The Use of Saliency in Underwater Computer Vision: A Review



Abstract
:1. Introduction
2. Saliency Models
2.1. Feature-Based Saliency
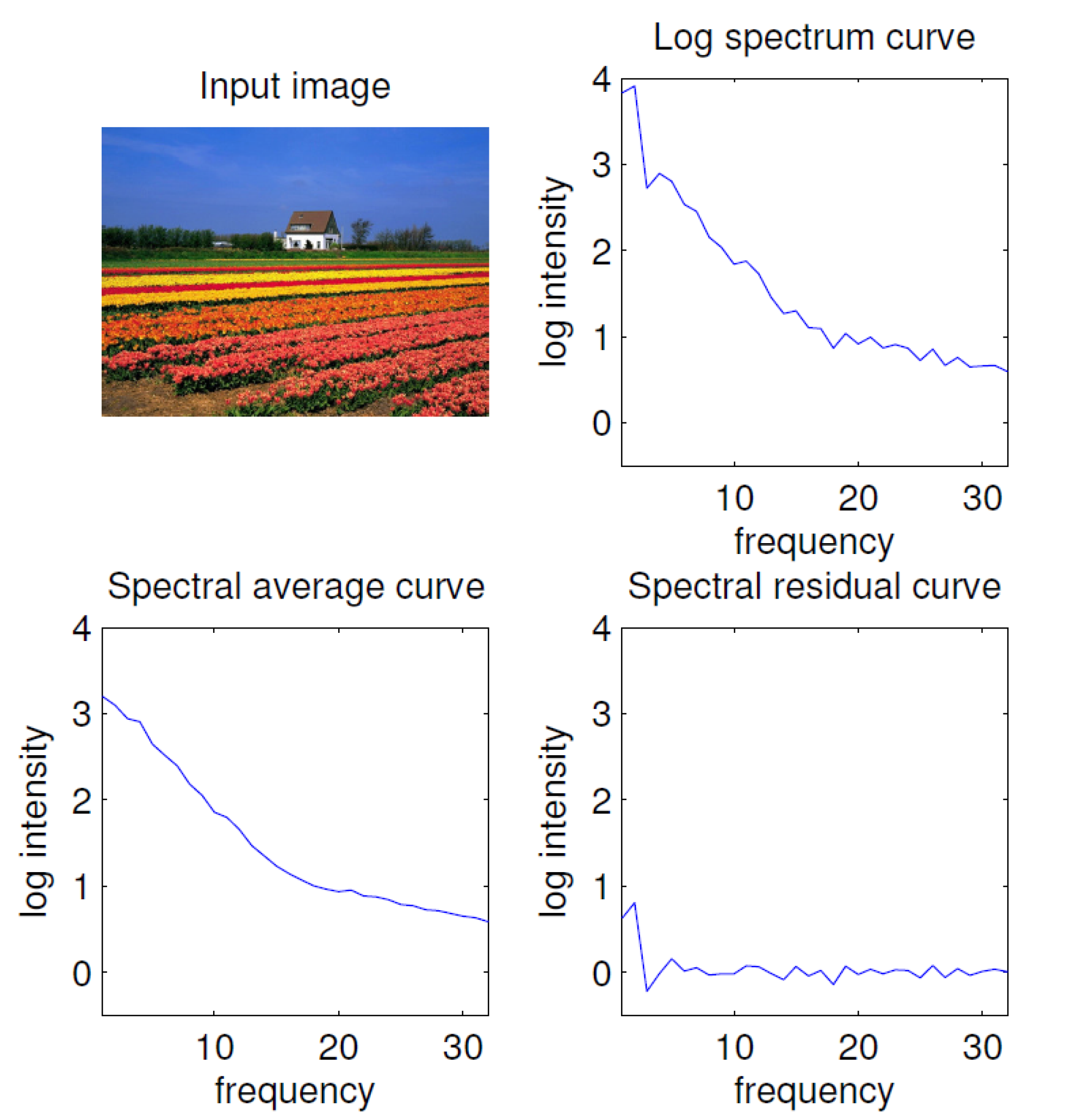
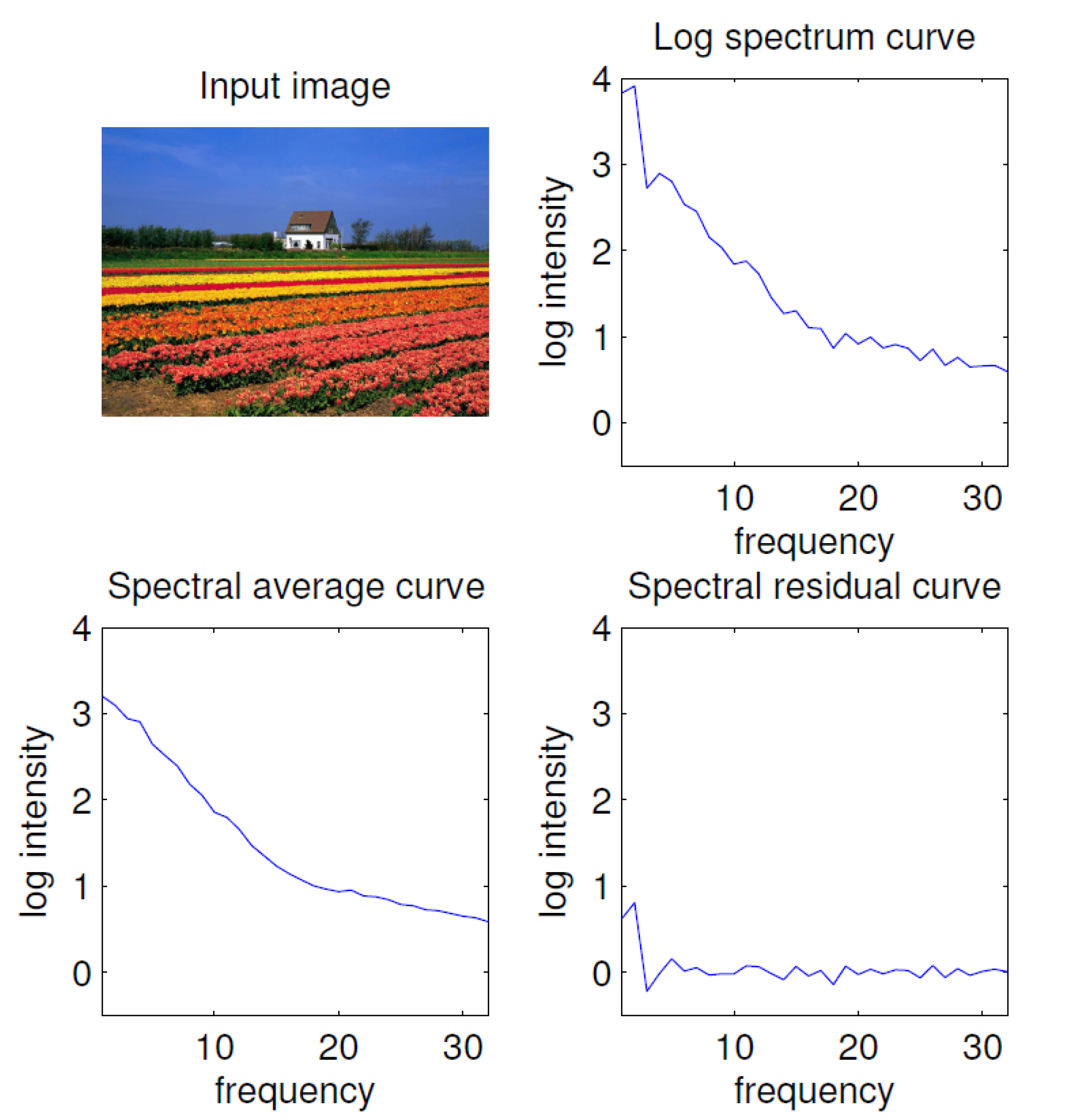
2.2. Spectral Residual-Based Saliency
2.3. Information Content-Based Saliency
3. Object Detection and Segmentation
3.1. Foreground Detection and Proto-Objects
3.2. Temporal Information and Object Tracking
3.3. Saliency in Active Contour Segmentation
3.4. Object Recognition, Classification, and Analysis
4. Navigation and Mapping
4.1. Entropy-Based Visual Attention for Localization & Mapping
4.2. Bottom-Up Visual Attention in Underwater Mapping
4.3. Visual Saliency through Data-Mining
5. Image Enhancement and Restoration
6. Resources and Benchmarking
7. Discussion and Conclusions
Funding
Conflicts of Interest
References
- Borji, A.; Itti, L. State-of-the-Art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 185–207. [Google Scholar] [CrossRef] [PubMed]
- Duntley, S.Q. Light in the sea. JOSA 1963, 53, 214–233. [Google Scholar] [CrossRef]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2011, 21, 1756–1769. [Google Scholar] [CrossRef] [PubMed]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Quo, J.; Pang, Y.; Chen, S.; Wang, J. Single underwater image restoration by blue-green channels dehazing and red channel correction. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1731–1735. [Google Scholar]
- Łuczyński, T.; Birk, A. Underwater image haze removal with an underwater-ready dark channel prior. In Proceedings of the IEEE OCEANS 2017-Anchorage, Anchorage, AK, USA, 18–21 September 2017; pp. 1–6. [Google Scholar]
