
An Overview of Neural Network Methods for Predicting Uncertainty in Atmospheric Remote Sensing


 ,
,
Abstract
:
1. Introduction
2. Theoretical Background
2.1. Point Estimates
- An exact data set , where ;
- A data set with output noise , where ; and
- A data set with input and output noise , where and .
- For a data model with output noise, we have , and with . Moreover, for the covariance matrix , where is the identity matrix, we find:or more precisely:Assuming and using Equation (21), we infer that the point estimate is the minimizer of the Tikhonov function:where is the regularization parameter.
- A model with exact data can be handled by considering the data model with output noise and by making in the representation of the data error covariance matrix . For , the relation yields , while Equation (23) and the relation gives:Thus, when learning a neural network with the exact data, the maximum likelihood estimate minimizes the sum of square errors. Note that in this case, regularization is not absolutely required, because the output data are exact.
- For a data model with input and output noise, the computation of the estimate is not a trivial task, because the covariance matrix which enters in the expression of , depends on . Moreover, in Equation (11), corresponds to a linearization of the neural network function under the assumption that the noise process in the input space is small. This problem can be solved by implicitly learning the covariance matrix from the loss function [29]. Specifically, we assume that is a diagonal matrix with entries , that is:implying:Here, we identified , and set and . To learn the variances from the loss function, we use a single network with input , and output ; thus, in the output layer, units are used to predict and units to predict . In practice, to increase numerical stability, we train the network to predict the log variance , in which case, the likelihood loss function is:with:It should be pointed out that from Equation (25) that it is apparent that the model is stopped from predicting high uncertainty through the term, but also low uncertainty for points with high residual error, as low will increase the contribution of the residual. On the other hand, it should also be noted that a basic assumption of the model is that the covariance matrix is diagonal, which unfortunately, is contradicted by Equation (11).
- In order to generate a data set with input and output noise, that is, , where , , and , we used the jitter approach. According to this approach, at each forward pass through the network, a new random noise is added to the original input vector . In other words, each time a training sample is passed through the network, random noise is added to the input variables, making them different every time it is passed through the network. By this approach, which is a simple form of data augmentation, the dimension of the data set is reduced (actually, the data set is with ).
2.2. Uncertainties
- The Laplace approximation, which yields an approximate representation for the posterior or
- A variational inference approach, which learns a variational distribution to approximate the posterior ,
- The first component is the covariance matrix in the distribution over the error in the output . This term, which is input dependent, describes the so-called aleatoric heteroscedastic uncertainty measured by . For a data model with output noise, we have (cf. Equation (11)) , and this term, which is input independent, describes the so-called aleatoric homoscedastic uncertainty measured by .
- The second component reflects the uncertainty induced in the weights , also called epistemic uncertainty or model uncertainty. The sources of this uncertainty measured by are for example: (i) non-optimal hyperparameters (the number of hidden layers, the number of units per layer, the type of activation function); (ii) non-optimal training parameters (the minimum learning rate at which the training is stopped, the learning rate decay factor, the batch size used for the mini-batch gradient descent); and (iii) a non-optimal optimization algorithm (ADAGRAD, ADADELTA, ADAM, ADAMAX, NADAM).
- The computation of the epistemic covariance matrix from Equation (34) requires the knowledge of the Hessian matrix . In general, this problem is practically insoluble because the matrix is very huge, and so, is very difficult to compute. However, the problem can be evaded by using the diagonal Hessian approximationwhere is the Kronecker delta. The diagonal matrix elements can be very efficiently computed by using a procedure which is similar to the back-propagation algorithm used for computing the first derivatives [31].
- The covariance matrix can be approximated by the conditional average covariance matrix of all network errors over the data set , meaning that:where and . Note that this is a very rough approximation, because in contrast to , does not depend on .
- For exact data, we have . Thus, when learning a neural network with exact data, the predictive distribution is Gaussian with mean and (epistemic) covariance matrix .
2.3. Bayesian Networks
2.3.1. Bayes by Backpropagation
2.3.2. Dropout
2.3.3. Batch Normalization
- The maximum a posteriori parameters ;
- The mean and variance realizations of the stochastic parameters ; and
- The moving averages of the mean and variance over the training set .
- A batch-normalized network samples the stochastic parameters once per training step (mini-batch). For a large number of epochs, the become independent and identical distributed random variables for each training example;
- The variational distribution corresponds to the joint distribution of the weights induced by the stochastic parameters ;
- The equivalence between a batch-normalized network and a Bayesian approximation was proven in [39] by showing that (cf. Equations (39) and (55)) . The proof relies on the following simplified assumptions: (i) no scale and shift transformations; (ii) batch normalization applied to each layer; (iii) independent input features in each layer; and (iv) large N and M.
3. Neural Networks for Atmospheric Remote Sensing
3.1. Neural Networks for Solving the Direct Problem
- Train a neural network with exact data for simulating the radiative transfer model;
- Compute the epistemic covariance matrix from the statistics of all network errors over the data set;
- Solve the inverse problem by a Bayesian approach under the assumption that the a priori knowledge and the measurement uncertainty are both Gaussian;
- Determine the uncertainty in the retrieval by assuming that the forward model is nearly linear.
