
A Multiview Semantic Vegetation Index for Robust Estimation of Urban Vegetation Cover


Abstract
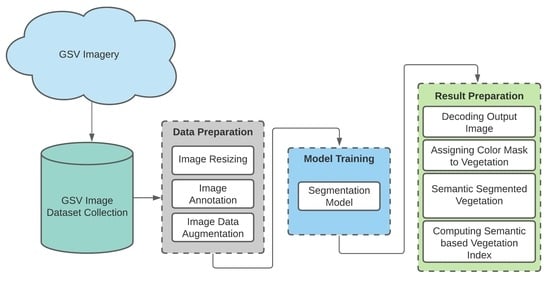
:
1. Introduction
2. Materials and Methods
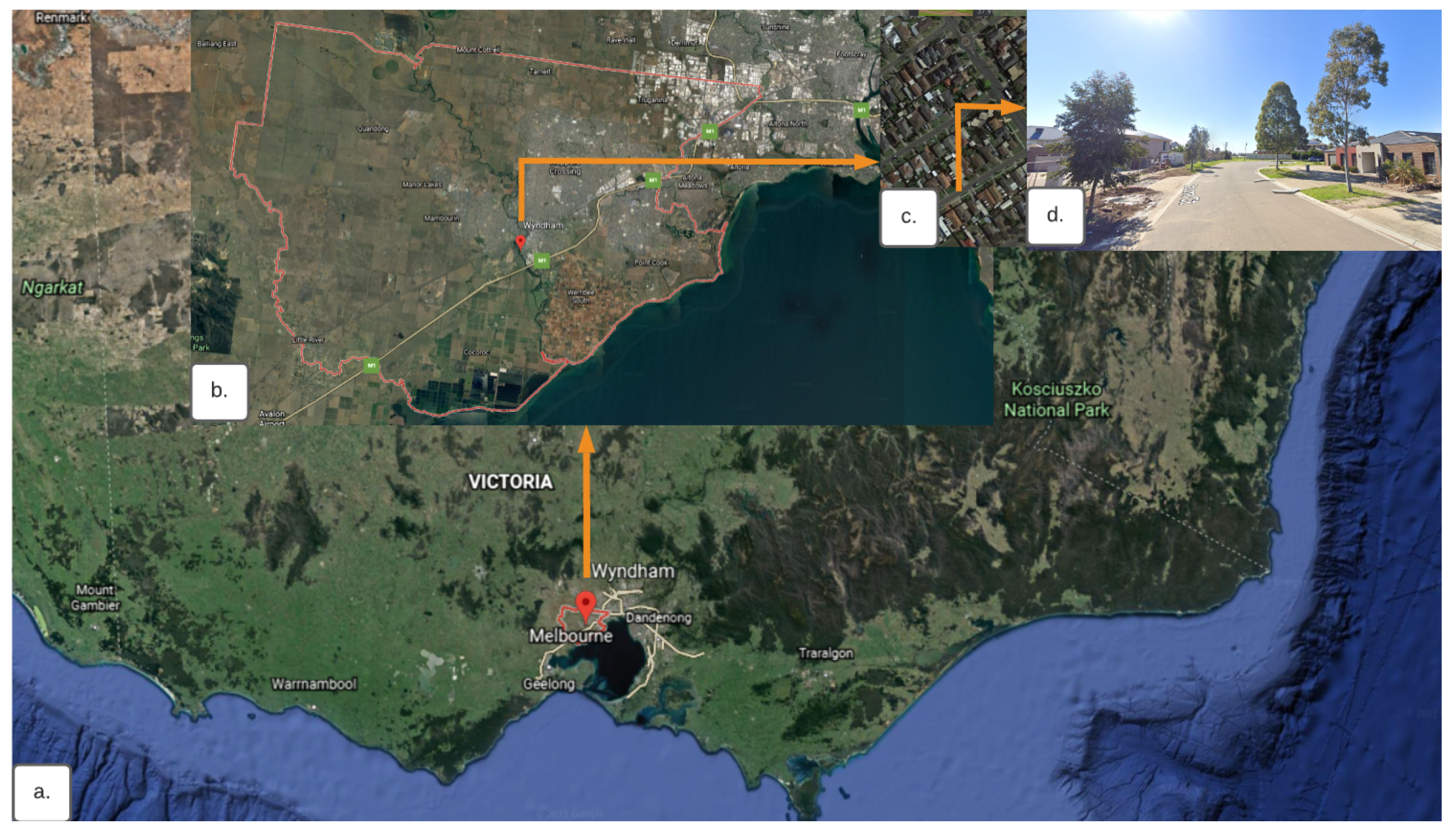
2.1. Study Area
