1. Introduction
In the immediate vicinity of the source of a future earthquake, anomalous changes in a number of processes occur. Abnormalities are instrumentally recorded in the frequency and intensity of seismic events, in the deformations of the Earth’s surface, in the chemical composition of fluids, in the groundwater level, in the time of passage of seismic waves, in the values of electric and geomagnetic fields, etc. [
1,
2,
3,
4]. Seismological monitoring data are currently the most widely available. Therefore, systematic earthquake prediction systems use only seismological data [
5,
6]. The use of additional information on spatial and temporal changes in a geological environment can provide more accurate predictions of earthquakes.
In recent years, the monitoring data of the Earth’s surface displacement obtained by Global Positioning System (GPS) have been published in real time for a number of seismically active regions. These data are used to study block models of the Earth’s crust and in earthquake prediction studies. In the articles [
7,
8,
9,
10], the displacements of the Earth’s surface were estimated from triplets of GPS ground network stations. Triangles with vertices at the stations’ locations can intersect different plates. It was shown that before strong earthquakes, there are changes in the area and other parameters of the triangles. In a number of later works, artificial intelligence methods were used to study the effectiveness of earthquake predictions based on GPS data [
11,
12,
13,
14]. In [
15], GPS ground displacement data were used to predict 15 major earthquakes in western North America in 2007–2016. The forecast algorithm uses time series of horizontal and vertical displacements of GPS stations.
It is known that the accuracy of GPS measurements for vertical components of coordinates is 2–4 times less than for horizontal ones [
16,
17]. Therefore, in this paper, we considered only the horizontal components of the displacement velocities. It was theoretically shown in [
18] that the field of horizontal velocities of the Earth’s surface displacements reflects the movements of the crustal blocks. Analysis of GPS data for the Bishkek geodynamic test area in the Tien Shan showed that seismicity increases in those areas where the horizontal component of the rate of change in the size and/or rotation of the Earth’s surface is close to its maximum values [
19].
In this article, we use a statistical approach to assess the effectiveness of using GPS data for earthquake prediction. Our conclusion is based on the results of earthquake forecasting in two regions, which differ significantly in the seismotectonic and geodynamic regimes. Following a statistical approach, we consider GPS data to be effective if the result of a successful prediction of earthquakes based on these data is significantly better than the result of a random prediction of the same earthquakes or a prediction based on spatial seismicity data.
Obviously, the forecast result depends on both the GPS time series preprocessing methods and the forecast method. Currently, a number of works are underway using machine learning methods for predicting earthquakes. They include the study of mathematical models for earthquake prediction, machine learning methods and testing earthquake prediction algorithms [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29]. Many articles are devoted to earthquake prediction using artificial neural networks [
30,
31] and more sophisticated methods, including hybrid neural network [
32], and recurrent neural network [
33], and a lot of other machine learning methods [
34]. Despite the relatively positive results claimed in those studies, some simpler models can offer similar or better predictive powers [
35]. This is due to the fact that the number of major seismic events is very low, making the forecasting of such events more difficult [
36].
Here we use a machine learning prediction method that we call the method of the minimum area of alarm [
37]. Forecast training is carried out according to the precedents of the occurred target earthquakes. The learning-based minimum alarm zone method systematically calculates a predictive alarm zone map in which a target earthquake with a magnitude greater than a predetermined magnitude is expected. The alarm zone is determined by the function of the grid spatio-temporal fields of features calculated on the basis of the initial data. For many seismically active regions, the quality of machine learning for predicting strong earthquakes is limited by a small number of precedents. Our method uses a mathematical model that allows, during training, to select anomalies in feature fields that precede target earthquakes, compare these anomalies with each other, and select other anomalies in feature fields similar to those selected during training. This model introduces constraints on the prediction rule that help compensate to some extent for a small number of use cases during training.
This article is divided into three sections. In
Section 2, we briefly discuss the method of the minimum area of alarm.
Section 3 and
Section 4 present and discuss the results of modeling the forecast of strong earthquakes in Japan and California. For each region, we compare the following results: random forecast of earthquakes, forecast obtained with the field of spatial density of earthquake epicenters, forecast obtained with spatio-temporal fields based on GPS data, based on seismological data, and based on combined GPS data and seismological data.
2. Method
The method of the minimum area of alarm was designed to systematically predict strong earthquakes with a magnitude above a certain threshold [
37]. The platform for systematic earthquake prediction regularly with a step
calculates the alarm zone, in which the epicenter of the target earthquake is expected. A demo version of the platform has been available since 2018 at
https://distcomp.ru/geo/prognosis/ (accessed on 5 March 2021).
We assume that strong earthquakes are preceded by abnormal manifestations, which can be represented in a spatio-temporal grid-based fields of features. The method of the minimum area of alarm is trained to calculate alarm zones based on retrospective observations consisting of the spatio-temporal fields of features,
, and a sample consisting of marked target abnormal objects and an unmarked mixture of target and normal objects. The abnormal objects here are the field values selected by the machine learning algorithm among the points preceding the epicenters of the target earthquakes
with magnitudes
(earthquake precursors). An unlabeled mixture of objects is represented by points with field values at all other grid nodes. This formulation in machine learning refers to one-class classification problems [
38,
39,
40].
The fields are set in a single coordinate grid. The values of the fields at the grid nodes correspond to the points of the I-dimensional feature space . During training, the spatio-temporal field , called the alarm field, is calculated. The values of the alarm field allocate a spatio-temporal area in it, called the alarm area. The temporal slice of the alarm area at the time of the forecast is exactly the alarm zone, in which the appearance of the epicenter of the target earthquake is predicted at the interval .
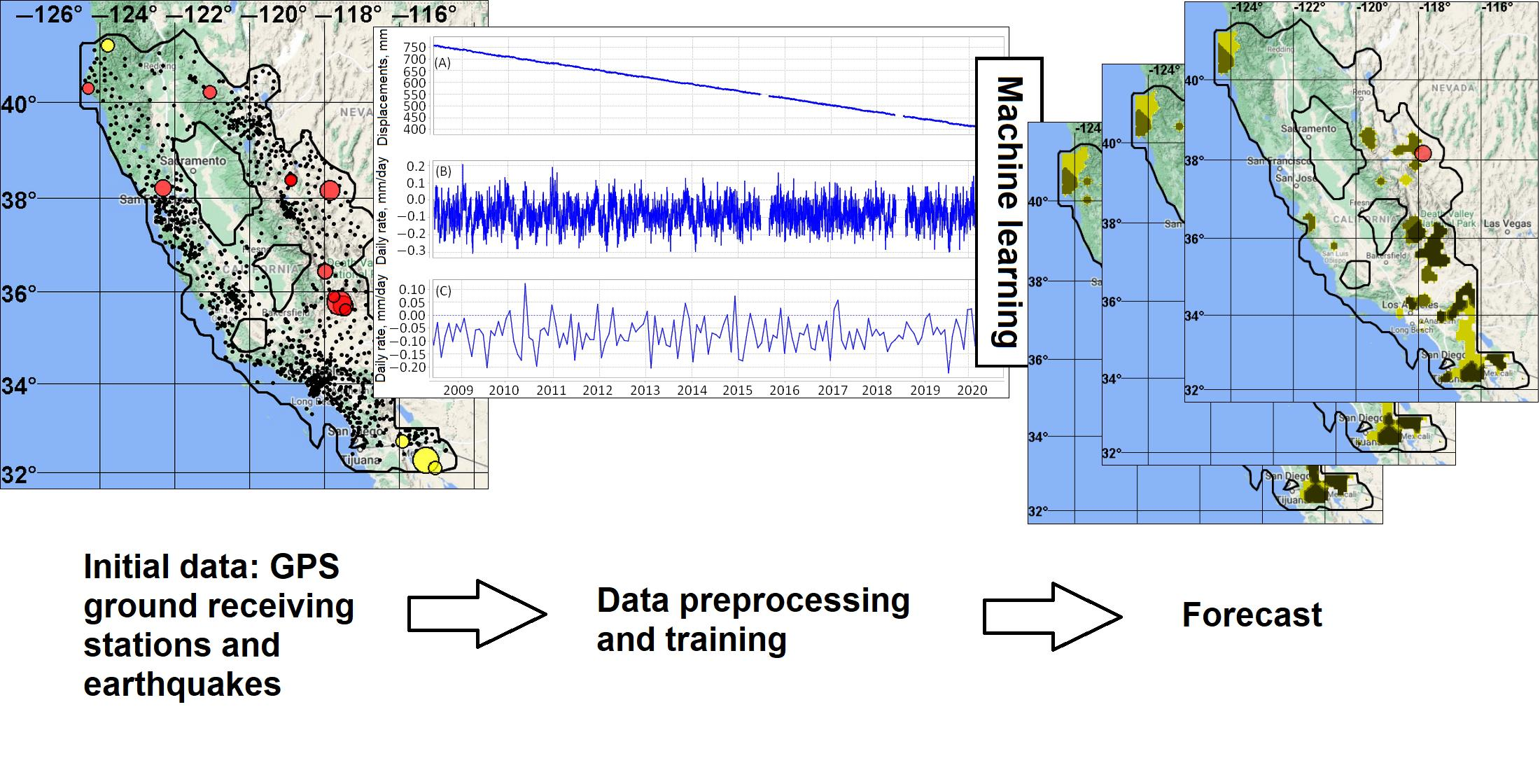
Figure 1 shows operations in the interval
. The program downloads new data from remote servers and user computer, then preprocess them, calculates spatial and spatio-temporal fields of features, and selects data on target earthquakes from the catalog. Then, using the algorithm of the method of the minimum area of alarm, the program calculates the alarm field
in the interval from the beginning of training to the moment of forecasting
. The time interval of the alarm field at the moment
is a map of the alarm zone.
