
Attention-Based Spatial and Spectral Network with PCA-Guided Self-Supervised Feature Extraction for Change Detection in Hyperspectral Images



Abstract
:1. Introduction
- The spatial features extracted by existing methods may not target for CD. For example, some methods require transfer learning from other tasks such as classification, segmentation, etc. These tasks require large-scale labeled data sets for supervised training, which increases the cost of use. There are also some methods that use autoencoders to extract the deep expression of each image. The features extracted by these two methods may not be suitable for CD. Therefore, how to extract sufficiently good spatial differential representations for CD tasks is a very critical issue.
- Most methods adopt a uniform global weight factor when combining spatial and spectral features, that is, spatial and spectral features are analyzed according to the same ratio for each pixel at each location, which is obviously a little rough. Therefore, how to balance these two features in a task-driven adaptive way is also worth studying.
- (1)
- A novel PCA-guided self-supervised spatial feature extraction network, which establishes the mapping relationship from the difference to the principal components of the difference, so as to extract more specific difference representation.
- (2)
- The attention mechanism is introduced, which adaptively balances the proportion of spatial and spectral features, avoiding rough combination with global uniform ratio, making the model more adaptable.
- (3)
- We propose an innovative framework for hyperspectral image change detection, which involves a novel PCA-guided self-supervised spatial feature extraction network and an attention-based spatial-spectral fusion network. Moreover, the proposed ASSCDN can achieve the superior performance using only a small number of training samples on three widely used HSI CD datasets.
