A Novel Coarse-to-Fine Method of Ship Detection in Optical Remote Sensing Images Based on a Deep Residual Dense Network


Abstract
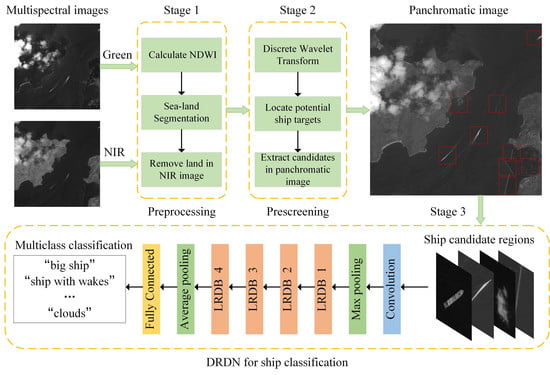
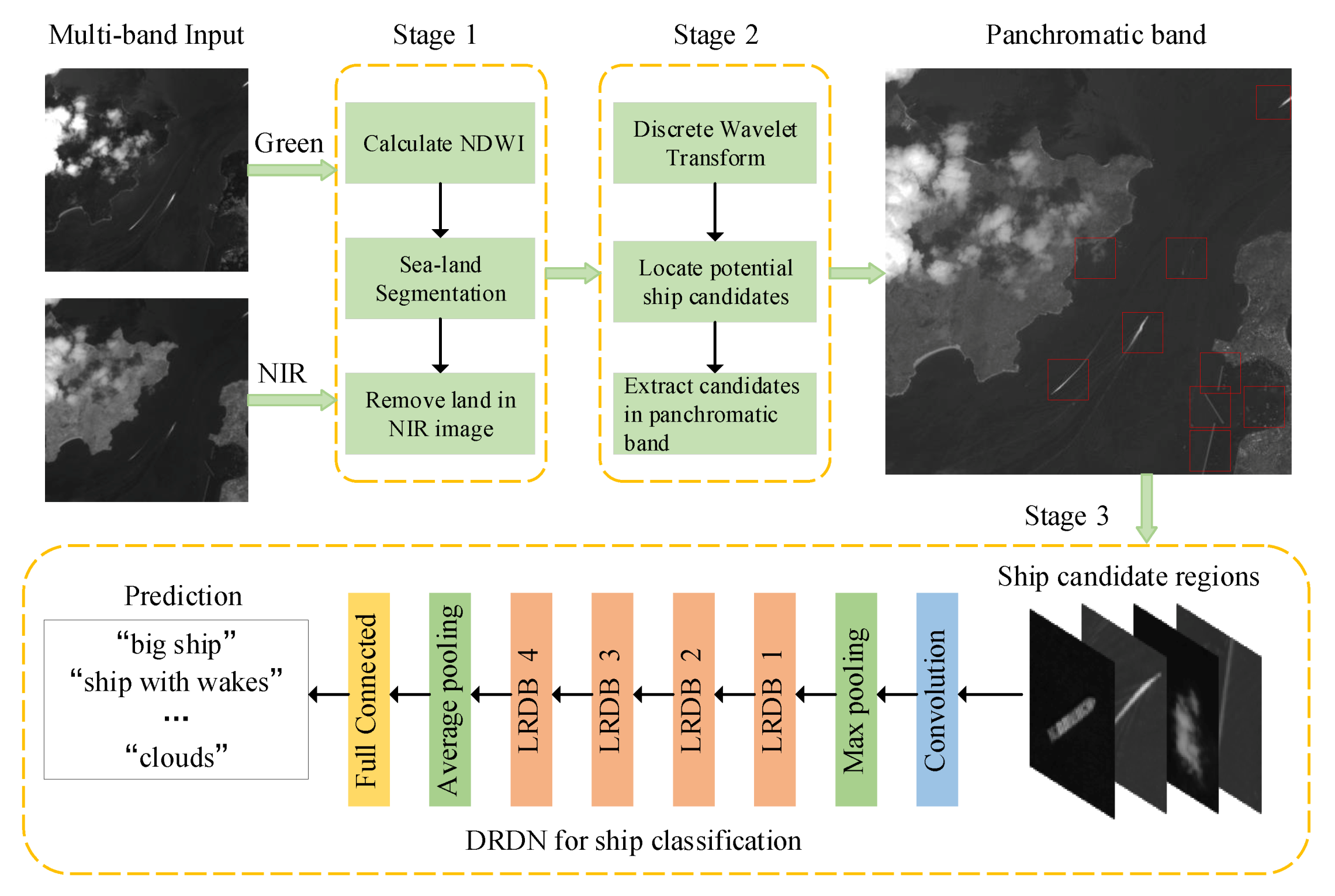
:
1. Introduction
2. Proposed Method
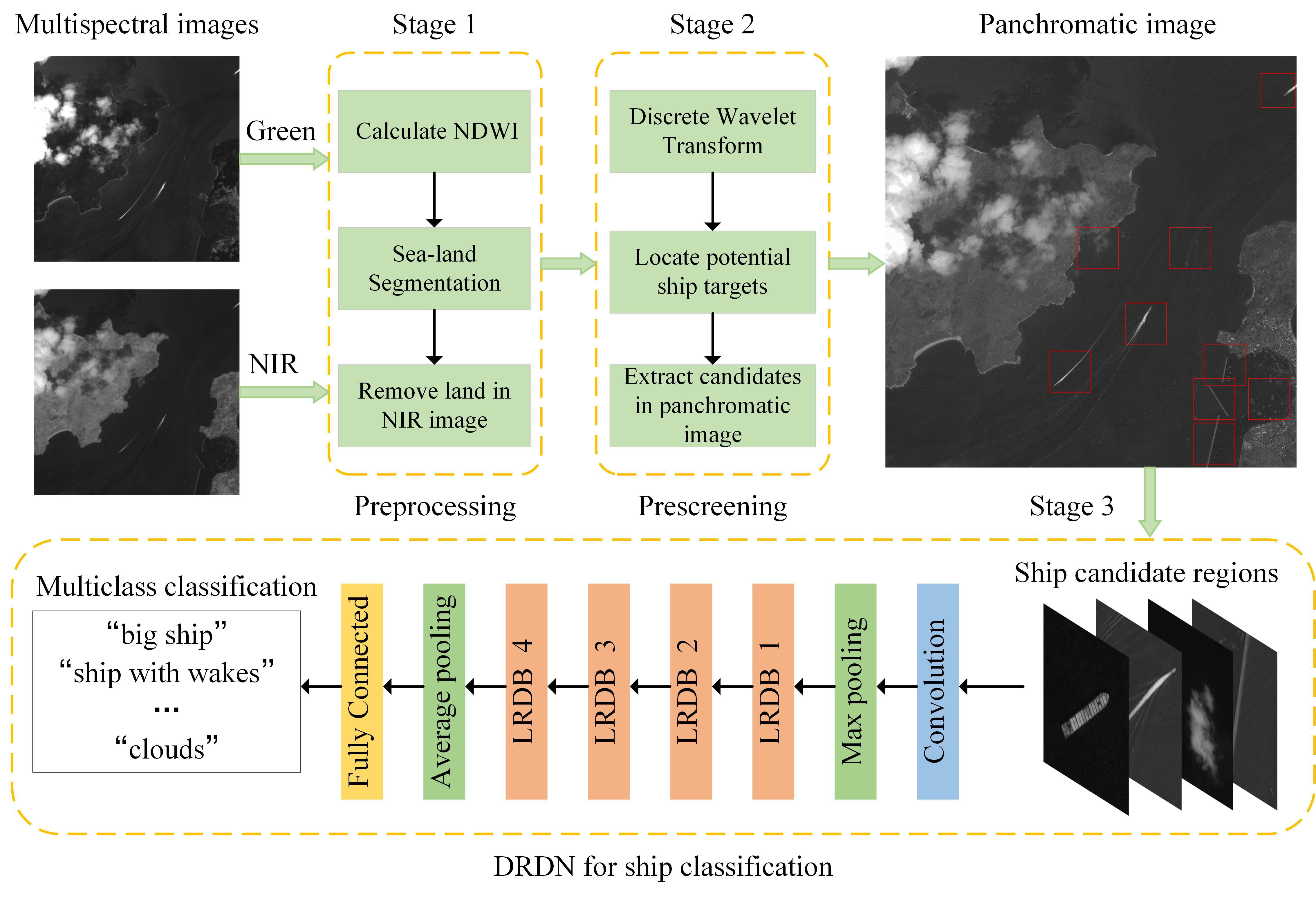
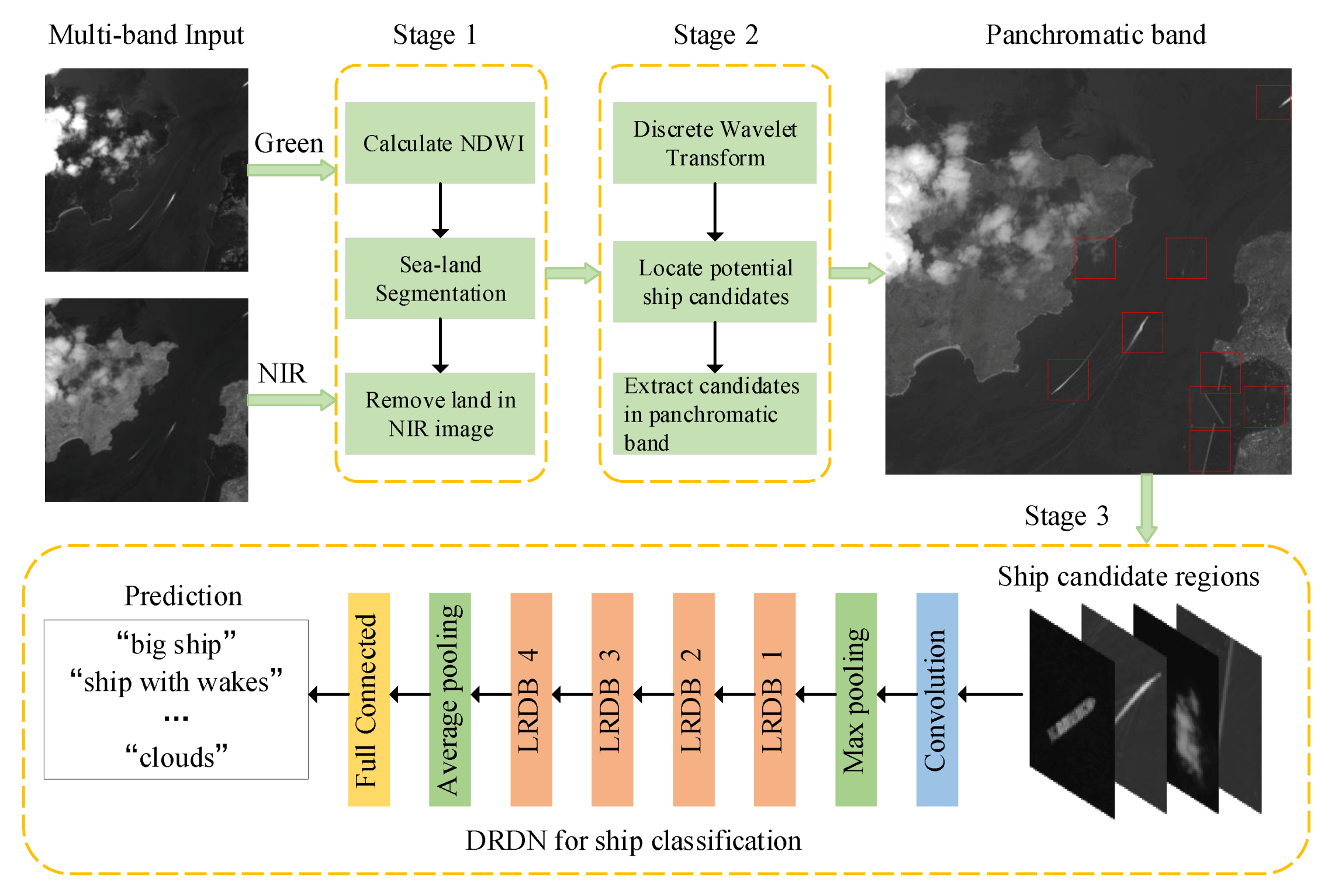
2.1. The Overall Framework
2.2. Sea-Land Segmentation with Multispectral Images
2.3. Ship Candidate Region Extraction
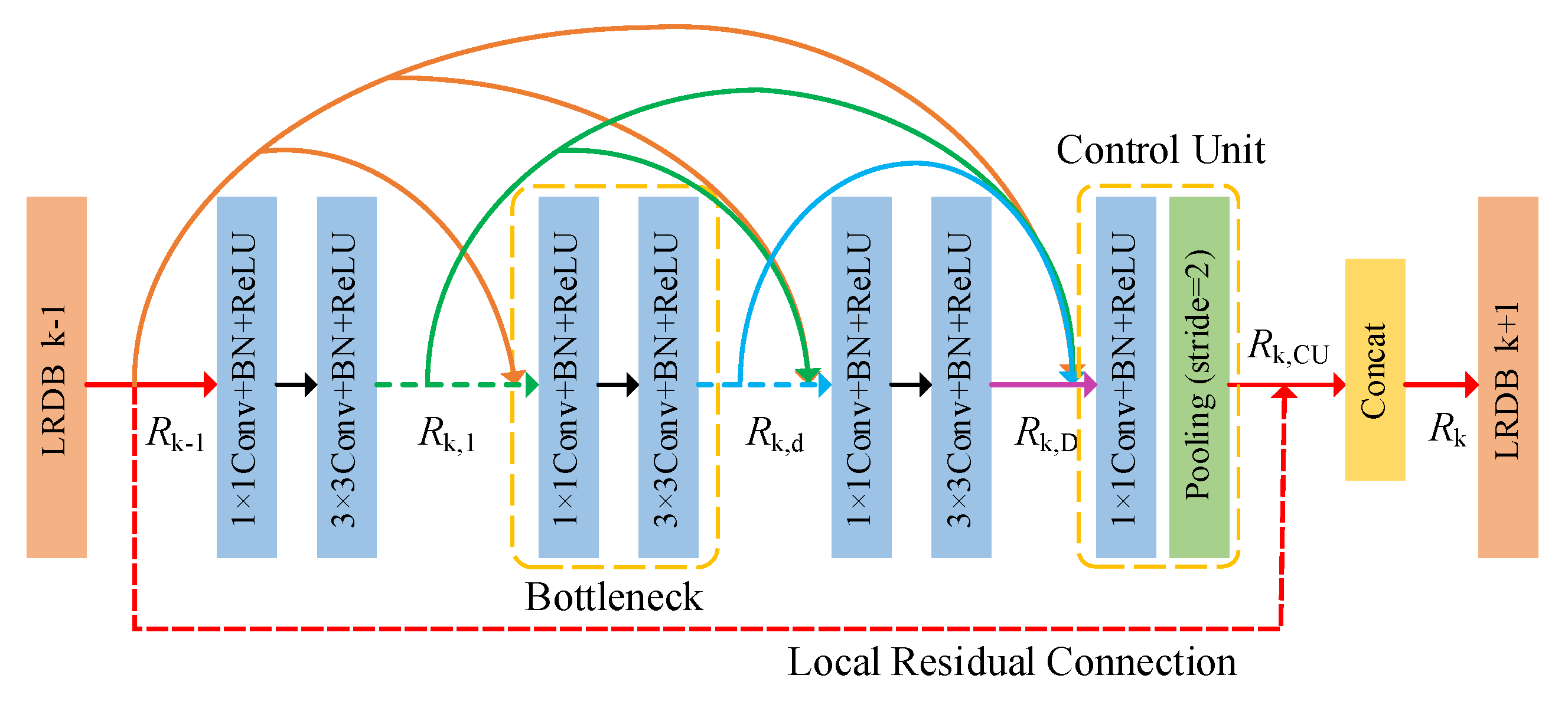
2.4. Ship Classification with DRDN
3. Dataset and Experiment Setup
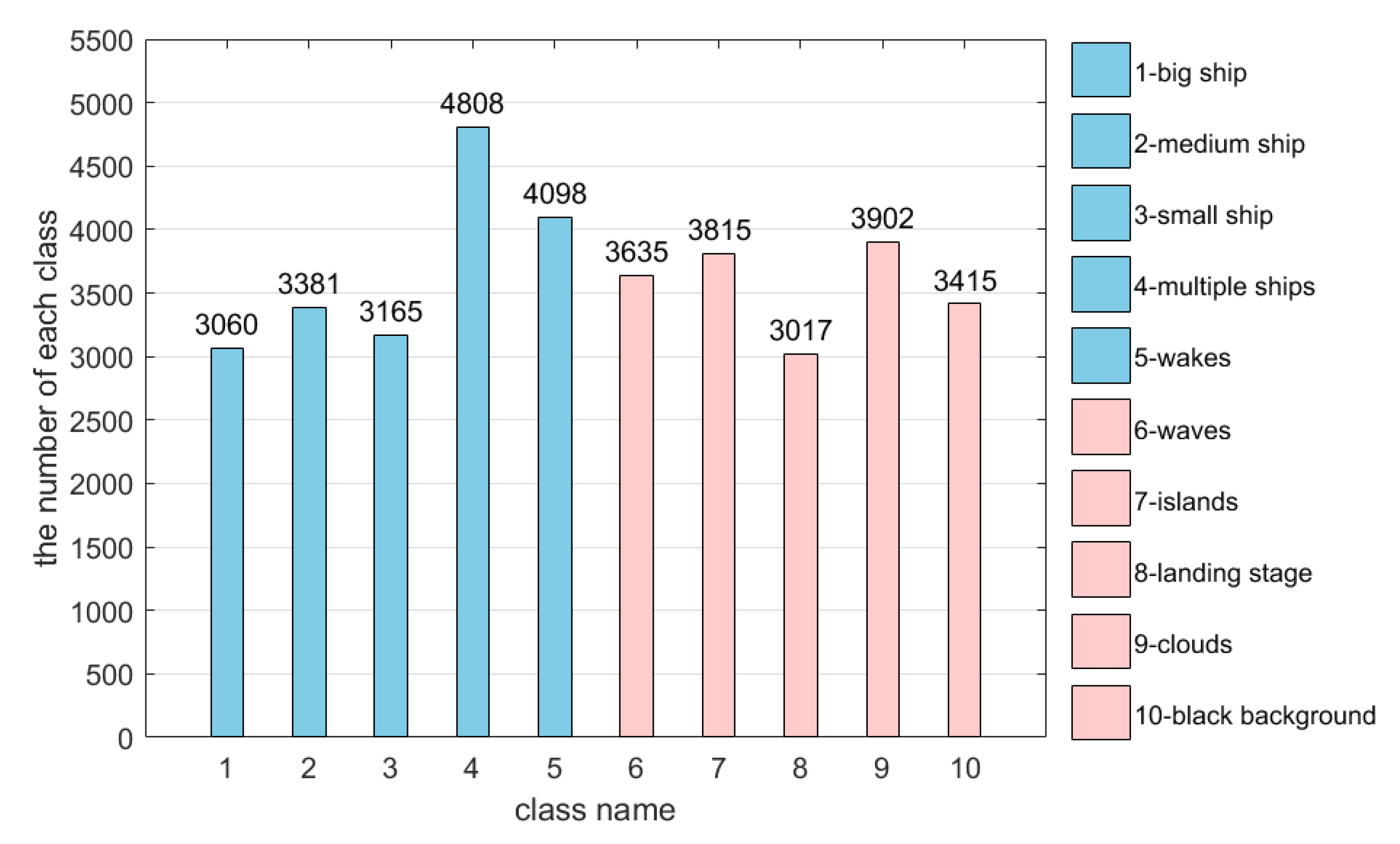
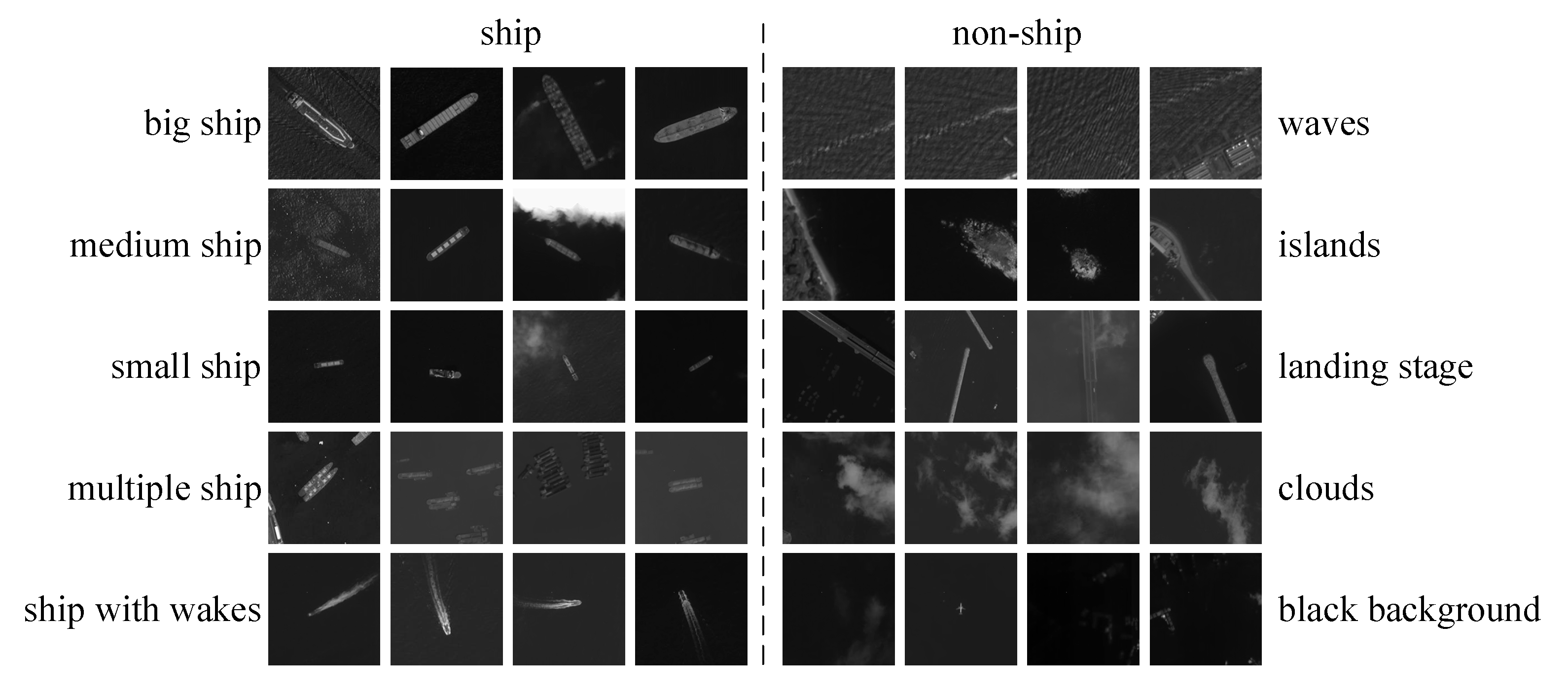
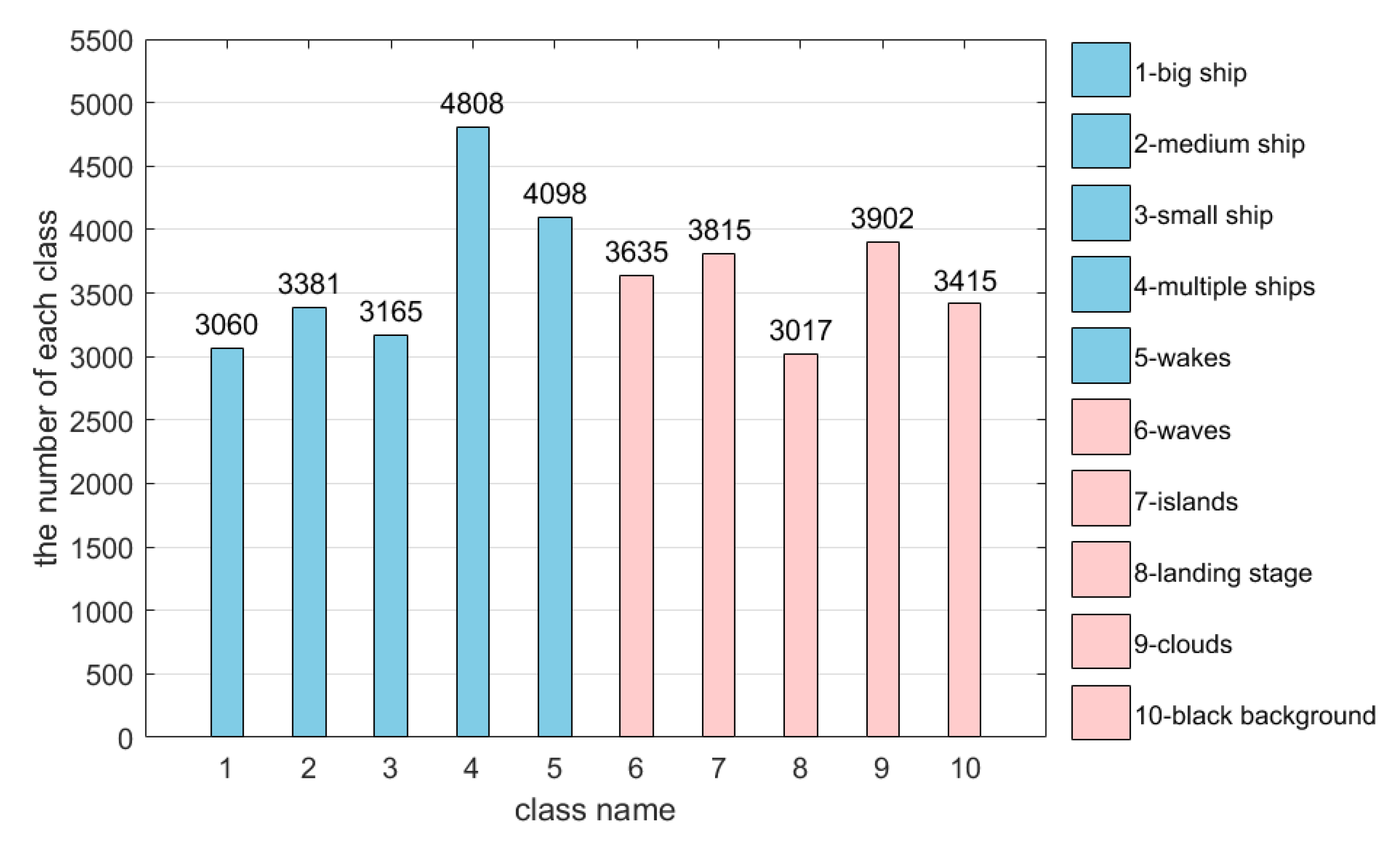
3.1. Dataset and Evaluation Metrics
3.2. Implementation Details
4. Parameter Setting and Comparative Experiments
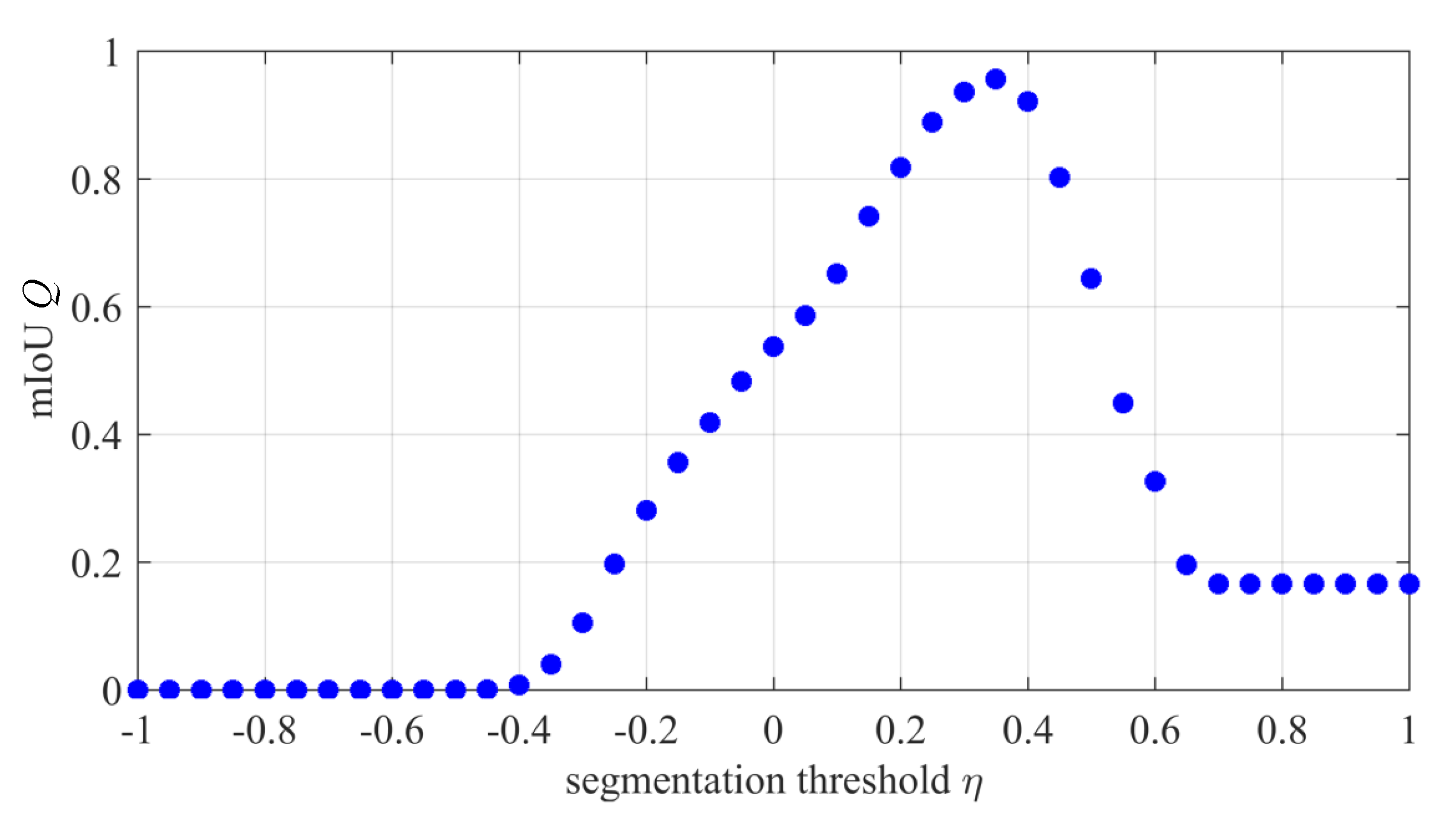
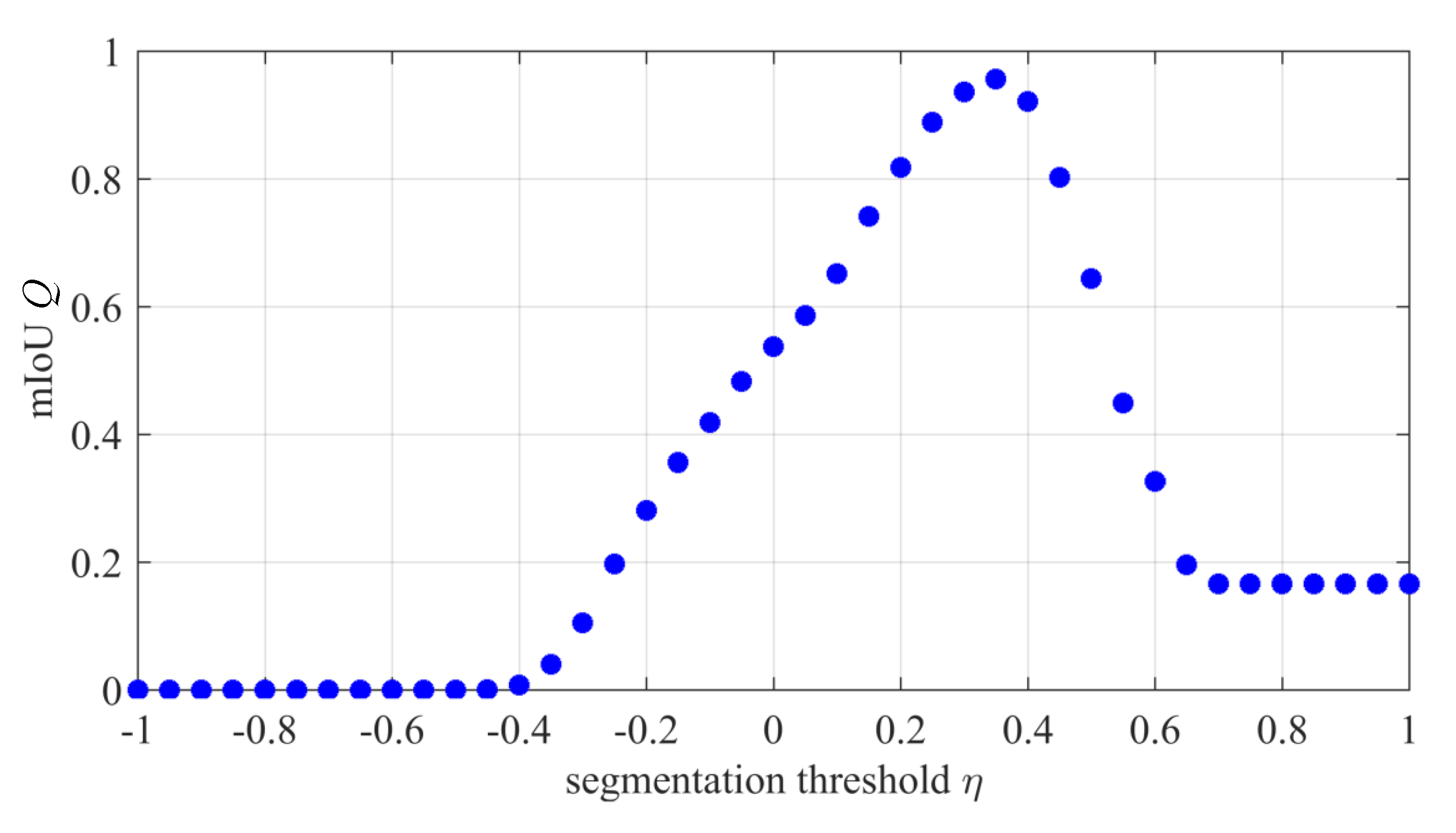
4.1. Parameter Setting
4.2. Comparisons for Different Sea-Land Segmentation Methods
4.3. Comparisons for Different Classification Strategies
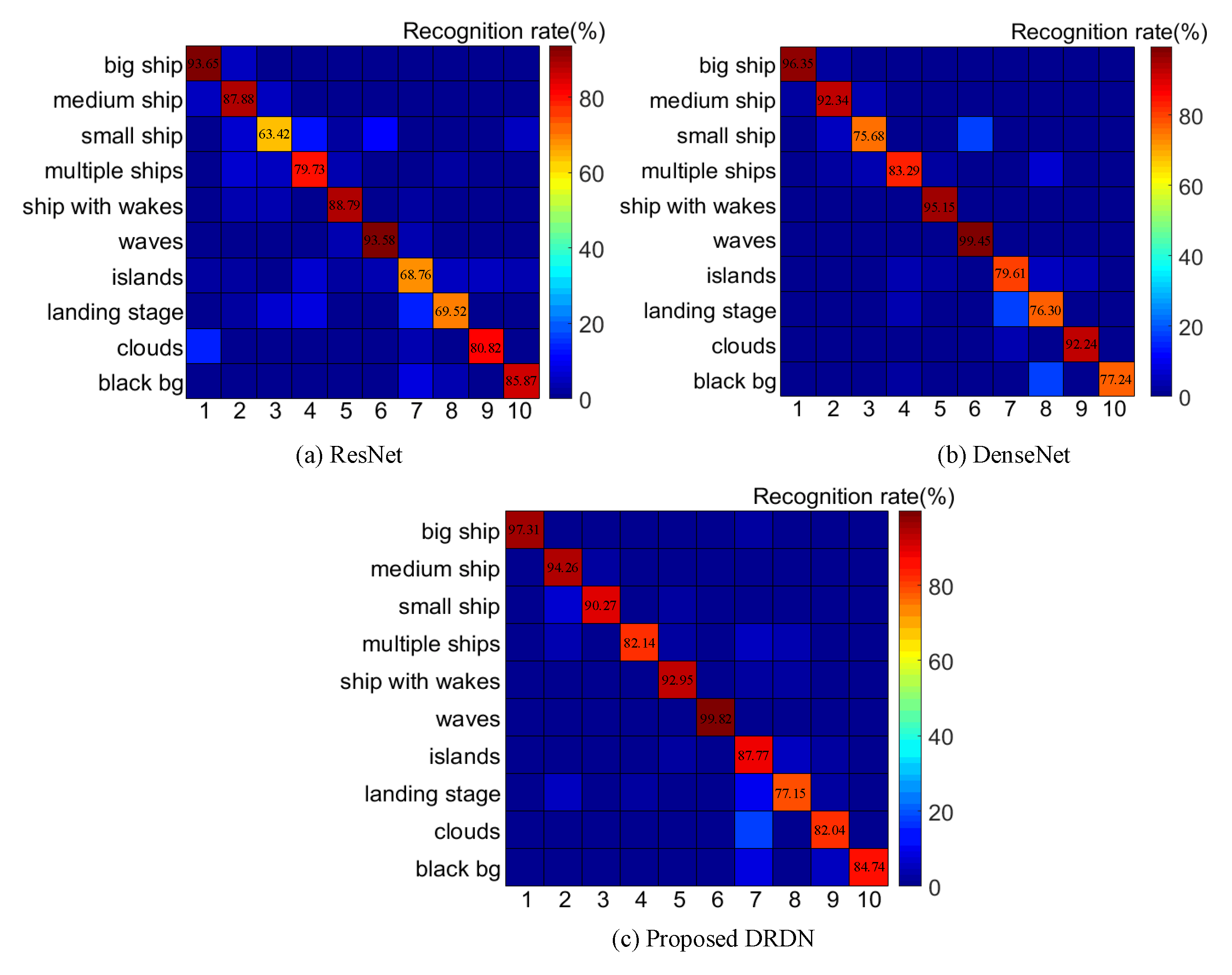
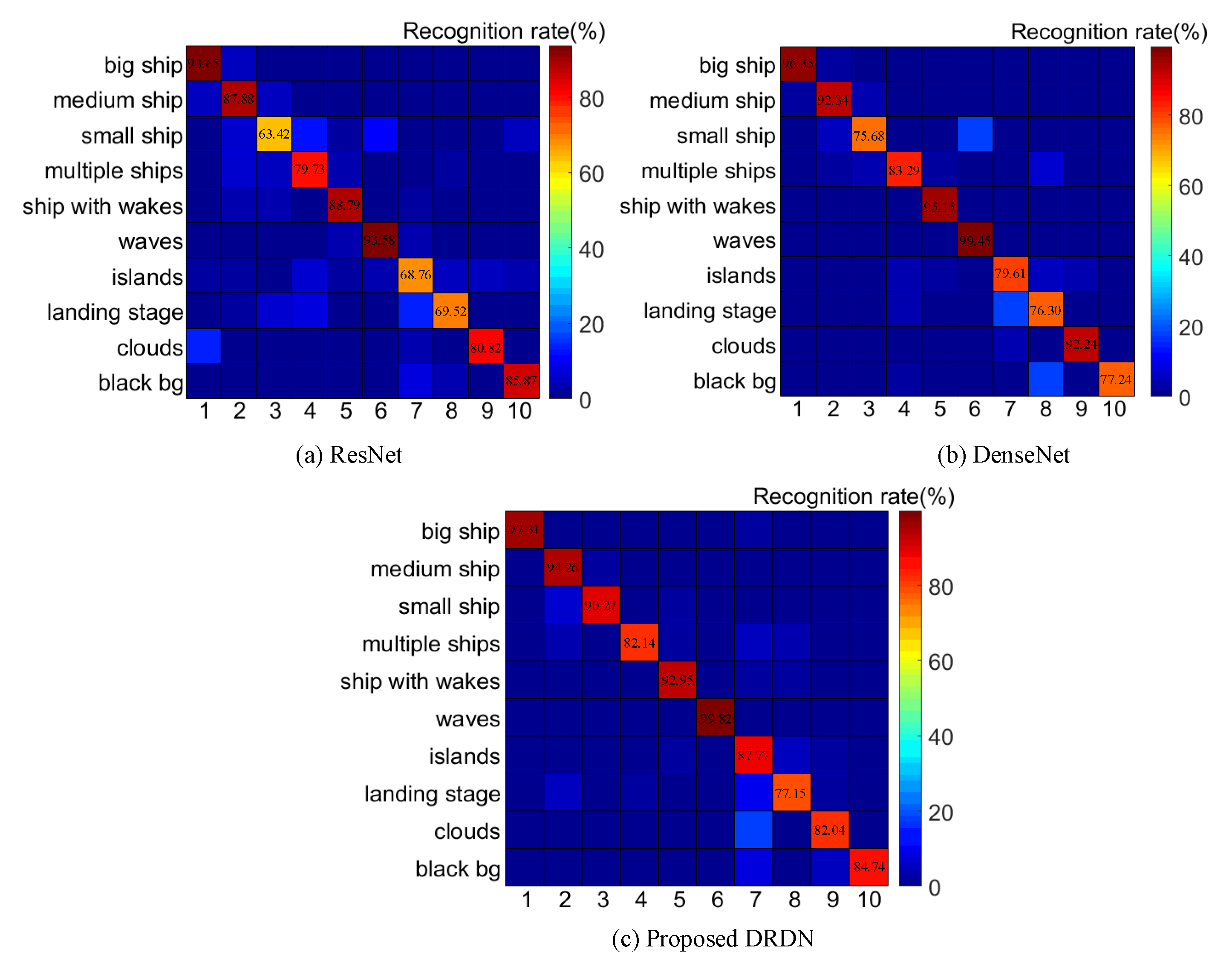
4.4. Comparisons of Different Classification Networks
5. Ship Detection Performance Analysis
