Figure 1.
Cropped image and ground truth checking for UOPNOA. (a) cropped image of 256 × 256 pixels from a PNOA image, (b) SIGPAC visor of the same region to check the ground truth mask, (c) ground truth mask.
Figure 1.
Cropped image and ground truth checking for UOPNOA. (a) cropped image of 256 × 256 pixels from a PNOA image, (b) SIGPAC visor of the same region to check the ground truth mask, (c) ground truth mask.
Figure 2.
Number of pixels for each class of the dataset UOPNOA.
Figure 2.
Number of pixels for each class of the dataset UOPNOA.
Figure 3.
Cropped image and ground truth checking for UOS2. (a) cropped image of 256 × 256 pixels from a Sentinel-2 image, (b) SIGPAC visor of the same region, (c) ground truth mask.
Figure 3.
Cropped image and ground truth checking for UOS2. (a) cropped image of 256 × 256 pixels from a Sentinel-2 image, (b) SIGPAC visor of the same region, (c) ground truth mask.
Figure 4.
Number of pixels for each class of the dataset UOS2.
Figure 4.
Number of pixels for each class of the dataset UOS2.
Figure 5.
UNet architecture. This diagram is based on the original UNet publication [
20].
Figure 5.
UNet architecture. This diagram is based on the original UNet publication [
20].
Figure 6.
DeepLabV3+ architecture. A backbone network such as ResNet-101 or Xception65 can be used as DCNN. This diagram is based on the original DeepLabV3+ publication [
21].
Figure 6.
DeepLabV3+ architecture. A backbone network such as ResNet-101 or Xception65 can be used as DCNN. This diagram is based on the original DeepLabV3+ publication [
21].
Figure 7.
Loss function for the “Base” experiment with DeepLabV3+ for PNOA.
Figure 7.
Loss function for the “Base” experiment with DeepLabV3+ for PNOA.
Figure 8.
Visualization of the predicted results for DeepLabV3+ evaluated in UOPNOA (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 8.
Visualization of the predicted results for DeepLabV3+ evaluated in UOPNOA (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 9.
Visualization of the predicted results for DeepLabV3+ evaluated in UOPNOA with “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 9.
Visualization of the predicted results for DeepLabV3+ evaluated in UOPNOA with “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 10.
Loss function for the “Base” experiment with UNet for PNOA.
Figure 10.
Loss function for the “Base” experiment with UNet for PNOA.
Figure 11.
Visualization of the predicted results for UNet evaluated in UOPNOA (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 11.
Visualization of the predicted results for UNet evaluated in UOPNOA (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 12.
Visualization of the predicted results for UNet evaluated in UOPNOA with “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 12.
Visualization of the predicted results for UNet evaluated in UOPNOA with “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 13.
Loss function for the “Base” experiment with UNet for UOS2.
Figure 13.
Loss function for the “Base” experiment with UNet for UOS2.
Figure 14.
Visualization of the predicted results for UNet evaluated in UOS2 (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 14.
Visualization of the predicted results for UNet evaluated in UOS2 (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 15.
Visualization of the predicted results for UNet evaluated in UOS2 with “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 15.
Visualization of the predicted results for UNet evaluated in UOS2 with “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 16.
Loss function for the “Base” experiment with UNet for UOS2 with simplified classes.
Figure 16.
Loss function for the “Base” experiment with UNet for UOS2 with simplified classes.
Figure 17.
Visualization of the predicted results for UNet evaluated in UOS2 for four classes (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 17.
Visualization of the predicted results for UNet evaluated in UOS2 for four classes (Experiment Base). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 18.
Visualization of the predicted results for UNet evaluated in UOS2 with four classes and “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 18.
Visualization of the predicted results for UNet evaluated in UOS2 with four classes and “Other” class (Experiment All-Purpose). (1st col.) Original images, (2nd col.) ground truth masks, (3rd col.) predictions, (4th col.) overlapping of original images with ground truth masks, (5th col.) overlapping of original images with predictions.
Figure 19.
Performance in seconds per infrastructure.
Figure 19.
Performance in seconds per infrastructure.
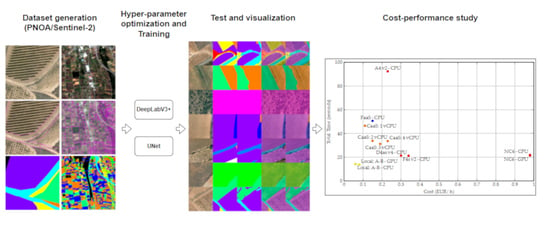
Figure 20.
Cost performance per infrastructure. Prices and the computing power are subject to change (April 2021).
Figure 20.
Cost performance per infrastructure. Prices and the computing power are subject to change (April 2021).
