
Parameter Flexible Wildfire Prediction Using Machine Learning Techniques: Forward and Inverse Modelling

 ,
, 
 ,
,
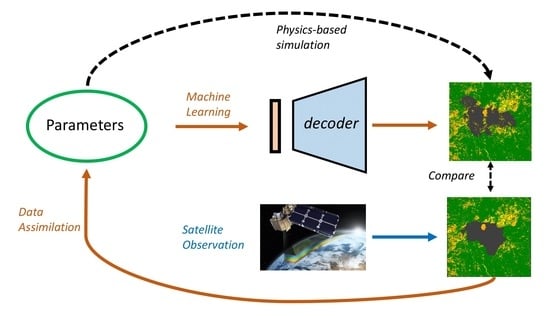
Abstract
:
1. Introduction
- We propose a parameter flexible data-driven algorithm scheme for burned area forecasting which can combine different approaches of ROM and ML prediction techniques with a large range of model parameters.
- We develop an inverse model to address the bottleneck of parameter identification in fire prediction models by using the recently developed GLA algorithm,
- We test the parameter flexible data-driven model and the inverse model for recent massive fire events in California where the data used for the assimilation are satellite observations (ORNL DAAC. 2018. MODIS and VIIRS Land Products Global Subsetting and Visualization Tool. ORNL DAAC, Oak Ridge, Tennessee, USA) of burned area.
2. Data Generation and Study Area
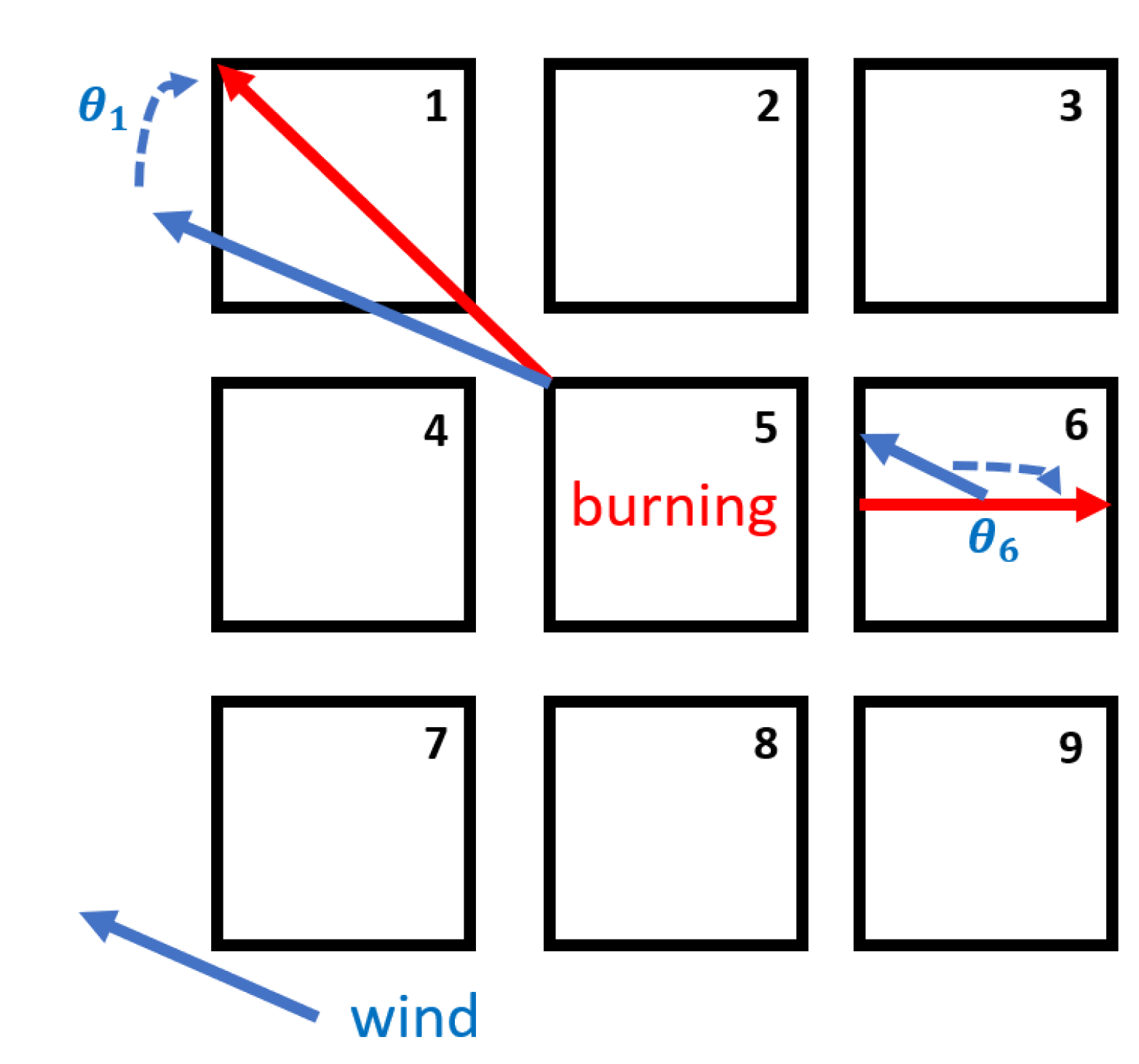
2.1. Cellular Automata Fire Simulation
- state 1: the cell can not be burned;
- state 2: the cell is burnable but has not been ignited;
- state 3: the cell is burning;
- state 4: the cell has been burned.
2.2. Study Area and Observation Data
3. A Parameter Flexible Data-Driven Model for Burned Area Forecasting: Methodology
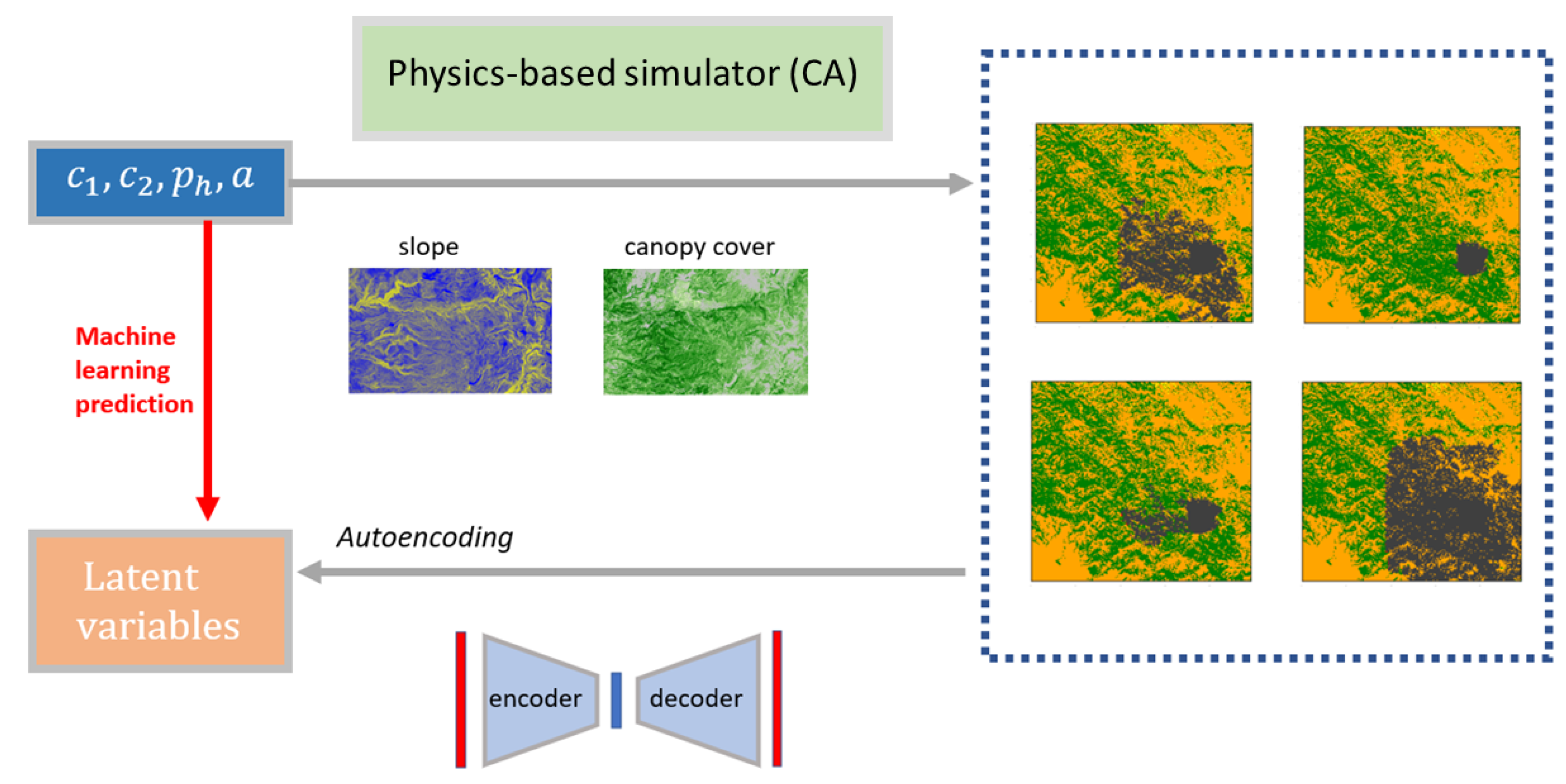
3.1. Reduced-Order Modelling
3.1.1. Principle Component Analysis
3.1.2. Convolutional Autoencoding
3.1.3. Singular Value Decomposition Autoencoding
3.2. Forward Problem: Machine Learning Prediction
3.2.1. Random Forest Regression
3.2.2. K-Nearest Neighbours Regression
3.2.3. Multi Layer Perceptron
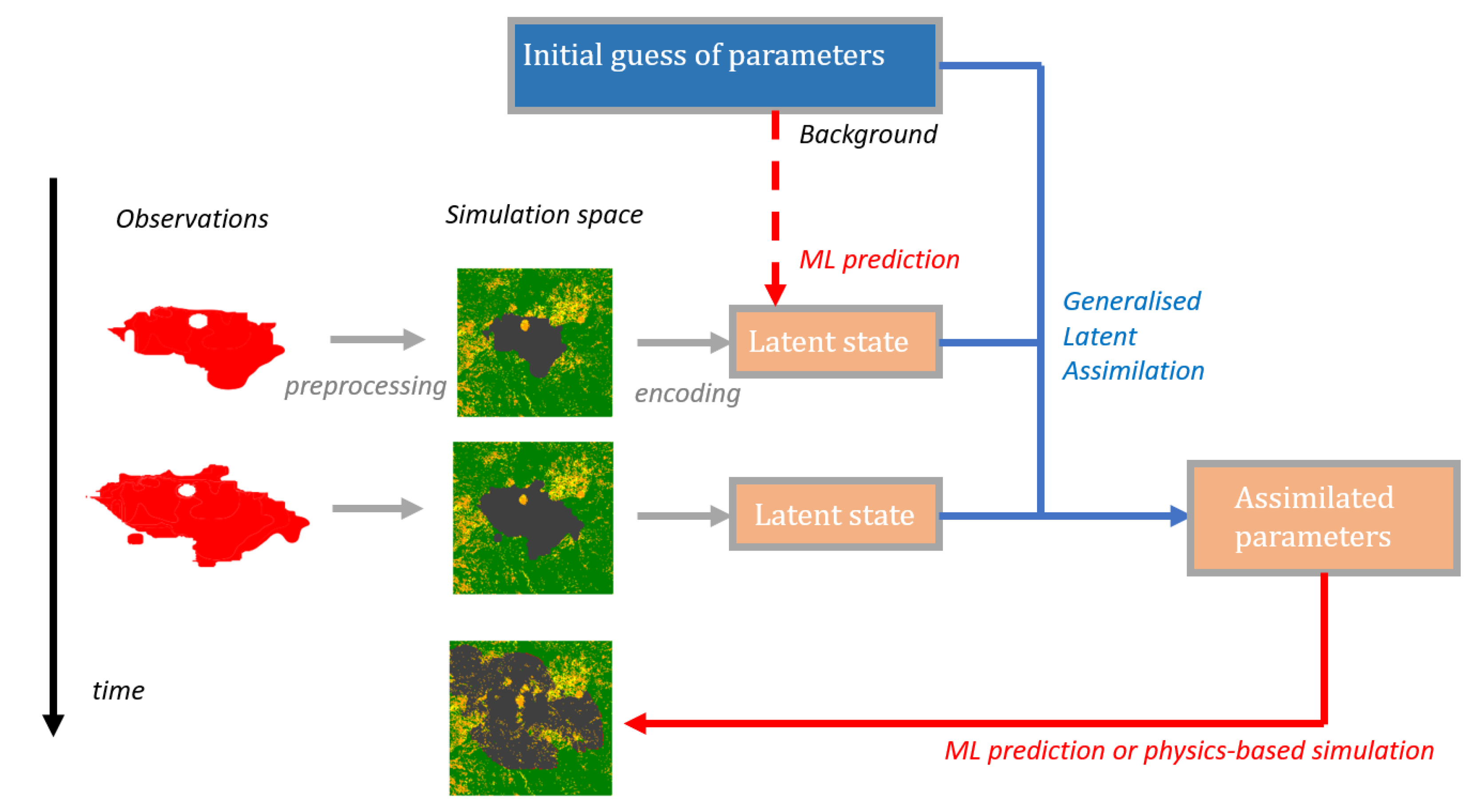
3.3. Inverse Problem: Latent Data Assimilation
3.3.1. Four Dimensional Variational Approach
3.3.2. Generalised Latent Assimilation
| Algorithm 1: 4Dvar GLA |
 |
3.4. Hyperparameter Tuning
4. Results and Analysis
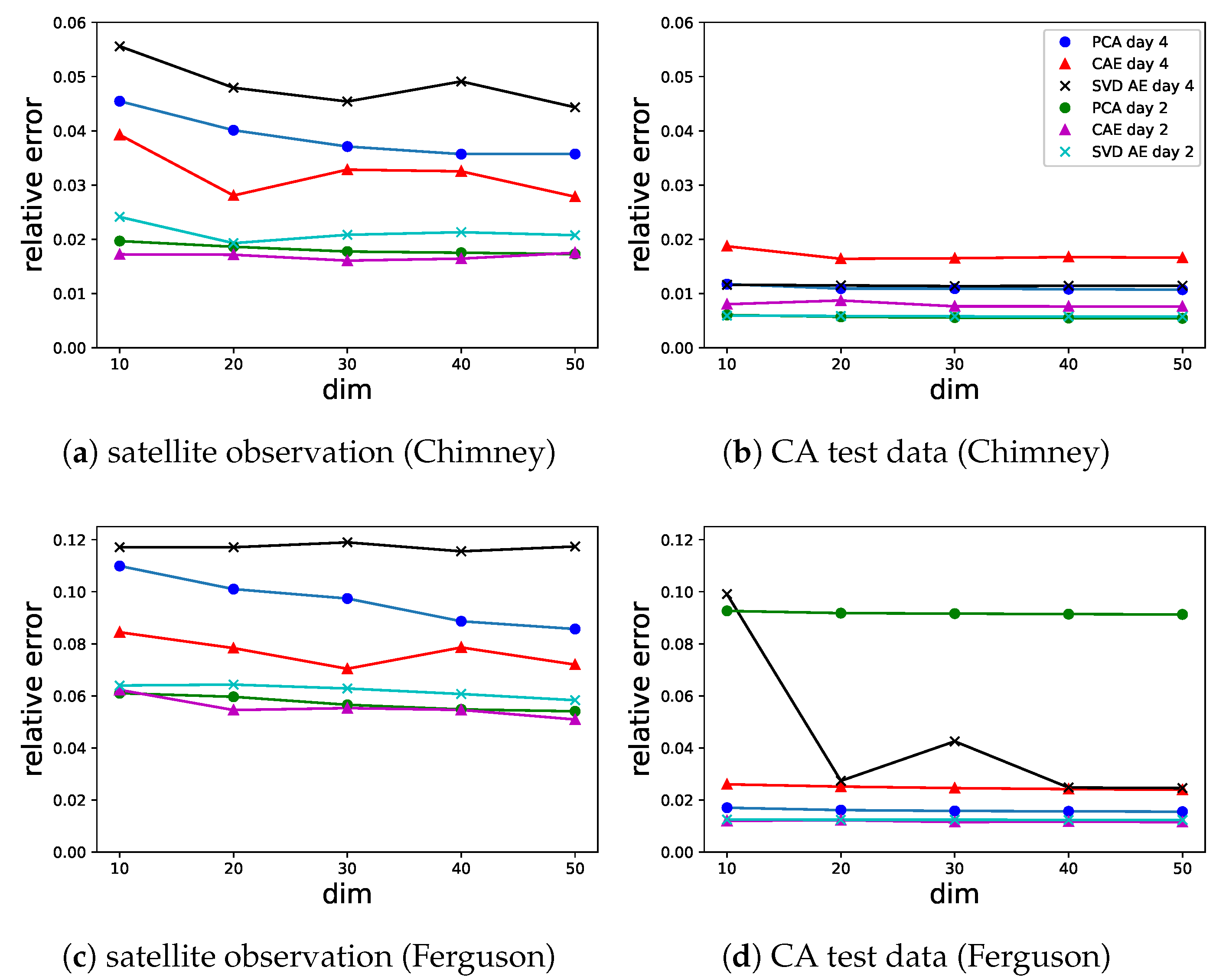
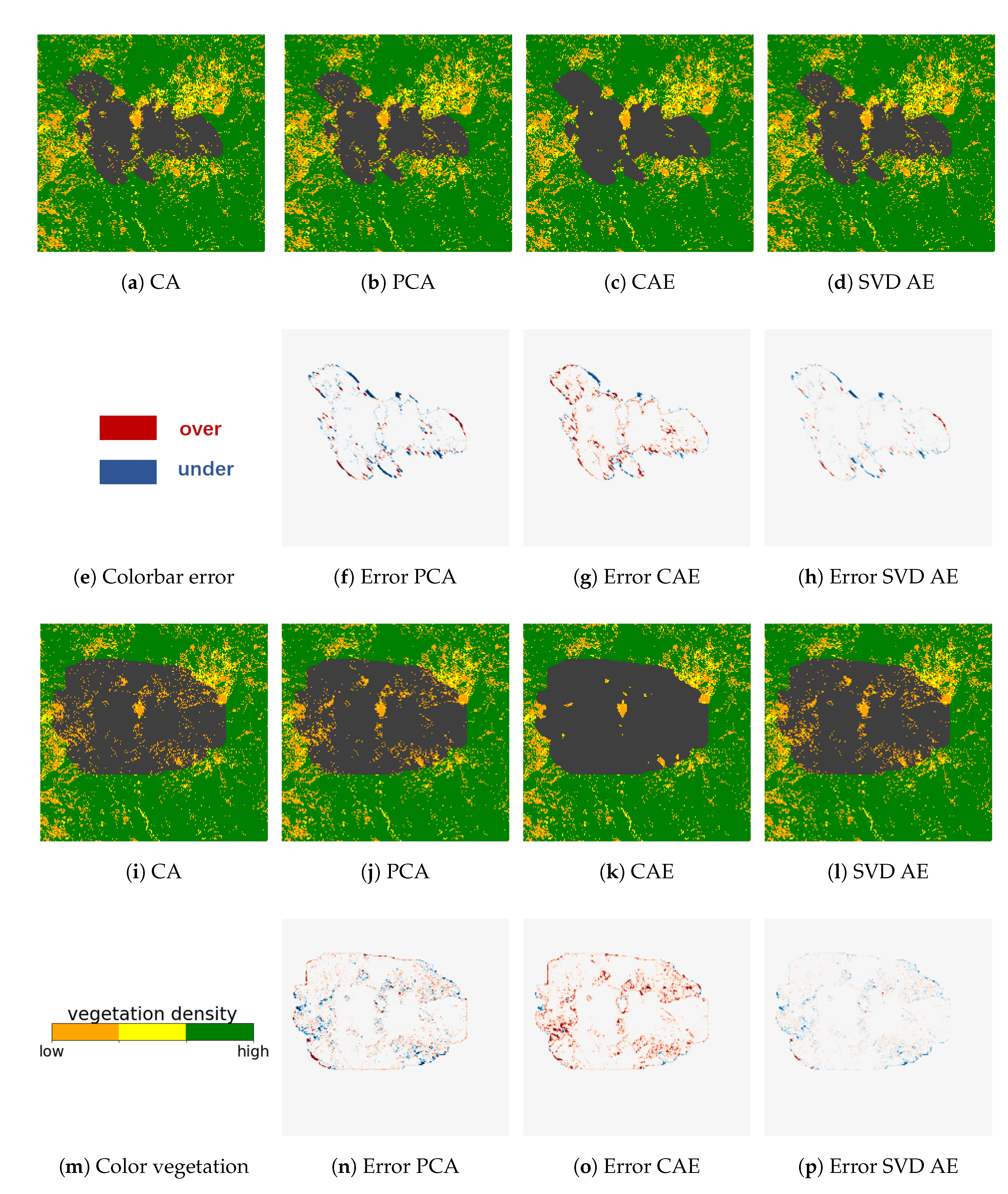
4.1. Reconstruction Accuracy of Reduced Order Modellings
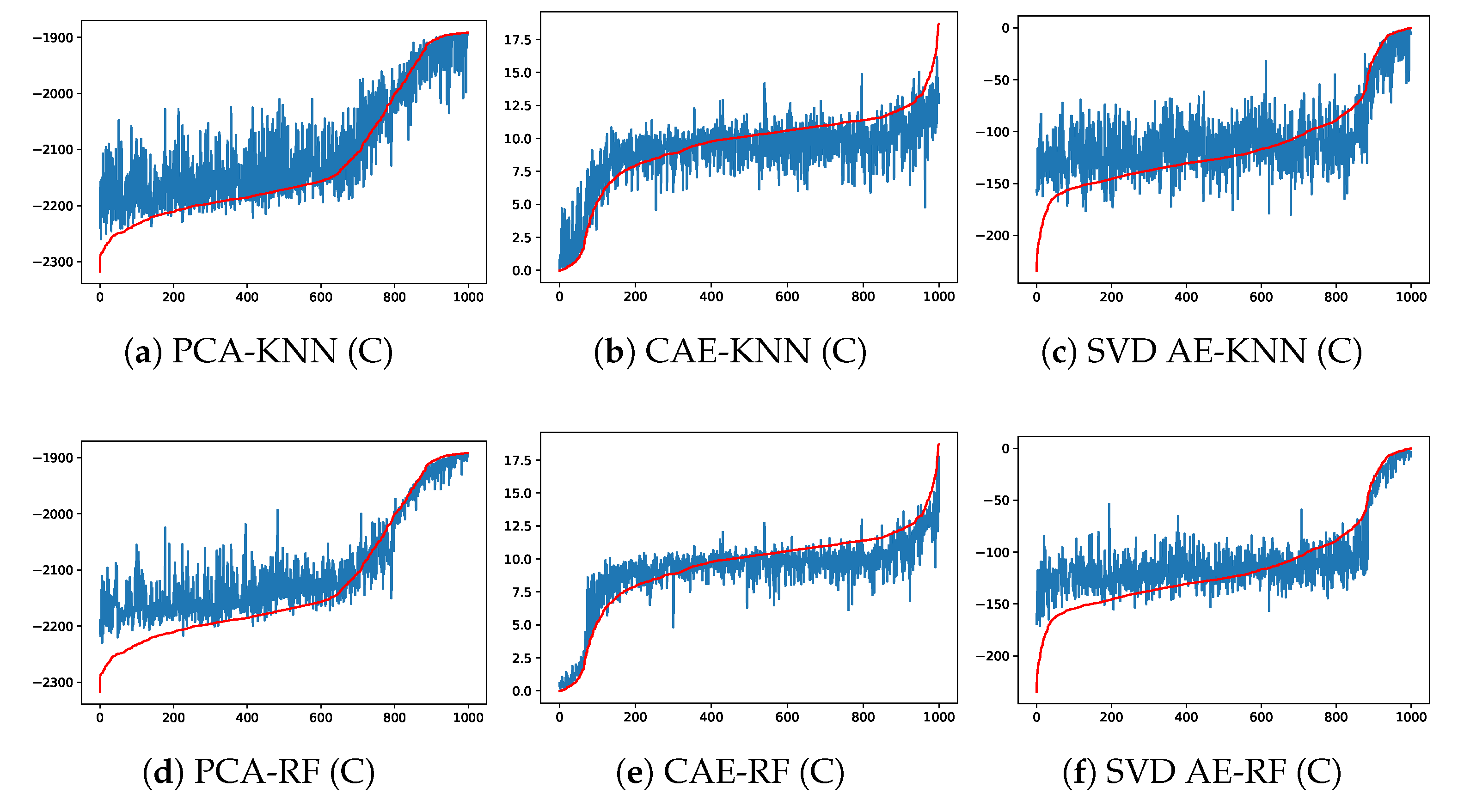
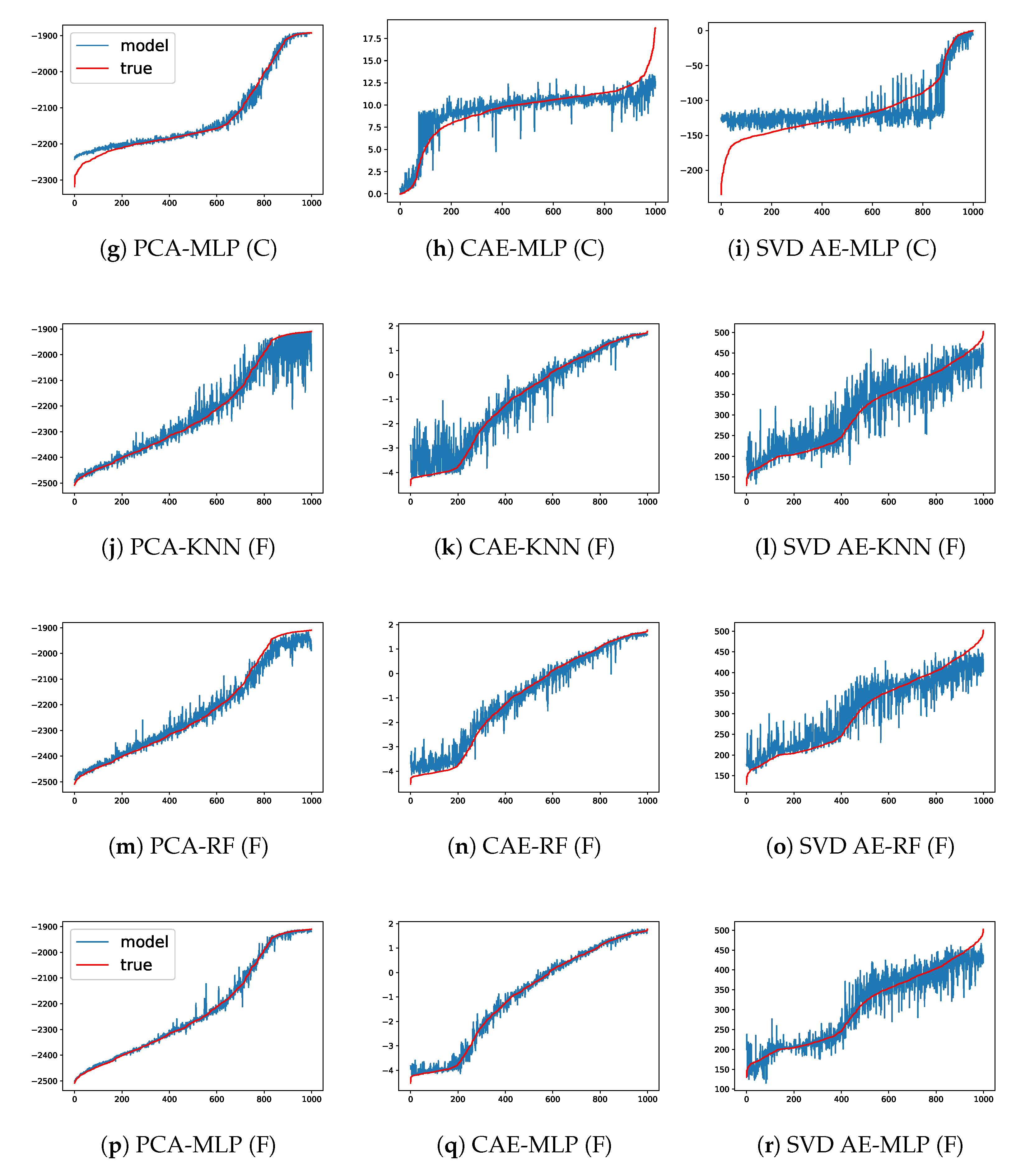
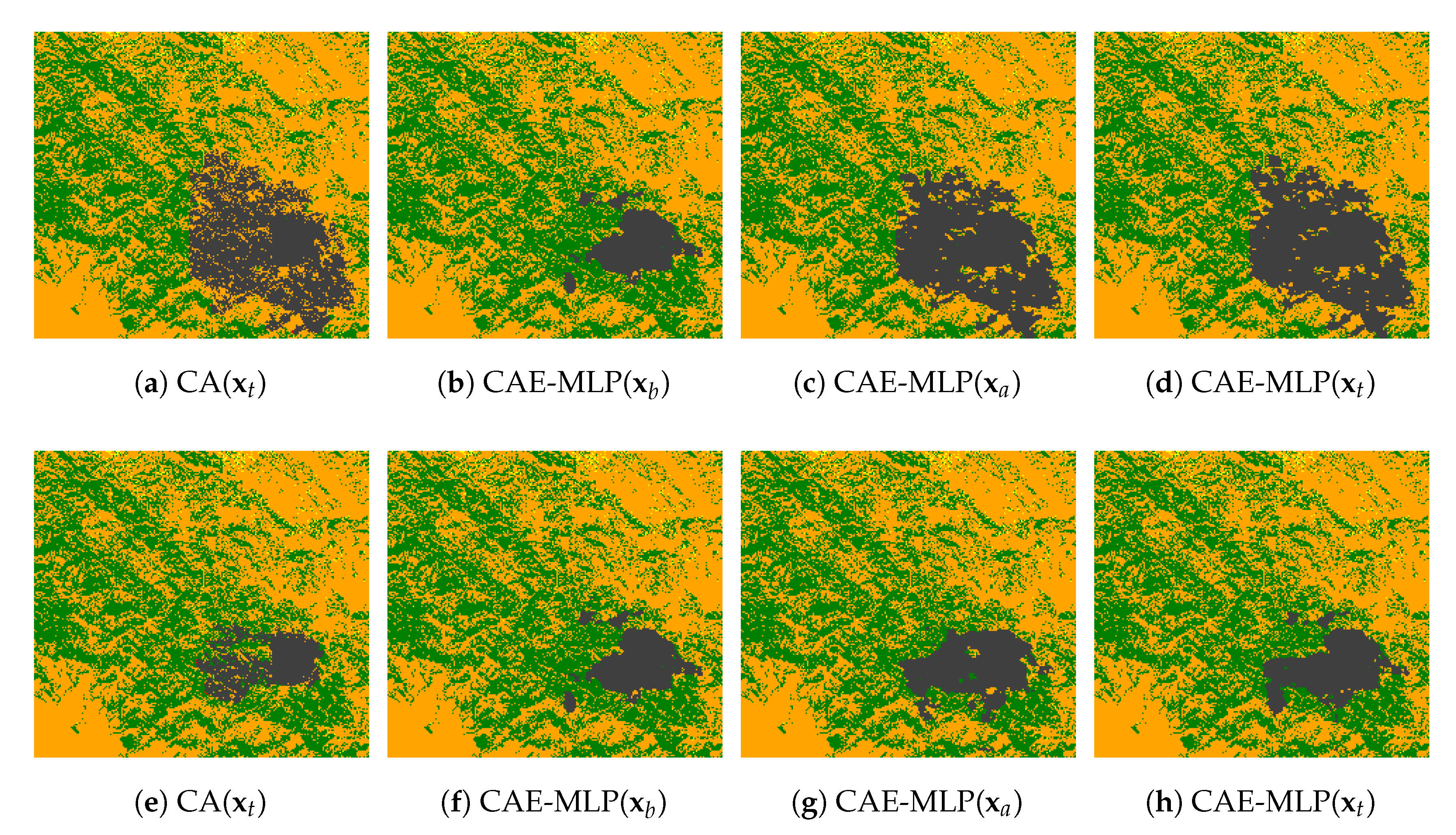
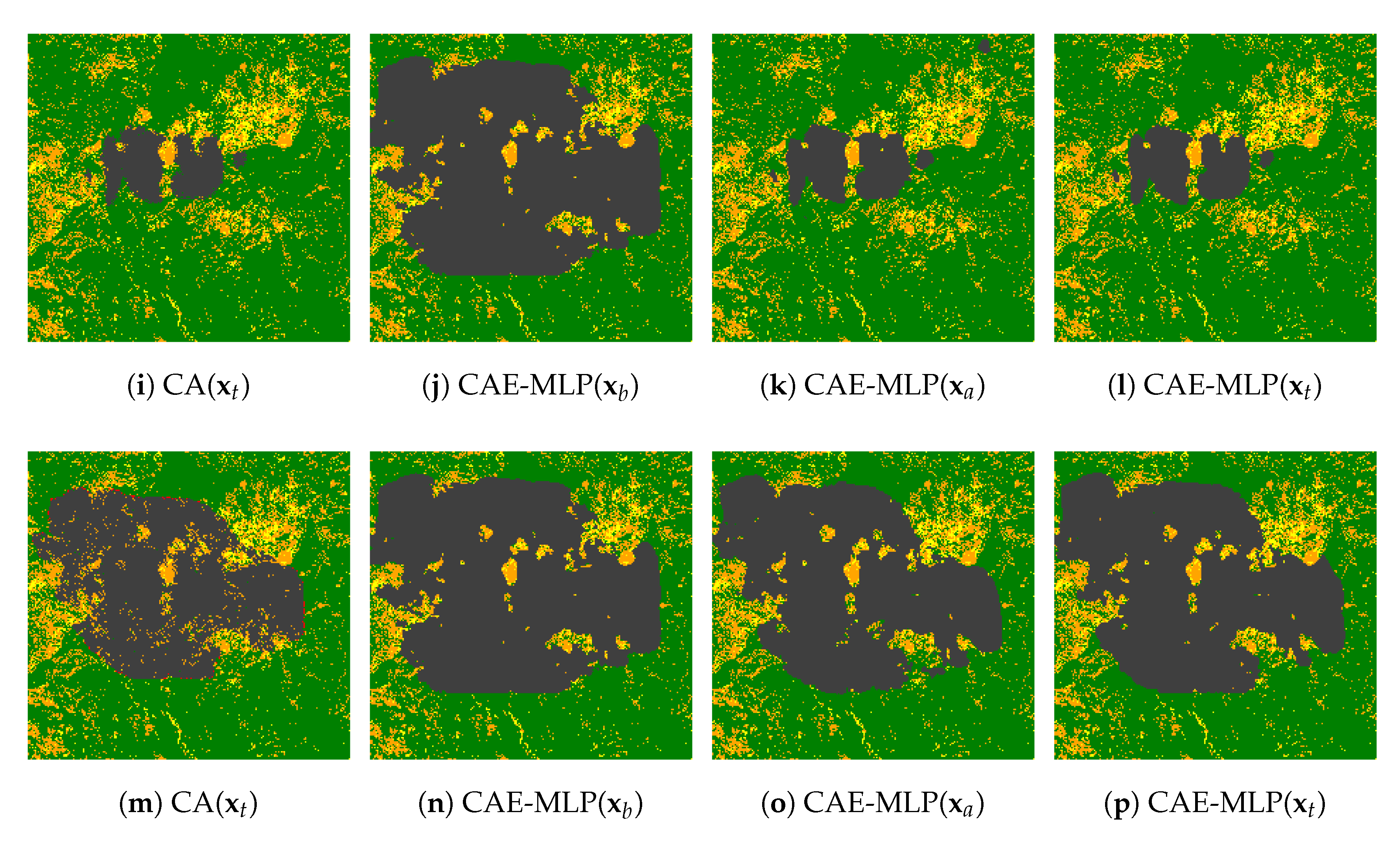
4.2. Prediction Performance of the Forward Model
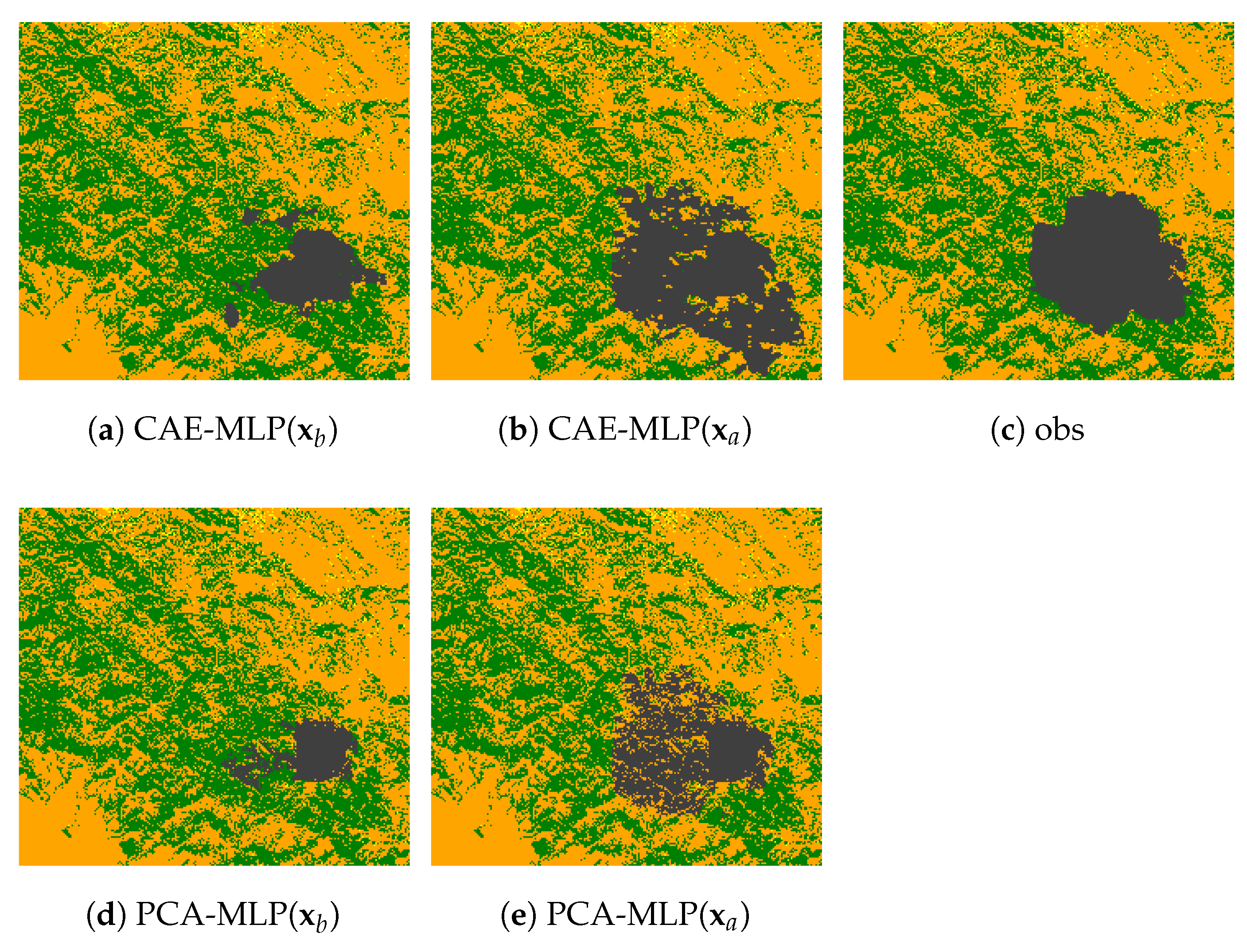
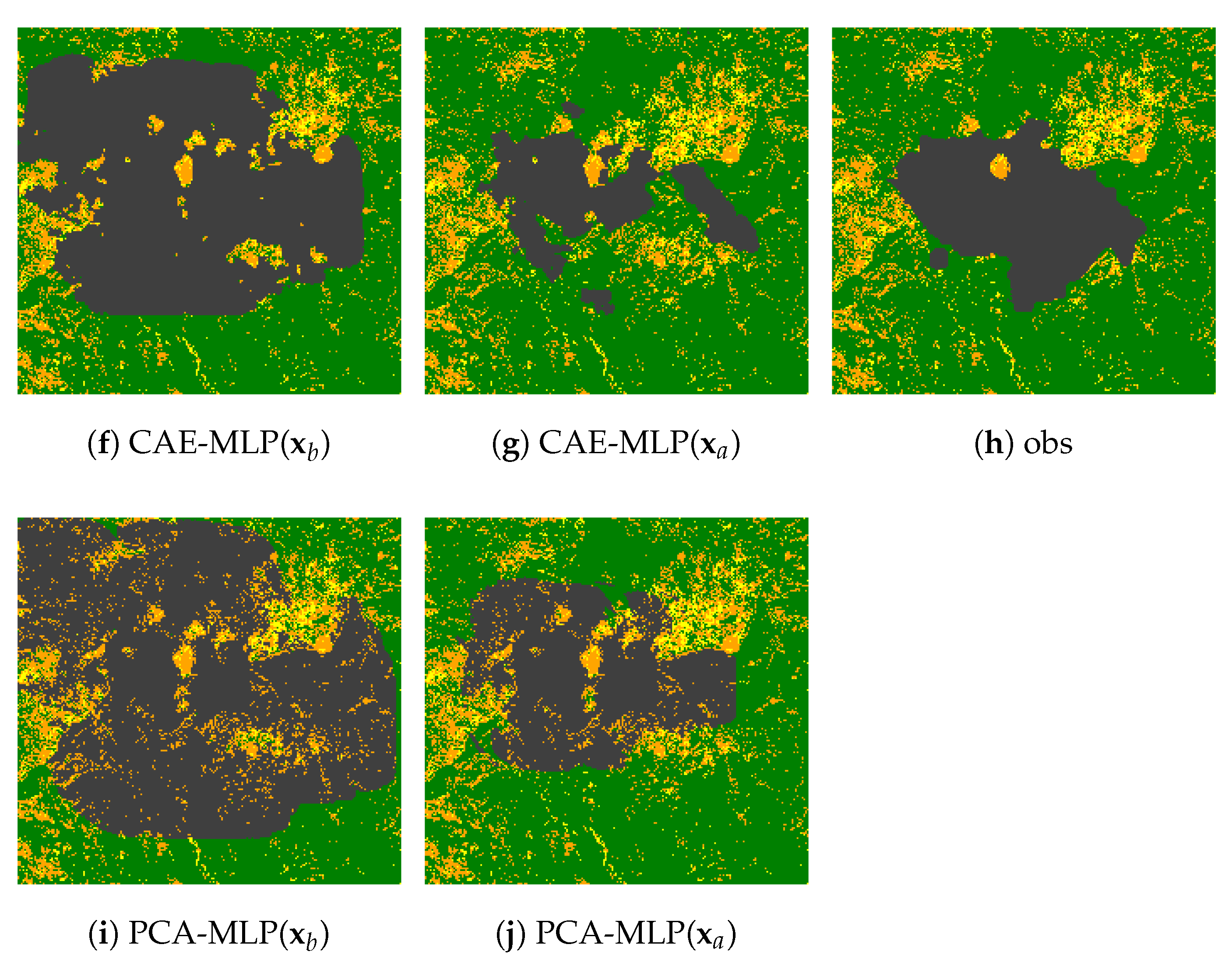
4.3. Parameter Estimation of the Inverse Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Acronyms
| NN | Neural Network |
| DNN | Deep Neural Network |
| ML | Machine Learning |
| LA | Latent Assimilation |
| DA | Data Assimilation |
