GSCA-UNet: Towards Automatic Shadow Detection in Urban Aerial Imagery with Global-Spatial-Context Attention Module




Abstract
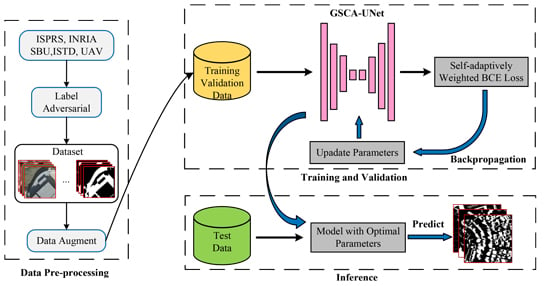
1. Introduction
- (1)
- we developed a spatial-attention module to capture the long-ranged contextual information for each pixel, which contributed to identifying the challenging shadows and non-shadows;
- (2)
- on the basis of the UNet network architecture reported in [42], we realized end-to-end automatic and accurate shadow detection in urban aerial images; and
- (3)
- we developed a self-adaptively weighted binary cross-entropy (SAWBCE) loss function that enhanced the training procedure.
2. Methodology
2.1. Data Preprocessing
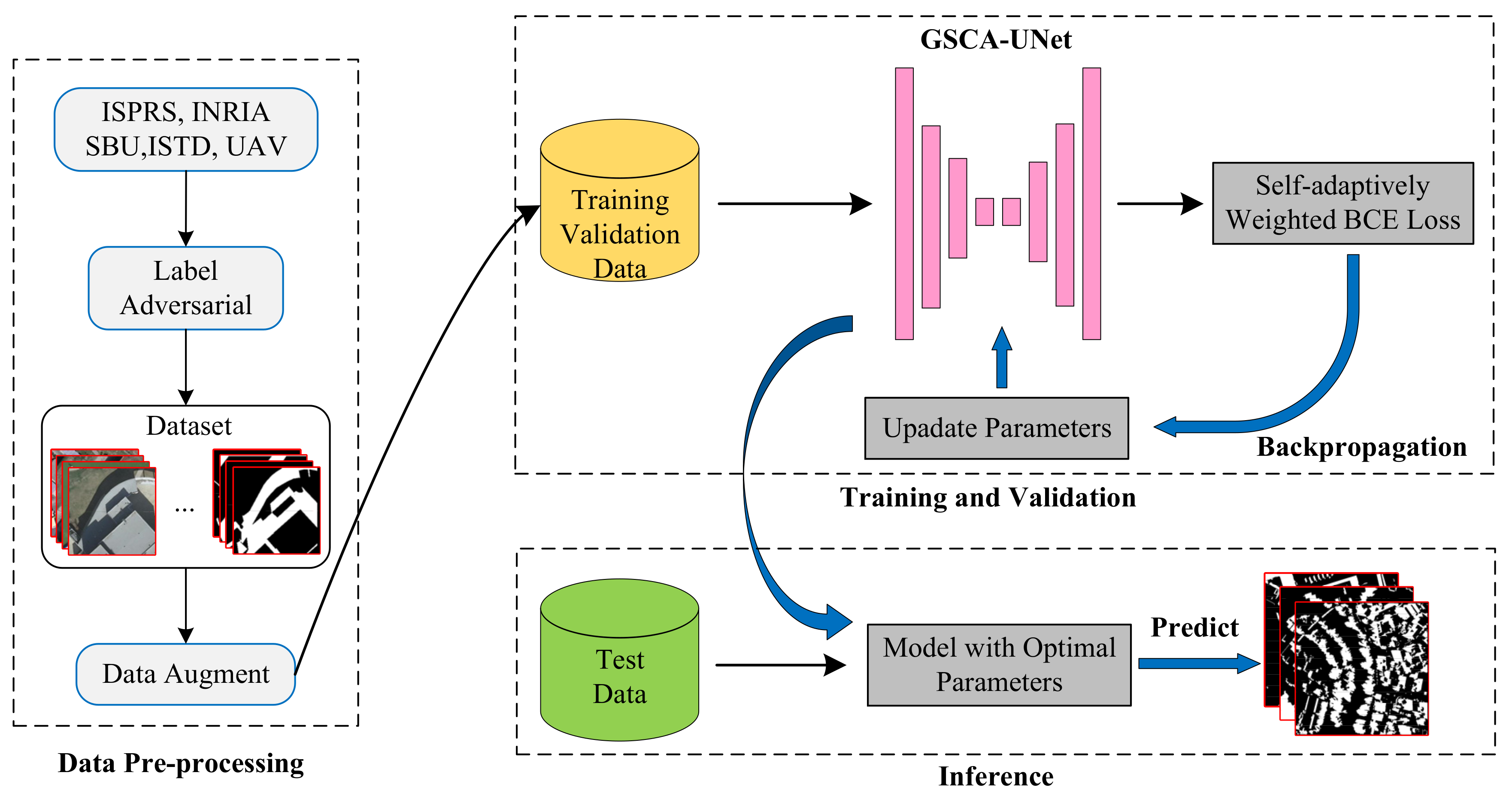
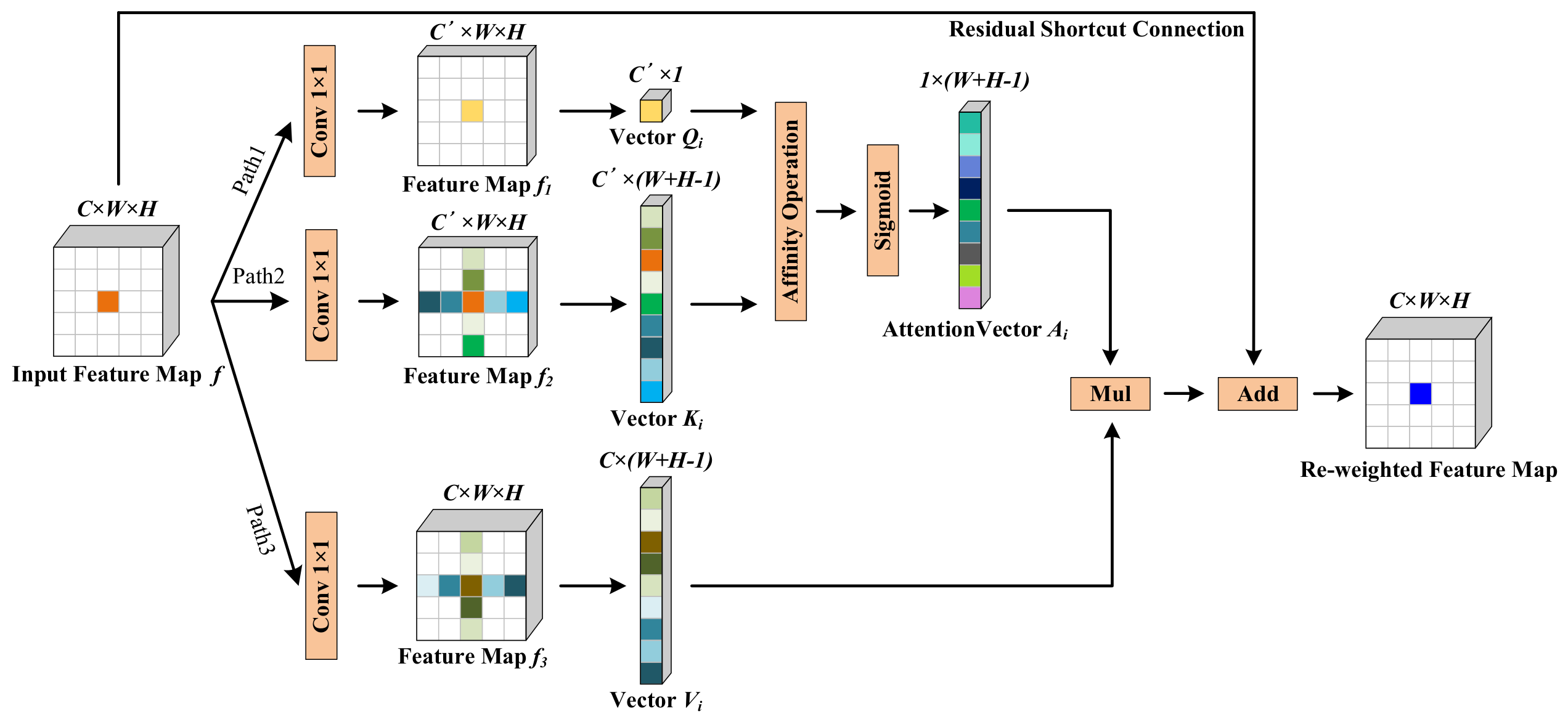
2.2. Global-Spatial-Context Attention Module
2.3. GSCA-UNet
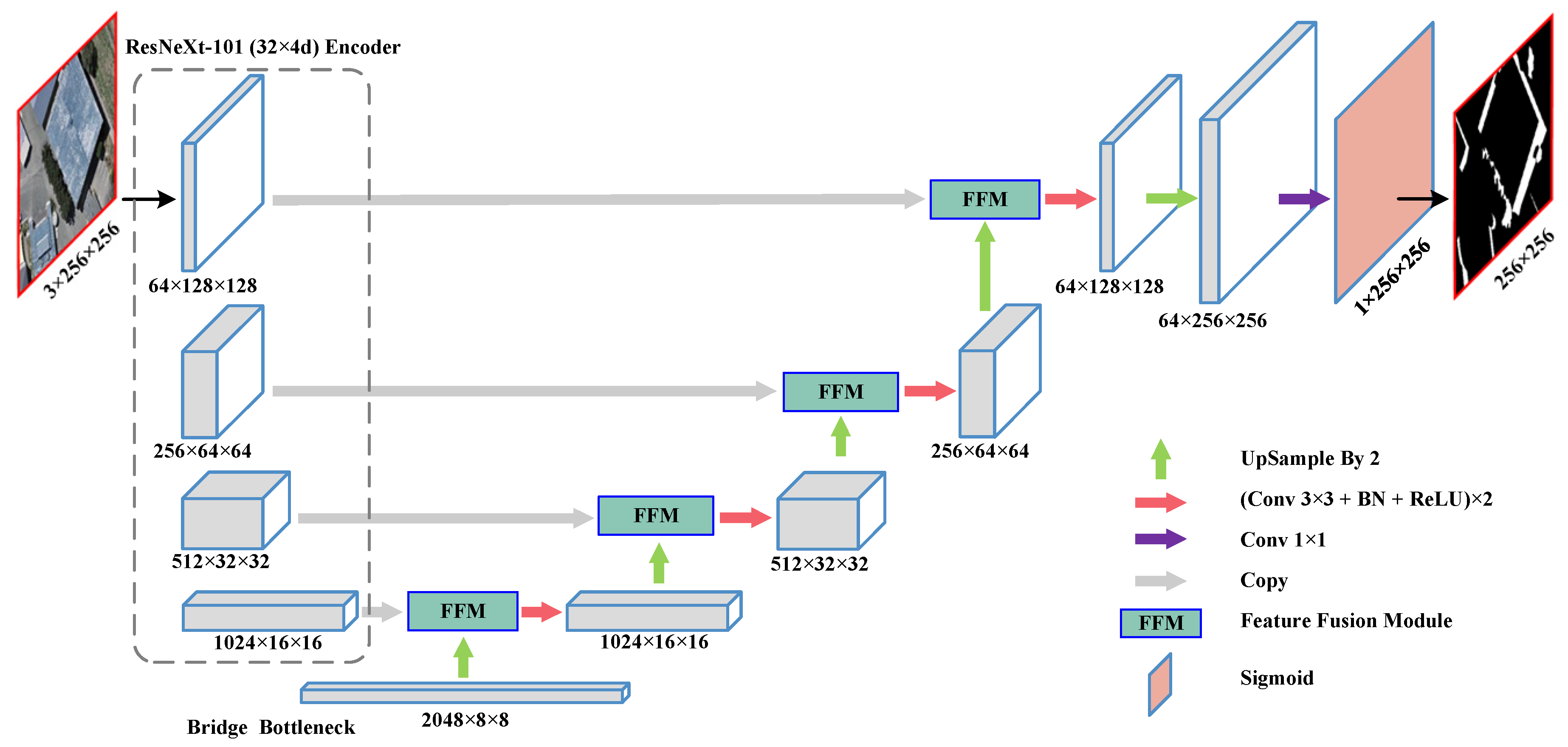
2.3.1. Network Architecture
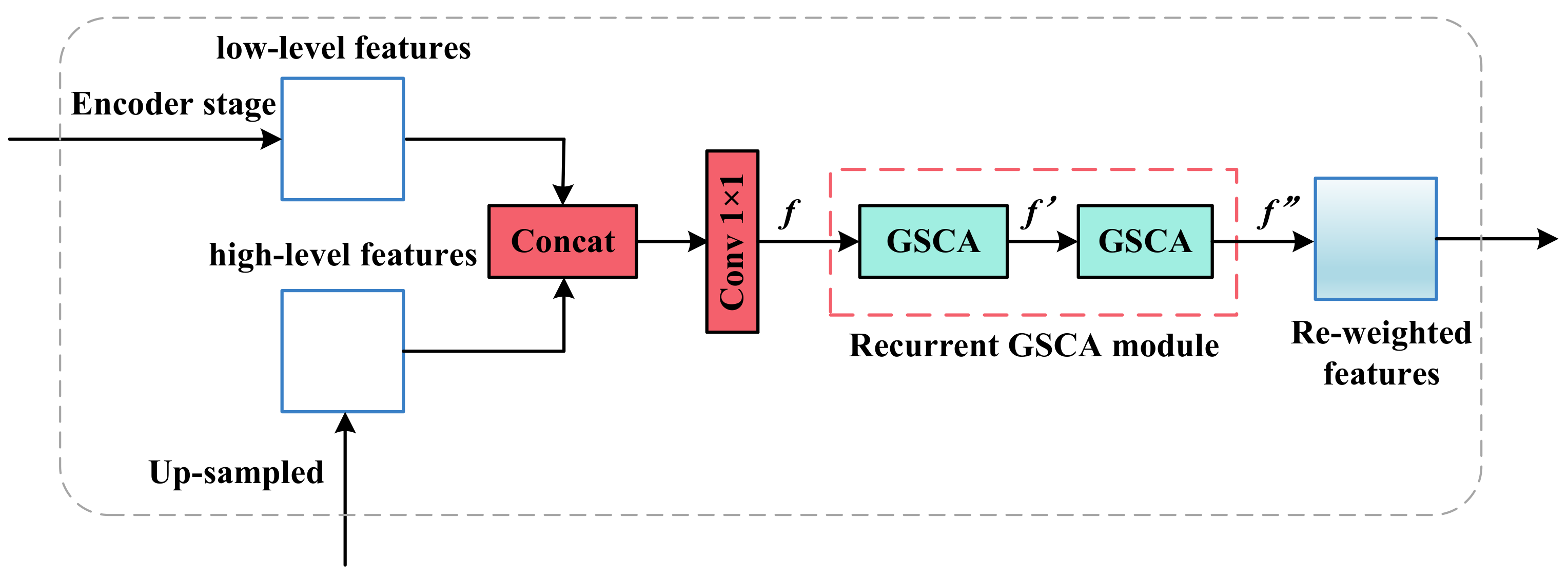
2.3.2. Feature Fusion Module
2.3.3. Modified Binary Cross-Entropy Loss
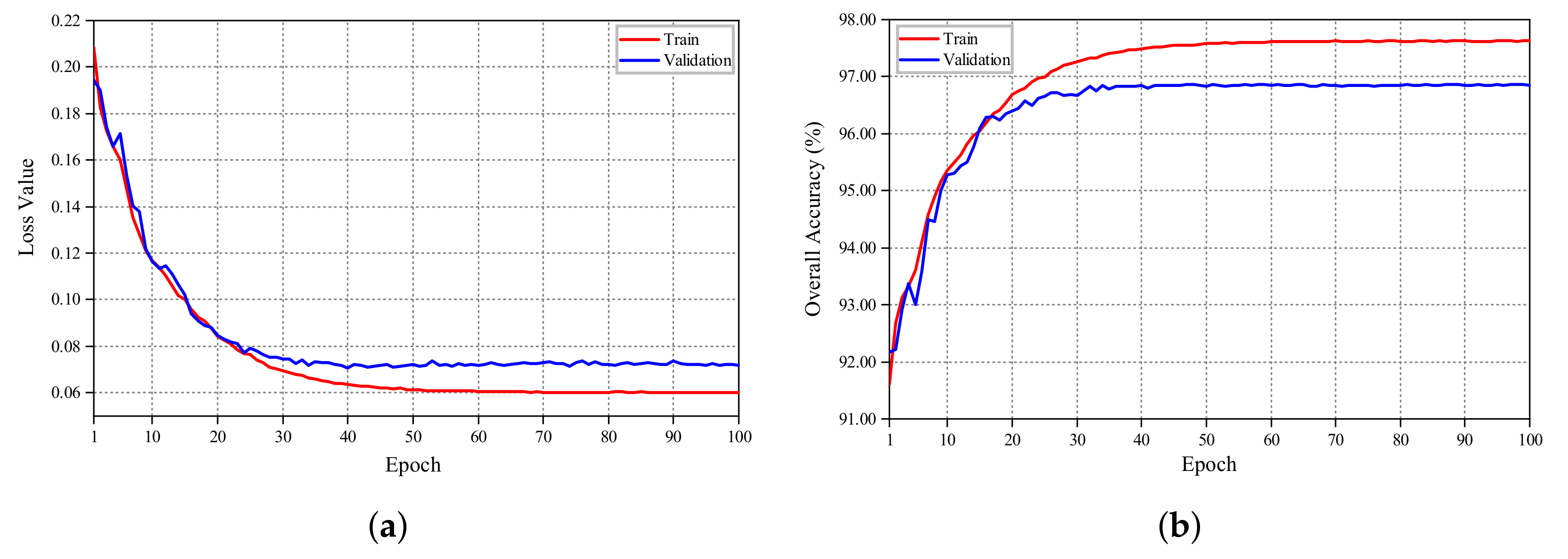
2.4. Training Details
3. Experiments and Results
3.1. Test Images
3.2. Implementation Details
3.3. Comparison with State-Of-The-Art Methods
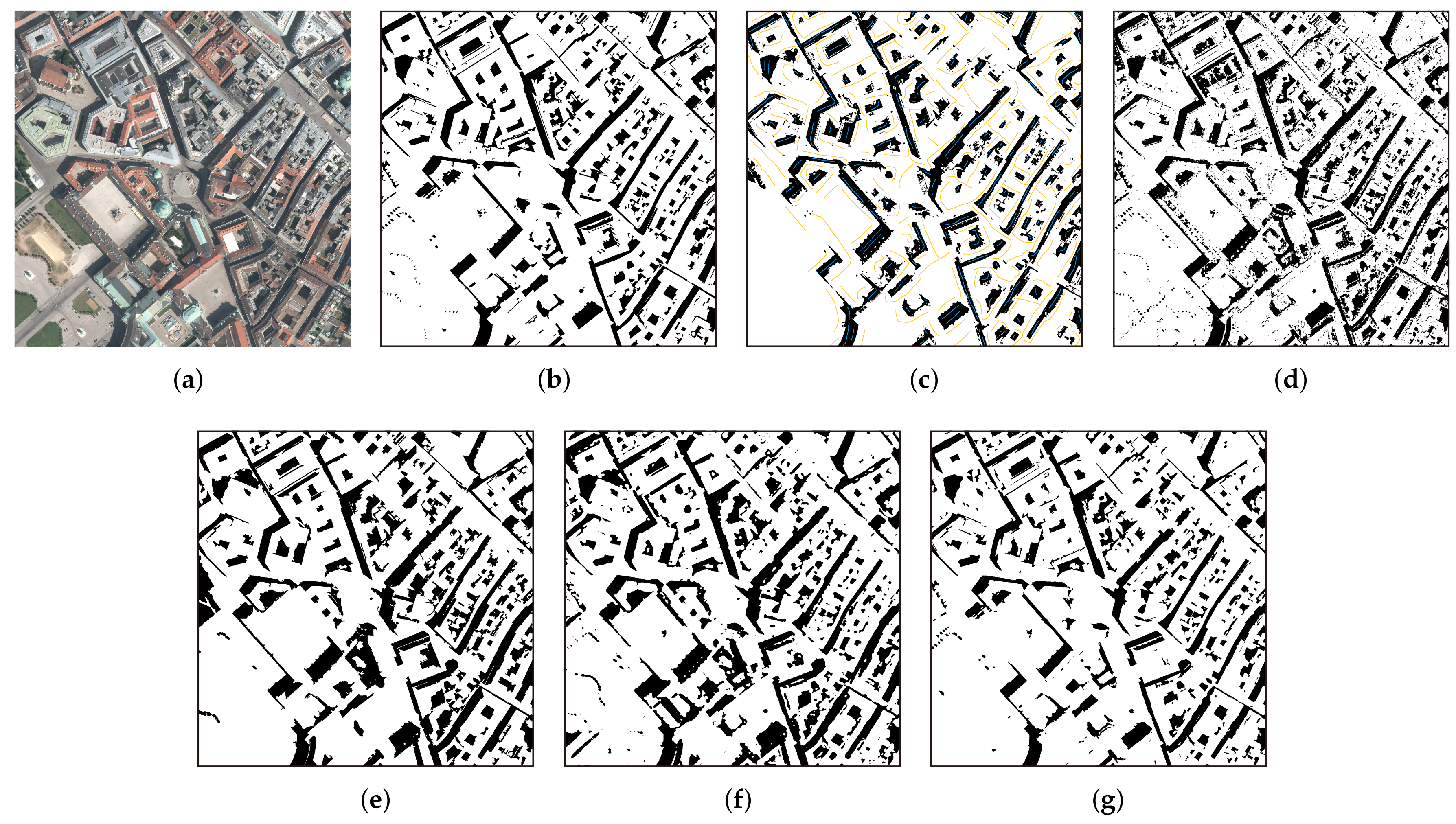
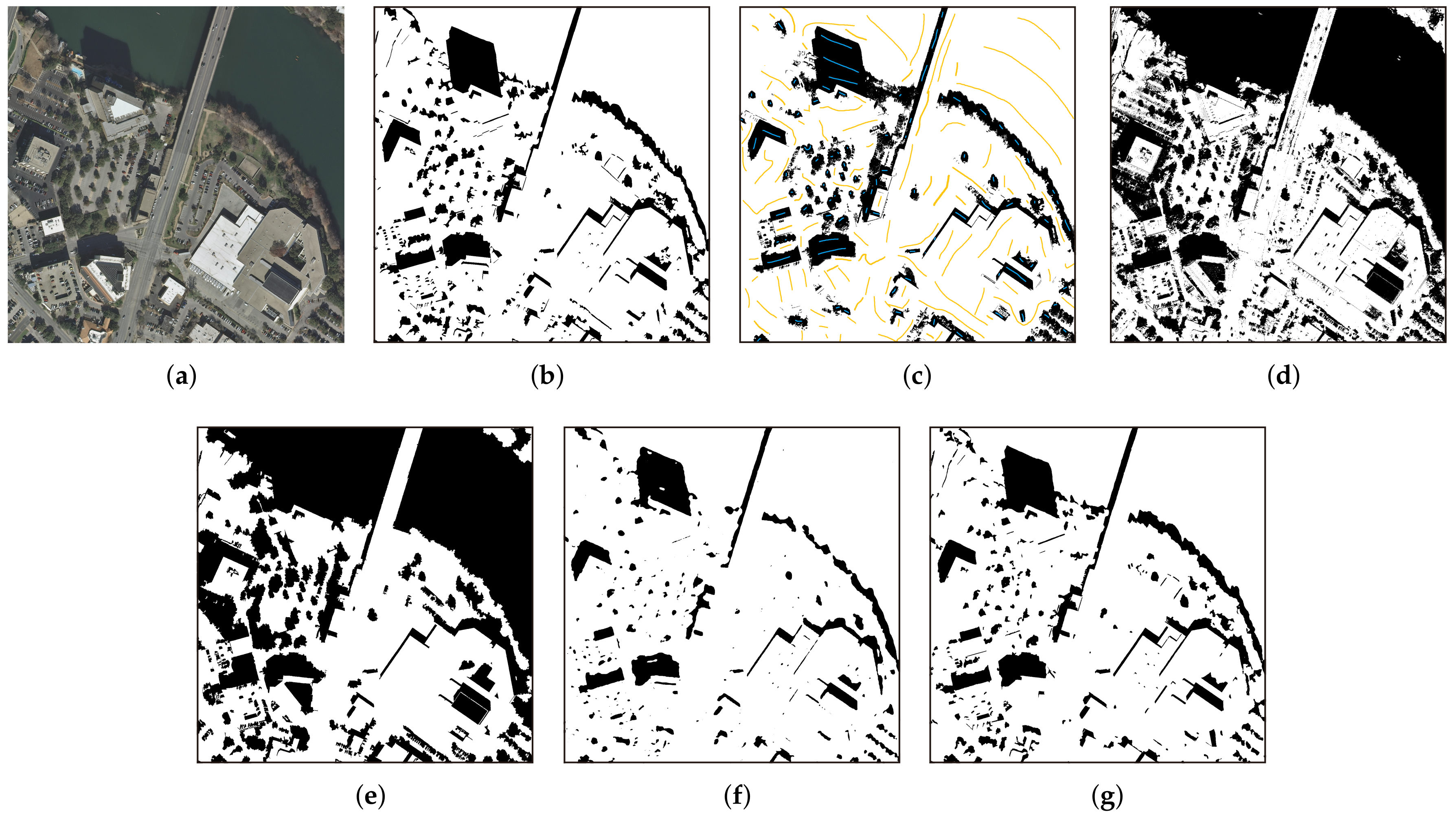
3.3.1. Visualization Results
3.3.2. Quantitative Comparisons
4. Discussion
4.1. Network-Design Evaluation
4.2. Advantages of the Proposed Method
4.3. Limitations and Further Improvements
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | Unmanned aerial vehicle |