2. Related Works
2.1. Traditional CD Methods
2.2. Deep Learning-Based CD Methods
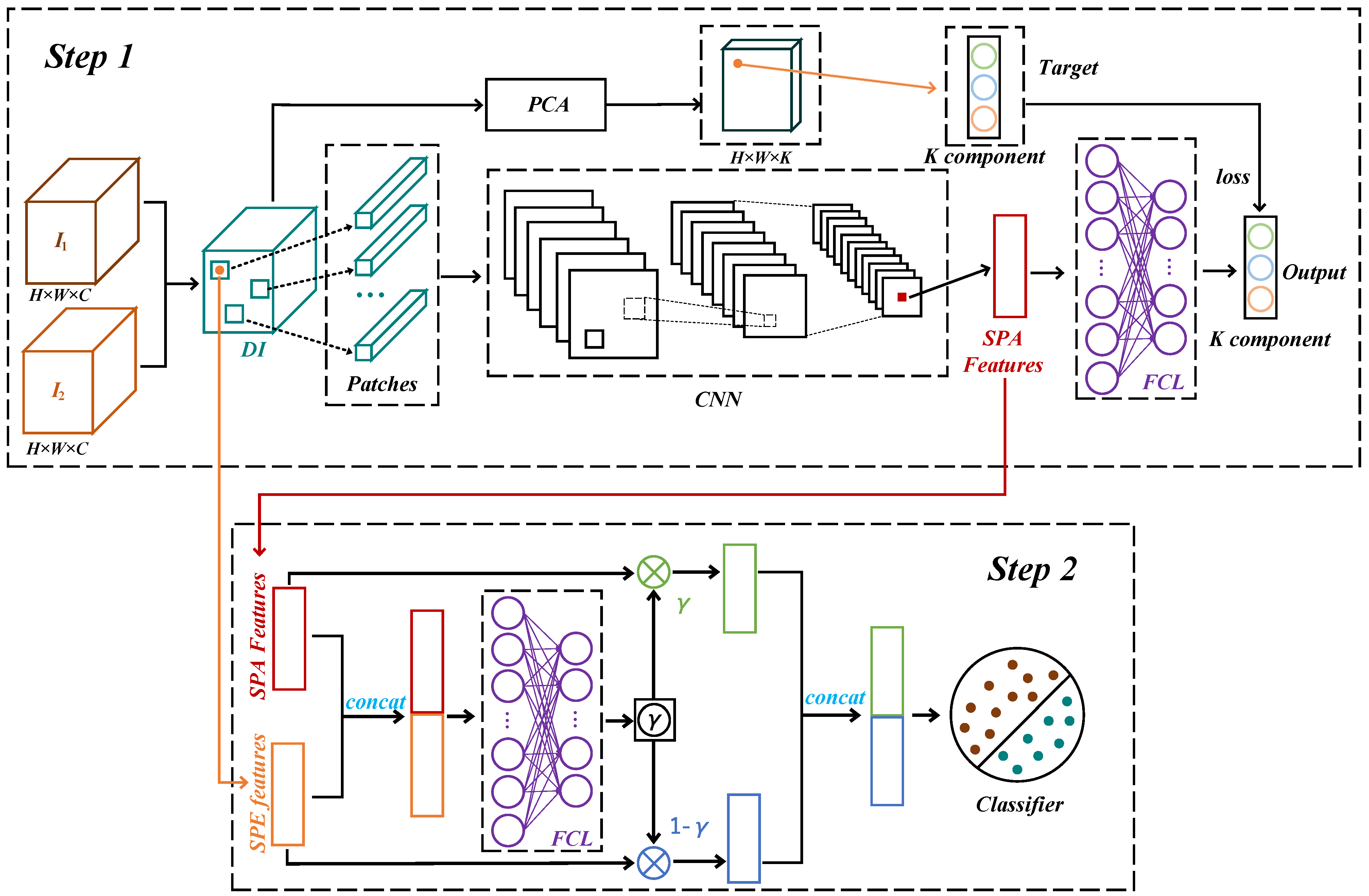
3. Proposed Method
3.1. Data Preparation
3.1.1. Data Preprocessing
3.1.2. Training Data Generation
3.1.3. Principal Component Analysis (PCA) for DM
3.2. PCA-Guided Self-Supervised Spatial Feature Extraction
3.3. Attention-Based Spatial and Spectral Network
3.4. Training and Testing Process
3.4.1. Training and Testing PCASFEN
3.4.2. Training and Testing ASSCDN
4. Experiments and Analysis
4.1. Dataset Descriptions
4.2. Experimental Settings
4.2.1. Evaluation Metrics
4.2.2. Comparative Methods
- (1)
- CVA, which is a classic method for CD, is a comprehensive measure for the differences in each spectral band [61]. Therefore, CVA is suitable for HSI CD.
- (2)
- KNN, aims to acquire the prediction labels of new data through the labels of the nearest K samples, which is used to acquire CDM.
- (3)
- SVM, a commonly applied supervised classifier, which is exploited to classify a difference image into a binary change detection map.
- (4)
- RCVA, was proposed by Thonfeld et al. for multi-sensor satellite images CD to improve the detection performance [39].
- (5)
- DCVA, can achieve an unsupervised CD based on deep change vector analysis, which implemented a pretrained CNN to extract features of bitemporal images [50].
- (6)
- DSFA, which employs two symmetric deep networks for multitemporal remote sensing images in [51]. This approach can effectively enhance the separability of changed and unchanged pixels by slow feature analysis.
- (7)
- GETNET, which is a benchmark method on River dataset [6]. This method introduces a unmixing-based subpixel representation to fuse multi-source information for HSI CD.
- (8)
- TDSSC, which can capture representative spectral–spatial features by concatenating the feature of spectral direction and two spatial directions, and thus improving detection performance [20].
