1. Introduction
The data of the Sentinel-2 satellite provided by the European Copernicus Earth Observation Program [
1] are free and available globally, and they have been widely used in several agricultural applications, such as crop classification [
2], cropland monitoring [
3], growth evaluation [
4,
5], and flood mapping [
6]. However, as an optical satellite, Sentinel-2 inevitably suffers from cloud and shadow contamination, which can cause a shortage of efficient Earth surface reflectance data for subsequent research [
7,
8].
Yang et al. [
7] and Zhang et al. [
9] replaced the contaminated images and created new images with time-close uncontaminated images or the mean of the fore-time phase and the post-time phase. The rationale behind this was that land features should be similar if the time and space of the respective images are close to each other. However, this method places a very high demand on related cloud-free images and is not able to capture changes between the reference data and the target data. In order to solve this issue, some researchers have tried to fuse other auxiliary optical images with the target optical images to increase the quality of the simulated images [
10,
11,
12,
13]. Although this method could add some new information to the model, the auxiliary images are still optical data, so if there are continual cloudy days appearing in some places, it is still impossible to collect efficient data.
To solve the cloud contamination problem, we should add some auxiliary data that are able to penetrate clouds. Synthetic Aperture Radar (SAR) could overcome the weakness of optical images. It can work throughout the day and night and under any weather conditions [
14]. It has a penetration capacity that captures surface features in spite of clouds [
15]. The Sentinel-1 satellite, as an SAR satellite, is provided by the Copernicus Sentinel-1 mission [
16], which is free to users, like Sentinel-2. Thus, some researchers started to consider how to use SAR/Sentinel-1 as input data to provide prior information [
17]. Ordinarily, this is an SAR-to-optical image translation process [
18]. However, SAR and optical remote sensing are fundamentally different in imaging principles, so a captured feature of the same object from these two technologies will be inconsistent. Meanwhile, SAR lacks spectrally resolved measurements, which means it would be a challenge to guarantee the quality of the retrieved spectrum.
With the development of deep learning [
19,
20,
21], the Generative Adversarial Network (GAN) has received increasing attention in remote sensing due to its superior performance in data generation [
22]. Many researchers have since tried to ingest Optical-SAR images into a Conditional Generative Adversarial Network (cGAN) [
23], a Cycle-consistent Adversarial Network (CycleGAN) [
24], and other GAN models [
25,
26]. There are two modules in the GAN-based model, one is the Generator, which is used to extract features from input data to generate the simulated images, and the other is the Discriminator, which judges whether the simulated images are real. These two modules, like opponents, compete with each other until the process reaches a trade-off status [
27]. We can classify these GAN methods into two categories, supervised and unsupervised. For deriving non-cloud Sentinel-2 images, the cGAN, a supervised GAN, needs a pair of Sentinel-1 and Sentinel-2 images as input. Sentinel-1 is used to provide surface feature information, and Sentinel-2 is able to continually correct the quality of the simulated images [
28,
29]. The CycleGAN, an unsupervised GAN, only needs a Sentinel-2 dataset and a Sentinel-1 dataset (they could be unpaired), which means this method would have a lighter restraint on data compared with the other methods [
24]. Regardless of which kind of methods is used, most researchers have only collected mono-temporal Sentinel-2/Sentinel-1 datasets as input data, which means they tried to learn the relationship between optical images and SAR images at the training stage, but for the inference stage, they only input the Sentinel-1 data into the trained network to generate the simulated Sentinel-2 data [
30,
31,
32,
33]. This would demand that Sentinel-1 has the same distinguishing ability as Sentinel-2 for different surface objects. Otherwise, the simulated images could not guarantee that enough details are simulated. Unfortunately, some surface objects always have similar backscattering properties, which makes it difficult to distinguish them using SAR data [
31]. Therefore, this kind of input data is a little too simple to guarantee a satisfactory accuracy.
In order to keep more real Earth surface details in the simulated optical images, Li et al. [
34] and Wang et al. [
35] started to pay attention to the corrupted optical images. These researchers tried to add the corrupted optical images as a kind of additional input data along with the Optical-SAR image pairs mentioned above to the network [
36,
37]. Adding the corrupted optical data, compared with other input data, is an efficient way to improve the accuracy of the simulated images. Ordinarily, the simulated images could save some textural and color details from the uncontaminated part of the corrupted images. However, how enough information can be learned if the corrupted optical images are covered by a large amount of clouds is still an open question. As we know, if we want to use deep learning, we often need to split the whole image into many small patches, such as images in 256 × 256 [
38] or 128 × 128 [
39]. That means that, even if we have filtered the cloud percentage and have selected some images with scattered clouds, such as these corrupted images, there is still a possibility that some split small images are full of thin or thick clouds. Meanwhile, this approach needs these corrupted images as input, which means it is not able to generate cloud-free optical images at other time phases when there are no optical images captured by satellite [
25,
40].