| GPU | Graphics processing unit |
| HSV | Hue-saturation-value |
| CUDA | Compute unified device architecture |
References
- Azevedo, S.; Silva, E.; Pedrosa, M. Shadow detection improvement using spectral indices and morphological operators in urban areas in high resolution images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2015, W3, 587–592. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q.; Zhang, Y.; Du, X.; Wang, H. Two-Step Urban Water Index (TSUWI): A New Technique for High-Resolution Mapping of Urban Surface Water. Remote Sens. 2018, 10, 1704. [Google Scholar] [CrossRef]
- Xie, C.; Huang, X.; Zeng, W.; Fang, X. A novel water index for urban high-resolution eight-band WorldView-2 imagery. Int. J. Digit. Earth 2016, 9, 925–941. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 5, 161–172. [Google Scholar] [CrossRef]
- Liasis, G.; Stavrou, S. Satellite images analysis for shadow detection and building height estimation. ISPRS J. Photogramm. Remote Sens. 2016, 119, 437–450. [Google Scholar] [CrossRef]
- Adeline, K.; Chen, M.; Briottet, X.; Pang, S.; Paparoditis, N. Shadow detection in very high spatial resolution aerial images: A comparative study. ISPRS J. Photogramm. Remote Sens. 2013, 80, 21–38. [Google Scholar] [CrossRef]
- Cameron, M.; Kumar, L. Diffuse Skylight as a Surrogate for Shadow Detection in High-Resolution Imagery Acquired Under Clear Sky Conditions. Remote Sens. 2018, 10, 1185. [Google Scholar] [CrossRef]
- Xue, L.; Yang, S.; Li, Y.; Ma, J. An automatic shadow detection method for high-resolution remote sensing imagery based on polynomial fitting. Int. J. Remote Sens. 2019, 40, 2986–3007. [Google Scholar] [CrossRef]
