
Identifying Optimal Wavelengths as Disease Signatures Using Hyperspectral Sensor and Machine Learning

 ,
,  and
and
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Plant Materials
2.2. Pathogen and Inoculation
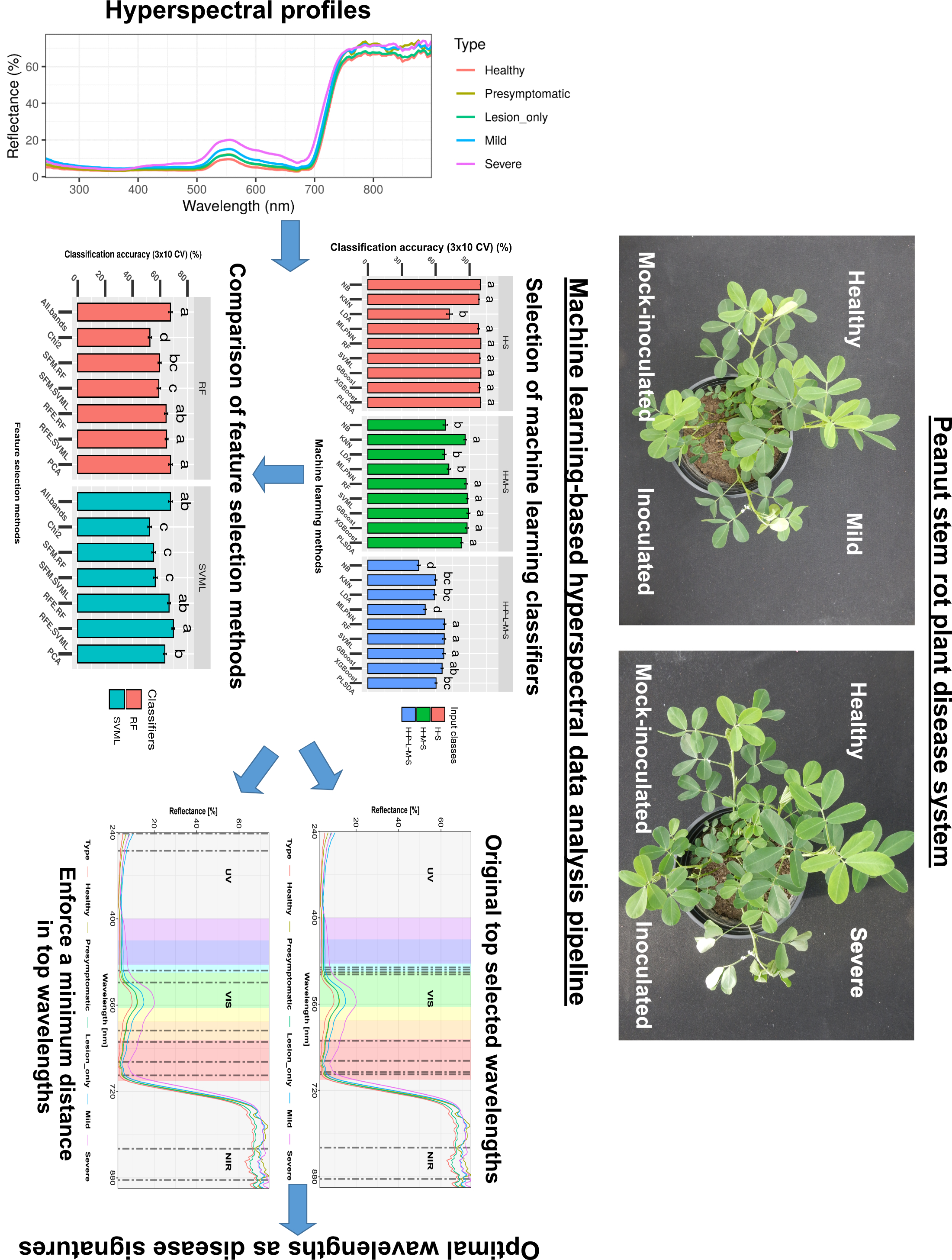
2.3. Experimental Setup
2.4. Stem Rot Severity Rating and Categorization
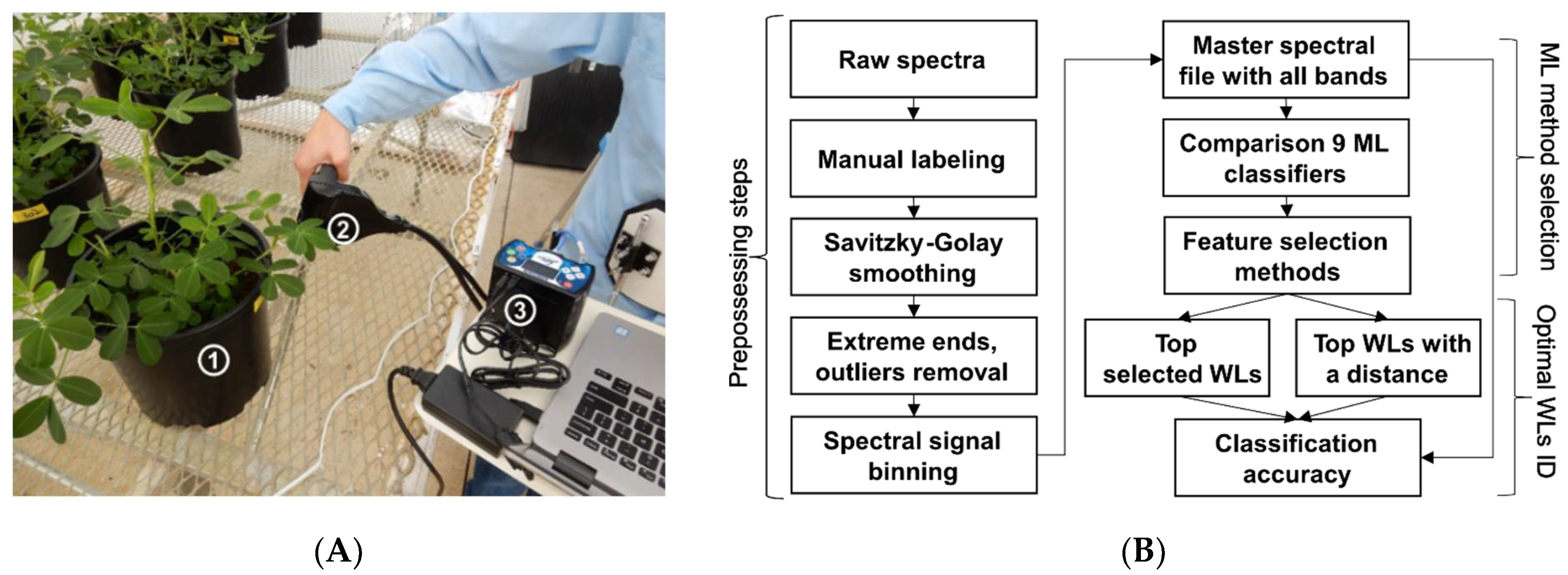
2.5. Spectral Reflectance Measurement
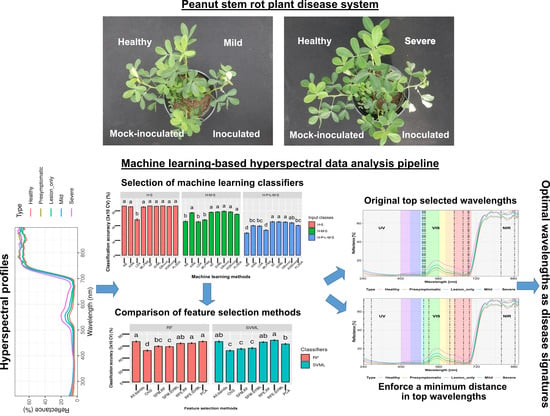
2.6. Data Analysis Pipeline
2.6.1. Data Preparation
2.6.2. Preprocessing of Raw Spectrum Files
2.6.3. Comparison of Machine Learning Methods for Classification
2.6.4. Comparison of Feature Selection Methods
2.6.5. Statistical Tests for Model Comparisons
3. Results
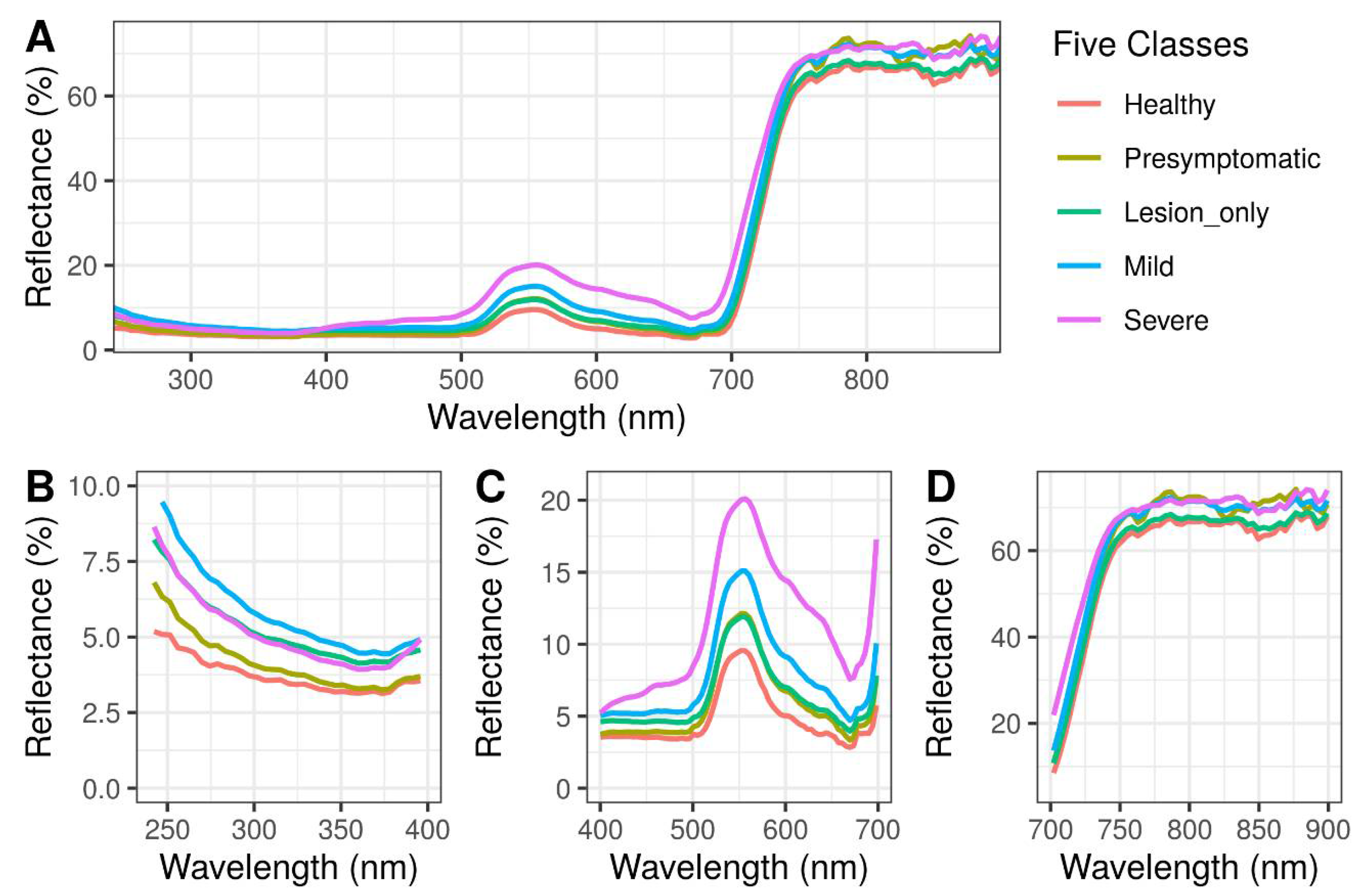
3.1. Spectral Reflectance Curves
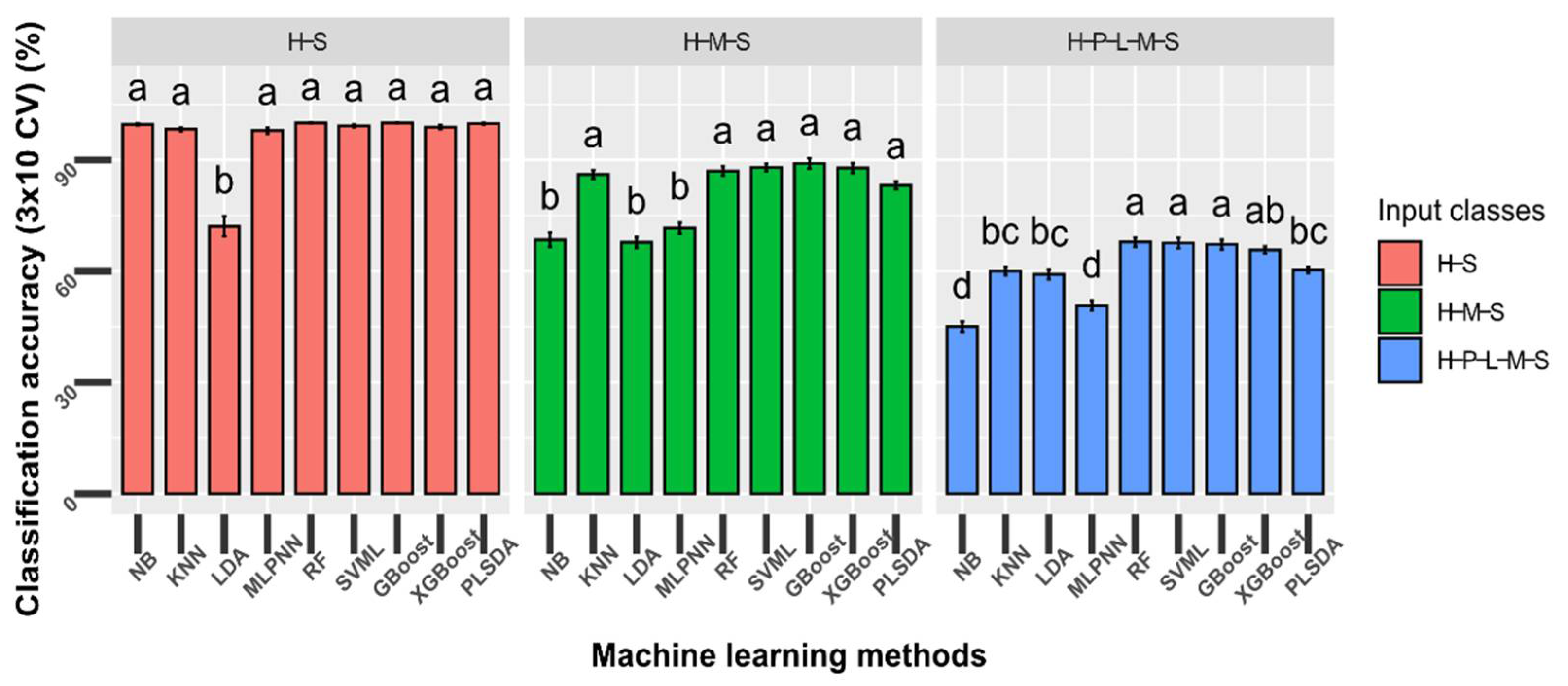
3.2. Classification Analysis
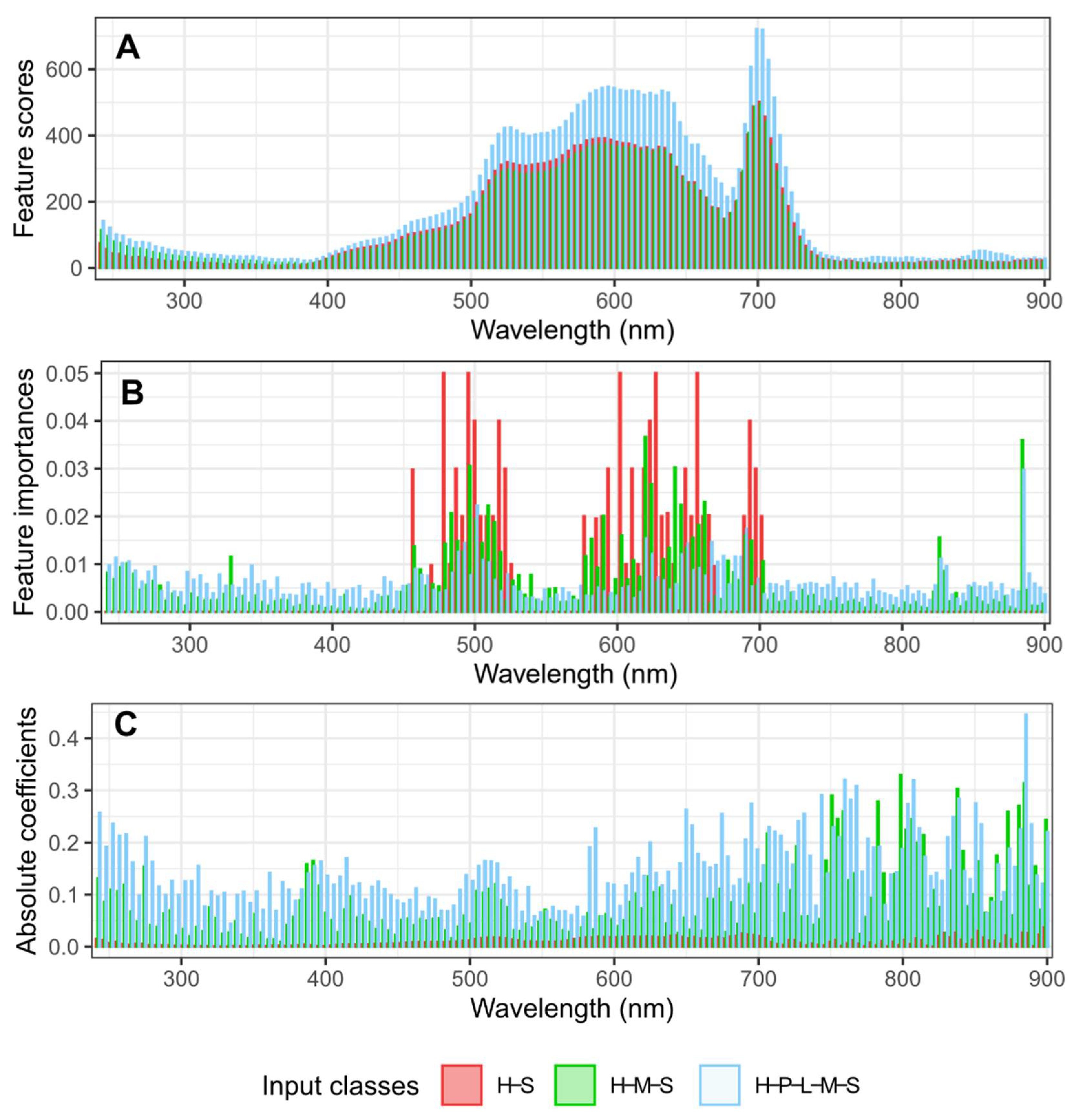
3.3. Feature Weights Calculated by Different Methods
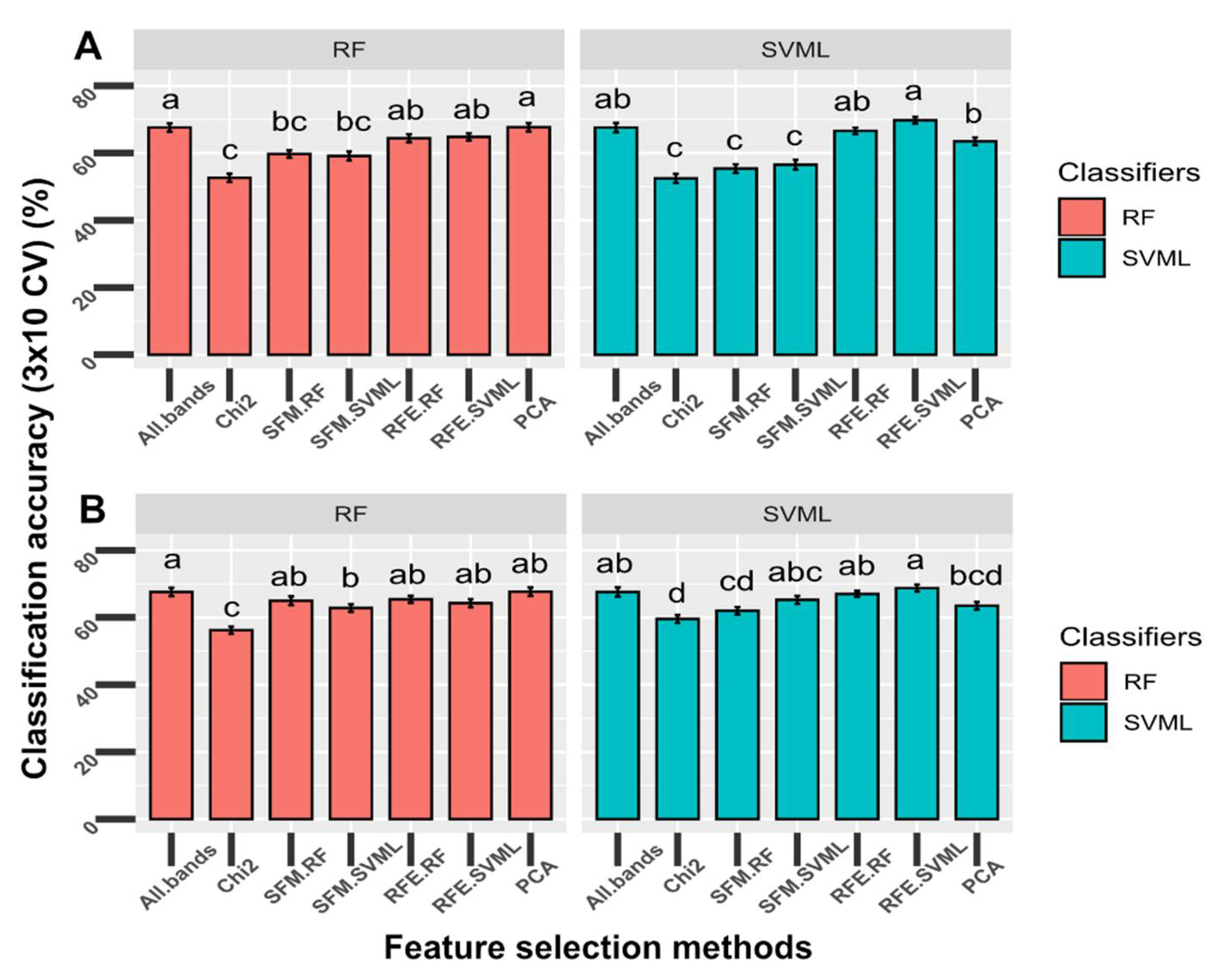
3.4. Dimension Reduction and Feature Selection Analysis
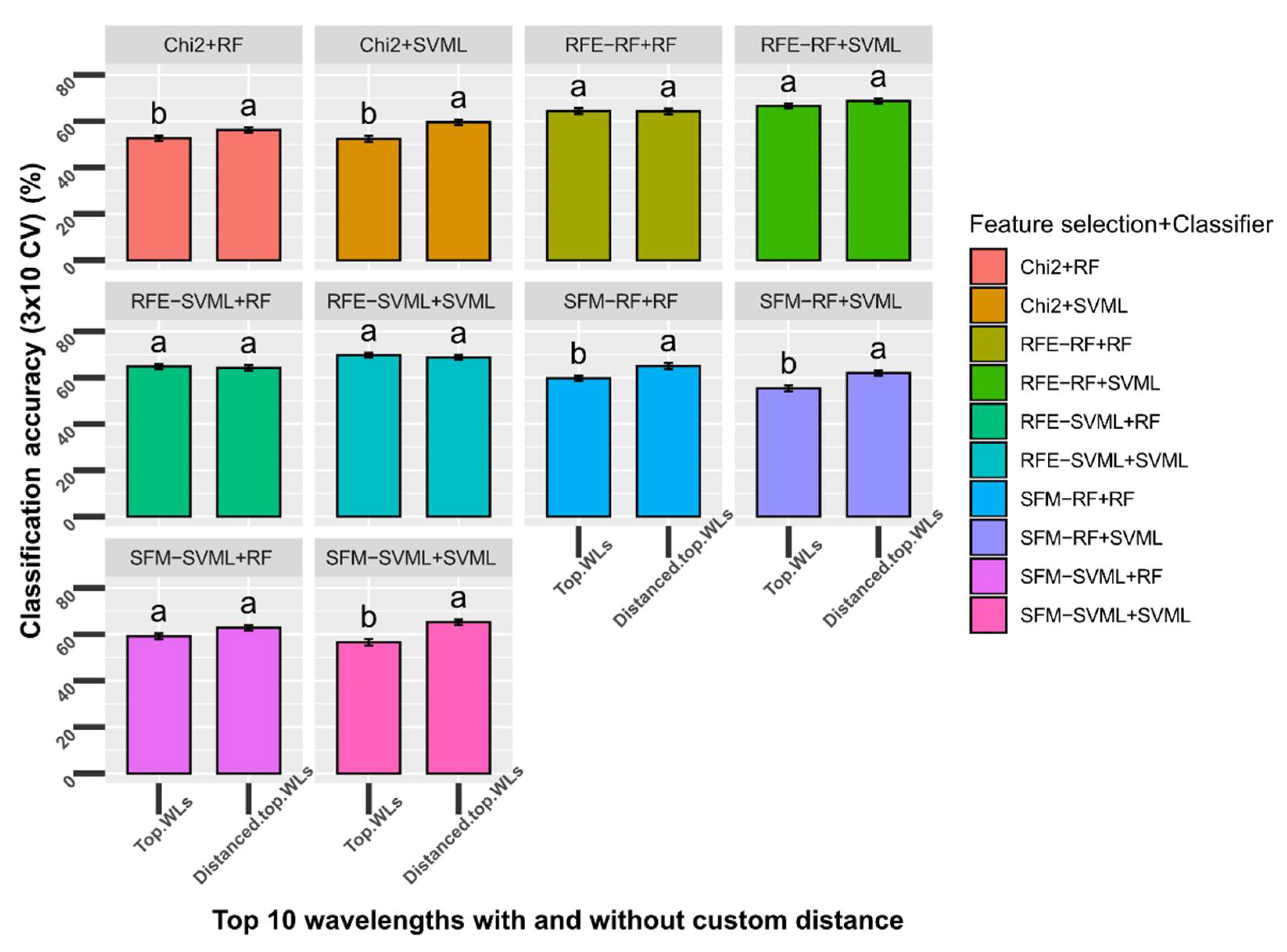
3.5. Feature Selection with a Custom Minimum Distance
3.6. Selected Wavelengths and Classification Accuracy for 5 Classes
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stalker, H. Peanut (Arachis hypogaea L.). Field Crops Res. 1997, 53, 205–217. [Google Scholar] [CrossRef]
- Venkatachalam, M.; Sathe, S.K. Chemical composition of selected edible nut seeds. J. Agric. Food Chem. 2006, 54, 4705–4714. [Google Scholar] [CrossRef] [PubMed]
- Porter, D.M. The peanut plant. In Compendium of Peanut Diseases, 2nd ed.; Kokalis-Burelle, N., Porter, D.M., Rodríguez-Kábana, R., Smith, D.H., Subrahmanyam, P., Eds.; The American Phytopathological Society: St. Paul, MN, USA, 1997; p. 1. [Google Scholar]
- Backman, P.A.; Brenneman, T.B. Stem rot. In Compendium of Peanut Diseases, 2nd ed.; Kokalis-Burelle, N., Porter, D.M., Rodríguez-Kábana, R., Smith, D.H., Subrahmanyam, P., Eds.; The American Phytopathological Society: St. Paul, MN, USA, 1997; pp. 36–37. [Google Scholar]
