
The Austrian Semantic EO Data Cube Infrastructure


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Big Earth Observation Data Management and Processing
2.2. Semantic Approaches in Big Earth Observation Analytics
3. Conceptual Foundations and System Requirements
3.1. Earth Observation Data Cubes
3.2. Semantic Enrichment in the Earth Observation Domain
3.3. Artificial-Intelligence-Based Expert System
- Initial generic semantic enrichment: exclusive and exhaustive partitioning of spectral signatures into generally applicable color information. Users can apply them as the basic building blocks to define general semantic entities;
- Convergence-of-evidence to increase the semantic granularity: semantic entities are defined using multiple sources of evidence, including color information, the temporal dimension, and potential auxiliary data and information, e.g., a digital elevation model (DEM);
- Extraction of land use/land cover units using the semantic entities in specific applications for better-posed big EO data queries and analyses (e.g., semantic content-based image retrieval (SCBIR, a method to retrieve images based on a semantic description of their content), cloud-free compositing, automatic change detection).
3.4. General System Requirements
- (a)
- Application support
- Facilitate at least the four following use-cases: (a) SCBIR, (b) best-pixel selection for user-defined composites (e.g., cloud-free), (c) location-based querying (a.k.a. pixel/point drill), and (d) parcel-based querying (a.k.a polygon drill);
- (b)
- Semantic EO data cubes and computing infrastructure
- Abstract data storage and access via EO data cubes, which contain at least one interpretation for every observation in space and time that can be queried in the same instance;
- Conduct automated EO data pre-processing, semantic enrichment and indexing; Utilize state-of-the-art cloud-based infrastructure (i.e., lightweight container-based virtualisation technology such as Docker) to reduce costs for installation and maintenance.
- (c)
- User interaction and interfaces
- Process in the cloud, implementing the big data paradigm to ‘bring user to the data, not data to the user’;
- Require no user-side installation beyond a standard web browser and Internet connection;
- Abstract data access and algorithms via a graphical querying language and semantic models as a-priori information in an explainable AI approach;
- Allow interactive system use and batch processing;
- Provide a programming-language independent API;
- Facilitate multiple, concurrent users, including separate spaces for each user. Provide further information about how to use the system as a manual and user support.
