3.1. Training Data
To circumvent the lack of labeled data suitable for training the detector, we generate synthetic training data with backgrounds from real-world videos captured using UAV-mounted camera to which we add artificially generated blob-like objects. For the purpose of the experiments in this paper, the movement of the artificially generated objects was derived, under the supervision of an expert, from manually selected and traced honeybees in UAV videos, with small random variations. The resulting objects, named “artificial honeybees” were created in a way to mimic the appearance and flight patterns of honeybees in search for food near the known location of food sources. It should be noted that the described method for generating synthetic training data can be easily adapted to different type of target objects and different real-world backgrounds.
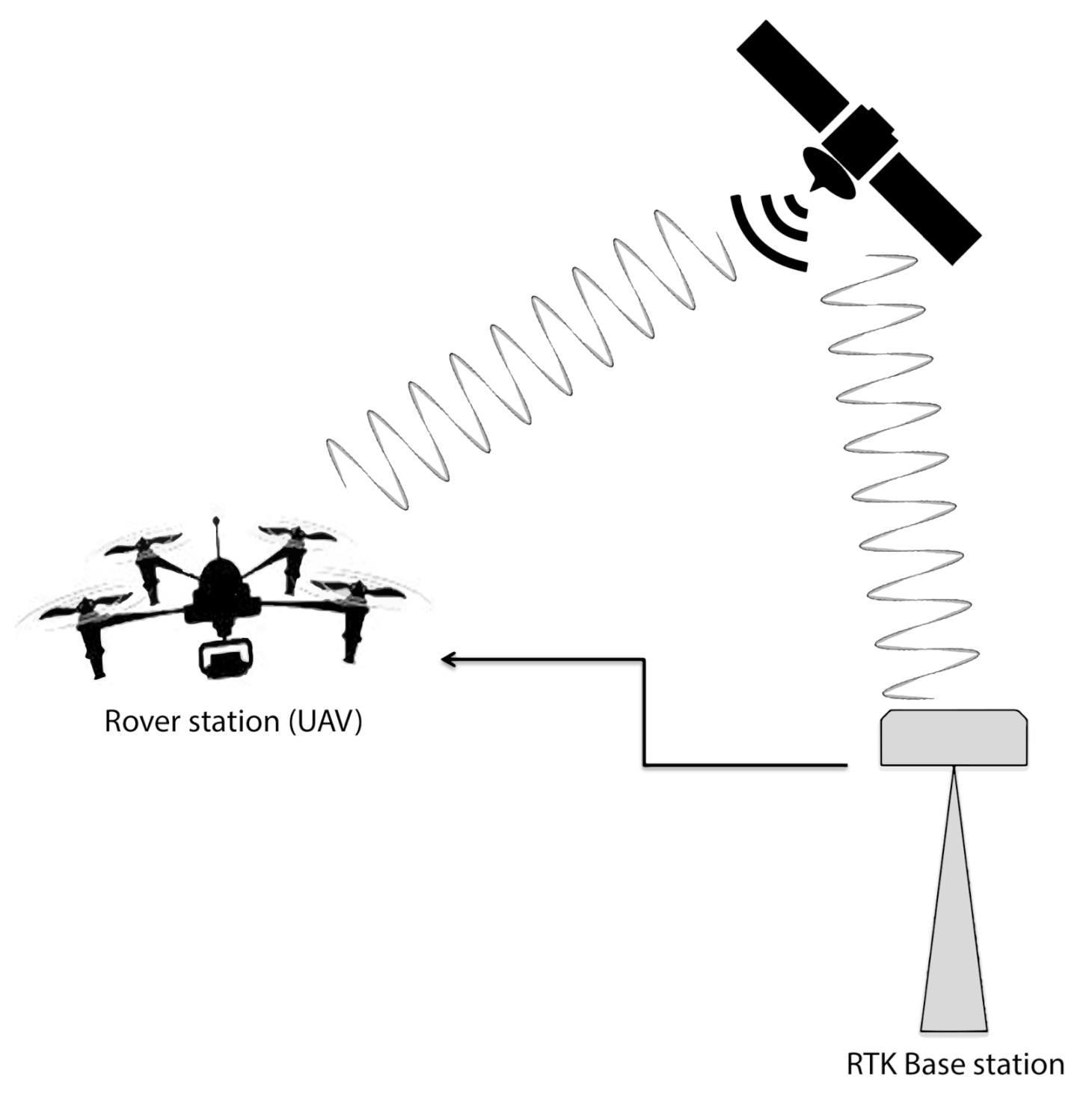
To make the method invariant to background appearance, we captured 3 videos at locations in Croatia. For capturing the videos used as backgrounds, as well as for testing the proposed method, we flew UAVs at altitudes between 7 and 15 meters. We used two very different UAVs, one quadcopter, DJI Inspire 1, and one large, proprietary-built, hexacopter equipped with high-accuracy positioning system: Real-Time Kinematic (RTK) GPS. RTK system,
Figure 2, allows a very precise hovering and provides a better output after automatic video-stabilization process. A limitation of this system is its requirement for a base station in the relative vicinity of the rover station, in our case UAV, but for covering a small area this limitation did not cause us problems. DJI Inspire 1 was equipped with Zenmuse 5R digital camera, allowing recording of 4K uncompressed videos with the possibility of using interchangeable lenses. For this purpose we used a 25 mm (equivalent to 50 mm in 35 mm systems) lens. The hexacopter was equipped with a modified GoPro Hero 6 camera with a 47 mm equivalent lens. These two setups provide similar recording performance with the usage of different aerial vehicles to eliminate any equipment-bias and provide different conditions for reproducibility of the experiment. Different lighting conditions were eliminated using automatic camera settings and did not impose problems in automatic processing of the recorded videos. Because of the nature of experiments, we needed to have rather good atmospheric conditions with dry weather and almost no wind, because honeybees avoid foraging in unfavorable weather conditions. All recorded videos have 4K resolution with frame rate of 25 fps.
