Identifying the Contributions of Multi-Source Data for Winter Wheat Yield Prediction in China


Abstract
1. Introduction
2. Material and Methods
2.1. Study Area
2.2. Dataset and Preprocessing
2.2.1. Crop Yield and Area
2.2.2. Satellite Data
2.2.3. Climate Data
2.2.4. Socio-Economic Factor
2.2.5. Other Datasets
2.3. Methods
2.3.1. Ridge Regression (RR)
2.3.2. Random Forest (RF)
2.3.3. Light Gradient Boosting Machine (LightGBM)
2.4. Experiment Design
2.4.1. The First Experiment to Separate the Spatial and Temporal Variations of Yields and Combine the Explanatory Ones Differently
2.4.2. The Second Experiment to Quantify the Contributions of Time Series Data to Yield Prediction
2.4.3. The Third Experiment to Investigate the Values of Static Variables on Yield Prediction, and to Validate the Model Performances
3. Results
3.1. Exploratory Data Analysis (EDA)
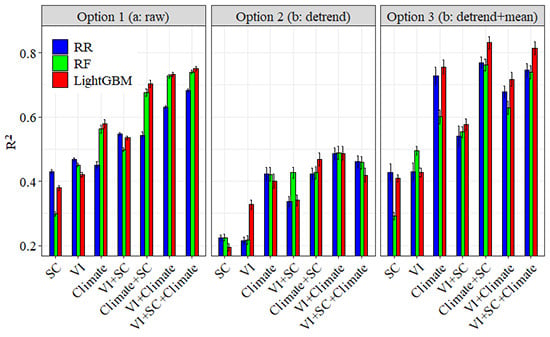
3.2. The Performances of Multi-Models for Predicting Wheat Yield
3.3. Quantifying Unique and Shared Information from Climate and VIs
3.4. The Effects of Spatial Information and Soil Properties on Improving Yield Estimation
4. Discussion
4.1. The Best Combinations of Explanatory Variables to Explain Spatial or Temporal Variability of Wheat Yield
4.2. The Unique and Shared Contributions of Different Data Sources for Predicting Crop Yield
4.3. Method Comparison
4.4. Some Limitations of this Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A


References
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Groten, S.M.E. NDVI—Crop monitoring and early yield assessment of Burkina Faso. Int. J. Remote Sens. 2007, 14, 1495–1515. [Google Scholar] [CrossRef]
- He, Z.; Xia, X.; Zhang, Y. Breeding noodle wheat in China. In Asian Noodles: Science, Technology, and Processing; Wiley: Hoboken, NJ, USA, 2010; pp. 1–23. [Google Scholar]
- Song, Y.; Linderholm, H.W.; Wang, C.; Tian, J.; Huo, Z.; Gao, P.; Song, Y.; Guo, A. The influence of excess precipitation on winter wheat under climate change in China from 1961 to 2017. Sci. Total Environ. 2019, 690, 189–196. [Google Scholar] [CrossRef] [PubMed]
- Zhai, Y.; Shen, X.; Quan, T.; Ma, X.; Zhang, R.; Ji, C.; Zhang, T.; Hong, J. Impact-oriented water footprint assessment of wheat production in China. Sci. Total Environ. 2019, 689, 90–98. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Wang, P.; Chen, D.; Shi, G.; Cheng, K.; Bian, R.; Liu, X.; Zhang, X.; Zheng, J.; Crowley, D.E.; et al. Short-term biochar manipulation of microbial nitrogen transformation in wheat rhizosphere of a metal contaminated Inceptisol from North China plain. Sci. Total Environ. 2018, 640, 1287–1296. [Google Scholar] [CrossRef]
- Huang, J.; Tian, L.; Liang, S.; Ma, H.; Becker-Reshef, I.; Huang, Y.; Su, W.; Zhang, X.; Zhu, D.; Wu, W. Improving winter wheat yield estimation by assimilation of the leaf area index from Landsat TM and MODIS data into the WOFOST model. Agric. For. Meteorol. 2015, 204, 106–121. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Tao, F. Improving regional winter wheat yield estimation through assimilation of phenology and leaf area index from remote sensing data. Eur. J. Agron. 2018, 101, 163–173. [Google Scholar] [CrossRef]
- Lobell, D.B.; Hammer, G.L.; McLean, G.; Messina, C.; Roberts, M.J.; Schlenker, W. The critical role of extreme heat for maize production in the United States. Nat. Clim. Chang. 2013, 3, 497–501. [Google Scholar] [CrossRef]
- Lesk, C.; Rowhani, P.; Ramankutty, N. Influence of extreme weather disasters on global crop production. Nature 2016, 529, 84–87. [Google Scholar] [CrossRef]
- Horie, T.; Yajima, M.; Nakagawa, H. Yield forecasting. Agric. Syst. 1992, 40, 211–236. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef]