- Mullen, J. Southern blight, southern stem blight, white mold. Plant Health Instr. 2001. [Google Scholar] [CrossRef]
- Punja, Z.K. The biology, ecology, and control of Sclerotium rolfsii. Annu. Rev. Phytopathol. 1985, 23, 97–127. [Google Scholar] [CrossRef]
- Agrios, G. Encyclopedia of Microbiology; Schaechter, M., Ed.; Elsevier Inc.: Amsterdam, The Netherlands, 2009; pp. 613–646. [Google Scholar]
- Gold, K.M.; Townsend, P.A.; Chlus, A.; Herrmann, I.; Couture, J.J.; Larson, E.R.; Gevens, A.J. Hyperspectral measurements enable pre-symptomatic detection and differentiation of contrasting physiological effects of late blight and early blight in potato. Remote Sens. 2020, 12, 286. [Google Scholar] [CrossRef] [Green Version]
- Zarco-Tejada, P.; Camino, C.; Beck, P.; Calderon, R.; Hornero, A.; Hernández-Clemente, R.; Kattenborn, T.; Montes-Borrego, M.; Susca, L.; Morelli, M. Previsual symptoms of Xylella fastidiosa infection revealed in spectral plant-trait alterations. Nat. Plants 2018, 4, 432–439. [Google Scholar] [CrossRef]
- Augusto, J.; Brenneman, T.; Culbreath, A.; Sumner, P. Night spraying peanut fungicides I. Extended fungicide residual and integrated disease management. Plant Dis. 2010, 94, 676–682. [Google Scholar] [CrossRef]
- Punja, Z.; Huang, J.-S.; Jenkins, S. Relationship of mycelial growth and production of oxalic acid and cell wall degrading enzymes to virulence in Sclerotium rolfsii. Can. J. Plant Pathol. 1985, 7, 109–117. [Google Scholar] [CrossRef]
- Weeks, J.; Hartzog, D.; Hagan, A.; French, J.; Everest, J.; Balch, T. Peanut Pest Management Scout Manual; ANR-598; Alabama Cooperative Extension Service: Auburn, AL, USA, 1991; pp. 1–16. [Google Scholar]
- Mehl, H.L. Peanut diseases. In Virginia Peanut Production Guide; Balota, M., Ed.; SPES-177NP; Virginia Cooperative Extension: Blacksburg, VA, USA, 2020; pp. 91–106. [Google Scholar]
- Mahlein, A.-K. Plant Disease Detection by Imaging Sensors—Parallels and Specific Demands for Precision Agriculture and Plant Phenotyping. Plant Dis. 2016, 100, 241–251. [Google Scholar] [CrossRef] [Green Version]