| PR | Polynomial Regression |
| AE | Autoencoder |
| VAE | Variational Autoencoder |
| CAE | Convolutional Autoencoder |
| VAE | Variational Autoencoder |
| BLUE | Best Linear Unbiased Estimator |
| 3D-Var | 3D Variational |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| LSTM | long short-term memory |
| POD | Proper Orthogonal Decomposition |
| PCA | Principal Component Analysis |
| PC | principal component |
| SVD | Singular Value Decomposition |
| ROM | reduced-order modelling |
| CFD | computational fluid dynamics |
| 1D | one-dimensional |
| 2D | two-dimensional |
| NWP | numerical weather prediction |
| MSE | mean square error |
| S2S | sequence-to-sequence |
| R-RMSE | relative root mean square error |
| BFGS | Broyden–Fletcher–Goldfarb–Shanno |
| LHS | Latin Hypercube Sampling |
| AI | artificial intelligence |
| DL | Deep Learning |
| PIV | Particle Image Velocimetry |
| LIF | Laser Induced Fluorescence |
| KNN | K-nearest Neighbours |
| DT | Decision Tree |
| RF | Random Forest |
| KF | Kalman filter |
| CART | Classification And Regression Tree |
| CA | Cellular Automata |
| MLP | Multi Layer Percepton |
| GLA | Generalised Latent Assimilation |
| 3Dvar | Three-dimensional variational data assimilation |
| 4Dvar | Four-dimensional variational data assimilation |
| MODIS | Moderate Resolution Imaging Spectroradiometer |
| VIIRS | Visible Infrared Imaging Radiometer Suite |
References
- Chen, G.; Guo, Y.; Yue, X.; Tong, S.; Gasparrini, A.; Bell, M.L.; Armstrong, B.; Schwartz, J.; Jaakkola, J.J.; Zanobetti, A.; et al. Mortality risk attributable to wildfire-related PM2· 5 pollution: A global time series study in 749 locations. Lancet Planet. Health 2021, 5, e579–e587. [Google Scholar] [CrossRef]
- Verisk Wildfire Risk Analysis: Number of Properties at High to Extreme Risk; Wildfire: Redwood City, CA, USA, 2021.
- Hanson, H.P.; Bradley, M.M.; Bossert, J.E.; Linn, R.R.; Younker, L.W. The potential and promise of physics-based wildfire simulation. Environ. Sci. Policy 2000, 3, 161–172. [Google Scholar] [CrossRef]
- Viegas, D.X.; Simeoni, A. Eruptive behaviour of forest fires. Fire Technol. 2011, 47, 303–320. [Google Scholar] [CrossRef] [Green Version]
- Valero, M.M.; Jofre, L.; Torres, R. Multifidelity prediction in wildfire spread simulation: Modeling, uncertainty quantification and sensitivity analysis. Environ. Model. Softw. 2021, 141, 105050. [Google Scholar] [CrossRef]
- Maffei, C.; Menenti, M. Predicting forest fires burned area and rate of spread from pre-fire multispectral satellite measurements. ISPRS J. Photogramm. Remote Sens. 2019, 158, 263–278. [Google Scholar] [CrossRef]
