1. Introduction
With the rapid development of 3D scanning technology, point clouds, as an irregular set of points that represent 3D geometry, have been widely used in various modern vision tasks, such as remote sensing application [
1,
2,
3], robot navigation [
4,
5,
6], autonomous driving [
7,
8,
9], and object pose estimation [
10,
11,
12]. However, owing to occlusion, limited viewing angles, and sensor resolution, real-world 3D point clouds captured by LiDAR and/or depth cameras are often irregular and incomplete. Therefore, point cloud completion has always been an urgent problem in point cloud data applications. Most traditional methods of shape completion are based on the geometric assumption [
13,
14,
15] that the incomplete area and some parts of the input are geometrically symmetric. These assumptions significantly limit the real-world applications of these methods. For example, Poisson surface reconstruction [
16,
17,
18] can usually repair the holes in 3D model surfaces, but discard fine-scale structures. Another geometry-based shape completion method is retrieval matching or shape similarity [
19,
20,
21]. Such methods are time consuming when applied to the matching process according to the database size, and cannot tolerate noise in the input 3D shape. Owing to the disadvantages of structural assumptions and matching time in traditional methods, the depth learning method of 3D point clouds has gradually increased recently with the emergence of large 3D model datasets, such as ModelNet40 [
22] and ShapeNet [
23]. Many deep learning-based approaches have been proposed for point cloud repair and completion.
The methods based on deep neural networks [
24,
25,
26,
27,
28,
29,
30,
31] directly map the partially missing shape input into a complete shape, among which the voxel-based method is widely used in 3D point clouds. Dai et al. [
32] proposed a point cloud completion method using a 3D encoder–predictor volumetric neural network, which inputs low-resolution missing shapes and outputs high-resolution complete shapes. Wang et al. [
33] proposed a network architecture to complete 3D shapes by combining cyclic convolution networks with antagonistic networks. A series of neural networks based on voxels were built for point cloud data processing and achieved some results; however, voxel grids were found to reduce the resolution of fine detailed shapes, and required significant calculations.
With the further development of deep learning in point cloud data processing, the proposed point cloud processing network, PointNet [
34] and PointNet++ [
35], overcome the limitation of building neural networks based on voxels. Compared with traditional voxel representation, using the point cloud as the direct input can considerably reduce the number of network parameters, and can represent fine details with less computation. This can significantly improve the training speed of the deep completion network, while retaining the shape structures of the input 3D shapes. Based on PointNet, many new methods [
3,
36] for extracting point features have been proposed.
Owing to the advantages in extracting features, the encoder–decoder approach provides a promising solution for completing point clouds with real-world structures in the missing area on inputs. The encoder encodes the input point cloud as a feature vector, and the decoder generates a dense and complete output point cloud from the feature vector. Learning Representations and Generative Models for 3D Point Clouds (L-GAN) [
37] is the first point cloud completion network based on the encoder–decoder architecture, which applies the Autoencoder Based Generative Adversarial Nets [
38] to point cloud completion. Considering that the network structure of L-GAN is generalized and not specifically designed for point cloud completion, it fails to achieve the desired effect. PCN [
39] is the first deep learning network architecture to focus on point cloud completion, which is achieved using a folding-based decoding operation to approximate a relatively smooth surface and conduct shape completion. A folding-based decoder (FBD) can hardly deform a 2D grid into subtle fine structures. PCN does not work well in completing these structures; however, in RL-GAN-Net [
40], reinforcement learning was combined with a Generative Adversarial Network (GAN) [
41] for point cloud completion for the first time. An RL agent is used to control the GAN to convert the noisy part of the point cloud data into a high-fidelity complementary shape. The network focuses more on the speed of prediction rather than improving the accuracy of prediction. PF-Net [
36] uses a multi-layer Gaussian pyramid network model to divide the feature vector encoding of the point cloud into different levels, from rough to fine, and to predict the results of different layers; these results are combined to generate the final point cloud. In addition, PF-Net only generates the missing part of the point cloud, which effectively avoids the problem of changing existing points during the generation process.
These methods typically use an encoder structure to extract the overall shape information from the input partial data, to generate a coarse shape, and subsequently, refine the coarse shape to a fine detailed point set to generate a complete point cloud. This method of generating point clouds typically extracts only the global characteristics of point clouds, and ignores the local characteristics of the point clouds, resulting in the predicted point clouds being generalized as the average of objects of the same class. The degradation of the local details is predictable. There are two main reasons for this problem. (1) The characteristics of the input point cloud are not fully utilized, where only the global characteristics of the point cloud are utilized, and the local characteristics are not considered. (2) The two-stage point cloud generation method, which ranges from rough to dense, results in a loss of local detail. To solve these problems, this study uses a multi-view-based method with an encoder–decoder architecture to leverage the structure and local information of sparse 3D data.
