
Developing a Method to Extract Building 3D Information from GF-7 Data

 ,
, 
Abstract
:1. Introduction
- The GaoFen-7 (GF-7) multi-view satellite image can describe the vertical structure of a ground object well. However, there are few studies on the extraction of building information from GF-7 satellite images, and satellite vertical structure extraction capabilities still require evaluation.
2. Data and Study Area
3. Methodology
3.1. Overview
3.2. Building Footprint Extraction
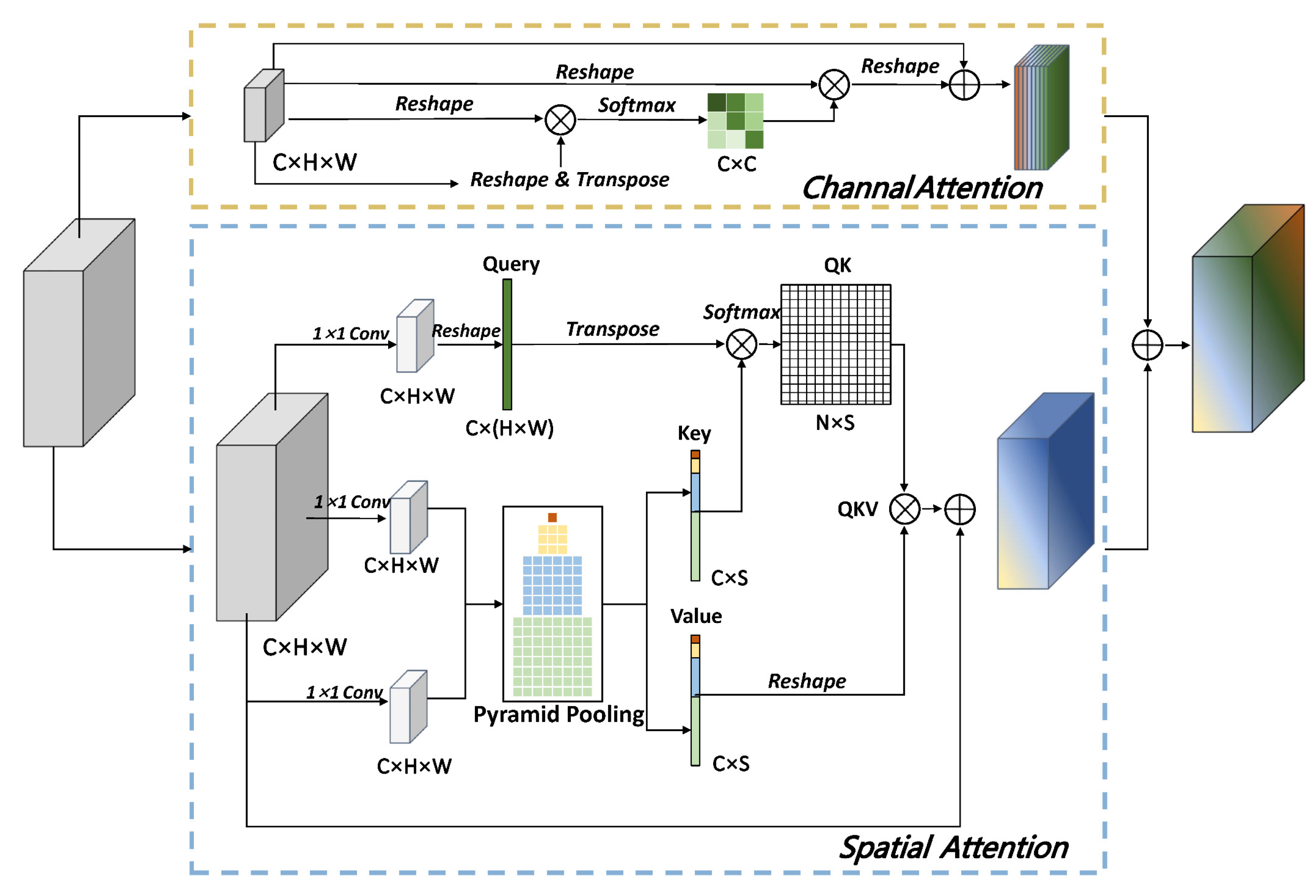
3.2.1. Attention Block
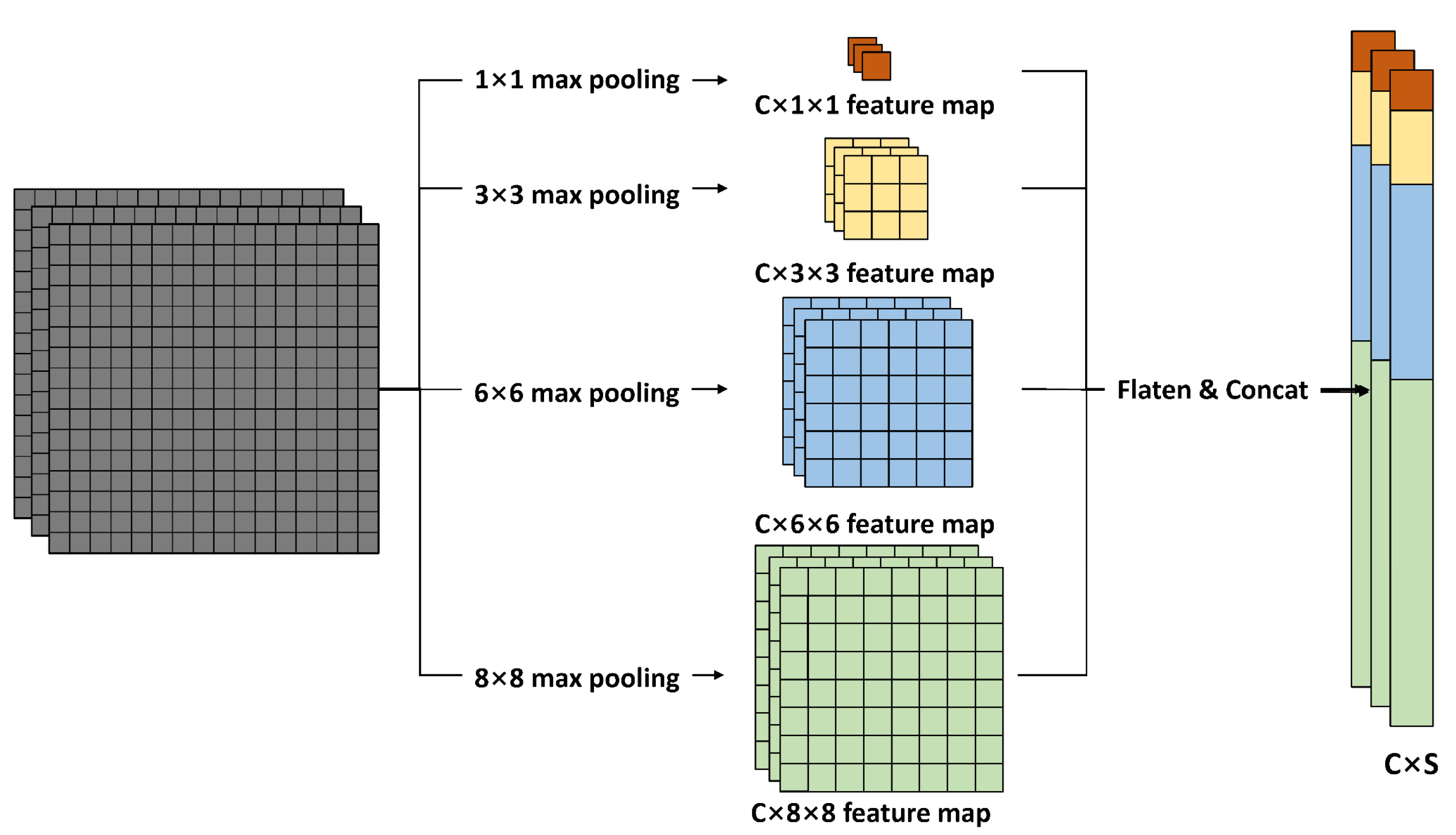
- Spatial Attention Block
- 2.