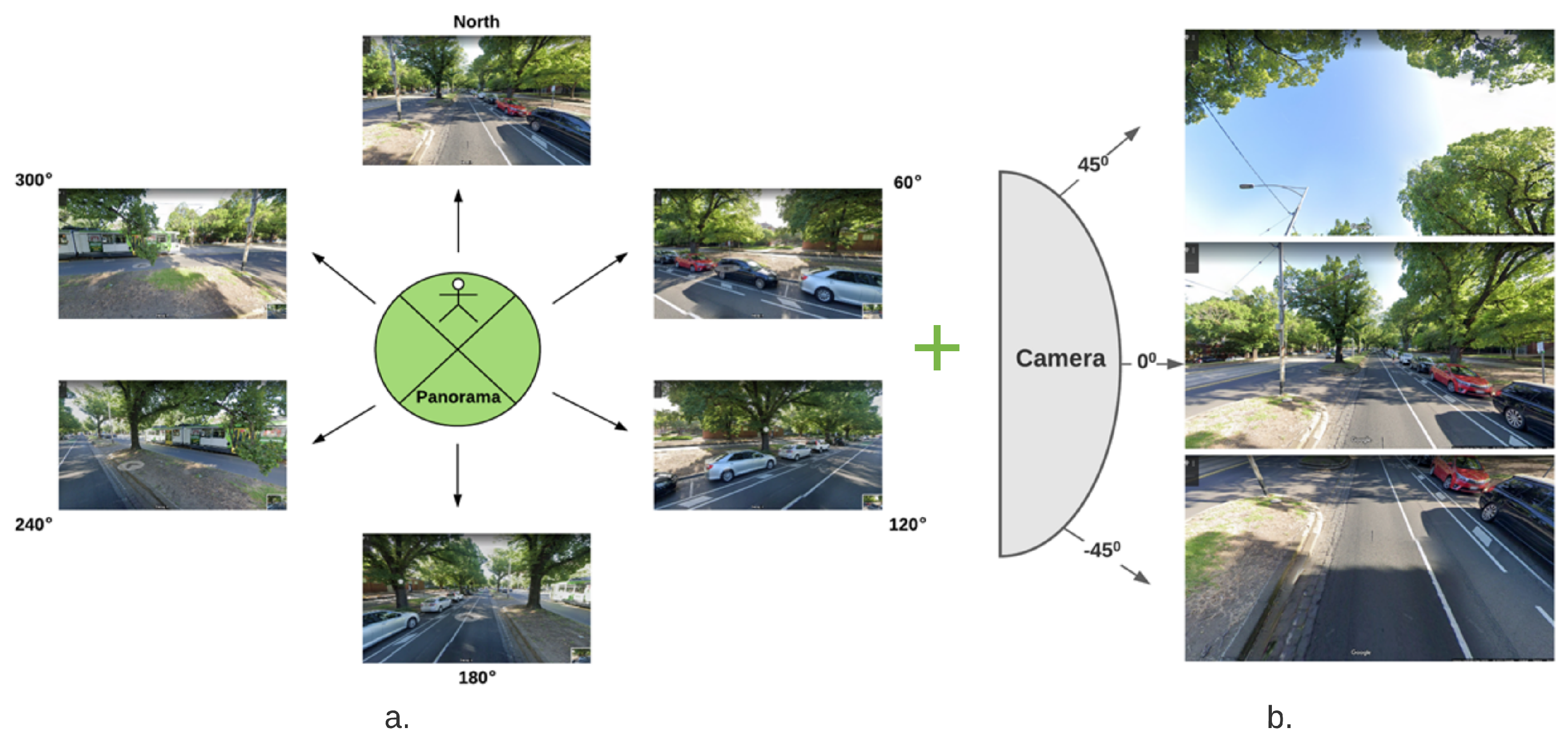
2.2. Input Data Set/Google Street View Image Collection
2.3. Deep Semantic Segmentation
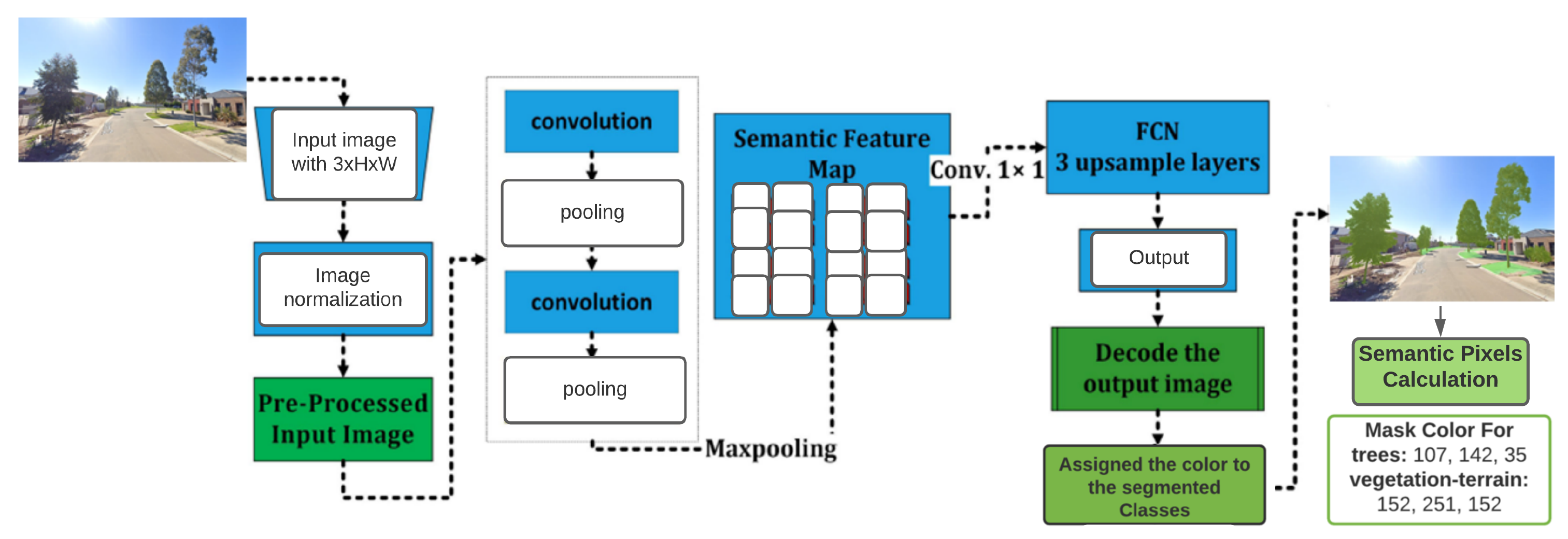
2.3.1. Fully Convolutional Network (FCN)
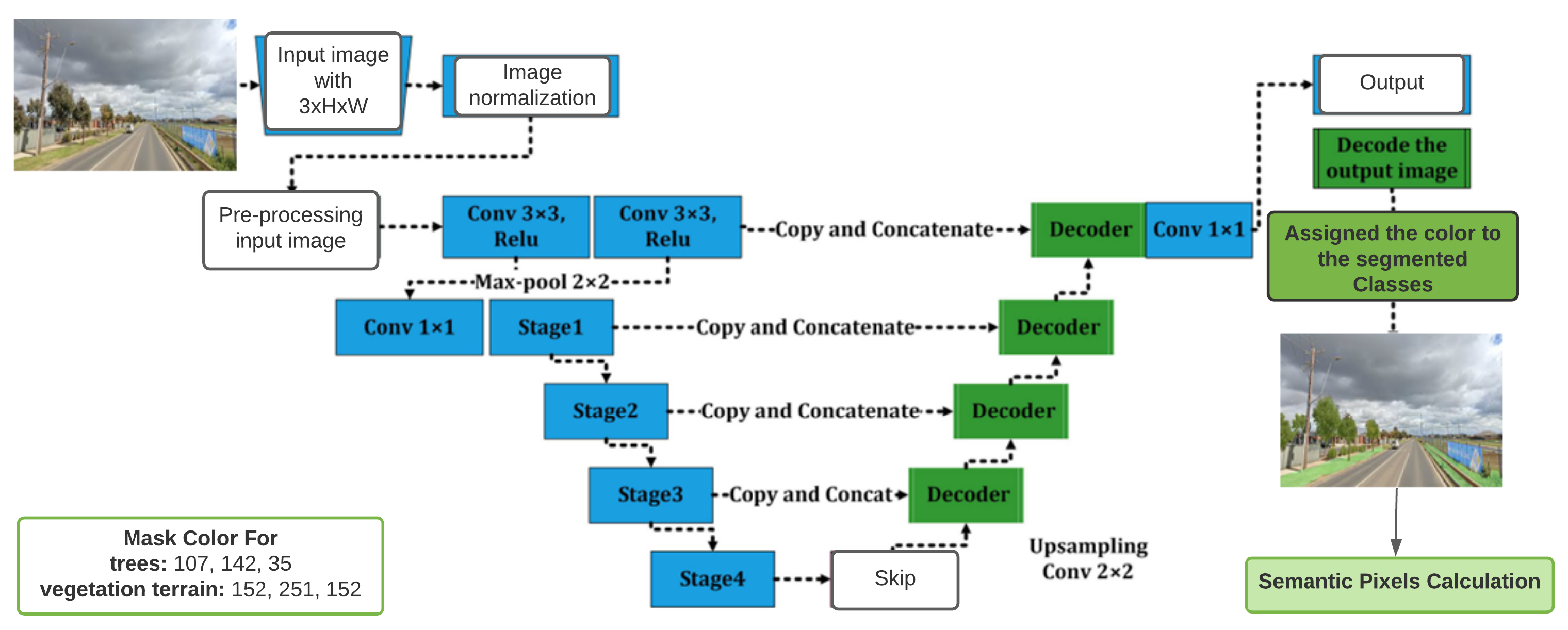
2.3.2. U-Net