- Asseng, S.; Cammarano, D.; Basso, B.; Chung, U.; Alderman, P.D.; Sonder, K.; Reynolds, M.; Lobell, D.B. Hot spots of wheat yield decline with rising temperatures. Glob. Chang. Biol. 2017, 23, 2464–2472. [Google Scholar] [CrossRef]
- Kogan, F.; Guo, W.; Yang, W.; Harlan, S. Space-based vegetation health for wheat yield modeling and prediction in Australia. J. Appl. Remote Sens. 2018, 12, 026002. [Google Scholar]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Dhakal, K.; Kakani, V.G.; Linde, E. Climate Change Impact on Wheat Production in the Southern Great Plains of the US Using Downscaled Climate Data. Atmos. Clim. Sci. 2018, 8, 143–162. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Tao, F.; Wang, P.; Wei, X. Spatio-temporal patterns of winter wheat yield potential and yield gap during the past three decades in North China. Field Crop. Res. 2017, 206, 11–20. [Google Scholar] [CrossRef]
- Lobell, D.B.; Thau, D.; Seifert, C.; Engle, E.; Little, B. A scalable satellite-based crop yield mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Wang, C.; Liu, J.; Zhang, L. Susceptibility assessment of landslides triggered by earthquakes in the Western Sichuan Plateau. Catena 2019, 175, 63–76. [Google Scholar] [CrossRef]
- Decencière, E.; Cazuguel, G.; Zhang, X.; Thibault, G.; Klein, J.C.; Meyer, F.; Marcotegui, B.; Quellec, G.; Lamard, M.; Danno, R.; et al. TeleOphta: Machine learning and image processing methods for teleophthalmology. Irbm 2013, 34, 196–203. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin, Heidelberg; Volume 3951, pp. 430–443. [Google Scholar] [CrossRef]
- Sidorov, G.; Velasquez, F.; Stamatatos, E.; Gelbukh, A.; Chanona-Hernández, L. Syntactic n-grams as machine learning features for natural language processing. Expert Syst. Appl. 2014, 41, 853–860. [Google Scholar] [CrossRef]
- Garosi, Y.; Sheklabadi, M.; Conoscenti, C.; Pourghasemi, H.R.; Van Oost, K. Assessing the performance of GIS- based machine learning models with different accuracy measures for determining susceptibility to gully erosion. Sci. Total Environ. 2019, 664, 1117–1132. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Sharma, S.; Ochsner, T.E.; Twidwell, D.; Carlson, J.; Krueger, E.S.; Engle, D.M.; Fuhlendorf, S.D. Nondestructive estimation of standing crop and fuel moisture content in tallgrass prairie. Rangel. Ecol. Manag. 2018, 71, 356–362. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218, 74–84. [Google Scholar] [CrossRef]
- Kaul, M.; Hill, R.L.; Walthall, C. Artificial neural networks for corn and soybean yield prediction. Agric. Syst. 2005, 85, 1–18. [Google Scholar] [CrossRef]
- Everingham, Y.; Sexton, J.; Skocaj, D.; Inman-Bamber, G. Accurate prediction of sugarcane yield using a random forest algorithm. Agron. Sustain. Dev. 2016, 36. [Google Scholar] [CrossRef]
- Guan, K.; Berry, J.A.; Zhang, Y.; Joiner, J.; Guanter, L.; Badgley, G.; Lobell, D.B. Improving the monitoring of crop productivity using spaceborne solar-induced fluorescence. Glob. Chang. Biol. 2016, 22, 716–726. [Google Scholar] [CrossRef]
- Johnson, D.M. An assessment of pre- and within-season remotely sensed variables for forecasting corn and soybean yields in the United States. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- Vincenzi, S.; Zucchetta, M.; Franzoi, P.; Pellizzato, M.; Pranovi, F.; De Leo, G.A.; Torricelli, P. Application of a Random Forest algorithm to predict spatial distribution of the potential yield of Ruditapes philippinarum in the Venice lagoon, Italy. Ecol. Model. 2011, 222, 1471–1478. [Google Scholar] [CrossRef]