- Richards, M.A.; Scheer, J.A.; Holm, W.A.; Beckley, B.; Mark, P.; Richards, A. (Eds.) Principles of Modern Radar: Basic Principles; Institution of Engineering and Technology: London, UK, 2010. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Frintrop, S.; Rome, E.; Christensen, H.I. Computational visual attention systems and their cognitive foundations: A survey. ACM Trans. Appl. Percept. (TAP) 2010, 7, 1–39. [Google Scholar] [CrossRef]
- Frintrop, S. Computational visual attention. In Computer Analysis of Human Behavior; Springer: Berlin, Germany, 2011; pp. 69–101. [Google Scholar]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Chen, Z.; Gao, H.; Zhang, Z.; Zhou, H.; Wang, X.; Tian, Y. Underwater salient object detection by combining 2d and 3d visual features. Neurocomputing 2020, 391, 249–259. [Google Scholar] [CrossRef]
- Marshall, J.; Carleton, K.L.; Cronin, T. Colour vision in marine organisms. Curr. Opin. Neurobiol. 2015, 34, 86–94. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Feng, H.; Yin, X.; Xu, L.; Lv, G.; Li, Q.; Wang, L. Underwater salient object detection jointly using improved spectral residual and Fuzzy c-Means. J. Intell. Fuzzy Syst. 2019, 37, 329–339. [Google Scholar] [CrossRef]
- Li, J.; Levine, M.D.; An, X.; Xu, X.; He, H. Visual saliency based on scale-space analysis in the frequency domain. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 996–1010. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ell, T.A. Quaternion-Fourier transforms for analysis of two-dimensional linear time-invariant partial differential systems. In Proceedings of the 32nd IEEE Conference on Decision and Control, San Antonio, TX, USA, 15–17 December 1993; pp. 1830–1841. [Google Scholar]
