1. Introduction
The extraction of buildings from remotely sensed images is essential for topographic mapping and urban planning. Although automatic building extraction methods have been investigated for decades, they are still difficult to achieve sufficient performance to meet the requirements for fully automated use. Conventional methods mainly exploit empirically designed features to recognize buildings, such as color, texture, and shadow, etc. Due to the limitation of hand-crafted features, these methods usually produce frustrating results in complex scenes. In recent years, with the development of deep learning techniques, building segmentation performance has been lifted a lot by various deep convolutional neural networks (DCNNs), such as U-Net [
1], SegNet [
2], DeepLabV3+ [
3]. These networks take RGB images as input and directly output the probability map of buildings in the image. By learning from massive amounts of training samples, they can achieve performance far beyond conventional methods. However, these CNN-based automatic building extraction algorithms are suffering from poor generalization ability, which means a well-trained network can only make good predictions on images with a similar distribution of the training data. Furthermore, the acquirement of pixel-wised annotated data itself is time-consuming and expensive, and the accuracy of the segmentation results is also far from the requirement of actual use.
Under these circumstances, the study of interactive building extraction is of great value and importance. Fully-automatic extraction methods are characterized by the prior constraints, such as shape and appearance of the buildings, and the output results are automatically generated and presented in front of the users before further processing. The main difference between fully-automatic and semi-automatic building extraction methods is that the latter can accept human supervision as additional input to ensure the quality of the output results. A good interactive segmentation method is always aimed at reducing the user effort. Actually, there was a significant amount of research before the advent of deep learning techniques. An earlier well-known method is intelligent scissors [
4], which focuses on the boundary property for object extraction. Afterward, a graph model-based interactive image segmentation algorithm was studied a significant amount. Boykov and Jolly [
5] utilize scribbles to estimate the probability of the foreground/background of the target object. The task is formulated as a graph partition problem and solved by a min-cut/max-flow algorithm [
6]. Veksler [
7] integrates a star-convexity shape into a graph-cut segmentation, and Gulshan et al. [
8] further improve the results with multiple stars and geodesics distances. Rother et al. [
9] take the bounding box as input and utilize a Gaussian mixture model for foreground and background prediction. Yu et al. [
10] use a Markov Random Field (MRF) to segment objects with loosely bounded boxes. In addition, Grady [
11] uses the label of the seed firstly reached by a random walker to mark unlabeled pixels. Limited by the capacity of these hand-crafted features, the amount of user inputs are still required in complex scenarios, such as low contrast and poor illumination.
Recently, deep learning techniques have also been applied to interactive object extraction and achieved great success in the field of computer vision. Xu et al. [
12] first propose a CNN-based model for interactive segmentation and devise a click simulation strategy for the training of the network. They transform the user-provided clicks into Euclidean distance maps and concatenate them with RGB images as the input to the network. This work is then extended and improved by many other works in different aspects. For example, Mahadevan et al. [
13] introduce an iterative way to improve the heuristic sampling strategy during the training stage. Li et al. [
14] select the optimal result among multiple diverse solutions to reduce the user efforts. Majumder and Yao [
15] combine superpixels and class-independent object proposals with user-provided clicks to generate more informative guidance maps for the performance promotion of interactive segmentation systems. Jang and Kim [
16] propose a backpropagating refinement scheme (BRS) to guarantee the correct prediction in user-annotated positions. Sofiiuk et al. [
17] further propose a feature backpropagating refinement scheme (f-BRS) to alleviate the computational burden of the forward and backward pass. Lin et al. [
18] consider that the first click contains location guidance of the main body of the target object and put forward a first click attention module to make better use of the first click.
