
A Novel Guided Anchor Siamese Network for Arbitrary Target-of-Interest Tracking in Video-SAR




Abstract
:1. Introduction
- We established a new network GASN, which trains a large number of paired images to build a matching function to judge the degree of similarity between two inputs. After similarity learning, GASN matches the subsequent frame with the initial area of the TOI in the first frame and returns the most similar area as the tracking result.
- We constructed a GA-SubNet embedded in GASN to suppress false alarms, as well as to improve the tracking accuracy. By incorporating the prior information of the template, our proposed GA-SubNet can generate sparse anchors that match the shape of the TOI the most.
2. Methodology
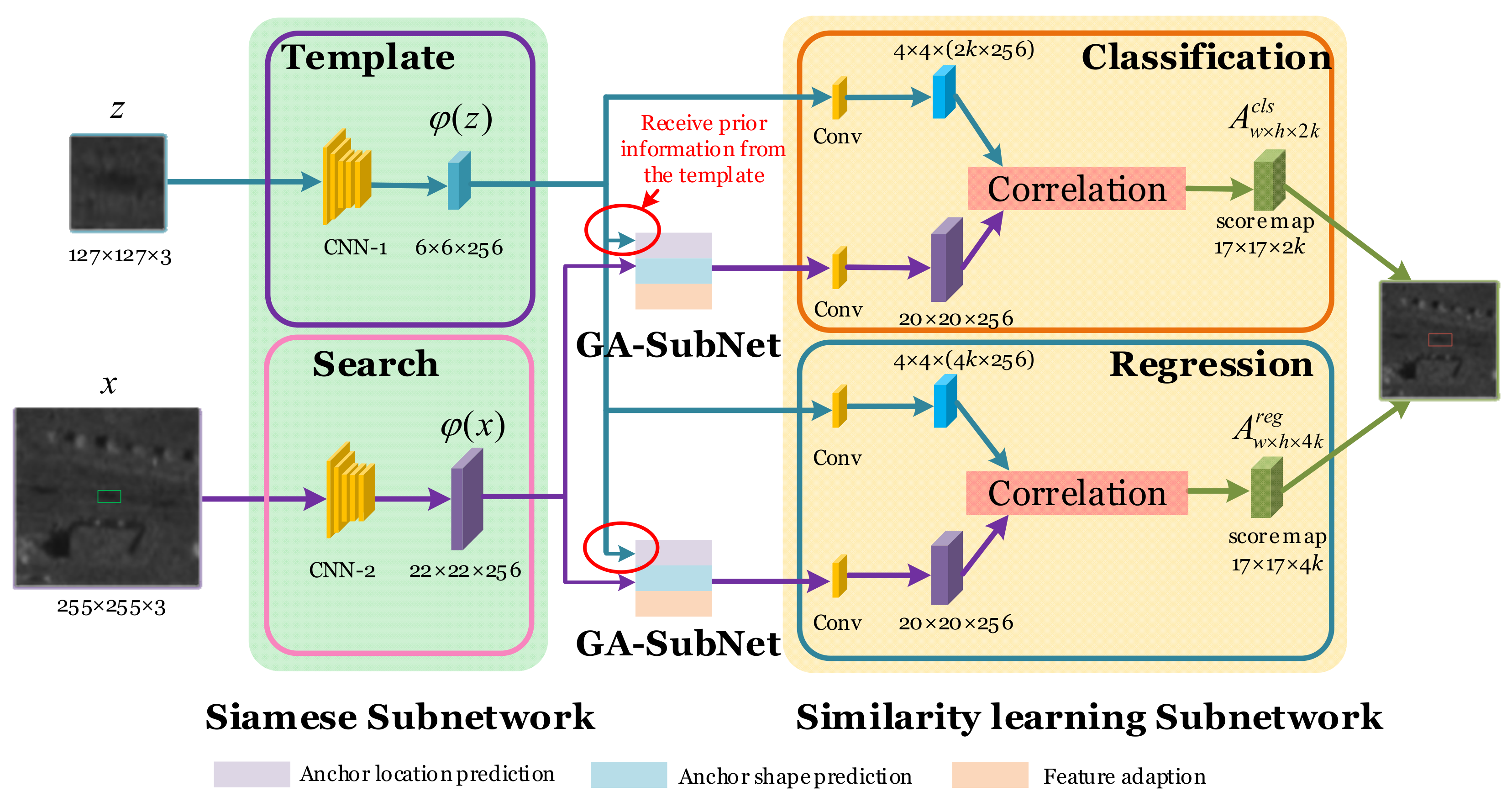
2.1. Network Architecture
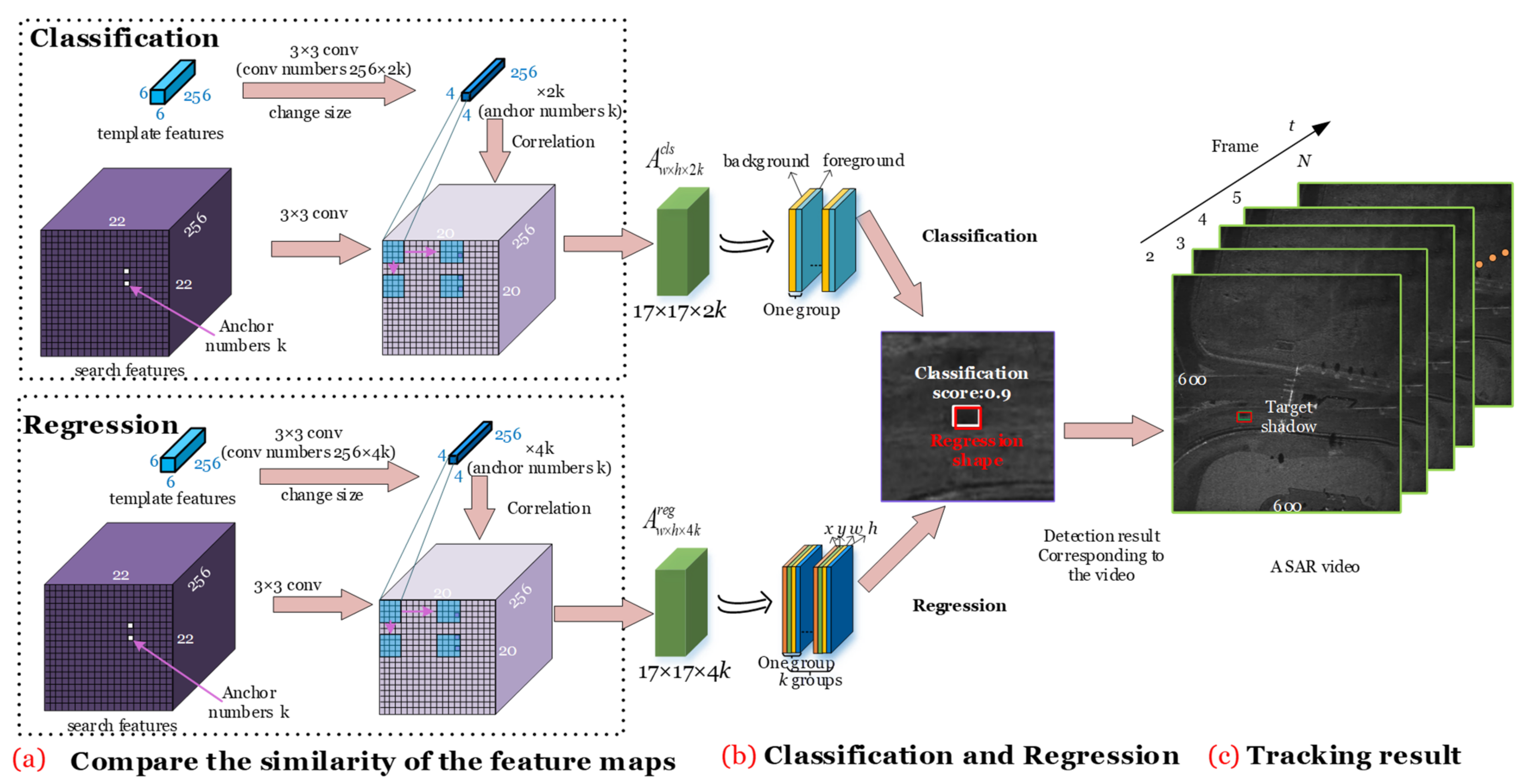
2.1.1. Siamese Subnetwork
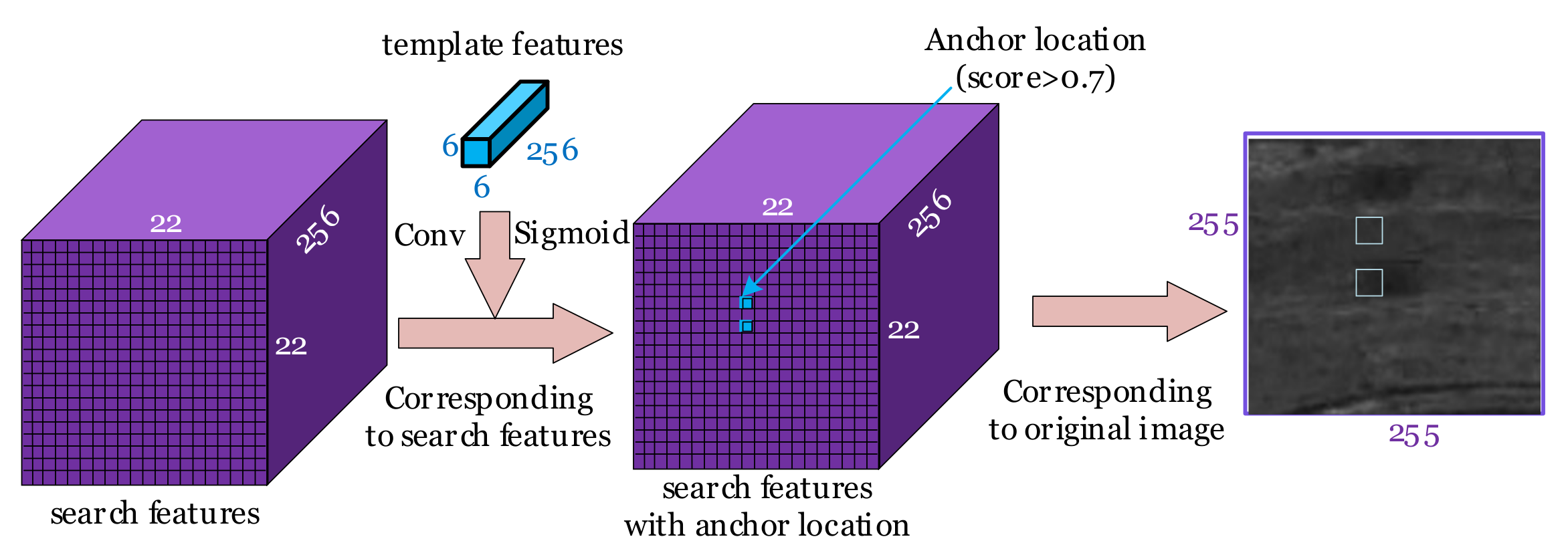
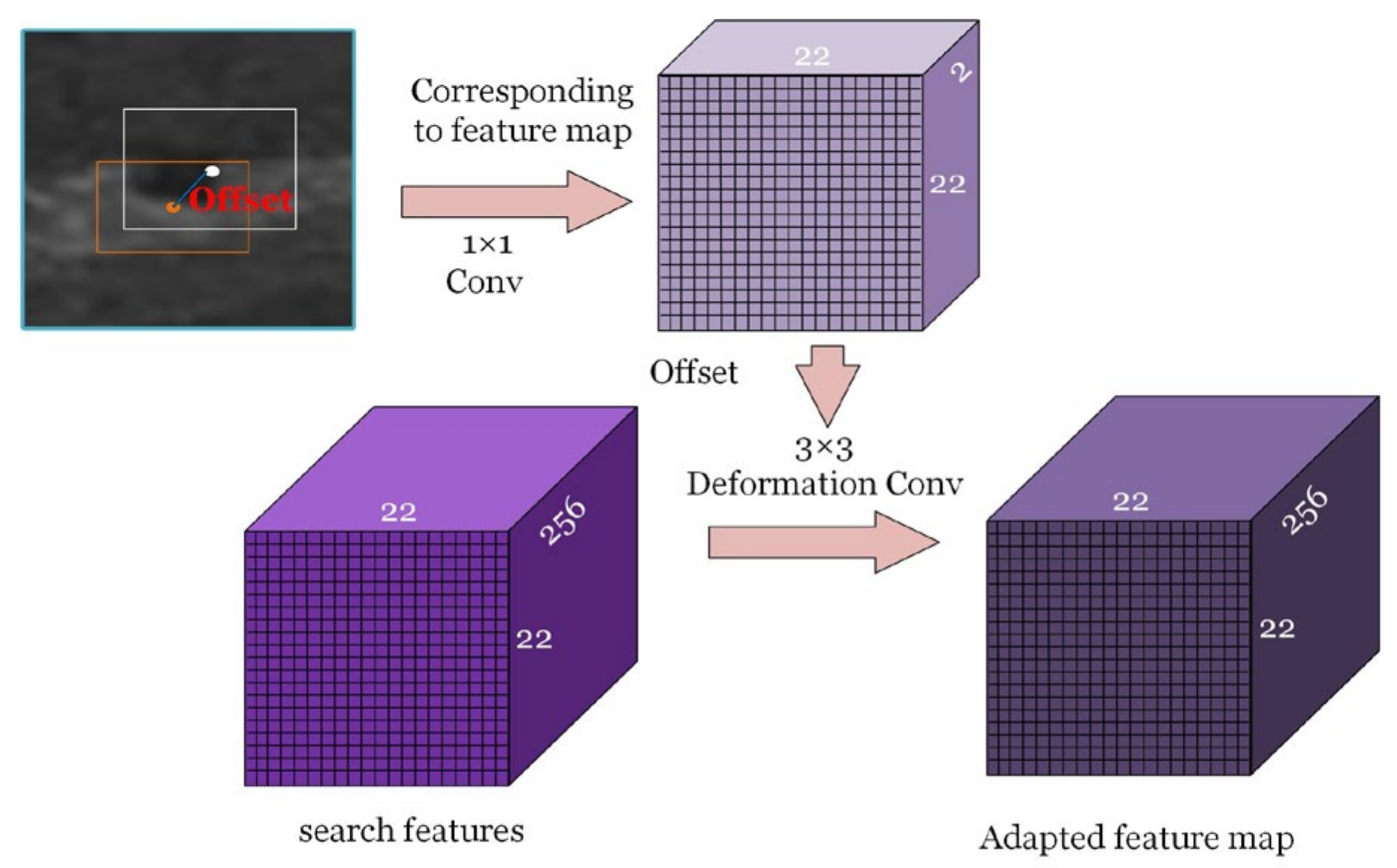
2.1.2. GA-SubNet
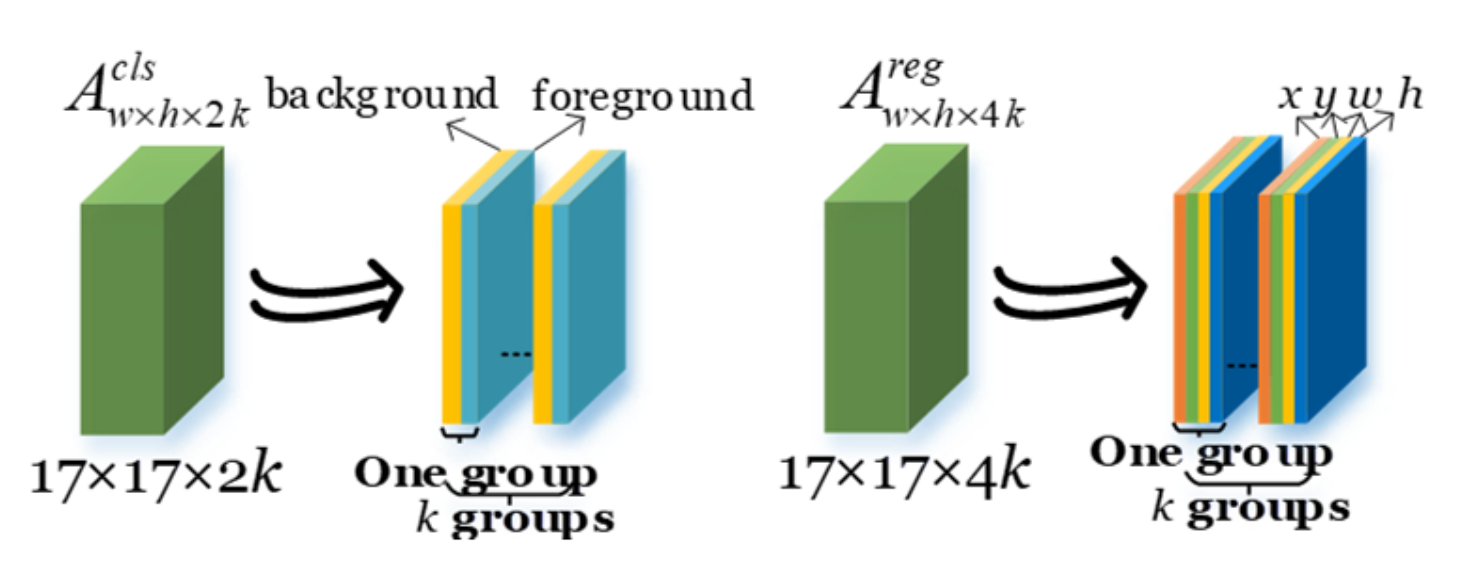
2.1.3. Similarity Learning Subnetwork
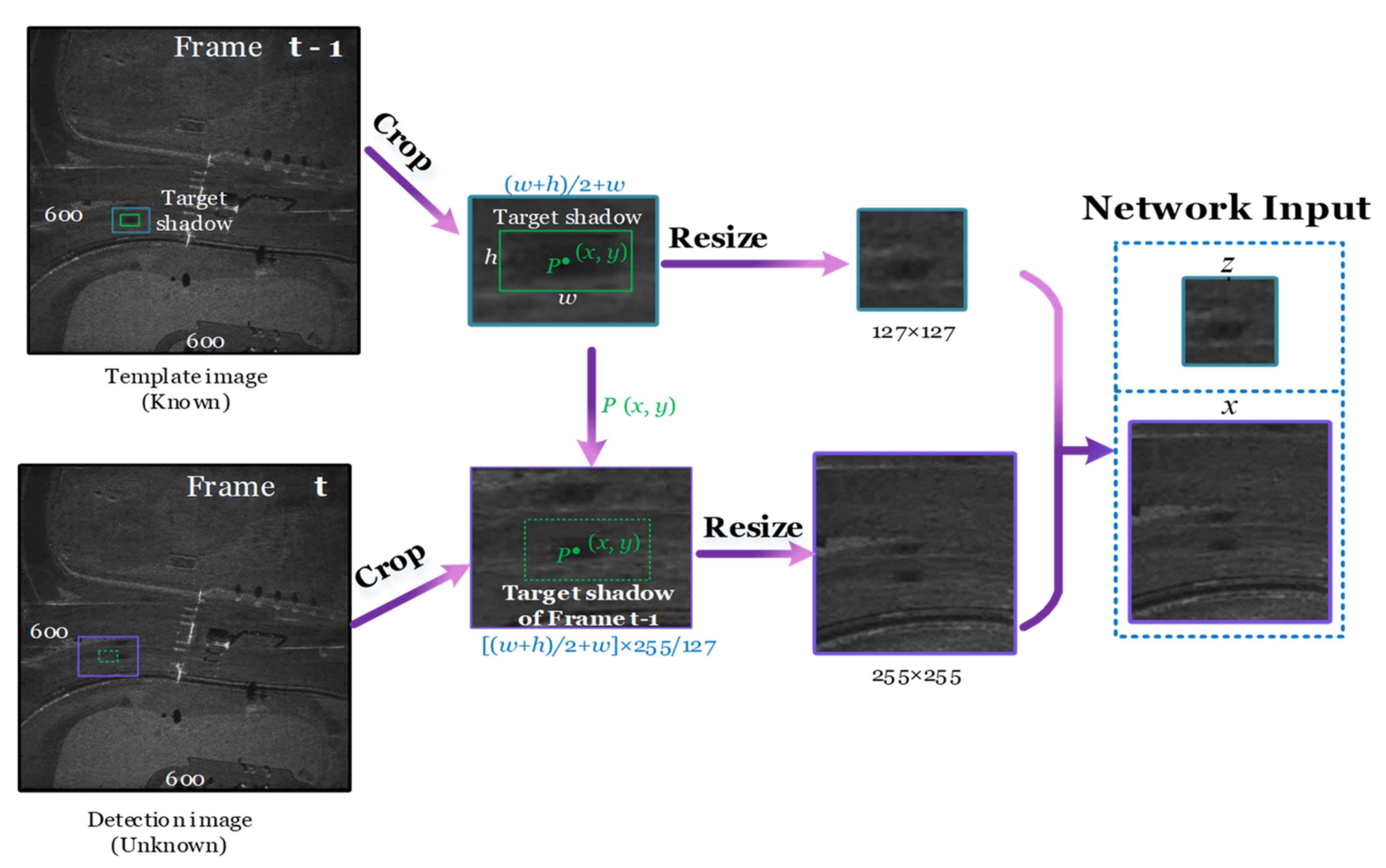
2.2. Preprocessing
2.3. Tracking Process
| Algorithm 1: GASN tracks arbitrary TOI in Video-SAR | |
| Input: Video-SAR images sequence. | |
| Begin | |
| 1 | do Pre-process the SAR images. |
| 2 | |
| 3 | do Embed features by Siamese subnetwork. |
| 4 | |