The multi-view-based method [
42,
43,
44,
45,
46,
47] is used to project shapes into multiple views, to extract profile features in multiple directions of point clouds. In MVCNN [
42], a 3D shape classification method based on multiple views is employed for the first time. A 2D rendering graph obtained from the different perspectives of the 3D model is then used to generate a 3D shape classifier. The method then max-poles multi-view features into a global descriptor to assist the classification. MHBN [
43] uses harmonized bilinear pooling to generate global descriptors, which integrate local convolution features to make the global descriptor more compact. On this basis, several other methods [
44,
45,
46] have been proposed to improve the recognition accuracy. In the latest paper by Wei, View-GCN [
47] applies graph convolutional networks to multiple views, and uses 2D multi-views of 3D objects to construct view-graphs as graph nodes. The experiments show that the view-GCN can obtain the best 3D shape classification results.
Given that it can be challenging for networks to directly exploit edge features in irregularly distributed incomplete point clouds, this study introduces a multi-view-based method for point cloud completion, and designs a convolutional neural network with an encoder–decoder architecture, comprising (1) multi-view-based boundary feature point extraction and (2) point cloud generation based on the encoder–decoder structure. In the first stage, the point cloud is projected in multiple directions. The 3D point clouds can easily cause higher density in the overlapping regions, and increase the computational cost when projected onto a plane. Therefore, a new boundary extraction method is used to sample each projection. This method eliminates the overlap caused by projection, and makes the network focus on characteristic profile information. In the second stage of the point projection network (PP-Net), an encoder–decoder structure is designed based on point cloud multi-directional projection. It extracts global features, and combines profile features from the projection and boundary feature points in different directions, which are fused into the feature vector by the encoder; then, a point cloud with fine profiles is generated by the decoder. In addition, a joint loss that combines the distance loss of multi-directional projections of a point cloud with adversarial loss is proposed to make the output point cloud more evenly distributed and closer to the ground truth.
The main contributions of the study follow.
A multi-view-based method using encoder–decoder architecture is proposed to complete the point cloud, which is performed through projections in multiple directions of an incomplete point cloud.
For the projection stage, a boundary feature extraction method is proposed, which can eliminate the overlap caused by projection and make the network focus on the characteristic profile information.
A new joint loss function is designed to combine the projected loss with adversarial loss to make the output point cloud more evenly distributed and closer to the ground truth.
3. Experiment and Result Analysis
This section first introduces the environment and parameters when training the completion network, and then, quantitatively and qualitatively evaluates the PP-Net and other existing point cloud completion methods. These methods will be used to complete some actual examples of point clouds for comparison and to visualize their completion results.
3.1. Experimental Implementation Details
To make the proposed PP-Net converge quickly during the network training, the mean value of the sampling point coordinates of the incomplete and complete point cloud models is normalized to zero; that is, the range of coordinates of each sampling point is scaled to (−1,1). PyTorch is then used to implement the proposed network. All network modules are alternately trained using the ADAM optimizer, with an initial learning rate of 0.0001 and a batch size of 25. Batch normalization and RELU activation units were used in the MRE and discriminator, but only used RELU activation units in the FBD.
In the data preprocessing, complete point cloud data are read in and processed to generate the incomplete point cloud in real time during each training. In the projection boundary extraction, the number of projection points is set to , where is the size of the incomplete point cloud. The boundary takes of the number of projection points, the number is , and the hyperparameter is 0.5; nine projections of size are obtained. In the MRE, the network uses a five-layer PointNet encoder, and the output feature sizes are 64, 128, 256, 512, and 1024. The network inputs nine projections separately, and connects the output of the last three layers to obtain a 9 × 1792-dimensional feature vector. Finally, the feature vector V is obtained through a three-layer MLP (9–1). In the first stage of the FBD, the decoder generates grid points, where the decoder sets to the number of squares, which is close to the number of missing point clouds; for example, if the number of missing point clouds is 512, is set to 576 (). The grid points are then converted into an matrix. In the second stage of the FBD, before the folding operation, to match the output of the encoder with the input of the decoder, the decoder inputs the feature vector V (with a size of 1792) generated by the encoder into the three-layer MLP (the output dimensions of each layer are 1792, 1792, and 512) to obtain a 512-dimensional codeword as the decoder input. Then, two consecutive folding operations are performed to obtain the final predicted point cloud. The MLP output sizes of the two folding operations were 512, 512, and 3. In the joint loss, the hyperparameter of multi-directional projection distance loss is 0.2, the hyperparameter of the multi-directional projection distance loss is 0.95, and the hyperparameter of the adversarial loss is 0.05.