- Zhou, K.; Lindenbergh, R.; Gorte, B. Automatic Shadow Detection in Urban Very-High-Resolution Images Using Existing 3D Models for Free Training. Remote Sens. 2019, 11, 72. [Google Scholar] [CrossRef]
- Tsai, V.J. A comparative study on shadow compensation of color aerial images in invariant color models. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1661–1671. [Google Scholar] [CrossRef]
- Su, N.; Zhang, Y.; Tian, S.; Yan, Y.; Miao, X. Shadow detection and removal for occluded object information recovery in urban high-resolution panchromatic satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2568–2582. [Google Scholar] [CrossRef]
- Song, H.; Huang, B.; Zhang, K. Shadow detection and reconstruction in high-resolution satellite images via morphological filtering and example-based learning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 2545–2554. [Google Scholar] [CrossRef]
- Chung, K.L.; Lin, Y.R.; Huang, Y.H. Efficient shadow detection of color aerial images based on successive thresholding scheme. IEEE Trans. Geosci. Remote Sens. 2008, 47, 671–682. [Google Scholar] [CrossRef]
- Silva, G.F.; Carneiro, G.B.; Doth, R.; Amaral, L.A.; de Azevedo, D.F. Near real-time shadow detection and removal in aerial motion imagery application. ISPRS J. Photogramm. Remote Sens. 2018, 140, 104–121. [Google Scholar] [CrossRef]
- Besheer, M.; Abdelhafiz, A. Modified invariant colour model for shadow detection. Int. J. Remote Sens. 2015, 36, 6214–6223. [Google Scholar] [CrossRef]