4.2.3. Implementation Details
4.3. Ablation Study and Parameter Analysis on River Dataset
4.3.1. Ablation Study for Different Components
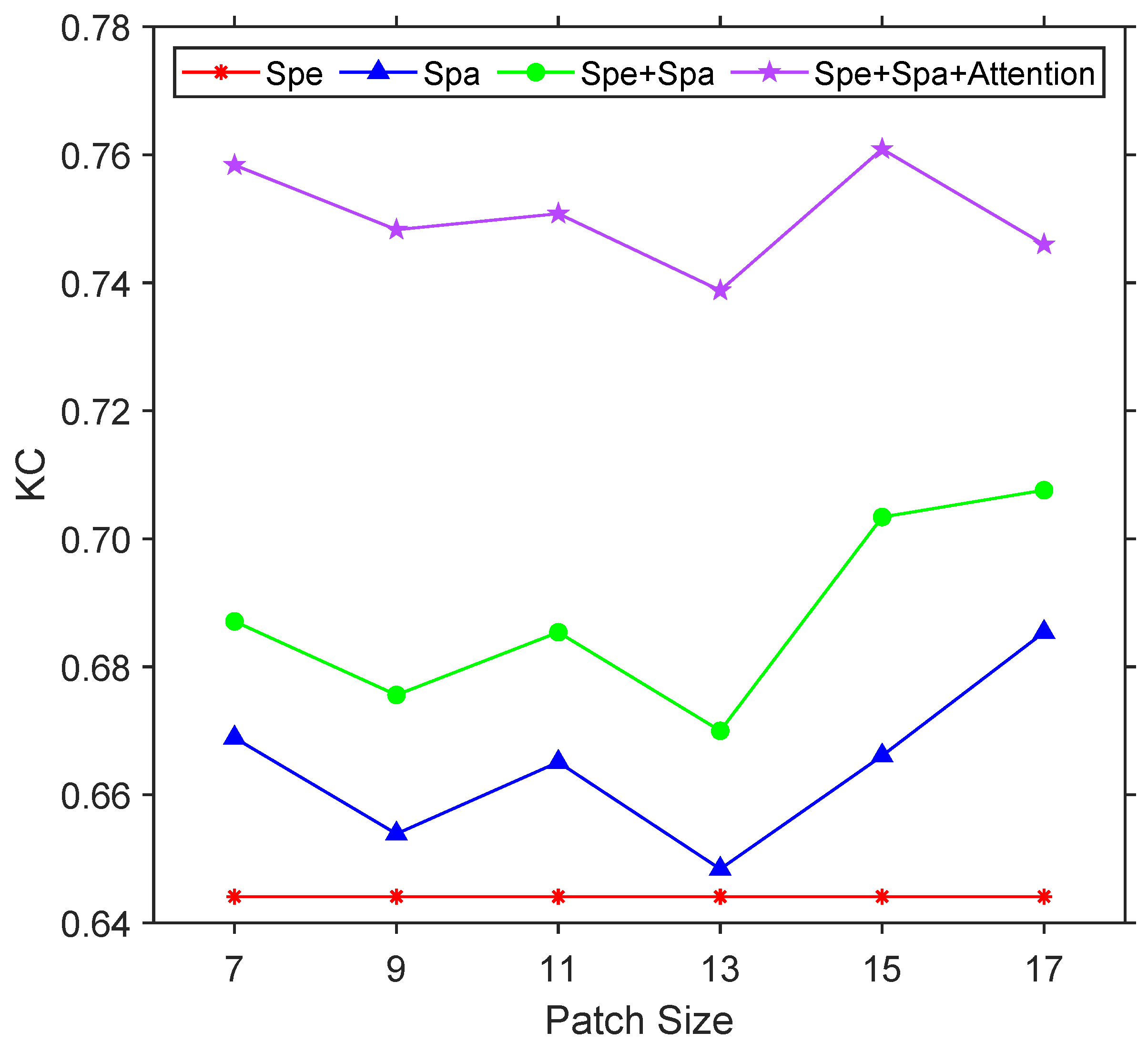
4.3.2. Sensitivity Analysis of Patch Size
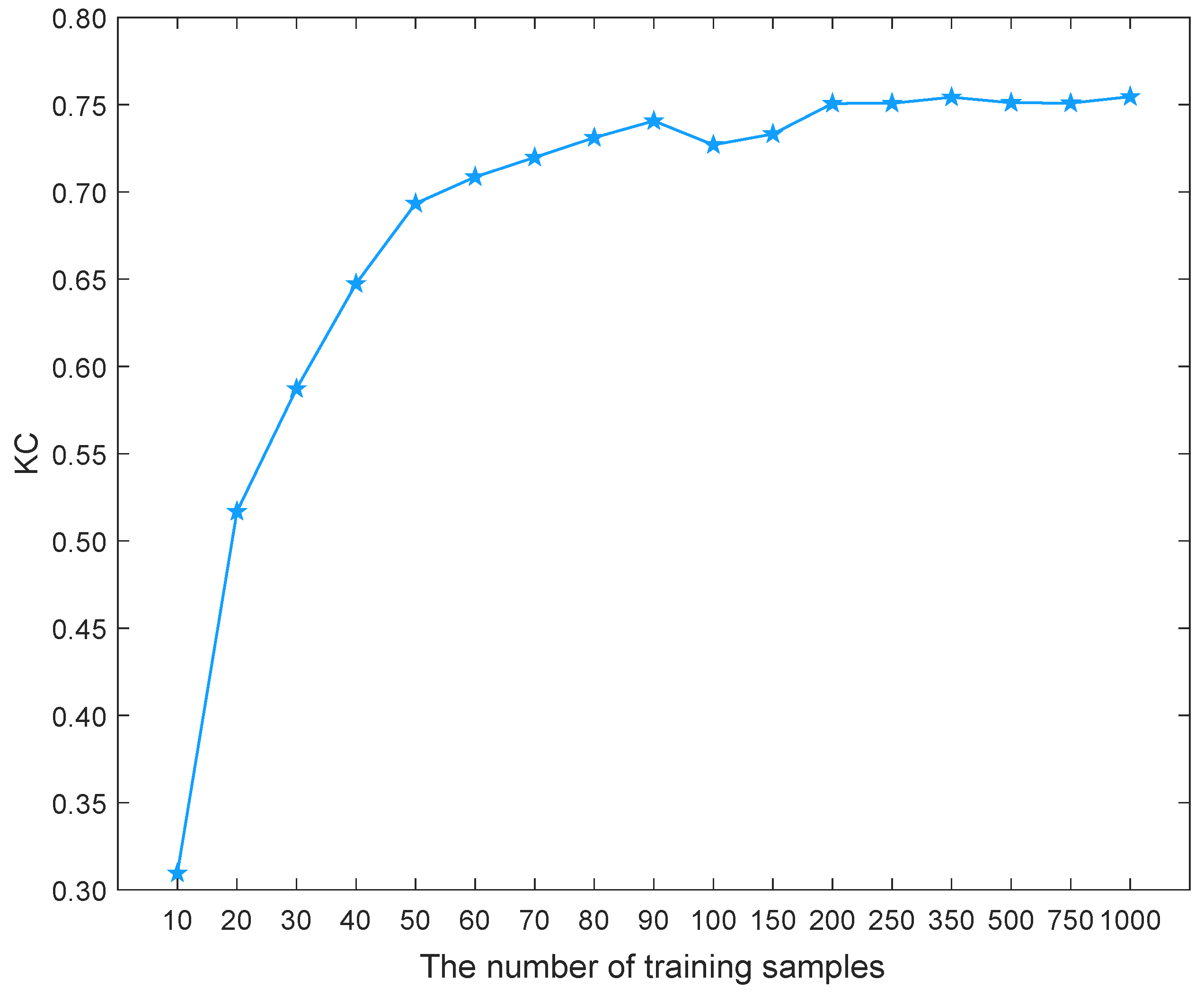
4.3.3. Analysis of the Relationship between the Number of Training Samples and Accuracy
4.4. Comparison Results and Analysis
4.4.1. Results and Comparison on Barbara and Bay Datasets
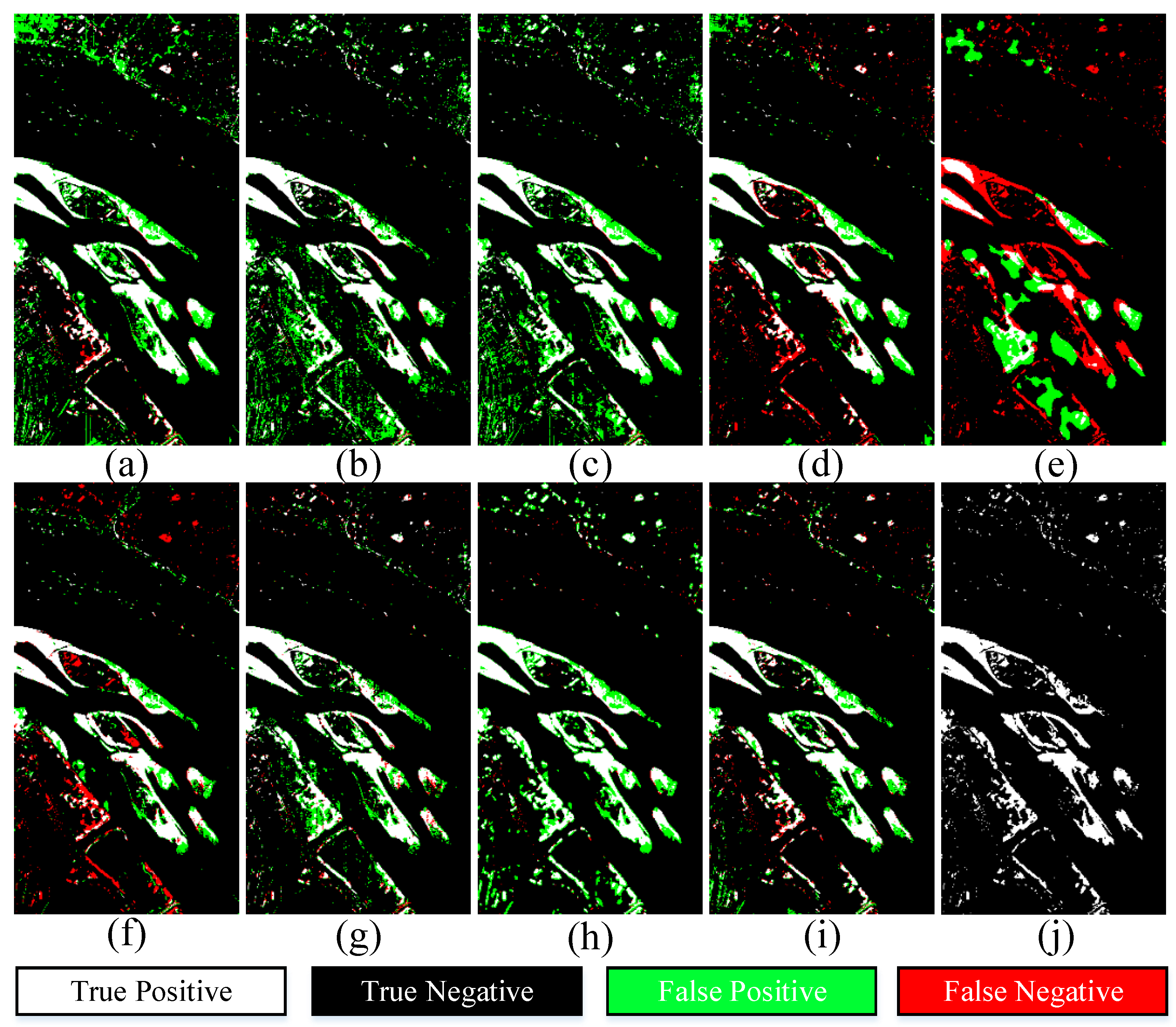
4.4.2. Results and Comparison on River Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lu, D.; Mausel, P.; Brondizio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Review ArticleDigital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Liu, S.; Marinelli, D.; Bruzzone, L.; Bovolo, F. A review of change detection in multitemporal hyperspectral images: Current techniques, applications, and challenges. IEEE Geosci. Remote Sens. Mag. 2019, 7, 140–158. [Google Scholar] [CrossRef]
- ZhiYong, L.; Liu, T.; Benediktsson, J.A.; Falco, N. Land Cover Change Detection Techniques: Very-High-Resolution Optical Images: A Review. IEEE Geosci. Remote Sens. Mag. 2021, 2–21. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A general end-to-end 2-D CNN framework for hyperspectral image change detection. IEEE Trans. Geosci. Remote Sens. 2018, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Du, Q.; Tong, X.; Samat, A.; Pan, H.; Ma, X. Band selection-based dimensionality reduction for change detection in multi-temporal hyperspectral images. Remote Sens. 2017, 9, 1008. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Gong, M.; Li, H.; Zhang, M.; Li, J. A two-phase multiobjective sparse unmixing approach for hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2017, 56, 508–523. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Zanetti, M.; Du, P. Sequential spectral change vector analysis for iteratively discovering and detecting multiple changes in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4363–4378. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Du, P. Hierarchical unsupervised change detection in multitemporal hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 244–260. [Google Scholar]