| 5 | do Predict anchor location. |
| 6 | |
| 7 | do Predict anchor shape. |
| 8 | |
| 9 | do Adapt the feature map guided by anchors. |
| 10 | |
| 11 | do Compare the similarity of the feature maps. |
| 12 | |
| 13 | do Classification and regression. |
| 14 | |
| End | |
| Output: Tracking results. | |
3. Experiments
3.1. Experimental Data
3.2. Implementation Details
3.3. Loss Function
3.4. Evaluation indicators
3.4.1. Tracking Accuracy
3.4.2. Tracking Stability
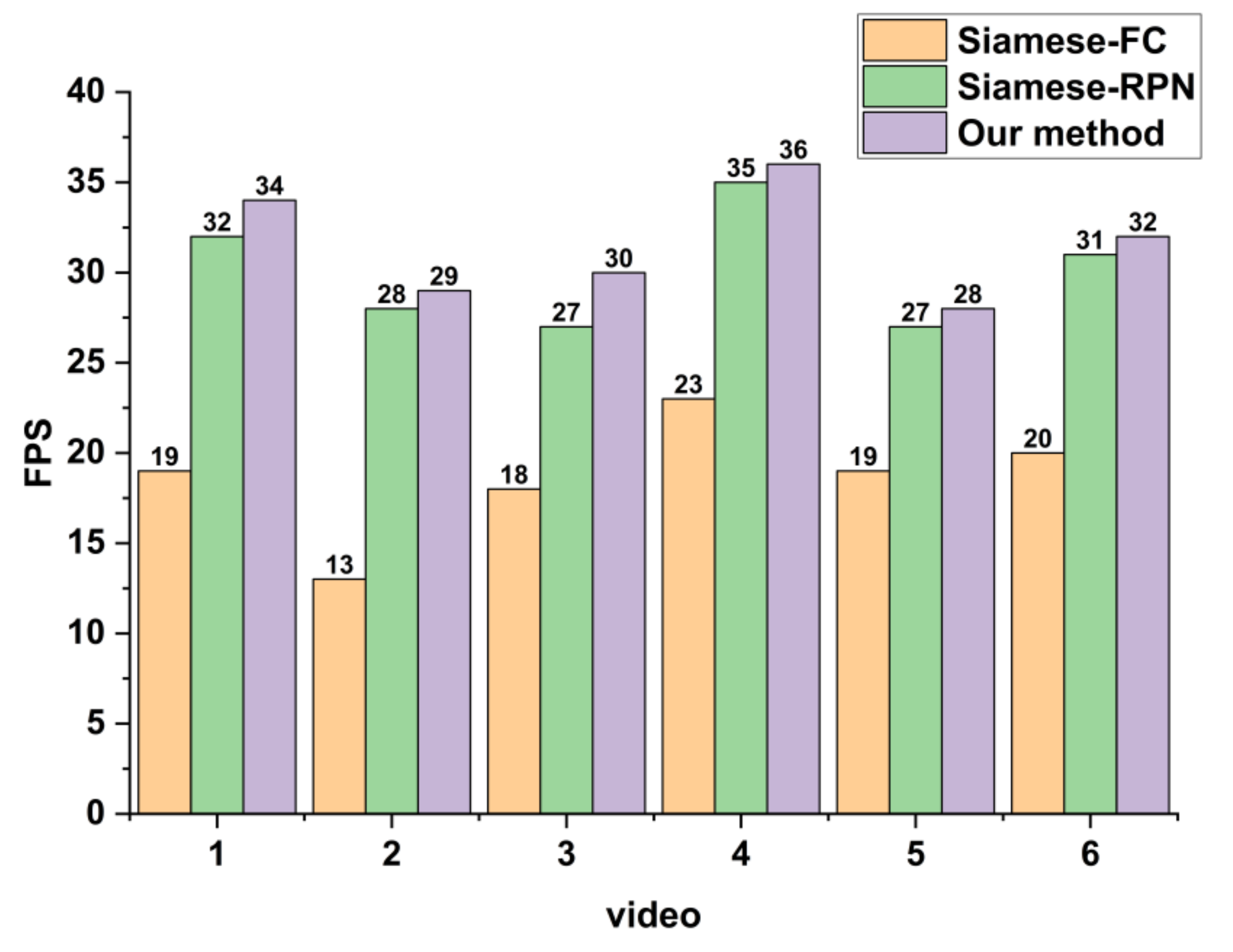
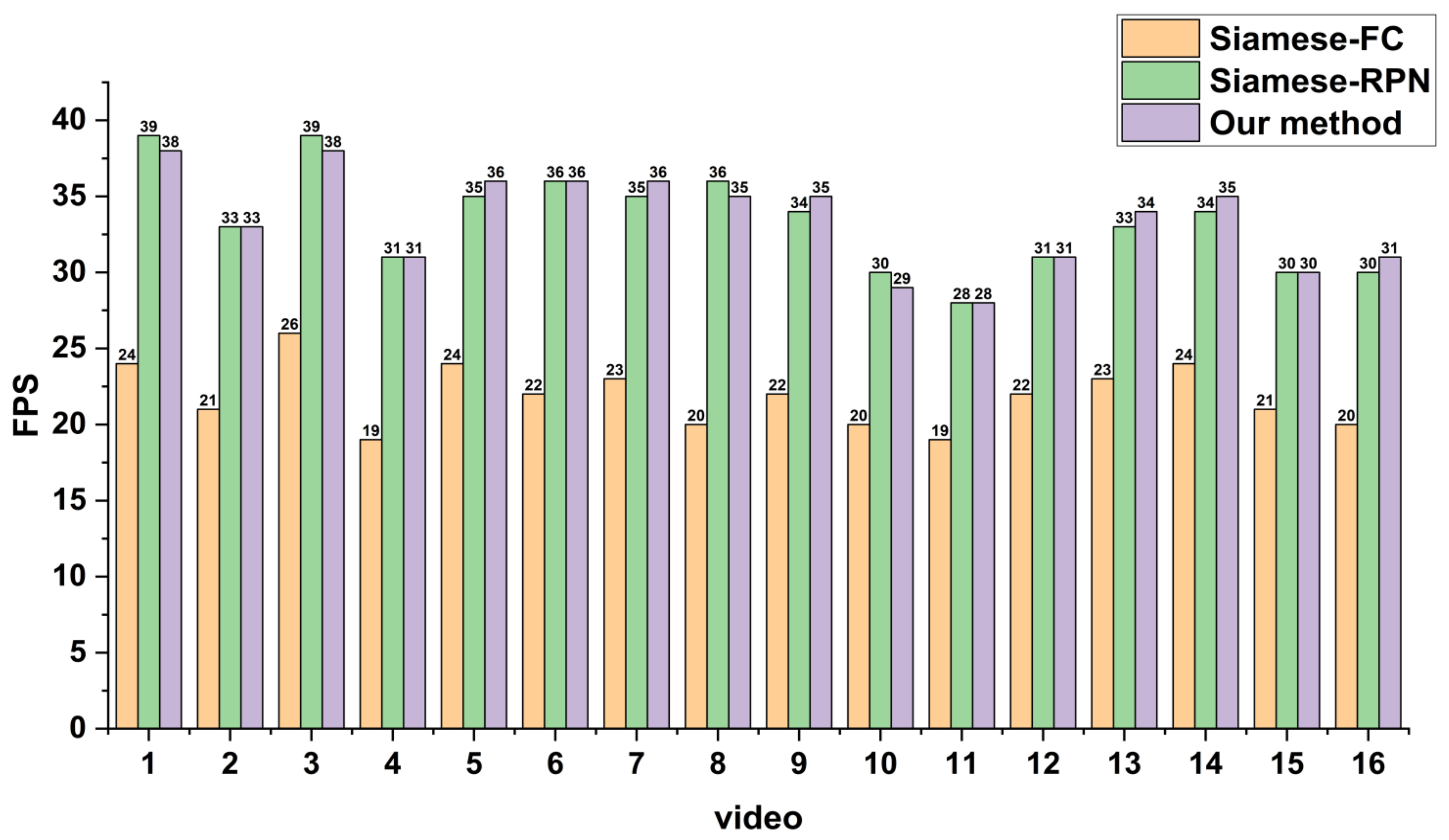
3.4.3. Tracking Speed
4. Results
4.1. Results of the Simulated Video-SAR Data
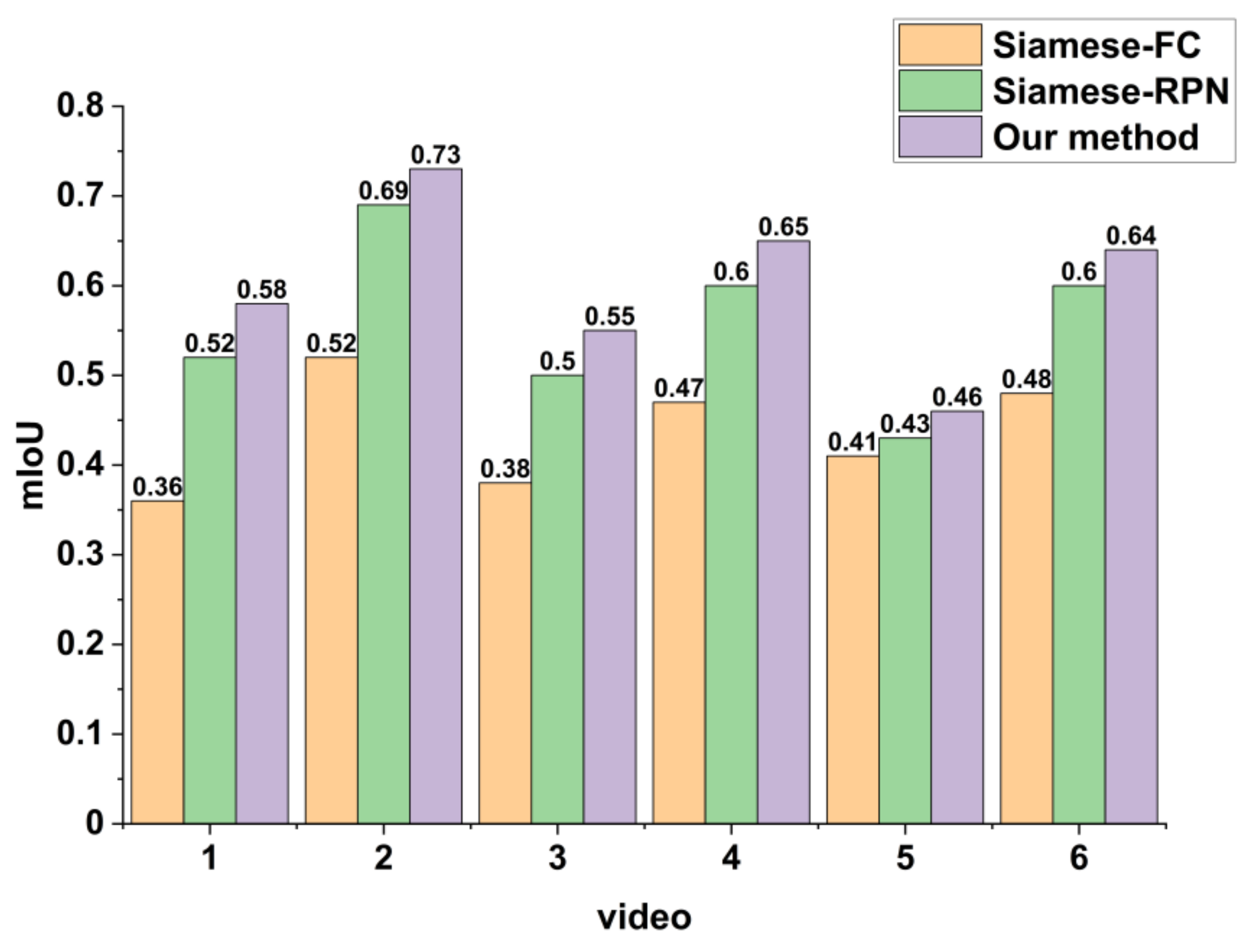
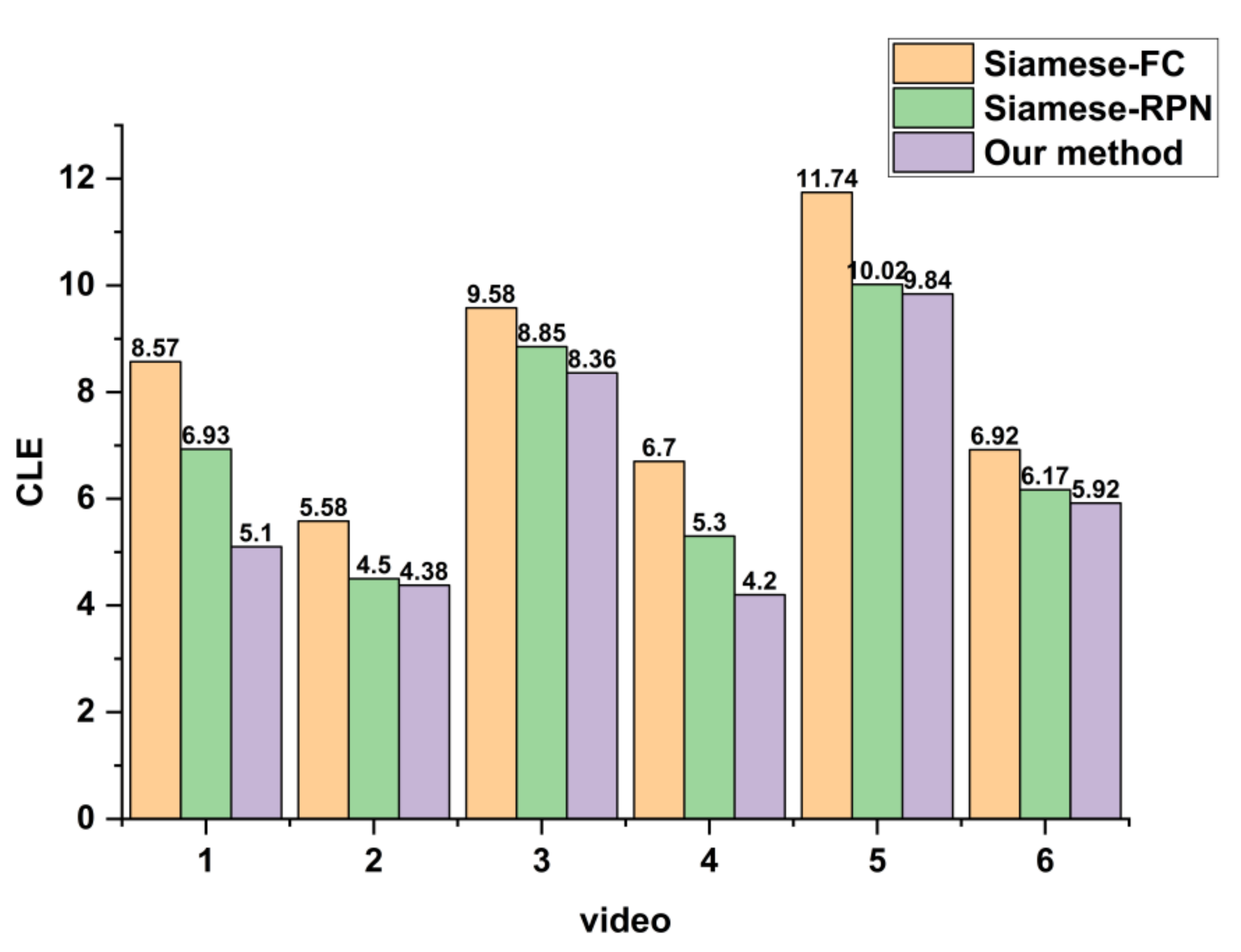
4.1.1. Comparison with Other Tracking Methods
4.1.2. Tracking Results with Distractors
4.1.3. Tracking Results of the Target with a Specific Speed
4.2. Results of Real Video-SAR Data
4.2.1. Comparison with Other Tracking Methods
4.2.2. Tracking Results with Clutter
4.2.3. Tracking Results of Different Frame Rates
4.2.4. Tracking Results of another Real Video-SAR Dataset
5. Discussion
5.1. Research on the Transfer
5.2. Ablation Experiment of GA-SubNet
5.3. Research on Pre-Training
5.4. Research on the Statistical Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Symbol | Definition |
| x | Search image |
| φ(x) | Detected feature map |
