
Building Damage Detection Using U-Net with Attention Mechanism from Pre- and Post-Disaster Remote Sensing Datasets

 ,
, 
Abstract
:
1. Introduction
- Explore the performance of multi-artificial neural networks on detecting different damage levels of buildings using both present and post satellite data.
- Compare the fusion results of different networks and the result of a single network.
- Evaluate the transferability and robustness of the total model.
2. Materials and Methods
2.1. Data
2.1.1. xBD Dataset
2.1.2. Instance Data
2.2. Methods
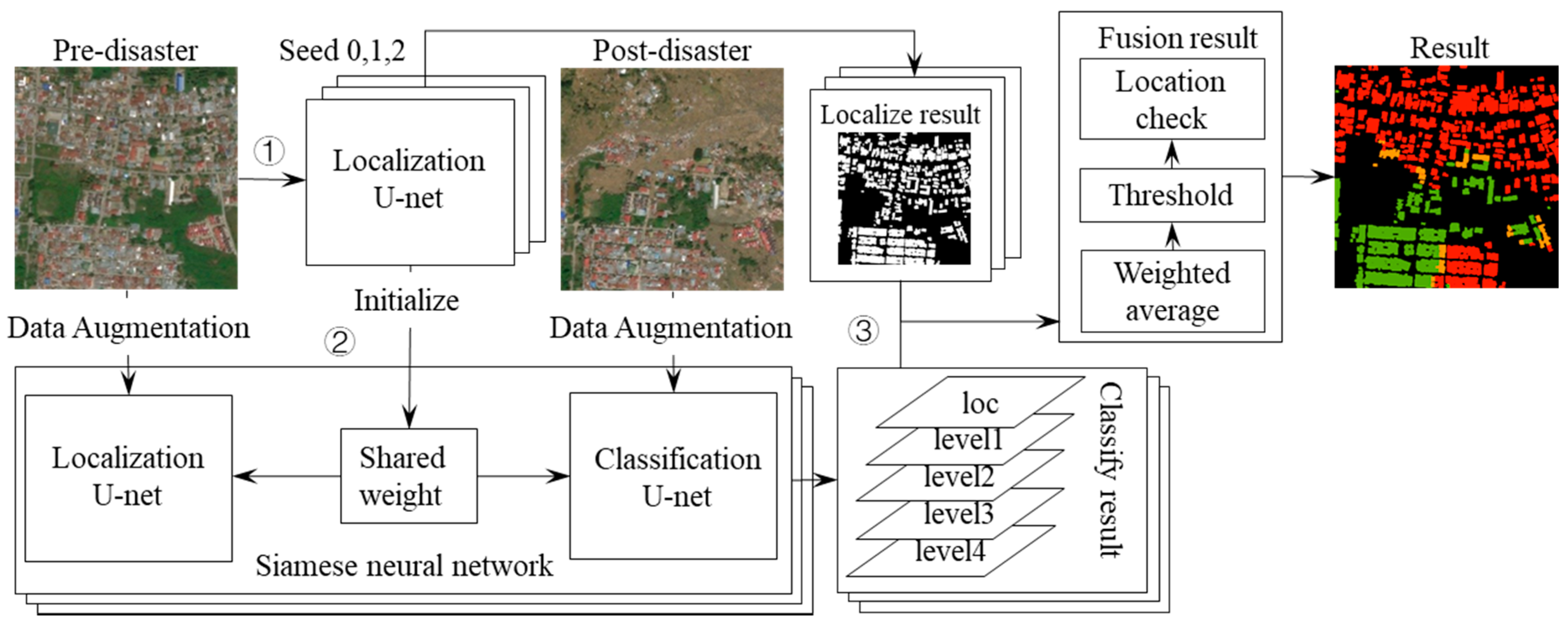
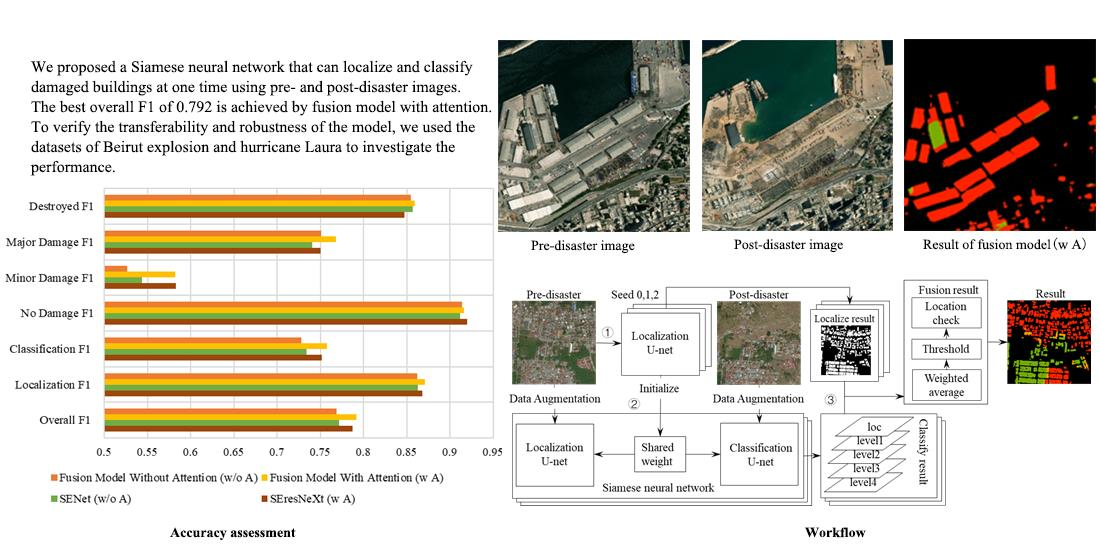
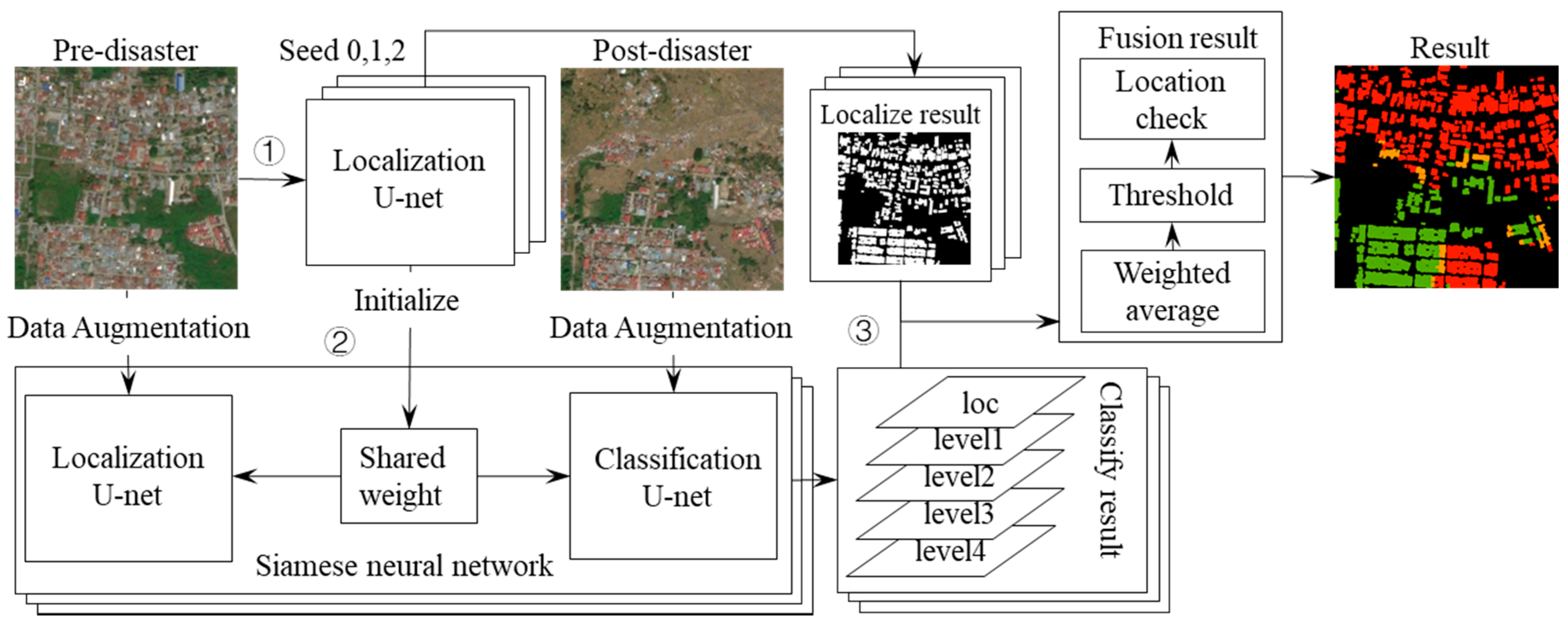
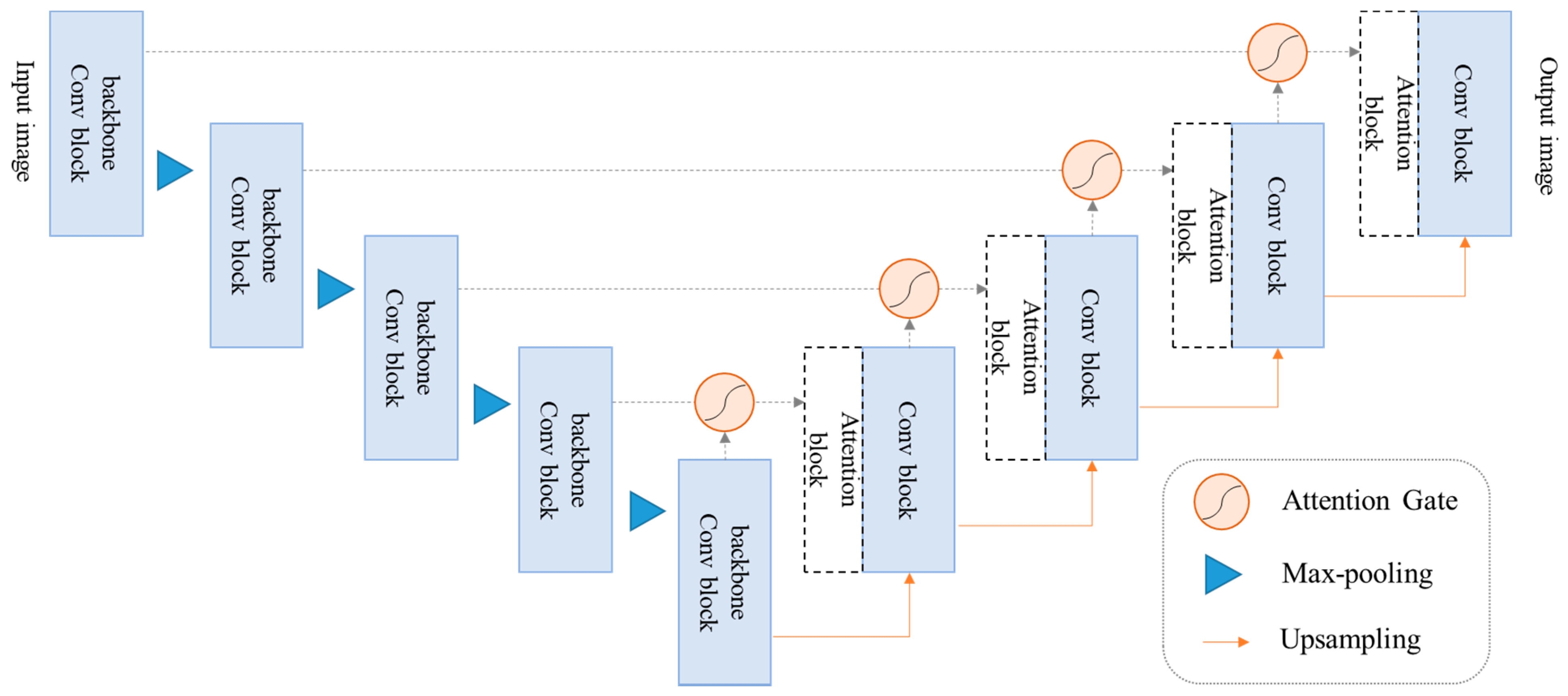
2.2.1. Proposed Framework
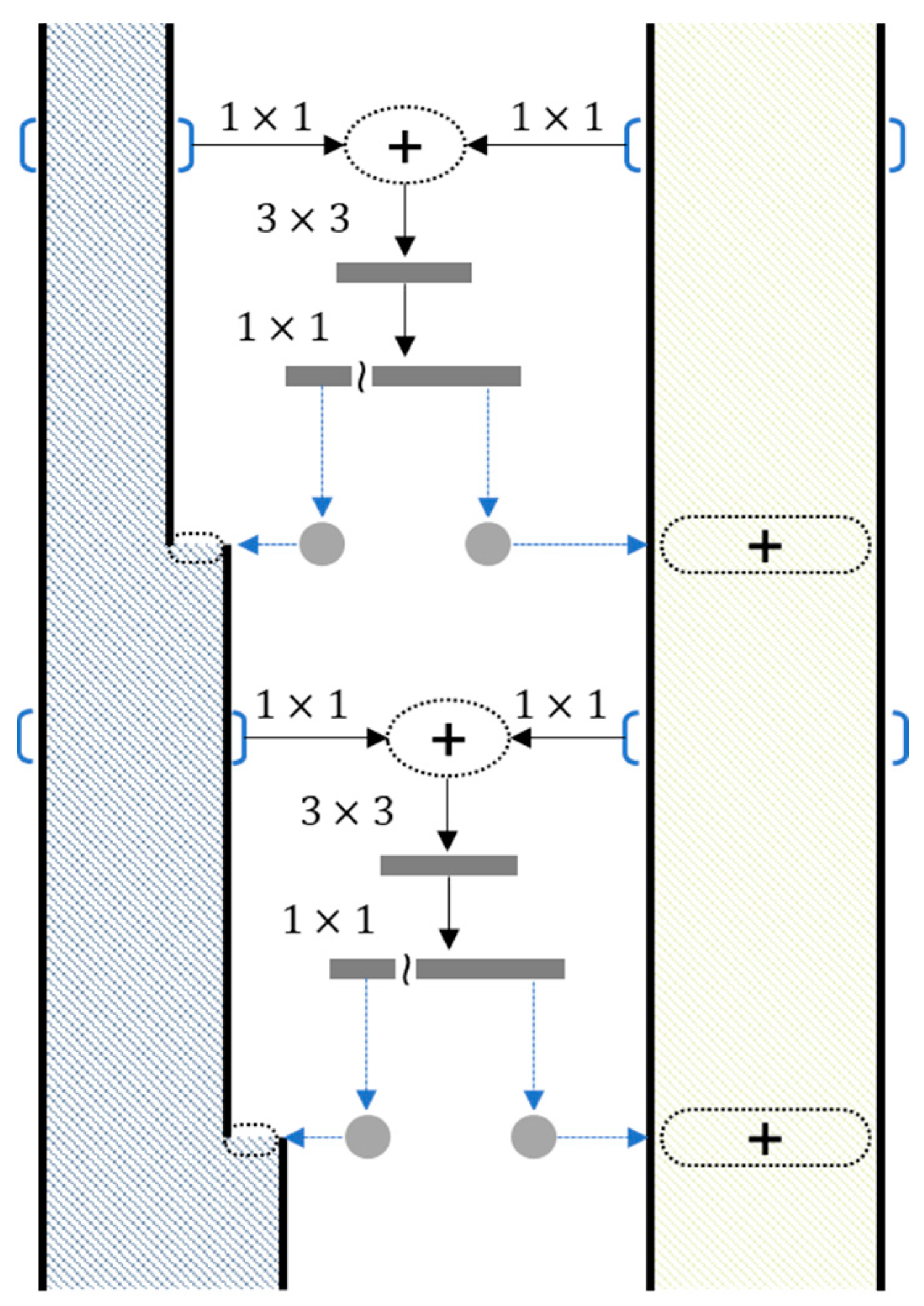
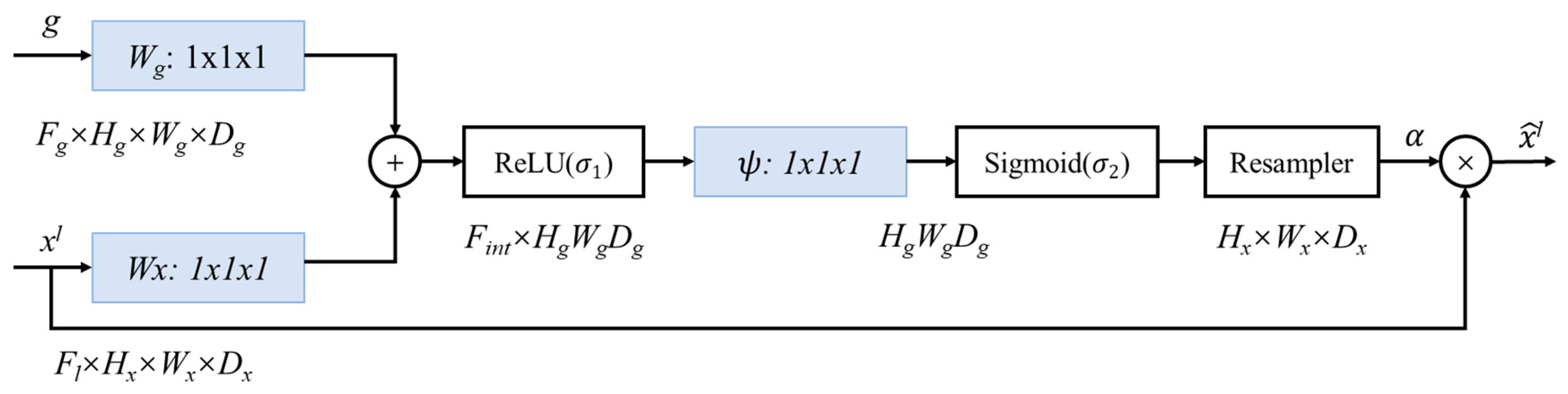
2.2.2. Attention U-Net
2.2.3. Data Augmentation
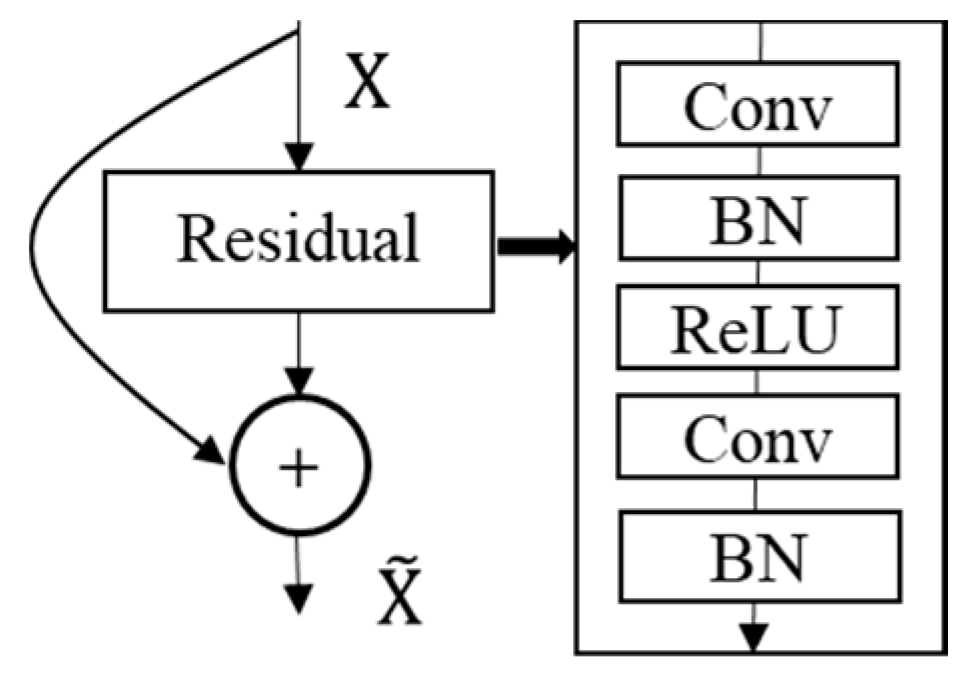
2.2.4. Backbones
- ResNet-34 backbone
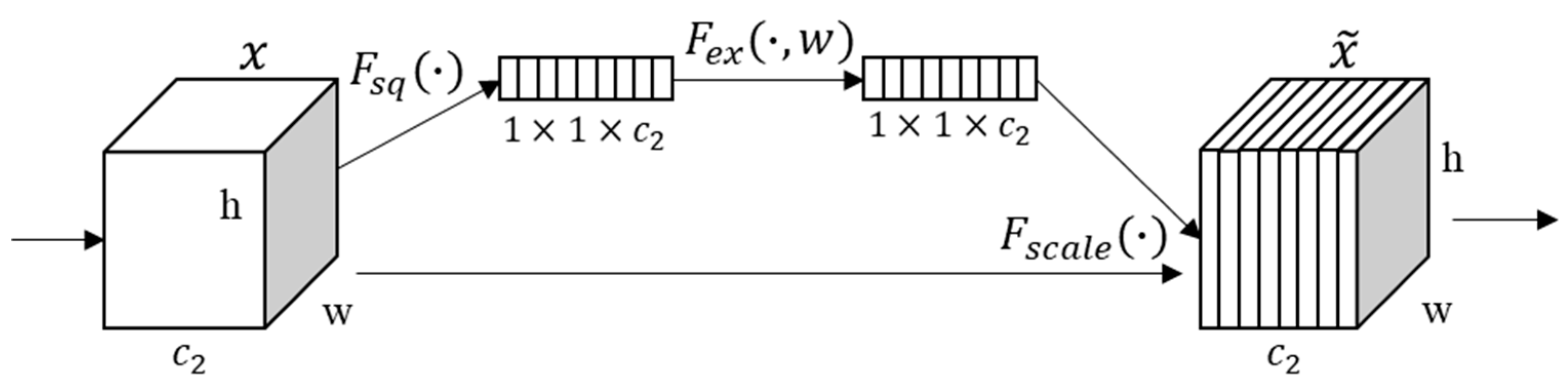
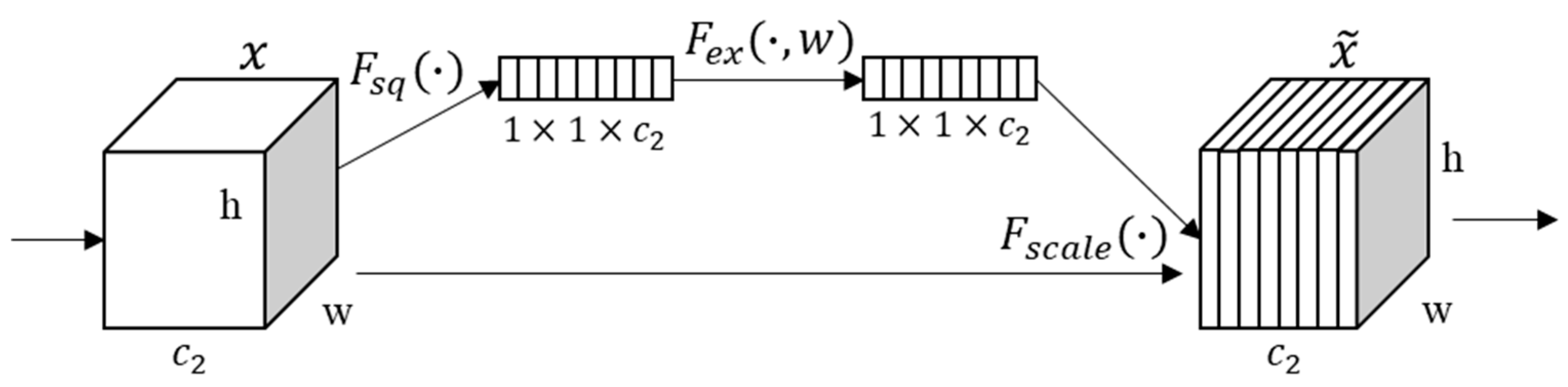