3.2. Neural Networks for Solving the Inverse Problem
3.2.1. Method 1
- For a deterministic network, we approximate by the conditional average covariance matrix of all network errors over, that is, , yielding ;
- For a batch normalized network, we compute aswith .
- Deterministic and stochastic networks trained with exact data to compute the epistemic covariance matrix; and
- The assumption that the predictive distribution of the network output is the convolution of the predictive distribution for an uncorrupted input with the input noise distribution to estimate the covariance matrix.
3.2.2. Method 2
3.2.3. Method 3
- Assumed density filtering (ADF). This approach was applied to neural networks by Gast and Roth [58] to replace each network activation by probability distributions. In the following, we provide a simplified justification of this approach, while for a more pertinent analysis, we refer to Appendix D. For a linear layer (, the feed-forward operation (without dropout) is:By straightforward calculation, we find:and:yielding:Assuming that the are independent random variables, in which case, the covariance matrix corresponding to the column vector is diagonal, meaning that:we obtain . In summary, the iterative process for a linear layer is:For a ReLU activation function , it was shown that:where and are given by Equations (78) and (79), respectively, and:
- Interval Arithmetic (IA). Interval arithmetic is based on an extension of the real number system to a system of closed intervals on the real axis [59]. For the intervals X and Y, the elementary arithmetic operations are defined by the rule , where the binary operation ⊕ can stand for addition, subtraction, multiplication, or division. This definition guarantees that . Functions of interval arguments are defined in terms of standard set mapping, that is, the image of an interval X under a function f is the set . This is not the same as an interval function obtained from a real function f by replacing the real argument by an interval argument and the real arithmetic operations by the corresponding interval operations. The latter is called an interval extension of the real function f and is denoted by . As a corollary of the fundamental theorem of interval analysis, it can be shown that . Interval analysis provides a simple and accessible way to assess error propagation. The iterative process for error propagation is (compared with Equations (77)–(79)):while the output predictions and their standard deviations are computed aswhere is the interval extension of the activation function , and and are the left and right endpoints of the interval X, respectively, that is, .
- Transform a dropout network into its assumed density filtering or interval arithmetic versions (which does not require retraining);
- Propagate through the dropout network and collect T output predictions and variances;
- Compute the predictive mean and covariance matrix by means of Equations (87) and (88).
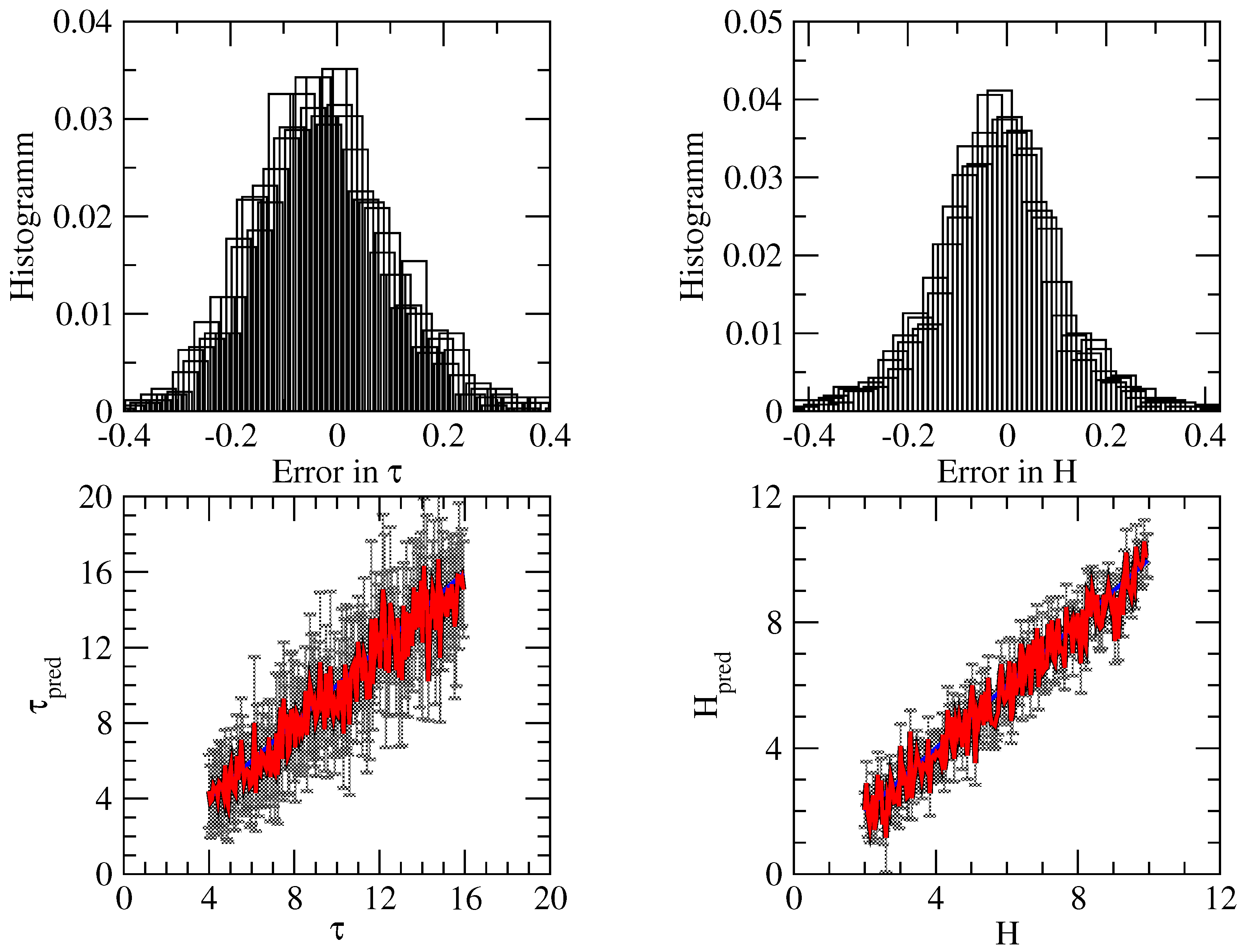
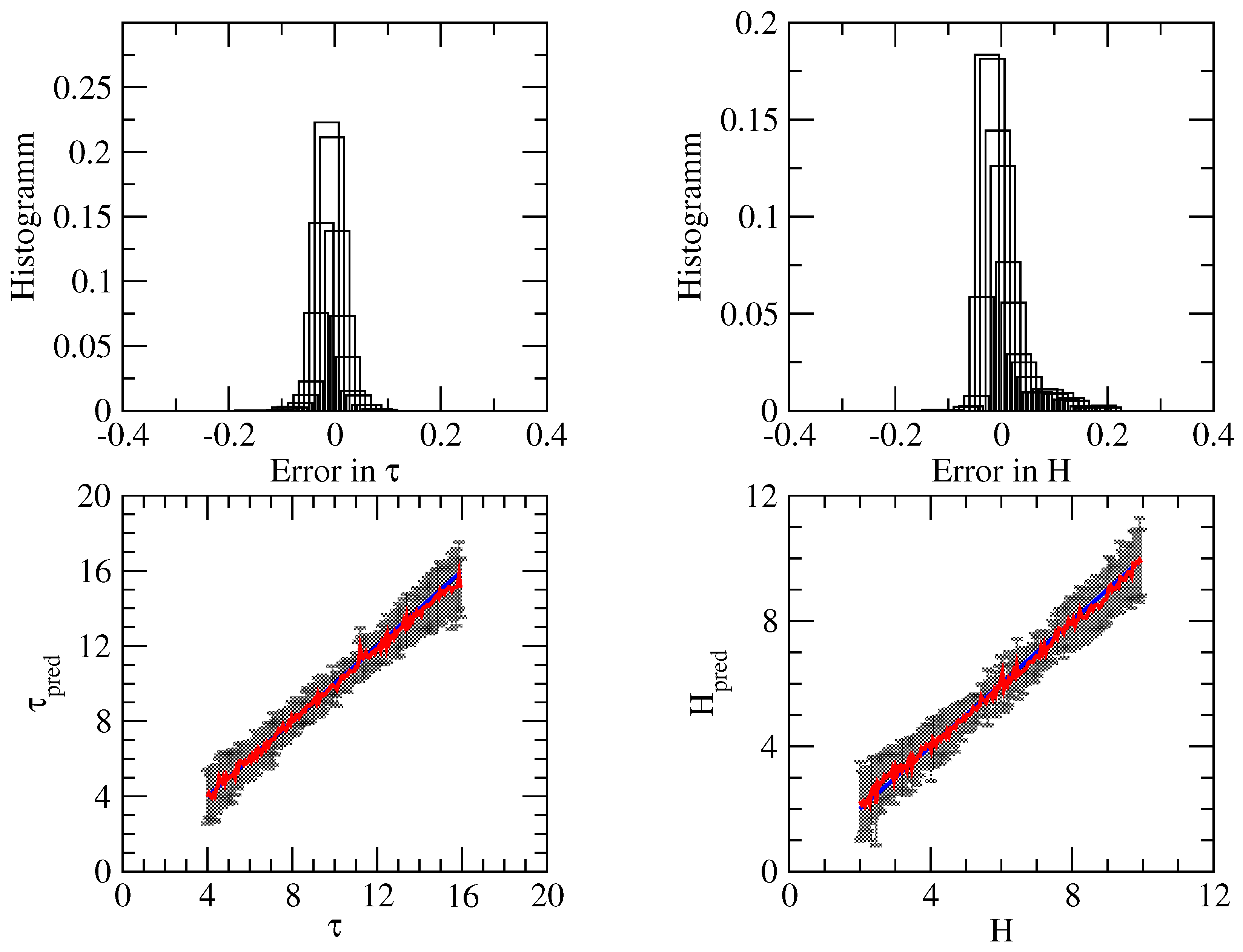
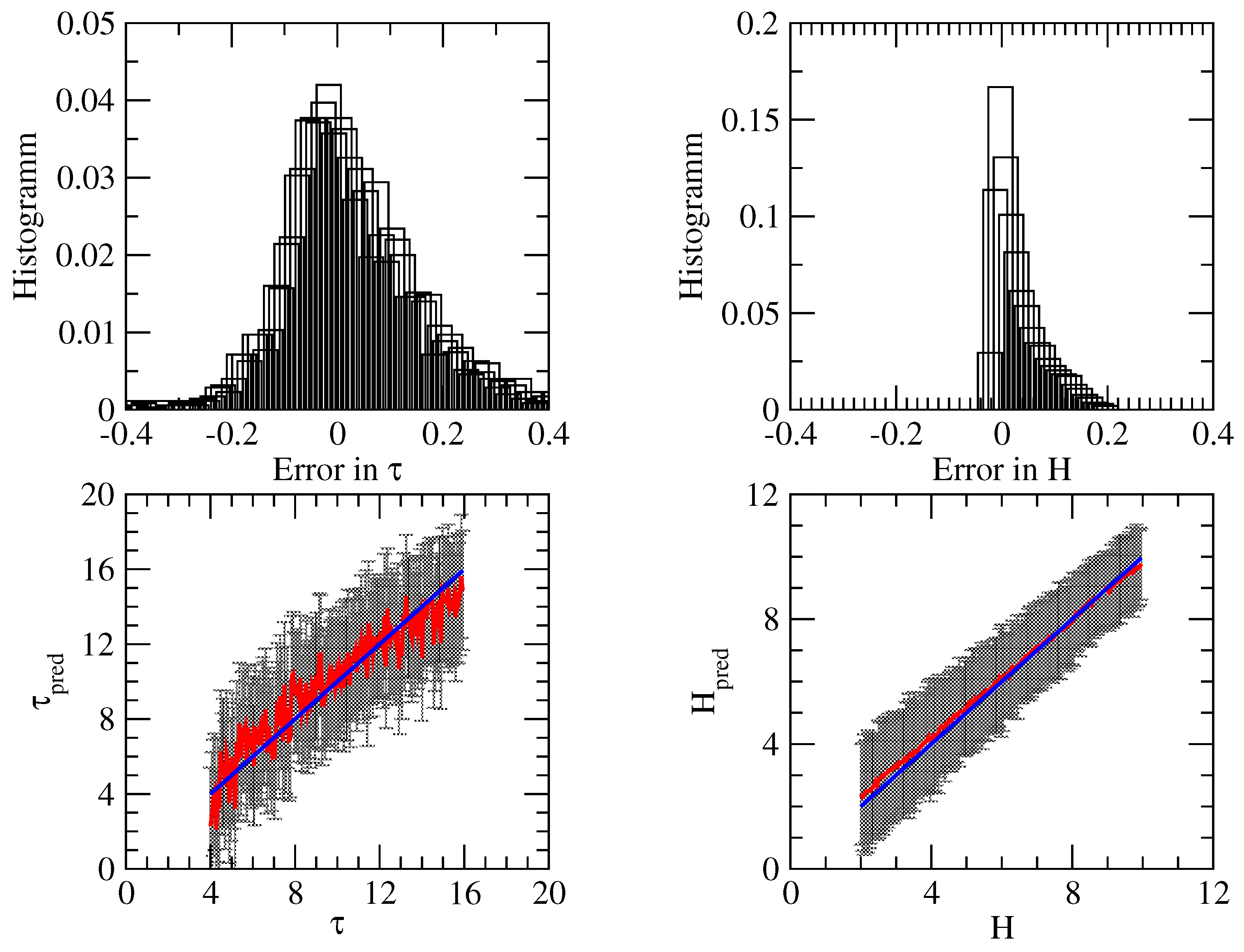