| g | Similarity learning function |
| F2 | New detected feature map for the best anchor shape |
| Similarity map regression | |
| (w, h) | The weight and height of the shadow |
| Anchor location loss | |
| Classification loss | |
| P | The tracking result |
| The center coordinates of the tracking result | |
| t | The total tracking time |
| z | Template image |
| φ(z) | Template feature map |
| F1 | Original detected feature map |
| k | The number of anchors |
| Similarity map for classification | |
| (x, y) | The center point of the shadow in the previous image |
| Anchor shape loss | |
| Regression loss | |
| G | The shadow’s ground truth |
| The center coordinates of the shadow’s ground truth | |
| N | The number of frames of the Video-SAR sequence |
References
- Damini, A.; Balaji, B.; Parry, C.; Mantle, V. A videoSAR mode for the X-band wideband experimental airborne radar. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XVII, Orlando, FL, USA, 18 April 2010; p. 76990E. [Google Scholar]
- Wells, L.; Sorensen, K.; Doerry, R.B. Developments in SAR and IFSAR systems and technologies at Sandia National Laboratories. In Proceedings of the 2003 IEEE Aerospace Conference Proceedings (Cat. No. 03TH8652.), Big Sky, MT, USA, 8–15 March 2003; pp. 21085–21095. [Google Scholar]