The target earthquake is predicted at the step if its epicenter falls into the alarm zone. The larger the product , the more successful the forecast. However, it is obvious that the value of this spatio-temporal area should be reasonably limited. The indicators of the forecast quality are the estimations of the probability of a successful forecast of events (the forecast probability) and the size of the alarm area in the training interval (volume of alarm). As a result of training, it is desirable to obtain a solution in which the maximum number of successful forecasts of target events is achieved for a given size of the volume of alarm.
The method of the minimum area of alarm is based on a model that introduces a measure of the anomality for points in the feature space. The algorithm uses this measure to select points that can be considered precursors of target earthquakes. The model contains two assumptions:
Abnormality: In feature space, the target earthquakes are preceded by points (earthquake precursors) for which the values of some components (the values of some feature fields) are unlikely and close to the maximum (or minimum). To simplify the explanation, we assumed without loss of generality that the precursors refer only to the maximal values of the fields of features.
Monotonicity: Feature space points that are, component-wise, larger than the earthquake precursor can also be precursors of similar target events.
For training, the earthquake prediction algorithm requires determining the precursor for each target event. Let the event q be preceded by a precursor . The precursor is associated with a feature space area whose points are, component-wise, greater than or equal to , i.e., the area . We called this area the orthant with a vertex at and the points are called the base points of the target event q.
According to the monotonicity condition, base points are also precursors of events that are similar to the event
q. In geographical coordinates, each base point forms
a cylinder of alarm with the radius
R and the element
T. The alarm cylinder of the base point
has a circular base center at the grid node
n with coordinates
, a radius of the base
R, and the elements
, where
, in which
is the start time of training and
is the time of action on forecast. An earthquake can only be predicted if its epicenter falls into one of the alarm cylinders. The union of alarm cylinders formed by the base points of the orthant
selects a set of grid nodes
,
. Accordingly, it follows that an earthquake
q with the epicenter coordinates
can be predicted only if the cylinder with the center of the base of
, a radius
R, and the elements
contains at least one base point. This cylinder is called
a precursor cylinder. The precursor of event
q is the point
, which has the minimum value of the alarm volume
among all points, corresponding to the grid nodes of the precursor cylinder, where
L is the number of all grid nodes of the spatio-temporal area of analysis. The quantity
(
volume of the precursor) defines the measure of anomality for the precursor of event
q. In the paper [
41], the measure of the abnormality for target events was determined by the likelihood ratio estimate.
The forecast quality is determined by two indicators: (1) The probability of prediction
U, equal to the fraction of correctly forecasted target events
to all target
Q events,
, and (2) the volume of alarm
V, equal to the fraction of the number of grid nodes of the alarm field
with the values
to the number of all grid nodes of the analyzed area
L,
. It can be seen from the definition that the alarm volume
V is equal to the probability of the detection of target events by random areas consisting of
grid nodes. Usually, the quality of the forecast is determined by the dependence
, which is analogous to the error curve represented by the ROC (receiver operating characteristic) curve [
42,
43,
44].
In classification problems, the decision rule is found by minimizing the function of losses from target detection errors and false alarms. The training algorithm is optimal if it calculates an alarm area with the volume
, which, for any value
, provides the maximum value of
U. In our case, this solution requires large calculations because the sets of base points associated with different precursors intersect. Therefore, we considered solutions that are close to optimal [
37].
Consider the algorithm for constructing the alarm field.
Generate a training sample set . Arrange the precedents , , in accordance with the increase in the alarm volume of the target events .
Calculate the alarm field .
- (a)
Assign to the nodes of the grid of the alarm field a value of 1.
- (b)
Replace the value of 1 of the field with in the set of the grid nodes corresponding to the base points of the precedent ; replace the value of 1 with at the grid nodes ; replace the value of 1 with at the grid nodes and then sequentially replace the values of 1 with the corresponding values of the alarm volumes. The resulting field takes the values or 1. The value refers to grid nodes from the set , refers to grid nodes from the set , refers to grid nodes from the set , etc.
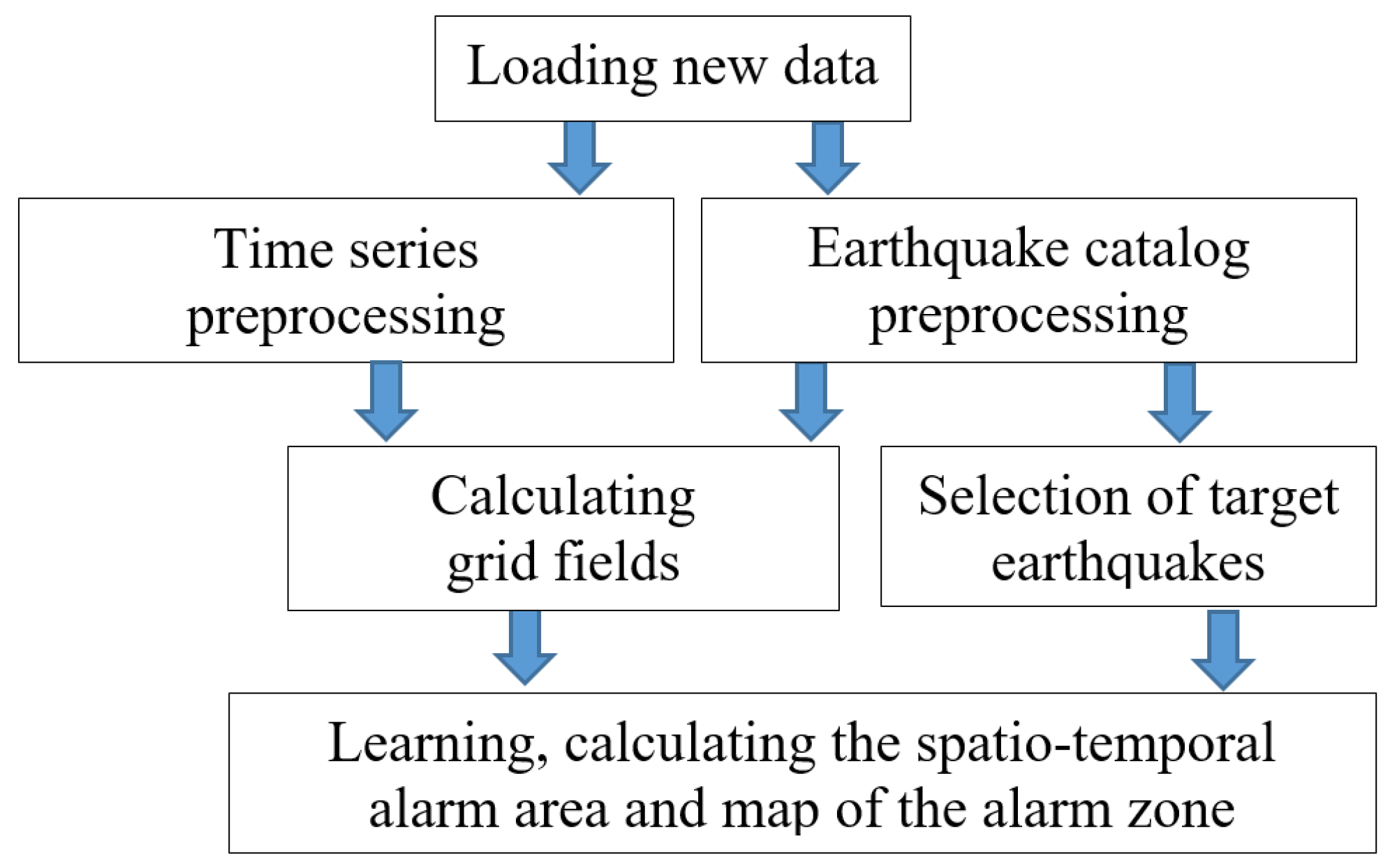
Figure 2 shows a flowchart of the algorithm. The grid feature fields and the sample of target earthquakes are regularly updated with a step
. For each epicenter from the sample, the precursor cylinders are calculated. Then, among the points of the feature space corresponding to the grid nodes in these cylinders, precursors
, orthants
, and alarm volumes of precursors
are selected. Then the precursors and orthants are ordered according to the increase in the alarm volumes of the precursors. After that, the alarm area and the map of the alarm zone are calculated.
3. Modeling
3.1. Technology
The efficiency of using the information on the Earth’s surface displacements according to GPS data for predicting earthquakes largely depends on the methods of data processing and analysis. For earthquake prediction, we used the method of the minimum area of alarm. Modeling simulates the operation of a demo platform (
https://distcomp.ru/geo/prognosis/) (accessed on 5 March 2021). We performed modeling on the GIS GeoTime 3 (
http://geo.iitp.ru/GT3/) (accessed on 5 March 2021).
The modeling technology, similarly to the forecast, is as follows. The area of analysis is selected. Point fields, time series, and rasters can be used as input. All initial data are converted into uniform grid-based spatial and spatio-temporal fields, which are used to calculate the zones of expected epicenters of target earthquakes at each moment of the forecast. The forecast is carried out systematically with a constant step. At each step n, training is performed using the data available from the start of training to the moment of forecasting , and the decision rule computed during training is checked at the interval . In the process of training, according to the monitoring data, new values of the forecast feature grid fields are calculated, the training sample of target earthquake epicenters is supplemented, the alarm area and the alarm zone are calculated. Testing verifies whether new epicenters of target earthquakes are in the calculated alarm zone.