- Guo, C.; Zhang, L. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Trans. Image Process. 2009, 19, 185–198. [Google Scholar]
- Kadir, T.; Brady, M. Saliency, Scale and Image Description. Int. J. Comput. Vis. 2001, 45, 83–105. [Google Scholar] [CrossRef]
- Edgington, D.R.; Salamy, K.A.; Risi, M.; Sherlock, R.; Walther, D.; Koch, C. Automated event detection in underwater video. In Oceans 2003. Celebrating the Past... Teaming Toward the Future (IEEE Cat. No. 03CH37492); IEEE: New York, NY, USA, 2003; Volume 5, pp. P2749–P2753. [Google Scholar]
- Ahn, J.; Nishida, Y.; Ishii, K.; Ura, T. A Sea Creatures Classification Method using Convolutional Neural Networks. In Proceedings of the 2018 18th International Conference on Control, Automation and Systems (ICCAS), PyeongChang, Korea, 17–20 October 2018; pp. 420–423. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Atallah, L.; Shang, C.; Bates, R. Object detection at different resolution in archaeological side-scan sonar images. Eur. Ocean. 2005, 1, 287–292. [Google Scholar]
- Wang, H.; Dong, X.; Jie, S.; Wu, X.; Chen, Z. Saliency-Based Adaptive Object Extraction for Color Underwater Images. Appl. Mech. Mater. 2013, 347–350. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharyya Distance. Encyclopedia of Mathematics. 2020. Available online: http://encyclopediaofmath.org/index.php?title=Bhattacharyya_distance&oldid=46047 (accessed on 21 December 2020).