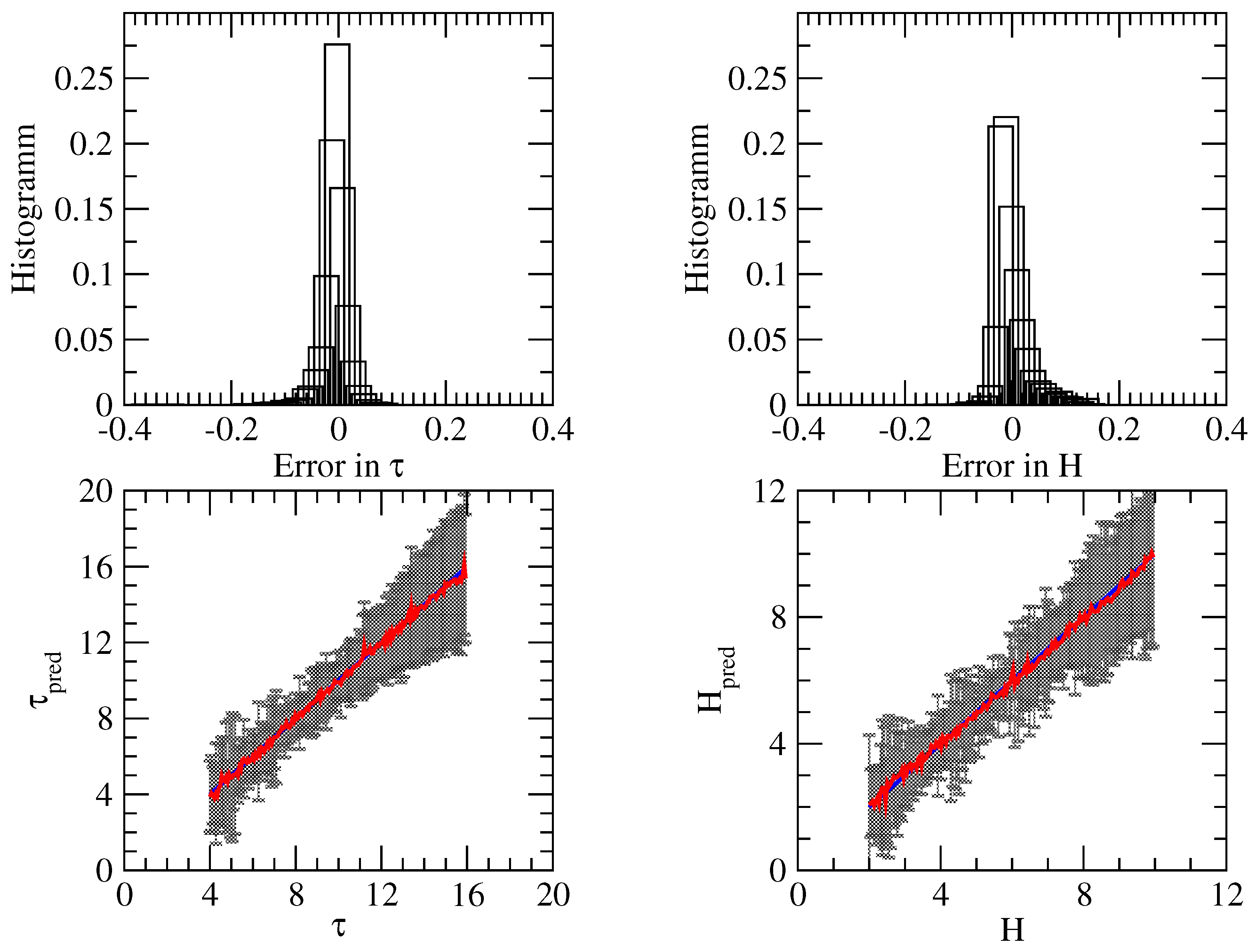
3.3. Summary of Numerical Analysis
- For the direct problem, the neural network method used in conjunction with a Bayesian inversion method provides satisfactory accuracy, but does not correctly predict the uncertainty. The reason for this is that the forward model is not nearly linear, which is the main assumption for computing the uncertainty in the retrieval.
- For the inverse problem, the following features are apparent.
- (a)
- Method 1 using a deterministic and Bayes-by-backprop network yields a low accuracy, while the method using dropout and batch-normalized networks provides high accuracy;
- (b)
- Method 2 using a dropout network has an acceptable accuracy. For cloud top height retrieval, the method using a Bayes-by-backprop network has a similar accuracy, but for cloud optical thickness retrieval, the accuracy is low. Possible reasons for the loss of accuracy of a Bayes-by-backprop network can be (i) a non-optimal training and/or the use of the prior instead of that given by Equation (45) (recall that for , the KL divergence can be computed analytically).
- (c)
- Method 3 with assumed density filtering and interval arithmetic is comparable with Method 2 using a dropout network, that is, the method has a high accuracy.
- (d)
- From the methods with reasonable accuracy, by using a dropout network, Method 2 predicts similar uncertainties to Method 3 with assumed density filtering and interval arithmetic. In contrast, using dropout and batch normalized networks, Method 1 provides lower uncertainties, dominated by epistemic uncertainties. In general, it seems that Method 1 predicts a too small heteroscedastic uncertainty. Possibly, this is due to the fact that we trained a neural network with exact data, and for this retrieval example, the predictive distribution, represented as a convolution integral over the input noise distribution, does not correctly reproduce the aleatoric uncertainty.
- (e)
- Because , we deduce that the conditional average covariance matrix does not coincide with the predictive covariance matrix , which reflects the uncertainty.
4. Conclusions
- For solving the direct problem, we considered a neural network for simulating the radiative transfer model, computed of the epistemic covariance matrix from the statistics of all network errors over the data set, solving the inverse problem by a Bayesian approach, and determined the uncertainty in the retrieval by assuming that the forward model is nearly linear.
- For solving the inverse problem, two neural network methods, relying on different assumptions, were implemented:
- (a)
- The first method uses deterministic and stochastic (Bayes-by-backprop, dropout, and batch normalization) networks to compute the epistemic covariance matrix and under the assumption that the predictive distribution of the network output is the convolution of the predictive distribution for a noise-free input with the input noise distribution, estimates the covariance matrix;
- (b)
- The second method uses dropout and Bayes-by-backprop to learn the heteroscedastic covariance matrix from the data.
