
Motion Blur Removal for Uav-Based Wind Turbine Blade Images Using Synthetic Datasets



Abstract
:1. Introduction
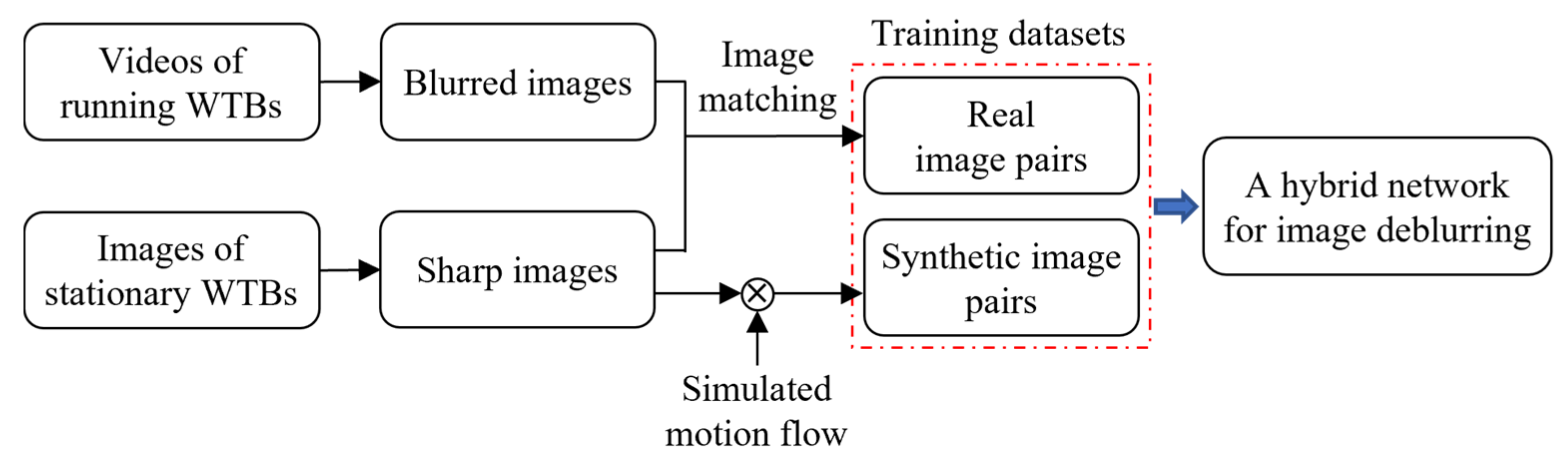
2. Synthetic Training Datasets
2.1. Image Pair Acquisition by Image Matching
2.2. Image Pair Acquisition by Sample Synthesis
| Algorithm 1 Blurred image synthesis |
| Operation: morphological dilation |
| morphological erosion Dirac Delta function |
| Input: sharp image ROI mask |
| central point additive noise N is uniformed to (0, 0.5) morphological structuring element with size s angular velocity ω, ranging in (0, 2) linear fusion factor α |
| 1: 2: 3: 4: for each pixel in do 5: 6: 7: 8: 9: if then 10: 11: end if 12: end for 13: for each pixel in do 14: if then 15: 16: else if then 17: |
| 18: else 19: 20: end if 21: end for Output: blurred image |
3. Hybrid Motion Deblurring Network
3.1. Generator
3.2. Discriminator
3.3. Loss Function
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hasager, C.B.; Sjöholm, M. Editorial for the special issue “Remote Sensing of Atmospheric Conditions for Wind Energy Applications”. Remote Sens. 2019, 11, 781. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Jiang, Y.; Guo, Q.; Hu, C.; Peng, Z. Multi-dimensional variational mode decomposition for bearing-crack detection in wind turbines with large driving-speed variations. Renew. Energy 2018, 116, 55–73. [Google Scholar] [CrossRef]
- Yang, R.; He, Y.; Zhang, H. Progress and trends in nondestructive testing and evaluation for wind turbine composite blade. Renew. Sustain. Energy Rev. 2016, 60, 1225–1250. [Google Scholar] [CrossRef]
- Ingersoll, B.; Ning, A. Efficient incorporation of fatigue damage constraints in wind turbine blade optimization. Wind Energy 2020, 23, 1063–1076. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.; Zhou, S.; Jing, X.; Peng, Y.; Wu, H.; Kwok, N. Damage detection techniques for wind turbine blades: A review. Mech. Syst. Signal Process. 2020, 141, 106445. [Google Scholar] [CrossRef]
- Aird, J.A.; Quon, E.W.; Barthelmie, R.J.; Debnath, M.; Doubrawa, P.; Pryor, S.C. Region-based convolutional neural network for wind turbine wake characterization in complex terrain. Remote Sens. 2021, 13, 4438. [Google Scholar] [CrossRef]
- Movsessian, A.; García Cava, D.; Tcherniak, D. An artificial neural network methodology for damage detection: Demonstration on an operating wind turbine blade. Mech. Syst. Signal Process. 2021, 159, 107766. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Wang, W. Multi-scale convolutional attention network for predicting remaining useful life of machinery. IEEE Trans. Ind. Electron. 2021, 68, 7496–7504. [Google Scholar] [CrossRef]
- Manso-Callejo, M.Á.; Cira, C.I.; Alcarria, R.; Arranz-Justel, J.J. Optimizing the recognition and feature extraction of wind turbines through hybrid semantic segmentation architectures. Remote Sens. 2020, 12, 3743. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Luo, X. A two-stage data-driven approach for image-based wind turbine blade crack inspections. IEEE/ASME Trans. Mechatron. 2019, 24, 1271–1281. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z. Automatic detection of wind turbine blade surface cracks based on UAV-taken images. IEEE Trans. Ind. Electron. 2017, 64, 7293–7303. [Google Scholar] [CrossRef]
- Shihavuddin, A.; Chen, X.; Fedorov, V.; Nymark Christensen, A.; Andre Brogaard Riis, N.; Branner, K.; Bjorholm Dahl, A.; Reinhold Paulsen, R. Wind turbine surface damage detection by deep learning aided drone inspection analysis. Energies 2019, 12, 676. [Google Scholar] [CrossRef] [Green Version]