The choice of the parameters for recording real-world videos, were chosen in such a way as to strike a balance between the ability of human observers to detect flying objects in the recorded sequences and not interfering with flying honeybees. Since honeybees are small targets, it is desirable to fly at lower altitudes to obtain as much information about their appearance as possible. However, flying at low altitudes results in a considerable amount of wind produced by the rotors of UAVs, which could interfere with flying honeybees, as well as create moving artifacts from, for example, grass or other vegetation. Furthermore, flying at low altitudes results in covering only a small part of the surface area in a frame, thereby reducing the ability of both human observers and the system to detect a flying honeybee at several locations in the frame and use its motion as a cue for detection.
From the available recordings we selected only parts without visible honeybees or other insects in order to obtain representative examples of backgrounds. However, since it is very hard to detect small flying objects in videos, it is possible that some residual flying insects exist in several frames of the selected videos. Nevertheless, we do not expect that a small number of residual insects will negatively impact the performance of the detector, since CNNs can tolerate a certain amount of labeling noise [
46].
In order to remove global camera motion, i.e., to stabilize the video sequence, we fit the affine transform between each frame in the sequence and the first frame, and then warp all frames into a common reference frame. For estimation of the affine transform between two frames, we first detect keypoints in both frames and compute their descriptors using ORB detector and descriptor [
47]. Then, we find matching pairs of keypoints by comparing the descriptors using Hamming distance. Finally, the matches are used for robust transform estimation using RANSAC algorithm.
We crop the frames of the stabilized videos into blocks of
pixels with 200 pixels overlap between successive blocks, and we skip 200 pixels from each side to eliminate border effects caused by stabilization. After this procedure we are left with 96 background video sequences with frames of
pixels in size. Each background sequence is 3 s long. Some examples of frames from the background sequences are shown in
Figure 3.
