
An Approach to Semantically Segmenting Building Components and Outdoor Scenes Based on Multichannel Aerial Imagery Datasets





Abstract
:1. Motivation and Introduction
2. Related Work
2.1. Energy Aduits
2.2. Neural Network Approaches for Feature Extraction
2.3. Semantic Segmentation
2.4. Current Datasets
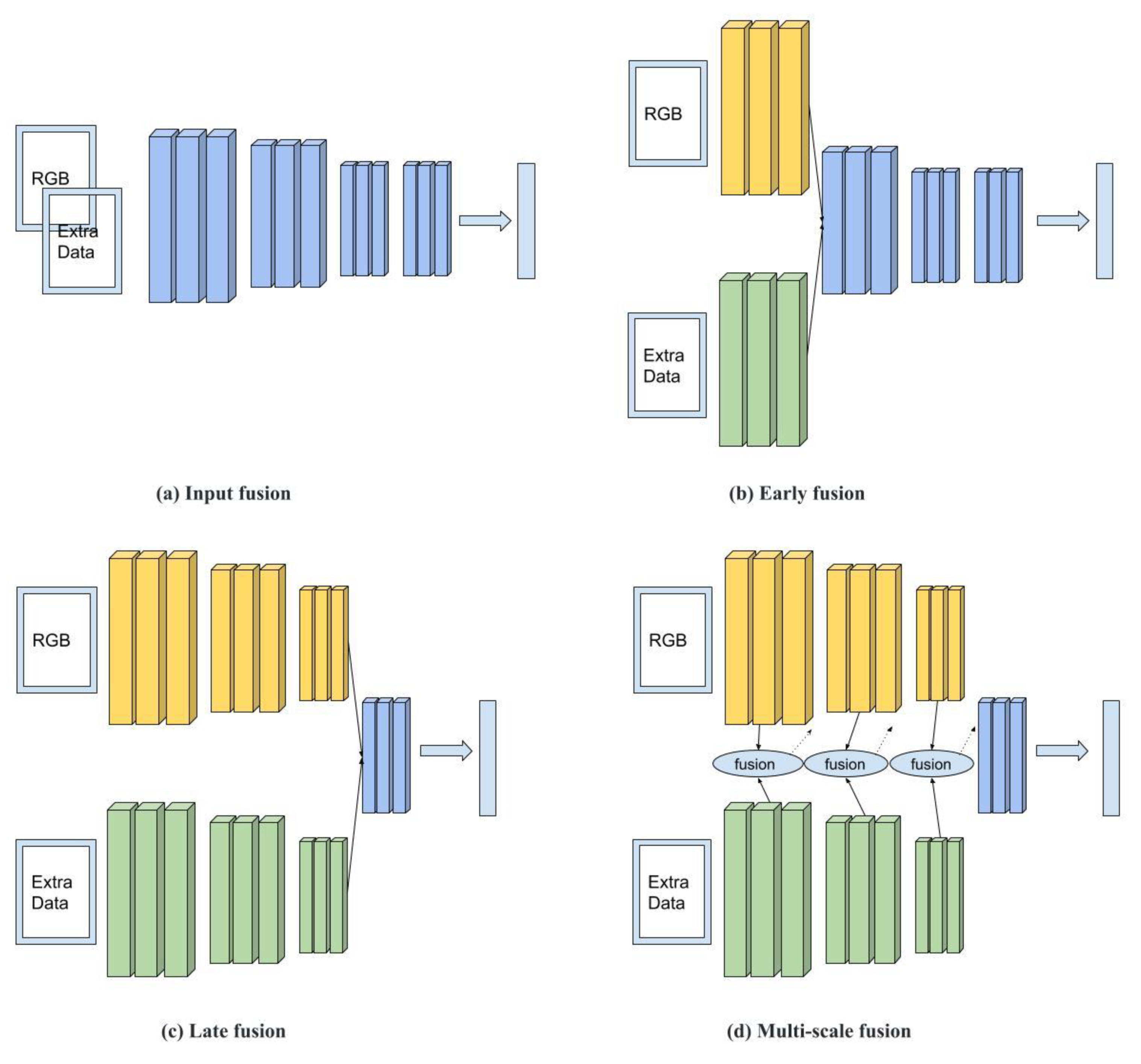
2.5. Image Data Fusion and Related Work
3. Methodology
3.1. Data Collection
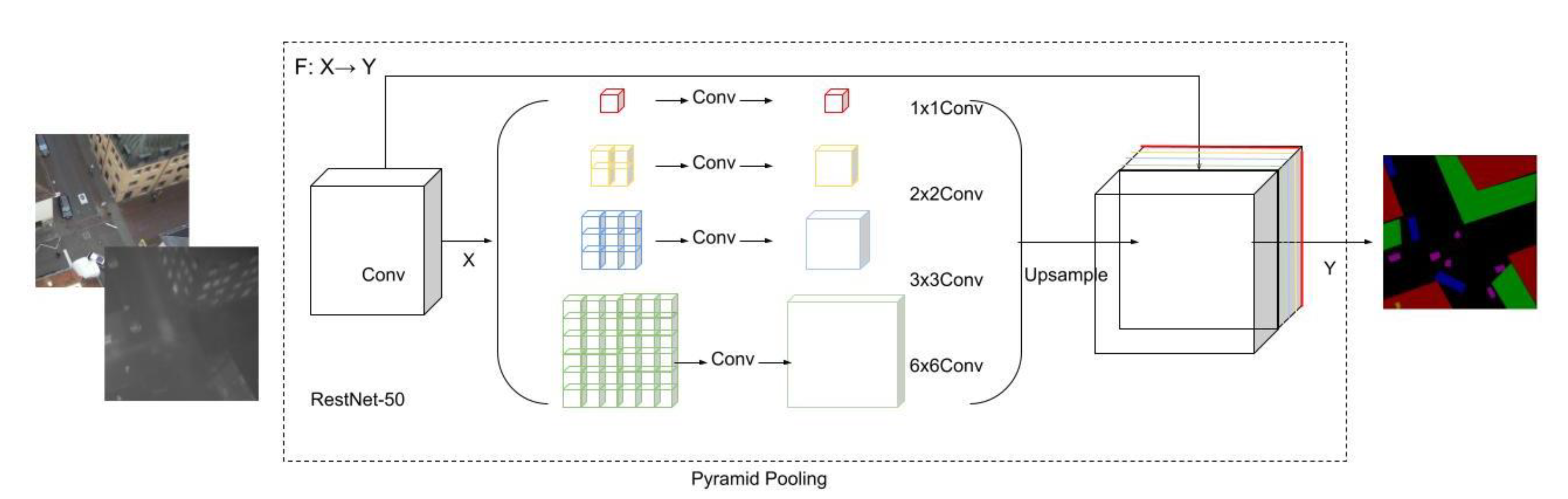
3.2. PSPNet Implementation
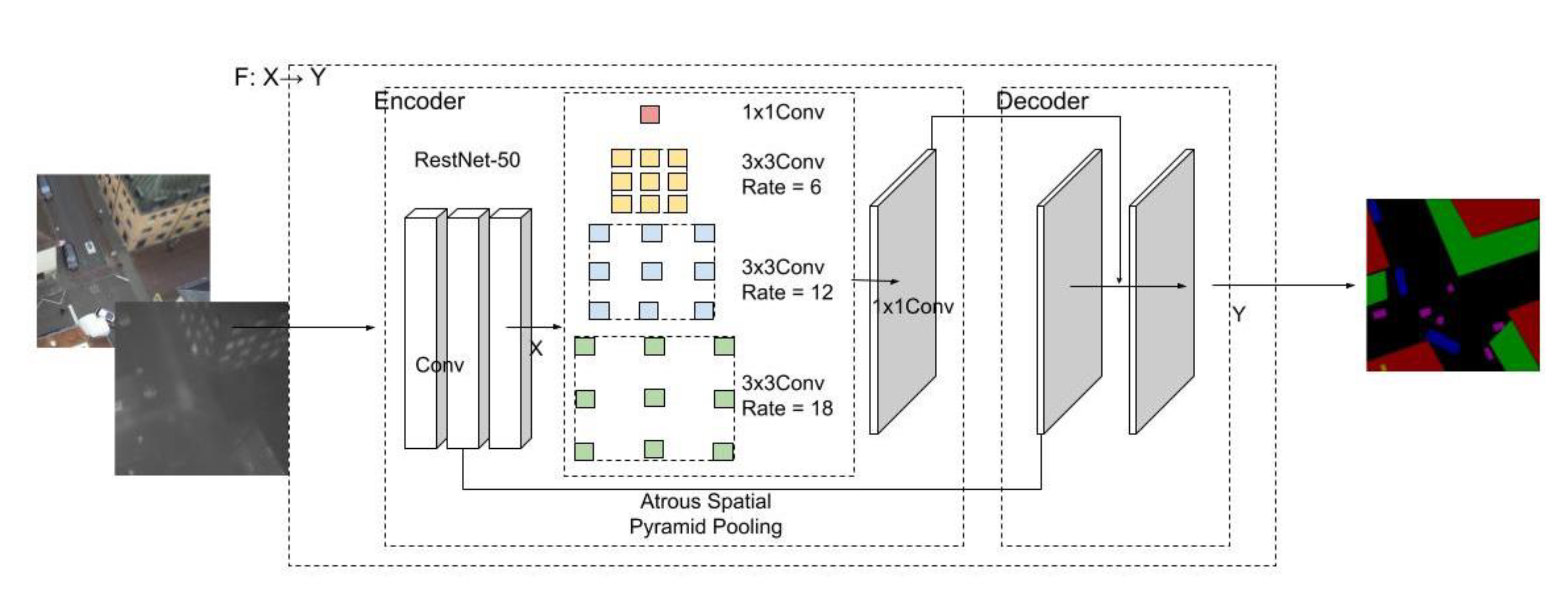
3.3. DeepLab v3+ Implementation
3.4. Mask R-CNN Implementation
3.5. Common Configurations (Hyperparameters) for Performance Comparison
4. Case Studies and Results
4.1. Performance Evaluation
4.2. Evaluation of PSPNet and DeepLab v3+
4.3. Evaluation of Mask R-CNN