- Channel Attention Block
3.2.2. Training Strategy
3.3. Point Cloud Generation
3.4. Building Height Extraction
3.5. Evaluation Metrics
4. Results and Discussion
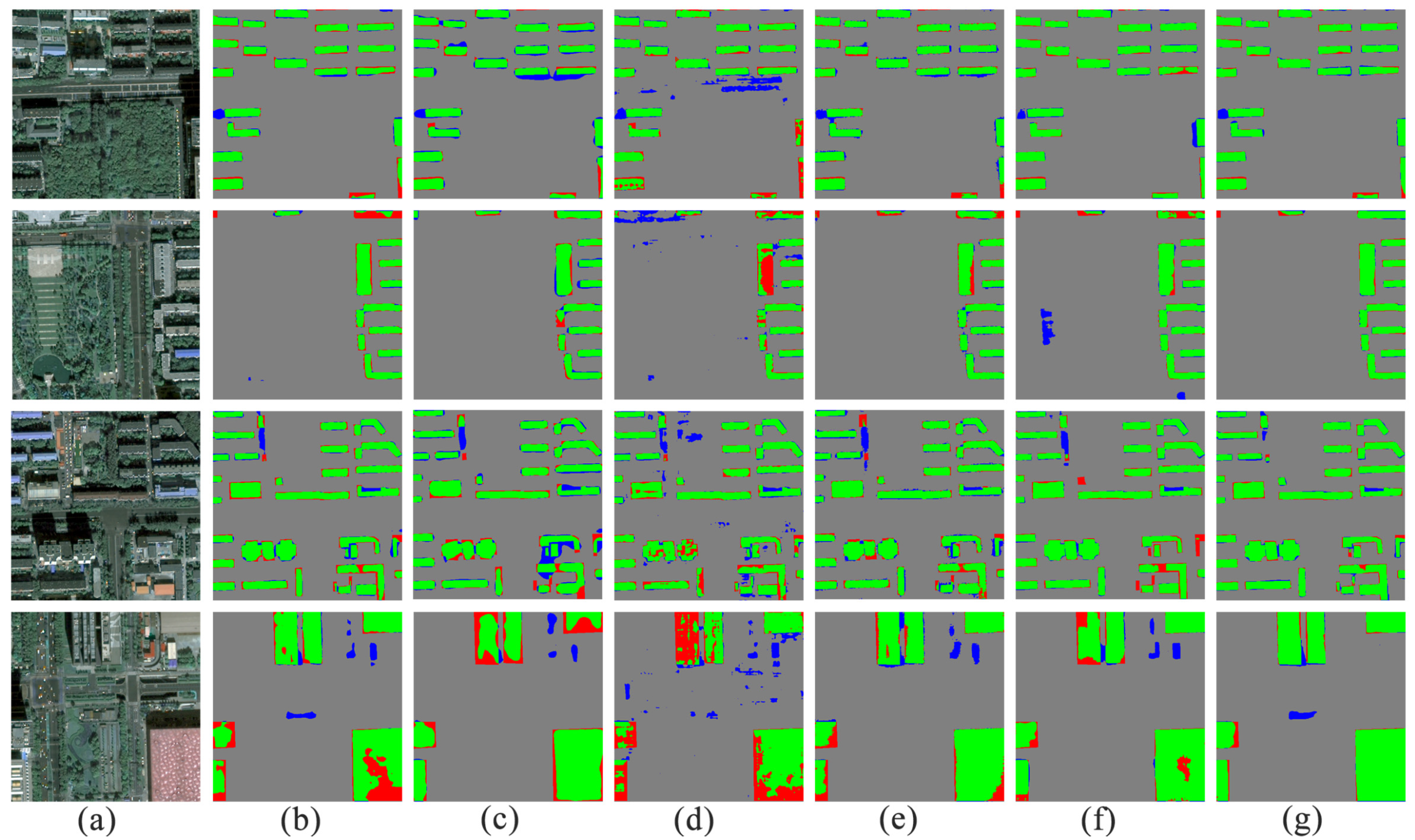
4.1. Performance of Building Footprint Extraction
4.1.1. WHU Building Dataset
4.1.2. GF-7 Self-Annotated Building Dataset
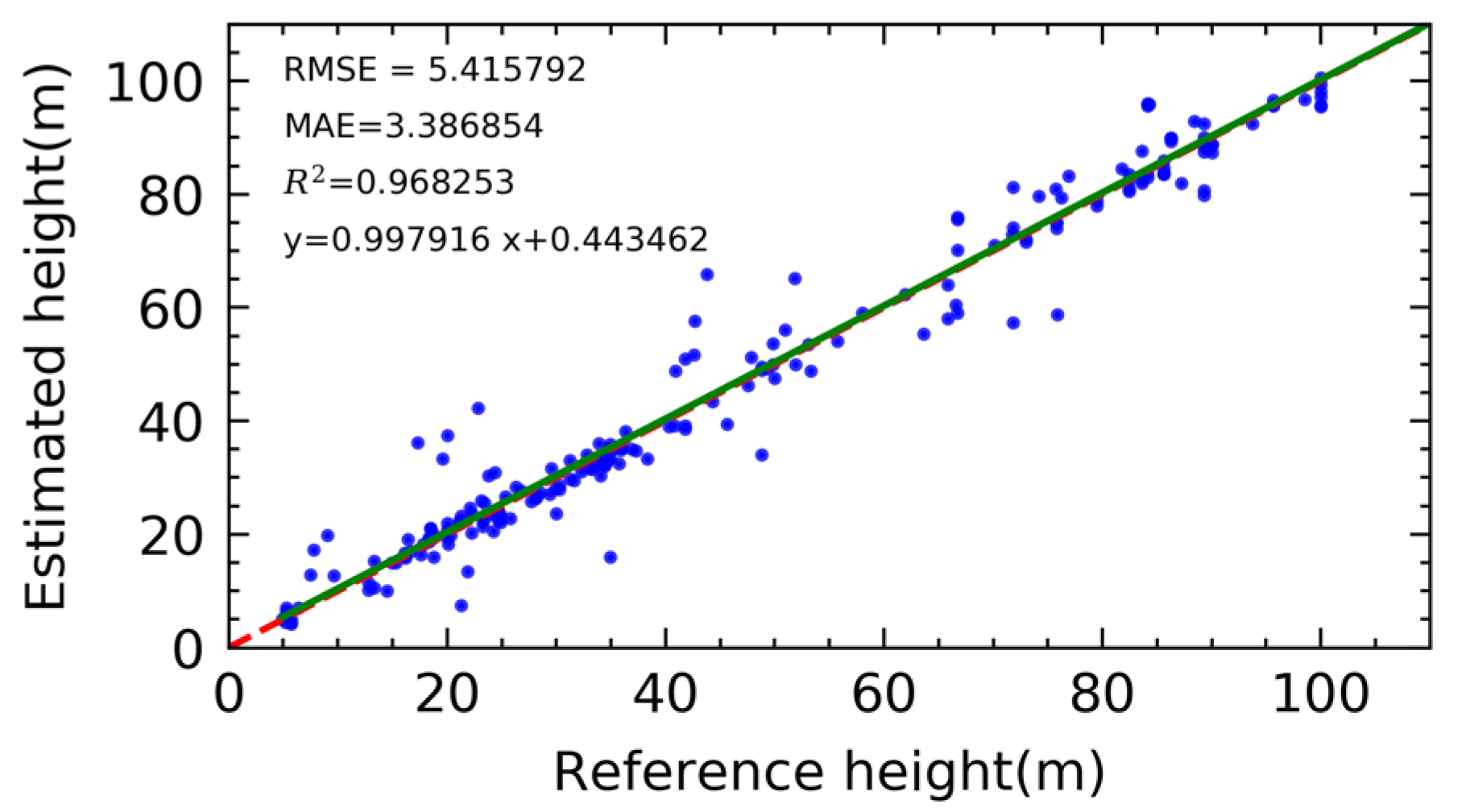
4.2. Performance of Building Height Extraction
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mahtta, R.; Mahendra, A.; Seto, K.C. Building up or spreading out? Typologies of urban growth across 478 cities of 1 million+. Environ. Res. Lett. 2019, 14, 124077. [Google Scholar] [CrossRef] [Green Version]
- Seto, K.C.; Dhakal, S.; Bigio, A.; Blanco, H.; Delgado, G.C.; Dewar, D.; Huang, L.; Inaba, A.; Kansal, A.; Lwasa, S. Human settlements, infrastructure and spatial planning. In Climate Change 2014: Mitigation of Climate Change. IPCC Working Group III Contribution to AR5; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Berger, C.; Rosentreter, J.; Voltersen, M.; Baumgart, C.; Schmullius, C.; Hese, S. Spatio-temporal analysis of the relationship between 2D/3D urban site characteristics and land surface temperature. Remote Sens. Environ. 2017, 193, 225–243. [Google Scholar] [CrossRef]
- Venter, Z.S.; Brousse, O.; Esau, I.; Meier, F. Hyperlocal mapping of urban air temperature using remote sensing and crowdsourced weather data. Remote Sens. Environ. 2020, 242, 111791. [Google Scholar] [CrossRef]
- Huang, X.; Wen, D.; Li, J.; Qin, R. Multi-level monitoring of subtle urban changes for the megacities of China using high-resolution multi-view satellite imagery. Remote Sens. Environ. 2017, 196, 56–75. [Google Scholar] [CrossRef]
- Xia, M.; Jia, K.; Zhao, W.; Liu, S.; Wei, X.; Wang, B. Spatio-temporal changes of ecological vulnerability across the Qinghai-Tibetan Plateau. Ecol. Indic. 2021, 123, 107274. [Google Scholar] [CrossRef]
- Qin, R. Change detection on LOD 2 building models with very high resolution spaceborne stereo imagery. ISPRS J. Photogramm. Remote Sens. 2014, 96, 179–192. [Google Scholar] [CrossRef]