- Huo, G.; Wu, Z.; Li, J.; Li, S. Underwater Target Detection and 3D Reconstruction System Based on Binocular Vision. Sensors 2018, 18, 3570. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Wang, H.; Shen, J.; Dong, X. Underwater Object Detection by Combining the Spectral Residual and Three-Frame Algorithm. In Advances in Computer Science and its Applications; Jeong, H.Y., Obaidat, M.S., Yen, N.Y., Park, J.J.J.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1109–1114. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Kumar, N.; Sardana, H.; Shome, S.; Mittal, N. Saliency Subtraction Inspired Automated Event Detection in Underwater Environments. Cogn. Comput. 2019, 12. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: London, UK; Prentice Hall: Upper Saddle River, NY, USA, 2018. [Google Scholar]
- Underwater moving object detection by temporal information. Int. J. Recent Technol. Eng. (IJRTE) 2019, 8.
- Cong, Y.; Fan, B.; Hou, D.; Fan, H.; Liu, K.; Luo, J. Novel Event Analysis for Human-Machine Collaborative Underwater Exploration. Pattern Recognit. 2019, 96, 106967. [Google Scholar] [CrossRef]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Zhu, Y.; Hao, B.; Jiang, B.; Nian, R.; He, B.; Ren, X.; Lendasse, A. Underwater image segmentation with co-saliency detection and local statistical active contour model. In Proceedings of the OCEANS 2017-Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–5. [Google Scholar]
- Barat, C.; Phlypo, R. A fully automated method to detect and segment a manufactured object in an underwater color image. EURASIP J. Adv. Signal Process. 2010, 2010, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Kumar, N.; Sardana, H.; Shome, S. Saliency based shape extraction of objects in unconstrained underwater environment. Multimed. Tools Appl. 2018, 78. [Google Scholar] [CrossRef]
- Paragios, N.; Deriche, R. Geodesic active contours and level sets for the detection and tracking of moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 266–280. [Google Scholar] [CrossRef] [Green Version]
- Barnes, C.; Best, M.; Bornhold, B.; Juniper, S.; Pirenne, B.; Phibbs, P. The NEPTUNE Project-a cabled ocean observatory in the NE Pacific: Overview, challenges and scientific objectives for the installation and operation of Stage I in Canadian waters. In Proceedings of the IEEE 2007 Symposium on Underwater Technology and Workshop on Scientific Use of Submarine Cables and Related Technologies, Tokyo, Japan, 17–20 April 2007; pp. 308–313. [Google Scholar]
- Gebali, A.; Albu, A.B.; Hoeberechts, M. Detection of salient events in large datasets of underwater video. In Proceedings of the 2012 Oceans, Hampton Roads, VA, USA, 14–19 October 2012; pp. 1–10. [Google Scholar] [CrossRef]
- Chen, Z.; Sun, Y.; Gu, Y.; Wang, H.; Qian, H.; Zheng, H. Underwater Object Segmentation Integrating Transmission and Saliency Features. IEEE Access 2019, 7, 72420–72430. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Sathya, R.; Bharathi, M.; Dhivyasri, G. Underwater image enhancement by dark channel prior. In Proceedings of the IEEE 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015; pp. 1119–1123. [Google Scholar]
- Vese, L.A.; Chan, T.F. A multiphase level set framework for image segmentation using the Mumford and Shah model. Int. J. Comput. Vis. 2002, 50, 271–293. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, UK, 2007; pp. 545–552. [Google Scholar]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. Visual saliency detection with free energy theory. IEEE Signal Process. Lett. 2015, 22, 1552–1555. [Google Scholar] [CrossRef]
- Erdem, E.; Erdem, A. Visual saliency estimation by nonlinearly integrating features using region covariances. J. Vis. 2013, 13, 11–11. [Google Scholar] [CrossRef]
- Johnson-Roberson, M.; Pizarro, O.; Williams, S. Saliency ranking for benthic survey using underwater images. In Proceedings of the 2010 11th International Conference on Control Automation Robotics Vision, Singapore, 7–10 December 2010; pp. 459–466. [Google Scholar]