- Hawley, R.W.; Garber, W.L. Aperture weighting technique for video synthetic aperture radar. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XVIII, Orlando, FL, USA, 4 May 2011; p. 805107. [Google Scholar]
- Linnehan, R.; Miller, J.; Bishop, E.; Horndt, V. An autofocus technique for video-SAR. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XX, Baltimore, MD, USA, 23 May 2013; p. 874608. [Google Scholar]
- Miller, J.; Bishop, E.; Doerry, A. An application of backprojection for Video-SAR image formation exploiting a subaperature circular shift register. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XX, Baltimore, MD, USA, 23 May 2013; p. 874609. [Google Scholar]
- Wang, H.; Chen, Z.; Zheng, S. Preliminary research of low-RCS moving target detection based on Ka-band Video-SAR. IEEE Geosci. Remote Sens. Lett. 2017, 14, 811–815. [Google Scholar] [CrossRef]
- Henke, D.; Dominguez, E.M.; Small, D.; Schaepman, M.E.; Meier, E. Moving target tracking in single-and multichannel SAR. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3146–3159. [Google Scholar] [CrossRef]
- Yang, X.; Shi, J.; Zhou, Y.; Wang, C.; Wei, S. Ground Moving Target Tracking and Refocusing Using Shadow in Video-SAR. Remote Sens. 2020, 12, 3083. [Google Scholar] [CrossRef]
- Ying, Z.; Daiyin, Z.; Xiang, Y.; Mao, X. Approach to moving targets shadow detection for VideoSAR. J. Electron. Inf. Technol. 2017, 39, 2197–2202. [Google Scholar]