- Mahlein, A.-K.; Kuska, M.T.; Behmann, J.; Polder, G.; Walter, A. Hyperspectral sensors and imaging technologies in phytopathology: State of the art. Annu. Rev. Phytopathol. 2018, 56, 535–558. [Google Scholar] [CrossRef]
- Bock, C.H.; Barbedo, J.G.; Del Ponte, E.M.; Bohnenkamp, D.; Mahlein, A.-K. From visual estimates to fully automated sensor-based measurements of plant disease severity: Status and challenges for improving accuracy. Phytopathol. Res. 2020, 2, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Silva, G.; Tomlinson, J.; Onkokesung, N.; Sommer, S.; Mrisho, L.; Legg, J.; Adams, I.P.; Gutierrez-Vazquez, Y.; Howard, T.P.; Laverick, A. Plant pest surveillance: From satellites to molecules. Emerg. Top. Life Sci. 2021. [Google Scholar] [CrossRef]
- Barreto, A.; Paulus, S.; Varrelmann, M.; Mahlein, A.-K. Hyperspectral imaging of symptoms induced by Rhizoctonia solani in sugar beet: Comparison of input data and different machine learning algorithms. J. Plant Dis. Prot. 2020, 127, 441–451. [Google Scholar] [CrossRef]
- Calderón, R.; Navas-Cortés, J.; Zarco-Tejada, P. Early detection and quantification of Verticillium wilt in olive using hyperspectral and thermal imagery over large areas. Remote Sens. 2015, 7, 5584–5610. [Google Scholar] [CrossRef] [Green Version]
- Gold, K.M.; Townsend, P.A.; Herrmann, I.; Gevens, A.J. Investigating potato late blight physiological differences across potato cultivars with spectroscopy and machine learning. Plant Sci. 2020, 295, 110316. [Google Scholar] [CrossRef] [PubMed]
- Gold, K.M.; Townsend, P.A.; Larson, E.R.; Herrmann, I.; Gevens, A.J. Contact reflectance spectroscopy for rapid, accurate, and nondestructive Phytophthora infestans clonal lineage discrimination. Phytopathology 2020, 110, 851–862. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hillnhütter, C.; Mahlein, A.-K.; Sikora, R.; Oerke, E.-C. Remote sensing to detect plant stress induced by Heterodera schachtii and Rhizoctonia solani in sugar beet fields. Field Crops Res. 2011, 122, 70–77. [Google Scholar] [CrossRef]