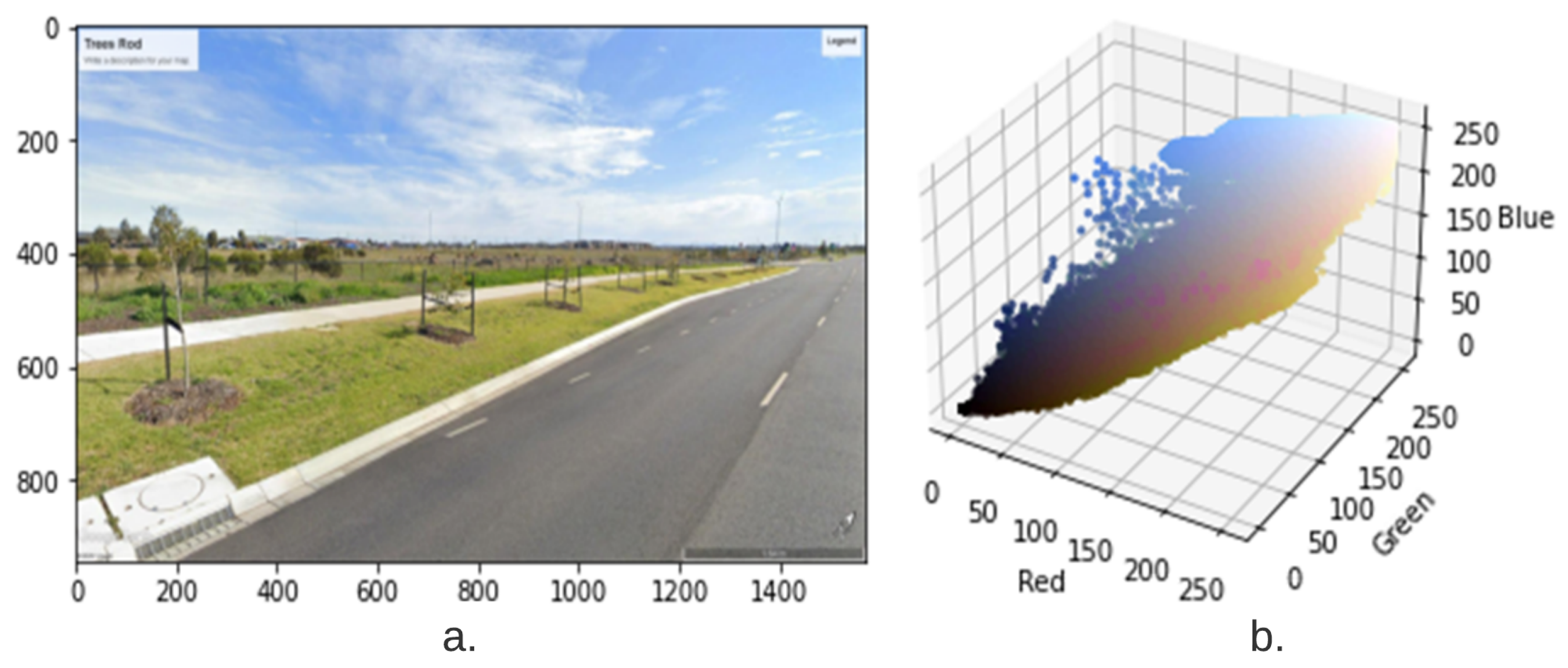
2.4. Vegetation Index Calculation from RGB Images
2.4.1. Green View Index (GVI)
- Step-1:
- First of all, the subtraction of red band from green band generates Diff 1, and subtraction of blue band from green band gives Diff 2.