- Chuang, M.; Hwang, J.; Williams, K. A Feature Learning and Object Recognition Framework for Underwater Fish Images. IEEE Trans. Image Process. 2016, 25, 1862–1872. [Google Scholar] [CrossRef]
- Boom, B.J.; Huang, P.X.; He, J.; Fisher, R.B. Supporting ground-truth annotation of image datasets using clustering. In Proceedings of the IEEE 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1542–1545. [Google Scholar]
- Zhu, J.; Siquan, Y.; Han, Z.; Tang, Y.; Wu, C. Underwater Object Recognition Using Transformable Template Matching Based on Prior Knowledge. Math. Probl. Eng. 2019, 2019, 1–11. [Google Scholar] [CrossRef]
- Jian, M.; Qi, Q.; Dong, J.; Sun, X.; Sun, Y.; Lam, K.M. Saliency detection using quaternionic distance based weber local descriptor and level priors. Multimed. Tools Appl. 2018, 77, 14343–14360. [Google Scholar] [CrossRef]
- Lan, R.; Zhou, Y.; Tang, Y.Y. Quaternionic weber local descriptor of color images. IEEE Trans. Circuits Syst. Video Technol. 2015, 27, 261–274. [Google Scholar] [CrossRef]
- Jian, M.; Qi, Q.; Dong, J.; Yin, Y.; Lam, K.M. Integrating QDWD with pattern distinctness and local contrast for underwater saliency detection. J. Vis. Commun. Image Represent. 2018, 53, 31–41. [Google Scholar] [CrossRef]
- Margolin, R.; Tal, A.; Zelnik-Manor, L. What makes a patch distinct? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1139–1146. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H. Graph-regularized saliency detection with convex-hull-based center prior. IEEE Signal Process. Lett. 2013, 20, 637–640. [Google Scholar] [CrossRef]
- Harrison, R.; Birchall, R.; Mann, D.; Wang, W. A novel ensemble of distance measures for feature evaluation: Application to sonar imagery. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin, Germany, 2011; pp. 327–336. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Kim, A.; Eustice, R. Combined visually and geometrically informative link hypothesis for pose-graph visual SLAM using bag-of-words. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1647–1654. [Google Scholar] [CrossRef] [Green Version]
- Kim, A.; Eustice, R.M. Real-Time Visual SLAM for Autonomous Underwater Hull Inspection Using Visual Saliency. IEEE Trans. Robot. 2013, 29, 719–733. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Kim, A.; Eustice, R.M. Active visual SLAM for robotic area coverage: Theory and experiment. Int. J. Robot. Res. 2015, 34, 457–475. [Google Scholar] [CrossRef] [Green Version]
- Ozog, P.; Carlevaris-Bianco, N.; Kim, A.; Eustice, R. Long-term Mapping Techniques for Ship Hull Inspection and Surveillance using an Autonomous Underwater Vehicle. J. Field Robot. 2015, 24. [Google Scholar] [CrossRef] [Green Version]
- Geng, Y.; Wang, Z.; Shi, C.; Nian, R.; Zhang, C.; He, B.; Shen, Y.; Lendasse, A. Seafloor visual saliency evaluation for navigation with BoW and DBSCAN. In Proceedings of the OCEANS 2016-Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In KDD’96, Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Li, J.; Kaess, M.; Eustice, R.M.; Johnson-Roberson, M. Pose-Graph SLAM Using Forward-Looking Sonar. IEEE Robot. Autom. Lett. 2018, 3, 2330–2337. [Google Scholar] [CrossRef]
- Kaeli, J. Real-Time Anomaly Detection in Side-Scan Sonar Imagery for Adaptive AUV Missions. In Proceedings of the 2016 IEEE/OES Autonomous Underwater Vehicles (AUV), Tokyo, Japan, 6–9 November 2016; pp. 85–89. [Google Scholar] [CrossRef]
- Chailloux, C. Region of interest on sonar image for non symbolic registration. In Proceedings of the OCEANS 2005 MTS/IEEE, Washington, DC, USA, 17–23 September 2005; pp. 810–814. [Google Scholar]
- Harris, C.G.; Stephens, M. A combined corner and edge detector. In Proceedings of the Fourth Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar] [CrossRef]
- Chauvin, A.; Hérault, J.; Marendaz, C.; Peyrin, C. Natural scene perception: Visual attractors and image neural computation and psychology. In Connectionist Models of Cognition and Perception, Proceedings of the Seventh Neural Computation and Psychology Workshop, Brighton, UK, 17–19 September 2001; Bullinaria, J.A., Lowe, W., Eds.; World Scientific Publishing Co Pte Ltd.: Singapore, 2002. [Google Scholar]
