, 45, 2251–2265. [Google Scholar] [CrossRef]
- Hu, Y.; Han, Y. Identification of urban functional areas based on POI data: A case study of the Guangzhou economic and technological development zone. Sustainability 2019, 11, 1385. [Google Scholar] [CrossRef] [Green Version]
- Yuan, G.; Sun, P.; Zhao, J.; Li, D.; Wang, C. A review of moving object trajectory clustering algorithms. Artif. Intell. Rev. 2017, 47, 123–144. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Zhou, H.; Yuan, Q.; Cheng, Z.; Shi, B. PHC: A fast partition and hierarchy-based clustering algorithm. J. Comput. Sci. Technol. 2003, 18, 407–411. [Google Scholar] [CrossRef]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Arora, P.; Varshney, S. Analysis of k-means and k-medoids algorithm for big data. Procedia Comput. Sci. 2016, 78, 507–512. [Google Scholar] [CrossRef] [Green Version]
- Zimichev, E.A.; Kazanskii, N.L.; Serafimovich, P.G. Spectral-spatial classification with k-means++ particional clustering. Comput. Opt. 2014, 38, 281–286. [Google Scholar] [CrossRef]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Thomson, A.G.; Fuller, R.M.; Eastwood, J.A. Supervised versus unsupervised methods for classification of coasts and river corridors from airborne remote sensing. Int. J. Remote Sens. 1998, 19, 3423–3431. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, Y.; Du, Z.; Zhang, F.; Liu, R.; Ye, X. Where urban youth work and live: A data-driven approach to identify urban functional areas at a fine scale. ISPRS Int. J. Geo Inf. 2020, 9, 42. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 56, 937–949. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Yin, X.; Goudriaan, J.A.N.; Lantinga, E.A.; Vos, J.A.N.; Spiertz, H.J. A flexible sigmoid function of determinate growth. Ann. Bot. 2003, 91, 361–371. [Google Scholar] [CrossRef] [PubMed]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z. Multi-class generative adversarial networks with the L2 loss function. arXiv 2016, arXiv:1611.04076, 1057–7149. [Google Scholar]
- Lu, J.; Ma, C.; Li, L.; Xing, X.; Zhang, Y.; Wang, Z.; Xu, J. A vehicle detection method for aerial image based on YOLO. J. Comput. Commun. 2018, 6, 98–107. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship detection based on YOLOv2 for SAR imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, X.; Gao, Y.; Li, Y. Rapid target detection in high resolution remote sensing images using Yolo model. ISPRS International Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 1915–1920. [Google Scholar] [CrossRef] [Green Version]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man. Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Kadilar, C.; Cingi, H. Ratio estimators in stratified random sampling. Biometrical J. J. Math. Methods Biosci. 2003, 45, 218–225. [Google Scholar] [CrossRef]
- Stehman, S. Estimating the kappa coefficient and its variance under stratified random sampling. Photogramm. Eng. Remote Sens. 1996, 62, 401–407. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Thompson, W.D.; Walter, S.D. A reappraisal of the kappa coefficient. J. Clin. Epidemiol. 1988, 41, 949–958. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block Function Type | Amount | Maximum Area (m2) | Minimum Area (m2) |
|---|---|---|---|
| Residential area | 232 | 1,129,280 | 16,049 |
| Business area | 30 | 395,814 | 12,947 |
| Education area | 18 | 929,251 | 36,745 |
| Industrial area | 109 | 1,730,130 | 21,572 |
| Administrative area | 14 | 285,251 | 16,990 |
| Public service area | 6 | 359,814 | 32,541 |
| Mixed area | 5 | 320,808 | 180,431 |
| Scenic spot | 7 | 1,088,470 | 47,223 |
| Bare/farmland | 61 | 544,611 | 17,984 |
| Rude Grained Division | Fine Grained Division |
|---|---|
| Public service area | Hospital |
| Station | |
| Gymnasium | |
| Residential area | Residential quarters |