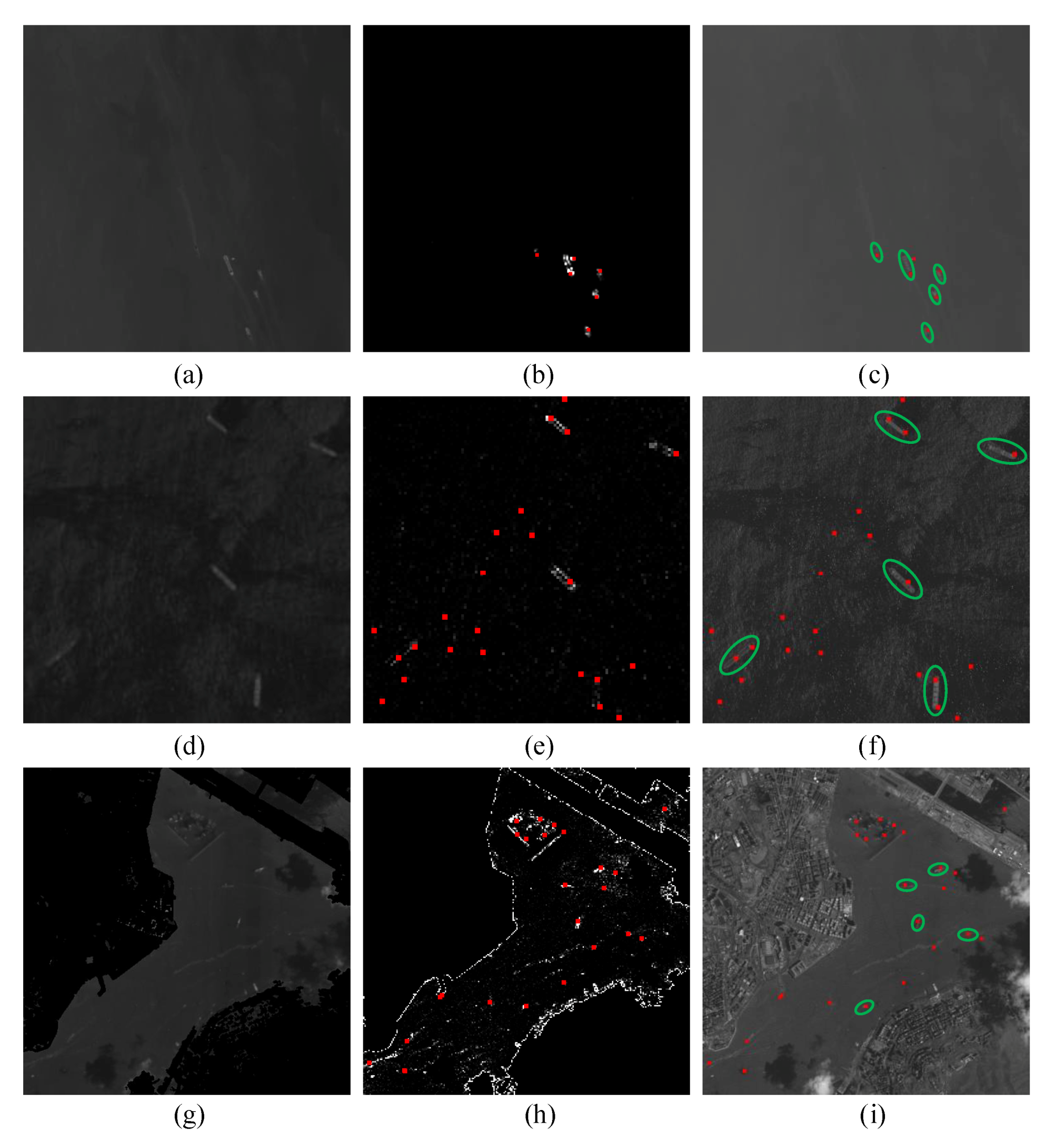
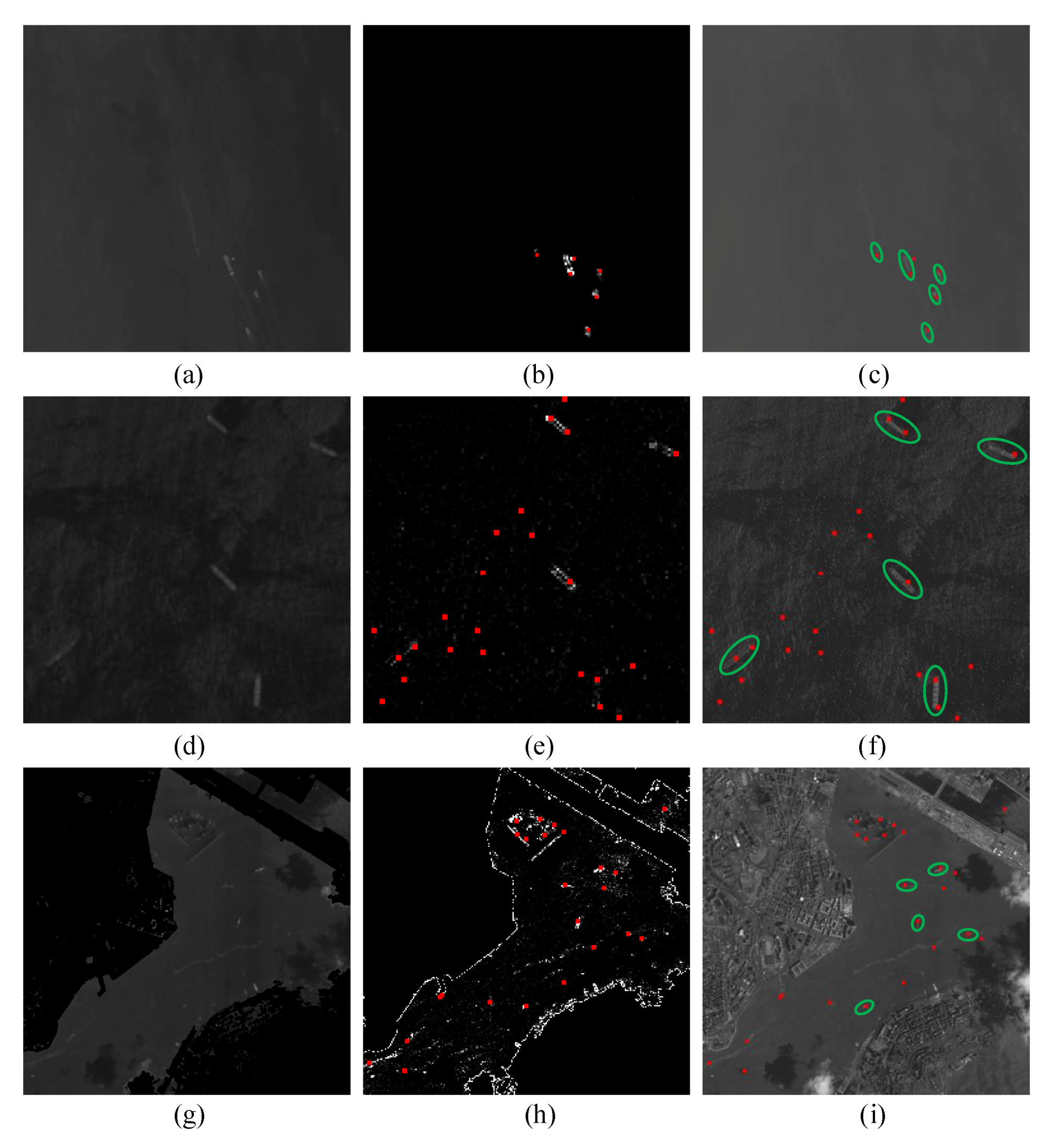
5.1. Location Performance in Different Image Backgrounds
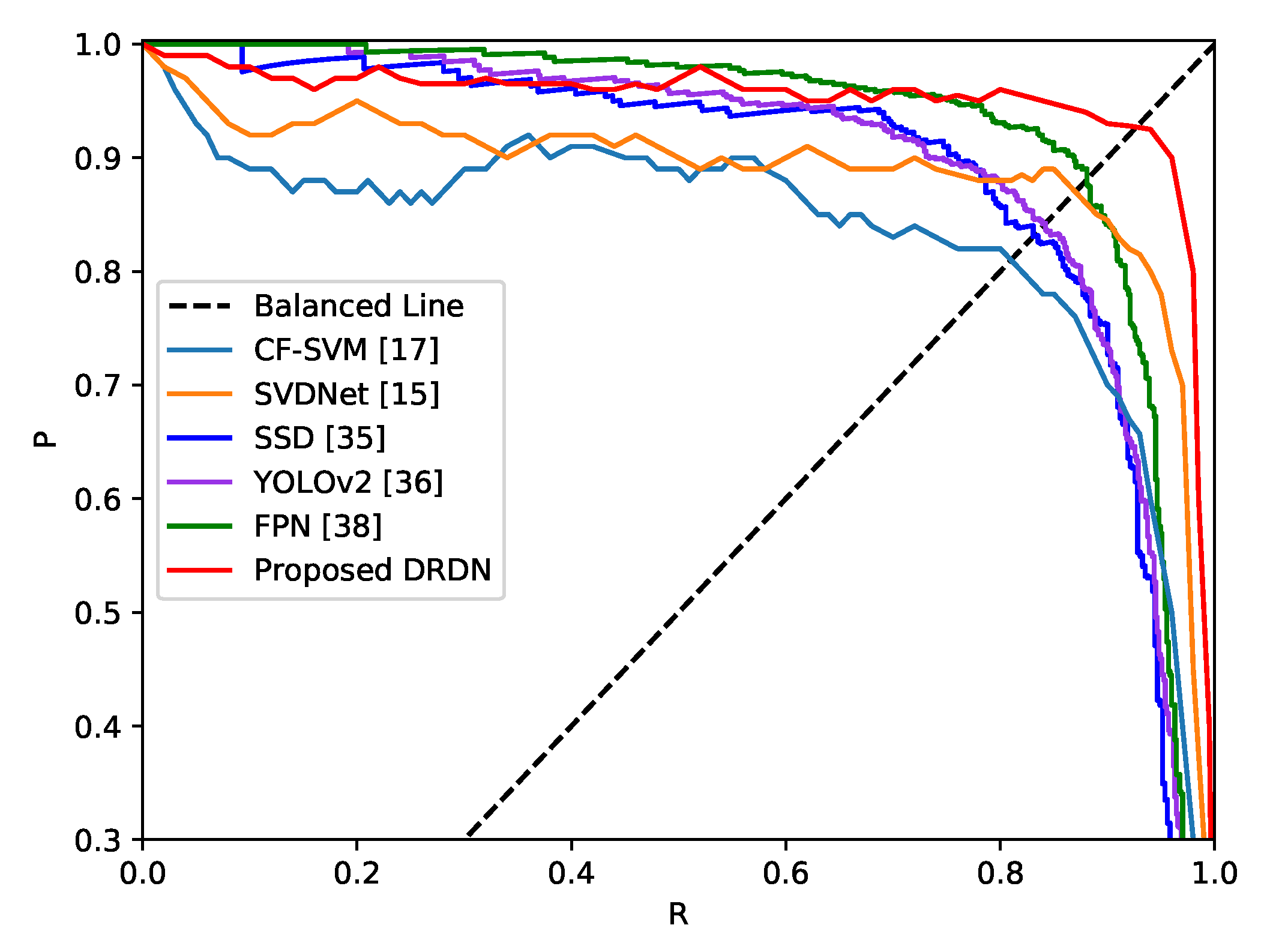
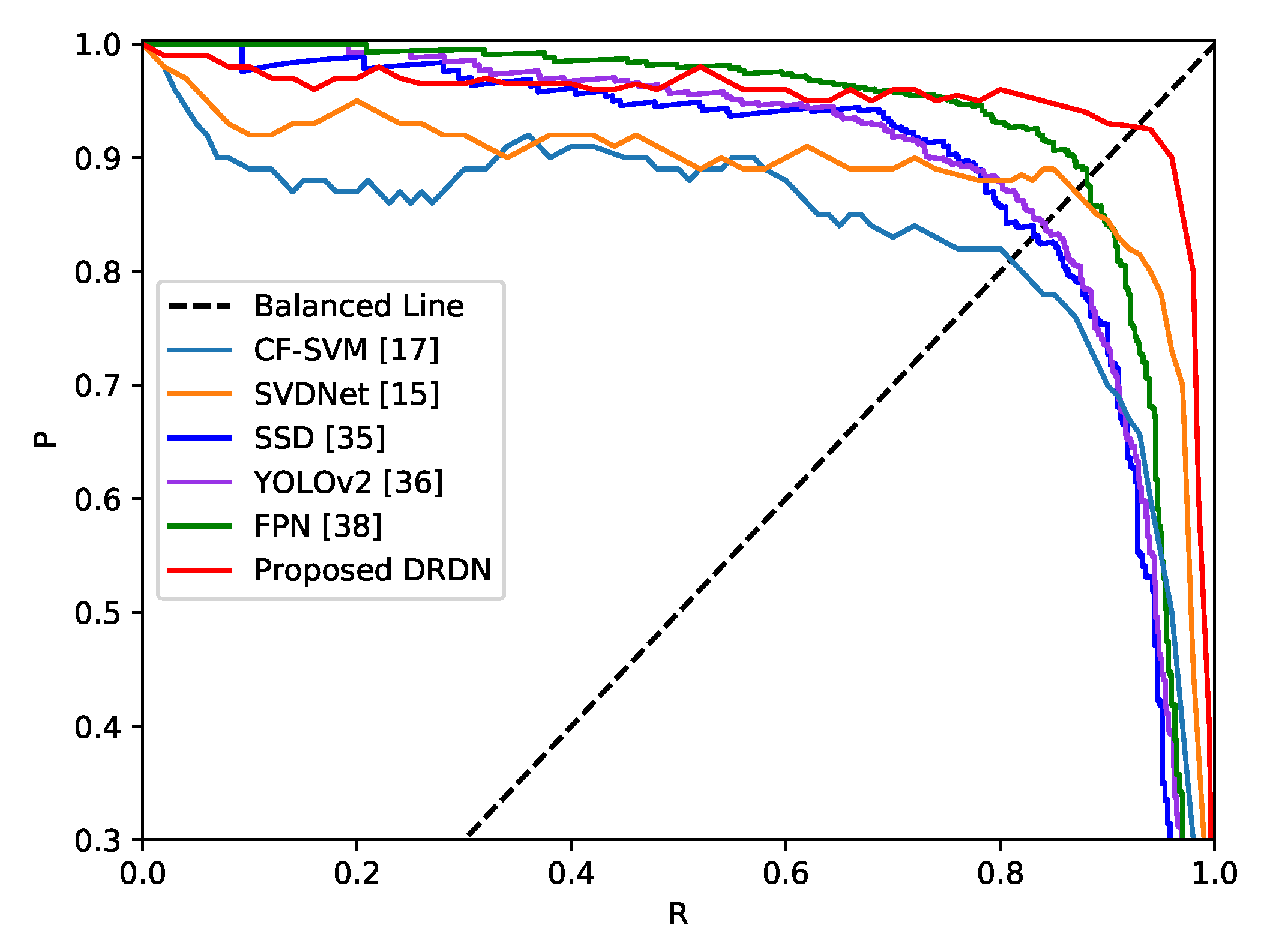
5.2. Comparisons with the State-Of-The-Art Detection Methods
5.3. Detection Performance in Different Image Backgrounds
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, H.; Li, Z.; Chen, Z.; Yang, D. Multi-layer sparse coding model-based ship detection for optical remote-sensing images. Int. J. Remote Sens. 2017, 38, 6281–6297. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, J.; Zhan, R. R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2031. [Google Scholar] [CrossRef]
- Liang, Y.; Sun, K.; Zeng, Y.; Li, G.; Xing, M. An adaptive hierarchical detection method for ship targets in high-resolution SAR images. Remote Sens. 2020, 12, 303. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Zhang, X.; Meng, J. A Small Ship Target Detection Method Based on Polarimetric SAR. Remote Sens. 2019, 11, 2938. [Google Scholar] [CrossRef] [Green Version]