3.2. Area of Analysis
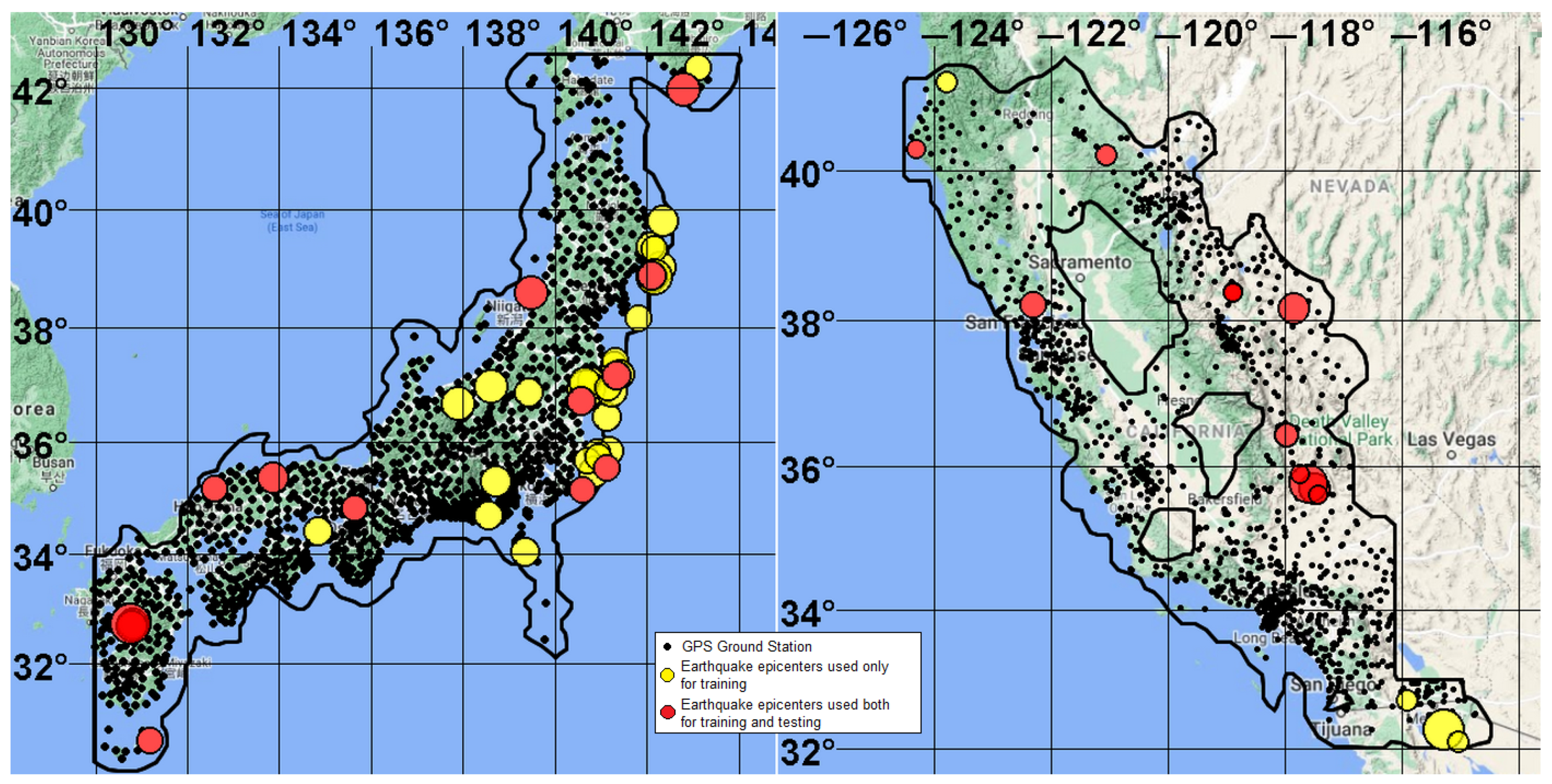
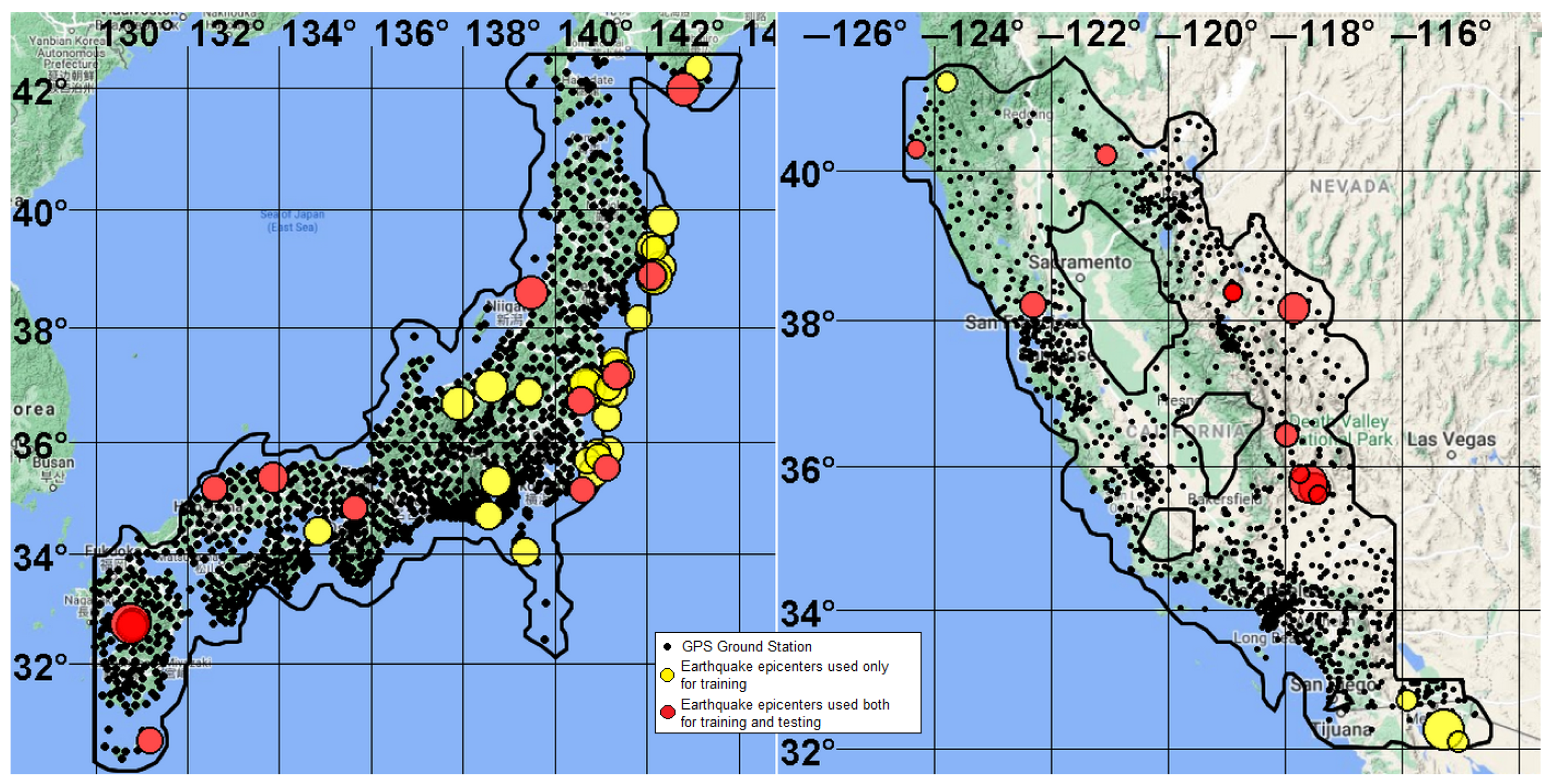
The regions under study are in Japan within the boundaries of 130–145.5° E and 30–43° N, and California (USA) within the boundaries of 125–114° W and 32–43° N. We forecasted earthquakes with a hypocenter depth of km for both regions, but with different magnitudes: in Japan and in California. The analysis of the depths of the hypocenters characteristic of the foci of tectonic earthquakes and the zones of their preparation in each of the regions under consideration was not carried out in this work. The area of analysis was determined by the intersection of two areas, A and B. Area A was defined as the territory for which the distance from any point to GPS ground receiving stations does not exceed 50 km. Area B was calculated from seismological data. It was selected such that, with an alarm volume of , the probability of predicting target earthquakes from the field of spatial (2D) density of earthquake epicenters 0.3–0.4. For this, in the time interval before the start of training, the 2D density field of earthquake epicenters with an averaging radius of 50 km was calculated. The boundary of the area of analysis was determined by the values of the field . If the forecast probability for the threshold C was greater than 0.3–0.4, then the threshold C had increased, and the procedure was repeated. Furthermore, the area of analysis was found as the intersection of areas A and B.
3.3. GPS Data Preprocessing
We analyzed the time series of daily horizontal displacements of the Earth’s surface at the intervals 1 January 2009–26 July 2020 for Japan and 1 January 2008–14 November 2020 for California. The data were obtained from the Nevada Geodetic Laboratory (NGL),
http://geodesy.unr.edu/about.php (accessed on 5 March 2021) [
45]. There are 1420 and 1803 GPS receiving stations in Japan and California, respectively, and the analysis areas contain 1229 and 1204 stations, respectively. The networks of GPS receiving stations, the areas of analysis, and the epicenters of target earthquakes are shown in
Figure 3. The stations evenly cover the analysis area. The average minimum distance between stations is 12.8 km for Japan and 9.38 km for California, with standard deviations of 5.4 and 5.74 km, respectively.
The calculation of the feature fields used for the earthquake prediction based on GPS data was performed in two stages. The purpose of the first stage was to extract a useful signal from the time series of coordinates of the receiving stations. The purpose of the second stage was to calculate spatio-temporal fields of forecast features.
3.3.1. Time Series of the Earth’s Surface Displacement Velocities
The initial data were daily time series of coordinates and of GPS ground receiving stations in the W–E and N–S directions in the intervals 1 January 2009–26 July 2020 for Japan and 1 January 2008–14 November 2020 for California. The daily horizontal velocities of the Earth’s surface displacements and were determined by two coordinates of the GPS receiving station, spaced in time by the interval : , . There were discontinuities (gaps) in the time series. In our case, for each coordinate, there were 23,682 gaps and 168,218 days of missed measurements for Japan, and 29,977 gaps and 357,067 days of missed measurements for California. Since the displacement rate estimates are ahead of the time of the values of the first station coordinates and by days, each gap in the time series of the station coordinates increases the number of missing values in the time series of velocities by days. With a large number of gaps, the number of missing velocity values can significantly exceed the number of missing coordinate values. To limit the number of missed velocity values, we linearly interpolated the coordinate values in the gaps less than or equal to . For gaps of more than days, we ended the calculation of the speed at the last value of the station coordinate before the start of the rupture and re-estimated the rates, starting from the first value of the station coordinate after the rupture.