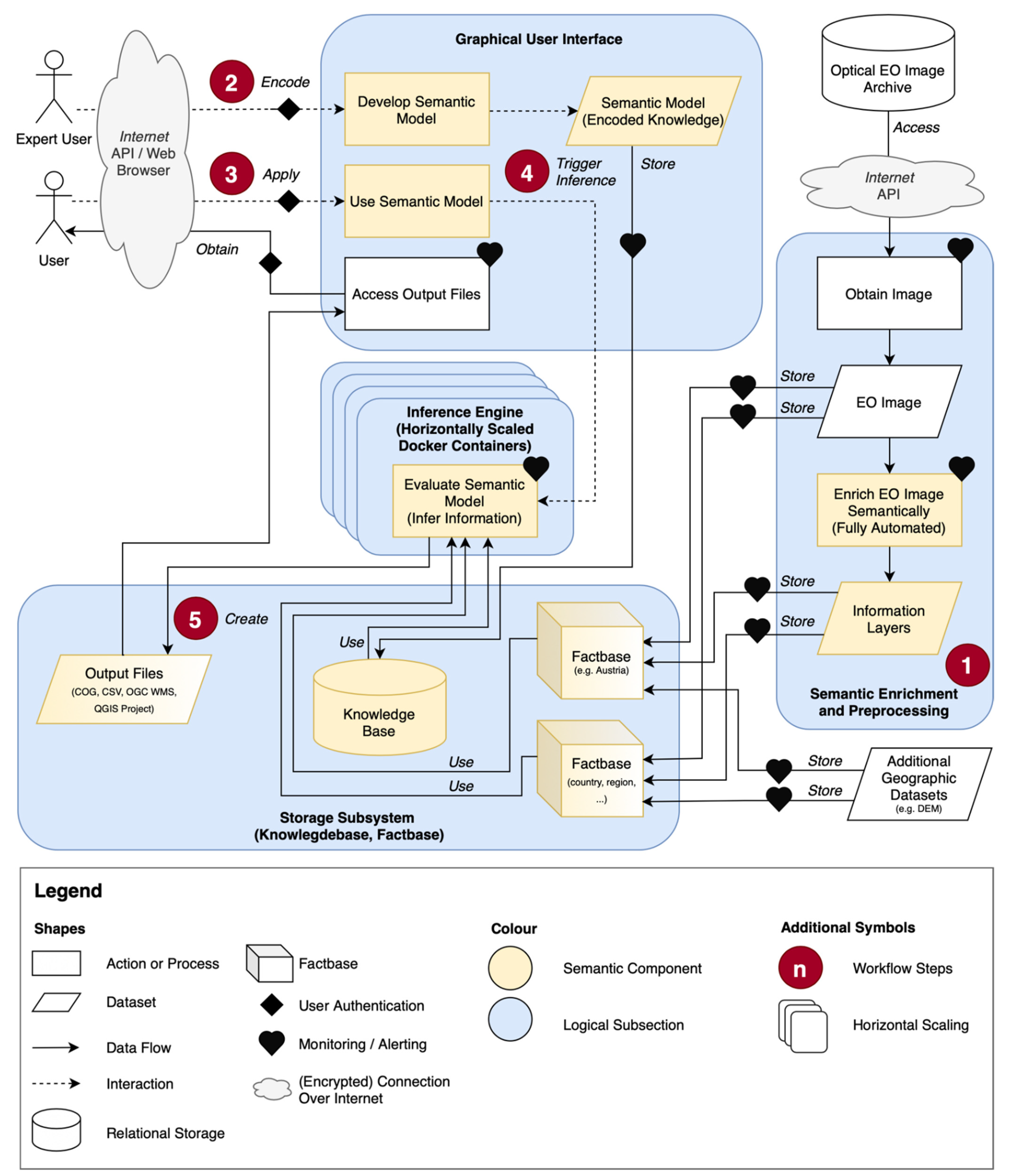
4. System Architecture
4.1. Factbase and Knowledgebase
4.1.1. Data Preparation and Pre-Processing with Semantic Enrichment
- Select and access candidate images. Currently, all available images covering the spatio-temporal target extent of the factbase are selected, regardless of image content (e.g., without filtering for cloud cover);
- Prepare images for semantic enrichment. Select the necessary spectral bands for each candidate image depending on the sensor, calibrate if not in at least top-of-atmosphere (ToA) reflectance, and transform them into the required format for SIAM. Automatically generate a mask to include only pixels with valid observations in all the necessary bands to guarantee a complete spectral signature and eliminate artefacts and errors at acquisition swath edges;
- If specified, the input file of necessary spectral bands for SIAM is re-projected using GDAL warp and the bilinear algorithm, and nearest neighbour for the valid-data mask;
- Semantic enrichment using SIAM. The exact enrichment outputs are derived from the semantic EO data cube’s layout [55] (e.g., a total of 33 spectral categories, haze mask, greenness ratio, brightness information layers);
- Generate metadata files for images and information layers depending on the EO data cube software;
- Index the new images and information layers into the EO data cube software;
- Remove intermediate outputs from steps 2–4 depending on configuration.
4.1.2. Data Models and Information Management
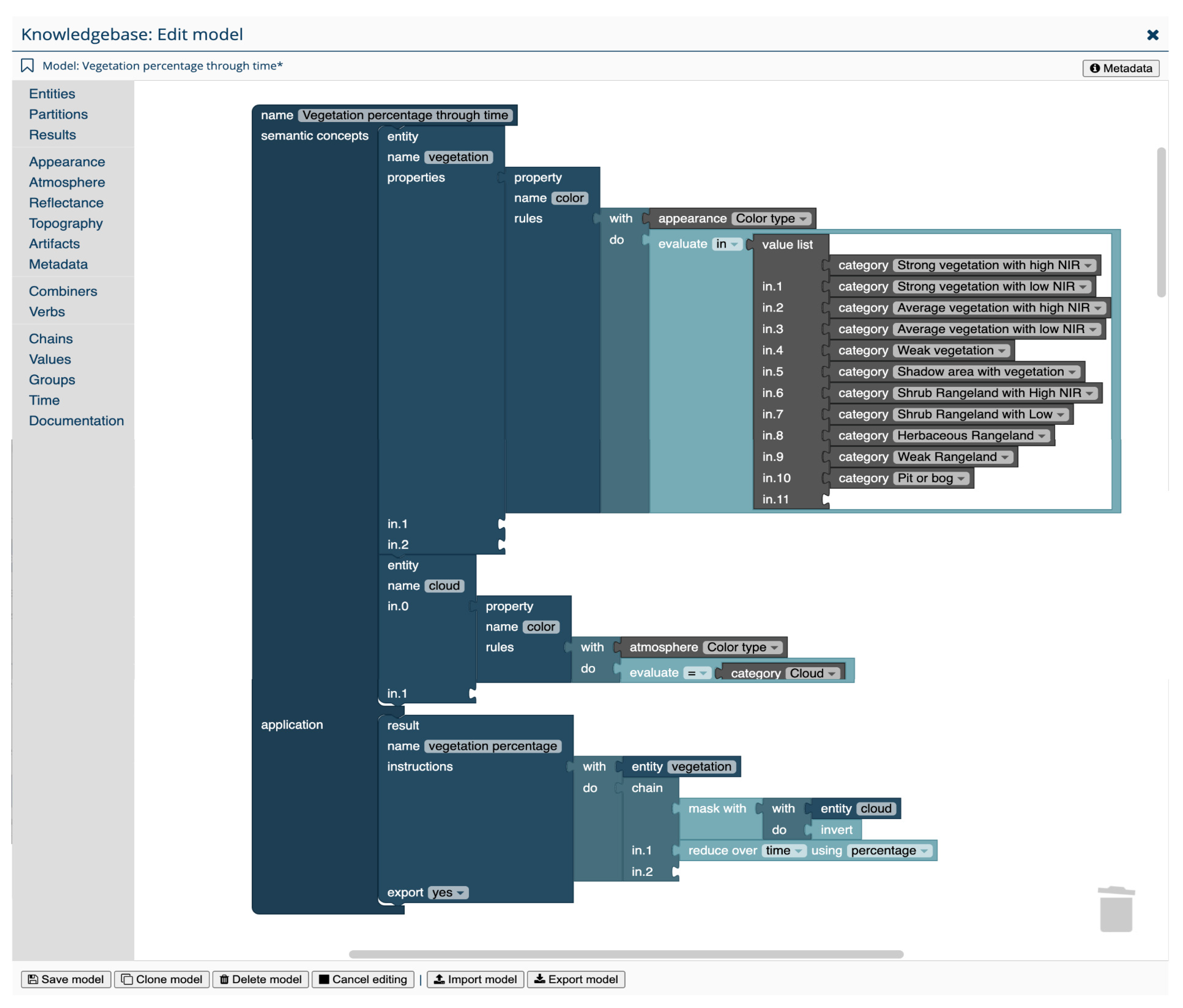
4.1.3. Knowledge Engineering Using Semantic Models
- (1)
- Semantic concepts: users define semantic concepts, such as entities, by combining several facts as entity properties in a convergence-of-evidence approach (e.g., land cover types). Examples are the spectral categories as color information, texture, topography or spatio-temporal attributes. By definition, and consistent with expert systems, multiple entity properties are connected by a logical AND. Each property contains one or more rules, which can be connected by either AND or OR. Optionally, a rule to define an entity can also be a constraint with additional criteria (e.g., specific time intervals). For example, the land cover type ‘surface water’ may be defined by attribute values of all available properties (e.g., color, texture, slope, spatio-temporal attributes) while the property ‘color’ may hold values ‘green’ or ‘blue’ and the property ‘slope’ the value ‘flat’. The defined entities may be directly or closely associated with physical entities (e.g., lake, farmland, vegetation). The semantic level is decided by the user on a case-by-case basis and only limited by the capabilities of available semantic enrichment and additional data (e.g., DEM).