3.2. Evaluation Standard
The network uses the point cloud completion accuracy of 13 categories in the dataset to evaluate the performance of the model. The evaluation used in this study contains two types of errors: predicted point cloud (Pred) → ground truth (GT) error and ground truth (GT) → predicted point cloud (Pred) error, which has been used in other papers [
50,
51].
The Pred→GT error calculates the CD from the predicted point cloud to the ground truth, which represents the difference between the predicted point cloud and ground truth.
The GT→Pred error calculates the CD from the ground truth to the predicted point cloud, which represents the extent to which the predicted point cloud covers the real point cloud. The error of the complete point cloud is caused by the change in the original point cloud and the prediction error of the missing point cloud. Because only the missing part of the point cloud is output, the original part of the shape is not changed. To ensure that the evaluation is fair, the Pred→GT and GT→Pred errors of the missing point cloud are compared. When the two errors are smaller, the complete point cloud generated by the model and the ground real point cloud are more similar, and the model performs better.
3.3. Experimental Results
After the data were generated, the proposed completion network was verified on the ShapeNet-based dataset.
Figure 6 shows part of the results of the shape completion. For each point cloud model, the first column shows the input point cloud model, the second column shows the result output of the completed network, and the third column shows the ground truth. The high-quality point cloud predicted by the PP-Net matches well with part of the input.
Table 1 shows the average value of the 13-category point cloud completion accuracy of some classic point cloud completion methods (details are in
Section 3.4). In the table, the Pred→GT error (left side) represents the difference between the predicted point cloud and ground truth, and the GT→Pred error (right side) represents the extent to which the predicted point cloud covers the ground truth. It can be seen that the PP-Net has advantages in both errors, indicating that the proposed method is effective.
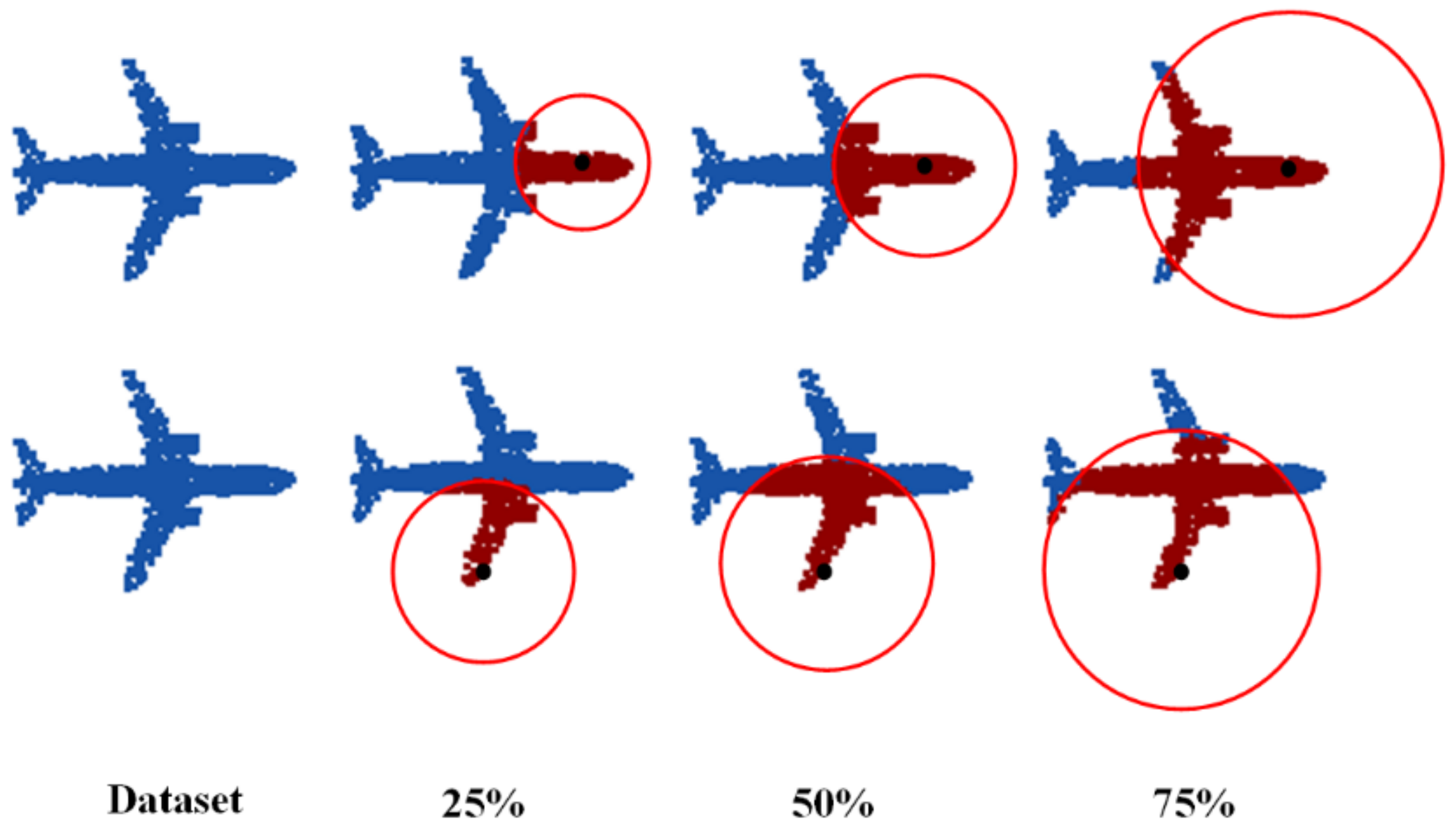
The PP-Net can encode the multi-directional projection of an incomplete point cloud as a 1792-dimensional feature, which represents the global feature of the 3D shape and multi-directional boundary feature. To verify its robustness for point cloud completion with different degrees of missing areas, the network parameters were adjusted to train it to repair point clouds with missing degrees of 25%, 50%, and 75%.