- Alexandridis, A.; Vakalis, D.; Siettos, C.; Bafas, G. A cellular automata model for forest fire spread prediction: The case of the wildfire that swept through Spetses Island in 1990. Appl. Math. Comput. 2008, 204, 191–201. [Google Scholar] [CrossRef]
- Papadopoulos, G.D.; Pavlidou, F.N. A comparative review on wildfire simulators. IEEE Syst. J. 2011, 5, 233–243. [Google Scholar] [CrossRef]
- Casas, C.Q.; Arcucci, R.; Wu, P.; Pain, C.; Guo, Y.K. A Reduced Order Deep Data Assimilation model. Phys. D Nonlinear Phenom. 2020, 412, 132615. [Google Scholar] [CrossRef]
- Murata, T.; Fukami, K.; Fukagata, K. Nonlinear mode decomposition with convolutional neural networks for fluid dynamics. J. Fluid Mech. 2020, 882. [Google Scholar] [CrossRef] [Green Version]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skilful precipitation nowcasting using deep generative models of radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef]
- Gong, H.; Cheng, S.; Chen, Z.; Li, Q. Data-Enabled Physics-Informed Machine Learning for Reduced-Order Modeling Digital Twin: Application to Nuclear Reactor Physics. Nucl. Sci. Eng. 2022, 196, 668–693. [Google Scholar] [CrossRef]
- Fukami, K.; Murata, T.; Zhang, K.; Fukagata, K. Sparse identification of nonlinear dynamics with low-dimensionalized flow representations. J. Fluid Mech. 2021, 926, A10. [Google Scholar] [CrossRef]
- Hinze, M.; Volkwein, S. Proper orthogonal decomposition surrogate models for nonlinear dynamical systems: Error estimates and suboptimal control. In Dimension Reduction of Large-Scale Systems; Springer: Berlin/Heidelberg, Germany, 2005; pp. 261–306. [Google Scholar]
- Cheng, S.; Lucor, D.; Argaud, J.P. Observation data compression for variational assimilation of dynamical systems. J. Comput. Sci. 2021, 53, 101405. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Pu, Y.; Gan, Z.; Henao, R.; Yuan, X.; Li, C.; Stevens, A.; Carin, L. Variational autoencoder for deep learning of images, labels and captions. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Phillips, T.R.; Heaney, C.E.; Smith, P.N.; Pain, C.C. An autoencoder-based reduced-order model for eigenvalue problems with application to neutron diffusion. Int. J. Numer. Methods Eng. 2021, 122, 3780–3811. [Google Scholar] [CrossRef]
- Quilodrán-Casas, C.; Arcucci, R.; Mottet, L.; Guo, Y.; Pain, C. Adversarial autoencoders and adversarial LSTM for improved forecasts of urban air pollution simulations. arXiv 2021, arXiv:2012.12056. [Google Scholar]