In the next step we add artificial honeybees to the obtained background sequences. Examining the appearance and behavior of real-world honeybees in videos captured using the same setup as described for the background sequences, we decided to represent artificial honeybees as elliptical blobs modelled using 2D Gaussian kernels with standard deviations randomly chosen from the intervals [2, 4.5] and [1, 3.5] for
x and
y axes, respectively. The number, sizes, initial locations, initial flight directions, and initial velocities of the artificial honeybees are also chosen randomly by sampling from uniform distributions with minimum and maximum values given in
Table 1. The texture of artificial honeybees is modelled using Gaussian noise. We create several datasets with varying means of Gaussian noise (texture means) to assess the impact of this hyperparameter on overall detection accuracy. Specific values are given in
Section 5 and discussed in the context of the obtained detection results. We use the same value of 0.07 for standard deviation of Gaussian noise in all datasets. In each frame new velocity
and flight direction
of each honeybee from the previous frame are calculated as
where
and
are sampled from normal distributions with zero mean and standard deviations 2 and 30, respectively, and
and
are honeybee velocity and direction in the previous frame. New positions of honeybees are then calculated using projections of their velocities onto
x and
y axes. If the new position of a honeybee is outside of the visible part of the scene we do not add it to the frame. To simulate honeybees flying out of and returning to the visible part of the scene we keep track of the positions of those honeybees but do not add them to the frame. When adding artificial honeybees to a frame we use their pixel values as alpha channel for blending between the background and black pixels. Therefore, artificial honeybees with lower values of the texture mean will appear lighter, i.e., will have low contrast ratio compared to the background, while artificial honeybees with higher values of texture mean will have high contrast ratio compared to the background.
Simultaneously, with generating frames for the training sequence, we generate the ground truth frames that will be used as training targets. Ground truth frames are grayscale frames with black background and artificial honeybees added in the same locations as in the training frames. In this case, we add artificial honeybees by setting the pixel values of the ground truth frame in the neighborhood of the honeybee location to the pixel values of an artificial honeybee. In total, 1000 sequences with frames of pixels containing artificial honeybees are created using the described procedure. Of those, we use 500 sequences for training, 250 sequences for validation, and we retain 250 sequences for testing.
We train the network by feeding it with sequences consisting of 5 consecutive frames of pixels in size cropped randomly from the synthetic training sequences. For each of these sequences the network is trained to predict the ground truth frame corresponding to the middle frame of the sequence. Since the number of honeybees in a single sequence is relatively small, a majority of cropped frames will contain a small number of honeybees or no honeybees at all. Therefore, including the cropped sequences into the training set with uniform probability would result in pronouncedly imbalanced numbers of honeybees present in each sequence. Bearing in mind difficulties of training the network with an imbalanced training set, we decided to include the cropped sequences into the training set with probabilities proportional to the number of honeybees present in the cropped part of the frame. In this way, sequences with a large number of honeybees, although sampled less frequently, will be more often included into the training set. In contrast, more frequently sampled sequences with little or no honeybees will be less frequently included into the training set. By sampling from the cropped sequences in this fashion, we obtain a training set with 53,760, a validation set with 12,800, and a test set with 12,800 samples.
3.2. Test Data
Besides testing on synthetic videos, we also evaluated the proposed method on real-world videos captured using the same setup as described previously for capturing the background sequences. We placed six hives near the examined area so the expected number of honeybees was significantly larger than the number of other flying insects of similar dimensions, the grass was cut and there were no flowers attractive to other pollinators. In addition, during the recording we monitored the area and did not notice significant presence of other flying insects and, in the labeling phase, we used knowledge about honeybee flying patterns. Therefore, we can assume that the flying objects in the test sequences are honeybees.
To quantitatively assess the performance of the proposed method on real-world videos, we developed a tool for manual labeling of small moving objects in video sequences. The developed tool enables users to move forward and backward through the video frame by frame, and mark locations of target objects in each frame. Since objects of interest are very small in comparison to the frame size, and it is of interest only to detect whether an object is present at a particular location, its spatial extent is disregarded. Therefore, bounding boxes or outlines of target objects are not recorded and only their locations in each frame are saved and used as ground truth in performance assessment.
For testing, we extracted three sequences with durations of around 3 seconds from the available recordings, performed their stabilization, and cropped a part of the frame of pixels. The cropped regions were selected on basis of honeybee appearances, i.e., we cropped those regions where it was possible for human observers to spot honeybees. More specifically, during manual labeling of honeybees in these sequences, we noted that it is hard for human observers to equally focus on all parts of a large frame, especially with small target objects. This led us to choose the size of the cropped region in such a way as to strike a balance between the desire to use as large region as possible in order to obtain more information about the behavior of honeybees, and the human ability to analyze large frames. We manually labeled all honeybees in these sequences and used the obtained annotations to evaluate the performance of the trained detectors. To conclude, the labeled test sequences contain frames with one to 4 honeybees, as well as frames without honeybees.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}