- Tao, Y.; Muller, J.-P. Super-resolution restoration of spaceborne ultra-high-resolution images using the UCL OpTiGAN system. Remote Sens. 2021, 13, 2269. [Google Scholar] [CrossRef]
- Wu, H.; Kwok, N.M.; Liu, S.; Li, R.; Wu, T.; Peng, Z. Restoration of defocused ferrograph images using a large kernel convolutional neural network. Wear 2019, 426–427, 1740–1747. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. In ACM SIGGRAPH 2006 Papers; Siggraph: Boston, MA, USA, 2006; pp. 787–794. [Google Scholar]
- Zhang, H.; Wipf, D.; Zhang, Y. Multi-image blind deblurring using a coupled adaptive sparse prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1051–1058. [Google Scholar]
- Gupta, A.; Joshi, N.; Zitnick, C.L.; Cohen, M.; Curless, B. Single image deblurring using motion density functions. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 171–184. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Gong, D.; Yang, J.; Liu, L.; Zhang, Y.; Reid, I.; Shen, C.; Van Den Hengel, A.; Shi, Q. From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3806–3815. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 257–265. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8877–8886. [Google Scholar]
- Köhler, R.; Hirsch, M.; Mohler, B.; Schölkopf, B.; Harmeling, S. Recording and playback of camera shake: Benchmarking blind deconvolution with a real-world database. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 27–40. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Brusius, F.; Schwanecke, U.; Barth, P. Blind image deconvolution of linear motion blur. In International Conference on Computer Vision, Imaging and Computer Graphics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 105–119. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Eecognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl. Based Syst. 2021, 213, 106617. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, G.; Lin, Y.; Qu, X. An infrared and visible image fusion method based on multi-scale transformation and norm optimization. Inf. Fusion 2021, 71, 109–129. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Model | PSNR | SSIM | ||||||
|---|---|---|---|---|---|---|---|---|
| 0–2 rad/s | 2–4 rad/s | 4–7 rad/s | Average | 0–2 rad/s | 2–4 rad/s | 4–7 rad/s | Average | |
| DeblurGAN | 80.922 | 74.179 | 72.355 | 75.819 | 0.953 | 0.846 | 0.766 | 0.855 |
| M-DeblurGANv2 | 85.179 | 76.871 | 75.523 | 79.191 | 0.975 | 0.932 | 0.896 | 0.934 |
| I-DeblurGANv2 | 86.128 | 77.609 | 76.676 | 80.138 | 0.975 | 0.940 | 0.908 | 0.950 |
| Network Model | Number of Parameters | Average Running Time |
|---|---|---|
| DeblurGAN | 11.7 M | 0.389 s |
| M-DeblurGANv2 | 3.1 M | 0.105 s |
| I-DeblurGANv2 | 66.6 M | 0.189 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Tang, Z.; Zhao, G.; Cao, G.; Wu, C. Motion Blur Removal for Uav-Based Wind Turbine Blade Images Using Synthetic Datasets. Remote Sens. 2022, 14, 87. https://doi.org/10.3390/rs14010087
Peng Y, Tang Z, Zhao G, Cao G, Wu C. Motion Blur Removal for Uav-Based Wind Turbine Blade Images Using Synthetic Datasets. Remote Sensing. 2022; 14(1):87. https://doi.org/10.3390/rs14010087
Chicago/Turabian StylePeng, Yeping, Zhen Tang, Genping Zhao, Guangzhong Cao, and Chao Wu. 2022. "Motion Blur Removal for Uav-Based Wind Turbine Blade Images Using Synthetic Datasets" Remote Sensing 14, no. 1: 87. https://doi.org/10.3390/rs14010087
APA StylePeng, Y., Tang, Z., Zhao, G., Cao, G., & Wu, C. (2022). Motion Blur Removal for Uav-Based Wind Turbine Blade Images Using Synthetic Datasets. Remote Sensing, 14(1), 87. https://doi.org/10.3390/rs14010087