- Step-2:
- Then the two images Diff 1 and Diff 2 were multiplied to create one Diff image. Normally, the green vegetation has greater reflectance values in the green band than the other two red and blue bands, and hence, the Diff image has positive green vegetation pixels.
- Step-3:
- The pixels that have lower values in the green band as compared to the red and blue bands exhibit negative values in the Diff image
- Step-4:
- As a result, an additional criterion was added stating that pixel values in the green band must be greater than those in the red band.
2.4.2. The Proposed Semantic Vegetation Index (SVI)
3. Results
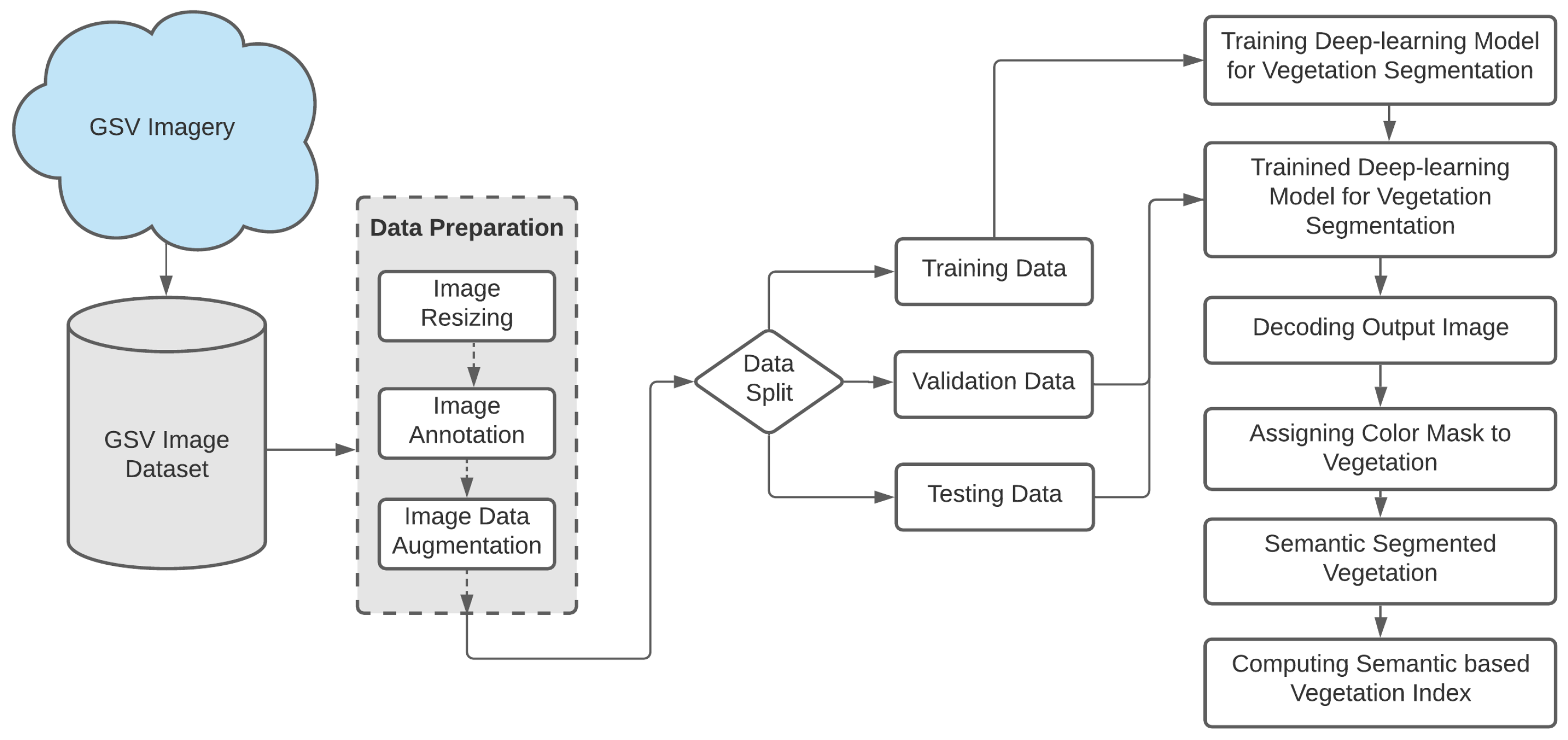
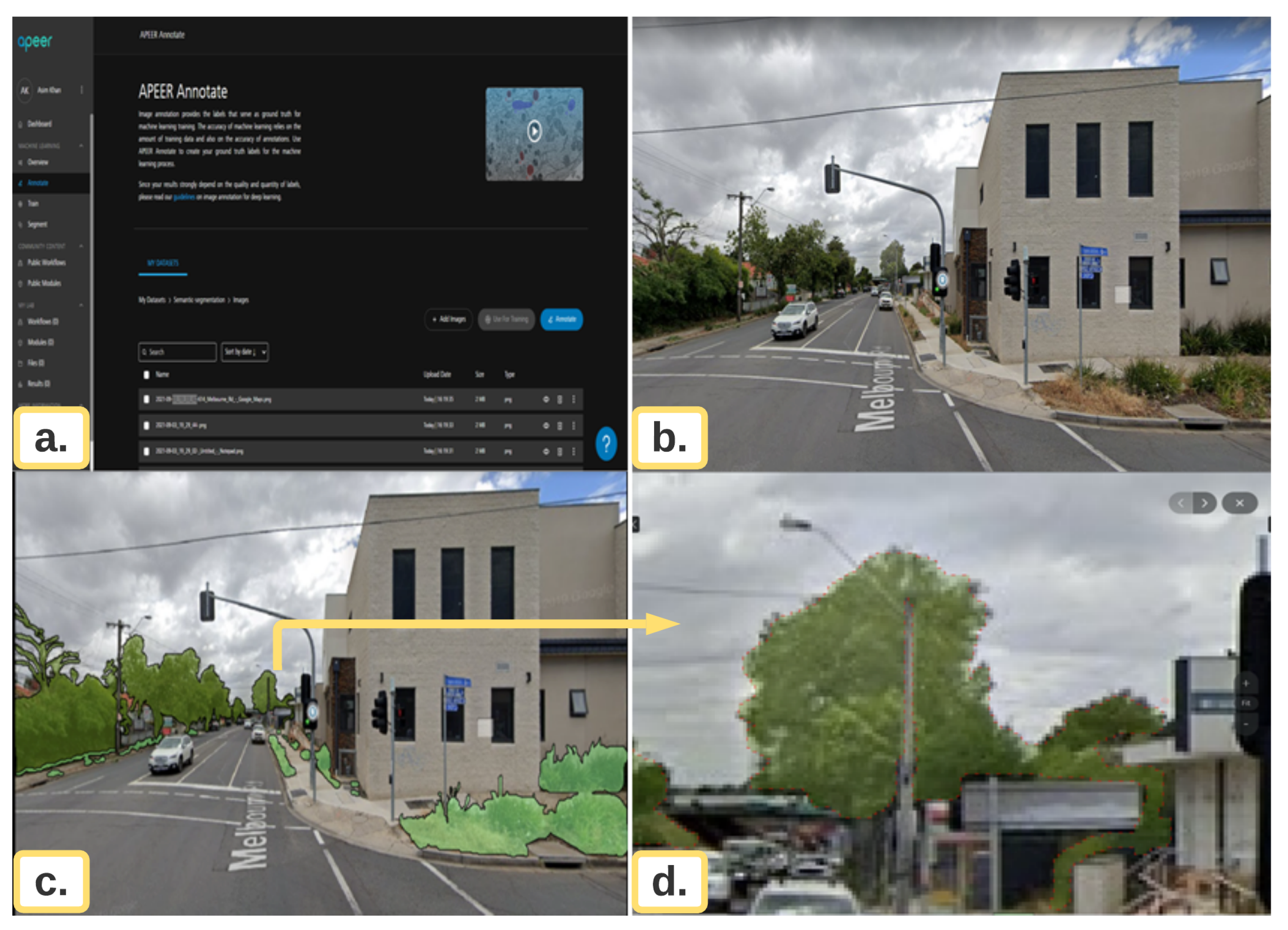
3.1. Preparation and Annotation of Data Set
3.2. Experimental Environment Configuration
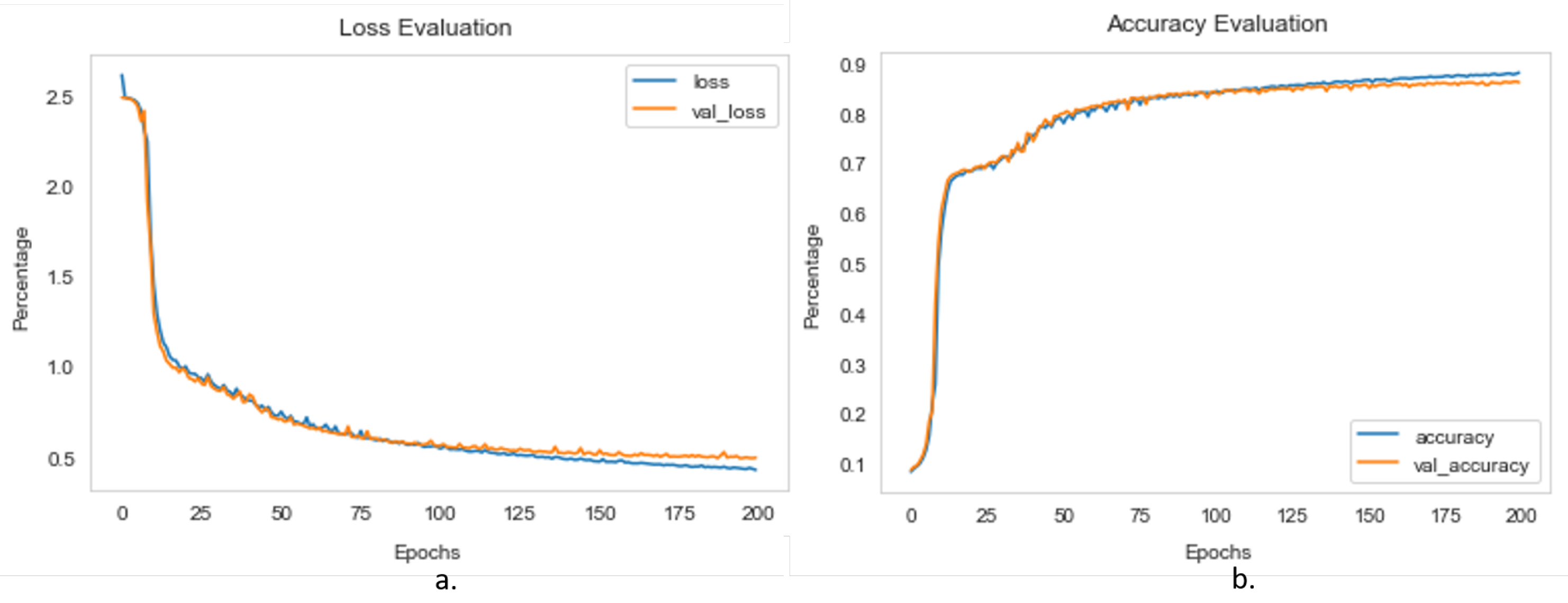
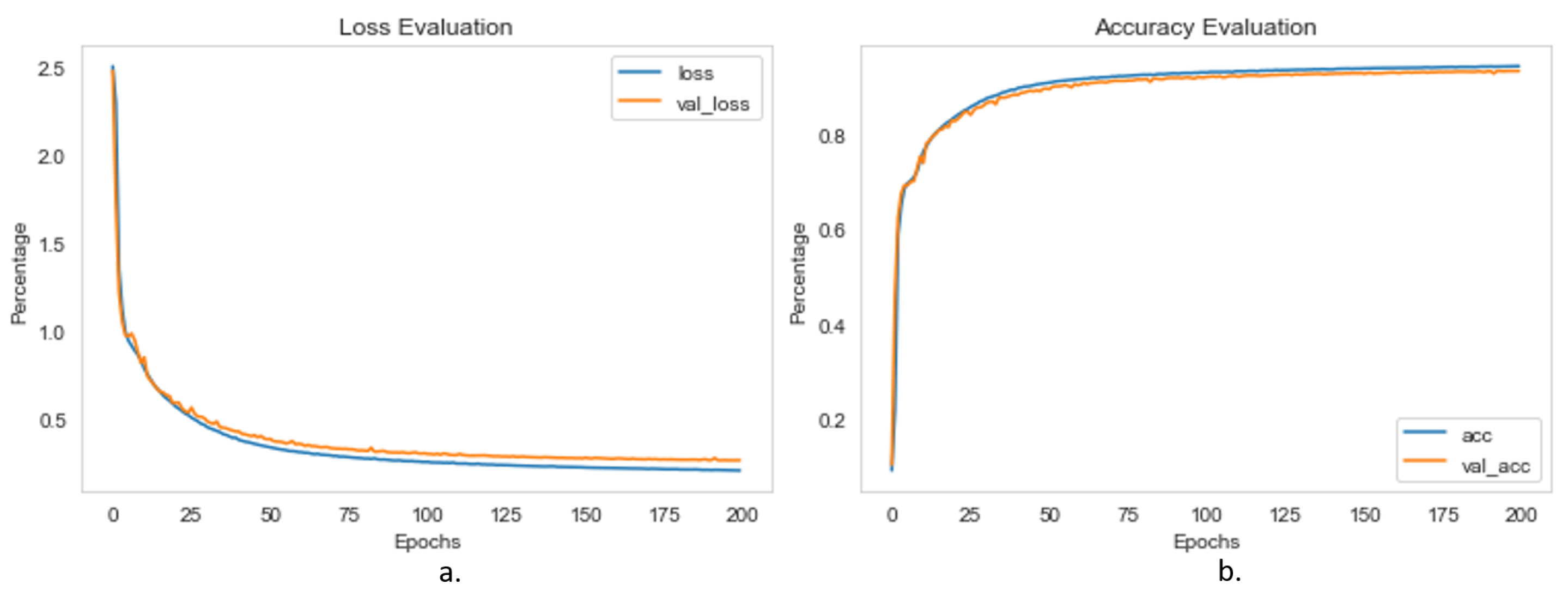
3.3. Training of Deep Semantic Segmentation Models
3.4. Performance Evaluation of Semantic Segmentation Networks
3.4.1. Precision, Recall, and F1-Score
3.4.2. Pixel Accuracy (PA)
3.4.3. Intersection over Union (IoU)
3.4.4. Mean-IoU (mIoU)
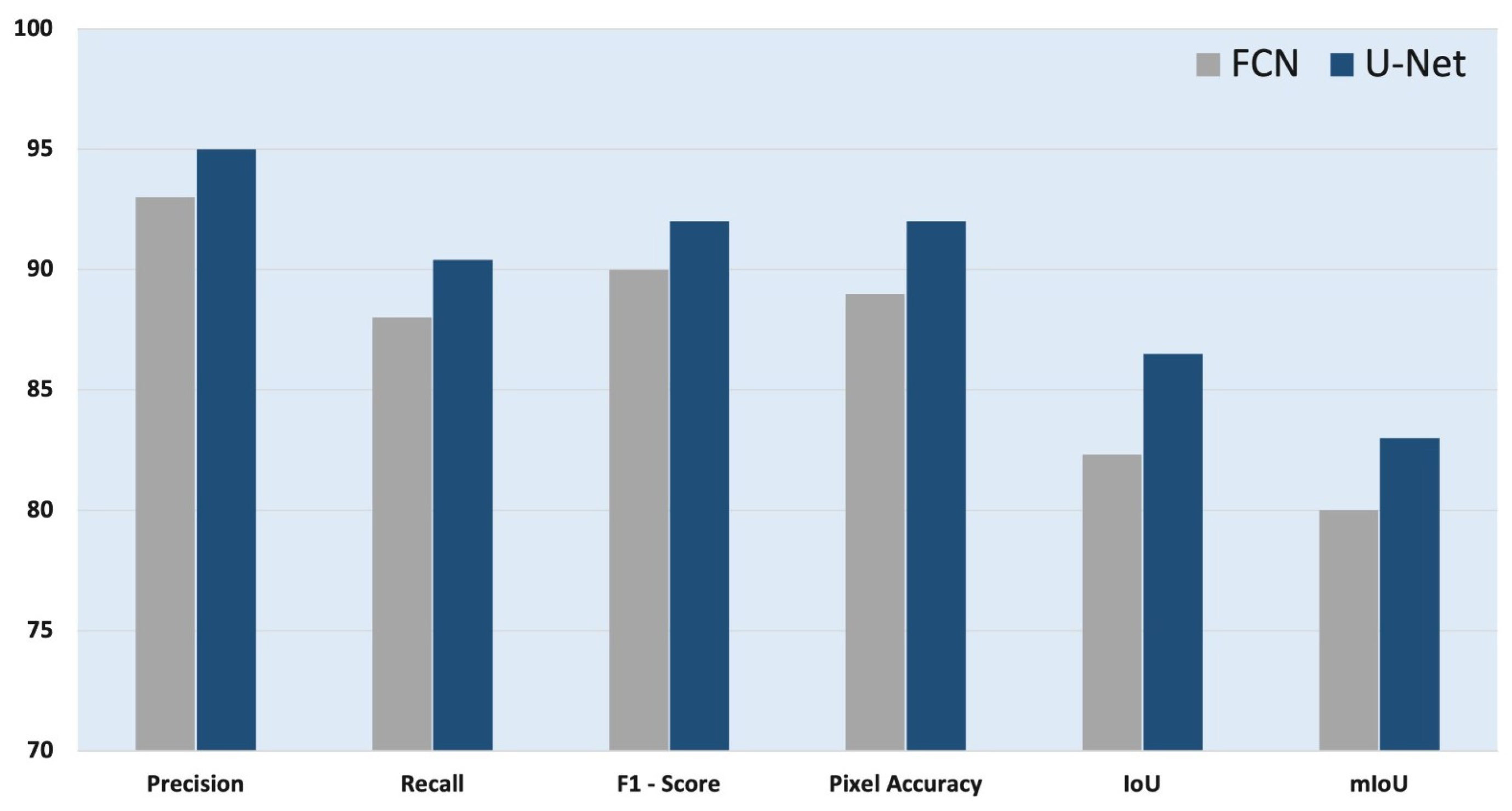
4. Comparative Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, X.P.; Hansen, M.C.; Stehman, S.V.; Potapov, P.V.; Tyukavina, A.; Vermote, E.F.; Townshend, J.R. Global land change from 1982 to 2016. Nature 2018, 560, 639–643. [Google Scholar] [CrossRef] [PubMed]
- Edgeworth, M.; Ellis, E.C.; Gibbard, P.; Neal, C.; Ellis, M. The chronostratigraphic method is unsuitable for determining the start of the Anthropocene. Prog. Phys. Geogr. 2019, 43, 334–344. [Google Scholar] [CrossRef] [Green Version]
- Rosan, T.M.; Aragão, L.E.; Oliveras, I.; Phillips, O.L.; Malhi, Y.; Gloor, E.; Wagner, F.H. Extensive 21st-Century Woody Encroachment in South America’s Savanna. Geophys. Res. Lett. 2019, 46, 6594–6603. [Google Scholar] [CrossRef] [Green Version]