- Marinelli, D.; Bovolo, F.; Bruzzone, L. A novel change detection method for multitemporal hyperspectral images based on binary hyperspectral change vectors. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4913–4928. [Google Scholar] [CrossRef]
- Song, A.; Choi, J.; Han, Y.; Kim, Y. Change detection in hyperspectral images using recurrent 3D fully convolutional networks. Remote Sens. 2018, 10, 1827. [Google Scholar] [CrossRef] [Green Version]
- Zhan, T.; Gong, M.; Jiang, X.; Zhang, M. Unsupervised Scale-Driven Change Detection With Deep Spatial–Spectral Features for VHR Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5653–5665. [Google Scholar] [CrossRef]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Liu, H.; Cao, X. Deep fully convolutional network-based spatial distribution prediction for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. A simplified 2D-3D CNN architecture for hyperspectral image classification based on spatial–spectral fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2485–2501. [Google Scholar] [CrossRef]
- Wang, D.; Du, B.; Zhang, L.; Xu, Y. Adaptive Spectral–Spatial Multiscale Contextual Feature Extraction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2461–2477. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Hyperspectral anomalous change detection based on joint sparse representation. ISPRS J. Photogramm. Remote Sens. 2018, 146, 137–150. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Li, L.; Tao, R.; Du, Q. Hyperspectral change detection based on multiple morphological profiles. IEEE Trans. Geosci. Remote. Sens. 2021, 1–12. [Google Scholar] [CrossRef]
- Zhan, T.; Song, B.; Sun, L.; Jia, X.; Wan, M.; Yang, G.; Wu, Z. TDSSC: A Three-Directions Spectral–Spatial Convolution Neural Network for Hyperspectral Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 377–388. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Misra, I.; Maaten, L.V.d. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE Conference on Computer Vision Recognition, CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 6707–6717. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sensing 2020, 12, 1662. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; Van Der Voort, M.; Tekinerdogan, B. Effect of Attention Mechanism in Deep Learning-Based Remote Sensing Image Processing: A Systematic Literature Review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. Pga-siamnet: Pyramid feature-based attention-guided siamese network for remote sensing orthoimagery building change detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Gong, M.; Jiang, F.; Zhang, Y.; Li, H. Landslide Inventory Mapping Method Based on Adaptive Histogram-Mean Distance with Bitemporal VHR Aerial Images. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- You, Y.; Cao, J.; Zhou, W. A survey of change detection methods based on remote sensing images for multi-source and multi-objective scenarios. Remote Sens. 2020, 12, 2460. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Automatic analysis of the difference image for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef] [Green Version]
- Bazi, Y.; Bruzzone, L.; Melgani, F. An unsupervised approach based on the generalized Gaussian model to automatic change detection in multitemporal SAR images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 874–887. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Chen, Y. Multi-feature object-based change detection using self-adaptive weight change vector analysis. Remote Sens. 2016, 8, 549. [Google Scholar] [CrossRef] [Green Version]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Bazi, Y.; Melgani, F.; Bruzzone, L.; Vernazza, G. A genetic expectation-maximization method for unsupervised change detection in multitemporal SAR imagery. Int. J. Remote Sens. 2009, 30, 6591–6610. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Shao, P.; Shi, W.; He, P.; Hao, M.; Zhang, X. Novel approach to unsupervised change detection based on a robust semi-supervised FCM clustering algorithm. Remote Sens. 2016, 8, 264. [Google Scholar] [CrossRef] [Green Version]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change detection based on deep siamese convolutional network for optical aerial images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Migas-Mazur, R.; Kycko, M.; Zwijacz-Kozica, T.; Zagajewski, B. Assessment of Sentinel-2 Images, Support Vector Machines and Change Detection Algorithms for Bark Beetle Outbreaks Mapping in the Tatra Mountains. Remote Sens. 2021, 13, 3314. [Google Scholar] [CrossRef]