- Chailloux, C.; Le Caillec, J.; Gueriot, D.; Zerr, B. Intensity-Based Block Matching Algorithm for Mosaicing Sonar Images. IEEE J. Ocean. Eng. 2011, 36, 627–645. [Google Scholar] [CrossRef]
- Mitchell, H.B. Image Fusion; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Fu, L.; Wang, Y.; Zhang, Z.; Nian, R.; Yan, T.; Lendasse, A. A shadow-removal based saliency map for point feature detection of underwater objects. In Proceedings of the OCEANS 2015-MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar]
- Zhang, L.; He, B.; Song, Y.; Yan, T. Underwater image feature extraction and matching based on visual saliency detection. In Proceedings of the OCEANS 2016-Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–4. [Google Scholar]
- Johnson-Roberson, M.; Bryson, M.; Douillard, B.; Pizarro, O.; Williams, S. Crowdsourced Saliency for Mining Robotically Gathered 3D Maps Using Multitouch Interaction on Smartphones and Tablets. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 31 May–5 June 2014; IEEE: New York, NY, USA, 2014; pp. 6032–6039. [Google Scholar] [CrossRef]
- Johnson-Roberson, M.; Bryson, M.; Douillard, B.; Pizarro, O.; Williams, S. Discovering salient regions on 3D photo-textured maps: Crowdsourcing interaction data from multitouch smartphones and tablets. Comput. Vis. Image Underst. 2015, 131, 28–41. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Fang, S.; Deng, R.; Cao, Y.; Fang, C. Effective Single Underwater Image Enhancement by Fusion. J. Comput. 2013, 8. [Google Scholar] [CrossRef]
- Singh, R.; Biswas, M. Adaptive histogram equalization based fusion technique for hazy underwater image enhancement. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Tamil Nadu, India, 15–17 December 2016; pp. 1–5. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; De Vleeschouwer, C.; Garcia, R.; Bovik, A.C. Multi-scale underwater descattering. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 4202–4207. [Google Scholar]
- Wang, J.; Wang, H.; Gao, G.; Lu, H.; Zhang, Z. Single Underwater Image Enhancement Based on Lp-norm Decomposition. IEEE Access 2019, 1. [Google Scholar] [CrossRef]
- Forbes, T.; Goldsmith, M.; Mudur, S.; Poullis, C. DeepCaustics: Classification and Removal of Caustics From Underwater Imagery. IEEE J. Ocean. Eng. 2019, 44, 728–738. [Google Scholar] [CrossRef]
- Autodesk Maya. 2020. Available online: https://www.autodesk.com/products/maya/ (accessed on 21 December 2020).
- Zhang, H.; Li, S.; Chen, W.; Liu, Y. The Influence of Different Saliency on Full-Reference Sonar Image Quality Evaluation. IOP Conf. Ser. Mater. Sci. Eng. 2019, 569, 052093. [Google Scholar] [CrossRef]
- Liu, T.; Sun, J.; Zheng, N.; Tang, X.; Shum, H. Learning to Detect A Salient Object. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Jian, M.; Qi, Q.; Dong, J.; Yin, Y.; Zhang, W.; Lam, K.M. The OUC-vision large-scale underwater image database. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1297–1302. [Google Scholar]
- Jian, M.; Qi, Q.; Yu, H.; Dong, J.; Cui, C.; Nie, X.; Zhang, H.; Yin, Y.; Lam, K.M. The extended marine underwater environment database and baseline evaluations. Appl. Soft Comput. 2019, 80, 425–437. [Google Scholar] [CrossRef]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M.H. Saliency detection via dense and sparse reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 2976–2983. [Google Scholar]
- Tong, N.; Lu, H.; Zhang, L.; Ruan, X. Saliency detection with multi-scale superpixels. IEEE Signal Process. Lett. 2014, 21, 1035–1039. [Google Scholar]
- Qin, Y.; Lu, H.; Xu, Y.; Wang, H. Saliency detection via cellular automata. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 110–119. [Google Scholar]
- Jian, M.; Qi, Q. Underwater Images Part A. 2019. Available online: https://zenodo.org/record/2542305#.X-INxNhKiUk (accessed on 21 December 2020).