4.4. Discussion
5. Conclusions and Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hou, Y.; Mayer, Z.; Li, Z.; Volk, R.; Soibelman, L. An Innovative Approach for Building Facade Component Segmentation on 3D Point Cloud Models Reconstructed by Aerial Images. In Proceedings of the 28th International Workshop on Intelligent Computing in Engineering, Berlin, Germany, 30 June–2 July 2021; pp. 1–10. [Google Scholar]
- Lin, D.; Jarzabek-Rychard, M.; Schneider, D.; Maas, H.G. Thermal texture selection and correction for building facade inspection based on thermal radiant characteristics. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2018, 42, 585–591. [Google Scholar] [CrossRef] [Green Version]
- Lin, D.; Jarzabek-rychard, M.; Tong, X.; Maas, H. Fusion of thermal imagery with point clouds for building façade thermal attribute mapping. ISPRS J. Photogramm. Remote Sens. 2019, 151, 162–175. [Google Scholar] [CrossRef]
- Hou, Y.; Soibelman, L.; Volk, R.; Chen, M. Factors Affecting the Performance of 3D Thermal Mapping for Energy Audits in A District by Using Infrared Thermography (IRT) Mounted on Unmanned Aircraft Systems (UAS). In Proceedings of the 36th International Symposium on Automation and Robotics in Construction (ISARC), Banff, AB, Canada, 21–24 May 2019; pp. 266–273. [Google Scholar] [CrossRef]
- Yao, X.; Wang, X.; Zhong, Y.; Liangpei, Z. Thermal Anomaly Detection based on Saliency Computation for Dristrict Heating System. 2016, pp. 681–684. Available online: http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7729171 (accessed on 24 October 2021).