- Pache, R.; Rung, T. Data-driven surrogate modeling of aerodynamic forces on the superstructure of container vessels. Eng. Appl. Comput. Fluid Mech. 2022, 16, 746–763. [Google Scholar] [CrossRef]
- Ly, H.; Tran, H. Modeling and control of physical processes using proper orthog- onal decomposition. J. Math. Comput. Model 2001, 33, 223–236. [Google Scholar] [CrossRef] [Green Version]
- Xiao, D.; Du, J.; Fang, F.; Pain, C.; Li, J. Parameterised non-intrusive reduced order methods for ensemble Kalman filter data assimilation. Comput. Fluids 2018, 177, 69–77. [Google Scholar] [CrossRef]
- Xiao, D.; Fang, F.; Pain, C.; Navon, I. A parameterized non-intrusive reduced order model and error analysis for general time-dependent nonlinear partial differential equations and its applications. Comput. Methods Appl. Mech. Eng. 2017, 317, 868–889. [Google Scholar] [CrossRef] [Green Version]
- Audouze, C.; Vuyst, F.D.; Nair, P.B. Reduced-order modeling of parameterized PDEs using time-space-parameter principal component analysis. Int. J. Numer. Methods Eng. 2009, 80, 1025–1057. [Google Scholar] [CrossRef]
- Xiao, D.; Yang, P.; Fang, F.; Xiang, J.; Pain, C.C.; Navon, I.M. Non-intrusive reduced order modelling of fluid–structure interactions. Comput. Methods Appl. Mech. Eng. 2016, 303, 35–54. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Fu, R.; Xiao, D.; Stefanescu, R.; Sharma, P.; Zhu, C.; Sun, S.; Wang, C. EnKF data-driven reduced order assimilation system. Eng. Anal. Bound. Elem. 2022, 139, 46–55. [Google Scholar] [CrossRef]
- Cheng, S.; Prentice, I.C.; Huang, Y.; Jin, Y.; Guo, Y.K.; Arcucci, R. Data-driven surrogate model with latent data assimilation: Application to wildfire forecasting. J. Comput. Phys. 2022, 464, 111302. [Google Scholar] [CrossRef]
- Finney, M.A. FARSITE, Fire Area Simulator—Model Development and Evaluation; Number 4; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 1998. [Google Scholar]
- Hilton, J.E.; Sullivan, A.L.; Swedosh, W.; Sharples, J.; Thomas, C. Incorporating convective feedback in wildfire simulations using pyrogenic potential. Environ. Model. Softw. 2018, 107, 12–24. [Google Scholar] [CrossRef]
- Mallet, V.; Keyes, D.E.; Fendell, F. Modeling wildland fire propagation with level set methods. Comput. Math. Appl. 2009, 57, 1089–1101. [Google Scholar] [CrossRef] [Green Version]
- Mu noz-Esparza, D.; Kosović, B.; Jiménez, P.A.; Coen, J.L. An accurate fire-spread algorithm in the Weather Research and Forecasting model using the level-set method. J. Adv. Model. Earth Syst. 2018, 10, 908–926. [Google Scholar] [CrossRef] [Green Version]