To calculate the daily rates, the interval days was selected. For this interval, the station movement values were comparable to the noise values of the daily measurements. For 30-day intervals, there were 23,119 gaps in each coordinate of the area in Japan, which was 97.62% of all gaps in the time series, and 50,537 blanks in the measurements (30.04%). For California, there were 27,990 measurement gaps (93.37%) and 88,387 blank measurements (24.75%) over a 30-day period for each coordinate. At the same time, the number of missing speed values in each of the W–E and N–S directions increased for Japan by (23,682 − 23,119) , and for California by (29,977 − 27,990) × 30 = 59,610 (16.69%).
The first stage was completed by calculating the spatio-temporal fields of the rate components
and
in the W–E and N–S directions. The fields were presented in the grid
day. The calculation of the fields was carried out using an interpolation technique known as inverse distance weighting. During interpolation, the gaps in the values of the time series were not filled, but they were taken into account as the absence of the receiving station. The values of the fields
and
at the grid points for each time slice of the field of the velocity component W–E were calculated by the formula:
where
is the value of the field of the W–E strain rate component at the grid node
n at the moment
t,
K is the maximum number of stations closest to the node
n in the circle of radius
, the values of which were used for interpolation,
is the value of the W–E strain rate component for the station
, at the time
t,
is the distance from the
k-th station to the grid node
n, and
p is the degree that determines the dependence of the station weight on its distance to the grid node. The interpolation parameters were
,
km, and
. If
, then
. The calculations of the field of the N–S strain rate components were similar.
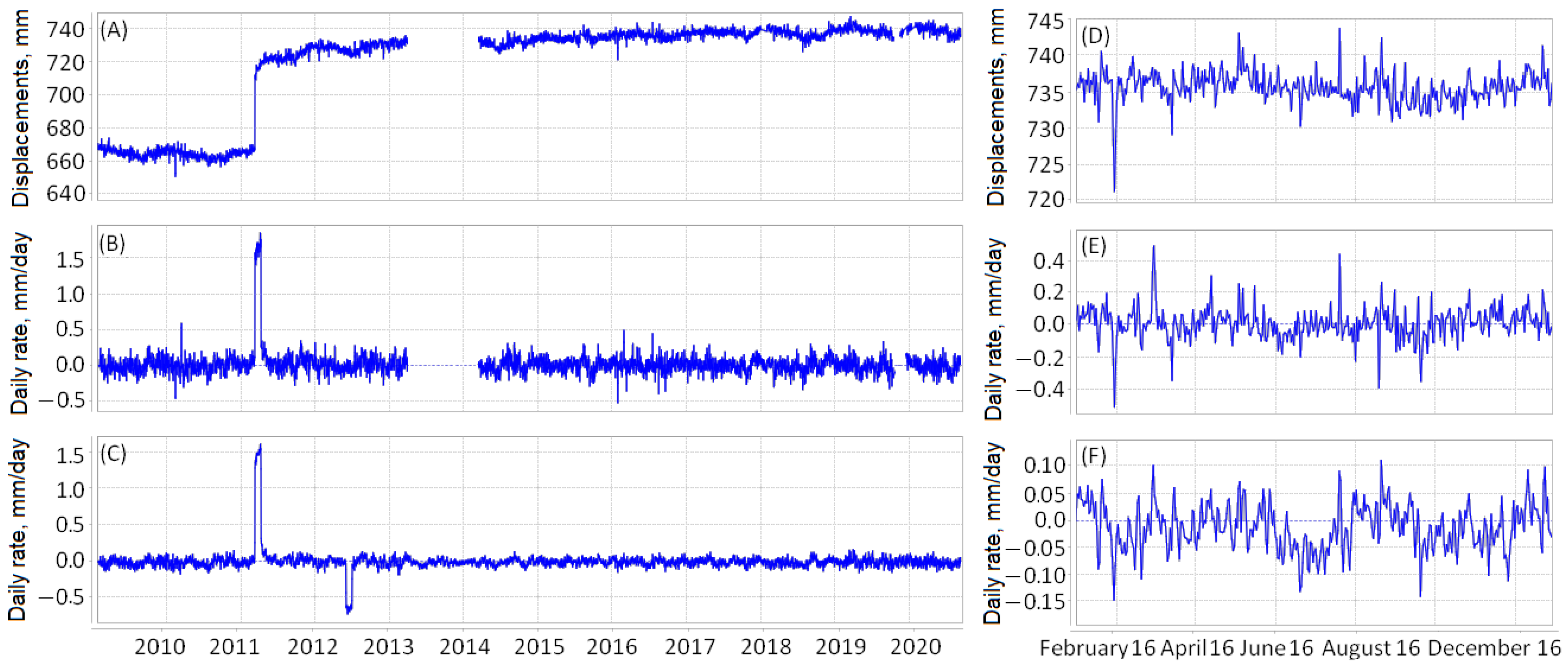
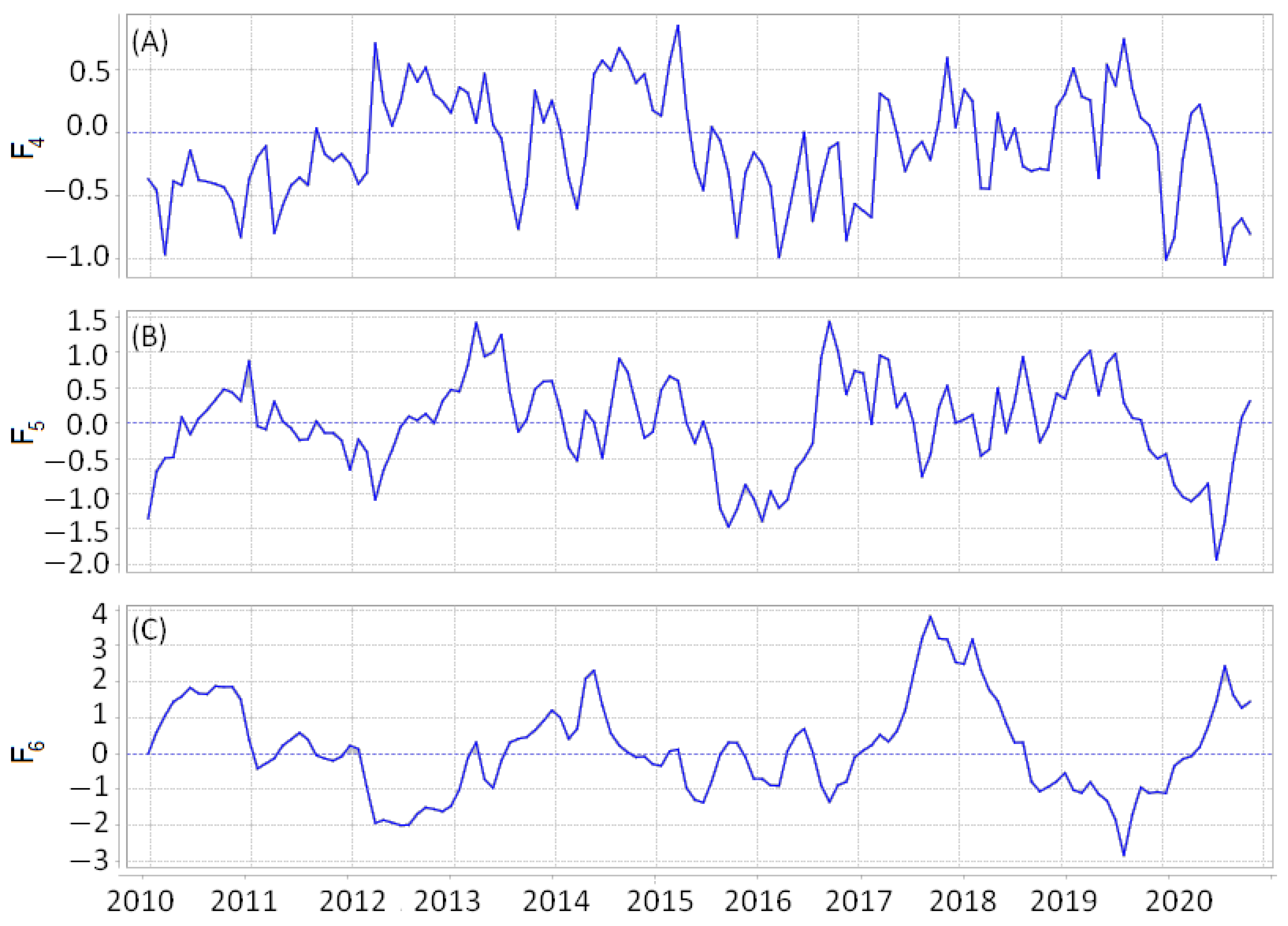
Figure 4 and
Figure 5 show an example of the time series at the point with coordinates
N and
E for Japan: (A) coordinates of the receiving station, (B) daily velocities, and (C) values of the field components
and
. The time series in the figure on the left refer to the interval 1 January 2009–26 July 2020, and on the right, to the interval 1 January 2016–14 December 2016. The jump in the time series of the station coordinates and the ejection of the velocity series was caused by the Tohoku earthquake (11 April 2011). It can be seen that the gaps in the values of the coordinates of the stations cause discontinuities in the time series of the daily rates of the displacement of the Earth’s surface. However, when calculating
and
strain rate fields, the missing velocity values were filled in by interpolating data from other GPS receiving stations.