- Friman, O.; Follo, P.; Ahlberg, J.; Sjökvist, S. Methods for Large-Scale Monitoring of District Heating Systems Using Airborne Thermography Methods for Large-Scale Monitoring of District Heating Systems using Airborne Thermography. IEEE Trans. Geosci. Remote. Sens. 2014, 52, 5175–5182. [Google Scholar] [CrossRef] [Green Version]
- Bauer, E.; Pavón, E.; Barreira, E.; de Castro, E.K. Analysis of building facade defects using infrared thermography: Laboratory studies. J. Build. Eng. 2016, 6, 93–104. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Wong, A.; Famuori, M.; Shafiee, M.J.; Li, F.; Chwyl, B.; Chung, J. YOLO Nano: A Highly Compact You Only Look Once Convolutional Neural Network for Object Detection. arXiv Prepr. 2019, arXiv:1910.01271, 1–5. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Spicer, R.; Mcalinden, R.; Conover, D. Producing Usable Simulation Terrain Data from UAS-Collected Imagery. In Proceedings of the 2016 Interservice/Industry Training Systems and Education Conference (I/ITSEC), Orlando, FL, USA, 4–7 December 2006; pp. 1–13. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. 2017, pp. 1–23. Available online: http://arxiv.org/abs/1704.06857 (accessed on 24 October 2021).
- Park, S.; Lee, S. RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Ki-Sang Hong. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Cambridge, MA, USA, 20–23 June 2017; pp. 4980–4989. [Google Scholar]
- Wang, J.; Wang, Z.; Tao, D.; See, S.; Wang, G. Learning common and specific features for RGB-D semantic segmentation with deconvolutional networks, Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9909 LNCS, pp. 664–679. [Google Scholar] [CrossRef] [Green Version]
- Berg, A.; Ahlberg, J. Classification of leakage detections acquired by airborne thermography of district heating networks. In Proceedings of the 2014 8th IAPR Workshop on Pattern Recognition in Remote Sensing. PRRS 2014, Stockholm, Sweden, 24 August 2014. [Google Scholar] [CrossRef] [Green Version]
- Berg, A.; Ahlberg, J.; Felsberg, M. Enhanced analysis of thermographic images for monitoring of district heat pipe networks. Pattern Recognit. Lett. 2016, 83, 215–223. [Google Scholar] [CrossRef] [Green Version]
- Cho, Y.K.; Ham, Y.; Golpavar-Fard, M. 3D as-is building energy modeling and diagnostics: A review of the state-of-the-art. Adv. Eng. Inform. 2015, 29, 184–195. [Google Scholar] [CrossRef]
- Lucchi, E. Applications of the infrared thermography in the energy audit of buildings: A review. Renew. Sustain. Energy Rev. 2018, 82, 3077–3090. [Google Scholar] [CrossRef]
- Maroy, K.; Carbonez, K.; Steeman, M.; van den Bossche, N. Assessing the thermal performance of insulating glass units with infrared thermography: Potential and limitations. Energy Build. 2017, 138, 175–192. [Google Scholar] [CrossRef]
- Hou, Y.; Volk, R.; Soibelman, L. A Novel Building Temperature Simulation Approach Driven by Expanding Semantic Segmentation Training Datasets with Synthetic Aerial Thermal Images. Energies 2021, 14, 353. [Google Scholar] [CrossRef]
- Nardi, I.; Lucchi, E.; de Rubeis, T.; Ambrosini, D. Quantification of heat energy losses through the building envelope: A state-of-the-art analysis with critical and comprehensive review on infrared thermography. Build. Environ. 2018, 146, 190–205. [Google Scholar] [CrossRef] [Green Version]
- Barreira, E.; Almeida, R.M.S.F.; Moreira, M. An infrared thermography passive approach to assess the effect of leakage points in buildings. Energy Build. 2017, 140, 224–235. [Google Scholar] [CrossRef]
