
Hardware Implementation of the CCSDS 123.0-B-2 Near-Lossless Compression Standard Following an HLS Design Methodology



Abstract
:1. Introduction
2. CCSDS 123.0-B-2 Algorithm
2.1. Prediction Stage
2.2. Hybrid Entropy Coding
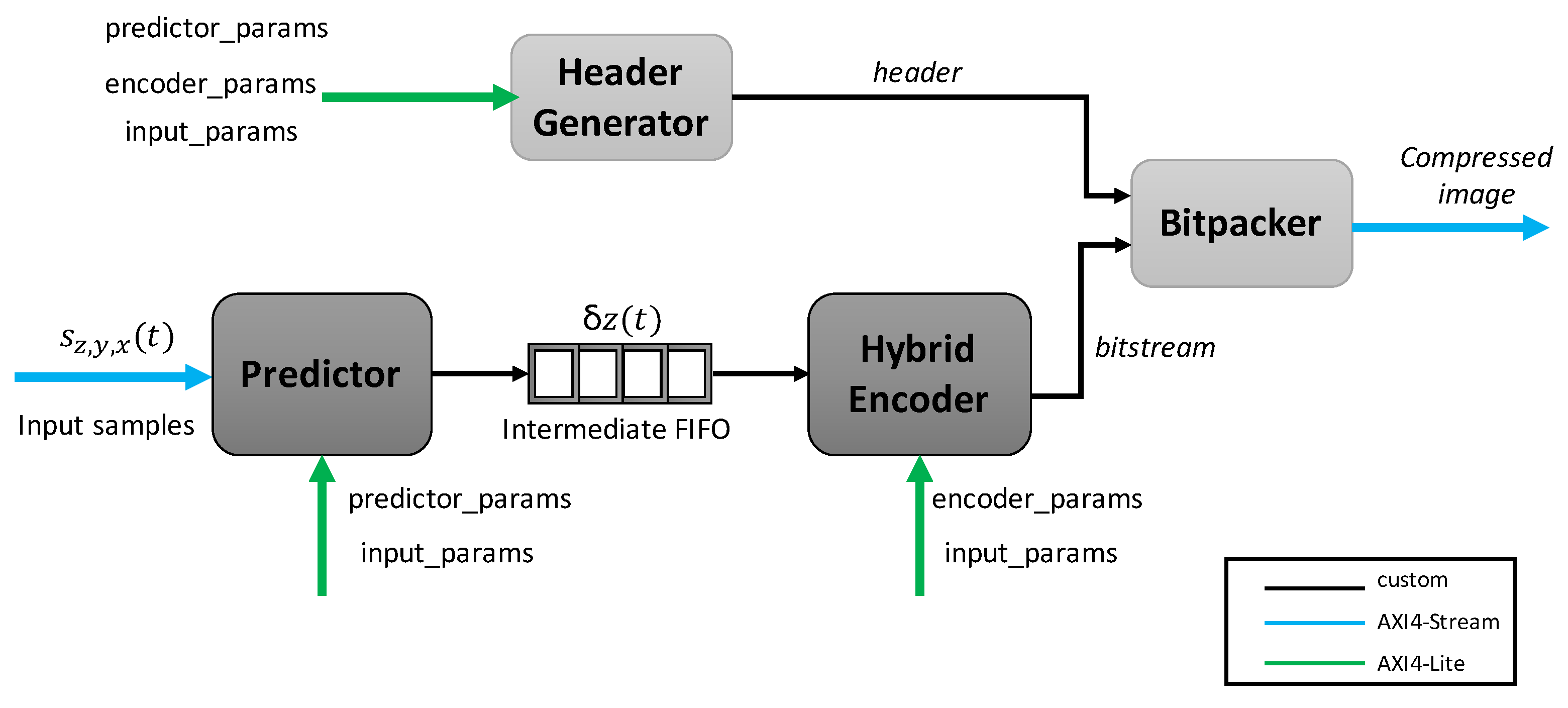
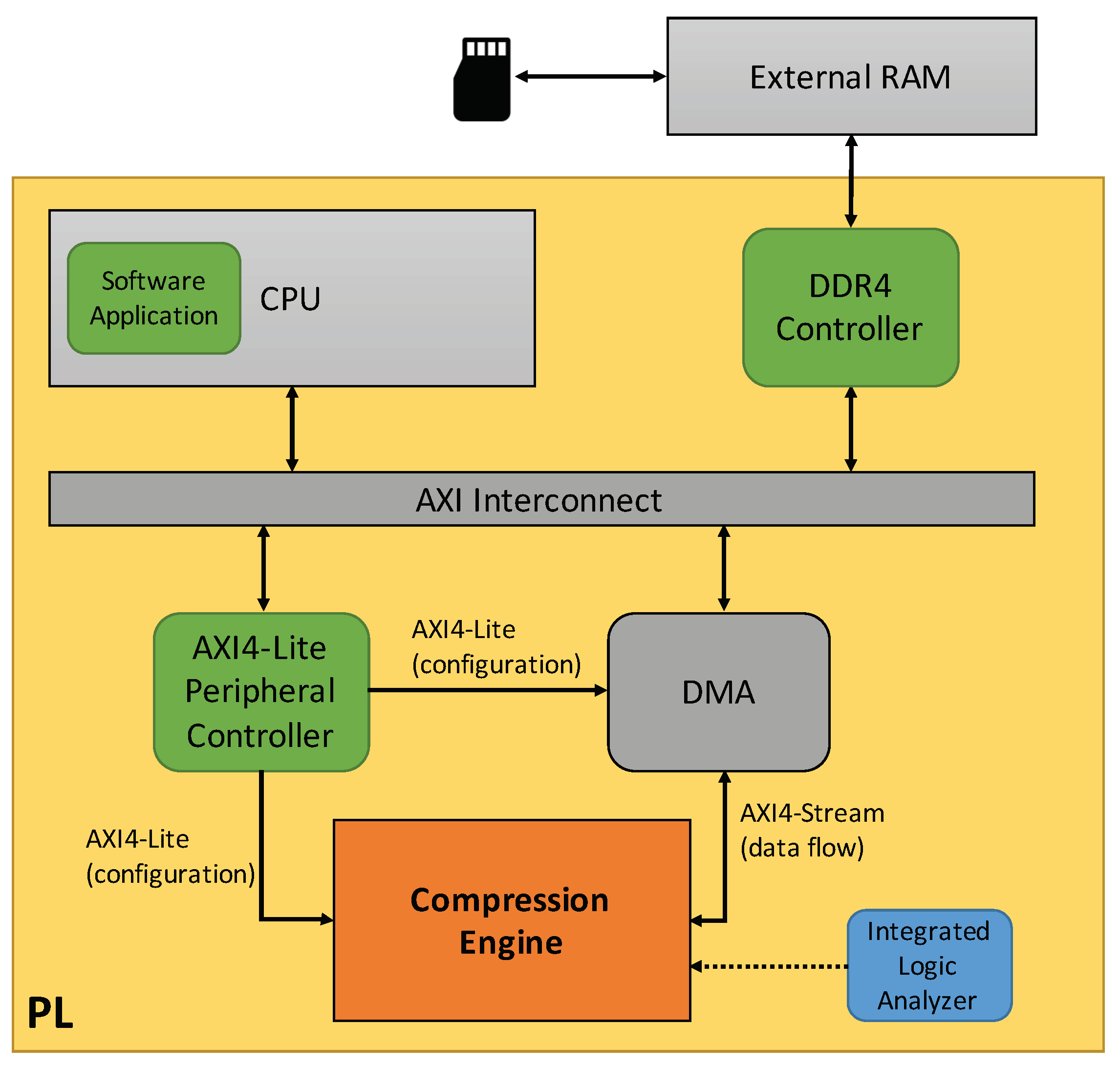
3. Hardware Design
3.1. Predictor
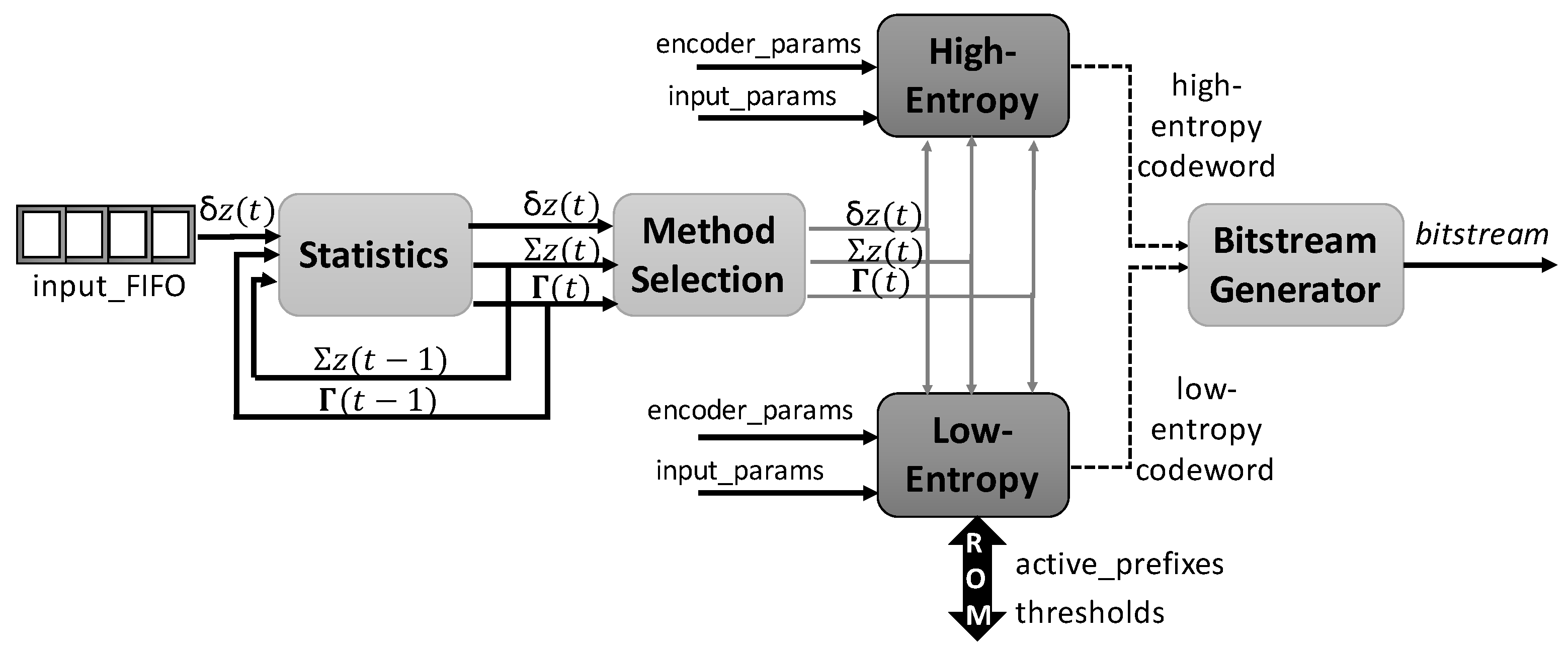
3.2. Hybrid Encoder
3.2.1. High-Entropy
- 1
- If , the codeword is comprised of the k least significant bits of , followed by a one and zeros. The parameter k is known as code index.
- 2
- Otherwise, the high-entropy codeword consists of the representation of with D bits, with D being the dynamic range of each input pixel, followed by zeros.
3.2.2. Low-Entropy
- 1