- Fan, Q.; Chen, F.; Cheng, M.; Lou, S.; Li, J. Ship Detection Using a Fully Convolutional Network with Compact Polarimetric SAR Images. Remote Sens. 2019, 11, 2171. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.Y.; Bretschneider, T.R. Improved ship detection using dual-frequency polarimetric synthetic aperture radar data. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 2274–2277. [Google Scholar]
- Zhi, L.; Changwen, Q.; Qiang, Z.; Chen, L.; Shujuan, P.; Jianwei, L. Ship detection in harbor area in SAR images based on constructing an accurate sea-clutter model. In Proceedings of the 2017 IEEE 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 13–19. [Google Scholar]
- Vieira, F.M.; Vincent, F.; Tourneret, J.; Bonacci, D.; Spigai, M.; Ansart, M.; Richard, J. Ship detection using SAR and AIS raw data for maritime surveillance. In Proceedings of the 2016 IEEE 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 2081–2085. [Google Scholar]
- Wang, X.; Chen, C. Ship detection for complex background SAR images based on a multiscale variance weighted image entropy method. IEEE Geosci. Remote Sens. Lett. 2016, 14, 184–187. [Google Scholar] [CrossRef]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 195–208. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Zhou, M.; Jing, M.; Liu, D.; Xia, Z.; Zou, Z.; Shi, Z. Multi-resolution networks for ship detection in infrared remote sensing images. Infrared Phys. Technol. 2018, 92, 183–189. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised ship detection based on saliency and S-HOG descriptor from optical satellite images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Nie, T.; He, B.; Bi, G.; Zhang, Y.; Wang, W. A method of ship detection under complex background. ISPRS Int. J. Geo-Inf. 2017, 6, 159. [Google Scholar] [CrossRef]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.B.; Zhao, B. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1174–1185. [Google Scholar] [CrossRef]
- Wu, Y.; Ma, W.; Gong, M.; Bai, Z.; Zhao, W.; Guo, Q.; Chen, X.; Miao, Q. A Coarse-to-Fine Network for Ship Detection in Optical Remote Sensing Images. Remote Sens. 2020, 12, 246. [Google Scholar] [CrossRef] [Green Version]
- Wenxiu, W.; Yutian, F.; Feng, D.; Feng, L. Remote sensing ship detection technology based on DoG preprocessing and shape features. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1702–1706. [Google Scholar]