- Balaras, C.A.; Argiriou, A.A. Infrared thermography for building diagnostics. Energy Build. 2002, 34, 171–183. [Google Scholar] [CrossRef]
- Tejedor, B.; Casals, M.; Gangolells, M.; Roca, X. Quantitative internal infrared thermography for determining in-situ thermal behaviour of façades. Energy Build. 2017, 151, 187–197. [Google Scholar] [CrossRef]
- Tejedor, B.; Casals, M.; Gangolells, M. Assessing the influence of operating conditions and thermophysical properties on the accuracy of in-situ measured U-values using quantitative internal infrared thermography. Energy Build. 2018, 171, 64–75. [Google Scholar] [CrossRef]
- Bison, P.; Cadelano, G.; Grinzato, E. Thermographic Signal Reconstruction with periodic temperature variation applied to moisture classification. Quant. InfraRed Thermogr. J. 2011, 8, 221–238. [Google Scholar] [CrossRef] [Green Version]
- Roselyn, J.P.; Uthra, R.A.; Raj, A.; Devaraj, D.; Bharadwaj, P.; Kaki, S.V.D.K. Development and implementation of novel sensor fusion algorithm for occupancy detection and automation in energy efficient buildings. Sustain. Cities Soc. 2019, 44, 85–98. [Google Scholar] [CrossRef]
- Hou, Y.; Chen, M.; Volk, R.; Soibelman, L. Investigation on performance of RGB point cloud and thermal information data fusion for building thermal map modeling using aerial images under different experimental conditions. J. Build. Eng. 2021, 103380. [Google Scholar] [CrossRef]
- Park, J.; Kim, P.; Cho, Y.K.; Kang, J. Framework for automated registration of UAV and UGV point clouds using local features in images. Autom. Constr. 2019, 98, 175–182. [Google Scholar] [CrossRef]
- Balan, P.S.; Sunny, L.E. Survey on Feature Extraction Techniques in Image Processing. Int. J. Res. Appl. Sci. Eng. Technol. (IJRASET) 2018, 6, 217–222. [Google Scholar]
- Hespanha, P.; Kriegman, D.J.; Belhumeur, P.N. Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection. IEEE Trans. pattern Anal. Mach. Intelligencevol. 1997, 19, 711–720. [Google Scholar]
- Turk, M.A.; Pentland, A.P. Face Recognition Using Eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1991; IEEE: Piscataway, NJ, USA, 1991; pp. 586–591. [Google Scholar]
- Yambor, W.S.; Draper, B.A.; Beveridge, J.R. Analyzing PCA-based Face Recognition Algorithms: Eigenvector Selection and Distance Measures. In Empirical Evaluation Methods in Computer Vision; World Scientific: Singapore, 2000; pp. 1–14. [Google Scholar]
- Martinez, A.M.; Kak, A.C. PCA versus LDA. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef] [Green Version]
- Toygar, Ö.; Introduction, I. Face Recognition Using PCA, LDA AND ICA Approaches on Colored Images. IU-J. Electr. Electron. Eng. 2003, 3, 735–743. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors, in null. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; pp. 506–513. [Google Scholar]
- Comon, P. Independent Component Analysis, A New Concept? Signal Process 1994, 287–314. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. Assoc. Comput. Mach. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the in European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Jiang, M.X.; Deng, C.; Shan, J.S.; Wang, Y.Y.; Jia, Y.J.; Sun, X. Hierarchical multi-modal fusion FCN with attention model for RGB-D tracking. Inf. Fusion 2019, 50, 1–8. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2018, 11211 LNCS, 833–851. [Google Scholar] [CrossRef] [Green Version]
- Paper with Code. 2021. Available online: https://paperswithcode.com/ (accessed on 27 May 2021).
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. 2017. Available online: http://arxiv.org/abs/1706.05587 (accessed on 24 October 2021).