- Huang, W.; Bu, M. Detecting shadows in high-resolution remote-sensing images of urban areas using spectral and spatial features. Int. J. Remote Sens. 2015, 36, 6224–6244. [Google Scholar] [CrossRef]
- Mostafa, Y.; Abdelhafiz, A. Accurate shadow detection from high-resolution satellite images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 494–498. [Google Scholar] [CrossRef]
- Ma, H.; Qin, Q.; Shen, X. Shadow segmentation and compensation in high resolution satellite images. In Proceedings of the 2008 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Boston, MA, USA, 7–11 July 2008; Volume 2, pp. II-1036–II-1039. [Google Scholar]
- Kang, X.; Huang, Y.; Li, S.; Lin, H.; Benediktsson, J.A. Extended random walker for shadow detection in very high resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 867–876. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, K.; Li, W. Object-oriented shadow detection and removal from urban high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6972–6982. [Google Scholar] [CrossRef]
- Mo, N.; Zhu, R.; Yan, L.; Zhao, Z. Deshadowing of urban airborne imagery based on object-oriented automatic shadow detection and regional matching compensation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 585–605. [Google Scholar] [CrossRef]
- Wang, Q.; Yan, L.; Yuan, Q.; Ma, Z. An automatic shadow detection method for VHR remote sensing orthoimagery. Remote Sens. 2017, 9, 469. [Google Scholar] [CrossRef]