- If l value is not 0, v value is written to the bitstream using l bits and is reset to 0.
- 2
- If l value is equal to 0, is updated to v value ().
3.3. Header Generator
3.4. Bitpacker
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Qian, S.E. Introduction to Hyperspectral Satellites. In Hyperspectral Satellites and System Design; CRC Press, Taylor & Francis Group: Abingdon, UK, 2020; Chapter 1; pp. 1–52. [Google Scholar]
- Benediktsson, J.A.; Chanussot, J.; Moon, W.M. Very High-Resolution Remote Sensing: Challenges and Opportunities [Point of View]. Proc. IEEE 2012, 100, 1907–1910. [Google Scholar] [CrossRef]
- Fu, W.; Ma, J.; Chen, P.; Chen, F. Remote Sensing Satellites for Digital Earth. In Manual of Digital Earth; Guo, H., Goodchild, M.F., Annoni, A., Eds.; Springer: Singapore, 2020; pp. 55–123. [Google Scholar] [CrossRef] [Green Version]
- Montealegre, N.; Merodio, D.; Fernández, A.; Armbruster, P. In-flight reconfigurable FPGA-based space systems. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Montreal, QC, Canada, 15–18 June 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Boada Gardenyes, R. Trends and Patterns in ASIC and FPGA Use in Space Missions and Impact in Technology Roadmaps of the European Space Agency. Ph.D. Thesis, UPC, Escola Tècnica Superior d’Enginyeria Industrial de Barcelona, Barcelona, Spain, 2011. [Google Scholar]
- Habinc, S. Suitability of Reprogrammable FPGAs in Space Applications. Gaisler Research. 2002. Available online: http://microelectronics.esa.int/techno/fpga_002_01-0-4.pdf (accessed on 2 September 2021).