- Hang, J.; Li, Y.; Sandberg, M.; Buccolieri, R.; Di Sabatino, S. The influence of building height variability on pollutant dispersion and pedestrian ventilation in idealized high-rise urban areas. Build. Environ. 2012, 56, 346–360. [Google Scholar] [CrossRef]
- Facciolo, G.; De Franchis, C.; Meinhardt-Llopis, E. Automatic 3D reconstruction from multi-date satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 57–66. [Google Scholar]
- Bullinger, S.; Bodensteiner, C.; Arens, M. 3D Surface Reconstruction From Multi-Date Satellite Images. arXiv 2021, arXiv:2102.02502. [Google Scholar] [CrossRef]
- Qin, R.; Song, S.; Ling, X.; Elhashash, M. 3D reconstruction through fusion of cross-view images. In Recent Advances in Image Restoration with Applications to Real World Problems; IntechOpen: London, UK, 2020; p. 123. [Google Scholar]
- Gui, S.; Qin, R. Automated LoD-2 model reconstruction from very-high-resolution satellite-derived digital surface model and orthophoto. ISPRS J. Photogramm. Remote Sens. 2021, 181, 1–19. [Google Scholar] [CrossRef]
- Huang, X.; Chen, H.; Gong, J. Angular difference feature extraction for urban scene classification using ZY-3 multi-angle high-resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2018, 135, 127–141. [Google Scholar] [CrossRef]
- Güneralp, B.; Zhou, Y.; Ürge-Vorsatz, D.; Gupta, M.; Yu, S.; Patel, P.L.; Fragkias, M.; Li, X.; Seto, K.C. Global scenarios of urban density and its impacts on building energy use through 2050. Proc. Natl. Acad. Sci. USA 2017, 114, 8945–8950. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, M.; Cao, C.; Jia, P. Mapping fine-scale urban spatial population distribution based on high-resolution stereo pair images, points of interest, and land cover data. Remote Sens. 2020, 12, 608. [Google Scholar] [CrossRef] [Green Version]
- Tomás, L.; Fonseca, L.; Almeida, C.; Leonardi, F.; Pereira, M. Urban population estimation based on residential buildings volume using IKONOS-2 images and lidar data. Int. J. Remote Sens. 2016, 37, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Weng, A.; Weng, Q. Population estimation of urban residential communities using remotely sensed morphologic data. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1111–1115. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar]