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix B
Appendix C
- For the first term, written aswe use the following reparameterization trick. Let be an auxiliary variable representing the stochasticity during the training, such that for some function t. Assuming that , we find:implying:Computing the above integral by a Monte Carlo approach with a single sample , yields:where . In our case and in view of Equations (A10)–(A12), we reparametrize the integrands by setting:where:to obtain:where:for the realizations , , and given by Equations (A20)–(A22). Taking the limit , we find that the realizations and can be approximated as
- In the case of , the second term in Equation (A13) is the KL divergence between a mixture of Gaussians and a single Gaussian, that is:where is as in Equations (A10) and (A11) and with . This term can be evaluated by using the following result: For , let be a probability vector, with a mixture of Gaussians with K components, and . Then, for sufficiently large N, we have the approximation:Consequently, for large numbers of hidden units , , we find:where C is a constant. In the case of , the KL divergence , where (cf. Equation (A12)) and , is a mixture of two single Gaussian and can be analytically computed as
Appendix D
- For , we use the relations:and (yielding ) to obtain:where corresponds to the density of all variables excluding , and , while:
- For , we use the relations:and (yielding ), to obtain:
References
- Tibshirani, R. A Comparison of Some Error Estimates for Neural Network Models. Neural Comput. 1996, 8, 152–163. [Google Scholar] [CrossRef]
- Loquercio, A.; Segu, M.; Scaramuzza, D. A General Framework for Uncertainty Estimation in Deep Learning. IEEE Robot. Autom. Lett. 2020, 5, 3153–3160. [Google Scholar] [CrossRef] [Green Version]
- Oh, S.; Byun, J. Bayesian Uncertainty Estimation for Deep Learning Inversion of Electromagnetic Data. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Chevallier, F.; Chéruy, F.; Scott, N.A.; Chédin, A. A Neural Network Approach for a Fast and Accurate Computation of a Longwave Radiative Budget. J. Appl. Meteorol. 1998, 37, 1385–1397. [Google Scholar] [CrossRef]
- Chevallier, F.; Morcrette, J.J.; Chéruy, F.; Scott, N.A. Use of a neural-network-based long-wave radiative-transfer scheme in the ECMWF atmospheric model. Q. J. R. Meteorol. Soc. 2000, 126, 761–776. [Google Scholar] [CrossRef]
- Cornford, D.; Nabney, I.T.; Ramage, G. Improved neural network scatterometer forward models. J. Geophys. Res. Ocean. 2001, 106, 22331–22338. [Google Scholar] [CrossRef] [Green Version]
- Krasnopolsky, V.M. The Application of Neural Networks in the Earth System Sciences; Springer: Dordrecht, The Netherlands, 2013. [Google Scholar] [CrossRef]
- Efremenko, D.S. Discrete Ordinate Radiative Transfer Model With the Neural Network Based Eigenvalue Solver: Proof of Concept. Light Eng. 2021, 1, 56–62. [Google Scholar] [CrossRef]
- Fan, Y.; Li, W.; Gatebe, C.K.; Jamet, C.; Zibordi, G.; Schroeder, T.; Stamnes, K. Atmospheric correction over coastal waters using multilayer neural networks. Remote Sens. Environ. 2017, 199, 218–240. [Google Scholar] [CrossRef]
- Fan, C.; Fu, G.; Noia, A.D.; Smit, M.; Rietjens, J.H.; Ferrare, R.A.; Burton, S.; Li, Z.; Hasekamp, O.P. Use of A Neural Network-Based Ocean Body Radiative Transfer Model for Aerosol Retrievals from Multi-Angle Polarimetric Measurements. Remote Sens. 2019, 11, 2877. [Google Scholar] [CrossRef] [Green Version]
- Gao, M.; Franz, B.A.; Knobelspiesse, K.; Zhai, P.W.; Martins, V.; Burton, S.; Cairns, B.; Ferrare, R.; Gales, J.; Hasekamp, O.; et al. Efficient multi-angle polarimetric inversion of aerosols and ocean color powered by a deep neural network forward model. Atmos. Meas. Tech. 2021, 14, 4083–4110. [Google Scholar] [CrossRef]
- Shi, C.; Hashimoto, M.; Shiomi, K.; Nakajima, T. Development of an Algorithm to Retrieve Aerosol Optical Properties Over Water Using an Artificial Neural Network Radiative Transfer Scheme: First Result From GOSAT-2/CAI-2. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9861–9872. [Google Scholar] [CrossRef]
- Jiménez, C.; Eriksson, P.; Murtagh, D. Inversion of Odin limb sounding submillimeter observations by a neural network technique. Radio Sci. 2003, 38, 27-1–27-8. [Google Scholar] [CrossRef]
- Holl, G.; Eliasson, S.; Mendrok, J.; Buehler, S.A. SPARE-ICE: Synergistic ice water path from passive operational sensors. J. Geophys. Res. Atmos. 2014, 119, 1504–1523. [Google Scholar] [CrossRef]
- Strandgren, J.; Bugliaro, L.; Sehnke, F.; Schröder, L. Cirrus cloud retrieval with MSG/SEVIRI using artificial neural networks. Atmos. Meas. Tech. 2017, 10, 3547–3573. [Google Scholar] [CrossRef] [Green Version]