- Guan, K.; Wu, J.; Kimball, J.S.; Anderson, M.C.; Frolking, S.; Li, B.; Hain, C.R.; Lobell, D.B. The shared and unique values of optical, fluorescence, thermal and microwave satellite data for estimating large-scale crop yields. Remote Sens. Environ. 2017, 199, 333–349. [Google Scholar] [CrossRef]
- Liu, J.; He, X.; Wang, P.; Huang, J. Early prediction of winter wheat yield with long time series meteorological data and random forest method. Trans. CSAE 2019, 35, 158–166. [Google Scholar] [CrossRef]
- Newlands, N.K.; Zamar, D.S.; Kouadio, L.A.; Zhang, Y.; Chipanshi, A.; Potgieter, A.; Toure, S.; Hill, H.S.J. An integrated, probabilistic model for improved seasonal forecasting of agricultural crop yield under environmental uncertainty. Front. Environ. Sci. 2014, 2. [Google Scholar] [CrossRef]
- Patrignani, A.; Lollato, R.P.; Ochsner, T.E.; Godsey, C.B.; Edwards, J.T. Yield Gap and Production Gap of Rainfed Winter Wheat in the Southern Great Plains. Agron. J. 2014, 106. [Google Scholar] [CrossRef]
- Vereecken, H.; Weihermüller, L.; Jonard, F.; Montzka, C. Characterization of Crop Canopies and Water Stress Related Phenomena using Microwave Remote Sensing Methods: A Review. Vadose Zone J. 2012, 11. [Google Scholar] [CrossRef]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A generalized regression-based model for forecasting winter wheat yields in Kansas and Ukraine using MODIS data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- Burke, M.; Lobell, D.B. Satellite-based assessment of yield variation and its determinants in smallholder African systems. Proc. Natl. Acad. Sci. USA 2017, 114, 2189–2194. [Google Scholar] [CrossRef]
- Sellers, P.; Berry, J.; Collatz, G.; Field, C.; Hall, F. Canopy reflectance, photosynthesis, and transpiration. III. A reanalysis using improved leaf models and a new canopy integration scheme. Remote Sens. Environ. 1992, 42, 187–216. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Viña, A.; Arkebauer, T.J.; Rundquist, D.C.; Keydan, G.; Leavitt, B. Remote estimation of leaf area index and green leaf biomass in maize canopies. Geophys. Res. Lett. 2003, 30. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Jain, M.; Srivastava, A.; Balwinder, S.; Joon, R.; McDonald, A.; Royal, K.; Lisaius, M.; Lobell, D. Mapping Smallholder Wheat Yields and Sowing Dates Using Micro-Satellite Data. Remote Sens. 2016, 8, 860. [Google Scholar] [CrossRef]
- Lopresti, M.F.; Di Bella, C.M.; Degioanni, A.J. Relationship between MODIS-NDVI data and wheat yield: A case study in Northern Buenos Aires province, Argentina. Inf. Process. Agric. 2015, 2, 73–84. [Google Scholar] [CrossRef]
- Ray, D.K.; Ramankutty, N.; Mueller, N.D.; West, P.C.; Foley, J.A. Recent patterns of crop yield growth and stagnation. Nat. Commun. 2012, 3, 1293. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wiberg, D.; Zehnder, A.J.B.; Yang, H. Modeling the role of irrigation in winter wheat yield, crop water productivity, and production in China. Irrig. Sci. 2007, 26, 21–33. [Google Scholar] [CrossRef]
- Mueller, N.D.; Gerber, J.S.; Johnston, M.; Ray, D.K.; Ramankutty, N.; Foley, J.A. Closing yield gaps through nutrient and water management. Nature 2012, 490, 254–257. [Google Scholar] [CrossRef]
- Trueblood, M.A.; Arnade, C. Crop Yield Convergence: How Russia’s Yield Performance Has Compared to Global Yield Leaders. Comp. Econ. Stud. 2001, 43, 59–81. [Google Scholar] [CrossRef]
- Yu, H.; Qiang, Z.; Peng, S.; Changqing, S. Impacts of drought intensity and drought duration on winter wheat yield in five provinces of North China plain. Acta Geogr. Sin. 2019, 074, 87–102. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, X.; Wang, H.; Li, Y.; Ye, Q. Climatic and technological ceilings for Chinese rice stagnation based on yield gaps and yield trend pattern analysis. Glob. Chang. Biol. 2014, 20, 1289–1298. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, Z.; Zhang, S.; Zhu, Z.; Shi, W. Response of crop yields to climate trends since 1980 in China. Clim. Res. 2012, 54, 233–247. [Google Scholar] [CrossRef]