- Aslam, Y.; Santhi, N.; Ramasamy, N.; Ramar, K. Localization and segmentation of metal cracks using deep learning. J. Ambient. Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. CGNet: A Light-Weight Context Guided Network for Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2018, 11209 LNCS, 432–448. [Google Scholar] [CrossRef] [Green Version]
- Mayer, Z.; Hou, Y.; Kahn, J.; Beiersdörfer, T.; Volk, R. Thermal Bridges on Building Rooftops—Hyperspectral (RGB + Thermal + Height) drone images of Karlsruhe, Germany, with thermal bridge annotations. Repos. KITopen 2021. [Google Scholar] [CrossRef]
- Nawaz, M.; Yan, H. Saliency Detection using Deep Features and Affinity-based Robust Background Subtraction. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y. Progressively Complementarity-Aware Fusion Network for RGB-D Salient Object Detection. In Proceedings of the in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3051–3060. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Ren, J.; Gong, X.; Yu, L.; Zhou, W.; Yang, M.Y. Exploiting global priors for RGB-D saliency detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; Volume 2015-Octob, pp. 25–32. [Google Scholar] [CrossRef]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. RGBD salient object detection: A benchmark and algorithms. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2014, 8691 LNCS, 92–109. [Google Scholar] [CrossRef]
- Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; Yang, Q. RGBD Salient Object Detection via Deep Fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef]
- Desingh, K.; K, M.K.; Rajan, D.; Jawahar, C. Depth really Matters: Improving Visual Salient Region Detection with Depth. In Proceedings of the BMVC, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Gong, X. Adaptive fusion for rgb-d salient object detection. IEEE Access 2019, 7, 55277–55284. [Google Scholar] [CrossRef]
- van der Ploeg, T.; Austin, P.C.; Steyerberg, E.W. Modern modelling techniques are data hungry: A simulation study for predicting dichotomous endpoints. BMC Med Res. Methodol. 2014, 14, 137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, M.; Feng, A.; Mcalinden, R.; Soibelman, L. Generating Synthetic Photogrammetric Data for Training Deep Learning based 3D Point Cloud Segmentation Models. arXiv 2020, arXiv:2008.09647v120221, 1–12. [Google Scholar]
- Chen, M.; Feng, A.; McCullough, K.; Prasad, P.B.; McAlinden, R.; Soibelman, L. 3D Photogrammetry Point Cloud Segmentation Using a Model Ensembling Framework. J. Comput. Civ. Eng. 2020, 34, 1–20. [Google Scholar] [CrossRef]
- Chen, M.; Feng, A.; Mccullough, K.; Prasad, B.; Mcalinden, R.; Soibelman, L. Semantic Segmentation and Data Fusion of Microsoft Bing 3D Cities and Small UAV-based Photogrammetric Data. arXiv 2020, arXiv:2008.09648v120220, 1–12. [Google Scholar]
- Hou, Y.; Volk, R.; Chen, M.; Soibelman, L. Fusing tie points’ RGB and thermal information for mapping large areas based on aerial images: A study of fusion performance under different flight configurations and experimental conditions. Autom. Constr. 2021, 124. [Google Scholar] [CrossRef]