- Coussy, P.; Gajski, D.D.; Meredith, M.; Takach, A. An Introduction to High-Level Synthesis. IEEE Des. Test Comput. 2009, 26, 8–17. [Google Scholar] [CrossRef]
- Cong, J.; Liu, B.; Neuendorffer, S.; Noguera, J.; Vissers, K.; Zhang, Z. High-Level Synthesis for FPGAs: From Prototyping to Deployment. IEEE Trans. -Comput.-Aided Des. Integr. Circuits Syst. 2011, 30, 473–491. [Google Scholar] [CrossRef] [Green Version]
- Consultative Committee for Space Data Systems. Low-Complexity Lossless and Near-Lossless Multispectral and Hyperspectral Image Compression, CCSDS 123.0-B-2; CCSDS: Washington, DC, USA, 2019; Volume 2. [Google Scholar]
- Blanes, I.; Kiely, A.; Hernández-Cabronero, M.; Serra-Sagristà, J. Performance Impact of Parameter Tuning on the CCSDS-123.0-B-2 Low-Complexity Lossless and Near-Lossless Multispectral and Hyperspectral Image Compression Standard. Remote Sens. 2019, 11, 1390. [Google Scholar] [CrossRef] [Green Version]
- Hernandez-Cabronero, M.; Kiely, A.B.; Klimesh, M.; Blanes, I.; Ligo, J.; Magli, E.; Serra-Sagrista, J. The CCSDS 123.0-B-2 Low-Complexity Lossless and Near-Lossless Multispectral and Hyperspectral Image Compression Standard: A comprehensive review. IEEE Geosci. Remote Sens. Mag. 2021, in press. [Google Scholar] [CrossRef]
- Barrios, Y.; Rodríguez, P.; Sánchez, A.; González, M.; Berrojo, L.; Sarmiento, R. Implementation of cloud detection and processing algorithms and CCSDS-compliant hyperspectral image compression for CHIME mission. In Proceedings of the 7th International Workshop on On-Board Payload Data Compression (OBPDC), Online Event, 21–23 September 2020; pp. 1–8. [Google Scholar]
- Chatziantoniou, P.; Tsigkanos, A.; Kranitis, N. A high-performance RTL implementation of the CCSDS-123.0-B-2 hybrid entropy coder on a space-grade SRAM FPGA. In Proceedings of the 7th International Workshop on On-Board Payload Data Compression (OBPDC), Online Event, 21–23 September 2020; pp. 1–8. [Google Scholar]
- Consultative Committee for Space Data Systems. Lossless Multispectral and Hyperspectral Image Compression, Recommended Standard CCSDS 123.0-B-1; CCSDS: Washington, DC, USA, 2012; Volume 1. [Google Scholar]
- Santos, L.; Gomez, A.; Sarmiento, R. Implementation of CCSDS Standards for Lossless Multispectral and Hyperspectral Satellite Image Compression. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 1120–1138. [Google Scholar] [CrossRef]
- Barrios, Y.; Sánchez, A.; Santos, L.; Sarmiento, R. SHyLoC 2.0: A versatile hardware solution for on-board data and hyperspectral image compression on future space missions. IEEE Access 2020, 8, 54269–54287. [Google Scholar] [CrossRef]
- Tsigkanos, A.; Kranitis, N.; Theodorou, G.A.; Paschalis, A. A 3.3 Gbps CCSDS 123.0-B-1 multispectral & Hyperspectral image compression hardware accelerator on a space-grade SRAM FPGA. IEEE Trans. Emerg. Top. Comput. 2018, 9, 90–103. [Google Scholar]
- Fjeldtvedt, J.; Orlandic, M.; Johansen, T.A. An Efficient Real-Time FPGA Implementation of the CCSDS-123 Compression Standard for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3841–3852. [Google Scholar] [CrossRef] [Green Version]