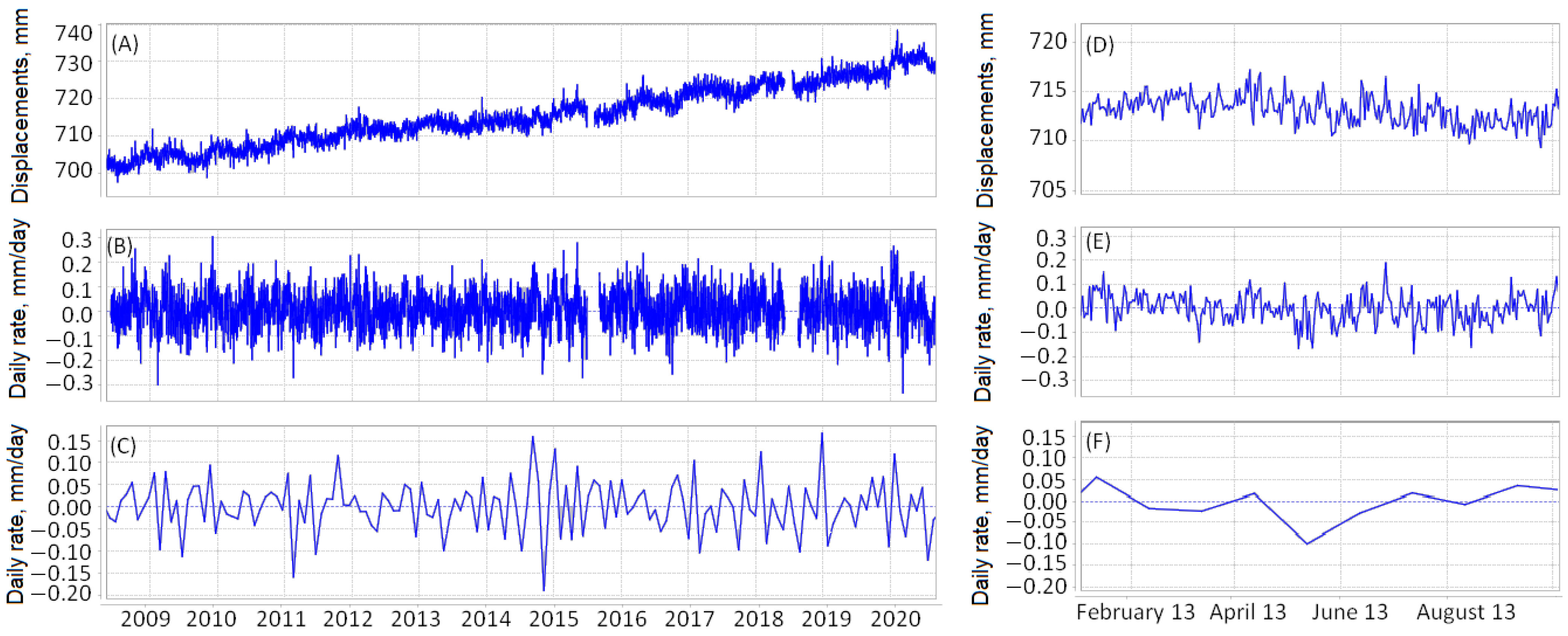
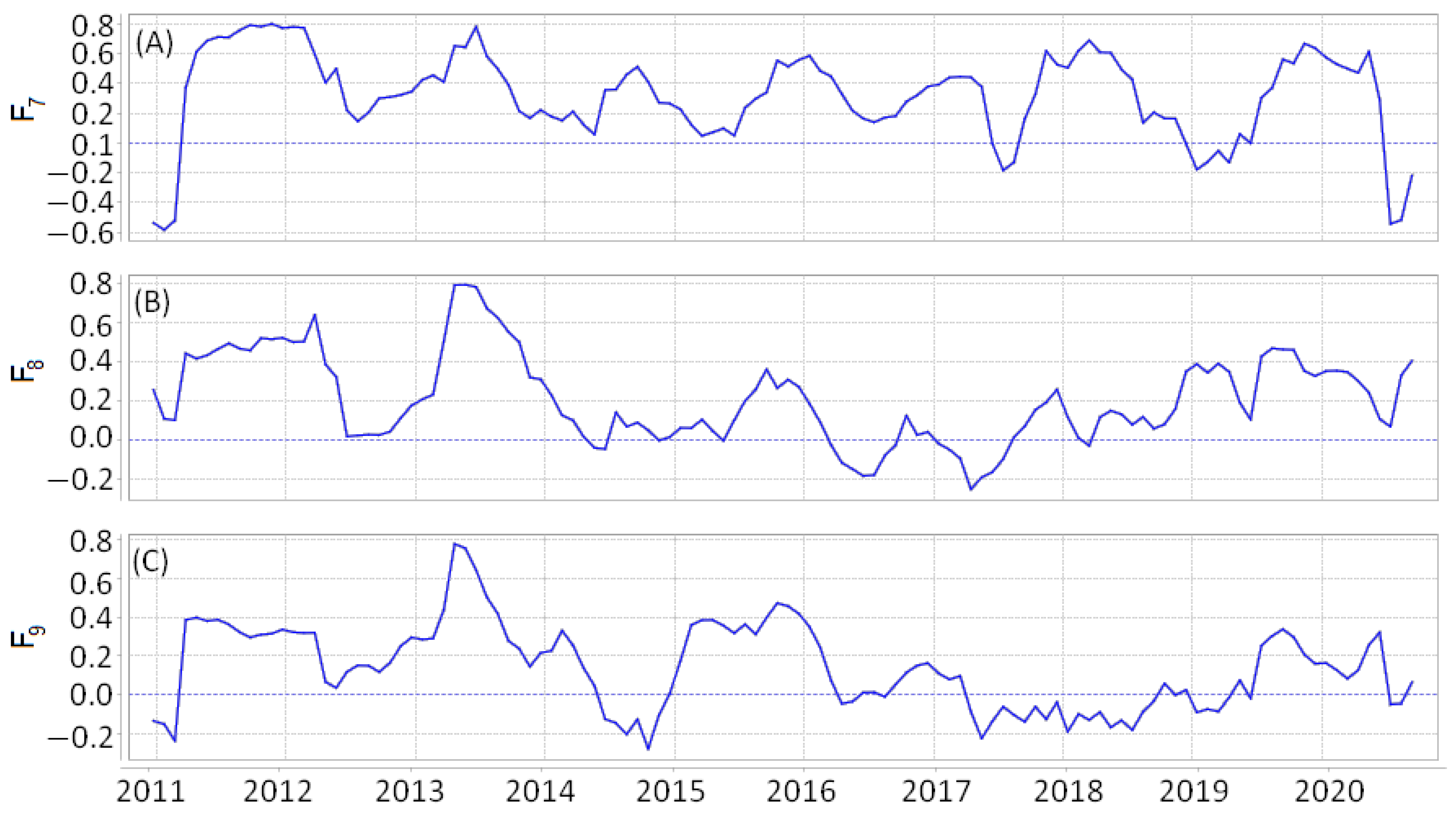
Figure 6 and
Figure 7 show similar example of the time series at the point with coordinates
N and
W for California for the intervals 1 January 2008–14 November 2020 and 1 January 2013–1 October 2013.
3.3.2. Spatio-Temporal Fields of Features
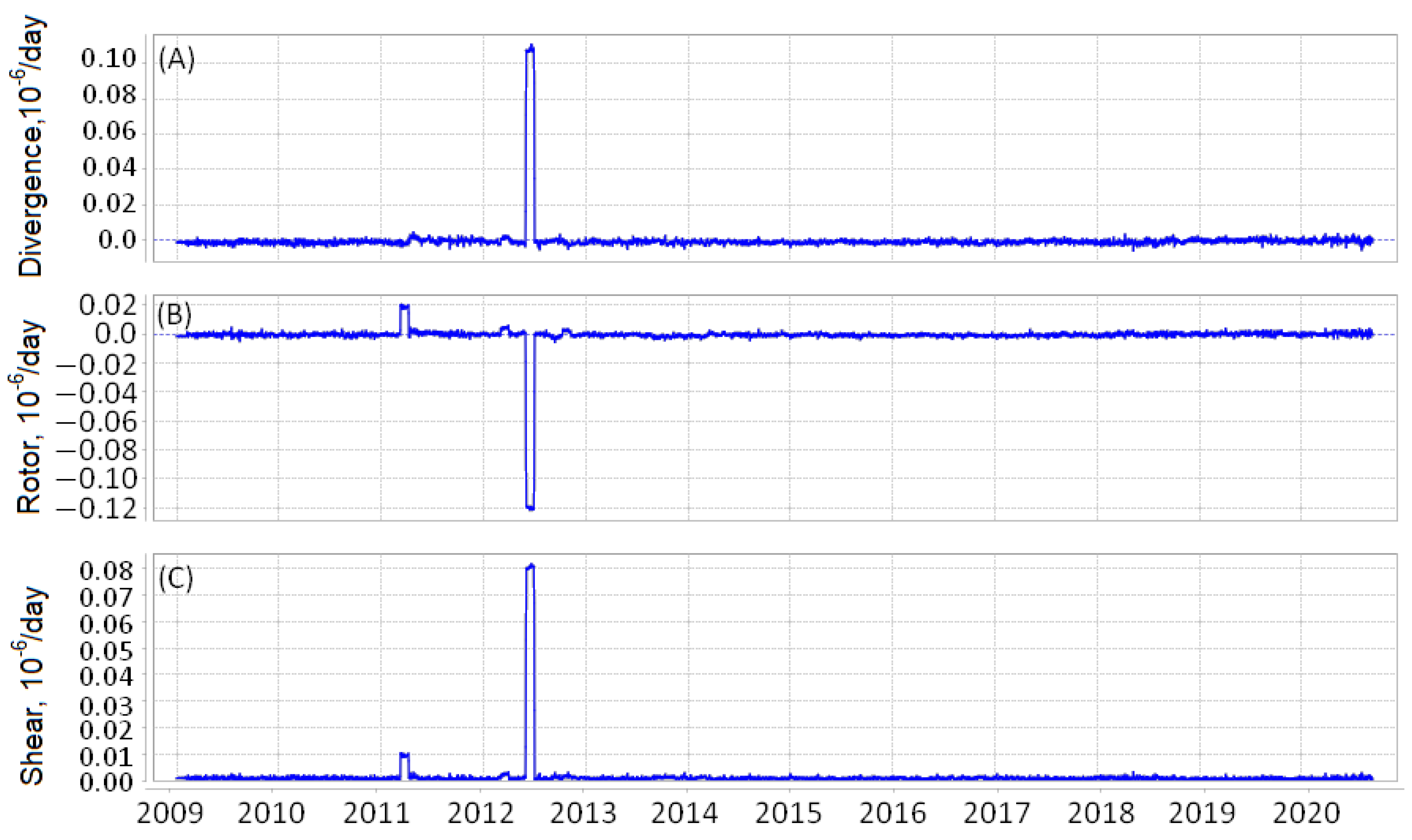
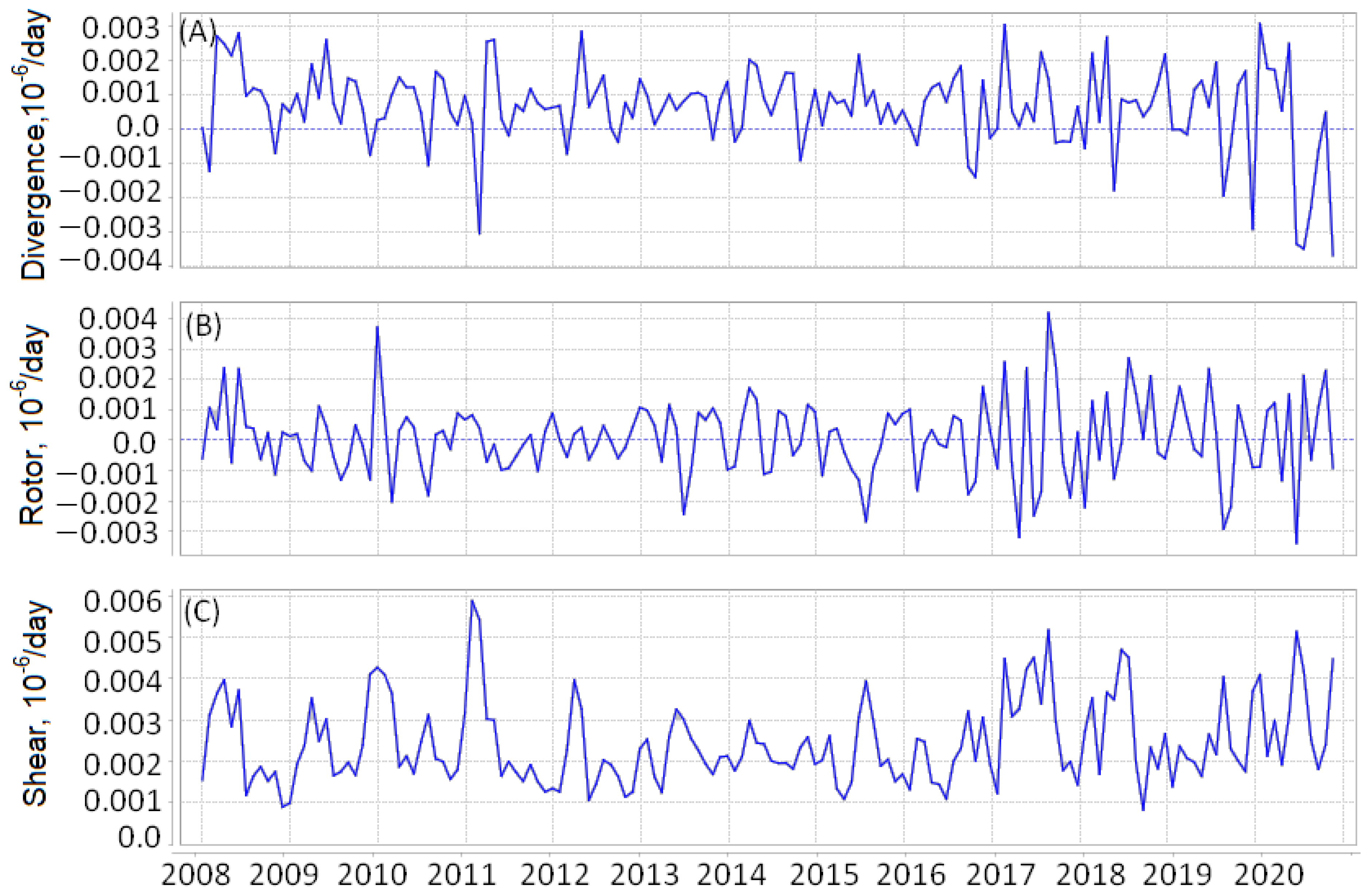
We assume that strong earthquakes are preceded by spatio-temporal anomalous changes in the regime of various deformations of the Earth’s surface. Therefore, we looked for fields containing information about the anomalous values of the change in the deformation mode. The basis of the considered fields of features was the following invariants of the strain rate fields.
is the field of divergence of the strain rates:
The maximum and minimum values of the divergence field refer to places where there is a relative contraction or expansion of the size of a small horizontal area.
is the field of rotor of the strain rates:
The field values determine the direction and intensity of the field twisting around the vertical axis.
is the field of shear of the strain rates:
The fields of features , , and represent changes in the fields of the strain rate invariants over time. They are equal to the ratios of the mean values of the invariants in two consecutive intervals to the standard deviation of this difference. The values of the fields are converted into the grid days.
The value of the field
at time
t is equal to the ratio of the difference
