1. Introduction
In a wide range of real-world applications, varying from urban planning to precision agriculture, including land cover, infrastructure management and so on, semantic segmentation of aerial and remote sensing (RS) imageries is a pivotal task, which continues to attract great interest [
1]. Semantic labeling, that consists in assigning a category to every pixel of the image, is particularly challenging in urban applications [
2,
3]. In fact, the complicated urban structure leads to interactions among objects, causing occlusions, shadows, and other noisy effects, which worsen the radiometric information of the images [
4]. Moreover, artificial manufacts have at least two main issues. On the one hand, objects belonging to different classes could retrieve very similar radiometric information (e.g., low vegetation and trees, or roads and pavements). On the other hand, manufacts of the same semantic class can present very different characteristics, such as color, texture, and shape [
5]. Eventually, it could be asserted that semantic segmentation in urban scenes is characterized by a strong intra-class variance and a reduced inter-class one [
6,
7].
In recent years, deep learning (DL) methods reached state-of-the-art, surpassing traditional methods, in several computer vision (CV) tasks. Many of these find large application also in RS, such as object detection, instance segmentation, and semantic labeling. It is unanimously recognized that DL methods have high generalization capabilities, succeeding in extracting robust and efficient features [
8,
9]. However, supervised training of these models depends on annotations. More than in other fields, for aerial and RS images, it is difficult to rely on a labeled dataset, in light of the high cost and the amount of effort and time that are required, along with a well founded expertise.
The advent of self-supervised learning (SSL) could handle this problem, reducing the amount of annotated data needed [
10,
11,
12]. The goal of SSL is to learn an effective visual representation of the input using a massive quantity of data provided without any label [
11,
13]. To solve this task in CV, we can see the problem as the need to build a well-structured and relevant set of features, able to represent an object in a fruitful way for several downstream tasks. Thus, intelligent systems need not to be structured a priori, but should instead learn about the conformation of the provided data in an unsupervised way [
14]. In particular, the majority of unsupervised approaches can be divided into two classes: generative and discriminative. Generative strategies learn to generate pixels in the input space. However, pixel-level generation can be computationally expensive. Discriminative approaches are based on learning the representation of the unlabeled data to solve downstream tasks. Among these techniques, in contrastive learning the goal is to generate a representation of the input, such that similar instances are near each other and far from dissimilar ones [
13,
15]. Other approaches fulfill the goal of reconstructing a target image, after perturbing it [
16,
17]. Essentially, SSL is earning more and more interest in CV, reaching state-of-the-art performances in several tasks.
In this technical letter, we propose a new approach, that combines a SSL algorithm (that is, online bag of words [
12]) and a semantic segmentation algorithm shaped for aerial images (properly, Multistage Attention ResU-Net [
18]), based on a linear attention mechanism (LAM). Particularly, we decided to train the encoder of the Multistage Attention ResU-Net (MAResU-Net), that is a ResNet-18 [
19], with the Online Bag of Words (OBoW) method, given its high capability of learning visual representations, that are effective for several downstream task. This characteristic is fundamental, because most of available SSL pretrained models do not perform particularly well on RS data. In fact, due to the problems that we addressed previously, aerial and RS imageries have peculiar characteristics, different from the images taken with close-range cameras. Indeed, unlike, for example, the ImageNet dataset, the RS images present an enormous amount of details to look after, to correctly segment the objects. Moreover, in addition to the aforementioned variance issues, the shapes, the colors and the scale of the objects are crucial in this task [
20]. In particular, the edges must have high consideration, as they are changeable and labile much more than in close-range camera images [
7].
On the other hand, attention exploits the ability of grasping long-term dependencies of the feature maps, exploring global contextual information of the data. Dot-product attention mechanism, generating response at each pixel by weighting features in the previous layers, expands the receptive field to the whole input feature maps, reaching state-of-the-art performance in many fields [
21,
22,
23]. However, the memory and computational overhead of the dot-product attention mechanism increases quadratically along with the spatio-temporal size of the input. To alleviate the huge computational costs, ref [
24] reduced the complexity from
to
; ref [
25] to
; and [
18,
26,
27] to
.
