4.2.2. Training Settings and Evaluation Indicators
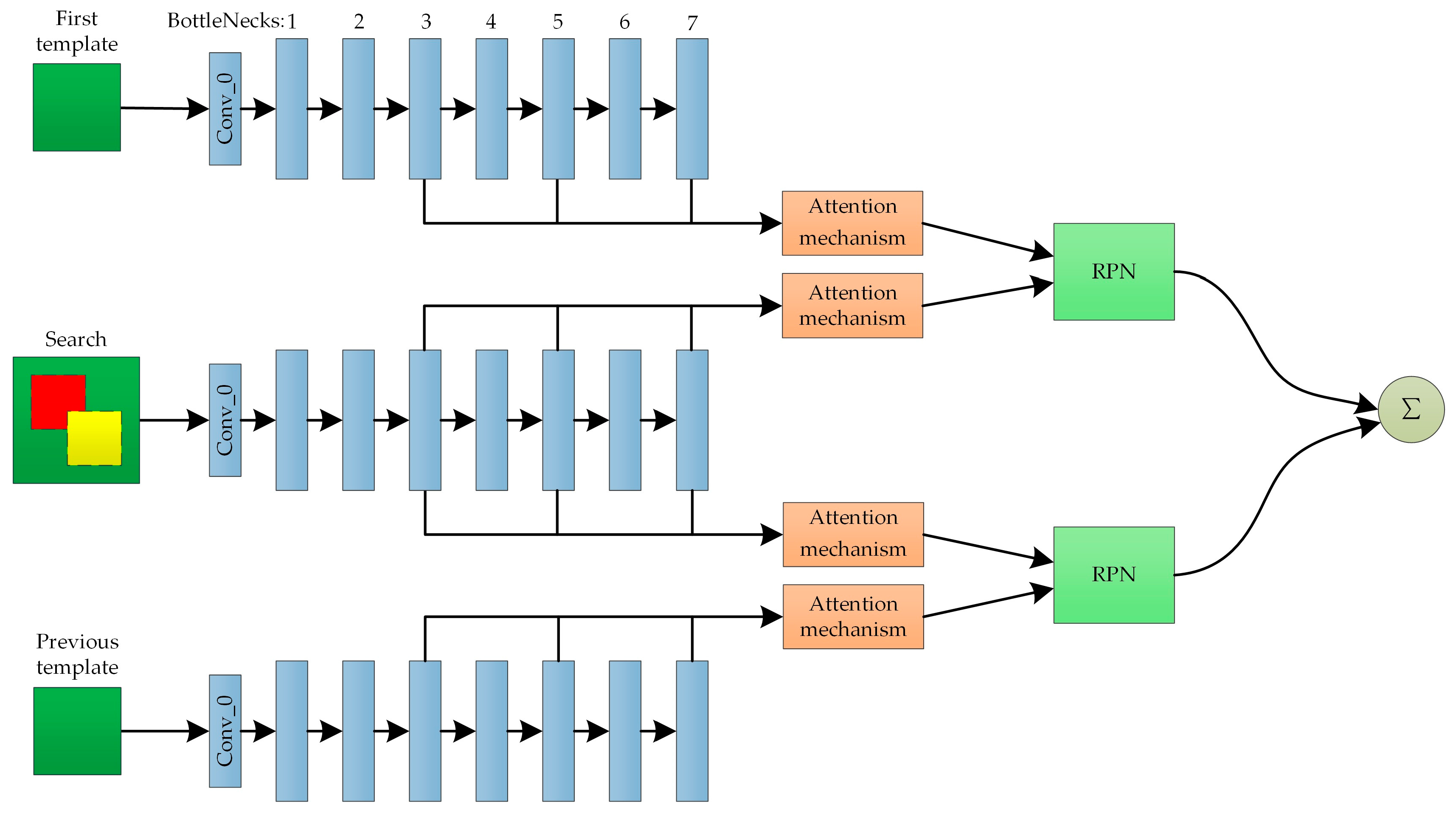
The end-to-end collaborative training is conducted based on the YouTube-BoundingBoxes dataset. During training, the sizes of the template images of the first and previous frames are each set to 127 × 127, whilst that of search image is set to 255 × 255, and the size of the output response map is set to 17 × 17. When the tracking object is not obviously occluded, the anchor step of the RPN is always set to 8, and the aspect ratio includes 1/3, 1/2, 1, 2, and 3.