- Bascones, D.; Gonzalez, C.; Mozos, D. FPGA Implementation of the CCSDS 1.2.3 Standard for Real-Time Hyperspectral Lossless Compression. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1158–1165. [Google Scholar] [CrossRef]
- Orlandic, M.; Fjeldtvedt, J.; Johansen, T.A. A Parallel FPGA Implementation of the CCSDS-123 Compression Algorithm. Remote Sens. 2019, 11, 673. [Google Scholar] [CrossRef] [Green Version]
- Bascones, D.; Gonzalez, C.; Mozos, D. Parallel Implementation of the CCSDS 1.2.3 Standard for Hyperspectral Lossless Compression. Remote Sens. 2017, 9, 973. [Google Scholar] [CrossRef] [Green Version]
- Barrios, Y.; Rodríguez, A.; Sánchez, A.; Pérez, A.; López, S.; Otero, A.; de la Torre, E.; Sarmiento, R. Lossy Hyperspectral Image Compression on a Reconfigurable and Fault-Tolerant FPGA-Based Adaptive Computing Platform. Electronics 2020, 9, 1576. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Allowed Values | Description |
|---|---|---|
| [8:32] | Unary Length Limit | |
| [max(4, + 1):9] | Rescaling Counter Size | |
| [1:8] | Initial Count Exponent |
| Parameter | Value |
|---|---|
| Image parameters | |
| Columns, | 677 |
| Lines, | 512 |
| Bands, | 224 |
| Dynamic Range, D | 16 |
| Encoding Order | BIL |
| Predictor parameters | |
| Bands for Prediction, P | 3 |
| Local Sum Mode | Narrow Neighbour-Oriented |
| Prediction Mode | Full Prediction |
| Weight Resolution, | 16 |
| Sample Adaptive Resolution, | 2 |
| Sample Adaptive Offset, | 1 |
| Sample Adaptive Damping, | 1 |
| Error Method | Absolute |
| Absolute Error Bitdepth, | 8 |
| Absolute Error Value, | 4 |
| Encoder parameters | |
| Unary Length Limit, | 16 |
| Rescaling Counter Size, | 5 |
| Initial Count Exponent, | 1 |
| 36 Kb BRAM | DSP48E | Registers | LUTs | |
|---|---|---|---|---|
| Predictor | 76 (12.7%) | 54 (2.8%) | 6054 (1.3%) | 10,087 (4.1%) |
| Hybrid Encoder | 9 (1.5%) | 9 (0.5%) | 2498 (0.5%) | 4286 (1.8%) |
| Header generator | 0 (0%) | 0 (0%) | 2976 (0.6%) | 2478 (1.0%) |
| Bitpacker | 0 (0%) | 0 (0%) | 387 (0.1%) | 334 (0.1%) |
| Total | 85 (14.2%) | 63 (3.3%) | 11,915 (2.5%) | 17,185 (7.0%) |
| Implementation | Development Time (Months) | Encoder | LUTs | FFs | DSPs | BRAMs | Freq. (MHz) | Throughput (MSamples/s) |
|---|---|---|---|---|---|---|---|---|
| SHyLoC 2.0 [16] | 24 | Sample | 5975 | 3599 | 13 | 74 | 152 | 59.4 |
| This work | 6 | Hybrid | 17,185 | 11,915 | 63 | 85 | 125 | 17.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barrios, Y.; Sánchez, A.; Guerra, R.; Sarmiento, R. Hardware Implementation of the CCSDS 123.0-B-2 Near-Lossless Compression Standard Following an HLS Design Methodology. Remote Sens. 2021, 13, 4388. https://doi.org/10.3390/rs13214388
Barrios Y, Sánchez A, Guerra R, Sarmiento R. Hardware Implementation of the CCSDS 123.0-B-2 Near-Lossless Compression Standard Following an HLS Design Methodology. Remote Sensing. 2021; 13(21):4388. https://doi.org/10.3390/rs13214388
Chicago/Turabian StyleBarrios, Yubal, Antonio Sánchez, Raúl Guerra, and Roberto Sarmiento. 2021. "Hardware Implementation of the CCSDS 123.0-B-2 Near-Lossless Compression Standard Following an HLS Design Methodology" Remote Sensing 13, no. 21: 4388. https://doi.org/10.3390/rs13214388