- Liu, J.; Kuang, W.; Zhang, Z.; Xu, X.; Qin, Y.; Ning, J.; Zhou, W.; Zhang, S.; Li, R.; Yan, C. Spatiotemporal characteristics, patterns, and causes of land-use changes in China since the late 1980s. J. Geogr. Sci. 2014, 24, 195–210. [Google Scholar] [CrossRef]
- Liu, J.; Liu, M.; Tian, H.; Zhuang, D.; Zhang, Z.; Zhang, W.; Tang, X.; Deng, X. Spatial and temporal patterns of China’s cropland during 1990–2000: An analysis based on Landsat TM data. Remote Sens. Environ. 2005, 98, 442–456. [Google Scholar] [CrossRef]
- Boken, V.K.; Shaykewich, C.F. Improving an operational wheat yield model using phenological phase-based Normalized Difference Vegetation Index. Int. J. Remote Sens. 2010, 23, 4155–4168. [Google Scholar] [CrossRef]
- Abatzoglou, J.T.; Dobrowski, S.Z.; Parks, S.A.; Hegewisch, K.C. TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015. Sci. Data 2018, 5, 170191. [Google Scholar] [CrossRef]
- Shangguan, W.; Dai, Y.; Liu, B.; Ye, A.; Yuan, H. A soil particle-size distribution dataset for regional land and climate modelling in China. Geoderma 2012, 171, 85–91. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Hernandez, J.; Lobos, G.; Matus, I.; del Pozo, A.; Silva, P.; Galleguillos, M. Using Ridge Regression Models to Estimate Grain Yield from Field Spectral Data in Bread Wheat (Triticum aestivum L.) Grown under Three Water Regimes. Remote Sens. 2015, 7, 2109–2126. [Google Scholar] [CrossRef]
- Ruppert, D. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. J. Am. Stat. Assoc. 2004, 99, 567. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2015, 13, 839–856. [Google Scholar] [CrossRef]
- Sun, X.; Liu, M.; Sima, Z. A novel cryptocurrency price trend forecasting model based on LightGBM. Financ. Res. Lett. 2018. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Thirty-First Conference on Neural Information Processing System, Long Beach, CA, USA, 4 December 2017. [Google Scholar]
- Zhang, W.; Quan, H.; Srinivasan, D. Parallel and reliable probabilistic load forecasting via quantile regression forest and quantile determination. Energy 2018, 160, 810–819. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, Z.; Song, X.; Chen, Y.; Wei, X.; Shi, P.; Tao, F. Temperature variations and rice yields in China: Historical contributions and future trends. Clim. Chang. 2014, 124, 777–789. [Google Scholar] [CrossRef]
- Hatfield, J.; Gitelson, A.A.; Schepers, J.S.; Walthall, C. Application of spectral remote sensing for agronomic decisions. Agron. J. 2008, 100, S117–S131. [Google Scholar] [CrossRef]
- Mahlein, A.-K.; Oerke, E.-C.; Steiner, U.; Dehne, H.-W. Recent advances in sensing plant diseases for precision crop protection. Eur. J. Plant Pathol. 2012, 133, 197–209. [Google Scholar] [CrossRef]
- Lobell, D.B. The use of satellite data for crop yield gap analysis. Field Crop. Res. 2013, 143, 56–64. [Google Scholar] [CrossRef]
- Manjunath, K.R.; Potdar, M.B.; Purohit, N.L. Large area operational wheat yield model development and validation based on spectral and meteorological data. Int. J. Remote Sens. 2010, 23, 3023–3038. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, P.; Chen, Y.; Song, X.; Wei, X.; Shi, P. Global warming over 1960–2009 did increase heat stress and reduce cold stress in the major rice-planting areas across China. Eur. J. Agron. 2014, 59, 49–56. [Google Scholar] [CrossRef]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep gaussian process for crop yield prediction based on remote sensing data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4 February 2017. [Google Scholar]