- Ambroz, M.; Mikula, K.; Fraštia, M.; Marčiš, M. Parameter estimation for the forest fire propagation model. Tatra Mt. Math. Publ. 2018, 75, 1–22. [Google Scholar] [CrossRef]
- Lautenberger, C. Wildland fire modeling with an Eulerian level set method and automated calibration. Fire Saf. J. 2013, 62, 289–298. [Google Scholar] [CrossRef]
- Rochoux, M.; Emery, C.; Ricci, S.; Cuenot, B.; Trouvé, A. A comparative study of parameter estimation and state estimation approaches in data-driven wildfire spread modeling. In Proceedings of the VII International Conference on Forest Fire Research, Coimbra, Portugal, 17–20 November 2014; pp. 14–20. [Google Scholar]
- Ervilha, A.; Pereira, J.; Pereira, J. On the parametric uncertainty quantification of the Rothermel’s rate of spread model. Appl. Math. Model. 2017, 41, 37–53. [Google Scholar] [CrossRef]
- Zhang, C.; Collin, A.; Moireau, P.; Trouvé, A.; Rochoux, M.C. State-parameter estimation approach for data-driven wildland fire spread modeling: Application to the 2012 RxCADRE S5 field-scale experiment. Fire Saf. J. 2019, 105, 286–299. [Google Scholar] [CrossRef]
- Alessandri, A.; Bagnerini, P.; Gaggero, M.; Mantelli, L. Parameter estimation of fire propagation models using level set methods. Appl. Math. Model. 2021, 92, 731–747. [Google Scholar] [CrossRef]
- Jensen, C.A.; Reed, R.D.; Marks, R.J.; El-Sharkawi, M.A.; Jung, J.B.; Miyamoto, R.T.; Anderson, G.M.; Eggen, C.J. Inversion of feedforward neural networks: Algorithms and applications. Proc. IEEE 1999, 87, 1536–1549. [Google Scholar] [CrossRef]
- Amendola, M.; Arcucci, R.; Mottet, L.; Casas, C.Q.; Fan, S.; Pain, C.; Linden, P.; Guo, Y.K. Data Assimilation in the Latent Space of a Neural Network. arXiv 2020, arXiv:2104.06297. [Google Scholar]
- Peyron, M.; Fillion, A.; Gürol, S.; Marchais, V.; Gratton, S.; Boudier, P.; Goret, G. Latent space data assimilation by using deep learning. Q. J. R. Meteorol. Soc. 2021, 147, 3759–3777. [Google Scholar] [CrossRef]
- Cheng, S.; Chen, J.; Anastasiou, C.; Angeli, P.; Matar, O.K.; Guo, Y.K.; Pain, C.C.; Arcucci, R. Generalised Latent Assimilation in Heterogeneous Reduced Spaces with Machine Learning Surrogate Models. arXiv 2022, arXiv:2204.03497. [Google Scholar]
- Carrassi, A.; Bocquet, M.; Bertino, L.; Evensen, G. Data assimilation in the geosciences: An overview of methods, issues, and perspectives. Wiley Interdiscip. Rev. Clim. Chang. 2018, 9, e535. [Google Scholar] [CrossRef] [Green Version]