- Efremenko, D.S.; Loyola R, D.G.; Hedelt, P.; Spurr, R.J.D. Volcanic SO2 plume height retrieval from UV sensors using a full-physics inverse learning machine algorithm. Int. J. Remote Sens. 2017, 38, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Prigent, C.; Aires, F.; Jimenez, C. A Statistical Retrieval of Cloud Parameters for the Millimeter Wave Ice Cloud Imager on Board MetOp-SG. IEEE Access 2017, 5, 4057–4076. [Google Scholar] [CrossRef]
- Brath, M.; Fox, S.; Eriksson, P.; Harlow, R.C.; Burgdorf, M.; Buehler, S.A. Retrieval of an ice water path over the ocean from ISMAR and MARSS millimeter and submillimeter brightness temperatures. Atmos. Meas. Tech. 2018, 11, 611–632. [Google Scholar] [CrossRef] [Green Version]
- Håkansson, N.; Adok, C.; Thoss, A.; Scheirer, R.; Hörnquist, S. Neural network cloud top pressure and height for MODIS. Atmos. Meas. Tech. 2018, 11, 3177–3196. [Google Scholar] [CrossRef] [Green Version]
- Hedelt, P.; Efremenko, D.S.; Loyola, D.G.; Spurr, R.; Clarisse, L. Sulfur dioxide layer height retrieval from Sentinel-5 Precursor/TROPOMI using FP_ILM. Atmos. Meas. Tech. 2019, 12, 5503–5517. [Google Scholar] [CrossRef] [Green Version]
- Noia, A.D.; Hasekamp, O.P.; van Harten, G.; Rietjens, J.H.H.; Smit, J.M.; Snik, F.; Henzing, J.S.; de Boer, J.; Keller, C.U.; Volten, H. Use of neural networks in ground-based aerosol retrievals from multi-angle spectropolarimetric observations. Atmos. Meas. Tech. 2015, 8, 281–299. [Google Scholar] [CrossRef] [Green Version]
- Noia, A.D.; Hasekamp, O.P.; Wu, L.; van Diedenhoven, B.; Cairns, B.; Yorks, J.E. Combined neural network/Phillips–Tikhonov approach to aerosol retrievals over land from the NASA Research Scanning Polarimeter. Atmos. Meas. Tech. 2017, 10, 4235–4252. [Google Scholar] [CrossRef] [Green Version]
- Aires, F. Neural network uncertainty assessment using Bayesian statistics with application to remote sensing: 1. Network weights. J. Geophys. Res. 2004, 109. [Google Scholar] [CrossRef] [Green Version]
- Aires, F. Neural network uncertainty assessment using Bayesian statistics with application to remote sensing: 2. Output errors. J. Geophys. Res. 2004, 109. [Google Scholar] [CrossRef]
- Pfreundschuh, S.; Eriksson, P.; Duncan, D.; Rydberg, B.; Håkansson, N.; Thoss, A. A neural network approach to estimating a posteriori distributions of Bayesian retrieval problems. Atmos. Meas. Tech. 2018, 11, 4627–4643. [Google Scholar] [CrossRef] [Green Version]
- Arnold, V. On the representation of functions of several variables as a superposition of functions of a smaller number of variables. Math. Teach. Appl. Hist. Matem. Prosv. Ser. 2 1958, 3, 41–61. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Nix, D.; Weigend, A. Estimating the mean and variance of the target probability distribution. In Proceedings of the 1994 IEEE International Conference on Neural Networks (ICNN–94), Orlando, FL, USA, 28 June–2 July 1994. [Google Scholar] [CrossRef]
- Wright, W.; Ramage, G.; Cornford, D.; Nabney, I. Neural Network Modelling with Input Uncertainty: Theory and Application. J. VLSI Signal Process. 2000, 26, 169–188. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Denker, J.; Solla, S. Optimal Brain Damage. In Advances in Neural Information Processing Systems; Touretzky, D., Ed.; Morgan-Kaufmann: Burlington, MA, USA, 1990; Volume 2, pp. 598–605. [Google Scholar]
- MacKay, D.J.C. A Practical Bayesian Framework for Backpropagation Networks. Neural Comput. 1992, 4, 448–472. [Google Scholar] [CrossRef]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, ICML’15, Lille, France, 6–11 July 2015; pp. 1613–1622. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. arXiv 2016, arXiv:1506.02142. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Teye, M.; Azizpour, H.; Smith, K. Bayesian Uncertainty Estimation for Batch Normalized Deep Networks. arXiv 2018, arXiv:1802.06455. [Google Scholar]
- Efremenko, D.S.; Molina García, V.; Gimeno García, S.; Doicu, A. A review of the matrix-exponential formalism in radiative transfer. J. Quant. Spectrosc. Radiat. Transf. 2017, 196, 17–45. [Google Scholar] [CrossRef] [Green Version]
- Efremenko, D.; Kokhanovsky, A. Foundations of Atmospheric Remote Sensing; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Efremenko, D.; Doicu, A.; Loyola, D.; Trautmann, T. Acceleration techniques for the discrete ordinate method. J. Quant. Spectrosc. Radiat. Transf. 2013, 114, 73–81. [Google Scholar] [CrossRef]