The stochastic gradient descent method is used for network optimization, the momentum coefficient is set to 0.9, and the weight attenuation value is set to 0.0001. The training process is divided into 50 rounds, and the learning rate decreases logarithmically from 0.03 to 0.0005 with the number of training rounds.
The object tracking algorithms were usually quantified based on the evaluation indicators to accurately evaluate their performance. The evaluation indicators used in this study mainly included the overlap rate (OR) and center location error (CLE).
The OR is the final overlap ratio of the predicted and real boxes; that is, the ratio of the intersection area of the predicted and real boxes to the union area of the two boxes. The maximum value is 1 and the minimum value is 0. This value is used to reflect the closeness between the tracking result and the real object, also known as the success rate, which can be expressed by the following formula:
where
represents the region of the predicted box,
represents the region of the real box, and
represents the number of pixels in the area.
The CLE refers to the center position error between the final predicted box and the real box; that is, the Euclidean distance between the center coordinates of the predicted and real boxes. This indicator is used to reflect the tracking accuracy of the algorithms and can be expressed by the following formula:
where
is the center coordinate of the predicted box and
is the center coordinate of the real box.
4.2.3. Analysis and Discussion of Testing Results
To fully test the tracking effect of the proposed object tracking algorithm in complex scenes, six typical video sequences from the OTB2015 dataset are selected as testing sequences. The selected video sequences cover all challenging aspects in order to better simulate the possible interference factors that may appear in actual road scenes. The testing sequences and their challenging aspects are listed in
Table 2. Furthermore, we select six state-of-the-art object tracking algorithms for experiments: CFNet, SA-Siam and SiamRPN, based on the Siamese network framework; and SRDCF [
48], MCCT [
49], and SACF [
50], with the correlation filtering model. The above algorithms are consistent with the system operating environment of the proposed algorithm, and related tests are performed based on the same tracking dataset to comprehensively evaluate the tracking performance of the proposed network model.
- 1.
Qualitative analysis and discussion
We observe the tracking results of the testing sequences in a variety of complex scenes, and analyze and discuss the performance of the algorithms in image description.
Figure 8 shows the tracking results of different object tracking algorithms for the testing sequences.
The above figure shows the tracking performances of the seven object tracking algorithms, including the proposed algorithm, for different testing sequences, and the tracking results are represented by bounding boxes of different colors.
In the CarDark video sequence, the main challenging aspects are IV and BC. In the initial frames, all tracking algorithms can closely follow the tracking object. However, at the 289th frame, due to the dark light and the presence of an interfering vehicle with similar characteristics to the tracking vehicle in the background, CFNet exhibits tracking drift. At the 309th frame, SRDCF also shows tracking drift due to a similar interference vehicle. At the 393rd frame, all the tracking algorithms except for CFNet and SRDCF, which completely lost the object, perform well without losing the object.
In the Human4 video sequence, the main challenging aspects are DEF, OCC, SV, and IV. The scale of the tracking person in this video sequence is small, the features contained in the object are limited, and interference occurs from unrelated surrounding objects. However, the tracking is easy in general because of the simple background. At the 195th frame, only CFNet has a positioning error and the tracking box deviates from the object person. At the 255th frame, CFNet repositions accurately and moves with the tracking person, as the other tracking algorithms.
In the BlurCar1 video sequence, the main challenging aspects are MB and FM. In the initial frames without motion blur, all algorithms can track the object vehicle accurately. However, at the 256th frame, the video image begins to become blurred due to camera shaking. At the 257th frame, all the algorithms except for the proposed algorithm have different degrees of tracking drift. As the video image gradually recovers its clarity, all algorithms can track the object vehicle stably at the 516th frame, indicating that the algorithms have memory functions and can save the key features of the object vehicle. With the rapid movement of the vehicle, the background of the video image is further blurred. At the 768th frame, CFNet, SRDCF, and MCCT completely lose the tracking object, thereby resulting in tracking failure.
In the MotorRolling video sequence, the main challenging aspects are IPR, LR, BC, SV, IV, MB, and FM. At the 68th frame, the video image has low resolution and motion blur is produced due to the fast motion of the motorcycle. Except for the proposed algorithm and SiamRPN, all other algorithms show slight tracking drift. At the 76th frame, the video image is still blurred and the motorcycle rotates in the air under a complex and dim background. The tracking boxes of all the algorithms except for the proposed algorithm deviate from the tracking object.