- Hillnhütter, C.; Mahlein, A.-K.; Sikora, R.A.; Oerke, E.-C. Use of imaging spectroscopy to discriminate symptoms caused by Heterodera schachtii and Rhizoctonia solani on sugar beet. Precis. Agric. 2012, 13, 17–32. [Google Scholar] [CrossRef]
- Nagasubramanian, K.; Jones, S.; Sarkar, S.; Singh, A.K.; Singh, A.; Ganapathysubramanian, B. Hyperspectral band selection using genetic algorithm and support vector machines for early identification of charcoal rot disease in soybean stems. Plant Methods 2018, 14, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Rumpf, T.; Mahlein, A.-K.; Steiner, U.; Oerke, E.-C.; Dehne, H.-W.; Plümer, L. Early detection and classification of plant diseases with support vector machines based on hyperspectral reflectance. Comput. Electron. Agric. 2010, 74, 91–99. [Google Scholar] [CrossRef]
- Zhu, H.; Chu, B.; Zhang, C.; Liu, F.; Jiang, L.; He, Y. Hyperspectral imaging for presymptomatic detection of tobacco disease with successive projections algorithm and machine-learning classifiers. Sci. Rep. 2017, 7, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomas, S.; Kuska, M.T.; Bohnenkamp, D.; Brugger, A.; Alisaac, E.; Wahabzada, M.; Behmann, J.; Mahlein, A.-K. Benefits of hyperspectral imaging for plant disease detection and plant protection: A technical perspective. J. Plant Dis. Prot. 2018, 125, 5–20. [Google Scholar] [CrossRef]
- Carter, G.A.; Knapp, A.K. Leaf optical properties in higher plants: Linking spectral characteristics to stress and chlorophyll concentration. Am. J. Bot. 2001, 88, 677–684. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jacquemoud, S.; Ustin, S.L. Leaf optical properties: A state of the art. In Proceedings of the 8th International Symposium of Physical Measurements & Signatures in Remote Sensing, Aussois, France, 8–12 January 2001; pp. 223–332. [Google Scholar]
- Behmann, J.; Mahlein, A.-K.; Rumpf, T.; Römer, C.; Plümer, L. A review of advanced machine learning methods for the detection of biotic stress in precision crop protection. Precis. Agric. 2015, 16, 239–260. [Google Scholar] [CrossRef]