- Tolt, G.; Shimoni, M.; Ahlberg, J. A shadow detection method for remote sensing images using VHR hyperspectral and LIDAR data. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Vancouver, BC, Canada, 24–29 July 2011; pp. 4423–4426. [Google Scholar]
- Richter, R.; Müller, A. De-shadowing of satellite/airborne imagery. Int. J. Remote Sens. 2005, 26, 3137–3148. [Google Scholar] [CrossRef]
- Yamazaki, F.; Liu, W.; Takasaki, M. Characteristics of shadow and removal of its effects for remote sensing imagery. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 4, pp. IV-426–IV-429. [Google Scholar]
- Li, H.; Zhang, L.; Shen, H. An adaptive nonlocal regularized shadow removal method for aerial remote sensing images. IEEE Trans. Geosci. Remote Sens. 2013, 52, 106–120. [Google Scholar] [CrossRef]
- Levin, A.; Lischinski, D.; Weiss, Y. A closed-form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 228–242. [Google Scholar] [CrossRef]
- Liu, J.; Fang, T.; Li, D. Shadow detection in remotely sensed images based on self-adaptive feature selection. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5092–5103. [Google Scholar]
- Lorenzi, L.; Melgani, F.; Mercier, G. A complete processing chain for shadow detection and reconstruction in VHR images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3440–3452. [Google Scholar] [CrossRef]
- Vicente, T.F.Y.; Hoai, M.; Samaras, D. Leave-one-out kernel optimization for shadow detection and removal. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 682–695. [Google Scholar] [CrossRef]