- Lu, T.; Ming, D.; Lin, X.; Hong, Z.; Bai, X.; Fang, J. Detecting building edges from high spatial resolution remote sensing imagery using richer convolution features network. Remote Sens. 2018, 10, 1496. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Shi, Y.; Huang, X.; Zhu, X.X. Building Footprint Generation by Integrating Convolution Neural Network With Feature Pairwise Conditional Random Field (FPCRF). IEEE Trans. Geosci. Remote Sens. 2020, 58, 7502–7519. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Li, M.; Yu, W. GIS-supervised building extraction with label noise-adaptive fully convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2135–2139. [Google Scholar] [CrossRef]
- Wang, C.; Li, L. Multi-Scale Residual Deep Network for Semantic Segmentation of Buildings with Regularizer of Shape Representation. Remote Sens. 2020, 12, 2932. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction From Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, D.; Ma, A.; Zhong, Y.; Fang, F.; Xu, K. Multiscale U-Shaped CNN Building Instance Extraction Framework with Edge Constraint for High-Spatial-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6106–6120. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X. A deep learning method for building height estimation using high-resolution multi-view imagery over urban areas: A case study of 42 Chinese cities. Remote Sens. Environ. 2021, 264, 112590. [Google Scholar] [CrossRef]
- Yang, X.; Wang, C.; Xi, X.; Wang, P.; Lei, Z.; Ma, W.; Nie, S. Extraction of multiple building heights using ICESat/GLAS full-waveform data assisted by optical imagery. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1914–1918. [Google Scholar] [CrossRef]
- Cheng, F.; Wang, C.; Wang, J.; Tang, F.; Xi, X. Trend analysis of building height and total floor space in Beijing, China using ICESat/GLAS data. Int. J. Remote Sens. 2011, 32, 8823–8835. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Y.; Gong, P.; Seto, K.C.; Clinton, N. Developing a method to estimate building height from Sentinel-1 data. Remote Sens. Environ. 2020, 240, 111705. [Google Scholar] [CrossRef]