- Gan, L.; Liu, P.; Wang, L. Rotation sliding window of the hog feature in remote sensing images for ship detection. In Proceedings of the 2015 IEEE 8th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 12–13 December 2015; Volume 1, pp. 401–404. [Google Scholar]
- Xu, J.; Sun, X.; Zhang, D.; Fu, K. Automatic detection of inshore ships in high-resolution remote sensing images using robust invariant generalized Hough transform. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2070–2074. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship detection in high-resolution optical imagery based on anomaly detector and local shape feature. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4511–4523. [Google Scholar]
- Li, Z.; Itti, L. Saliency and gist features for target detection in satellite images. IEEE Trans. Image Process. 2010, 20, 2017–2029. [Google Scholar] [PubMed] [Green Version]
- Zhang, R.; Yao, J.; Zhang, K.; Feng, C.; Zhang, J. S-CNN-based Ship Detection from High-Resolution Remote Sensing Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 423–430. [Google Scholar] [CrossRef]
- Nie, T.; Han, X.; He, B.; Li, X.; Liu, H.; Bi, G. Ship Detection in Panchromatic Optical Remote Sensing Images Based on Visual Saliency and Multi-Dimensional Feature Description. Remote Sens. 2020, 12, 152. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Xu, Q.; Li, B. Ship detection from optical satellite images based on saliency segmentation and structure-LBP feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, M.; Lin, C.; Chen, D. Ship detection in optical remote sensing image based on visual saliency and AdaBoost classifier. Optoelectron. Lett. 2017, 13, 151–155. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector; European conference on computer vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Li, X.; Wang, S.; Jiang, B.; Chan, X. Inshore ship detection in remote sensing images based on deep features. In Proceedings of the 2017 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xiamen, China, 22–25 October 2017; pp. 1–5. [Google Scholar]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Tello, M.; López-Martínez, C.; Mallorqui, J.J. A novel algorithm for ship detection in SAR imagery based on the wavelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band Type | Wavelength (m) | Resolution (m) | Image Size (pixel) |
|---|---|---|---|
| Panchromatic | 0.45–0.90 | 2 | |
| Blue | 0.45–0.52 | 8 | |
| Green | 0.52–0.59 | 8 | |