- Goody, R.; West, R.; Chen, L.; Crisp, D. The correlated-k method for radiation calculations in nonhomogeneous atmospheres. J. Quant. Spectrosc. Radiat. Transf. 1989, 42, 539–550. [Google Scholar] [CrossRef]
- Efremenko, D.; Doicu, A.; Loyola, D.; Trautmann, T. Optical property dimensionality reduction techniques for accelerated radiative transfer performance: Application to remote sensing total ozone retrievals. J. Quant. Spectrosc. Radiat. Transf. 2014, 133, 128–135. [Google Scholar] [CrossRef]
- Molina García, V.; Sasi, S.; Efremenko, D.S.; Doicu, A.; Loyola, D. Radiative transfer models for retrieval of cloud parameters from EPIC/DSCOVR measurements. J. Quant. Spectrosc. Radiat. Transf. 2018, 213, 228–240. [Google Scholar] [CrossRef] [Green Version]
- del Águila, A.; Efremenko, D.S.; Trautmann, T. A Review of Dimensionality Reduction Techniques for Processing Hyper-Spectral Optical Signal. Light Eng. 2019, 27, 85–98. [Google Scholar] [CrossRef] [Green Version]
- Schreier, F.; Gimeno García, S.; Hedelt, P.; Hess, M.; Mendrok, J.; Vasquez, M.; Xu, J. GARLIC—A general purpose atmospheric radiative transfer line-by-line infrared-microwave code: Implementation and evaluation. J. Quant. Spectrosc. Radiat. Transf. 2014, 137, 29–50. [Google Scholar] [CrossRef] [Green Version]
- Schreier, F. Optimized implementations of rational approximations for the Voigt and complex error function. J. Quant. Spectrosc. Radiat. Transf. 2011, 112, 1010–1025. [Google Scholar] [CrossRef]
- Gordon, I.; Rothman, L.; Hill, C.; Kochanov, R.; Tan, Y.; Bernath, P.; Birk, M.; Boudon, V.; Campargue, A.; Chance, K.; et al. The HITRAN2016 molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transf. 2017, 203, 3–69. [Google Scholar] [CrossRef]
- Bodhaine, B.A.; Wood, N.B.; Dutton, E.G.; Slusser, J.R. On Rayleigh Optical Depth Calculations. J. Atmos. Ocean. Technol. 1999, 16, 1854–1861. [Google Scholar] [CrossRef]
- Anderson, G.; Clough, S.; Kneizys, F.; Chetwynd, J.; Shettle, E. AFGL Atmospheric Constituent Profiles (0-120 km). AFGL-TR-86-0110; Air Force Geophysics Laboratory: Hanscom Air Force Base, MA, USA, 1986. [Google Scholar]
- Loyola R, D.G.; Pedergnana, M.; García, S.G. Smart sampling and incremental function learning for very large high dimensional data. Neural Netw. 2016, 78, 75–87. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Rodgers, C. Inverse Methods for Atmospheric Sounding: Theory and Practice; Wolrd Scientific Publishing: Singapore, 2000. [Google Scholar]
- Doicu, A.; Trautmann, T.; Schreier, F. Numerical Regularization for Atmospheric Inverse Problems; Springer: Berlin, Germany, 2010. [Google Scholar]
- Tresp, V.; Ahmad, S.; Neuneier, R. Training Neural Networks with Deficient Data. In Advances in Neural Information Processing Systems; Cowan, J., Tesauro, G., Alspector, J., Eds.; Morgan-Kaufmann: Burlington, MA, USA, 1994; Volume 6, pp. 128–135. [Google Scholar]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Gast, J.; Roth, S. Lightweight Probabilistic Deep Networks. arXiv 2018, arXiv:1805.11327. [Google Scholar]
- Jaulin, L.; Kieffer, M.; Didrit, O.; Walter, É. Applied Interval Analysis; Springer: London, UK, 2001. [Google Scholar] [CrossRef]
- Kearfott, R.B.; Dawande, M.; Du, K.; Hu, C. Algorithm 737: INTLIB—a portable Fortran 77 interval standard-function library. ACM Trans. Math. Softw. 1994, 20, 447–459. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | x | Error | Std. Deviation |
|---|---|---|---|
| H | |||
| 1a | |||
| H | |||
| 1b | |||
| H | |||
| 1c | |||
| H | |||
| 1d | |||
| H | |||
| 2a | |||
| H | |||
| 2b | |||
| H | |||
| 3a | |||
| H | |||
| 3b | |||
| H |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doicu, A.; Doicu, A.; Efremenko, D.S.; Loyola, D.; Trautmann, T. An Overview of Neural Network Methods for Predicting Uncertainty in Atmospheric Remote Sensing. Remote Sens. 2021, 13, 5061. https://doi.org/10.3390/rs13245061
Doicu A, Doicu A, Efremenko DS, Loyola D, Trautmann T. An Overview of Neural Network Methods for Predicting Uncertainty in Atmospheric Remote Sensing. Remote Sensing. 2021; 13(24):5061. https://doi.org/10.3390/rs13245061
Chicago/Turabian StyleDoicu, Adrian, Alexandru Doicu, Dmitry S. Efremenko, Diego Loyola, and Thomas Trautmann. 2021. "An Overview of Neural Network Methods for Predicting Uncertainty in Atmospheric Remote Sensing" Remote Sensing 13, no. 24: 5061. https://doi.org/10.3390/rs13245061
APA StyleDoicu, A., Doicu, A., Efremenko, D. S., Loyola, D., & Trautmann, T. (2021). An Overview of Neural Network Methods for Predicting Uncertainty in Atmospheric Remote Sensing. Remote Sensing, 13(24), 5061. https://doi.org/10.3390/rs13245061