- Zhuang, H.; Deng, K.; Fan, H.; Yu, M. Strategies combining spectral angle mapper and change vector analysis to unsupervised change detection in multispectral images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 681–685. [Google Scholar] [CrossRef]
- Thonfeld, F.; Feilhauer, H.; Braun, M.; Menz, G. Robust Change Vector Analysis (RCVA) for multi-sensor very high resolution optical satellite data. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 131–140. [Google Scholar] [CrossRef]
- Kuncheva, L.I.; Faithfull, W.J. PCA feature extraction for change detection in multidimensional unlabeled data. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 69–80. [Google Scholar] [CrossRef]
- Bazi, Y.; Melgani, F.; Al-Sharari, H.D. Unsupervised change detection in multispectral remotely sensed imagery with level set methods. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3178–3187. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Myint, S.W.; Lu, P.; Wang, Q. Semi-automated landslide inventory mapping from bitemporal aerial photographs using change detection and level set method. Remote Sens. Environ. 2016, 175, 215–230. [Google Scholar] [CrossRef]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy clustering with a modified MRF energy function for change detection in synthetic aperture radar images. IEEE Trans. Fuzzy Syst. 2013, 22, 98–109. [Google Scholar] [CrossRef]
- Yu, H.; Yang, W.; Hua, G.; Ru, H.; Huang, P. Change detection using high resolution remote sensing images based on active learning and Markov random fields. Remote Sens. 2017, 9, 1233. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 125–138. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Wang, M.; Tan, K.; Jia, X.; Wang, X.; Chen, Y. A deep siamese network with hybrid convolutional feature extraction module for change detection based on multi-sensor remote sensing images. Remote Sens. 2020, 12, 205. [Google Scholar] [CrossRef] [Green Version]
- Lv, Z.; Liu, T.; Kong, X.; Shi, C.; Benediktsson, J.A. Landslide Inventory Mapping With Bitemporal Aerial Remote Sensing Images Based on the Dual-Path Fully Convolutional Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4575–4584. [Google Scholar] [CrossRef]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised deep change vector analysis for multiple-change detection in VHR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Yuan, Z.; Wang, Q. Unsupervised deep noise modeling for hyperspectral image change detection. Remote Sens. 2019, 11, 258. [Google Scholar] [CrossRef] [Green Version]