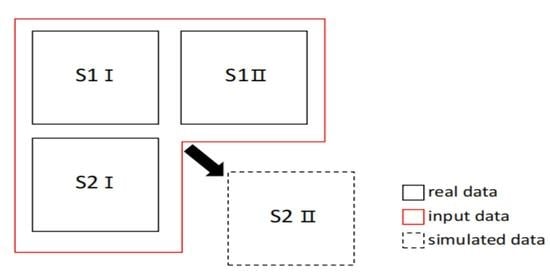
In this study, we increased the channels of the cGAN [
23] to make the model able to exploit multi-temporal Sentinel-2/Sentinel-1 image pairs, which is the MCcGAN. The structure of this paper is as follows: In
Section 2, we introduce the structure and loss functions of the cGAN we used and explain how the three different datasets can be built. In
Section 3, we elaborate how we implemented the experiments to assess different methods. Finally,
Section 4 and
Section 5 discuss the experimental results and describe future work.
4. Discussion
The multi-temporal models were not only able to convert the style of the images from SAR to Optical, but were also able to save more details. They could simulate optical images with a higher quality compared to the mono-temporal models, especially the proposed method (MCcGAN), whose advantages are shown in
Section 3. Using the mono-temporal models, due to the difference between SAR data and optical data in ground object reflection, it is more difficult to generate optical images with high quality only from mono-temporal SAR. However, generally, these multi-temporal models are sensitive to the time interval between the reference data and the simulated data, which means the MCcGAN cannot guarantee simulation quality if the acquisition date of the reference cloud-free optical image is far away from the target date. We could not quantitatively estimate the relationship between the time interval and the simulation quality in this study, and this is also a common issue in other related literature. In future work, we will use datasets with more phases to explore the relationship between the time interval and the simulation quality.
Compared with the proposed method, the mono-temporal models (CycleGAN [
24], S-CycleGAN [
31], and pix2pix [
40]) were also able to convert the style of images from SAR to Optical, but they could not recover more details. Their advantage is that they do not need reference paired images, which means they can play a significant role if it is hard to acquire reference optical images with high quality. Moreover, we think that the CycleGAN is not suitable for this kind of task because, while its advantage is an unsupervised transfer, it is not able to retain pixel-wise accuracy.
Although both the MCcGAN and the MTcGAN [
43] are multi-temporal models, they have their own advantages.
Table 8 shows that the MCcGAN is better than the MTcGAN in most validation areas, except for Area 2. We checked the main types of the surface object in these five areas. Area 2 contains some towns and mountains, and other areas are cropland. Therefore, when comparing these two models, the MTcGAN is more suitable for generating cloud-free Sentinel-2-like images in the towns and mountains, and the MCcGAN is better for generating cloud-free Sentinel-2-like images in the cropland.
The loss functions used in this paper are GANLoss, L1Loss, and DLoss, which are loss functions commonly used in typical conditional generative adversarial networks. In the reference [
36], Gao et al. proposed that a perceptual loss function is able to generate results with better visual perception, because this function is designed to measure high dimensional features such as color and shape. However, we mainly updated the network with low dimensional features (the difference in pixel values between the simulated images and the real images). Next, we would add this function to MCcGAN to see whether it is useful for our model.
In fact, we only used two types of temporal information. In the future, we hope to add more time-series data as a reference to simulate the target data. We want to explore whether the cGAN is able to capture changes according to the reference data and transfer it to the simulated stage to retain results with high quality.
In order to obtain simulated optical images with more detail, we also intend to use corrupted real optical images in our model in the future. The results are expected to retain details from cloud-free areas in corrupted real optical images. For corrupted areas, we hope that the model can recover the details from the multi-temporal reference data. In this way, we think the simulation will have a higher quality. To evaluate the results, it will be necessary to add absolute validation with ground truth data. Therefore, collecting ground truth data from the Radiometric Calibration Network portal (RadCalNet,
https://www.radcalnet.org/#!/ (accessed on 10 December 2020)) will be our next task.
5. Conclusions
In this paper, we added new channels to the cGAN to obtain the MCcGAN, which is able to learn information from multi-temporal paired images of Sentinel-1 and Sentinel-2. We downloaded and processed original Sentinel series images from the official website and then produced them as a multi-temporal dataset used in this paper. Meanwhile, the global dataset was built based on the GEE. To explore the advantage of the proposed method, we designed three experiments to make comparisons with other state-of-the-art methods. In order to quantitatively assess the results, we used popular statistical metrics, including RMSE, R, KGE, SSIM, PSNR, and SAM. The results in the first experiment illustrated that the proposed method can be trained in one place and then used in another place. The results in the second experiment showed that the proposed method is sensitive to the time interval between the reference data and the simulated data. It would be better to keep the time interval as narrow as possible when using the MCcGAN. The last experiment proved that the proposed method is applicable on a large scale. The proposed method not only succeeded in transferring the style of the images from SAR to Optical but also recovered more details. It is superior to other methods. We think that our method can play an important role in Optical-SAR transfer tasks, data filling in crop classification, and other research.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