- Qi, F.; Zhai, J.Z.; Dang, G. Building height estimation using Google Earth. Energy Build. 2016, 118, 123–132. [Google Scholar] [CrossRef]
- Liu, C.; Huang, X.; Wen, D.; Chen, H.; Gong, J. Assessing the quality of building height extraction from ZiYuan-3 multi-view imagery. Remote Sens. Lett. 2017, 8, 907–916. [Google Scholar] [CrossRef]
- Xu, Y.; Ma, P.; Ng, E.; Lin, H. Fusion of worldview-2 stereo and multitemporal TerraSAR-X images for building height extraction in urban areas. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1795–1799. [Google Scholar]
- Chen, Q.; Wang, L.; Waslander, S.L.; Liu, X. An end-to-end shape modeling framework for vectorized building outline generation from aerial images. ISPRS J. Photogramm. Remote Sens. 2020, 170, 114–126. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 6230–6239. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Zhou, D.; Wang, G.; He, G.; Long, T.; Yin, R.; Zhang, Z.; Chen, S.; Luo, B. Robust Building Extraction for High Spatial Resolution Remote Sensing Images with Self-Attention Network. Sensors 2020, 20, 7241. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Su, J.; Duan, C.; Zheng, S. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. arXiv 2020, arXiv:2011.14302. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- de Franchis, C.; Meinhardt-Llopis, E.; Michel, J.; Morel, J.M.; Facciolo, G. An automatic and modular stereo pipeline for pushbroom images. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences; HAL: Bengaluru, India, 2014; Volume II-3, pp. 49–56. [Google Scholar] [CrossRef] [Green Version]
- de Franchis, C.; Meinhardt-Llopis, E.; Michel, J.; Morel, J.-M.; Facciolo, G. Automatic sensor orientation refinement of Pléiades stereo images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1639–1642. [Google Scholar]