- Zhao, B.; Han, Y.; Wang, H.; Tang, L.; Wang, T. Robust Shadow Tracking for Video-SAR. IEEE Geosci. Remote Sens. Lett. 2020, 18, 821–825. [Google Scholar] [CrossRef]
- Tian, X.; Liu, J.; Mallick, M. Simultaneous Detection and Tracking of Moving-Target Shadows in ViSAR Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1182–1199. [Google Scholar] [CrossRef]
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video-SAR Moving Target Indication Using Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:150601497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gers, F.A.; Schmidhuber, J.; Cummins, F.A. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Shi, J.; Wang, C.; Hu, H.; Zhou, Z.; Yang, X.; Zhang, X.; Wei, S. SAR Ground Moving Target Refocusing by Combining mRe3 Network and TVβ -LSTM. IEEE Trans. Geosci. Remote Sens. 2020, 1–4. [Google Scholar] [CrossRef]
- Wen, L.; Ding, J.; Loffeld, O. Video-SAR Moving Target Detection Using Dual Faster R-CNN. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2984–2994. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zheng, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P. Fully-convolutional siamese networks for object tracking. In Proceedings of the European conference on computer vision, Amsterdam, The Netherlands, 3 November 2016; pp. 850–865. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1420–1429. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European conference on computer vision, Amsterdam, The Netherlands, 3 November 2016; pp. 749–765. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 24–27 October 2017; pp. 764–773. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 24– 27 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; CL Chen, C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2965–2974. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; He, Z. The visual object tracking vot2017 challenge results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1949–1972. [Google Scholar]
- Van Sloun, R.J.G.; Cohen, R.; Eldar, Y. Deep Learning in Ultrasound Imaging. Proc. IEEE 2019, 108, 11–29. [Google Scholar] [CrossRef] [Green Version]
- Yin, S.; Peng, Q.; Li, H.; Zhang, Z.; You, X.; Fischer, K.; Furth, S.L.; Tasian, G.E.; Fan, Y. Computer-Aided Diagnosis of Congenital Abnormalities of the Kidney and Urinary Tract in Children Using a Multi-Instance Deep Learning Method Based on Ultrasound Imaging Data. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1347–1350. [Google Scholar] [CrossRef]