- (2)
- Application: users formulate how to generate analysis results by using one or more defined semantic concepts. Specific, well-defined processing actions can be used and chained to obtain the outputs. Semantic concepts and results can be (re-)used in many outputs in the application domain.
4.2. Semantic Querying and Inference Engine
- Prepare semantic model for processing. The inference engine creates its own processing-optimized internal representation of a semantic model. General checks are performed, e.g., whether the query‘s extent intersects spatio-temporally the factbase’s extent;
- Execute the semantic query. Each building block in a semantic model is associated with a dedicated evaluation function that performs a certain processing task. There are three main types of processing tasks: (1) translating high-level semantic concepts into low-level database queries, (2) using these queries to retrieve actual data values from the factbase, and (3) applying specified data cube operations (e.g., reductions, filters) to the retrieved data;
- Export outputs. Each result specified in the application part of a semantic model is an n-dimensional array. The number of dimensions (n) depends on the performed reduction and expansion operations. The most common outputs are 1D arrays with a time dimension (i.e., time series such as a vegetation status over a year) and 2D arrays with two spatial dimensions (i.e., map such as green spaces in a city, cloud-free composite). However, other dimension combinations as outputs are possible, including a scalar value (e.g., the maximum number of water pixels in an area), categories (e.g., most occurring entity over time), and dates (e.g., cloud-free dates). For each result, the inference engine writes the content of the returned array to a file. The file type depends on the dimensions of the array. For example, a time series is written to a CSV file, while a map is written to a GeoTIFF file.
- Semantic model: a subset of the knowledgebase that stores users’ a-priori knowledge as a set of rules that define semantic concepts (i.e., entities). It also contains a formulation for producing desired results based on these concepts used to infer new information;
- Area-of-interest: a subset (spatial extent) of the factbase;
- Time Interval: a subset (temporal extent) of the factbase;
- Results: one or more outputs, which are defined in the semantic model and generated through inference;
- Meta-data: information about the inference (e.g., execution times, duration, owner/creator).