- Lagüela, S.; Armesto, J.; Arias, P.; Herráez, J. Automation of thermographic 3D modelling through image fusion and image matching techniques. Autom. Constr. 2012, 27, 24–31. [Google Scholar] [CrossRef]
- Luo, C.; Sun, B.; Yang, K.; Lu, T.; Yeh, W.C. Thermal infrared and visible sequences fusion tracking based on a hybrid tracking framework with adaptive weighting scheme. Infrared Phys. Technol. 2019, 99, 265–276. [Google Scholar] [CrossRef]
- Li, C.; Wu, X.; Zhao, N.; Cao, X.; Tang, J. Fusing two-stream convolutional neural networks for RGB-T object tracking. Neurocomputing 2018, 281, 78–85. [Google Scholar] [CrossRef]
- Zhai, S.; Shao, P.; Liang, X.; Wang, X. Fast RGB-T Tracking via Cross-Modal Correlation Filters. Neurocomputing 2019, 334, 172–181. [Google Scholar] [CrossRef]
- Jiang, J.; Jin, K.; Qi, M.; Wang, Q.; Wu, J.; Chen, C. A Cross-Modal Multi-granularity Attention Network for RGB-IR Person Re-identification. Neurocomputing 2020, 406, 59–67. [Google Scholar] [CrossRef]
- Mayer, Z.; Hou, Y.; Kahn, J.; Volk, R.; Schultmann, F. AI-Based Thermal Bridge Detection of Building Rooftops on District Scale Using Aerial Images. 2021. Available online: https://publikationen.bibliothek.kit.edu/1000136256/123066859 (accessed on 24 October 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Testing Dataset | Metric | Global Rank |
|---|---|---|---|
| Mask R-CNN | COCO | Average precision | 1st |
| Mean average precision | 1st | ||
| Cell17 | F1 score | 2nd | |
| Dice | 2nd | ||
| PSPNet | NYU Depth v2 | Mean IoU | 4th |
| Cityscapes | Mean IoU | 3rd | |
| DeepLab v3+ | PASCAL VOC | Mean IoU | 2nd |
| SkyScapesDense | Mean IoU | 2nd | |
| UPerNet [49] | ADE20K | Mean IoU | 45th |
| UNet [47] | Anatomical Tracings of Lesions After Stroke (ATLAS) | IoU | 2nd |
| Retinal vessel segmentation | F1 score | 10th | |
| CGNet [48] | MSU video super resolution benchmark | Subjective score | 21st |
| Index | Description | Roofs | Cars | Facades | Ground Equipment | Roof Equipment | Total Number of Instances |
|---|---|---|---|---|---|---|---|
| (1) | Number of instances in the training datasets (Percentage of the given category in the total number of instances) | 10,147 (27.1%) | 3426 (9.15%) | 9286 (24.8%) | 3679 (9.8%) | 10,888 (29.1%) | 37,426 |
| (2) | Number of instances in the testing datasets (Percentage of the given category in the total number of instances) | 2448 (27.5%) | 804 (9.0%) | 2177 (24.4%) | 880 (9.9%) | 2606 (29.2%) | 8915 |
| (3) | Ratio of (1):(2) | 4.145 | 4.261 | 4.266 | 4.181 | 4.178 | 4.198 |
| Index | Algorithms | ACC | F1 | IoU | Precision | Recall | Memory Per Iteration | Training Time Per Iteration |
|---|---|---|---|---|---|---|---|---|
| 1 | RGB-only- City-DeepLabv3+ | 0.91621 | 0.79454 | 0.68392 | 0.86021 | 0.75690 | 1400–1500 MB | 0.2–0.3 s |
| 2 | RGB-only- City-PSPNet | 0.91712 | 0.79213 | 0.68199 | 0.85542 | 0.75468 | ||
| 3 | RGB-only- VOC-DeepLabv3+ | 0.91686 | 0.79846 | 0.68930 | 0.85561 | 0.76388 | ||
| 4 | RGB-only- VOC-PSPNet | 0.91759 | 0.79232 | 0.68347 | 0.85904 | 0.75432 | ||
| 5 | RGB-Thermal- City-DeepLabv3+ | 0.91546 | 0.79576 | 0.68426 | 0.84683 | 0.76195 | ||