- Squeeze-and-Excitation Networks (SENet) backbone
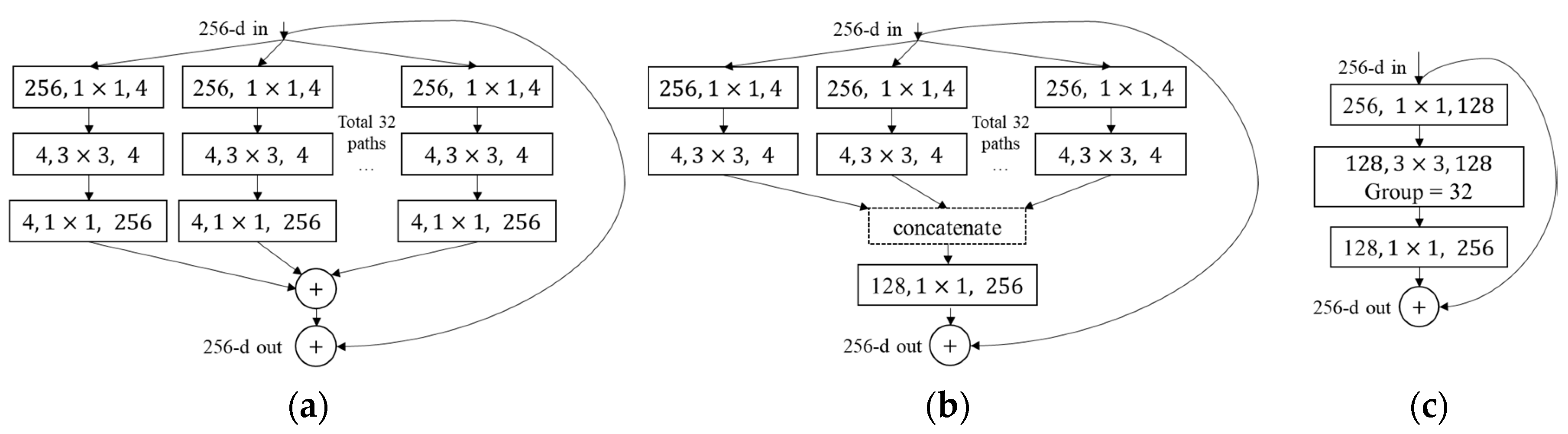
- SEResNeXt backbone
- Dual Path Net (DPN) backbone
2.2.5. Fusion
2.3. Metric
2.4. Training Implementation
3. Results
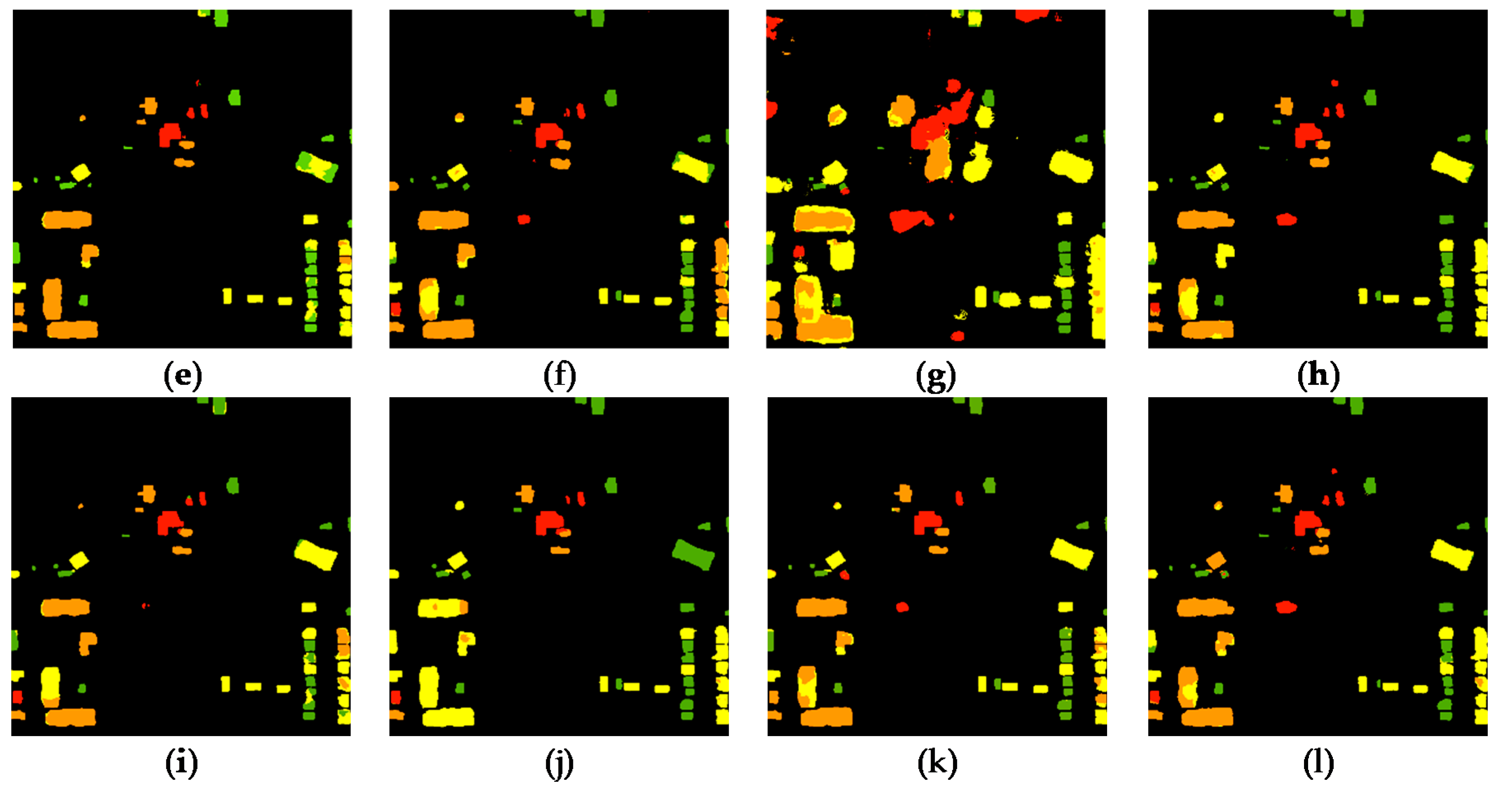
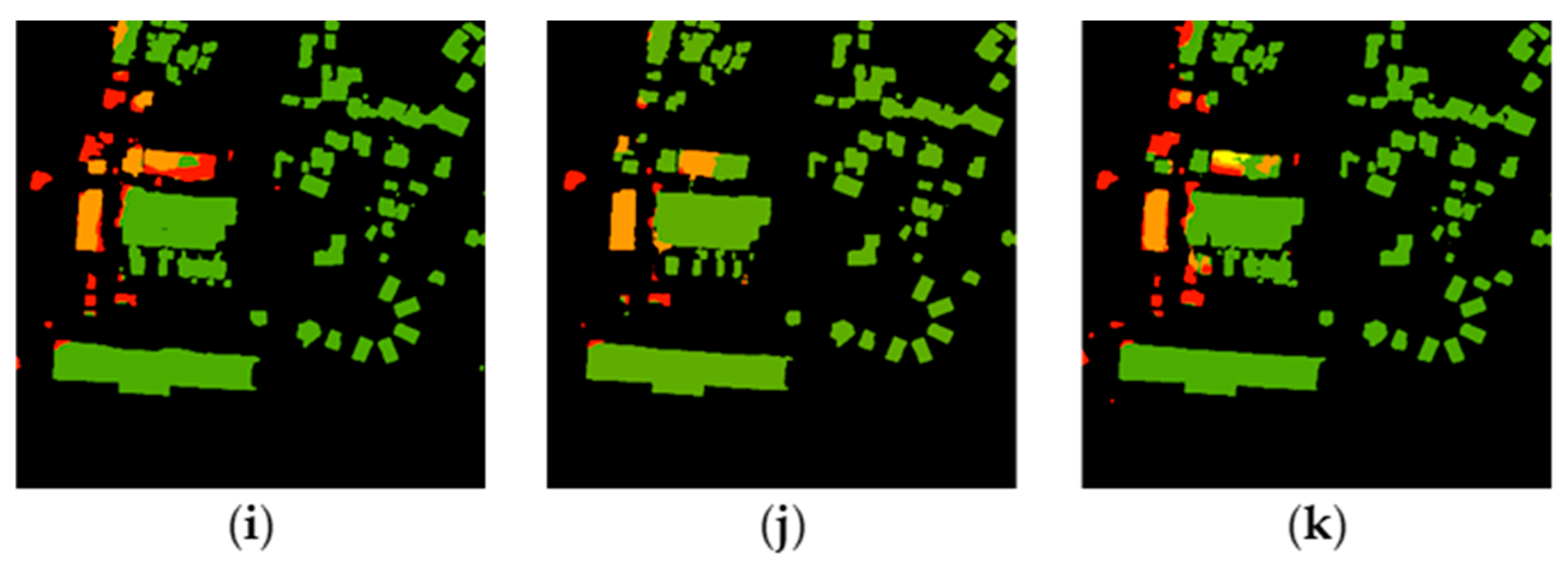
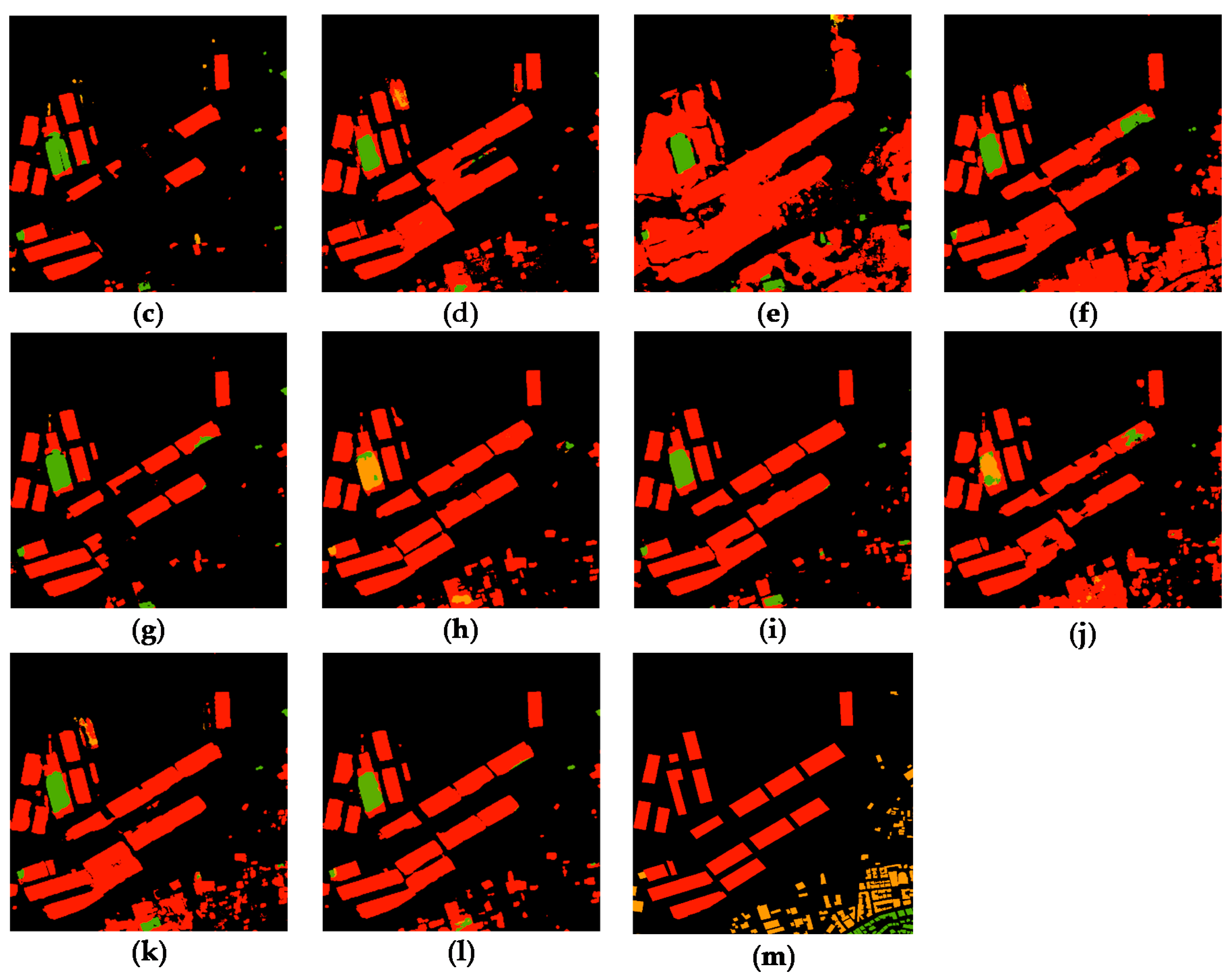
3.1. Compare Models
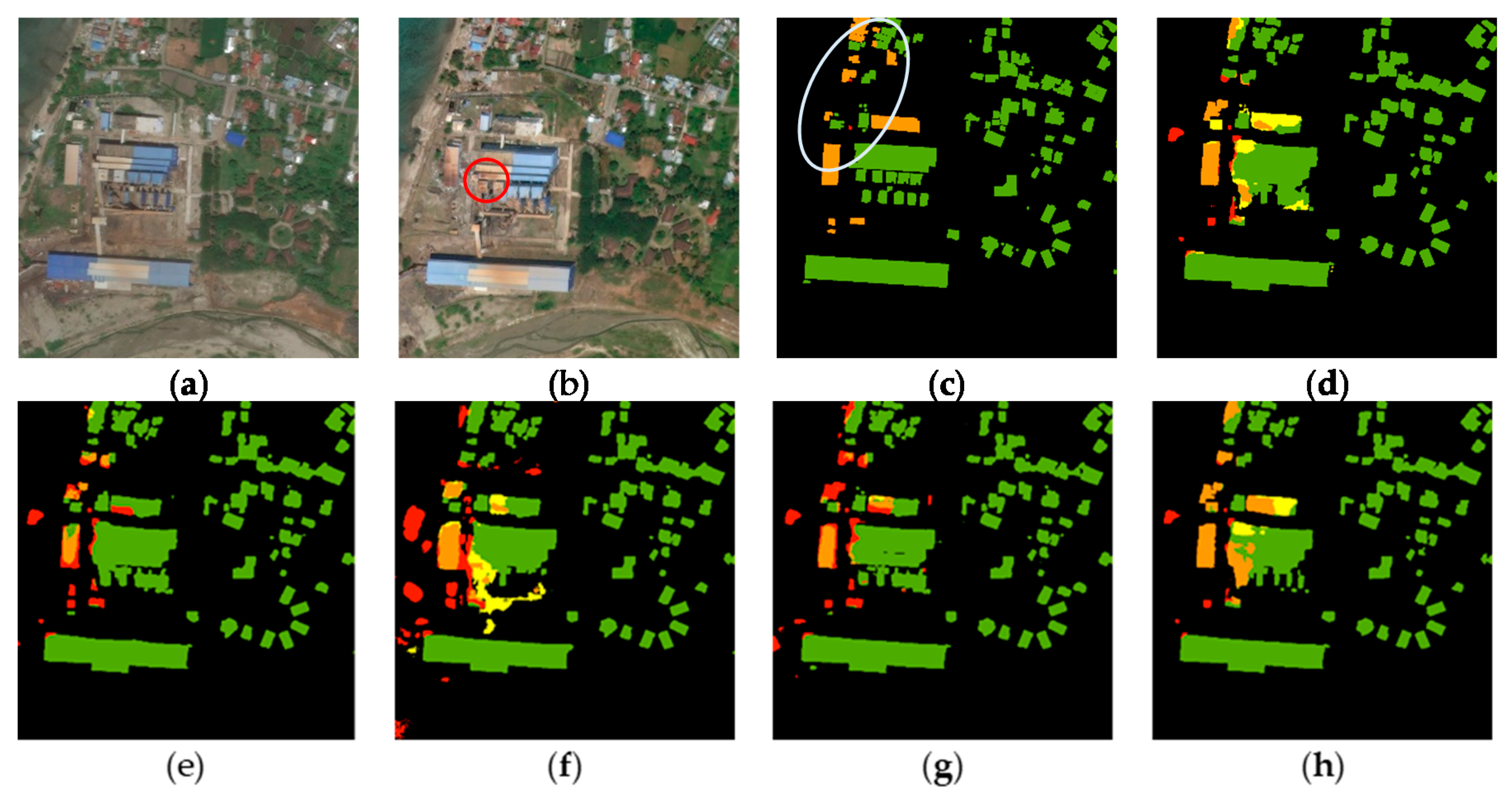
3.2. Fusion Results
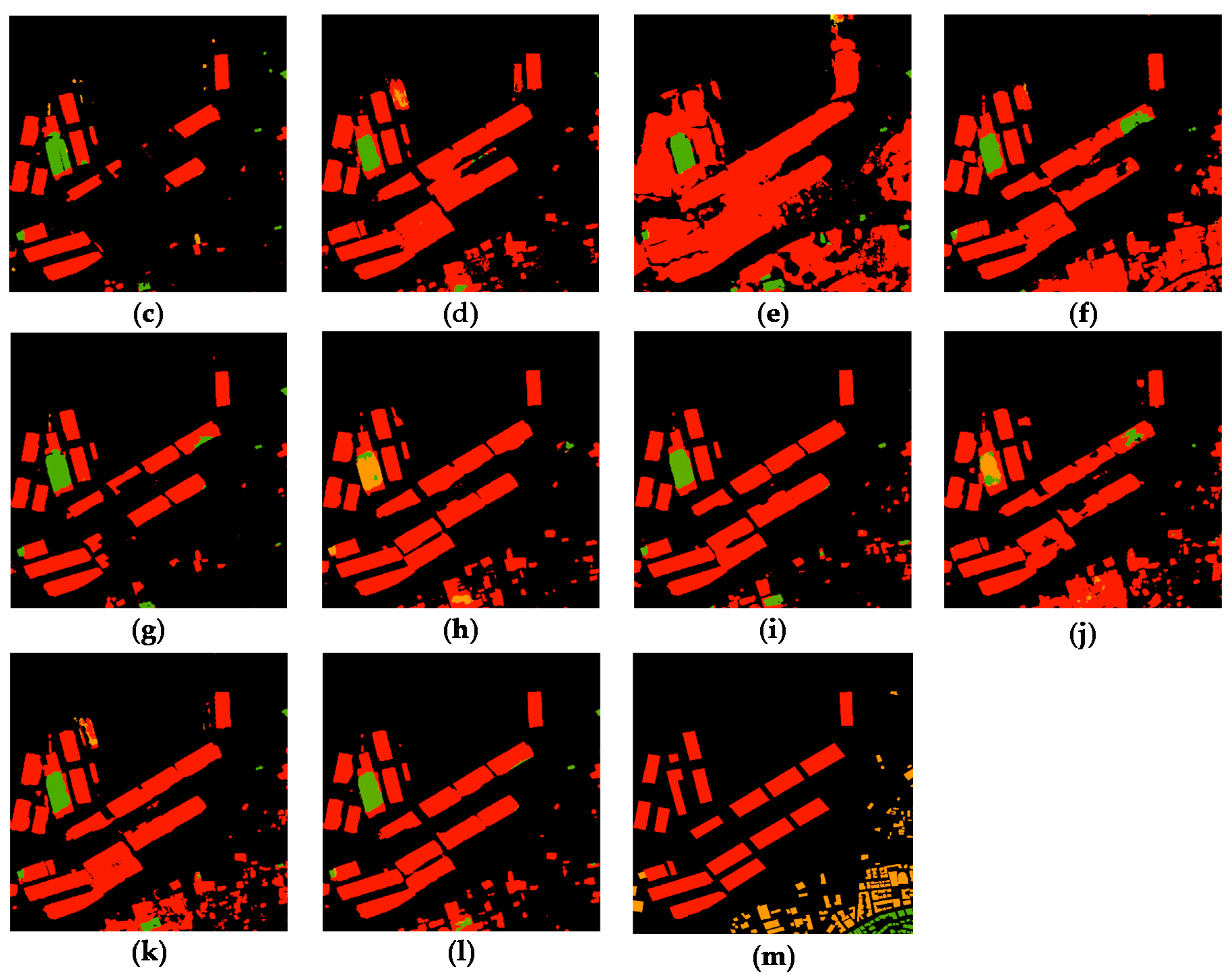
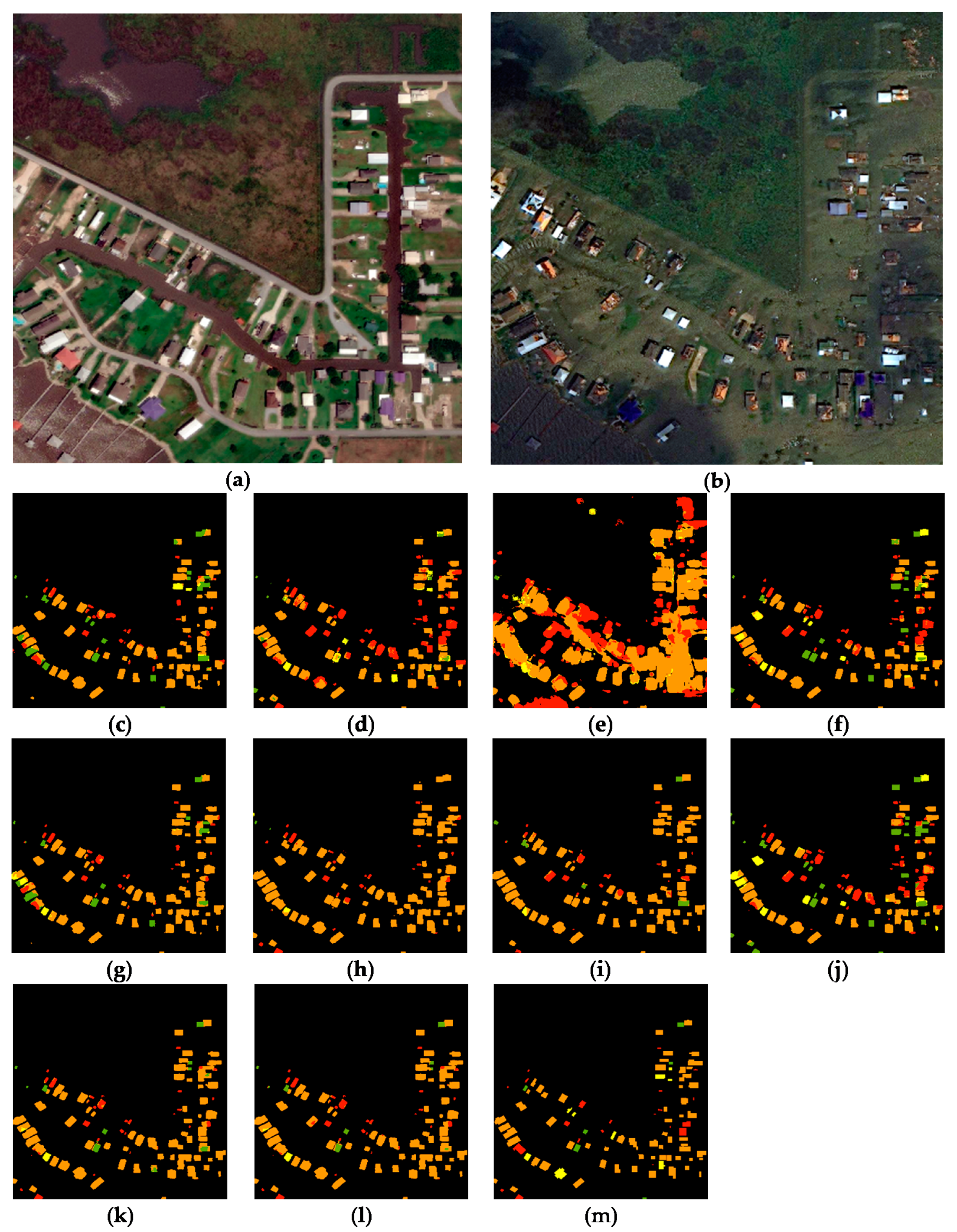
3.3. Transferability and Robustness
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Frankenberg, E.; Sumantri, C.; Thomas, D. Effects of a natural disaster on mortality risks over the longer term. Nat. Sustain. 2020, 3, 614–619. [Google Scholar] [CrossRef]
- Menderes, A.; Erener, A.; Sarp, G. Automatic Detection of Damaged Buildings after Earthquake Hazard by Using Remote Sensing and Information Technologies. Procedia Earth Planet. Sci. 2015, 15, 257–262. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.Z.; Lu, W.; Li, Z.; Khaitan, P.; Zaytseva, V. Building Damage Detection in Satellite Imagery Using Convolutional Neural Networks. arXiv 2019, arXiv:1910.06444. [Google Scholar]