4.3. Graphical User Interfaces (GUIs) and Application Programming Interfaces (API)
4.4. Performance, Scaling, and Security Considerations
4.5. Support, Workshops, and Community
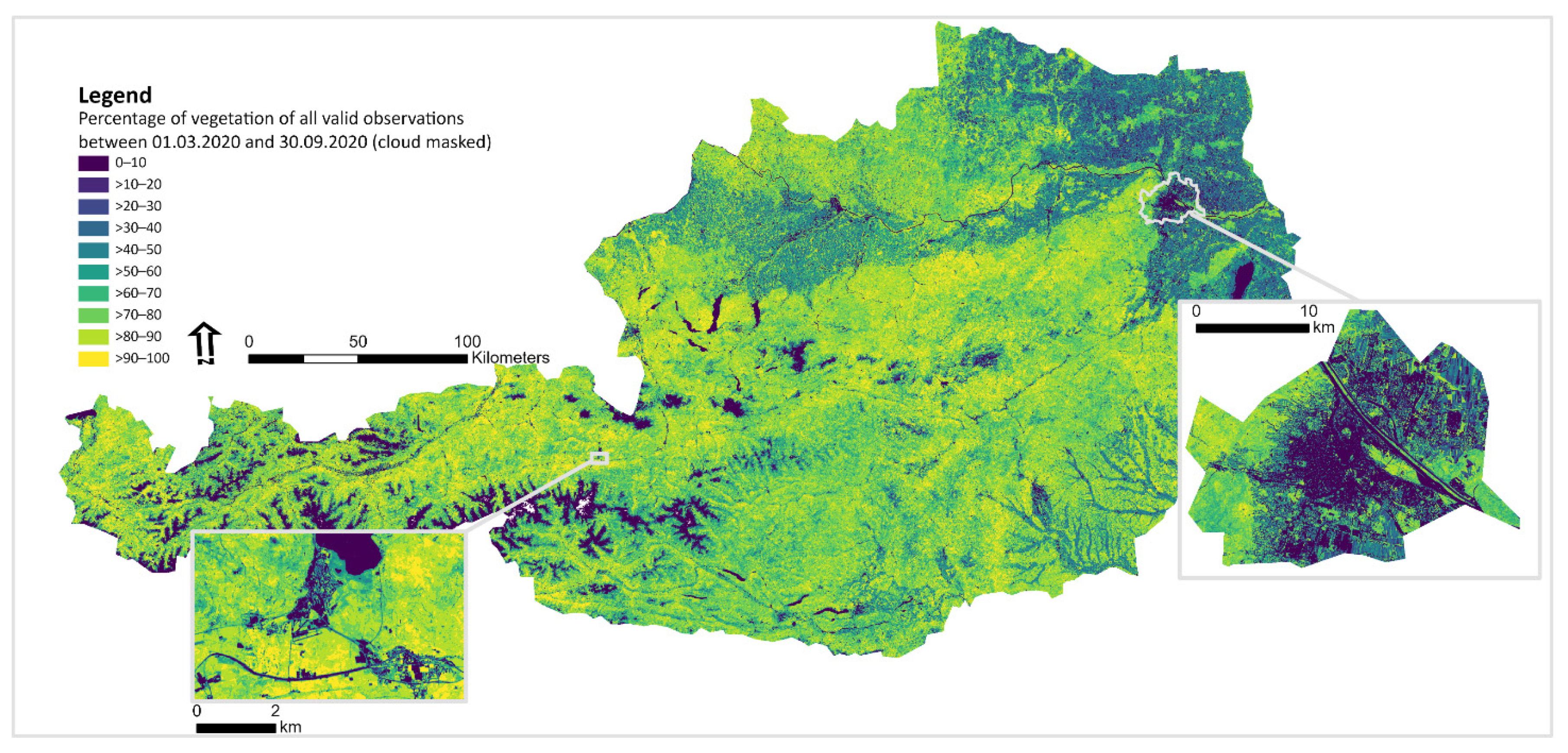
5. The National Austrian Semantic EO Data Cube Infrastructure
6. Discussion
7. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dhu, T.; Guiliani, G.; Juárez, J.; Kavvada, A.; Killough, B.; Merodio, P.; Minchin, S.; Ramage, S. National Open Data Cubes and Their Contribution to Country-Level Development Policies and Practices. Data 2019, 4, 144. [Google Scholar] [CrossRef] [Green Version]
- Lewis, A.; Lacey, J.; Mecklenburg, S.; Ross, J.; Siqueira, A.; Killough, B.; Szantoi, Z.; Tadono, T.; Rosenavist, A.; Goryl, P.; et al. CEOS Analysis Ready Data for Land (CARD4L) Overview. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7407–7410. [Google Scholar]
- Mueller, N.; Lewis, A.; Roberts, D.; Ring, S.; Melrose, R.; Sixsmith, J.; Lymburner, L.; McIntyre, A.; Tan, P.; Curnow, S.; et al. Water Observations from Space: Mapping Surface Water from 25 Years of Landsat Imagery across Australia. Remote Sens. Environ. 2016, 174, 341–352. [Google Scholar] [CrossRef] [Green Version]
- Baraldi, A.; Boschetti, L. Operational Automatic Remote Sensing Image Understanding Systems: Beyond Geographic Object-Based and Object-Oriented Image Analysis (GEOBIA/GEOOIA). Part 1: Introduction. Remote Sens. 2012, 4, 2694–2735. [Google Scholar] [CrossRef] [Green Version]
- Wagemann, J.; Siemen, S.; Seeger, B.; Bendix, J. Users of Open Big Earth Data—An Analysis of the Current State. Comput. Geosci. 2021, 157, 104916. [Google Scholar] [CrossRef]
- Kavvada, A.; Metternicht, G.; Kerblat, F.; Mudau, N.; Haldorson, M.; Laldaparsad, S.; Friedl, L.; Held, A.; Chuvieco, E. Towards Delivering on the Sustainable Development Goals Using Earth Observations. Remote Sens. Environ. 2020, 247, 111930. [Google Scholar] [CrossRef]
- Sudmanns, M.; Tiede, D.; Lang, S.; Bergstedt, H.; Trost, G.; Augustin, H.; Baraldi, A.; Blaschke, T. Big Earth Data: Disruptive Changes in Earth Observation Data Management and Analysis? Int. J. Digit. Earth 2019, 13, 832–850. [Google Scholar] [CrossRef] [PubMed]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.E.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.B.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A Publishing Format for Reproducible Computational Workflows. In Positioning and Power in Academic, Proceedings of the 20th International Conference on Electronic Publishing, Göttingen, Germany, 7–9 June 2016; Loizides, F., Schmidt, B., Eds.; IOS Press: Berlin, Germany; Washington, DC, USA, 2016; pp. 87–90. [Google Scholar]
- Baumann, P. The OGC Web Coverage Processing Service (WCPS) Standard. Geoinformatica 2010, 14, 447–479. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Valero, S.; Morin, D.; Inglada, J.; Sepulcre, G.; Arias, M.; Hagolle, O.; Dedieu, G.; Bontemps, S.; Defourny, P.; Koetz, B. Production of a Dynamic Cropland Mask by Processing Remote Sensing Image Series at High Temporal and Spatial Resolutions. Remote Sens. 2016, 8, 55. [Google Scholar] [CrossRef] [Green Version]
- Gascon, F. Sentinel-2 for Agricultural Monitoring. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8166–8168. [Google Scholar]