| 6 | RGB-Thermal- City-PSPNet | 0.91556 | 0.78685 | 0.67646 | 0.84792 | 0.75238 | ||
| 7 | RGB-Thermal- VOC-DeepLabv3+ | 0.91638 | 0.79561 | 0.68491 | 0.85775 | 0.75978 | ||
| 8 | RGB-Thermal- VOC-PSPNet | 0.91567 | 0.78870 | 0.67818 | 0.85354 | 0.75136 |
| Index | Algorithms | IoU.Background | IoU.Cars | IoU.Facades | IoU.Ground_Equipment | IoU.Roof_Equipment | IoU.Roofs |
|---|---|---|---|---|---|---|---|
| 1 | RGB-only- City-DeepLabv3+ | 0.80200 | 0.73955 | 0.79259 | 0.32389 | 0.54672 | 0.89874 |
| 2 | RGB-only- City-PSPNet | 0.80532 | 0.74463 | 0.79551 | 0.31752 | 0.5294 | 0.89961 |
| 3 | RGB-only- VOC-DeepLabv3+ | 0.80249 | 0.75421 | 0.79487 | 0.32512 | 0.56011 | 0.89900 |
| 4 | RGB-only- VOC-PSPNet | 0.80674 | 0.75462 | 0.79513 | 0.30555 | 0.53918 | 0.89961 |
| 5 | RGB-Thermal- City-DeepLabv3+ | 0.79940 | 0.73289 | 0.79512 | 0.33899 | 0.54223 | 0.89686 |
| 6 | RGB-Thermal- City-PSPNet | 0.80279 | 0.74061 | 0.79102 | 0.29864 | 0.52828 | 0.89738 |
| 7 | RGB-Thermal- VOC-DeepLabv3+ | 0.80260 | 0.73676 | 0.79529 | 0.33040 | 0.54663 | 0.89781 |
| 8 | RGB-Thermal- VOC-PSPNet | 0.80201 | 0.74216 | 0.79298 | 0.30767 | 0.52699 | 0.89723 |
| Index | Algorithms | Precision Value | Precision -Cars | Precision -Facades | Precision -Ground_ Equipment | Precision -Roof_ Equipment | Precision -Roofs | Precision @ IoU ≥ 0.5 | Precision @ IoU ≥ 0.75 | Precision-Large | Precision-Medium | Precision-Small |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | RGB_ only_ VOC | 30.50027 | 48.50009 | 39.40096 | 7.894894 | 18.51801 | 38.18739 | 53.82021 | 31.2914 | 25.17297 | 30.15385 | 10.09727 |
| 2 | RGB_ only_ City | 36.40356 | 56.87393 | 39.8599 | 13.93462 | 25.40921 | 44.08705 | 61.05142 | 37.09566 | 30.71153 | 35.43907 | 18.89682 |
| 3 | RGB_ Thermal_VOC | 34.67095 | 53.46492 | 38.34726 | 13.29906 | 23.57708 | 44.66644 | 59.18085 | 35.19486 | 32.31295 | 32.6255 | 13.10268 |
| 4 | RGB_ Thermal_City | 39.69939 | 59.65007 | 38.87487 | 18.22493 | 26.52003 | 49.22706 | 63.64552 | 41.1819 | 38.88473 | 39.07861 | 17.92202 |
| Memory per iteration | 4500–4600 MB | |||||||||||
| Training time per iteration | 0.5–0.6 s | |||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; Chen, M.; Volk, R.; Soibelman, L. An Approach to Semantically Segmenting Building Components and Outdoor Scenes Based on Multichannel Aerial Imagery Datasets. Remote Sens. 2021, 13, 4357. https://doi.org/10.3390/rs13214357
Hou Y, Chen M, Volk R, Soibelman L. An Approach to Semantically Segmenting Building Components and Outdoor Scenes Based on Multichannel Aerial Imagery Datasets. Remote Sensing. 2021; 13(21):4357. https://doi.org/10.3390/rs13214357
Chicago/Turabian StyleHou, Yu, Meida Chen, Rebekka Volk, and Lucio Soibelman. 2021. "An Approach to Semantically Segmenting Building Components and Outdoor Scenes Based on Multichannel Aerial Imagery Datasets" Remote Sensing 13, no. 21: 4357. https://doi.org/10.3390/rs13214357
APA StyleHou, Y., Chen, M., Volk, R., & Soibelman, L. (2021). An Approach to Semantically Segmenting Building Components and Outdoor Scenes Based on Multichannel Aerial Imagery Datasets. Remote Sensing, 13(21), 4357. https://doi.org/10.3390/rs13214357