To sum up, the three major contributions offered by the proposed technical letter are the following:
we show how the SSL approach, designed for generic CV downstream tasks, performs well even on more sectorial areas of image analysis, such as RS;
we highlight that SSL methods are effective to reduce dependence on well-annotated dataset, currently required to reach high performances in RS tasks, since they require high costs and great need of time, effort, and knowledge to be produced;
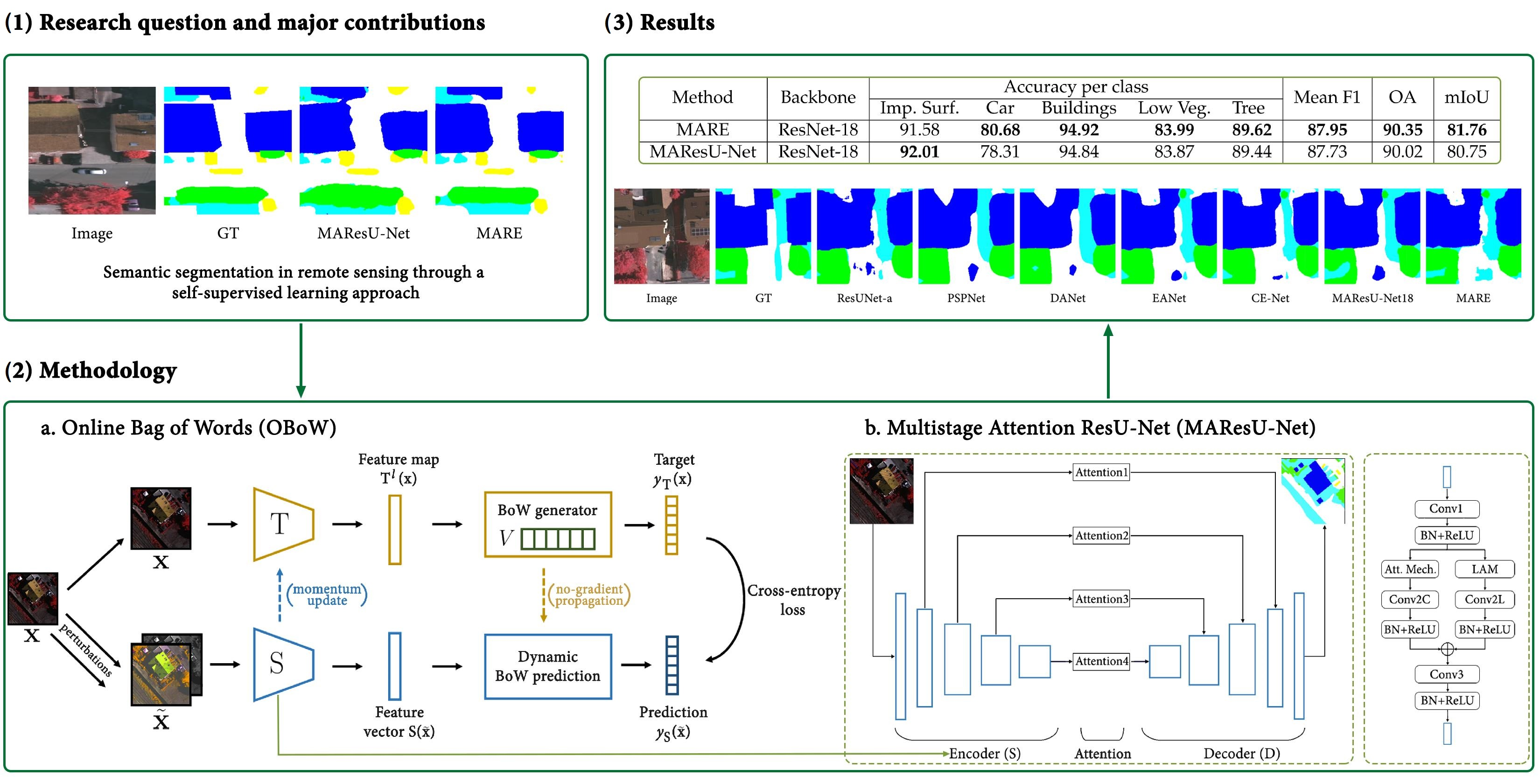
we obtain the best results in literature for the semantic segmentation of the ISPRS Vaihingen benchmark dataset [
28] with ResNet-18 as encoder. This confirms an excellent trade-off between the number of parameters and the performance of the model.