- Arvor, D.; Betbeder, J.; Daher, F.R.G.; Blossier, T.; Le Roux, R.; Corgne, S.; Corpetti, T.; de Freitas Silgueiro, V.; Silva Junior, C.A. da Towards User-Adaptive Remote Sensing: Knowledge-Driven Automatic Classification of Sentinel-2 Time Series. Remote Sens. Environ. 2021, 264, 112615. [Google Scholar] [CrossRef]
- Baraldi, A.; Tiede, D. AutoCloud+, a “Universal” Physical and Statistical Model-Based 2D Spatial Topology-Preserving Software for Cloud/Cloud–Shadow Detection in Multi-Sensor Single-Date Earth Observation Multi-Spectral Imagery—Part 1: Systematic ESA EO Level 2 Product Generati. ISPRS Int. J. Geo-Inf. 2018, 7, 457. [Google Scholar] [CrossRef] [Green Version]
- Augustin, H.; Sudmanns, M.; Tiede, D.; Lang, S.; Baraldi, A. Semantic Earth Observation Data Cubes. Data 2019, 4, 102. [Google Scholar] [CrossRef] [Green Version]
- Hoyer, S.; Hamman, J.J. Xarray: N-D Labeled Arrays and Datasets in Python. J. Open Res. Softw. 2017, 5, 10. [Google Scholar] [CrossRef] [Green Version]
- Killough, B. Overview of the Open Data Cube Initiative. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8629–8632. [Google Scholar]
- Dhu, T.; Dunn, B.; Lewis, B.; Lymburner, L.; Mueller, N.; Telfer, E.; Lewis, A.; McIntyre, A.; Minchin, S.; Phillips, C. Digital Earth Australia—Unlocking New Value from Earth Observation Data. Big Earth Data 2017, 1, 64–74. [Google Scholar] [CrossRef] [Green Version]
- Giuliani, G.; Chatenoux, B.; De Bono, A.; Rodila, D.; Richard, J.-P.; Allenbach, K.; Dao, H.; Peduzzi, P. Building an Earth Observations Data Cube: Lessons Learned from the Swiss Data Cube (SDC) on Generating Analysis Ready Data (ARD). Big Earth Data 2017, 1, 100–117. [Google Scholar] [CrossRef] [Green Version]
- Giuliani, G.; Chatenoux, B.; Honeck, E.; Richard, J.-P. Towards Sentinel-2 Analysis Ready Data: A Swiss Data Cube Perspective. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8659–8662. [Google Scholar]
- Ariza-Porras, C.; Bravo, G.; Villamizar, M.; Moreno, A.; Castro, H.; Galindo, G.; Cabera, E.; Valbuena, S.; Lozano, P. CDCol: A Geoscience Data Cube that Meets Colombian Needs. In Advances in Computing. CCC 2017. Communications in Computer and Information Science; Solano, A., Ordoñez, H., Eds.; Springer: Cham, Switzerland, 2017; pp. 87–99. [Google Scholar]
- Quang, N.H.; Tuan, V.A.; Hao, N.T.P.; Hang, L.T.T.; Hung, N.M.; Anh, V.L.; Phuong, L.T.M.; Carrie, R. Synthetic Aperture Radar and Optical Remote Sensing Image Fusion for Flood Monitoring in the Vietnam Lower Mekong Basin: A Prototype Application for the Vietnam Open Data Cube. Eur. J. Remote Sens. 2019, 52, 599–612. [Google Scholar] [CrossRef] [Green Version]
- Asmaryan, S.; Muradyan, V.; Tepanosyan, G.; Hovsepyan, A.; Saghatelyan, A.; Astsatryan, H.; Grigoryan, H.; Abrahamyan, R.; Guigoz, Y.; Giuliani, G. Paving the Way towards an Armenian Data Cube. Data 2019, 4, 117. [Google Scholar] [CrossRef] [Green Version]
- Maso, J.; Zabala, A.; Serral, I.; Pons, X. A Portal Offering Standard Visualization and Analysis on Top of an Open Data Cube for Sub-National Regions: The Catalan Data Cube Example. Data 2019, 4, 96. [Google Scholar] [CrossRef] [Green Version]
- Euro Data Cube Consortium Euro Data Cube. Available online: https://eurodatacube.com (accessed on 28 October 2021).