- Saha, S.; Bovolo, F.; Bruzzone, L. Building change detection in VHR SAR images via unsupervised deep transcoding. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1917–1929. [Google Scholar] [CrossRef]
- Wu, C.; Chen, H.; Du, B.; Zhang, L. Unsupervised Change Detection in Multitemporal VHR Images Based on Deep Kernel PCA Convolutional Mapping Network. IEEE Trans. Cybern. 2021, 1–15. [Google Scholar] [CrossRef]
- Shao, P.; Shi, W.; Liu, Z.; Dong, T. Unsupervised change detection using fuzzy topology-based majority voting. Remote Sens. 2021, 13, 3171. [Google Scholar] [CrossRef]
- Jiang, F.; Gong, M.; Zhan, T.; Fan, X. A semisupervised GAN-based multiple change detection framework in multi-spectral images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1223–1227. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- López-Fandiño, J.; Garea, A.S.; Heras, D.B.; Argüello, F. Stacked autoencoders for multiclass change detection in hyperspectral images. In Proceedings of the 2018 IEEE International Geoscience & Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA; pp. 1906–1909. [Google Scholar]
- Lv, Z.; Li, G.; Jin, Z.; Benediktsson, J.A.; Foody, G.M. Iterative training sample expansion to increase and balance the accuracy of land classification from VHR imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 139–150. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Benediktsson, J.A. Object-oriented key point vector distance for binary land cover change detection using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6524–6533. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain. IEEE Trans. Geosci. Remote Sens. 2006, 45, 218–236. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | OA(%) | KC | F1 (%) |
|---|---|---|---|
| spe | 92.32 | 0.6441 | 68.38 |
| spa | 93.60 | 0.6661 | 70.06 |
| spe + spa | 94.61 | 0.7034 | 73.27 |
| spe + spa + Attention | 95.82 | 0.7609 | 78.37 |
| Methods | OA (%) | KC | F1 (%) | PRE (%) | REC (%) |
|---|---|---|---|---|---|
| CVA [61] | 87.12 | 0.7320 | 83.96 | 82.26 | 85.72 |
| KNN | 91.02 | 0.8122 | 88.64 | 88.24 | 89.05 |
| SVM | 93.21 | 0.8568 | 91.20 | 93.01 | 89.46 |