The remainder of this technical note is organized as follows: in
Section 2 the related works, divided in three subsections, concerning, respectively, semantic segmentation (
Section 2.1), semantic segmentation for aerial and RS imageries (
Section 2.2) and SSL (
Section 2.3), are illustrated; in
Section 3 OBoW and MAResU-Net methodologies are briefly explained; in
Section 4 the experimental results and the ablation studies are presented. Finally, in
Section 5, a discussion of the results, including the limitations of the proposed strategy, and further developments are dispensed.
3. Methodology
To deal with the challenge of limited annotated training data for RS segmentation, we rely on SSL to learn powerful representations, that can tap on the potential of the large amount of unlabeled data, readily available in RS. Particularly, we decided to use OBoW [
12], because it exploits the use of visual words, which are visual concepts localized in the spatial domain (as opposed to global concepts as in most other SSL methods). This could be beneficial for dense prediction tasks, such as semantic segmentation. Furthermore, it exhibits very strong empirical performance. On the other hand, we decided to rely on MAResU-Net, for the semantic segmentation task, because of several reasons. U-Net-based architectures have proven to be an excellent choice for image segmentation tasks. Moreover, the use of a self-attention mechanism has shown to provide high-capacity models that can properly take advantage of large scale datasets. Finally, to deal with the high computational cost of self-attention, we extend the solution proposed by MAResU-Net.
In the following subsections, we provide details about the chosen architectures.
3.1. Self-Supervised Learning for Remote Sensing Using Online Bag of Visual Words
In [
17], the authors propose BoWNet, which offers the idea of using Bag of Visual Words (BoW) as targets for SSL. This approach, despite its effectiveness and innovativeness, had some limitations, such as a static visual words vocabulary.
These limits were tackled in [
12], where the authors propose an improved solution, that is OBoW.
The BoW reconstruction task involves a student convolutional neural network (CNN) that learns image representations, and a teacher CNN that generates BoW targets used for training the student network. The student is parameterized by and the teacher by .
Inspired by [
15], the parameters
of
are an exponential moving average of the student parameters. As a consequence, the teacher has the same architecture as the student, though maintaining different batch-norm statistics.
To generate a BoW representation
out of an image
x, the teacher first extracts the feature map
, of spatial size
with
channels, from its last layer
l. It quantizes the
-dimensional feature vectors
at each location
of the feature map over a vocabulary
of
K visual words of dimension
. The vocabulary
V of visual words is a
K-sized queue of random features. At each step, after computing the assignment codes over the vocabulary
V,
V is updated by selecting one feature vector per image from the current mini-batch, removing the oldest item in the queue if its size exceeds
K. The feature selection consists of a local average pooling with a
kernel of the feature map
followed by a uniform random sampling of one of the resulting feature vectors. Thus, assuming that the local features in a
neighborhood belong to one common visual concept, local averaging selects a representative visual-word feature from this neighborhood. This quantization process produces for each location
u a
K-dimensional code vector
that encodes the assignment of
to its closest visual word. Then, the teacher reduces the quantized feature maps
to a
K-dimensional BoW
by channel-wise max-pooling. For this step, a soft-assignment is preferable due to the fact that the vocabulary of visual words is continuously evolving. The soft assignment depends on an adaptive parameter
. Finally,
is converted into a probability distribution over the visual words by
-normalization, i.e.,
To learn effective image representations, the student must predict the BoW distribution over
V of an image using as input a perturbed version of that same image. In OBoW, the vocabulary is constantly updated. Therefore, a dynamic BoW-prediction head that can adapt to the evolving nature of the vocabulary is proposed. To that end, the authors employ a generation network
that takes as input the current vocabulary of visual words
V and produces prediction weights for them as
, where
consists in a 2-layer multilayer perceptron (MLP) whose input and output vectors are
-normalized and
represents the prediction weight vector for the
kth visual word. Therefore,
is computed as follows:
where
is a fixed coefficient that equally scales the magnitudes of all the predicted weights
. The
K-dimensional vector
is the predicted softmax probability of the target
. Hence, the training loss that is minimized for a single image
is the cross entropy between the softmax distribution
predicted by the student from the perturbed image
, and the BoW distribution
of the unperturbed image
given by the teacher.