- Guo, R.; Dai, Q.; Hoiem, D. Paired regions for shadow detection and removal. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2956–2967. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Spain, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Automatic feature learning for robust shadow detection. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1939–1946. [Google Scholar]
- Hosseinzadeh, S.; Shakeri, M.; Zhang, H. Fast shadow detection from a single image using a patched convolutional neural network. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3124–3129. [Google Scholar]
- Nguyen, V.; Yago Vicente, T.F.; Zhao, M.; Hoai, M.; Samaras, D. Shadow detection with conditional generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4510–4518. [Google Scholar]
- Le, H.; Vicente, T.F.Y.; Nguyen, V.; Hoai, M.; Samaras, D. A+ D-Net: Shadow detection with adversarial shadow attenuation. Lect. Notes Comput. Sci. 2018, 11206, 680–696. [Google Scholar]
- Zhu, L.; Deng, Z.; Hu, X.; Fu, C.W.; Xu, X.; Qin, J.; Heng, P.A. Bidirectional feature pyramid network with recurrent attention residual modules for shadow detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 121–136. [Google Scholar]
- Ding, B.; Long, C.; Zhang, L.; Xiao, C. Argan: Attentive recurrent generative adversarial network for shadow detection and removal. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10213–10222. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Vicente, T.F.Y.; Hou, L.; Yu, C.P.; Hoai, M.; Samaras, D. Large-scale training of shadow detectors with noisily-annotated shadow examples. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 816–832. [Google Scholar]