- Mahecha, M.D.; Gans, F.; Brandt, G.; Christiansen, R.; Cornell, S.E.; Fomferra, N.; Kraemer, G.; Peters, J.; Bodesheim, P.; Camps-Valls, G.; et al. Earth System Data Cubes Unravel Global Multivariate Dynamics. Earth Syst. Dyn. 2020, 11, 201–234. [Google Scholar] [CrossRef] [Green Version]
- Baumann, P.; Dehmel, A.; Furtado, P.; Ritsch, R.; Widmann, N. The Multidimensional Database System RasDaMan. In Acm Sigmod Record; ACM: New York, NY, USA, 1998; Volume 27, pp. 575–577. [Google Scholar]
- Baumann, P.; Mazzetti, P.; Ungar, J.; Barbera, R.; Barboni, D.; Beccati, A.; Bigagli, L.; Boldrini, E.; Bruno, R.; Calanducci, A.; et al. Big Data Analytics for Earth Sciences: The EarthServer Approach. Int. J. Digit. Earth 2016, 9, 1–27. [Google Scholar] [CrossRef]
- Storch, T.; Reck, C.; Holzwarth, S.; Wiegers, B.; Mandery, N.; Raape, U.; Strobl, C.; Volkmann, R.; Böttcher, M.; Hirner, A.; et al. Insights into CODE-DE—Germany’s Copernicus Data and Exploitation Platform. Big Earth Data 2019, 3, 338–361. [Google Scholar] [CrossRef]
- Soille, P.; Burger, A.; De Marchi, D.; Kempeneers, P.; Rodriguez, D.; Syrris, V.; Vasilev, V. A Versatile Data-Intensive Computing Platform for Information Retrieval from Big Geospatial Data. Futur. Gener. Comput. Syst. 2018, 81, 30–40. [Google Scholar] [CrossRef]
- Guo, H. Big Earth Data: A New Frontier in Earth and Information Sciences. Big Earth Data 2017, 1, 4–20. [Google Scholar] [CrossRef] [Green Version]
- Simoes, R.; Camara, G.; Queiroz, G.; Souza, F.; Andrade, P.R.; Santos, L.; Carvalho, A.; Ferreira, K. Satellite Image Time Series Analysis for Big Earth Observation Data. Remote Sens. 2021, 13, 2428. [Google Scholar] [CrossRef]
- Baumann, P.; Misev, D.; Merticariu, V.; Huu, B.P.; Bell, B. DataCubes: A Technology Survey. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 430–433. [Google Scholar]
- Gomes, V.C.F.; Queiroz, G.R.; Ferreira, K.R. An Overview of Platforms for Big Earth Observation Data Management and Analysis. Remote Sens. 2020, 12, 1253. [Google Scholar] [CrossRef] [Green Version]
- Datcu, M.; Daschiel, H.; Pelizzari, A.; Quartulli, M.; Galoppo, A.; Colapicchioni, A.; Pastori, M.; Seidel, K.; Marchetti, P.G.; D’Elia, S. Information Mining in Remote Sensing Image Archives: System Concepts. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2923–2936. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Bretschneider, T. Semantics-Based Satellite Image Retrieval Using Low-Level Features. In Proceedings of the 2004 IGARSS—2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 7, pp. 4406–4409. [Google Scholar]
- Dumitru, C.O.; Cui, S.; Schwarz, G.; Datcu, M. Information Content of Very-High-Resolution SAR Images: Semantics, Geospatial Context, and Ontologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1635–1650. [Google Scholar] [CrossRef] [Green Version]
- Alirezaie, M.; Kiselev, A.; Längkvist, M.; Klügl, F.; Loutfi, A. An Ontology-Based Reasoning Framework for Querying Satellite Images for Disaster Monitoring. Sensors 2017, 17, 2545. [Google Scholar] [CrossRef] [Green Version]
- Tran, B.-H.; Aussenac-Gilles, N.; Comparot, C.; Trojahn, C. Semantic Integration of Raster Data for Earth Observation: An RDF Dataset of Territorial Unit Versions with Their Land Cover. ISPRS Int. J. Geo-Inf. 2020, 9, 503. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Loveland, T.R.; Herold, M.; Bauer, M.E. Transitioning from Change Detection to Monitoring with Remote Sensing: A Paradigm Shift. Remote Sens. Environ. 2020, 238, 111558. [Google Scholar] [CrossRef]
- Bullock, E.L.; Woodcock, C.E.; Holden, C.E. Improved Change Monitoring Using an Ensemble of Time Series Algorithms. Remote Sens. Environ. 2020, 238, 111165. [Google Scholar] [CrossRef]
- Boschetti, M.; Stroppiana, D.; Brivio, P.A.; Bocchi, S. Multi-Year Monitoring of Rice Crop Phenology through Time Series Analysis of MODIS Images. Int. J. Remote Sens. 2009, 30, 4643–4662. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Pickert, J.; Hostert, P. Towards National-Scale Characterization of Grassland Use Intensity from Integrated Sentinel-2 and Landsat Time Series. Remote Sens. Environ. 2020, 238, 111124. [Google Scholar] [CrossRef]