- Miao, X.; Gong, P.; Swope, S.; Pu, R.; Carruthers, R.; Anderson, G.L. Detection of yellow starthistle through band selection and feature extraction from hyperspectral imagery. Photogramm. Eng. Remote Sens. 2007, 73, 1005–1015. [Google Scholar]
- Sun, W.; Du, Q. Hyperspectral band selection: A review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Dópido, I.; Villa, A.; Plaza, A.; Gamba, P. A quantitative and comparative assessment of unmixing-based feature extraction techniques for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 421–435. [Google Scholar] [CrossRef]
- Sun, W.; Halevy, A.; Benedetto, J.J.; Czaja, W.; Liu, C.; Wu, H.; Shi, B.; Li, W. UL-Isomap based nonlinear dimensionality reduction for hyperspectral imagery classification. ISPRS J. Photogramm. Remote Sens. 2014, 89, 25–36. [Google Scholar] [CrossRef]
- Hsu, P.-H. Feature extraction of hyperspectral images using wavelet and matching pursuit. ISPRS J. Photogramm. Remote Sens. 2007, 62, 78–92. [Google Scholar] [CrossRef]
- Yang, C.; Lee, W.S.; Gader, P. Hyperspectral band selection for detecting different blueberry fruit maturity stages. Comput. Electron. Agric. 2014, 109, 23–31. [Google Scholar] [CrossRef]
- Mahlein, A.K.; Rumpf, T.; Welke, P.; Dehne, H.W.; Plümer, L.; Steiner, U.; Oerke, E.C. Development of spectral indices for detecting and identifying plant diseases. Remote Sens. Environ. 2013, 128, 21–30. [Google Scholar] [CrossRef]
- Heim, R.; Wright, I.; Chang, H.C.; Carnegie, A.; Pegg, G.; Lancaster, E.; Falster, D.; Oldeland, J. Detecting myrtle rust (Austropuccinia psidii) on lemon myrtle trees using spectral signatures and machine learning. Plant Pathol. 2018, 67, 1114–1121. [Google Scholar] [CrossRef]
- Yang, H.; Du, Q.; Chen, G. Particle swarm optimization-based hyperspectral dimensionality reduction for urban land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 544–554. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, A.; Ganapathysubramanian, B.; Singh, A.K.; Sarkar, S. Machine learning for high-throughput stress phenotyping in plants. Trends Plant Sci. 2016, 21, 110–124. [Google Scholar] [CrossRef] [Green Version]