Table 1.
Bands from PNOA.
Table 1.
Bands from PNOA.
| Bands | GSD (m/pixel) | Bits |
|---|
| B1 Red | 0.25 | 8 |
| B2 Green | 0.25 | 8 |
| B3 Blue | 0.25 | 8 |
| B4 NIR | 0.25 | 8 |
Table 2.
Number of SIGPAC plots and pixels for each class used in UOPNOA.
Table 2.
Number of SIGPAC plots and pixels for each class used in UOPNOA.
| Class | Plots | # of Pixels |
|---|
| UN | 410 | 8,095,351 |
| PA | 1883 | 46,738,269 |
| SH | 3467 | 168,342,415 |
| FO | 472 | 73,980,816 |
| BU | 125 | 7,562,696 |
| AR | 4935 | 968,106,602 |
| GR | 220 | 93,208,409 |
| RO | 943 | 67,552,872 |
| WA | 340 | 19,776,364 |
| FR | 93 | 4,150,529 |
| VI | 1759 | 163,774,218 |
Table 3.
Bands from Sentinel-2A and Sentinel-2B.
Table 3.
Bands from Sentinel-2A and Sentinel-2B.
| Band | Wavelength (nm) | Bandwidth (nm) | GSD (m/pixel) |
|---|
| B1 Coastal aerosol | 442.7/442.2 | 21/21 | 60 |
| B2 Blue | 492.4/492.1 | 66/66 | 10 |
| B3 Green | 559.8/559.0 | 36/36 | 10 |
| B4 Red | 664.6/664.9 | 31/31 | 10 |
| B5 VRE | 704.1/703.8 | 15/16 | 20 |
| B6 VRE | 740.5/739.1 | 15/15 | 20 |
| B7 VRE | 782.8/779.7 | 20/20 | 20 |
| B8 NIR | 832.8/832.9 | 106/106 | 10 |
| B8A Narrow NIR | 864.7/864.0 | 21/22 | 20 |
| B9 Water vapour | 945.1/943.2 | 20/21 | 60 |
| B10 SWIR Cirrus | 1374.0/1376.9 | 31/30 | 60 |
| B11 WIR | 1614.0/1610.4 | 91/94 | 20 |
| B12 SWIR | 2202.0/2185.7 | 175/185 | 20 |
Table 4.
Number of SIGPAC plots used in UOPNOA.
Table 4.
Number of SIGPAC plots used in UOPNOA.
| Class | Plots | # of Pixels |
|---|
| UN | 26,912 | 1,455,995 |
| PA | 152,359 | 5,591,140 |
| SH | 265,046 | 16,465,578 |
| FO | 48,977 | 10,746,146 |
| BU | 207,839 | 1,047,900 |
| AR | 772,427 | 60,046,203 |
| GR | 28,649 | 4,494,801 |
| RO | 73,250 | 3,719,742 |
| WA | 16,802 | 1,733,641 |
| FR | 6306 | 566,355 |
| VI | 87,071 | 4,126,803 |
Table 5.
Global metrics for the experiments with RF and SVM on UOPNOA.
Table 5.
Global metrics for the experiments with RF and SVM on UOPNOA.
| Experiment | OA | PA | UA | IoU | F1 |
|---|
| RF | 0.074 | 0.114 | 0.130 | 0.034 | 0.121 |
| SVM | 0.073 | 0.138 | 0.130 | 0.035 | 0.134 |
Table 6.
Network parameters for DeepLabV3+ on UOPNOA.
Table 6.
Network parameters for DeepLabV3+ on UOPNOA.
| Network Parameters |
|---|
| Input size | 256 × 256 × 3 |
| Classes | 11 |
| Backbone network | Xception41 |
| Output stride | 16 |
| Padding | Yes |
| Class balancing | Median frequency weighting |
Table 7.
Training parameters for DeepLabV3+ on UOPNOA.
Table 7.
Training parameters for DeepLabV3+ on UOPNOA.
| Training Parameters |
|---|
| Solver | Adam |
| Epochs | 60 |
| Fine Tune Batch Normalization | No |
| Batch size | 12 |
| Learning rate | 0.00005 |
| Gradient clipping | No |
| L2 regularization | 0.0004 |
| Shuffle | Yes |
| Data augmenting | No |
Table 8.
Global metrics for the experiment with DeepLabV3+ on UOPNOA.
Table 8.
Global metrics for the experiment with DeepLabV3+ on UOPNOA.
| Experiment | OA | PA | UA | IoU | F1 |
|---|
| Base | 0.898 | 0.781 | 0.758 | 0.637 | 0.769 |
| All-Purpose | 0.750 | 0.678 | 0.678 | 0.524 | 0.678 |
Table 9.