- Einsidler, D.; Dhanak, M.; Beaujean, P. A Deep Learning Approach to Target Recognition in Side-Scan Sonar Imagery. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lopes, A.; Touzi, R.; Nezry, E. Adaptive speckle filters and scene heterogeneity. IEEE Trans. Geosci. Remote Sens. 1990, 28, 992–1000. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Center frequency/GHz Platform velocity/m s−1 Platform height/m | 35 300 8000 |
| Pulse repetition frequency/Hz | 4000 |
| Total record time/s SNR | 10 40 dB |
| Target | Azimuth Velocity (m s−1) | Radial Velocity (m s−1) |
|---|---|---|
| T1 | 6 | –8 |
| T2 | –1 | –2 |
| T3 | 1.5 | –3 |
| T4 | 0.4 | –0.8 |
| T5 | 3 | 1.5 |
| T6 | 1.5 | –1.5 |
| Method | Accuracy | CLE | FPS |
|---|---|---|---|
| MOSSE | 31.21% | 19.76 | 105 |
| KCF | 41.80% | 11.30 | 58 |
| Siamese-FC | 43.67% | 8.46 | 19 |
| Siamese-RPN | 55.61% | 7.94 | 31 |
| GASN (ours) | 60.16% | 6.68 | 32 |
| Method | Accuracy | CLE | FPS |
|---|---|---|---|
| MOSSE | 29.64% | 37.64 | 125 |
| KCF | 39.98% | 18.79 | 54 |
| Siamese-FC | 41.60% | 15.41 | 21 |
| Siamese-RPN | 52.75% | 14.69 | 33 |
| GASN (ours) | 54.68% | 11.37 | 33 |
| Method | Accuracy | CLE | FPS |
|---|---|---|---|
| MOSSE | 30.70% | 38.73 | 65 |
| KCF | 46.30% | 19.03 | 58 |
| Siamese-FC | 51.70% | 16.81 | 21 |
| Siamese-RPN | 53.68% | 12.04 | 20 |
| GASN (ours) | 55.01% | 11.78 | 19 |
| Train Data | Test Data | Accuracy |
|---|---|---|
| Simulated | Simulated | 60.16% |
| Real | Simulated | 59.26% |