- Cheng, S.; Argaud, J.P.; Iooss, B.; Lucor, D.; Ponçot, A. Background error covariance iterative updating with invariant observation measures for data assimilation. Stoch. Environ. Res. Risk Assess. 2019, 33, 2033–2051. [Google Scholar] [CrossRef] [Green Version]
- Ide, K.; Courtier, P.; Ghil, M.; Lorenc, A.C. Unified notation for data assimilation: Operational, sequential and variational (gtspecial issueltdata assimilation in meteology and oceanography: Theory and practice). J. Meteorol. Soc. Jpn. Ser. II 1997, 75, 181–189. [Google Scholar] [CrossRef] [Green Version]
- Drury, S.A.; Rauscher, H.M.; Banwell, E.M.; Huang, S.; Lavezzo, T.L. The interagency fuels treatment decision support system: Functionality for fuels treatment planning. Fire Ecol. 2016, 12, 103–123. [Google Scholar] [CrossRef] [Green Version]
- Weise, D.R.; Biging, G.S. A qualitative comparison of fire spread models incorporating wind and slope effects. For. Sci. 1997, 43, 170–180. [Google Scholar]
- Hersbach, H. Copernicus Climate Change Service (C3S) (2017): ERA5: Fifth Generation of ECMWF Atmospheric Reanalyses of the Global Climate; Technical Report; Copernicus Climate Change Service Climate Data Store (CDS); ACM: New York, NY, USA, 2017. [Google Scholar]
- Giglio, L.; Schroeder, W.; Justice, C.O. The collection 6 MODIS active fire detection algorithm and fire products. Remote Sens. Environ. 2016, 178, 31–41. [Google Scholar] [CrossRef] [Green Version]
- Schroeder, W.; Oliva, P.; Giglio, L.; Csiszar, I.A. The New VIIRS 375 m active fire detection data product: Algorithm description and initial assessment. Remote Sens. Environ. 2014, 143, 85–96. [Google Scholar] [CrossRef]
- Scaduto, E.; Chen, B.; Jin, Y. Satellite-Based Fire Progression Mapping: A Comprehensive Assessment for Large Fires in Northern California. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5102–5114. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Lewis, R.J. An introduction to classification and regression tree (CART) analysis. In Proceedings of the Annual Meeting of the Society for Academic Emergency Medicine, San Francisco, CA, USA, 22–25 May 2000; Volume 14. [Google Scholar]
- Ram, P.; Sinha, K. Revisiting kd-tree for nearest neighbor search. In Proceedings of the 25th ACM Sigkdd International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1378–1388. [Google Scholar]
- Tandeo, P.; Ailliot, P.; Bocquet, M.; Carrassi, A.; Miyoshi, T.; Pulido, M.; Zhen, Y. A Review of Innovation-Based Methods to Jointly Estimate Model and Observation Error Covariance Matrices in Ensemble Data Assimilation. arXiv 2018, arXiv:1807.11221. [Google Scholar] [CrossRef]