- Wolf, K.L. Business district streetscapes, trees, and consumer response. J. For. 2005, 103, 396–400. [Google Scholar]
- Appleyard, D. Urban trees, urban forests: What do they mean. In Proceedings of the National Urban Forestry Conference, Washington, DC, USA, 13–16 November 1979; pp. 138–155. [Google Scholar]
- Nowak, D.J.; Hoehn, R.; Crane, D.E. Oxygen production by urban trees in the United States. Arboric. Urban For. 2007, 33, 220–226. [Google Scholar]
- Chen, X.L.; Zhao, H.M.; Li, P.X.; Yin, Z.Y. Remote sensing image-based analysis of the relationship between urban heat island and land use/cover changes. Remote Sens. Environ. 2006, 104, 133–146. [Google Scholar] [CrossRef]
- Onishi, A.; Cao, X.; Ito, T.; Shi, F.; Imura, H. Evaluating the potential for urban heat-island mitigation by greening parking lots. Urban For. Urban Green. 2010, 9, 323–332. [Google Scholar] [CrossRef]
- Camacho-Cervantes, M.; Schondube, J.E.; Castillo, A.; MacGregor-Fors, I. How do people perceive urban trees? Assessing likes and dislikes in relation to the trees of a city. Urban Ecosyst. 2014, 17, 761–773. [Google Scholar] [CrossRef]
- Balram, S.; Dragićević, S. Attitudes toward urban green spaces: Integrating questionnaire survey and collaborative GIS techniques to improve attitude measurements. Landsc. Urban Plan. 2005, 71, 147–162. [Google Scholar] [CrossRef]
- Gao, L.; Wang, X.; Johnson, B.A.; Tian, Q.; Wang, Y.; Verrelst, J.; Mu, X.; Gu, X. Remote sensing algorithms for estimation of fractional vegetation cover using pure vegetation index values: A review. ISPRS J. Photogramm. Remote Sens. 2020, 159, 364–377. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, L.; Mcbride, J.; Gong, P. Can you see green? Assessing the visibility of urban forests in cities. Landsc. Urban Plan. 2009, 91, 97–104. [Google Scholar] [CrossRef]