between the mean values of the divergence in two consecutive intervals, namely,
and
, to the standard deviation of this difference
,
days.
where
is calculated from the values of field
at the interval
,
is calculated at the interval
.
The values of field
are calculated similarly to the values of field
,
The values of field
are calculated similarly to the values of field
,
Fields , , and represent spatial correlations of strain rate changes in a sliding window of km. With this window size, the correlation coefficients are estimated in approximately 70–80 grid points of the fields.
is the field of spatial correlations in fields and .
is the field of spatial correlations in fields and .
is the field of spatial correlations in fields and .
Correlation fields , , and carry information about the spatial relationship between the values of the change in the rate of different pairs of deformation types. The minimum or maximum fields of the correlation fields combine this information.
To combine information on the spatial relationship between the values of the change in the rate of different pairs of deformation types, you can use the field of maximum or minimum values of the correlation fields
,
, and
. This operation can be interpreted in terms of fuzzy logic [
46]. For Japan, the most successful prediction of target earthquakes was obtained using the
field:
is the field of minimum values of the fields
and
:
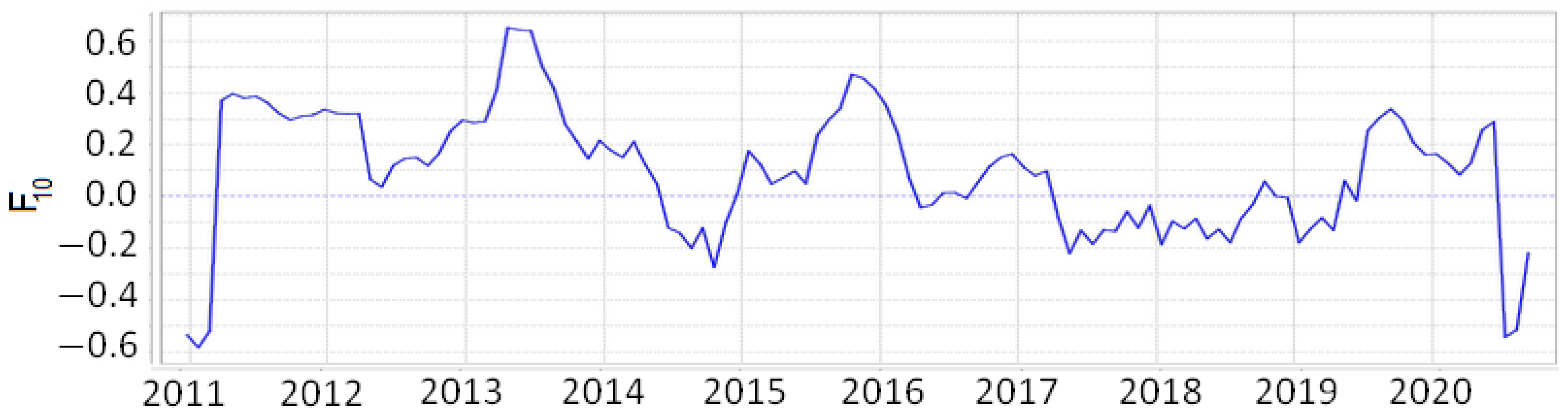
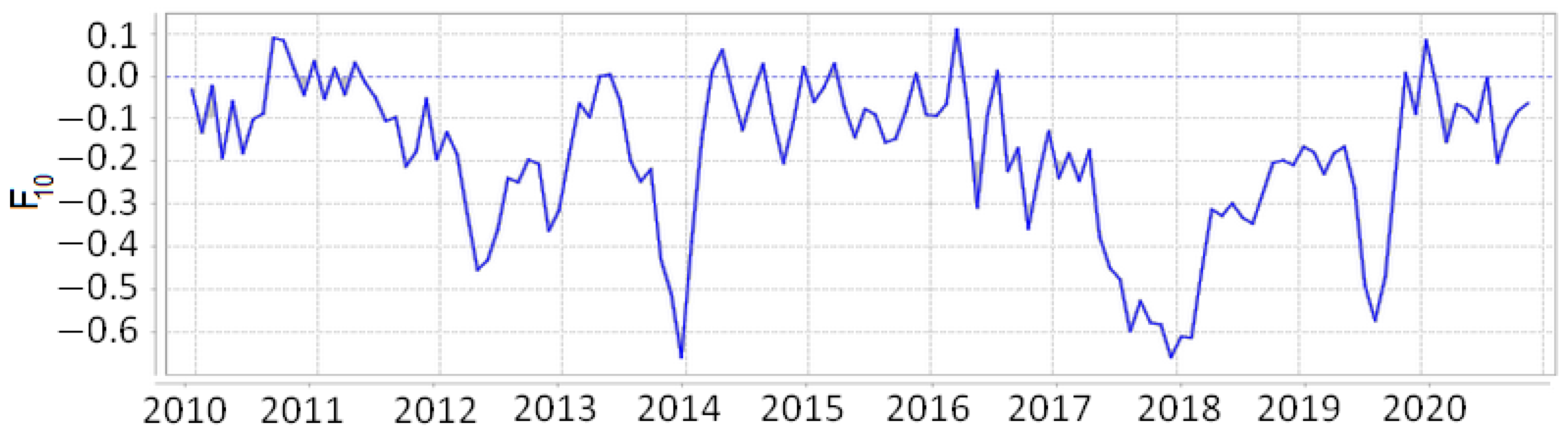
The time series of field
at point
N and
E in Japan and
N and
W in California are shown in
Figure 14 and
Figure 15.