- Cheng, S.; Qiu, M. Observation error covariance specification in dynamical systems for data assimilation using recurrent neural networks. Neural Comput. Appl. 2021, 1–19. [Google Scholar] [CrossRef]
- Fulton, W. Eigenvalues, invariant factors, highest weights, and Schubert calculus. Bull. Am. Math. Soc. 2000, 37, 209–250. [Google Scholar] [CrossRef] [Green Version]
- Trucchia, A.; D’Andrea, M.; Baghino, F.; Fiorucci, P.; Ferraris, L.; Negro, D.; Gollini, A.; Severino, M. PROPAGATOR: An operational cellular-automata based wildfire simulator. Fire 2020, 3, 26. [Google Scholar] [CrossRef]
- Freire, J.G.; DaCamara, C.C. Using cellular automata to simulate wildfire propagation and to assist in fire management. Nat. Hazards Earth Syst. Sci. 2019, 19, 169–179. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Peng, X.; Huang, Z.; Zhu, Y.; Saenko, K. Federated adversarial domain adaptation. arXiv 2019, arXiv:1911.02054. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fire | Latitude | Longitude | Area | Duration | Start | Wind |
|---|---|---|---|---|---|---|
| Chimney | 37.6230 | −119.8247 | ≈ | 23 days | 13 August 2016 | 23.56 mph |
| Ferguson | 35.7386 | −121.0743 | ≈ | 36 dyas | 13 July 2018 | 18.54 mph |
| Model/Hyperparameters | Grid Search Space | Final Set |
|---|---|---|
| CAE | ||
| Filter, Strides, Pooling size | / | Table 3 |
| Activation | {ReLu, LeakyReLu, Sigmoid} | Table 3 |
| Optimizer | {Adam, SGD} | Adam |
| Batch size | 32 | |
| RF | ||
| split criteria | {‘gini’, ‘entropy’} | ‘gini’ |
| 100 | ||
| {‘log2’, ‘sqrt’} | ‘sqrt’ | |
| KNN | ||
| k | {5, 10, 20} | 5 |
| Metric | ||
| MLP | ||
| {10, 20, 30} | 20 | |
| {30, 40, 50} | 30 | |
| Activation | {ReLu, LeakyReLu, Sigmoid} | |
| Optimizer | {Adam, SGD} | Adam |
| GLA | ||
| 2–6 | 4 | |
| 1000 | ||
| 50–200% |
| Layer (Type) | Output Shape | Activation |
|---|---|---|
| Encoder | ||
| Input | ||
| Conv 2D (10 × 10) | ReLu | |
| MaxPooling 2D (5 × 5) | ||
| Conv 2D (4 × 4) | ReLu | |
| MaxPooling 2D (3 × 3) | ||
| Conv 2D (3 × 3) | ReLu | |
| MaxPooling 2D (3 × 3) | ||
| Conv 2D (2 × 2) | ReLu | |
| MaxPooling 2D (2 × 2) | ||
| Flatten | 880 | |
| Dense | q | LeakyReLu (0.3) |
| Decoder | ||
| Input | q | |
| Dense | 110 | LeakyReLu (0.3) |
| Reshape | ||
| Conv 2D (2 × 2) | ReLu | |
| Upsampling 2D (2 × 2) | ||
| Conv 2D (3 × 3) | ReLu | |
| Upsampling 2D (3 × 3) | ||
| Conv 2D (4 × 4) | ReLu | |
| Upsampling 2D (3 × 3) | ||
| Conv 2D (5 × 5) | ReLu | |
| Upsampling 2D (5 × 5) | ||