| Red | 0.63–0.69 | 8 | |
| Near-infrared | 0.77–0.89 | 8 |
| Layer Name | Output Size | Stride | DRDN-134 | DRDN-214 | DRDN-278 |
|---|---|---|---|---|---|
| Convolution | 2 | Conv | |||
| Pooling | 2 | max pooling | |||
| LRDB1 | 1 | ||||
| 1 | Conv | ||||
| 2 | avg pooling | ||||
| LRDB2 | 1 | ||||
| 1 | Conv | ||||
| 2 | avg pooling | ||||
| LRDB3 | 1 | ||||
| 1 | Conv | ||||
| 2 | avg pooling | ||||
| LRDB4 | 1 | ||||
| 1 | Conv | ||||
| Classification Layer | global average pooling | ||||
| fully connected, softmax | |||||
| Segmentation Methods | Otsu on Panchromatic Images | Otsu on NIR | NDWI with Multispectral Images |
|---|---|---|---|
| mIoU | 0.7842 | 0.8438 | 0.9560 |
| Classification Strategy | Binary Class | Multiclass |
|---|---|---|
| P(%) | 85.68 | 95.43 |
| R(%) | 91.76 | 93.03 |
| F(%) | 14.32 | 4.57 |
| M(%) | 8.24 | 6.97 |
| (%) | 88.62 | 94.21 |
| Classification Network | #params | P (%) | R (%) | (%) |
|---|---|---|---|---|
| AlexNet [32] | 57.04 M | 72.13 | 70.06 | 71.08 |
| VGG-16 [50] | 134.31 M | 84.11 | 83.57 | 83.84 |
| ResNet-101 [33] | 42.52 M | 89.87 | 87.39 | 88.61 |
| DenseNet-264 [34] | 30.68 M | 92.75 | 91.66 | 92.20 |
| Inception V4 [51] | 41.12 M | 94.59 | 92.14 | 93.35 |