- Tiede, D.; Baraldi, A.; Sudmanns, M.; Belgiu, M.; Lang, S. Architecture and Prototypical Implementation of a Semantic Querying System for Big Earth Observation Image Bases. Eur. J. Remote Sens. 2017, 50, 452–463. [Google Scholar] [CrossRef] [PubMed]
- Maciel, A.M.; Camara, G.; Vinhas, L.; Picoli, M.C.A.; Begotti, R.A.; de Assis, L.F.F.G. A Spatiotemporal Calculus for Reasoning about Land-Use Trajectories A Spatiotemporal Calculus for Reasoning about Land-Use Trajectories. Int. J. Geogr. Inf. Sci. 2018, 33, 176–192. [Google Scholar] [CrossRef] [Green Version]
- Nativi, S.; Mazzetti, P.; Craglia, M. A View-Based Model of Data-Cube to Support Big Earth Data Systems Interoperability. Big Earth Data 2017, 1, 75–99. [Google Scholar] [CrossRef] [Green Version]
- Lewis, A.; Lymburner, L.; Purss, M.B.J.; Brooke, B.; Evans, B.; Ip, A.; Dekker, A.G.; Irons, J.R.; Minchin, S.; Mueller, N.; et al. Rapid, High-Resolution Detection of Environmental Change over Continental Scales from Satellite Data—The Earth Observation Data Cube. Int. J. Digit. Earth 2016, 9, 106–111. [Google Scholar] [CrossRef]
- Strobl, P.; Baumann, P.; Lewis, A.; Szantoi, Z.; Killough, B.; Purss, M.; Craglia, M.; Nativi, S.; Held, A.; Dhu, T. The six faces of the data cube. In Proceedings of the 2017 Conference on Big Data from Space; Soille, P., Marchetti, P., Eds.; Publications Office of the European Union: Luxembourg, 2017; pp. 32–35. ISBN 978-92-79-73527-1. [Google Scholar]
- Baraldi, A.; Humber, M.L.; Tiede, D.; Lang, S. GEO-CEOS Stage 4 Validation of the Satellite Image Automatic Mapper Lightweight Computer Program for ESA Earth Observation Level 2 Product Generation—Part 1: Theory. Cogent Geosci. 2018, 4, 1467357. [Google Scholar] [CrossRef]
- Baraldi, A.; Humber, M.L.; Tiede, D.; Lang, S. GEO-CEOS Stage 4 Validation of the Satellite Image Automatic Mapper Lightweight Computer Program for ESA Earth Observation Level 2 Product Generation—Part 2: Validation. Cogent Geosci. 2018, 4, 1467254. [Google Scholar] [CrossRef]
- Baraldi, A.; Humber, M.; Boschetti, L. Quality Assessment of Pre-Classification Maps Generated from Spaceborne/Airborne Multi-Spectral Images by the Satellite Image Automatic MapperTM and Atmospheric/Topographic CorrectionTM-Spectral Classification Software Products: Part 2—Experimental Result. Remote Sens. 2013, 5, 5209–5264. [Google Scholar] [CrossRef] [Green Version]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Automatic Spectral-Rule-Based Preliminary Classification of Radiometrically Calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye, and DMC/SPOT-1/-2 Imagery—Part I: System Design and Implementation. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1299–1325. [Google Scholar] [CrossRef]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Automatic Spectral Rule-Based Preliminary Classification of Radiometrically Calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye, and DMC/SPOT-1/-2 Imagery—Part II: Classification Accuracy Assessment. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1326–1354. [Google Scholar] [CrossRef]
- Laurini, R.; Thompson, D. Fundamentals of Spatial Information Systems; Academic Press: London, UK, 1992; ISBN 9780124383807. [Google Scholar]
- Sudmanns, M.; Augustin, H.; van der Meer, L.; Werner, C.; Baraldi, A.; Tiede, D. One GUI to Rule Them All: Accessing Multiple Semantic EO Data Cubes in One Graphical User Interface. GI_Forum 2021, 1, 53–59. [Google Scholar] [CrossRef]
- Baraldi, A.; Tiede, D.; Sudmanns, M.; Belgiu, M.; Lang, S. Systematic ESA EO Level 2 Product Generation as Pre-Condition to Semantic Content-Based Image Retrieval and Information/Knowledge Discovery in EO Image Databases. Proc. BiDS 2017, 17, 17–20. [Google Scholar]
- Docker Runtime Options with Memory, CPUs, and GPUs. Available online: https://github.com/docker/docker.github.io/blob/df661019a6f56d9ce3fc2053cad0b6f05802f9e4/config/containers/resource_constraints.md (accessed on 28 October 2021).