- Singh, A.; Jones, S.; Ganapathysubramanian, B.; Sarkar, S.; Mueller, D.; Sandhu, K.; Nagasubramanian, K. Challenges and opportunities in machine-augmented plant stress phenotyping. Trends Plant Sci. 2020. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wei, X.; Langston, D.; Mehl, H.L. Spectral and thermal responses of peanut to infection and colonization with Athelia rolfsii. PhytoFrontiers 2021. [Google Scholar] [CrossRef]
- Shokes, F.; Róźalski, K.; Gorbet, D.; Brenneman, T.; Berger, D. Techniques for inoculation of peanut with Sclerotium rolfsii in the greenhouse and field. Peanut Sci. 1996, 23, 124–128. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Febrero Bande, M.; Oviedo de la Fuente, M. Statistical computing in functional data analysis: The R package fda. usc. J. Stat. Softw. 2012, 51, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Stevens, A.; Ramirez-Lopez, L. An Introduction to the Prospectr Package, R package Vignette R package version 0.2.1; 2020. Available online: http://bioconductor.statistik.tu-dortmund.de/cran/web/packages/prospectr/prospectr.pdf (accessed on 19 July 2021).
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Team, R.C. Caret: Classification and Regression Training, R package version 6.0.-84; Astrophysics Source Code Library: Houghton, MI, USA, 2020. [Google Scholar]
- Mevik, B.-H.; Wehrens, R.; Liland, K.H.; Mevik, M.B.-H.; Suggests, M. pls: Partial Least Squares and Principal Component Regression, R package version 2.7-2; 2020. Available online: https://cran.r-project.org/web/packages/pls/pls.pdf (accessed on 19 July 2021).
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Hennessy, A.; Clarke, K.; Lewis, M. Hyperspectral classification of plants: A review of waveband selection generalisability. Remote Sens. 2020, 12, 113. [Google Scholar] [CrossRef] [Green Version]