Class metrics for the experiment with DeepLabV3+ on UOPNOA.
Table 9.
Class metrics for the experiment with DeepLabV3+ on UOPNOA.
| | Experiment Base | Experiment All-Purpose |
|---|
| Class | PA | UA | IoU | PA | UA | IoU |
|---|
| UN | 0.56 | 0.66 | 0.43 | 0.65 | 0.63 | 0.47 |
| PA | 0.79 | 0.78 | 0.65 | 0.55 | 0.48 | 0.27 |
| SH | 0.58 | 0.53 | 0.38 | 0.38 | 0.39 | 0.30 |
| FO | 0.84 | 0.84 | 0.73 | 0.63 | 0.68 | 0.49 |
| BU | 0.85 | 0.86 | 0.76 | 0.78 | 0.75 | 0.62 |
| AR | 0.94 | 0.97 | 0.92 | 0.76 | 0.82 | 0.65 |
| GR | 0.75 | 0.89 | 0.69 | 0.81 | 0.87 | 0.72 |
| RO | 0.84 | 0.60 | 0.54 | 0.82 | 0.75 | 0.65 |
| WA | 0.77 | 0.47 | 0.41 | 0.75 | 0.52 | 0.44 |
| FR | 0.66 | 0.73 | 0.53 | 0.46 | 0.56 | 0.34 |
| VI | 0.96 | 0.95 | 0.92 | 0.62 | 0.77 | 0.53 |
| OT | - | - | - | 0.86 | 0.86 | 0.76 |
Table 10.
Network parameters for UNet on UOPNOA.
Table 10.
Network parameters for UNet on UOPNOA.
| Network Parameters |
|---|
| Input size | 256 × 256 × 3 |
| Classes | 11 |
| Depth | 4 |
| Filters on first level | 64 |
| Padding | Yes |
| Class balancing | Median frequency weighting |
Table 11.
Training parameters for UNet on UOPNOA.
Table 11.
Training parameters for UNet on UOPNOA.
| Training Parameters |
|---|
| Solver | Adam |
| Epochs | 20 |
| Batch size | 16 |
| Learning rate | 0.0001 |
| Gradient clipping | 1.0 |
| L2 regularization | 0.0001 |
| Shuffle | Yes |
| Data augmenting | No |
Table 12.
Global metrics for the experiment with UNet on UOPNOA.
Table 12.
Global metrics for the experiment with UNet on UOPNOA.
| Experiment | OA | PA | UA | IoU | F1 |
|---|
| Base | 0.830 | 0.618 | 0.473 | 0.473 | 0.536 |
| All-Purpose | 0.641 | 0.607 | 0.391 | 0.391 | 0.476 |
Table 13.
Class metrics for the experiment with UNet on UOPNOA.
Table 13.
Class metrics for the experiment with UNet on UOPNOA.
| | Experiment Base | Experiment All-Purpose |
|---|
| Class | PA | UA | IoU | PA | UA | IoU |
|---|
| UN | 0.45 | 0.29 | 0.21 | 0.40 | 0.23 | 0.17 |
| PA | 0.54 | 0.25 | 0.20 | 0.36 | 0.21 | 0.15 |
| SH | 0.69 | 0.62 | 0.49 | 0.64 | 0.51 | 0.39 |
| FO | 0.21 | 0.78 | 0.20 | 0.52 | 0.63 | 0.40 |
| BU | 0.59 | 0.92 | 0.56 | 0.71 | 0.62 | 0.49 |
| AR | 0.93 | 0.96 | 0.90 | 0.88 | 0.75 | 0.68 |
| GR | 0.62 | 0.70 | 0.49 | 0.67 | 0.59 | 0.46 |
| RO | 0.77 | 0.51 | 0.45 | 0.79 | 0.37 | 0.34 |
| WA | 0.60 | 0.43 | 0.34 | 0.63 | 0.30 | 0.26 |
| FR | 0.45 | 0.92 | 0.43 | 0.54 | 0.70 | 0.44 |
| VI | 0.90 | 0.97 | 0.88 | 0.95 | 0.76 | 0.74 |
| OT | - | - | - | 0.15 | 0.47 | 0.13 |
Table 14.
Network parameters for UNet on UOS2.
Table 14.
Network parameters for UNet on UOS2.
| Network Parameters |
|---|
| Input size | 256 × 256 × 10 |
| Classes | 11 |
| Depth | 4 |
| Filters on first level | 32 |
| Padding | Yes |
| Class weighting | Median frequency |
Table 15.
Training parameters for UNet on UOS2.
Table 15.
Training parameters for UNet on UOS2.
| Training Parameters |
|---|
| Solver | Adam |
| Epochs | 125 |
| Batch size | 32 |
| Learning rate | 0.0005 |
| Gradient clipping | 1.0 |
| L2 regularization | 0.0001 |
| Shuffle | Yes |
| Data augmenting | Yes (Mirroring on both axes) |
Table 16.