- Jian, M.; Qi, Q. Underwater Images Part B. 2019. Available online: https://zenodo.org/record/2542307#.X-INxdhKiUk (accessed on 21 December 2020).
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cui, Z.; Wu, J.; Yu, H.; Zhou, Y.; Liang, L. Underwater Image Saliency Detection Based on Improved Histogram Equalization. In International Conference of Pioneering Computer Scientists, Engineers and Educators; Springer: Berlin, Germany, 2019; pp. 157–165. [Google Scholar]
- Boom, B.J.; He, J.; Palazzo, S.; Huang, P.X.; Beyan, C.; Chou, H.M.; Lin, F.P.; Spampinato, C.; Fisher, R.B. A research tool for long-term and continuous analysis of fish assemblage in coral-reefs using underwater camera footage. Ecol. Inform. 2014, 23, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Yu, Y. Visual saliency detection based on multiscale deep CNN features. IEEE Trans. Image Process. 2016, 25, 5012–5024. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, K.; Gao, S. Image saliency detection via multi-scale iterative CNN. Vis. Comput. 2020, 36, 1355–1367. [Google Scholar] [CrossRef]
- Sanchez-Torres, G.; Ceballos-Arroyo, A.; Robles-Serrano, S. Automatic measurement of fish weight and size by processing underwater hatchery images. Eng. Lett. 2018, 26, 461–472. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | Purpose | Saliency Model | Data | Evaluation | |||
|---|---|---|---|---|---|---|---|---|
| RGB Images | Video | Acoustic Data | Real | Synthetic | ||||
| Object Detection and Segmentation | ||||||||
| Edgington et al. [20] | 2003 | Object detection | Itti | ✓ | ✓ | |||
| Ahn et al. [21] | 2018 | Object detection and CNN-based classification | Itti | ✓ | ✓ | |||
| Atallah et al. [23] | 2005 | Object detection | Entropy-based | ✓ | ✓ | |||
| Wang et al. [24] | 2013 | Detection & Segmentation | Itti | ✓ | ✓ | |||
| Chen et al. [27] | 2014 | Object detection | Spectral residual | ✓ | ✓ | |||
| Chuang et al. [48] | 2016 | Initialization of object recognition | Phase Fourier Transform | ✓ | ✓ | |||
| Zhu et al. [34] | 2017 | Detection & Segmentation | Saliency map based on contrast, position, and correspondence | ✓ | ✓ | |||
| Sanchrez-Torres et al. [99] | 2018 | Segmentation | Ad hoc based on morphological operators | ✓ | ✓ | |||
| Huo et al. [26] | 2018 | Detection & 3D Reconstruction | Aggregation of salient superpixels | ✓ | ✓ | |||
| Kumar et al. [36] | 2019 | Shape reconstruction using edge-based active contours | Itti | ✓ | ✓ | ✓ | ||
| Chen et al. [40] | 2019 | Segmentation using region-based active contours | HFT | ✓ | ✓ | |||
| Barat et al. [35] | 2010 | Segmentation using active contours featuring saliency in initialization | Itti | ✓ | ✓ | |||
| Kumar et al. [31] | 2019 | Moving object detection | Multiple frames difference | ✓ | ✓ | |||
| Zhu et al. [50] | 2019 | Template Matching | Spectral residual | ✓ | ✓ | |||
| Jian et al. [51] | 2018 | Object detection | QDWB | ✓ | ✓ | |||
| Jian et al. [53] | 2018 | Object detection | QDWB + PD + LC | ✓ | ✓ | |||
| Johnson-Roberson et al. [47] | 2010 | Classification | Entropy-based | ✓ | ✓ | |||
| Cong et al. [32] | 2019 | Saliency-based Object Detection | Saliency map obtained by Deep Convolutional Neural Network | ✓ | ✓ | ✓ | ||