- Gitelson, A.A.; Merzlyak, M.N. Signature analysis of leaf reflectance spectra: Algorithm development for remote sensing of chlorophyll. J. Plant Physiol. 1996, 148, 494–500. [Google Scholar] [CrossRef]
- Merzlyak, M.N.; Gitelson, A.A.; Chivkunova, O.B.; Rakitin, V.Y. Non-destructive optical detection of pigment changes during leaf senescence and fruit ripening. Physiol. Plant. 1999, 106, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Thenkabail, P.S.; Enclona, E.A.; Ashton, M.S.; Van Der Meer, B. Accuracy assessments of hyperspectral waveband performance for vegetation analysis applications. Remote Sens. Environ. 2004, 91, 354–376. [Google Scholar] [CrossRef]
- Balota, M.; Oakes, J. UAV remote sensing for phenotyping drought tolerance in peanuts. In Proceedings of the SPIE Commercial + Scientific Sensing and Imaging, Anaheim, CA, USA, 16 May 2017. [Google Scholar]
- Luis, J.; Ozias-Akins, P.; Holbrook, C.; Kemerait, R.; Snider, J.; Liakos, V. Phenotyping peanut genotypes for drought tolerance. Peanut Sci. 2016, 43, 36–48. [Google Scholar] [CrossRef]
- Sarkar, S.; Ramsey, A.F.; Cazenave, A.-B.; Balota, M. Peanut leaf wilting estimation from RGB color indices and logistic models. Front. Plant Sci. 2021, 12, 713. [Google Scholar] [CrossRef] [PubMed]
- Higgins, B.B. Physiology and parasitism of Sclerotium rolfsii Sacc. Phytopathology 1927, 17, 417–447. [Google Scholar]
- Bateman, D.; Beer, S. Simultaneous production and synergistic action of oxalic acid and polygalacturonase during pathogenesis by Sclerotium rolfsii. Phytopathology 1965, 55, 204–211. [Google Scholar] [PubMed]
- Moshou, D.; Pantazi, X.-E.; Kateris, D.; Gravalos, I. Water stress detection based on optical multisensor fusion with a least squares support vector machine classifier. Biosyst. Eng. 2014, 117, 15–22. [Google Scholar] [CrossRef]
- Conrad, A.O.; Li, W.; Lee, D.-Y.; Wang, G.-L.; Rodriguez-Saona, L.; Bonello, P. Machine Learning-Based Presymptomatic Detection of Rice Sheath Blight Using Spectral Profiles. Plant Phenomics 2020, 2020, 954085. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