Generally speaking, user inputs are typically given as clicks [
12,
13,
14,
15,
16,
17,
18,
19], scribbles [
5] and bounding boxes [
9,
10]. Compared with the other two modes of interactions, the click-based way is relatively simple and can reduce the burden of the annotators. In this work, we focus on the study of click-based interactive extraction of buildings. In this setting, users sequentially provide positive points on the foreground or negative points on the background to interact with the model until the segmented results are satisfied. To feed the interaction information to the CNN-based interactive segmentation model, an important issue is how to encode the user-provided clicks. Most of the existing methods follow [
12] to simulate positive and negative clicks and transform them into a two-channel guidance map by Euclidean distance [
12,
14,
16,
17,
19] or gaussian masks [
18], and we utilize a satellite image in CrowdAI [
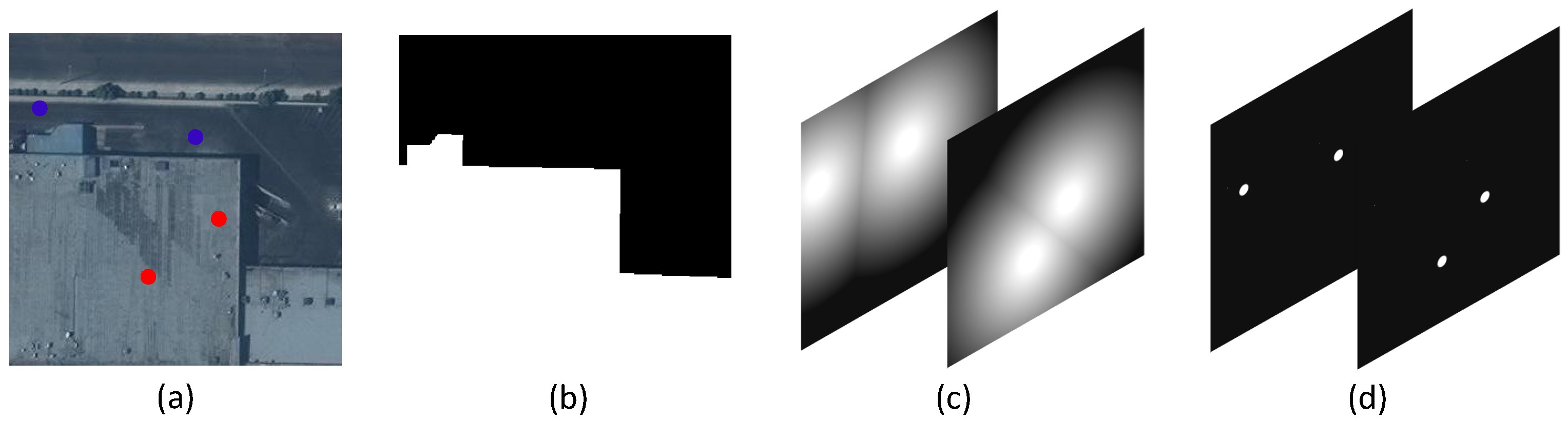
20] dataset to demonstrate this in
Figure 1. These two encoding methods are simple and straightforward representations of user-provided click points, which are convenient for the simulation of the training samples and the batch training of the network. In addition, they are also flexible in dealing with objects of multi-parts or weird shapes in natural scenes. However, such two-channel representations lack enough information to make an interactive segmentation network maintain good stability. In
Figure 2, we present an image segmentation example of a baseline network in a natural scene that only utilizes guidance maps transformed from the user-provided clicks by Euclidean distance. We can see that the building is almost perfectly segmented after the first click. However, after the second click is added for further mask refinement, the segmentation result is severely degraded. It is because the predictions are independent at each step both in the training and inference stages. The guidance map treats all clicks independently, the network basically predicts the mask of the target object by the distribution of the positive and negative click points. Furthermore, the Gaussian masks of clicks or Euclidean distance maps are a kind of “weak” guidance, which is not conducive to the stability of mask refinement.
In our opinion, an interactive segmentation process is a coarse-to-fine process, which is carried out with two objectives, the fast estimation of the scale of the target object and the continuous refinement of the predicted masks. These two objectives conflict in the extent of the change to the previous segmentation mask. The former focuses on flexibility, and the latter emphasizes stability. A robust interactive segmentation system should progressively improve the segmentation mask with as little oscillation as possible because a false prediction will require additional clicks to revise. We argue that existing guidance maps are flexible representations for dealing with complex objects in natural scenes. However, compared with objects (multi-parts, elongated) in natural scenarios, buildings in overhead remote sensing images tend to have relatively regular shapes. For these “easy” buildings, the stability of the interactive segmentation process is critical to the improvement of performance. Motivated by the above circumstances, in this work, we focus on developing a robust interactive building extraction method based on CNN. To promote the stability of the interactive segmentation network, we firstly combine the previous segmentation map, which is considered as a kind of “strong” guidance, with existing distance-based guidance maps. In addition, we observe that annotators often tend to click around the center of the largest misclassified region. Thus, in most cases, the distance of the newly added click to the boundary of the previous segmentation mask can provide instructive progress information of the interactive segmentation process. This distance can be easily obtained during the inference stage, and we call this distance the indication distance. We make use of this distance and transform it into another guidance map to increase the stability of the interactive segmentation model. Moreover, we propose an adaptive zoom-in strategy and an iterative training strategy for further performance promotion of the algorithm. Comprehensive experiments show that our method is effective in both natural scenes and remote sensing images. Especially, compared with the latest state-of-the-art methods, FCA [
18] and f-BRS [
17], our approach basically requires 1–2 fewer clicks to achieve the same segmentation results on three building datasets of remote sensing images, which significantly reduces the workload of users. Furthermore, we propose an additional metric for the further evaluation of the robustness of the proposed interactive segmentation network, and the experimental results demonstrate that our approach yields better stability over other methods.
Our contributions can be summarized as follows:
We analyze the benefits of a segmentation mask to improve the stability of network prediction, and we combine it with existing distance-based guidance maps to promote the performance of the interactive segmentation system.
We also propose an adaptive zoom-in scheme during the inference phase, and we propose an iterative training strategy for the training of an interactive segmentation network.
We achieve state-of-the-art performance on five widely used natural image datasets and three building datasets. In particular, our approach significantly reduces the user interactions in the interactive extraction of buildings. Comprehensive experiments demonstrate the good robustness of our algorithm.
The remainder of this article is arranged as follows:
Section 2 describes details of the proposed method; the corresponding experimental assessment and discussion of the obtained results are shown in
Section 3 and
Section 4, respectively;
Section 5 presents our concluding remarks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}