| Harrison et al. [56] | 2011 | Texture segmentation | Co-occurence matrices and ensemble of distance | ✓ | ✓ | |||
| Navigation and Mapping | ||||||||
| Kim et al. [58] | 2011 | Navigation & Mapping through Local/Global Saliency estimation | Entropy-based | ✓ | ✓ | ✓ | ||
| Kim et al. [59] | 2013 | Navigation & Mapping through Local/Global Saliency estimation | Entropy-based | ✓ | ✓ | ✓ | ||
| Kim et al. [62] | 2015 | Navigation & Mapping through Local/Global Saliency estimation | Entropy-based | ✓ | ✓ | ✓ | ||
| Ozog et al. [63] | 2015 | Navigation & Mapping through Local/Global Saliency estimation | Entropy-based | ✓ | ✓ | ✓ | ||
| Geng et al. [64] | 2016 | Navigation & Mapping | Entropy-based | ✓ | ✓ | |||
| Li et al. [66] | 2018 | Simultaneous Localization and Mapping | Entropy-based | ✓ | ✓ | |||
| Johnson-Roberson et al. [75] | 2014 | Saliency Estimation through Crowdsourcing | Gaze-tracking & Hidden Markov Model estimation | ✓ | ✓ | |||
| Johnson-Roberson et al. [76] | 2015 | Saliency Estimation through Crowdsourcing | Gaze-tracking & Hidden Markov Model estimation | ✓ | ✓ | |||
| Kaeli et al. [67] | 2016 | Anomaly detection | Entropy-based | ✓ | ✓ | |||
| Kumar et al. [29] | 2019 | Saliency estimation for object detection | Itti | ✓ | ✓ | |||
| Chailloux [68] | 2005 | Image registration based on landmarks | Ittis’ model variation | ✓ | ✓ | |||
| Chailloux et al. [71] | 2011 | Saliency estimation for large scale mapping | Itti | ✓ | ✓ | |||
| Fu et al. [73] | 2015 | Saliency estimation for feature point detection | Local contrast | ✓ | ✓ | |||
| Zhang et al. [74] | 2016 | Feature point detection and matching | HFT | ✓ | ✓ | |||
| Image Enhancement and Restoration | ||||||||
| Achanta et al. [78] | 2009 | Salient region detection | Difference of Gaussian-based band pass filtering | ✓ | ✓ | |||
| Fang et al. [79] | 2013 | Underwater Image restoration | Difference of Gaussian-based band pass filtering | ✓ | ✓ | |||
| Singh et al. [80] | 2016 | Underwater Image restoration | Difference of Gaussian-based band pass filtering | ✓ | ✓ | |||
| Ancuti et al. [81] | 2016 | Underwater Image restoration | Salient region detection | ✓ | ✓ | |||
| Jianhua et al. [82] | 2019 | Underwater Image restoration | Salient region detection | ✓ | ✓ | |||
| Forbes et al. [83] | 2019 | Image restoration | Convolutional neural network-based saliency estimation | ✓ | ✓ | ✓ | ||
| Zhang et al. [85] | 2019 | Image Quality Evaluation | Several models are employed | ✓ | ✓ | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reggiannini, M.; Moroni, D. The Use of Saliency in Underwater Computer Vision: A Review. Remote Sens. 2021, 13, 22. https://doi.org/10.3390/rs13010022
Reggiannini M, Moroni D. The Use of Saliency in Underwater Computer Vision: A Review. Remote Sensing. 2021; 13(1):22. https://doi.org/10.3390/rs13010022
Chicago/Turabian StyleReggiannini, Marco, and Davide Moroni. 2021. "The Use of Saliency in Underwater Computer Vision: A Review" Remote Sensing 13, no. 1: 22. https://doi.org/10.3390/rs13010022
APA StyleReggiannini, M., & Moroni, D. (2021). The Use of Saliency in Underwater Computer Vision: A Review. Remote Sensing, 13(1), 22. https://doi.org/10.3390/rs13010022