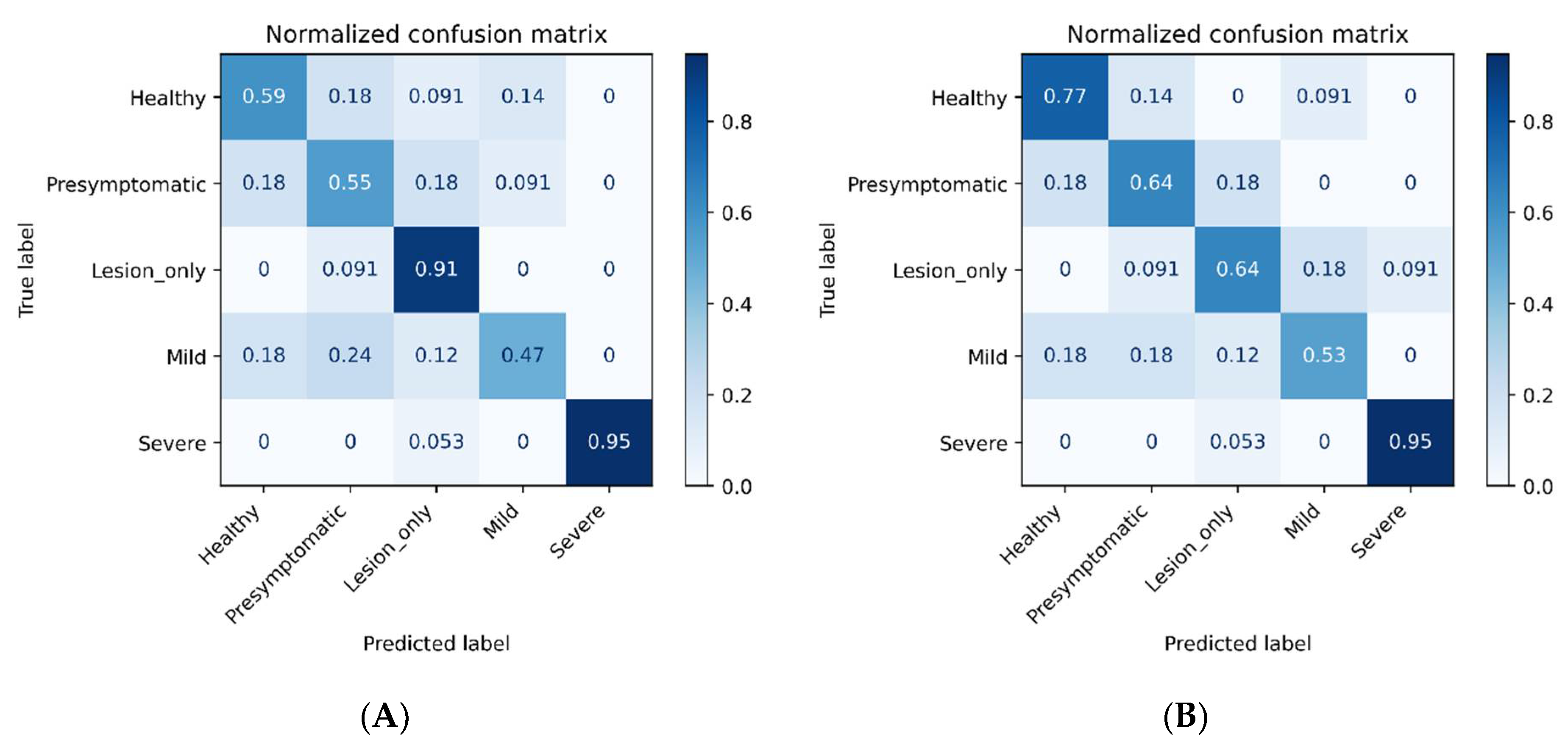{kind=link}
| Rank/Methods | Selected Wavelengths (nm) | ||||
|---|---|---|---|---|---|
| Chi-Square | SFM_RF | SFM_SVML | RFE_RF | RFE_SVML | |
| (A) Original top 10 selected features | |||||
| 1 | 698 | 496 | 884 | 501 | 505 |
| 2 | 702 | 884 | 759 | 884 | 396 |
| 3 | 706 | 665 | 807 | 505 | 302 |
| 4 | 694 | 501 | 767 | 274 | 391 |
| 5 | 595 | 690 | 743 | 620 | 261 |
| 6 | 590 | 686 | 838 | 735 | 653 |
| 7 | 599 | 826 | 763 | 247 | 514 |
| 8 | 603 | 505 | 850 | 686 | 884 |
| 9 | 586 | 628 | 694 | 645 | 763 |
| 10 | 611 | 492 | 803 | 690 | 830 |
| (B) Top 10 selected features with a custom minimum distance | |||||
| 1 | 698 | 496 | 884 | 501 | 505 |
| 2 | 595 | 884 | 759 | 884 | 396 |
| 3 | 632 | 665 | 807 | 274 | 302 |
| 4 | 573 | 690 | 838 | 620 | 261 |
| 5 | 527 | 826 | 694 | 735 | 653 |
| 6 | 552 | 628 | 649 | 247 | 884 |
| 7 | 657 | 242 | 242 | 686 | 763 |
| 8 | 719 | 518 | 731 | 645 | 830 |
| 9 | 505 | 607 | 674 | 779 | 431 |
| 10 | 678 | 274 | 586 | 826 | 624 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Johnson, M.A.; Langston, D.B., Jr.; Mehl, H.L.; Li, S. Identifying Optimal Wavelengths as Disease Signatures Using Hyperspectral Sensor and Machine Learning. Remote Sens. 2021, 13, 2833. https://doi.org/10.3390/rs13142833
Wei X, Johnson MA, Langston DB Jr., Mehl HL, Li S. Identifying Optimal Wavelengths as Disease Signatures Using Hyperspectral Sensor and Machine Learning. Remote Sensing. 2021; 13(14):2833. https://doi.org/10.3390/rs13142833
Chicago/Turabian StyleWei, Xing, Marcela A. Johnson, David B. Langston, Jr., Hillary L. Mehl, and Song Li. 2021. "Identifying Optimal Wavelengths as Disease Signatures Using Hyperspectral Sensor and Machine Learning" Remote Sensing 13, no. 14: 2833. https://doi.org/10.3390/rs13142833
APA StyleWei, X., Johnson, M. A., Langston, D. B., Jr., Mehl, H. L., & Li, S. (2021). Identifying Optimal Wavelengths as Disease Signatures Using Hyperspectral Sensor and Machine Learning. Remote Sensing, 13(14), 2833. https://doi.org/10.3390/rs13142833