In the Suv video sequence, the main challenging aspects are OCC, IPR, and OV. In the initial frame, all algorithms perform well in tracking the object vehicle. Starting from the 509th frame, the object vehicle begins to be partially obscured. At the 536th frame, the object vehicle is completely obscured by roadside trees. All the algorithms except for the proposed algorithm, SiamRPN, and SA-Siam show obvious tracking drift. At the 576th frame, the object vehicle is no longer occluded by the surrounding environment, but some tracking algorithms are not accurate enough for object positioning, indicating that long-term occlusion has a certain effect on the tracking performance of the algorithms.
In the Biker video sequence, the main challenging aspects are OV, SV, OPR, MB, FM, LR, and OCC. At the 21st frame, the biker rides forward, and all algorithms can achieve accurate tracking of his face. At the 73rd frame, due to the out-of-plane rotation of the bicycle, the biker’s face is sideways and beyond the edge of the image, and only the proposed algorithm can track it stably. At the 86th frame, the biker rides backward. Owing to the limited object features extracted, all the algorithms except for the proposed algorithm and SiamRPN have a small range of tracking drift.
From the qualitative analysis of the test results, it can be seen that other object tracking algorithms have limitations, and most of them can only be applied to a single simple scenario. When the environment changes dramatically or the appearance of the object changes significantly, it is easy for tracking drift to occur or even for the object to be lost. The proposed algorithm can still achieve effective tracking of different objects in complex scenes, and the bounding boxes are accurate and of the appropriate size. It shows good robustness with regard to the changes in appearance of the object and various degrees of occlusion, as well as excellent environmental adaptability with regard to the illumination variation and differing background.
- 2.
Quantitative analysis and discussion
The tracking results of the different object tracking algorithms in the testing sequences are quantified, and the performances of the algorithms are analyzed and discussed in the form of numerical comparison. The average OR and average CLE of the various object tracking algorithms in the testing sequences are shown in
Table 3 and
Table 4, respectively.
From the quantitative analysis of testing results, it can be seen that, compared with other object tracking algorithms, the proposed algorithm shows outstanding performance in all testing sequences. The mean value of the average OR is the highest, reaching 82.5%, and the mean value of the average CLE is the lowest, only 8.5 pixels. The proposed algorithm obtains the best performance parameters in all the video sequences except for the Human4 video sequence. Among the correlation filtering algorithms, SACF is the best of its kind, but there is still a big gap compared with the proposed algorithm. Such algorithms can be better applied for object tracking in simple scenes, and the shortcomings of having insufficient robustness are easily exposed in complex backgrounds. Although the linear interpolation update in the correlation filtering model can lead to the tracker gradually adapting to the current features of the object without losing the initial features, gradual accumulation occurs due to tracking errors in the long-term tracking process. When the tracking object is occluded for a long time, this kind of algorithm encounters difficulty in accurately locating the latest position of the object. Compared with the correlation filtering algorithms, the other algorithms based on the Siamese network framework exhibit better tracking performances, except for CFNet. Among them, the proposed algorithm performs better than SiamRPN, largely due to the effective fusion of deep and shallow features and the online updating mechanism of dynamic templates. The robustness of the network model is significantly enhanced by dynamically adjusting parameters and updating templates. Although SA-Siam also deploys a channel attention module, due to the lack of a tracking result detection mechanism, some useless background information is learned by mistake, making it prone to exhibiting tracking drift with cluttered backgrounds. In other words, the proposed algorithm can approach the real object to the greatest extent in a variety of complex scenes, with high tracking accuracy and powerful anti-jamming ability for different interference factors, indicating that the double-template Siamese network model based on multi-feature fusion can greatly enhance the stability of the algorithm while effectively improving its tracking performance.
For autonomous vehicles, one crucial feature is that the tracking speed of the algorithm must meet the real-time requirements.
Table 5 shows the tracking speeds of the different object tracking algorithms in the testing sequences.
In this article, the algorithm with tracking speeds above 30 FPS is considered to meet the requirements for real-time tracking. It can be seen intuitively from the above table that, among the correlation filtering algorithms, SACF and MCCT have higher tracking speeds, while SRDCF does not meet the requirements for real-time tracking. The algorithms based on the Siamese network framework all meet the requirements for real-time tracking. Among them, CFNet has the highest tracking speed, reaching 67 FPS, and the proposed algorithm ranks third, reaching 56 FPS, slightly behind CFNet and SiamRPN. The results show that, although the attention mechanism and template online update mechanism are introduced into the network model, it does not have a great impact on the tracking speed, but it further improves the tracking accuracy while ensuring good real-time performance.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}