- ESA. Sentinel-2 L1C Data Quality Report Issue 65 (July 2021). 2021. Available online: https://sentinels.copernicus.eu/documents/247904/685211/Sentinel-2_L1C_Data_Quality_Report.pdf/6ad66f15-48ca-4e65-b304-59ef00b7f0e0 (accessed on 28 October 2021).
- Pfeifer, H. About the EEA Reference Grid. 2021. Available online: https://www.eea.europa.eu/data-and-maps/data/eea-reference-grids-2/about-the-eea-reference-grid/eea_reference_grid_v1.pdf (accessed on 28 October 2021).
- Tiede, D.; Sudmanns, M.; Augustin, H.; Baraldi, A. Investigating ESA Sentinel-2 Products’ Systematic Cloud Cover Overestimation in Very High Altitude Areas. Remote Sens. Environ. 2021, 252, 112163. [Google Scholar] [CrossRef]
- Matsuyama, T.; Hwang, V.S.-S. SIGMA—A Knowledge-Based Aerial Image Understanding System; Springer: Boston, MA, USA, 1990; ISBN 978-1-4899-0869-8. [Google Scholar]
- Kapos, V.; Rhind, J.; Edwards, M.; Price, M.F.; Ravilious, C. Developing a map of the world’s mountain forests. In Forests in Sustainable Mountain Development: A State of Knowledge Report for 2000. Task Force on Forests in Sustainable Mountain Development; CABI: Wallingford, UK, 2000; pp. 4–19. [Google Scholar]
- Schramm, M.; Pebesma, E.; Milenković, M.; Foresta, L.; Dries, J.; Jacob, A.; Wagner, W.; Mohr, M.; Neteler, M.; Kadunc, M.; et al. The OpenEO API–Harmonising the Use of Earth Observation Cloud Services Using Virtual Data Cube Functionalities. Remote Sens. 2021, 13, 1125. [Google Scholar] [CrossRef]
- Augustin, H.; Sudmanns, M.; Tiede, D.; Baraldi, A. A Semantic Earth Observation Data Cube for Monitoring Environmental Changes during the Syrian Conflict. GI_Forum 2018, 1, 214–227. [Google Scholar] [CrossRef]
- Giuliani, G.; Chatenoux, B.; Piller, T.; Moser, F.; Lacroix, P. Data Cube on Demand (DCoD): Generating an Earth Observation Data Cube Anywhere in the World. Int. J. Appl. Earth Obs. Geoinf. 2020, 87, 102035. [Google Scholar] [CrossRef]
- Digital Earth Africa. Digital Earth Africa Phase 1 Summary. 2019. Available online: https://www.digitalearthafrica.org/sites/default/files/downloads/201905_Digital_Earth_Africa_phase1.pdf (accessed on 28 October 2021).
- Closa, G.; Masó, J.; Proß, B.; Pons, X. W3C PROV to Describe Provenance at the Dataset, Feature and Attribute Levels in a Distributed Environment. Comput. Environ. Urban Syst. 2017, 64, 103–117. [Google Scholar] [CrossRef]
- Figgemeier, H.; Henzen, C.; Rümmler, A. A Geo-Dashboard Concept for the Interactively Linked Visualization of Provenance and Data Quality for Geospatial Datasets. Agil. GISci. Ser. 2021, 2, 1–8. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sudmanns, M.; Augustin, H.; van der Meer, L.; Baraldi, A.; Tiede, D. The Austrian Semantic EO Data Cube Infrastructure. Remote Sens. 2021, 13, 4807. https://doi.org/10.3390/rs13234807
Sudmanns M, Augustin H, van der Meer L, Baraldi A, Tiede D. The Austrian Semantic EO Data Cube Infrastructure. Remote Sensing. 2021; 13(23):4807. https://doi.org/10.3390/rs13234807
Chicago/Turabian StyleSudmanns, Martin, Hannah Augustin, Lucas van der Meer, Andrea Baraldi, and Dirk Tiede. 2021. "The Austrian Semantic EO Data Cube Infrastructure" Remote Sensing 13, no. 23: 4807. https://doi.org/10.3390/rs13234807