Figure 7 and
Table 2 show the performance of the network in the test set.
Figure 7 shows that, even in the case of a large missing area, the network can still fully identify and repair the outline of the overall point cloud.
Table 2 show that, for predicted point clouds generated with different degrees of missing areas, the error between the predicted point cloud and ground truth is unchanged, which proves the robustness of the proposed network to varying degrees of missing information. To further prove the robustness of the network, the network was trained to complete missing point clouds at multiple locations. The results are shown in
Figure 8. The network can still correctly predict the missing point cloud, while ensuring that the error is unchanged.
3.4. Comparison with Other Methods
To verify the advanced nature of the proposed method, in this study, three existing strong baseline point cloud completion methods were selected for comparison with the PP-Net. These three methods are the same as those in the PP-Net. The network was trained based on an encoding–decoding structure. All methods were trained and tested using the same dataset for a quantitative comparative analysis.
L-GAN [
37]: L-GAN is the first point cloud completion method based on deep learning, which also uses an encoder–decoder structure, specifically, a PointNet-based encoder and simple fully connected decoder in the decoding module.
PCN [
39]: This is the most well-known method for point cloud completion. It provides good results, and is one of the best performing methods for point cloud completion. Similar to the PP-Net, PCN uses an FBD to output the final result.
PF-Net [
36]: PF-Net employs a CMLP based on PointNet, which concatenates the features extracted by MLP to obtain the feature vector. The encoder of the PP-Net is inspired by the CMLP. It proposes a three-stage point cloud completion method from rough to fine in the decoding module.
The results are presented in
Table 3. Comparing the results of 13 different categories of different objects of point cloud completion, the proposed method (PP-Net) outperforms the existing methods in 6 of the 13 categories for the Pred→GT and GT→Pred errors, namely, airplane, car, laptop, motorbike, pistol, and skateboard. One of the Pred→GT and GT→Pred errors for PP-Net is better than those for the existing methods in four categories: cap, bag, table, and lamp. There are also three types of completion results that are not dominant, namely, chair, guitar, and mug. It can be found that the completion result is mainly affected by the following three factors: (1) whether object is symmetrical, (2) whether there are subtle fine structures, and (3) whether there is occlusion. The PP-Net projects the point cloud in various directions; for symmetrical objects, the missing structure can be inferred from the projection. Objects, such as airplanes, cars, laptops, motorbikes, pistols, and skateboards, are symmetrical in at least one direction, meaning good results can be obtained. The shape of a guitar with a sound hole is not necessarily symmetrical, thus affecting the completion result. The decoder of the PP-Net is based on a folding decoder. It is difficult to deform the grid into subtle, fine structures; because such structures exist in bag, table, chair, and mug, the completion is affected. The disadvantage of the multi-view-based method is that information loss is inevitable when projecting complex structures. Most lamps are equipped with lampshades. During projection, the structural information of the lamp cannot be extracted, thus affecting the completion result. However, in general, the PP-Net achieved better results in some categories, while demonstrating advantages in the average error of all categories.
In
Figure 9, the output point cloud generated by the abovementioned methods is visualized, and all were from the test set. Compared with other methods, the PP-Net prediction shows a clear boundary, with a more complete recovery level and finer profile. In (1), (5), and (9), the outputs of the other methods are blurred in the fine profile. In (3) and (8), the outputs of the other methods fail to generate a reasonable shape. In (6), (7), and (8), there is a certain deviation in the outline of the other methods. We also take advantage of PF-Net. Only the missing parts are output, and the hollows and backrests are properly filled in (2) and (4). To summarize, the proposed approach focuses more on boundaries and produces finer profiles.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}