- Li, X.; Zhang, C.; Li, W.; Ricard, R.; Meng, Q.; Zhang, W. Assessing street-level urban greenery using Google Street View and a modified green view index. Urban For. Urban Green. 2015, 14, 675–685. [Google Scholar] [CrossRef]
- Li, X.; Zhang, C.; Li, W.; Kuzovkina, Y.A. Environmental inequities in terms of different types of urban greenery in Hartford, Connecticut. Urban For. Urban Green. 2016, 18, 163–172. [Google Scholar] [CrossRef]
- Dong, R.; Zhang, Y.; Zhao, J. How green are the streets within the sixth ring road of Beijing? An analysis based on tencent street view pictures and the green view index. Int. J. Environ. Res. Public Health 2018, 15, 1367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Dong, R. Impacts of street-visible greenery on housing prices: Evidence from a hedonic price model and a massive street view image dataset in Beijing. ISPRS Int. J. Geo Inf. 2018, 7, 104. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Liu, L. How green are the streets? An analysis for central areas of Chinese cities using Tencent Street View. PLoS ONE 2017, 12, e0171110. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L.; Chu, S.; Zong, W.; Li, S.; Wu, J.; Li, M. Use of tencent street view imagery for visual perception of streets. ISPRS Int. J. Geo Inf. 2017, 6, 265. [Google Scholar] [CrossRef]
- Kendal, D.; Hauser, C.E.; Garrard, G.E.; Jellinek, S.; Giljohann, K.M.; Moore, J.L. Quantifying plant colour and colour difference as perceived by humans using digital images. PLoS ONE 2013, 8, e72296. [Google Scholar]
- Lopatin, J.; Dolos, K.; Kattenborn, T.; Fassnacht, F.E. How canopy shadow affects invasive plant species classification in high spatial resolution remote sensing. Remote Sens. Ecol. Conserv. 2019, 5, 302–317. [Google Scholar] [CrossRef]