- Wang, J.; Li, X.; Yang, J. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1788–1797. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Cheng, M.H.; Huang, T.Z.; Zhao, X.L.; Ma, T.H.; Huang, J. A variational model with hybrid Hyper-Laplacian priors for Retinex. Appl. Math. Model. 2019, 66, 305–321. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yuan, Y.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3146–3154. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wagner, F.H.; Dalagnol, R.; Tarabalka, Y.; Segantine, T.Y.; Thomé, R.; Hirye, M. U-Net-Id, an Instance Segmentation Model for Building Extraction from Satellite Images—Case Study in the Joanópolis City, Brazil. Remote Sens. 2020, 12, 1544. [Google Scholar] [CrossRef]
- Jiao, L.; Huo, L.; Hu, C.; Tang, P. Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation. Remote Sens. 2020, 12, 2001. [Google Scholar] [CrossRef]
- Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sens. 2020, 12, 1574. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, Y.; Chen, C.; Ding, M.; Li, J. Real-time dense semantic labeling with dual-Path framework for high-resolution remote sensing image. Remote Sens. 2019, 11, 3020. [Google Scholar] [CrossRef]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]
- Da, K. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Baatz, M.; Schäpe, A. Multiresolution Segmentation: An Optimization Approach for High Quality Multi-Scale Image Segmentation. 2010. Available online: http://www.agit.at/papers/2000/baatz_FP_12.pdf (accessed on 20 December 2019).