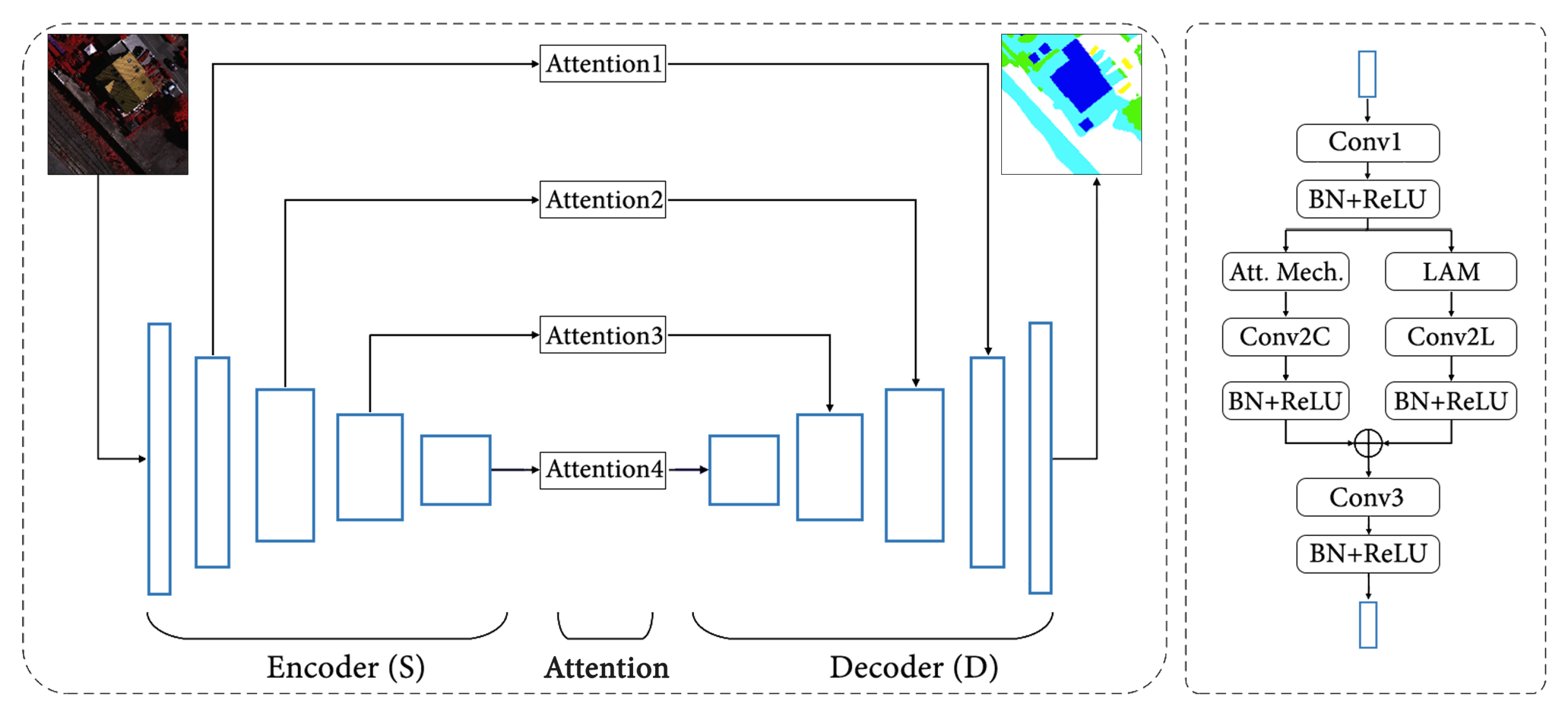
The architecture described so far is represented in
Figure 1.