- Wardlow, B.D.; Egbert, S.L. Large-area crop mapping using time-series MODIS 250 m NDVI data: An assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Guanter, L.; Zhang, Y.; Jung, M.; Joiner, J.; Voigt, M.; Berry, J.A.; Frankenberg, C.; Huete, A.R.; Zarco-Tejada, P.; Lee, J.E.; et al. Global and time-resolved monitoring of crop photosynthesis with chlorophyll fluorescence. Proc. Natl. Acad. Sci. USA 2014, 111, E1327–E1333. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Variables | Spatial Resolution | Temporal Resolution | Available Records | References |
|---|---|---|---|---|---|
| Crop yield and area | Crop yield | County-level | Yearly | 2001-2015 | http://www.stats.gov.cn |
| Crop area | 1 km | Five-year | 2005, 2010, 2015 | [45,46] | |
| Satellite data | MOD09A1 | 500 m | 8-day | 2001–2018 | MODIS MOD09A1 |
| DEM | 90 m | 2000 | 2000 | SRTM3 V4.1 | |
| Climate data | Tmin, Tmax, Pre, Vpd, and Vap | ~4 km | Monthly | 1958–2018 | [51] |
| Socio-economic factors | CAP, CCF, ECRA, IA, and TPAM | County-level | Yearly | 2001–2015 | http://www.stats.gov.cn |
| Soil properties data | soil depth, soil texture, organic carbon content, pH, cation exchange capacity, and bulk density | 0.00833 (~1 km) | 2012 | 2012 | [52] |
| Tmax | Tmin | Pre | Vap | Vpd | CAP | CCF | ECRA | IA | TPAM | NDVI | GCVI | EVI | Yield | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tmax | 1.00 | 0.78 | 0.33 | 0.58 | 0.35 | −0.09 | −0.16 | −0.14 | −0.19 | −0.19 | 0.48 | 0.41 | 0.45 | 0.03 (**) |
| Tmin | - | 1.00 | 0.67 | 0.90 | −0.22 | −0.05 | −0.15 | −0.14 | −0.11 | −0.16 | 0.49 | 0.43 | 0.43 | −0.08 (***) |
| Pre | - | - | 1.00 | 0.82 | −0.58 | −0.06 | −0.21 | −0.16 | −0.14 | −0.19 | 0.32 | 0.28 | 0.20 | −0.40 (***) |
| Vap | - | - | - | 1.00 | −0.52 | −0.06 | −0.19 | −0.19 | −0.11 | −0.20 | 0.42 | 0.38 | 0.33 | −0.23 (***) |
| Vpd | - | - | - | - | 1.00 | −0.01 | 0.03 | 0.03 | −0.09 | 0.01 | 0.01 | 0.00 | 0.09 | 0.29 (***) |
| CAP | - | - | - | - | - | 1.00 | 0.42 | 0.08 | 0.37 | 0.42 | 0.05 | 0.04 | 0.05 | 0.10 (***) |
| CCF | - | - | - | - | - | - | 1.00 | 0.57 | 0.83 | 0.82 | −0.12 | −0.13 | −0.09 | 0.16 (***) |
| ECRA | - | - | - | - | - | - | - | 1.00 | 0.46 | 0.50 | −0.09 | −0.09 | −0.07 | 0.12 (***) |
| IA | - | - | - | - | - | - | - | - | 1.00 | 0.74 | −0.16 | −0.16 | −0.13 | 0.09 (***) |
| TPAM | - | - | - | - | - | - | - | - | - | 1.00 | −0.10 | −0.10 | −0.07 | 0.16(***) |
| NDVI | - | - | - | - | - | - | - | - | - | - | 1.00 | 0.99 | 0.97 | 0.31 (***) |
| GCVI | - | - | - | - | - | - | - | - | - | - | - | 1.00 | 0.97 | 0.39 (***) |
| EVI | - | - | - | - | - | - | - | - | - | - | - | - | 1.00 | 0.33 (***) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Han, J.; Li, Z. Identifying the Contributions of Multi-Source Data for Winter Wheat Yield Prediction in China. Remote Sens. 2020, 12, 750. https://doi.org/10.3390/rs12050750
Cao J, Zhang Z, Tao F, Zhang L, Luo Y, Han J, Li Z. Identifying the Contributions of Multi-Source Data for Winter Wheat Yield Prediction in China. Remote Sensing. 2020; 12(5):750. https://doi.org/10.3390/rs12050750
Chicago/Turabian StyleCao, Juan, Zhao Zhang, Fulu Tao, Liangliang Zhang, Yuchuan Luo, Jichong Han, and Ziyue Li. 2020. "Identifying the Contributions of Multi-Source Data for Winter Wheat Yield Prediction in China" Remote Sensing 12, no. 5: 750. https://doi.org/10.3390/rs12050750
APA StyleCao, J., Zhang, Z., Tao, F., Zhang, L., Luo, Y., Han, J., & Li, Z. (2020). Identifying the Contributions of Multi-Source Data for Winter Wheat Yield Prediction in China. Remote Sensing, 12(5), 750. https://doi.org/10.3390/rs12050750