| Train Data | Test Data | Accuracy |
|---|---|---|
| Real | Real | 54.68% |
| Simulated | Real | 53.38% |
| Method | GA-SubNet | Accuracy |
|---|---|---|
| Siamese-RPN | ✗ | 55.57% |
| GASN (ours) | ✓ | 60.09% |
| Pre-Training | Accuracy |
|---|---|
| ✗ | 56.73% |
| ✓ | 60.09% |
| Method | Accuracy % | CLE |
|---|---|---|
| Siamese-RPN | 56.37 ± 0.72 | 7.49 ± 0.98 |
| GASN (ours) | 58.79 ± 0.61 | 6.56 ± 0.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, J.; Zhang, X.; Zhang, T.; Shi, J.; Wei, S. A Novel Guided Anchor Siamese Network for Arbitrary Target-of-Interest Tracking in Video-SAR. Remote Sens. 2021, 13, 4504. https://doi.org/10.3390/rs13224504
Bao J, Zhang X, Zhang T, Shi J, Wei S. A Novel Guided Anchor Siamese Network for Arbitrary Target-of-Interest Tracking in Video-SAR. Remote Sensing. 2021; 13(22):4504. https://doi.org/10.3390/rs13224504
Chicago/Turabian StyleBao, Jinyu, Xiaoling Zhang, Tianwen Zhang, Jun Shi, and Shunjun Wei. 2021. "A Novel Guided Anchor Siamese Network for Arbitrary Target-of-Interest Tracking in Video-SAR" Remote Sensing 13, no. 22: 4504. https://doi.org/10.3390/rs13224504
APA StyleBao, J., Zhang, X., Zhang, T., Shi, J., & Wei, S. (2021). A Novel Guided Anchor Siamese Network for Arbitrary Target-of-Interest Tracking in Video-SAR. Remote Sensing, 13(22), 4504. https://doi.org/10.3390/rs13224504