- Cooner, A.J.; Shao, Y.; Campbell, J.B. Detection of urban damage using remote sensing and machine learning algorithms: Revisiting the 2010 Haiti earthquake. Remote Sens. 2016, 8, 868. [Google Scholar] [CrossRef] [Green Version]
- Dell’Acqua, F.; Gamba, P. Remote sensing and earthquake damage assessment: Experiences, limits, and perspectives. Proc. IEEE 2012, 100, 2876–2890. [Google Scholar] [CrossRef]
- Wang, T.L.; Jin, Y.Q. Postearthquake building damage assessment using multi-mutual information from pre-event optical image and postevent SAR image. IEEE Geosci. Remote Sens. Lett. 2012, 9, 452–456. [Google Scholar] [CrossRef]
- Vu, T.T.; Ban, Y. Context-based mapping of damaged buildings from high-resolution optical satellite images. Int. J. Remote Sens. 2010, 31, 3411–3425. [Google Scholar] [CrossRef]
- Adriano, B.; Xia, J.; Baier, G.; Yokoya, N.; Koshimura, S. Multi-source data fusion based on ensemble learning for rapid building damage mapping during the 2018 Sulawesi earthquake and Tsunami in Palu, Indonesia. Remote Sens. 2019, 11, 886. [Google Scholar] [CrossRef] [Green Version]
- Weber, E.; Kané, H. Building Disaster Damage Assessment in Satellite Imagery with Multi-Temporal Fusion. arXiv 2020, arXiv:2004.05525. [Google Scholar]
- Chen, S.A.; Escay, A.; Haberland, C.; Schneider, T.; Staneva, V.; Choe, Y. Benchmark Dataset for Automatic Damaged Building Detection from Post-Hurricane Remotely Sensed Imagery. arXiv 2018, arXiv:1812.05581. [Google Scholar]
- Dong, L.; Shan, J. A comprehensive review of earthquake-induced building damage detection with remote sensing techniques. ISPRS J. Photogramm. Remote Sens. 2013, 84, 85–99. [Google Scholar] [CrossRef]
- Duarte, D.; Nex, F.; Kerle, N.; Vosselman, G. Satellite image classification of building damages using airborne and satellite image samples in a deep learning approach. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Copernicus GmbH, Riva del Garda, Italy, 4–7 June 2018; Volume 4, pp. 89–96. [Google Scholar]