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping forest tree species in high resolution UAV-based RGB-imagery by means of convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Council, W.C. Street Tree Planting | Wyndham City. 2021. Available online: https://www.wyndham.vic.gov.au/treeplanting (accessed on 15 August 2021).
- Street View Static API Overview | Google Developers. Available online: https://developers.google.com/maps/documentation/streetview/overview (accessed on 17 August 2021).
- Tsai, V.J.; Chang, C.T. Three-dimensional positioning from Google street view panoramas. IET Image Process. 2013, 7, 229–239. [Google Scholar] [CrossRef] [Green Version]
- Hao, S.; Zhou, Y.; Guo, Y. A brief survey on semantic segmentation with deep learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Uhrig, J.; Cordts, M.; Franke, U.; Brox, T. Pixel-level encoding and depth layering for instance-level semantic labeling. In German Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2016; pp. 14–25. [Google Scholar]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Almeer, M.H. Vegetation extraction from free google earth images of deserts using a robust BPNN approach in HSV Space. Int. J. Adv. Res. Comput. Commun. Eng. 2012, 1, 134–140. [Google Scholar]
- Blaschke, T.; Lang, S.; Lorup, E.; Strobl, J.; Zeil, P. Object-oriented image processing in an integrated GIS/remote sensing environment and perspectives for environmental applications. Environ. Inf. Plan. Politics Public 2000, 2, 555–570. [Google Scholar]
- APEER. Available online: https://www.apeer.com/ (accessed on 15 August 2021).
- Hamers, L. Similarity measures in scientometric research: The Jaccard index versus Salton’s cosine formula. Inf. Process. Manag. 1989, 25, 315–318. [Google Scholar] [CrossRef]