| Cropping 2D | ||
| Conv 2D (8 × 8) | Sigmoid |
| ML Approache | Chimney | Ferguson | ||||
|---|---|---|---|---|---|---|
| PCA | CAE | SVD AE | PCA | CAE | SVD AE | |
| KNN | 1.87% | 4.95% | 1.88% | 2.00 % | 3.30% | 2.73% |
| RF | 1.70% | 4.91% | 1.80% | 1.89% | 3.27% | 2.45% |
| MLP | 1.71% | 4.54% | 1.59% | 2.13% | 3.11% | 2.54% |
| Fire | Offline ROM and ML Training | Online Prediction | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PCA | CAE | SVD AE | KNN | RF | MLP | CA | PCA | CAE | SVD AE | |
| Chimney | 101.06 s | ≈1 h 38 min | 414.55 s | 0.02 s | 0.67 s | 108 s | ≈35 min | 0.52 s | 0.41 s | 14.47 s |
| Ferguson | 97.50 s | ≈1 h 29 min | 316.61 s | 0.02 s | 0.54 s | 116 s | ≈29 min | 0.25 s | 0.31 s | 18.62 s |
| Fire | Data | Forward | PCA | CAE | ||||
|---|---|---|---|---|---|---|---|---|
| Prior | Posterior | Time | Prior | Posterior | Time | |||
| Chimney | CA(test) | KNN | 10.1% | 6.0% | 0.98 s | 11.1% | 7.5% | 0.52 s |
| RF | 10.4% | 5.7% | 0.78 s | 10.2% | 6.6% | 0.45 s | ||
| MLP | 10.9% | 6.3% | 1.25 s | 10.6% | 5.0% | 0.46 s | ||
| observation | MLP | 8.3% | 5.0% | 9.65% | 6.5% | |||
| Ferguson | CA(test) | KNN | 30.5% | 20.3% | 0.74 s | 21.3% | 9.4% | 0.60 s |
| RF | 27.0% | 22.5% | 0.60 s | 23.1% | 13.6% | 0.58 s | ||
| MLP | 30.7% | 17.9% | 0.76 s | 22.4% | 12.6% | 0.88 s | ||
| observation | MLP | 41.6% | 14.8% | 23.8% | 11.9% | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Jin, Y.; Harrison, S.P.; Quilodrán-Casas, C.; Prentice, I.C.; Guo, Y.-K.; Arcucci, R. Parameter Flexible Wildfire Prediction Using Machine Learning Techniques: Forward and Inverse Modelling. Remote Sens. 2022, 14, 3228. https://doi.org/10.3390/rs14133228
Cheng S, Jin Y, Harrison SP, Quilodrán-Casas C, Prentice IC, Guo Y-K, Arcucci R. Parameter Flexible Wildfire Prediction Using Machine Learning Techniques: Forward and Inverse Modelling. Remote Sensing. 2022; 14(13):3228. https://doi.org/10.3390/rs14133228
Chicago/Turabian StyleCheng, Sibo, Yufang Jin, Sandy P. Harrison, César Quilodrán-Casas, Iain Colin Prentice, Yi-Ke Guo, and Rossella Arcucci. 2022. "Parameter Flexible Wildfire Prediction Using Machine Learning Techniques: Forward and Inverse Modelling" Remote Sensing 14, no. 13: 3228. https://doi.org/10.3390/rs14133228
APA StyleCheng, S., Jin, Y., Harrison, S. P., Quilodrán-Casas, C., Prentice, I. C., Guo, Y.-K., & Arcucci, R. (2022). Parameter Flexible Wildfire Prediction Using Machine Learning Techniques: Forward and Inverse Modelling. Remote Sensing, 14(13), 3228. https://doi.org/10.3390/rs14133228