| DRDN-134 | 8.15 M | 95.43 | 93.03 | 94.21 |
| DRDN-214 | 19.69 M | 95.85 | 93.61 | 94.72 |
| DRDN-278 | 32.54 M | 96.19 | 94.05 | 95.11 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Shi, W.; Fan, C.; Zou, L.; Deng, D. A Novel Coarse-to-Fine Method of Ship Detection in Optical Remote Sensing Images Based on a Deep Residual Dense Network. Remote Sens. 2020, 12, 3115. https://doi.org/10.3390/rs12193115
Chen L, Shi W, Fan C, Zou L, Deng D. A Novel Coarse-to-Fine Method of Ship Detection in Optical Remote Sensing Images Based on a Deep Residual Dense Network. Remote Sensing. 2020; 12(19):3115. https://doi.org/10.3390/rs12193115
Chicago/Turabian StyleChen, Liqiong, Wenxuan Shi, Cien Fan, Lian Zou, and Dexiang Deng. 2020. "A Novel Coarse-to-Fine Method of Ship Detection in Optical Remote Sensing Images Based on a Deep Residual Dense Network" Remote Sensing 12, no. 19: 3115. https://doi.org/10.3390/rs12193115
APA StyleChen, L., Shi, W., Fan, C., Zou, L., & Deng, D. (2020). A Novel Coarse-to-Fine Method of Ship Detection in Optical Remote Sensing Images Based on a Deep Residual Dense Network. Remote Sensing, 12(19), 3115. https://doi.org/10.3390/rs12193115