- Khan, A.; Ulhaq, A.; Robinson, R.W. Multi-temporal registration of environmental imagery using affine invariant convolutional features. In Pacific-Rim Symposium on Image and Video Technology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 269–280. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item Name | Parameter |
|---|---|
| Central processing unit (CPU) | Intel i7 9700k |
| Operating system | MS Windows 10 |
| Operating volatile memory | 32GB RAM |
| Graphic processing unit (GPU) | Nvidia Titan RTX |
| Development environment configuration | Python 3.8 + TensorFlow 2.5 + CUDA 11.2 + cuDNN V8.1.0 + Visual Studio 2019 |
| Segmentation Model | Precision | Recall | F1-Score | Pixel Accuracy | IoU | mIoU |
|---|---|---|---|---|---|---|
| FCN | 93.2 | 87.3 | 90.1 | 89.4 | 82.3 | 80 |
| U-Net | 95 | 90.8 | 92.3 | 92.4 | 86.5 | 83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.; Asim, W.; Ulhaq, A.; Robinson, R.W. A Multiview Semantic Vegetation Index for Robust Estimation of Urban Vegetation Cover. Remote Sens. 2022, 14, 228. https://doi.org/10.3390/rs14010228
Khan A, Asim W, Ulhaq A, Robinson RW. A Multiview Semantic Vegetation Index for Robust Estimation of Urban Vegetation Cover. Remote Sensing. 2022; 14(1):228. https://doi.org/10.3390/rs14010228
Chicago/Turabian StyleKhan, Asim, Warda Asim, Anwaar Ulhaq, and Randall W. Robinson. 2022. "A Multiview Semantic Vegetation Index for Robust Estimation of Urban Vegetation Cover" Remote Sensing 14, no. 1: 228. https://doi.org/10.3390/rs14010228
APA StyleKhan, A., Asim, W., Ulhaq, A., & Robinson, R. W. (2022). A Multiview Semantic Vegetation Index for Robust Estimation of Urban Vegetation Cover. Remote Sensing, 14(1), 228. https://doi.org/10.3390/rs14010228