3.4. Seismological Data Preprocessing
Seismological data for Japan and California were taken from the Japan Meteorological Agency earthquake catalogs [
47,
48] and the National Earthquake Information Center (NEIC) [
49] at intervals 02 June 2002–26 July 2020 and 1 January 1995–20 December 2020, represented by earthquakes with a magnitude of
and a hypocenter depth of
km.
is the 3D field of the density of earthquake epicenters.
is the 3D field of the mean earthquake magnitude.
is the 3D field of the negative temporal anomalies of the density of earthquake epicenters.
is the 3D field of the positive temporal anomalies of the density of earthquake epicenters.
is the 3D field of the negative temporal anomalies of the mean earthquake magnitude.
is the 3D field of the positive temporal anomalies of the mean earthquake magnitude.
is the 2D field of the density of earthquake epicenters: Kernel smoothing with the parameter km in the interval from the beginning of the analysis to the start of training.
is the 3D field of quantiles of the background density of earthquake epicenters, calculated using the interval from the beginning of the analysis to the start of training, which corresponds to the density values of earthquake epicenters at the current time.
The estimation of 3D fields and was performed with the method of local kernel regression. The kernel function for the q-th earthquake has the form , where and are the distance and time interval between the q-th epicenter of the earthquake and the node of the 3D grid of the field, , km, days for and R = 100 km, and T = 730 days for . The field was calculated with the kernel function . The parameters for evaluating the fields, the radii R, and the interval T were chosen empirically, considering the step of the network of fields and the approximate number of events in the evaluation window. To calculate the fields , , , and , Student’s t-test was used. This t-statistic was determined for each grid node as the ratio of the difference in the average values of the current interval and the background interval to the standard deviation of this difference. Positive values of the t-statistic correspond to an increase in the value on the test interval.
We also analyzed fields similar to the fields , , , and , but with different values of the and intervals.
When predicting from seismological data, the following three fields turned out to be the most informative.
is the field of ratios of the density values of the earthquake epicenters to the values of the quantiles of the density of the epicenters calculated on the interval from the beginning of the analysis to the start of training, which corresponds to the density values of earthquake epicenters at the current time .
is the field of negative anomalies of Student’s t-statistic of the density of earthquake epicenters with the intervals and days.
is the field of negative anomalies of Student’s t-statistic of the mean earthquake magnitude with the intervals and days.
For Japan, the most informative were the fields
and
. Both of them previously proved to be the most effective in predicting earthquakes and their magnitudes in Kamchatka and the Aegean region [
50]. The anomalous values of the
field correspond to areas of the seismic process in which the density values of earthquake epicenters are quite high but significantly less than the average values of the density of epicenters in the interval from the beginning of the analysis to the start of training. The anomalous values of the
field correspond to the spatio-temporal regions of the seismic process, in which the average values of the density of earthquake epicenters in the
interval are significantly lower than the average field values in the
interval. These changes highlight anomalous areas in which a quiescence sets in after the activation of the seismic process. The time series of the
field simulates the preparation of strong earthquakes proposed by the IPE model (named after the Institute of Physics of the Earth) proposed in [
51]. For California, the most informative were the fields
and
.
3.5. Earthquake Forecast
The initial training intervals started for Japan and California on 1 January 2011 and 23 December 2009 and ended before the next forecast, starting on 20 November 2015 and 19 January 2013, respectively. The testing intervals were 20 November 2015–10 September 2020 for Japan and 19 January 2013–14 November 2020 for California. The areas of analysis at the testing intervals contained 14 epicenters of target earthquakes in Japan with a magnitude of
and 12 epicenters of target earthquakes in California with a magnitude of
. The alarm cylinder parameters were the cylinder radius
km and its generatrix
days for Japan and
km and its generatrix
days for California. The best forecast of target earthquakes according to GPS data for Japan was obtained from the
field and for California from the
and
fields.
Table 1 and
Table 2 show the forecast results for each target event in Japan and California. The forecast is considered successful if the epicenter of the target event falls into the alarm zone with the alarm volume value
. The final forecast results are summarized in
Table 3 and
Table 4. It can be seen that the forecast probabilities from GPS data with an alarm volume
are significantly higher than the forecast probability for a random field and a spatial density field of earthquake epicenters
.
Let us consider the prediction of target earthquakes based on feature fields calculated from the earthquake catalog. The alarm fields for Japan and California were calculated in the same grid and with the same parameters of the alarm cylinders as for the forecasted results from the GPS fields.
Two fields of features were selected for Japan: Field
and field
. The results of the forecasting based on seismological feature fields
and
, as well as based on fields
,
, and
are shown in
Table 5.
Table 6 shows the probabilities of a successful prediction for several alarm volumes. From
Table 5 and
Table 6, it can be seen that the forecast results for fields
,
, and
practically do not differ from the forecast for fields
and
. Fields
and
proved to be the most informative for predicting earthquakes in California. The results of the forecasting and the probabilities of a successful prediction based on seismological feature fields
and
, as well as based on fields
,
,
, and
are shown in
Table 7 and
Table 8.
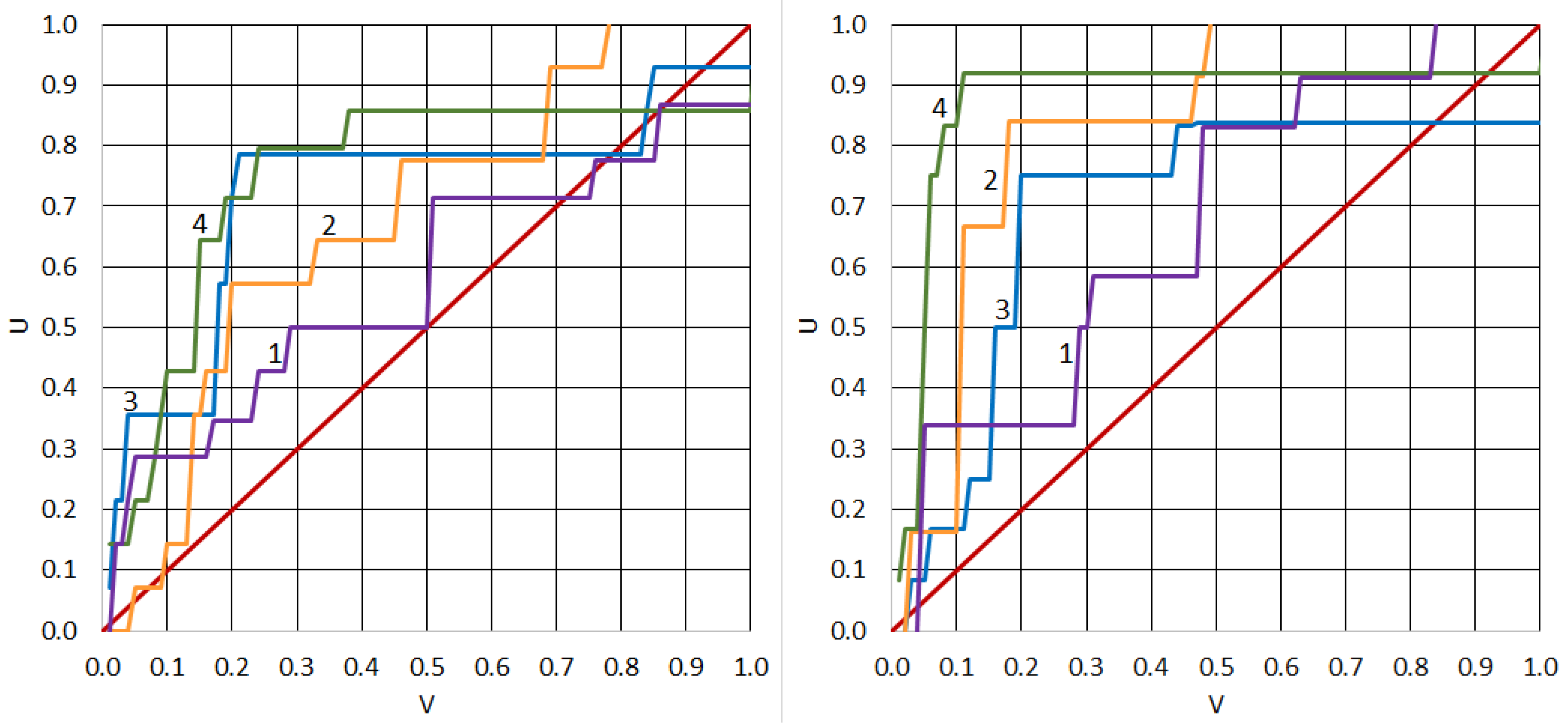
Figure 16 shows the dependencies
obtained for Japan and for California from the GPS and seismological fields.