3.2. MAResU-Net
MAResU-Net proposes a modified U-Net architecture. In fact, first of all, the encoder S is made up of a ResNet. Moreover, the blocks of the encoder S and the decoder D are not simple skip connections, but are replaced by attention modules. To reduce the computational times, these modules combine a conventional attention mechanism and a linear one, i.e. LAM.
The loss function follows the formula:
where
M is the number of training examples,
C the number of classes,
the target label for training example
m of class
c,
the weight for the class
c,
the input for the training example
m and
the model with the weights
.
Particularly, if all the are set to 1 and soft assignment is performed, the loss becomes a soft categorical cross entropy (SCE), otherwise it is a weighted categorical cross entropy (WCE).
Eventually, the LAM is presented in the next
Section 3.2.1, while the whole architecture is shown in
Figure 2.
3.2.1. Linear Attention Mechanism
Providing
N and
C as the length of input sequences and the number of input channels, where
, with
H and
W the height and width of the input, with the input feature
, dot-product attention utilizes three projected matrices
,
, and
to generate the corresponding query matrix
, the key matrix
, and the value matrix
. The attention is, according to [
21], computed as follows:
where
is a scale factor. As
and
, the product between
and
belongs to
, which leads to
memory and computational complexity. Thus, the
row of result matrix generated by the dot-product attention module can be written as:
First generalizing (
5), then approximating
with first-order Taylor expansion, finally
-normalizing the resulting equation, (
5) can be written as:
As and is common to every query, complexity of this linear attention mechanism is . Nevertheless, for the channel dimension dot-product-based attention is computed, considering that the channels of the input C are much less than the pixels. Thus, by taking the ResNet as the backbone, MAResU-Net combines low and high-level feature maps through attention block in multiple stages.
5. Conclusions
5.1. Review and Conclusion of the Accomplished Work
Semantic segmentation in RS remains a challenging and pivotal task. On the other hand, cutting-edge methods, such as SSL, and the attention mechanism are gaining increasing interest, finding a wide range of applications in real-world tasks. The application of a SSL model, such as OBoW, can lead to the creation of robust features that can improve the representation of the considered data, tackling, at least partially, the important problem of annotated data scarcity in RS. Furthermore, the attention mechanism allows the net to take into account the long-term dependencies also in specific sub-domains of images, such as RS. Following this intuition, in this letter we successfully combine existing methods in a technically sound manner in order to deliver a segmentation method that is efficient and high-performing.
5.2. Limitations and Outlook of the Proposed Approach
The set of experiments presented here shows how SSL methods are highly effective in RS, making it possible to exploit large amounts of non-annotated data, partially freeing segmentation systems from the need of annotated datasets. Furthermore, the foundations are laid for the validation of the effectiveness of SSL techniques on a wide range of downstream tasks related to different sectors of image analysis. However, the study presents only a first step in this direction. First of all, it would be interesting to extend the range of experiments, showing the behavior of this approach with the modification of some parameters, such as the size of the encoder or the SSL strategy. However, once again it is stated that the trade-off obtained between the number of parameters and excellent performance (the best with a ResNet-18 as an encoder) is very important.
5.3. Further Developments
On the one hand, further developments will be to extend this research, not only to other self-supervised algorithms, but also to assess how SSL affects the performances in other downstream tasks, connected to the RS area, such as object detection or disparity map creation, to further reduce the need of annotated data, exploiting at the maximum the available images. Moreover, it would be interesting to evaluate how such approaches, which exploit information from non-annotated data, behave as the number of labeled data decreases.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}