- Hu, Z.; Li, Q.; Zou, Q.; Zhang, Q.; Wu, G. A bilevel scale-sets model for hierarchical representation of large remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7366–7377. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, Q.; Zou, Q.; Li, Q.; Wu, G. Stepwise evolution analysis of the region-merging segmentation for scale parameterization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2461–2472. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Captured Place | Resolution (cm) | Size | Scene |
|---|---|---|---|---|
| Toronto | Toronto | 15 | Dense city | |
| Chicago | Chicago | 30 cm | dense city | |
| Vienna | Vienna | 30 | Dense city | |
| Austin | Austin | 30 | Dense city, water |
| Method | F1 (%) | OA (%) | BER (%) | IoU (%) |
|---|---|---|---|---|
| IMM | ||||
| ERW | 81.69 | 89.11 | 12.49 | 75.28 |
| OO | 87.13 | 93.54 | 8.97 | 79.08 |
| BDRAR | 85.09 | 92.66 | 9.15 | 78.07 |
| Proposed method | 92.11 | 96.08 | 5.92 | 84.23 |
| Image | Method | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|
| IMM | |||||
| ERW | 85.21 | 91.14 | 9.68 | 74.24 | |
| Toronto | OO | 94.01 | 96.58 | 4.50 | 88.70 |
| BDRAR | 90.63 | 94.45 | 6.00 | 82.86 | |
| Proposed method | 96.61 | 98.03 | 2.18 | 93.44 | |
| IMM | 88.37 | 91.84 | 9.17 | 79.17 | |
| ERW | 90.00 | 92.85 | 7.66 | 81.82 | |
| Chicago | OO | ||||
| BDRAR | 88.10 | 91.63 | 9.37 | 78.73 | |
| Proposed method | 93.96 | 95.73 | 4.79 | 88.61 | |
| IMM | 12.10 | ||||
| ERW | 78.81 | 89.82 | 10.98 | 65.03 | |
| Vienna | OO | 79.15 | 89.86 | 65.49 | |
| BDRAR | 78.00 | 89.15 | 10.90 | 63.93 | |
| Proposed method | 89.06 | 95.26 | 6.89 | 80.28 | |
| IMM | 92.86 | ||||
| ERW | 45.10 | 65.38 | 23.25 | 29.11 | |
| Austin | OO | 44.93 | 65.01 | 23.32 | 28.97 |
| BDRAR | 74.04 | 19.14 | 58.78 | ||
| Proposed method | 87.12 | 96.14 | 8.18 | 77.18 |
| Network | (%) | (%) | (%) | (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Unet | 87.77 | - | 94.66 | - | 8.02 | - | 78.69 | - |
| ResNeXt-Unet | 88.28 | 0.58 | 94.87 | 0.22 | 7.50 | 6.48 | 79.51 | 1.03 |
| Proposed method | 91.69 | 4.47 | 96.29 | 1.72 | 5.51 | 31.3 | 84.88 | 7.77 |
| Loss | (%) | (%) | (%) | (%) |
|---|---|---|---|---|
| BCE | 91.57 | 96.25 | 5.50 | 84.84 |
| SAWBCE | 91.69 | 96.29 | 5.51 | 84.88 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.; Xu, W.; Hu, Z.; Jia, H.; Luo, X.; Shao, D. GSCA-UNet: Towards Automatic Shadow Detection in Urban Aerial Imagery with Global-Spatial-Context Attention Module. Remote Sens. 2020, 12, 2864. https://doi.org/10.3390/rs12172864
Jin Y, Xu W, Hu Z, Jia H, Luo X, Shao D. GSCA-UNet: Towards Automatic Shadow Detection in Urban Aerial Imagery with Global-Spatial-Context Attention Module. Remote Sensing. 2020; 12(17):2864. https://doi.org/10.3390/rs12172864
Chicago/Turabian StyleJin, Yuwei, Wenbo Xu, Zhongwen Hu, Haitao Jia, Xin Luo, and Donghang Shao. 2020. "GSCA-UNet: Towards Automatic Shadow Detection in Urban Aerial Imagery with Global-Spatial-Context Attention Module" Remote Sensing 12, no. 17: 2864. https://doi.org/10.3390/rs12172864
APA StyleJin, Y., Xu, W., Hu, Z., Jia, H., Luo, X., & Shao, D. (2020). GSCA-UNet: Towards Automatic Shadow Detection in Urban Aerial Imagery with Global-Spatial-Context Attention Module. Remote Sensing, 12(17), 2864. https://doi.org/10.3390/rs12172864