4. Discussion
The results of forecasting earthquakes in Japan and California based on the data of space geodesy were considered herein. The criterion for the effectiveness of forecasting according to GPS data was the probability of successful forecasting of strong earthquakes, obtained by the method of the minimum area of alarm. We can see from
Figure 16 that for alarm volume
, the probability of forecasting target earthquakes according to GPS data was significantly higher than the probability of forecast based on random data and forecast based on the field of spatial density of earthquake epicenters. However, the
dependencies, the plots of which are shown in
Figure 16, were found for a small number of target events. More convincing results about the effectiveness of GPS data in predicting strong earthquakes can be obtained using statistical hypothesis testing models. To do this, we compared the results of the prediction of target earthquakes using GPS data with the forecast results using a random field. If the target events were independent, we used the binomial distribution statistics.
Considering the results of earthquake forecasts in Japan. The test data contained 14 events.
Table 1 shows that events 2, 3, and 4 were dependent. We will consider them as one event. Then, our sample consisted of
independent target events.
Table 1 shows that
events were predicted in a sample of 12 events according to the GPS data. For the forecast, we chose the alarm volume
. We interpreted the value of the alarm volume
V as the probability
p of a successful prediction of events with a purely random distribution of alarm locations with a total alarm volume
V in the analysis area. The observed frequency of a successful forecast
exceeded the probability
of successful forecast for a random field. Thus, the question arises: Can the observed difference between these two values be explained by the random nature of the sample? In terms of hypothesis testing, this means that the null hypothesis
requires testing against the right-sided alternative
. Taking a binomial distribution model with
number of trials and a
probability of a successful event, we found from the binomial distribution tables that the probability of obtaining
or more successful predictions was 0.0194. Since this value is significantly less than the generally accepted significance levels of 0.05, the null hypothesis was rejected.
A number of transformations were required to calculate feature fields based on GPS data. These included interpolation of time series at relatively small time intervals of discontinuity in the operation of GPS receiving stations, calculation of time series of components of the rates of horizontal displacements of stations, calculation of spatio-temporal fields of components of the rate of the Earth’s surface deformations, calculation of fields of invariants of velocities and fields of variation of invariants of rates in time, calculation of spatial correlation fields, and calculation of minimum and maximum values of correlations. A number of parameters were used in the algorithms for calculating these transformations: the time interval for estimating the daily displacement rates, the sizes of the spatial and temporal smoothing windows, and the windows for estimating the spatial correlation coefficients, as well as the time intervals for calculating the field of invariants of the strain rates. The GPS fields for Japan and California were calculated with the same parameters. The choice of transformation parameters, as well as the choice of the feature fields themselves, requires special study. In this work, such a study was not carried out. The types of transformations of the initial data into the fields of features and transformation parameters were selected based on qualitative considerations about the methods of cleaning signals from noise, recovering missing values, and disclosing information about the spatio-temporal properties of geodynamic processes.
The best forecast for Japan was given by the field, and for California was given by the and fields. Field carries information about the consistency of the processes of changing the rates of various types of deformations in space. Fields and carry information about the positive values of the change in the mean values of the divergence and shift of the strain rate with an interval of 361 days. When simulating earthquake predictions, we analyzed several types of such fields. A number of fields containing information on the change in strain rate invariants provided similar results for a successful prediction. We considered the field for Japan and the fields and for California to be more efficient, since, for them, the probability of a successful forecast practically did not change with small changes in the parameters of the alarm field: With the radius of the signal cylinder, R changed from 14 to 18 km when its generatrix T changed from 61 to 91 days.
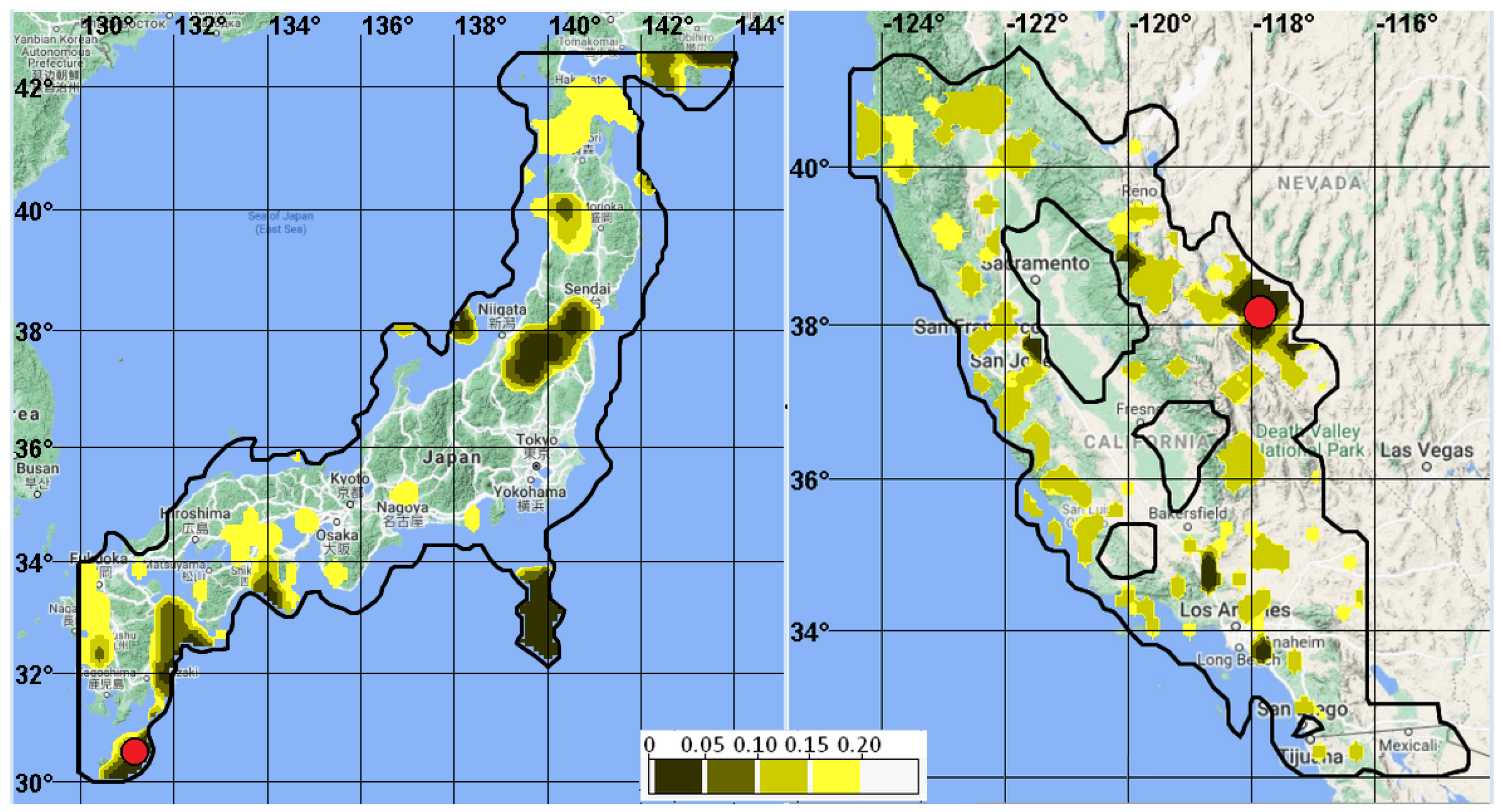
Figure 17 shows maps of alarm zones when forecasting earthquakes using GPS data. Alarm zones highlight subdomains in which the values of the fields
for Japan,
and
for California take on anomalous values. Shaded alarm zones indicate the volume of the alarm. The level of shading of the alarm zones shows the value of the alarm volume. On alarm zone maps, these values are approximately equal to fractions of the alarm area relative to the analysis area. On the maps, target events fell into subdomains: for Japan, the proportion of the alarm area is about 15%, and for California, about 3%.
In the modeling, we used the experience of our previous studies to assess the relationship between data on horizontal displacements of the Earth’s surface with seismicity [
19,
52] and on the application of the method of the minimum area of alarm to earthquake prediction [
50].
5. Conclusions
A number of seismically active regions are equipped with a rather dense network of GPS receiving stations that track the movements of the Earth’s surface. In our study, we tried to answer two questions: (1) Are space geodesy data effective for systematic earthquake prediction?; (2) is the earthquake forecast improved if seismological data are supplemented with space geodesy data? Obviously, the answers to these questions depend on the spatial density of the network of receiving stations, on the parameters of the time series of GPS measurements, on the method of preprocessing of GPS data, and on the method for forecasting earthquakes.
The results in this article were obtained from data from Japan and California. Space geodesy data are represented by daily time series of horizontal displacements of the Earth’s surface. The heart of the processing of GPS time series is occupied by the calculation of spatio-temporal fields of changes in the invariants of the seismic strain rate. To predict earthquakes, we used our developed machine learning method that we called the method of the minimum area of alarm. For Japan, it was shown that with an alarm volume of
, the probability of forecasting earthquakes with magnitudes
according to GPS data was statistically significantly higher than a forecast based on random data. It can be seen from the tables and
Figure 16 that with the same volume of alarms, the probability of predicting earthquakes with magnitudes of
according to GPS data in California significantly exceeded the probability of forecasting based on random data and spatial density field earthquakes.
Figure 16 also shows that adding GPS data to seismological data increased the probability of predicting an earthquake at an alarm volume of
.
The method of the minimum area of alarm is universal for various types of initial data since, for forecasting, all data are converted into uniform spatial and spatio-temporal grid fields. Modeling earthquake predictions in the regions of Japan and California showed that the anomalous field values that determine the change in the rates of deformations of the Earth’s surface, the change in the characteristics of the seismic regime, and the spatial correlation of these processes quite well distinguish the spatio-temporal areas preceding the appearance of the epicenters of strong earthquakes. Taking into account that this result was obtained for regions that differ significantly in seismotectonic and geodynamic regimes [
53,
54], it can be concluded that fields reflecting anomalous changes in seismotectonic and geodynamic processes are the most informative for predicting earthquakes.
The obtained results require additional verification, since the analysis material was limited by a relatively short observation time, two investigated regions, and a small number of target earthquakes.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}