- de Franchis, C.; Meinhardt-Llopis, E.; Michel, J.; Morel, J.-M.; Facciolo, G. On stereo-rectification of pushbroom images. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5447–5451. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, S.-C.; Whitman, D.; Shyu, M.-L.; Yan, J.; Zhang, C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVRP), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA (%) | IOU (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| PSPNet | 98.55 | 87.67 | 92.49 | 94.39 | 93.45 |
| FCN | 97.42 | 79.48 | 89.73 | 87.42 | 88.56 |
| DeepLab v3+ | 96.84 | 73.55 | 78.79 | 91.71 | 84.76 |
| SegNet | 98.06 | 84.01 | 91.40 | 91.21 | 91.31 |
| U-Net | 98.56 | 87.94 | 93.84 | 93.33 | 93.58 |
| MSAU-Net | 98.74 | 89.31 | 94.18 | 94.52 | 94.35 |
| Method | OA (%) | IOU (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| PSPNet | 94.66 | 75.27 | 81.98 | 90.18 | 85.89 |
| FCN | 93.09 | 70.21 | 82.16 | 82.84 | 82.50 |
| DeepLab v3+ | 91.53 | 62.55 | 71.40 | 83.46 | 76.96 |
| SegNet | 94.16 | 74.04 | 84.03 | 86.03 | 85.08 |
| U-Net | 95.17 | 77.58 | 84.21 | 90.70 | 87.33 |
| MSAU-Net | 95.74 | 80.27 | 87.46 | 90.71 | 89.06 |
| Number | RMSE | MAE | |
|---|---|---|---|
| Below 30 m | 83 | 4.95 | 2.83 |
| From 30 m to 70 m | 67 | 5.99 | 3.91 |
| Above 70 m | 63 | 5.35 | 3.55 |
| All | 213 | 5.41 | 3.39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Hu, X.; Meng, Q.; Zhang, L.; Wang, C.; Liu, X.; Zhao, M. Developing a Method to Extract Building 3D Information from GF-7 Data. Remote Sens. 2021, 13, 4532. https://doi.org/10.3390/rs13224532
Wang J, Hu X, Meng Q, Zhang L, Wang C, Liu X, Zhao M. Developing a Method to Extract Building 3D Information from GF-7 Data. Remote Sensing. 2021; 13(22):4532. https://doi.org/10.3390/rs13224532
Chicago/Turabian StyleWang, Jingyuan, Xinli Hu, Qingyan Meng, Linlin Zhang, Chengyi Wang, Xiangchen Liu, and Maofan Zhao. 2021. "Developing a Method to Extract Building 3D Information from GF-7 Data" Remote Sensing 13, no. 22: 4532. https://doi.org/10.3390/rs13224532
APA StyleWang, J., Hu, X., Meng, Q., Zhang, L., Wang, C., Liu, X., & Zhao, M. (2021). Developing a Method to Extract Building 3D Information from GF-7 Data. Remote Sensing, 13(22), 4532. https://doi.org/10.3390/rs13224532