- Guo, H.D.; Wang, X.Y.; Li, X.W.; Liu, G.; Zhang, L.; Yan, S.Y. Yushu earthquake synergic analysis using multimodal SAR datasets. Chin. Sci. Bull. 2010, 55, 3499–3503. [Google Scholar] [CrossRef]
- Mao, Y.; Zhu, B.; Zhang, Q.; Wang, J. Urban Change Detection Based on High Resolution SAR and Optical Remote Sensing Data. Urban Geotech. Investig. Surv. 2019, 5, 17–20. [Google Scholar]
- Ji, M.; Liu, L.; Buchroithner, M. Identifying collapsed buildings using post-earthquake satellite imagery and convolutional neural networks: A case study of the 2010 Haiti Earthquake. Remote Sens. 2018, 10, 1689. [Google Scholar] [CrossRef] [Green Version]
- Pesaresi, M.; Gerhardinger, A.; Haag, F. Rapid damage assessment of built-up structures using VHR satellite data in tsunami-affected areas. Int. J. Remote Sens. 2007, 28, 3013–3036. [Google Scholar] [CrossRef]
- Gamba, P.; Dell’Acqua, F.; Odasso, L. Object-oriented building damage analysis in VHR optical satellite images of the 2004 Tsunami over Kalutara, Sri Lanka. In Proceedings of the 2007 Urban Remote Sensing Joint Event, Paris, France, 11–13 April 2007; pp. 1–5. [Google Scholar]
- Tong, X.; Hong, Z.; Liu, S.; Zhang, X.; Xie, H.; Li, Z.; Yang, S.; Wang, W.; Bao, F. Building-damage detection using pre- and post-seismic high-resolution satellite stereo imagery: A case study of the May 2008 Wenchuan earthquake. ISPRS J. Photogramm. Remote Sens. 2012, 68, 13–27. [Google Scholar] [CrossRef]
- Liu, R.; Cheng, Z.; Zhang, L.; Li, J. Remote sensing image change detection based on information transmission and attention mechanism. IEEE Access 2019, 7, 156349–156359. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Kerle, N.; Pasolli, E.; Arsanjani, J.J. Post-disaster building database updating using automated deep learning: An integration of pre-disaster OpenStreetMap and multi-temporal satellite data. Remote Sens. 2019, 11, 2427. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhang, X.; Huang, J.; Wang, H.; Xin, Q. Fine-Grained Building Change Detection From Very High-Spatial-Resolution Remote Sensing Images Based on Deep Multitask Learning. IEEE Geosci. Remote Sens. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.K.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 3, 2204–2212. [Google Scholar]
- Hao, H.; Baireddy, S.; Bartusiak, E.R.; Konz, L.; LaTourette, K.; Gribbons, M.; Chan, M.; Comer, M.L.; Delp, E.J. An attention-based system for damage assessment using satellite imagery. arXiv 2020, arXiv:2004.06643. [Google Scholar]
- Mou, L.; Zhu, X.X. Learning to Pay Attention on Spectral Domain: A Spectral Attention Module-Based Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 110–122. [Google Scholar] [CrossRef]
- Gupta, R.; Hosfelt, R.; Sajeev, S.; Patel, N.; Goodman, B.; Doshi, J.; Heim, E.; Choset, H.; Gaston, M. xBD: A Dataset for Assessing Building Damage from Satellite Imagery. arXiv 2019, arXiv:1911.09296. [Google Scholar]
- Open Data Program. Available online: https://www.maxar.com/open-data (accessed on 24 November 2020).