Global metrics for the experiment with UNet on UOS2.
Table 16.
Global metrics for the experiment with UNet on UOS2.
| Experiment | OA | PA | UA | IoU | F1 |
|---|
| Base | 0.647 | 0.569 | 0.428 | 0.323 | 0.489 |
| All-Purpose | 0.527 | 0.521 | 0.364 | 0.259 | 0.429 |
| RGB | 0.585 | 0.090 | 0.079 | 0.053 | 0.084 |
| ME | 0.570 | 0.091 | 0.109 | 0.052 | 0.099 |
| 6 bands | 0.569 | 0.480 | 0.373 | 0.252 | 0.420 |
| 13 bands | 0.589 | 0.463 | 0.371 | 0.261 | 0.412 |
Table 17.
Class metrics for the experiment with UNet on UOS2.
Table 17.
Class metrics for the experiment with UNet on UOS2.
| | Experiment Base | Experiment All-Purpose |
|---|
| Class | PA | UA | IoU | PA | UA | IoU |
|---|
| UN | 0.56 | 0.22 | 0.19 | 0.51 | 0.22 | 0.18 |
| PA | 0.42 | 0.28 | 0.20 | 0.46 | 0.21 | 0.17 |
| SH | 0.36 | 0.67 | 0.30 | 0.37 | 0.54 | 0.28 |
| FO | 0.59 | 0.60 | 0.43 | 0.52 | 0.48 | 0.34 |
| BU | 0.81 | 0.50 | 0.45 | 0.74 | 0.39 | 0.34 |
| AR | 0.77 | 0.94 | 0.73 | 0.69 | 0.85 | 0.62 |
| GR | 0.62 | 0.37 | 0.30 | 0.58 | 0.28 | 0.23 |
| RO | 0.36 | 0.16 | 0.12 | 0.40 | 0.13 | 0.11 |
| WA | 0.61 | 0.22 | 0.19 | 0.63 | 0.17 | 0.16 |
| FR | 0.34 | 0.10 | 0.08 | 0.45 | 0.08 | 0.07 |
| VI | 0.78 | 0.59 | 0.51 | 0.76 | 0.56 | 0.48 |
| OT | - | - | - | 0.09 | 0.38 | 0.08 |
Table 18.
Network parameters for UNet with simplified classes on UOS2.
Table 18.
Network parameters for UNet with simplified classes on UOS2.
| Network Parameters |
|---|
| Input size | 256 × 256 × 10 |
| Classes | 4 |
| Depth | 4 |
| Filters on first level | 32 |
| Padding | Yes |
| Class weighting | Median frequency |
Table 19.
Training parameters for UNet with simplified classes on UOS2.
Table 19.
Training parameters for UNet with simplified classes on UOS2.
| Training Parameters |
|---|
| Solver | Adam |
| Epochs | 125 |
| Batch size | 32 |
| Learning rate | 0.0005 |
| Gradient clipping | No |
| L2 regularization | No |
| Shuffle | Yes |
Table 20.
Global metrics for the experiment with UNet with simplified classes on UOS2.
Table 20.
Global metrics for the experiment with UNet with simplified classes on UOS2.
| Experiment | OA | PA | UA | IoU | F1 |
|---|
| Base | 0.822 | 0.786 | 0.677 | 0.576 | 0.727 |
| All-Purpose | 0.650 | 0.639 | 0.578 | 0.402 | 0.607 |
Table 21.
Class metrics for the experiment with UNet with simplified classes on UOS2. These classes consist of PASHGR (PA + SH + GR—all pastures), BURO (BU + RO—all infrastructures), ARVI (AR + VI—arable lands and vineyards), and OT.
Table 21.
Class metrics for the experiment with UNet with simplified classes on UOS2. These classes consist of PASHGR (PA + SH + GR—all pastures), BURO (BU + RO—all infrastructures), ARVI (AR + VI—arable lands and vineyards), and OT.
| | Experiment Base | Experiment All-Purpose |
|---|
| Class | PA | UA | IoU | PA | UA | IoU |
|---|
| PASHGR | 0.82 | 0.81 | 0.69 | 0.71 | 0.52 | 0.43 |
| BURO | 0.70 | 0.25 | 0.23 | 0.70 | 0.17 | 0.16 |
| ARVI | 0.83 | 0.95 | 0.80 | 0.77 | 0.85 | 0.68 |
| OT | - | - | - | 0.36 | 0.75 | 0.21 |


 ,
, 




































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}