| Countryside | |
| Education area | Primary school |
| Middle school | |
| College | |
| University |
| Label | Res. Rate | Bus. Rate | Edu. Rate | Ind. Rate | Adm. Rate | Pub. Rate | Mix. Rate | Sce. Rate | Bar. Rate | Merge |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 75% | 25% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | Res. |
| 2 | 33% | 11% | 0% | 11% | 22% | 22% | 0% | 0% | 0% | Res. |
| 3 | 80% | 0% | 0% | 20% | 0% | 0% | 0% | 0% | 0% | Res. |
| 4 | 100% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | Res. |
| 5 | 69% | 15% | 0% | 8% | 8% | 0% | 0% | 0% | 0% | Res. |
| 6 | 25% | 0% | 50% | 25% | 0% | 0% | 0% | 0% | 0% | Edu. |
| 7 | 67% | 0% | 0% | 11% | 11% | 0% | 0% | 0% | 11% | Res. |
| … | … | … | … | … | … | … | … | … | … | … |
| 39 | 17% | 17% | 50% | 17% | 0% | 0% | 0% | 0% | 0% | Edu. |
| 40 | 50% | 0% | 0% | 50% | 0% | 0% | 0% | 0% | 0% | Res. |
| 41 | 0% | 0% | 0% | 0% | 0% | 100% | 0% | 0% | 0% | Pub. |
| 42 | 60% | 0% | 20% | 20% | 0% | 0% | 0% | 0% | 0% | Res. |
| 43 | 75% | 25% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | Res. |
| 44 | 100% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | Res. |
| 45 | 75% | 0% | 0% | 0% | 0% | 0% | 0% | 25% | 0% | Res. |
| Image ID | True Category | STET | Confidence Score | Playground Area Rate | |||
|---|---|---|---|---|---|---|---|
| Playground | Factory | House | Bare/farmland | ||||
| 1 | Sce. | 0.010 | 0.000 | 0.870 | 0.814 | 0.897 | 0.000 |
| 2 | Res. | 0.013 | 0.000 | 0.800 | 0.153 | 0.055 | 0.000 |
| 3 | Ind. | 0.014 | 0.000 | 0.963 | 0.632 | 0.587 | 0.000 |
| 4 | Bar. | 0.003 | 0.000 | 0.359 | 0.379 | 0.823 | 0.000 |
| 5 | Ind. | 0.001 | 0.000 | 0.915 | 0.521 | 0.646 | 0.000 |
| 6 | Edu. | 0.009 | 0.981 | 0.261 | 0.977 | 0.316 | 0.172 |
| 7 | Ind. | 0.002 | 0.000 | 0.969 | 0.194 | 0.264 | 0.000 |
| 8 | Edu. | 0.105 | 0.991 | 0.800 | 0.828 | 0.697 | 0.040 |
| 9 | Res. | 0.003 | 0.000 | 0.158 | 0.927 | 0.141 | 0.000 |
| 10 | Res. | 0.039 | 0.000 | 0.541 | 0.811 | 0.589 | 0.000 |
| 11 | Ind. | 0.027 | 0.000 | 0.998 | 0.126 | 0.185 | 0.000 |
| 12 | Ind. | 0.002 | 0.000 | 0.810 | 0.535 | 0.509 | 0.000 |
| 13 | Res. | 0.009 | 0.000 | 0.412 | 0.845 | 0.244 | 0.000 |
| 14 | Ind. | 0.008 | 0.000 | 0.997 | 0.053 | 0.058 | 0.000 |
| 15 | Edu. | 0.012 | 0.926 | 0.584 | 0.847 | 0.872 | 0.020 |
| 16 | Edu. | 0.039 | 0.987 | 0.180 | 0.972 | 0.050 | 0.045 |
| 17 | Bar. | 0.007 | 0.000 | 0.396 | 0.649 | 0.876 | 0.000 |
| 18 | Res. | 0.004 | 0.000 | 0.522 | 0.827 | 0.590 | 0.000 |
| 19 | Bar. | 0.004 | 0.319 | 0.590 | 0.644 | 0.973 | 0.107 |
| 20 | Bar. | 0.007 | 0.000 | 0.397 | 0.696 | 0.872 | 0.000 |
| 21 | Res. | 0.003 | 0.000 | 0.460 | 0.835 | 0.723 | 0.000 |
| 22 | Res. | 0.001 | 0.000 | 0.571 | 0.890 | 0.687 | 0.000 |
| 23 | Res. | 0.003 | 0.000 | 0.266 | 0.958 | 0.517 | 0.000 |
| 24 | Ind. | 0.048 | 0.000 | 0.935 | 0.466 | 0.578 | 0.000 |
| 25 | Res. | 0.003 | 0.000 | 0.491 | 0.908 | 0.536 | 0.000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, Z.; Liu, X.; Tao, F.; Zhou, T. Identification of Urban Functional Areas by Coupling Satellite Images and Taxi GPS Trajectories. Remote Sens. 2020, 12, 2449. https://doi.org/10.3390/rs12152449
Qian Z, Liu X, Tao F, Zhou T. Identification of Urban Functional Areas by Coupling Satellite Images and Taxi GPS Trajectories. Remote Sensing. 2020; 12(15):2449. https://doi.org/10.3390/rs12152449
Chicago/Turabian StyleQian, Zhen, Xintao Liu, Fei Tao, and Tong Zhou. 2020. "Identification of Urban Functional Areas by Coupling Satellite Images and Taxi GPS Trajectories" Remote Sensing 12, no. 15: 2449. https://doi.org/10.3390/rs12152449
APA StyleQian, Z., Liu, X., Tao, F., & Zhou, T. (2020). Identification of Urban Functional Areas by Coupling Satellite Images and Taxi GPS Trajectories. Remote Sensing, 12(15), 2449. https://doi.org/10.3390/rs12152449