- Castello, R.; Roquette, S.; Esguerra, M.; Guerra, A.; Scartezzini, J.L. Deep learning in the built environment: Automatic detection of rooftop solar panels using Convolutional Neural Networks. J. Phys. Conf. Ser. 2019. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Ebrahim, M.; Al-Ayyoub, M.; Alsmirat, M.A. Will Transfer Learning Enhance ImageNet Classification Accuracy Using ImageNet-Pretrained Models? In Proceedings of the 2019 10th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 11–19 June 2019; pp. 211–216. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; 2009; pp. 248–255. [Google Scholar]
- Telgarsky, M. Benefits of depth in neural networks. In Proceedings of the Journal of Machine Learning Research: Workshop and Conference Proceedings, New York, NY, USA, 23–26 June 2016; Volume 49, pp. 1517–1539. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 5987–5995. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing, Long beach, CA, USA, 3–9 December 2017; pp. 4468–4476. [Google Scholar]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Van Rijsbergen, C.J. Information retrieval; 2nd ed.; Butterworth, 1978. J. librariansh. 1979, 11, 237. [Google Scholar]
- Yang, Y. An evaluation of statistical approaches to text categorization. Inf. Retr. Boston 1999, 1, 69–90. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.O.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings; International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Corbane, C.; Saito, K.; Dell’Oro, L.; Bjorgo, E.; Gill, S.P.D.; Piard, B.E.; Huyck, C.K.; Kemper, T.; Lemoine, G.; Spence, R.J.S.; et al. A comprehensive analysis of building damage in the 12 January 2010 MW7 Haiti earthquake using high-resolution satelliteand aerial imagery. Photogramm. Eng. Remote Sens. 2011, 77, 997–1009. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Proportion |
|---|---|
| Not Building | 539.721 |
| No Damage Building | 12.963 |
| Minor Damage Building | 1.433 |
| Major Damage Building | 1.493 |
| Destroyed Building | 1 |
| xBD Level | CEMS Level |
|---|---|
| No Damage | Possible Damage |
| Minor Damage | Moderate Damage, Possible Damage |
| Major Damage | Severe Damage, Moderate Damage |
| Destroyed | Destroyed, Severe Damage |
| Disaster | Location | Date | Pre-Image Date | Post-Image Date |
|---|---|---|---|---|
| Beirut Explosion | Beirut, Lebanon | 04/08/2020 | 09/06/2020 | 05/08/2020 |
| Hurricane Laura | Parts of Louisiana and far-eastern Texas | 27/08/2020 | 03/06/2019 | 27/08/2020 |
| Backbone Type (BT) | Overall F1 (OF1) | LocalizationF1 (LF1) | ClassificationF1 (CF1) | No Damage | Minor Damage | Major Damage | Destroyed | Localization MIoU (LMIoU) | Classification MIoU (CMIoU) |
|---|---|---|---|---|---|---|---|---|---|
| resNet | 0.636 | 0.856 | 0.541 | 0.863 | 0.351 | 0.474 | 0.789 | 0.748 | 0.371 |
| SEresNeXt | 0.755 | 0.860 | 0.710 | 0.916 | 0.502 | 0.741 | 0.834 | 0.754 | 0.551 |
| DPN | 0.739 | 0.735 | 0.741 | 0.920 | 0.553 | 0.742 | 0.865 | 0.581 | 0.589 |
| SENet | 0.772 | 0.863 | 0.734 | 0.912 | 0.544 | 0.741 | 0.857 | 0.759 | 0.579 |
| BT | OF1 | LF1 | CF1 | No Damage | Minor Damage | Major Damage | Destroyed | LMIoU | CMIoU |
|---|---|---|---|---|---|---|---|---|---|
| resNet | 0.744 | 0.856 | 0.696 | 0.880 | 0.501 | 0.719 | 0.818 | 0.748 | 0.533 |
| SEresNeXt | 0.787 | 0.868 | 0.752 | 0.920 | 0.583 | 0.750 | 0.847 | 0.767 | 0.603 |
| DPN | 0.781 | 0.870 | 0.742 | 0.919 | 0.553 | 0.759 | 0.852 | 0.769 | 0.590 |
| SENet | 0.779 | 0.859 | 0.745 | 0.903 | 0.569 | 0.751 | 0.853 | 0.753 | 0.594 |
| Group | OF1 | LF1 | CF1 | No Damage | Minor Damage | Major Damage | Destroyed | LMIoU | CMIoU |
|---|---|---|---|---|---|---|---|---|---|
| Without Attention | 0.769 | 0.862 | 0.728 | 0.914 | 0.527 | 0.751 | 0.855 | 0.758 | 0.573 |
| With Attention | 0.792 | 0.871 | 0.758 | 0.916 | 0.582 | 0.768 | 0.859 | 0.771 | 0.611 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Zhang, F.; Xia, J.; Xu, Y.; Li, G.; Xie, J.; Du, Z.; Liu, R. Building Damage Detection Using U-Net with Attention Mechanism from Pre- and Post-Disaster Remote Sensing Datasets. Remote Sens. 2021, 13, 905. https://doi.org/10.3390/rs13050905
Wu C, Zhang F, Xia J, Xu Y, Li G, Xie J, Du Z, Liu R. Building Damage Detection Using U-Net with Attention Mechanism from Pre- and Post-Disaster Remote Sensing Datasets. Remote Sensing. 2021; 13(5):905. https://doi.org/10.3390/rs13050905
Chicago/Turabian StyleWu, Chuyi, Feng Zhang, Junshi Xia, Yichen Xu, Guoqing Li, Jibo Xie, Zhenhong Du, and Renyi Liu. 2021. "Building Damage Detection Using U-Net with Attention Mechanism from Pre- and Post-Disaster Remote Sensing Datasets" Remote Sensing 13, no. 5: 905. https://doi.org/10.3390/rs13050905
APA StyleWu, C., Zhang, F., Xia, J., Xu, Y., Li, G., Xie, J., Du, Z., & Liu, R. (2021). Building Damage Detection Using U-Net with Attention Mechanism from Pre- and Post-Disaster Remote Sensing Datasets. Remote Sensing, 13(5), 905. https://doi.org/10.3390/rs13050905