| RCVA [39] | 86.74 | 0.7226 | 83.22 | 82.83 | 83.62 |
| DCVA [50] | 79.21 | 0.5313 | 66.96 | 89.24 | 53.59 |
| DSFA [51] | 86.76 | 0.7174 | 69.83 | 87.06 | 77.92 |
| GETNET [6] | 95.01 | 0.8962 | 93.80 | 91.62 | 96.09 |
| TDSSC [20] | 94.22 | 0.8789 | 92.67 | 92.39 | 92.95 |
| ASSCDN | 95.39 | 0.9046 | 94.33 | 91.45 | 97.39 |
| Methods | OA (%) | KC | F1 (%) | PRE (%) | REC (%) |
|---|---|---|---|---|---|
| CVA [61] | 87.61 | 0.7534 | 87.45 | 94.16 | 81.64 |
| KNN | 91.37 | 0.8268 | 91.87 | 91.58 | 92.16 |
| SVM | 92.58 | 0.8516 | 92.80 | 95.35 | 90.38 |
| RCVA [39] | 87.90 | 0.7598 | 87.46 | 96.77 | 79.79 |
| DCVA [50] | 82.48 | 0.6546 | 80.62 | 97.19 | 68.87 |
| DSFA [51] | 63.37 | 0.2800 | 58.34 | 73.24 | 48.48 |
| GETNET [6] | 85.50 | 0.7076 | 86.80 | 83.73 | 90.10 |
| TDSSC [20] | 94.63 | 0.8927 | 94.73 | 98.50 | 91.19 |
| ASSCDN | 95.53 | 0.9107 | 95.66 | 98.45 | 93.02 |
| Methods | OA (%) | KC | F1 (%) | PRE (%) | REC (%) |
|---|---|---|---|---|---|
| CVA [61] | 92.16 | 0.6272 | 66.81 | 52.86 | 90.76 |
| KNN | 92.58 | 0.6532 | 69.17 | 54.15 | 95.72 |
| SVM | 92.42 | 0.6504 | 68.96 | 53.52 | 96.92 |
| RCVA [39] | 94.65 | 0.6760 | 70.54 | 67.62 | 73.72 |
| DCVA [50] | 88.47 | 0.2466 | 30.94 | 32.27 | 29.72 |
| DSFA [51] | 94.61 | 0.6645 | 69.41 | 68.44 | 70.41 |
| GETNET [6] | 95.42 | 0.7496 | 77.45 | 67.71 | 90.45 |
| TDSSC [20] | 94.29 | 0.7134 | 74.38 | 60.94 | 95.43 |
| ASSCDN | 95.82 | 0.7609 | 78.37 | 71.18 | 87.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Jiang, F.; Liu, T.; Xie, F.; Li, P. Attention-Based Spatial and Spectral Network with PCA-Guided Self-Supervised Feature Extraction for Change Detection in Hyperspectral Images. Remote Sens. 2021, 13, 4927. https://doi.org/10.3390/rs13234927
Wang Z, Jiang F, Liu T, Xie F, Li P. Attention-Based Spatial and Spectral Network with PCA-Guided Self-Supervised Feature Extraction for Change Detection in Hyperspectral Images. Remote Sensing. 2021; 13(23):4927. https://doi.org/10.3390/rs13234927
Chicago/Turabian StyleWang, Zhao, Fenlong Jiang, Tongfei Liu, Fei Xie, and Peng Li. 2021. "Attention-Based Spatial and Spectral Network with PCA-Guided Self-Supervised Feature Extraction for Change Detection in Hyperspectral Images" Remote Sensing 13, no. 23: 4927. https://doi.org/10.3390/rs13234927